 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Framework based on Deep Neural Networks to Extract Anatomy of Mosquitoes from Images
Jul 21, 2020
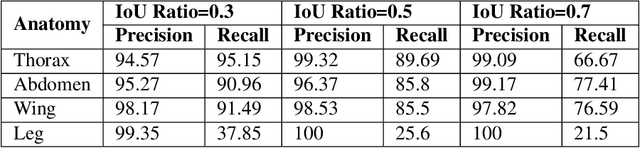
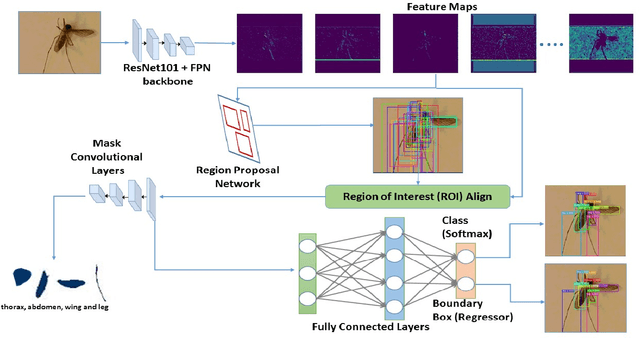
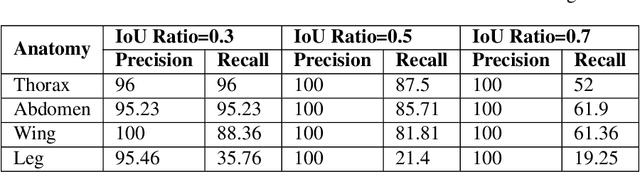

We design a framework based on Mask Region-based Convolutional Neural Network (Mask R-CNN) to automatically detect and separately extract anatomical components of mosquitoes - thorax, wings, abdomen and legs from images. Our training dataset consisted of 1500 smartphone images of nine mosquito species trapped in Florida. In the proposed technique, the first step is to detect anatomical components within a mosquito image. Then, we localize and classify the extracted anatomical components, while simultaneously adding a branch in the neural network architecture to segment pixels containing only the anatomical components. Evaluation results are favorable. To evaluate generality, we test our architecture trained only with mosquito images on bumblebee images. We again reveal favorable results, particularly in extracting wings. Our techniques in this paper have practical applications in public health, taxonomy and citizen-science efforts.
A Dual-Source Approach for 3D Human Pose Estimation from a Single Image
Sep 06, 2017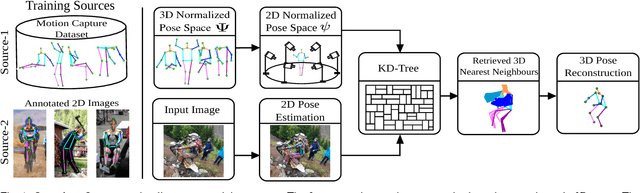
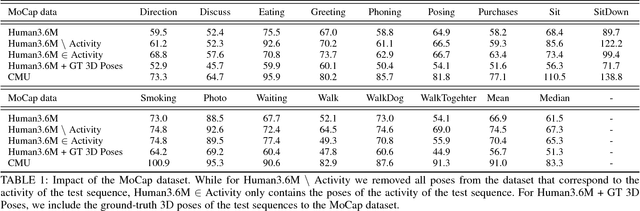
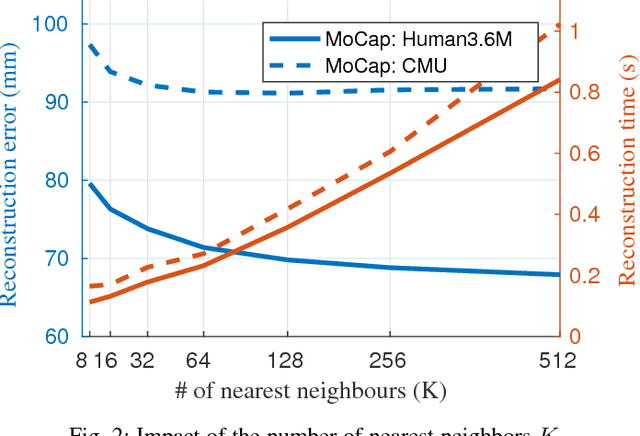
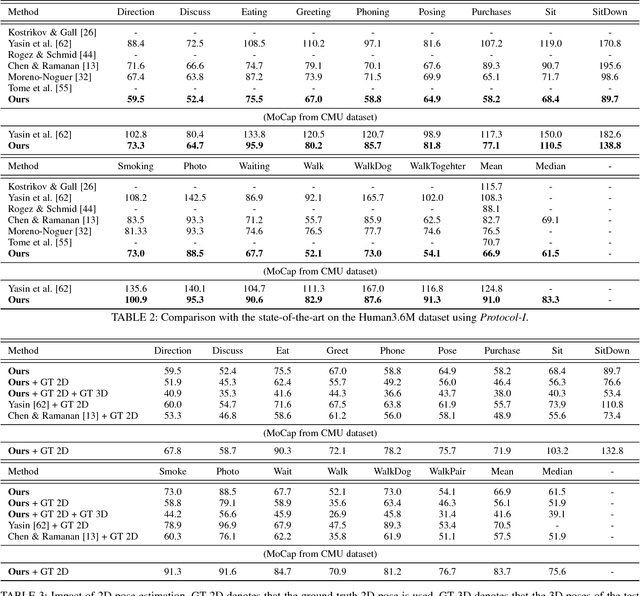
In this work we address the challenging problem of 3D human pose estimation from single images. Recent approaches learn deep neural networks to regress 3D pose directly from images. One major challenge for such methods, however, is the collection of training data. Specifically, collecting large amounts of training data containing unconstrained images annotated with accurate 3D poses is infeasible. We therefore propose to use two independent training sources. The first source consists of accurate 3D motion capture data, and the second source consists of unconstrained images with annotated 2D poses. To integrate both sources, we propose a dual-source approach that combines 2D pose estimation with efficient 3D pose retrieval. To this end, we first convert the motion capture data into a normalized 2D pose space, and separately learn a 2D pose estimation model from the image data. During inference, we estimate the 2D pose and efficiently retrieve the nearest 3D poses. We then jointly estimate a mapping from the 3D pose space to the image and reconstruct the 3D pose. We provide a comprehensive evaluation of the proposed method and experimentally demonstrate the effectiveness of our approach, even when the skeleton structures of the two sources differ substantially.
Photosequencing of Motion Blur using Short and Long Exposures
Dec 11, 2019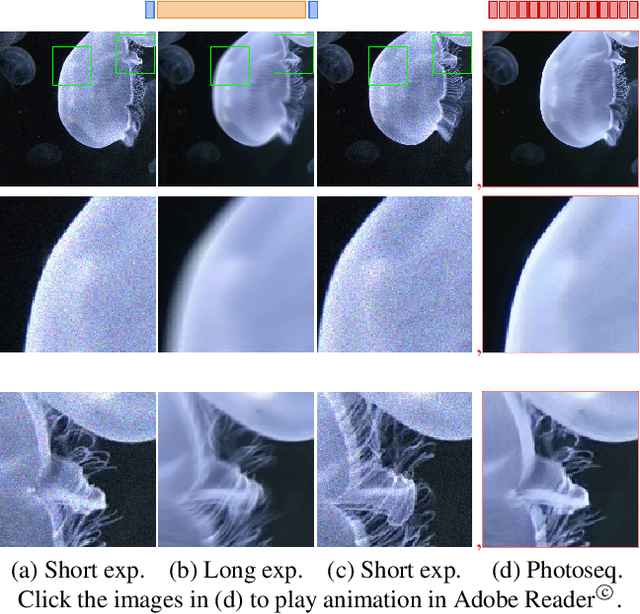

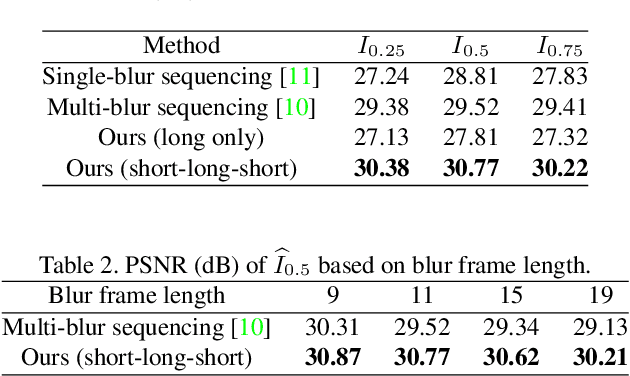
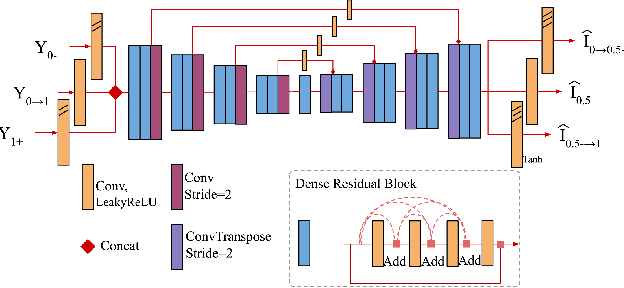
Photosequencing aims to transform a motion blurred image to a sequence of sharp images. This problem is challenging due to the inherent ambiguities in temporal ordering as well as the recovery of lost spatial textures due to blur. Adopting a computational photography approach, we propose to capture two short exposure images, along with the original blurred long exposure image to aid in the aforementioned challenges. Post-capture, we recover the sharp photosequence using a novel blur decomposition strategy that recursively splits the long exposure image into smaller exposure intervals. We validate the approach by capturing a variety of scenes with interesting motions using machine vision cameras programmed to capture short and long exposure sequences. Our experimental results show that the proposed method resolves both fast and fine motions better than prior works.
Deeply-Recursive Convolutional Network for Image Super-Resolution
Nov 11, 2016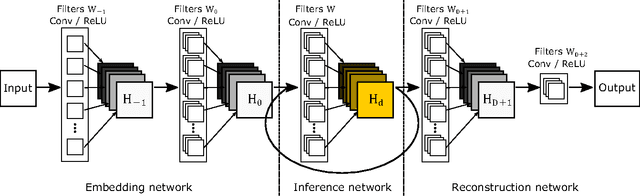
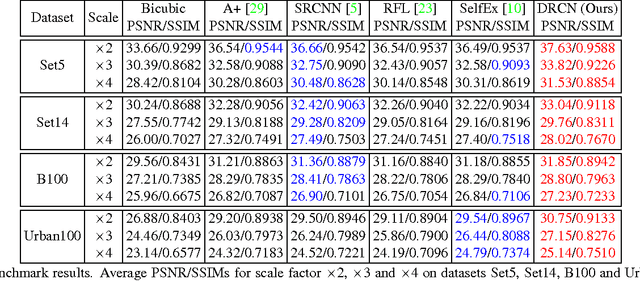
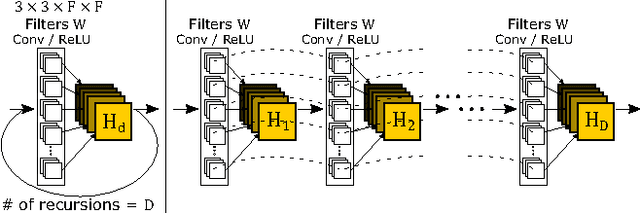
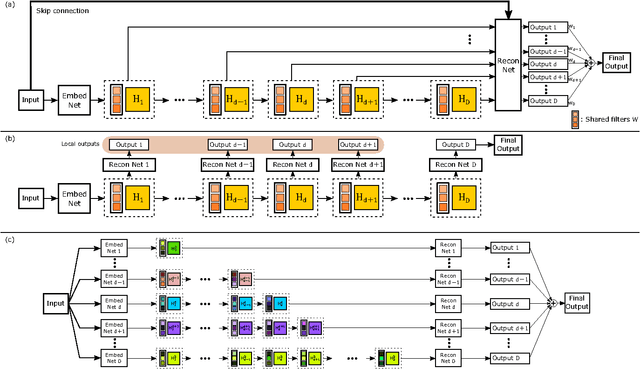
We propose an image super-resolution method (SR) using a deeply-recursive convolutional network (DRCN). Our network has a very deep recursive layer (up to 16 recursions). Increasing recursion depth can improve performance without introducing new parameters for additional convolutions. Albeit advantages, learning a DRCN is very hard with a standard gradient descent method due to exploding/vanishing gradients. To ease the difficulty of training, we propose two extensions: recursive-supervision and skip-connection. Our method outperforms previous methods by a large margin.
A Convex Approach for Image Hallucination
Apr 26, 2013



In this paper we propose a global convex approach for image hallucination. Altering the idea of classical multi image super resolution (SU) systems to single image SU, we incorporate aligned images to hallucinate the output. Our work is based on the paper of Tappen et al. where they use a non-convex model for image hallucination. In comparison we formulate a convex primal optimization problem and derive a fast converging primal-dual algorithm with a global optimal solution. We use a database with face images to incorporate high-frequency details to the high-resolution output. We show that we can achieve state-of-the-art results by using a convex approach.
The VISIONE Video Search System: Exploiting Off-the-Shelf Text Search Engines for Large-Scale Video Retrieval
Aug 06, 2020
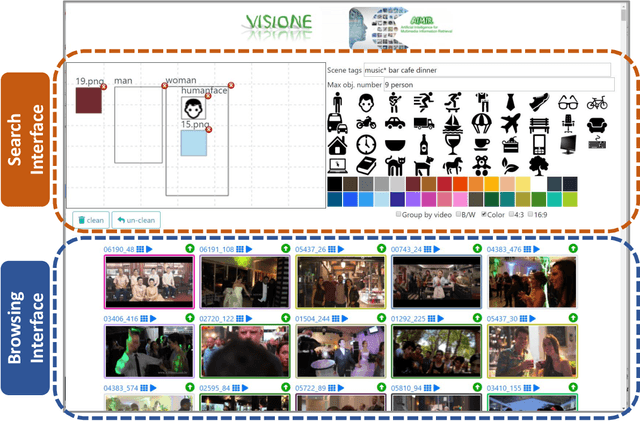
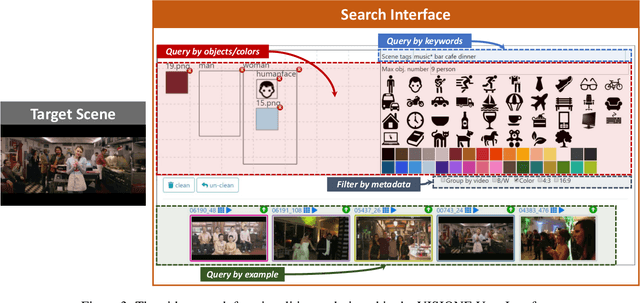
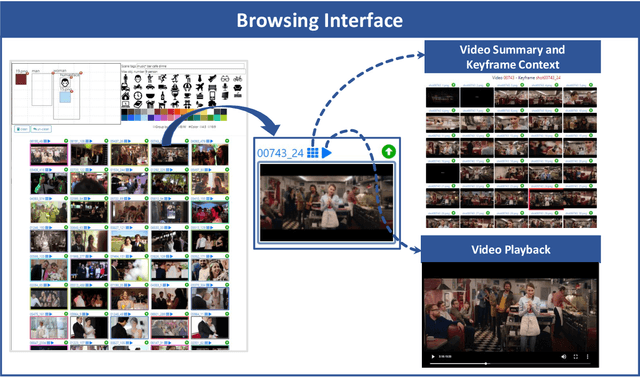
In this paper, we describe VISIONE, a video search system that allows users to search for videos using textual keywords, occurrence of objects and their spatial relationships, occurrence of colors and their spatial relationships, and image similarity. These modalities can be combined together to express complex queries and satisfy user needs. The peculiarity of our approach is that we encode all the information extracted from the keyframes, such as visual deep features, tags, color and object locations, using a convenient textual encoding indexed in a single text retrieval engine. This offers great flexibility when results corresponding to various parts of the query needs to be merged. We report an extensive analysis of the system retrieval performance, using the query logs generated during the Video Browser Showdown (VBS) 2019 competition. This allowed us to fine-tune the system by choosing the optimal parameters and strategies among the ones that we tested.
Deep learning with 4D spatio-temporal data representations for OCT-based force estimation
May 20, 2020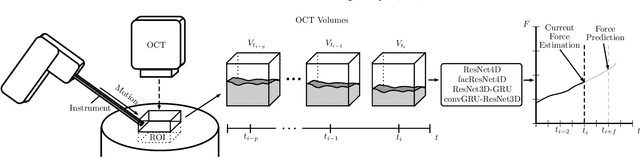
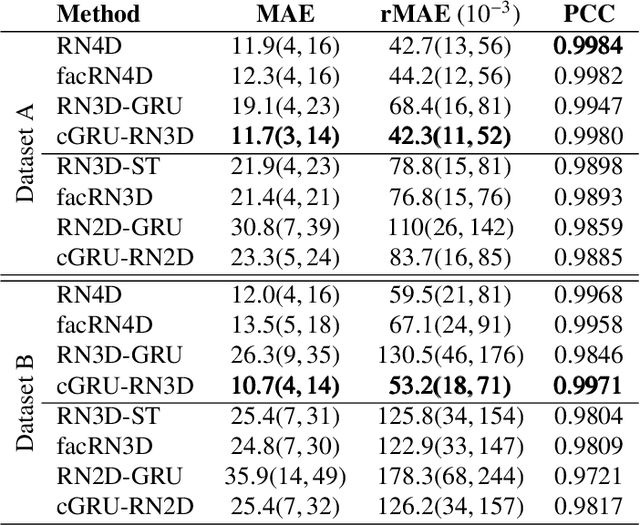
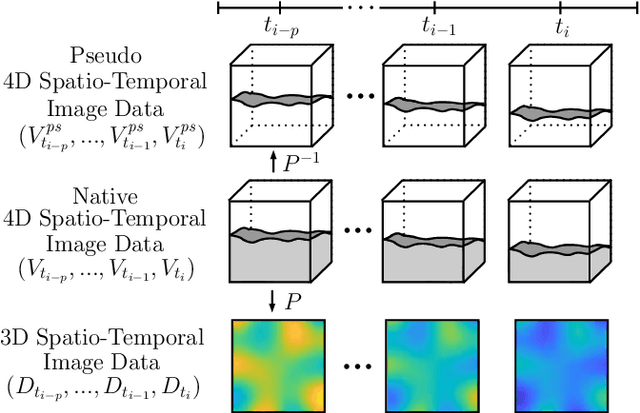
Estimating the forces acting between instruments and tissue is a challenging problem for robot-assisted minimally-invasive surgery. Recently, numerous vision-based methods have been proposed to replace electro-mechanical approaches. Moreover, optical coherence tomography (OCT) and deep learning have been used for estimating forces based on deformation observed in volumetric image data. The method demonstrated the advantage of deep learning with 3D volumetric data over 2D depth images for force estimation. In this work, we extend the problem of deep learning-based force estimation to 4D spatio-temporal data with streams of 3D OCT volumes. For this purpose, we design and evaluate several methods extending spatio-temporal deep learning to 4D which is largely unexplored so far. Furthermore, we provide an in-depth analysis of multi-dimensional image data representations for force estimation, comparing our 4D approach to previous, lower-dimensional methods. Also, we analyze the effect of temporal information and we study the prediction of short-term future force values, which could facilitate safety features. For our 4D force estimation architectures, we find that efficient decoupling of spatial and temporal processing is advantageous. We show that using 4D spatio-temporal data outperforms all previously used data representations with a mean absolute error of 10.7mN. We find that temporal information is valuable for force estimation and we demonstrate the feasibility of force prediction.
Satellite Image-based Localization via Learned Embeddings
Apr 04, 2017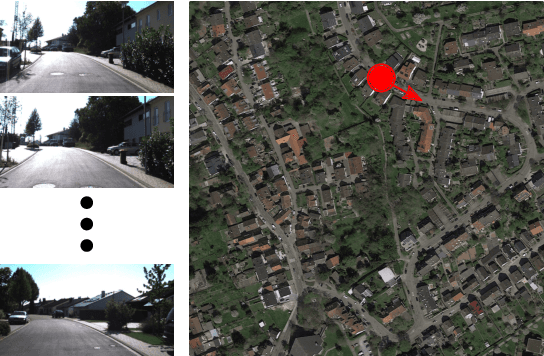
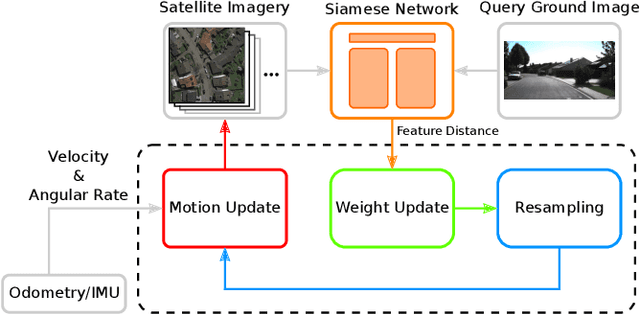

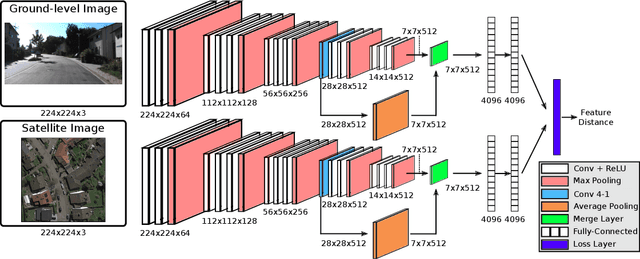
We propose a vision-based method that localizes a ground vehicle using publicly available satellite imagery as the only prior knowledge of the environment. Our approach takes as input a sequence of ground-level images acquired by the vehicle as it navigates, and outputs an estimate of the vehicle's pose relative to a georeferenced satellite image. We overcome the significant viewpoint and appearance variations between the images through a neural multi-view model that learns location-discriminative embeddings in which ground-level images are matched with their corresponding satellite view of the scene. We use this learned function as an observation model in a filtering framework to maintain a distribution over the vehicle's pose. We evaluate our method on different benchmark datasets and demonstrate its ability localize ground-level images in environments novel relative to training, despite the challenges of significant viewpoint and appearance variations.
Deep Fence Estimation using Stereo Guidance and Adversarial Learning
Jul 03, 2020
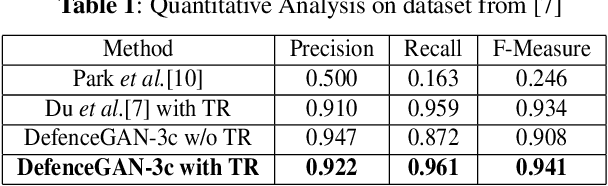
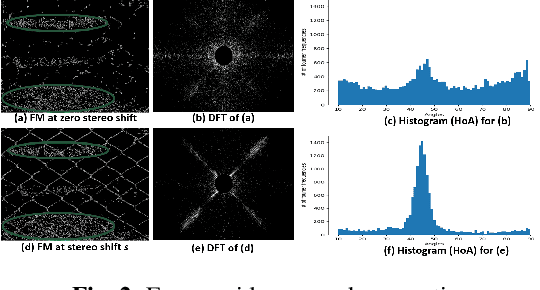
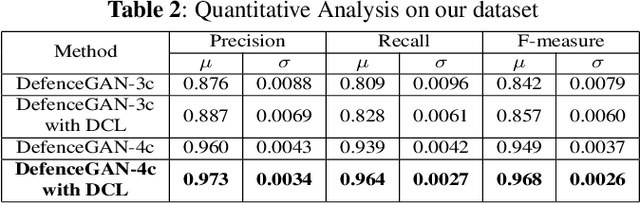
People capture memorable images of events and exhibits that are often occluded by a wire mesh loosely termed as fence. Recent works in removing fence have limited performance due to the difficulty in initial fence segmentation. This work aims to accurately segment fence using a novel fence guidance mask (FM) generated from stereo image pair. This binary guidance mask contains deterministic cues about the structure of fence and is given as additional input to the deep fence estimation model. We also introduce a directional connectivity loss (DCL), which is used alongside adversarial loss to precisely detect thin wires. Experimental results obtained on real world scenarios demonstrate the superiority of proposed method over state-of-the-art techniques.
Direct CMOS Implementation of Neuromorphic Temporal Neural Networks for Sensory Processing
Aug 27, 2020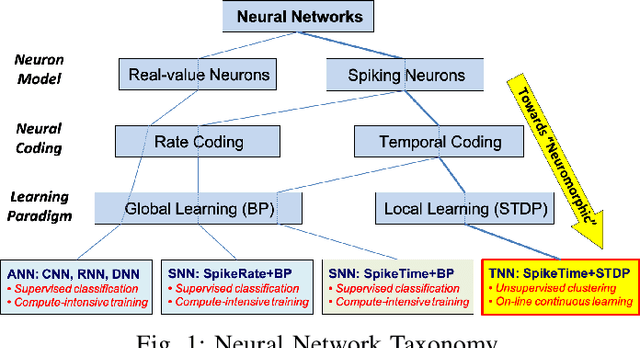
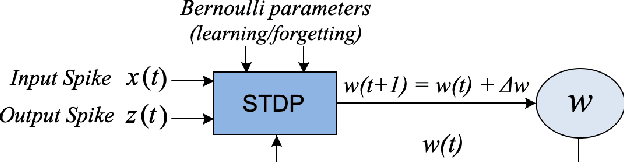
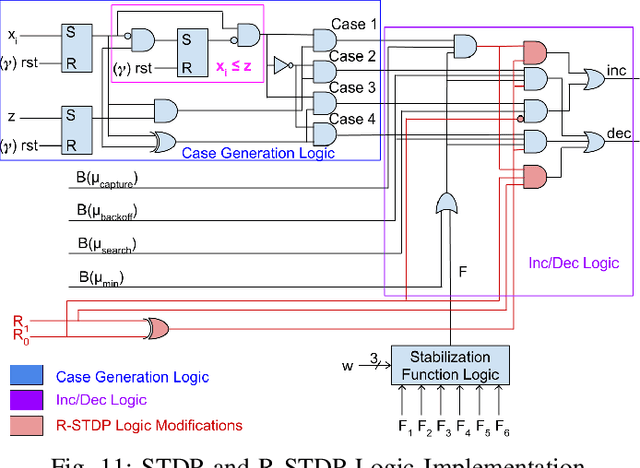
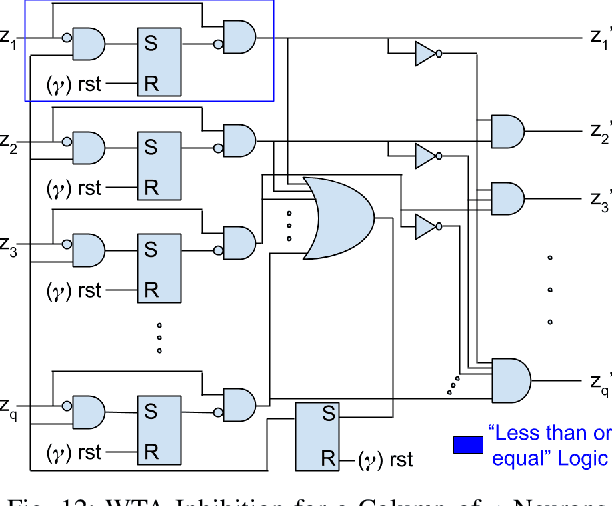
Temporal Neural Networks (TNNs) use time as a resource to represent and process information, mimicking the behavior of the mammalian neocortex. This work focuses on implementing TNNs using off-the-shelf digital CMOS technology. A microarchitecture framework is introduced with a hierarchy of building blocks including: multi-neuron columns, multi-column layers, and multi-layer TNNs. We present the direct CMOS gate-level implementation of the multi-neuron column model as the key building block for TNNs. Post-synthesis results are obtained using Synopsys tools and the 45 nm CMOS standard cell library. The TNN microarchitecture framework is embodied in a set of characteristic equations for assessing the total gate count, die area, compute time, and power consumption for any TNN design. We develop a multi-layer TNN prototype of 32M gates. In 7 nm CMOS process, it consumes only 1.54 mm^2 die area and 7.26 mW power and can process 28x28 images at 107M FPS (9.34 ns per image). We evaluate the prototype's performance and complexity relative to a recent state-of-the-art TNN model.