 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adaptive Signal Variances: CNN Initialization Through Modern Architectures
Aug 16, 2020
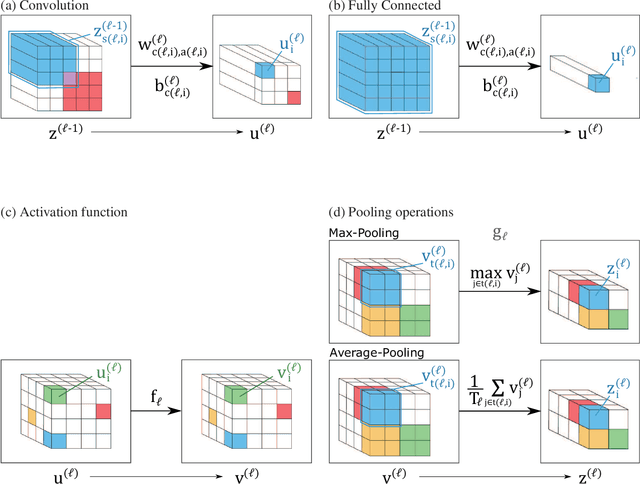


Deep convolutional neural networks (CNN) have achieved the unwavering confidence in its performance on image processing tasks. The CNN architecture constitutes a variety of different types of layers including the convolution layer and the max-pooling layer. CNN practitioners widely understandthe fact that the stability of learning depends on how to initialize the model parameters in each layer. Nowadays, no one doubts that the de facto standard scheme for initialization is the so-called Kaiming initialization that has been developed by He et al. The Kaiming scheme was derived from a much simpler model than the currently used CNN structure having evolved since the emergence of the Kaiming scheme. The Kaiming model consists only of the convolution and fully connected layers, ignoring the max-pooling layer and the global average pooling layer. In this study, we derived the initialization scheme again not from the simplified Kaiming model, but precisely from the modern CNN architectures.
Audio Dequantization for High Fidelity Audio Generation in Flow-based Neural Vocoder
Aug 16, 2020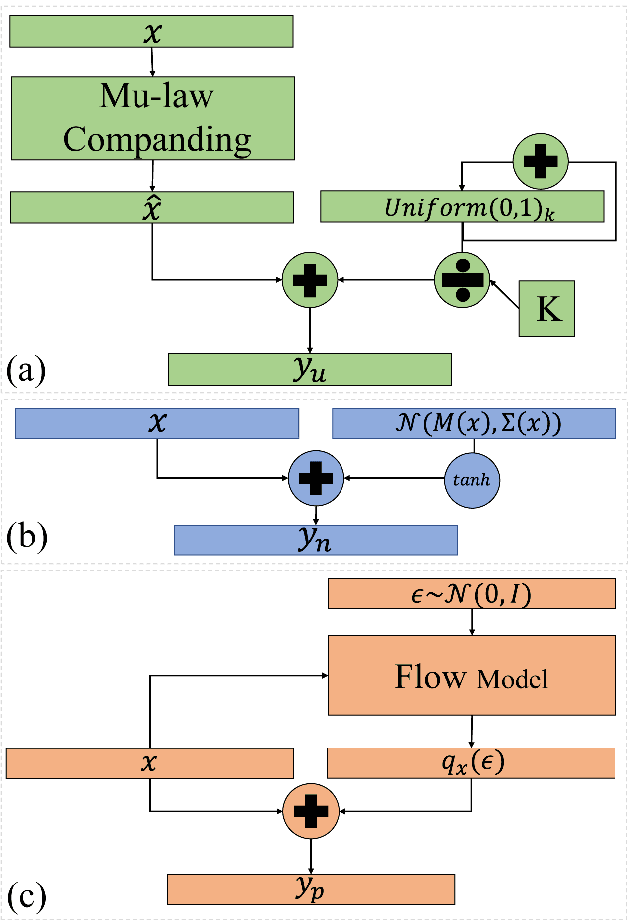
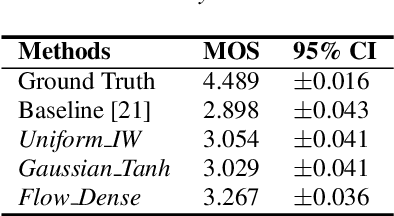
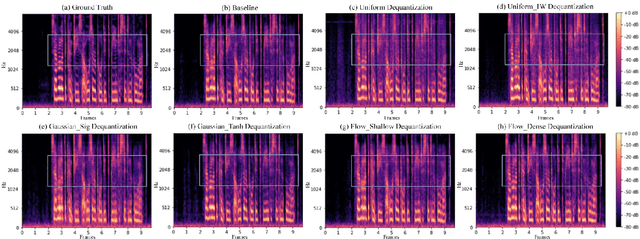

In recent works, a flow-based neural vocoder has shown significant improvement in real-time speech generation task. The sequence of invertible flow operations allows the model to convert samples from simple distribution to audio samples. However, training a continuous density model on discrete audio data can degrade model performance due to the topological difference between latent and actual distribution. To resolve this problem, we propose audio dequantization methods in flow-based neural vocoder for high fidelity audio generation. Data dequantization is a well-known method in image generation but has not yet been studied in the audio domain. For this reason, we implement various audio dequantization methods in flow-based neural vocoder and investigate the effect on the generated audio. We conduct various objective performance assessments and subjective evaluation to show that audio dequantization can improve audio generation quality. From our experiments, using audio dequantization produces waveform audio with better harmonic structure and fewer digital artifacts.
TextDecepter: Hard Label Black Box Attack on Text Classifiers
Aug 16, 2020
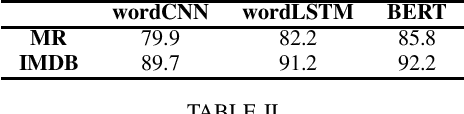
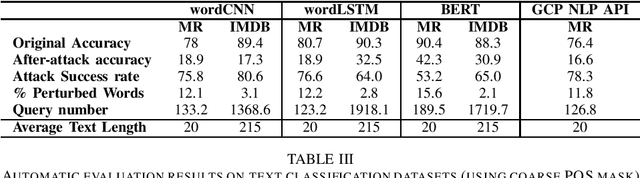
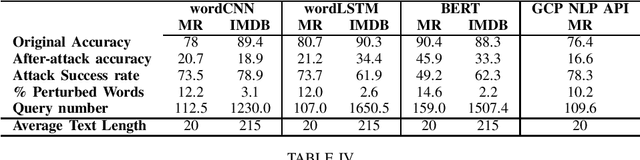
Machine learning has been proven to be susceptible to carefully crafted samples, known as adversarialexamples. The generation of these adversarial examples helps to make the models more robust and give as an insight of the underlying decision making of these models. Over the years, researchers have successfully attacked image classifiers in, both, white and black-box setting. Although, these methods are not directly applicable to texts as text data is discrete in nature. In recent years, research on crafting adversarial examples against textual applications has been on the rise. In this paper, we present a novel approach for hard label black-box attacks against Natural Language Processing (NLP) classifiers, where no model information is disclosed, and an attacker can only query the model to get final decision of the classifier, without confidence scores of the classes involved. Such attack scenario is applicable to real world black-box models being used for security-sensitive applications such as sentiment analysis and toxic content detection
An Image Enhancing Pattern-based Sparsity for Real-time Inference on Mobile Devices
Feb 22, 2020
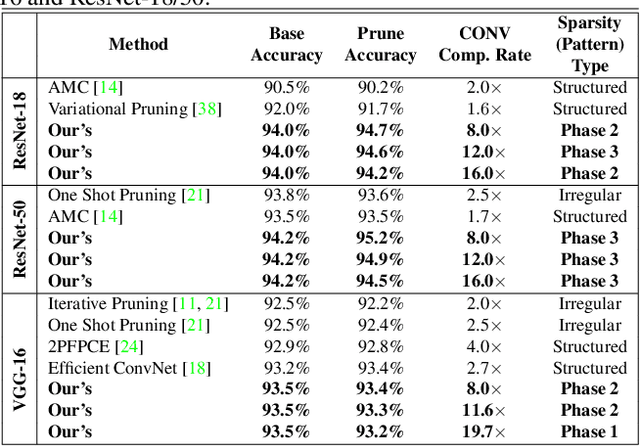
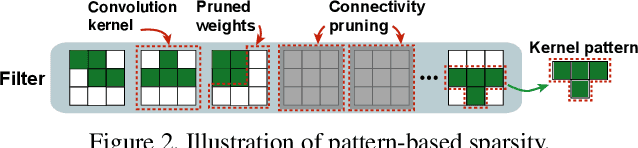
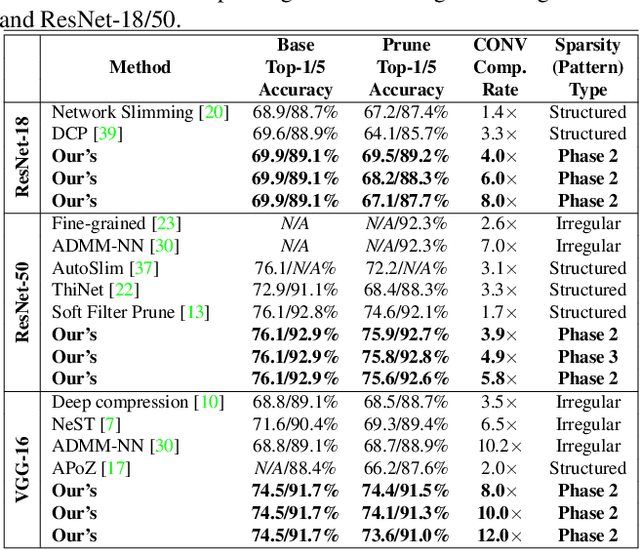
Weight pruning has been widely acknowledged as a straightforward and effective method to eliminate redundancy in Deep Neural Networks (DNN), thereby achieving acceleration on various platforms. However, most of the pruning techniques are essentially trade-offs between model accuracy and regularity which lead to impaired inference accuracy and limited on-device acceleration performance. To solve the problem, we introduce a new sparsity dimension, namely pattern-based sparsity that comprises pattern and connectivity sparsity, and becoming both highly accurate and hardware friendly. With carefully designed patterns, the proposed pruning unprecedentedly and consistently achieves accuracy enhancement and better feature extraction ability on different DNN structures and datasets, and our pattern-aware pruning framework also achieves pattern library extraction, pattern selection, pattern and connectivity pruning and weight training simultaneously. Our approach on the new pattern-based sparsity naturally fits into compiler optimization for highly efficient DNN execution on mobile platforms. To the best of our knowledge, it is the first time that mobile devices achieve real-time inference for the large-scale DNN models thanks to the unique spatial property of pattern-based sparsity and the help of the code generation capability of compilers.
Convex Shape Representation with Binary Labels for Image Segmentation: Models and Fast Algorithms
Feb 22, 2020
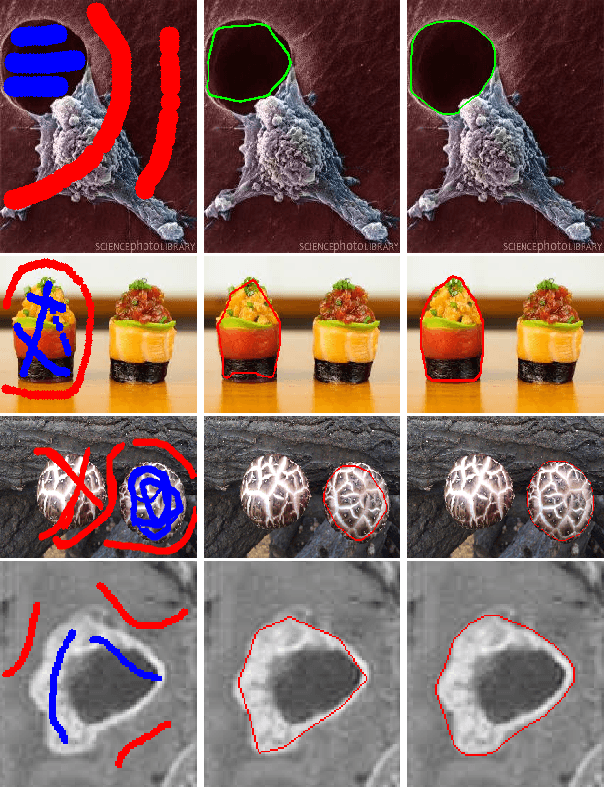

We present a novel and effective binary representation for convex shapes. We show the equivalence between the shape convexity and some properties of the associated indicator function. The proposed method has two advantages. Firstly, the representation is based on a simple inequality constraint on the binary function rather than the definition of convex shapes, which allows us to obtain efficient algorithms for various applications with convexity prior. Secondly, this method is independent of the dimension of the concerned shape. In order to show the effectiveness of the proposed representation approach, we incorporate it with a probability based model for object segmentation with convexity prior. Efficient algorithms are given to solve the proposed models using Lagrange multiplier methods and linear approximations. Various experiments are given to show the superiority of the proposed methods.
Sparse Representation of a Blur Kernel for Blind Image Restoration
Dec 14, 2015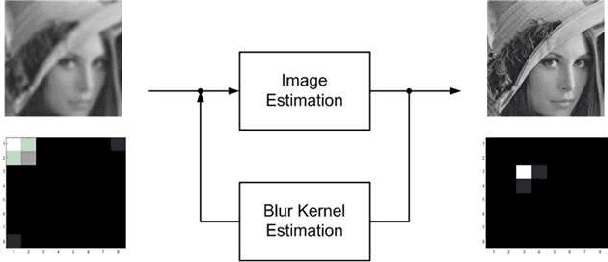
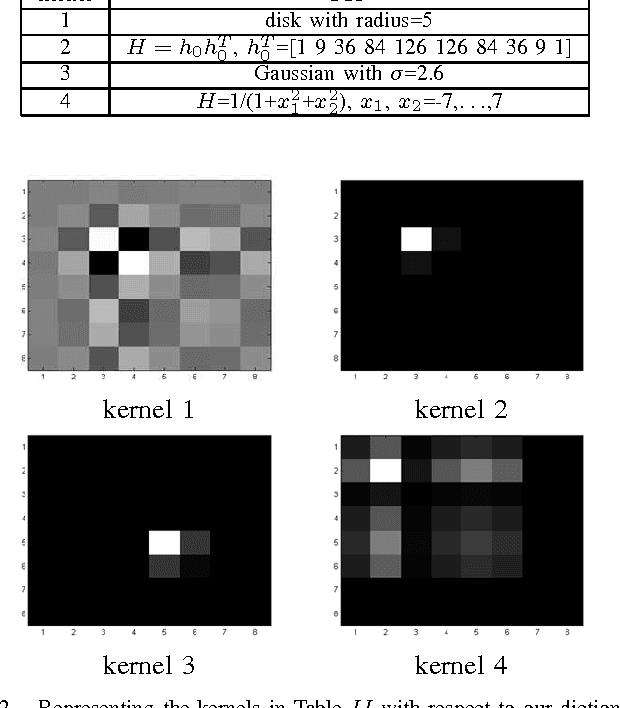

Blind image restoration is a non-convex problem which involves restoration of images from an unknown blur kernel. The factors affecting the performance of this restoration are how much prior information about an image and a blur kernel are provided and what algorithm is used to perform the restoration task. Prior information on images is often employed to restore the sharpness of the edges of an image. By contrast, no consensus is still present regarding what prior information to use in restoring from a blur kernel due to complex image blurring processes. In this paper, we propose modelling of a blur kernel as a sparse linear combinations of basic 2-D patterns. Our approach has a competitive edge over the existing blur kernel modelling methods because our method has the flexibility to customize the dictionary design, which makes it well-adaptive to a variety of applications. As a demonstration, we construct a dictionary formed by basic patterns derived from the Kronecker product of Gaussian sequences. We also compare our results with those derived by other state-of-the-art methods, in terms of peak signal to noise ratio (PSNR).
Bone marrow cells detection: A technique for the microscopic image analysis
May 05, 2018
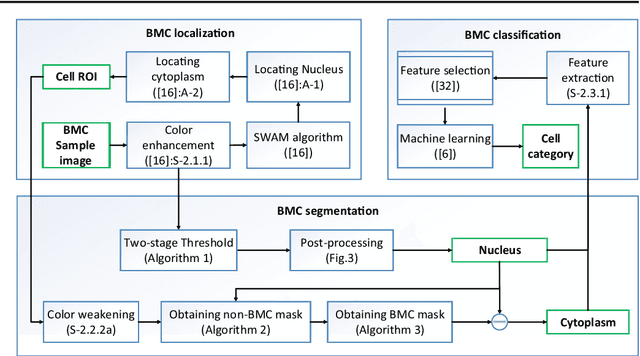

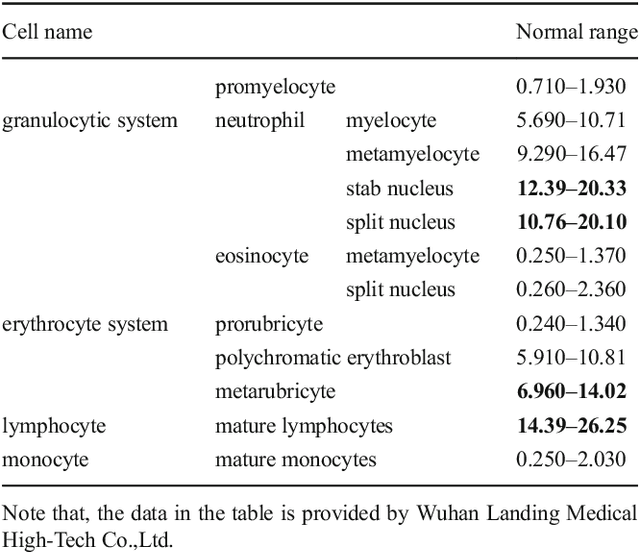
In the detection of myeloproliferative, the number of cells in each type of bone marrow cells (BMC) is an important parameter for the evaluation. In this study, we propose a new counting method, which also consists of three modules including localization, segmentation and classification. The localization of BMC is achieved from a color transformation enhanced BMC sample image and stepwise averaging method (SAM). In the nucleus segmentation, both SAM and Otsu's method will be applied to obtain a weighted threshold for segmenting the patch into nucleus and non-nucleus. In the cytoplasm segmentation, a color weakening transformation, an improved region growing method and the K-Means algorithm are used. The connected cells with BMC will be separated by the marker-controlled watershed algorithm. The features will be extracted for the classification after the segmentation. In this study, the BMC are classified using the SVM, Random Forest, Artificial Neural Networks, Adaboost and Bayesian Networks into five classes including one outlier, namely, neutrophilic split granulocyte, neutrophilic stab granulocyte, metarubricyte, mature lymphocytes and the outlier (all other cells not listed). Our experimental results show that the best average recognition rate is 87.49% for the SVM.
A Mobile Robot Hand-Arm Teleoperation System by Vision and IMU
Mar 11, 2020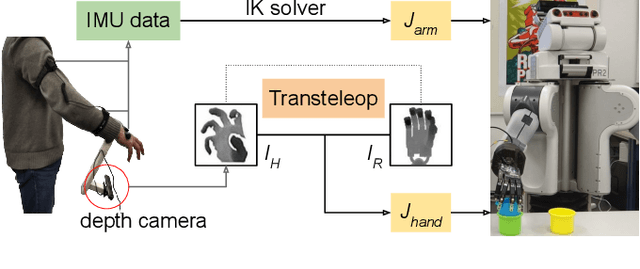
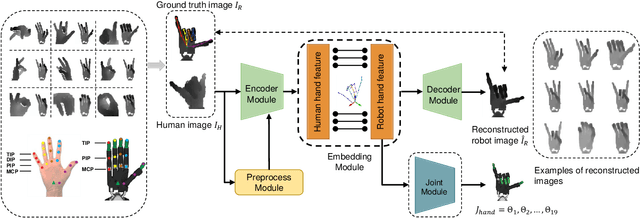


In this paper, we present a multimodal mobile teleoperation system that consists of a novel vision-based hand pose regression network (Transteleop) and an IMU-based arm tracking method. Transteleop observes the human hand through a low-cost depth camera and generates not only joint angles but also depth images of paired robot hand poses through an image-to-image translation process. A keypoint-based reconstruction loss explores the resemblance in appearance and anatomy between human and robotic hands and enriches the local features of reconstructed images. A wearable camera holder enables simultaneous hand-arm control and facilitates the mobility of the whole teleoperation system. Network evaluation results on a test dataset and a variety of complex manipulation tasks that go beyond simple pick-and-place operations show the efficiency and stability of our multimodal teleoperation system.
TP-LSD: Tri-Points Based Line Segment Detector
Sep 11, 2020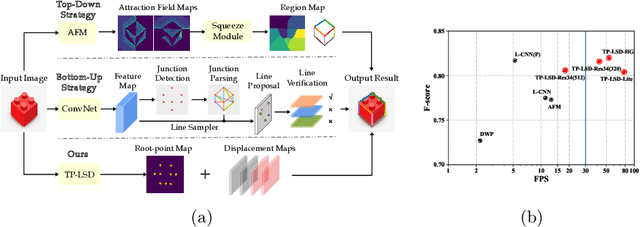
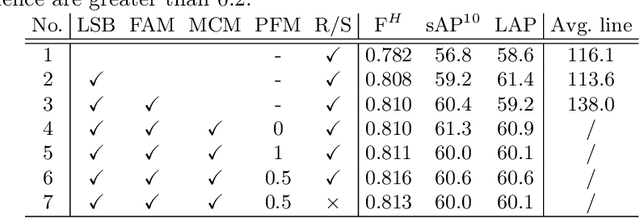

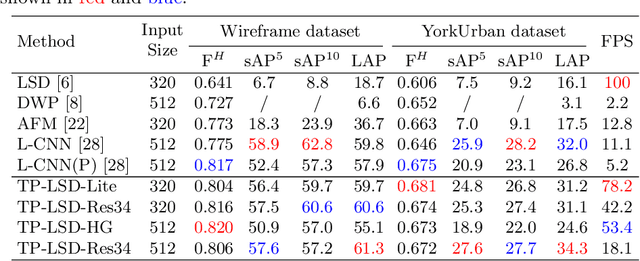
This paper proposes a novel deep convolutional model, Tri-Points Based Line Segment Detector (TP-LSD), to detect line segments in an image at real-time speed. The previous related methods typically use the two-step strategy, relying on either heuristic post-process or extra classifier. To realize one-step detection with a faster and more compact model, we introduce the tri-points representation, converting the line segment detection to the end-to-end prediction of a root-point and two endpoints for each line segment. TP-LSD has two branches: tri-points extraction branch and line segmentation branch. The former predicts the heat map of root-points and the two displacement maps of endpoints. The latter segments the pixels on straight lines out from background. Moreover, the line segmentation map is reused in the first branch as structural prior. We propose an additional novel evaluation metric and evaluate our method on Wireframe and YorkUrban datasets, demonstrating not only the competitive accuracy compared to the most recent methods, but also the real-time run speed up to 78 FPS with the $320\times 320$ input.
* Accepted by ECCV 2020
Multi-stage transfer learning for lung segmentation using portable X-ray devices for patients with COVID-19
Oct 30, 2020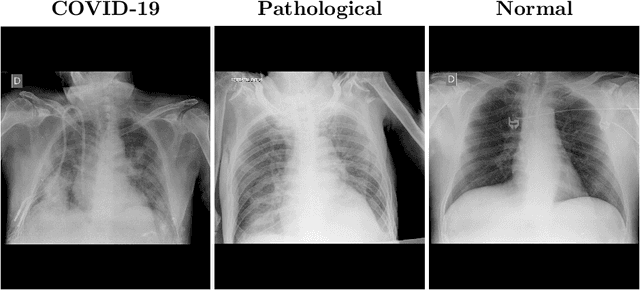
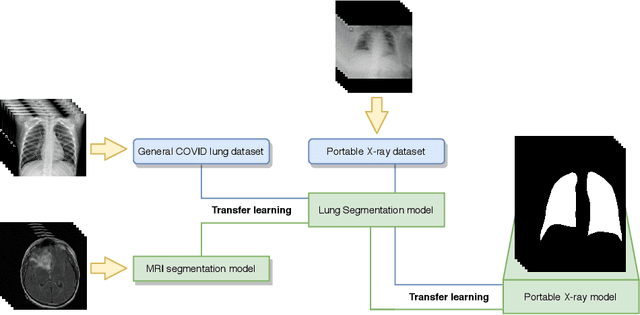

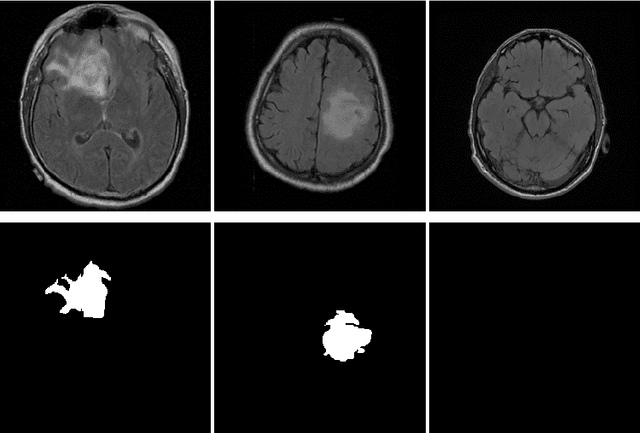
In 2020, the SARS-CoV-2 virus causes a global pandemic of the new human coronavirus disease COVID-19. This pathogen primarily infects the respiratory system of the afflicted, usually resulting in pneumonia and in a severe case of acute respiratory distress syndrome. These disease developments result in the formation of different pathological structures in the lungs, similar to those observed in other viral pneumonias that can be detected by the use of chest X-rays. For this reason, the detection and analysis of the pulmonary regions, the main focus of affection of COVID-19, becomes a crucial part of both clinical and automatic diagnosis processes. Due to the overload of the health services, portable X-ray devices are widely used, representing an alternative to fixed devices to reduce the risk of cross-contamination. However, these devices entail different complications as the image quality that, together with the subjectivity of the clinician, make the diagnostic process more difficult. In this work, we developed a novel fully automatic methodology specially designed for the identification of these lung regions in X-ray images of low quality as those from portable devices. To do so, we took advantage of a large dataset from magnetic resonance imaging of a similar pathology and performed two stages of transfer learning to obtain a robust methodology with a low number of images from portable X-ray devices. This way, our methodology obtained a satisfactory accuracy of $0.9761 \pm 0.0100$ for patients with COVID-19, $0.9801 \pm 0.0104$ for normal patients and $0.9769 \pm 0.0111$ for patients with pulmonary diseases with similar characteristics as COVID-19 (such as pneumonia) but not genuine COVID-19.