 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DropLeaf: a precision farming smartphone application for measuring pesticide spraying methods
Aug 31, 2020

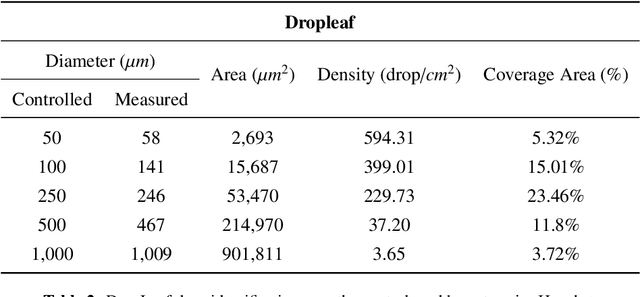
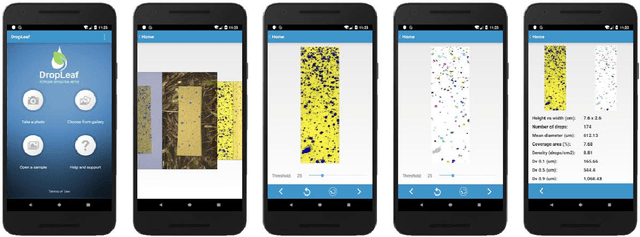
Pesticide application has been heavily used in the cultivation of major crops, contributing to the increase of crop production over the past decades. However, their appropriate use and calibration of machines rely upon evaluation methodologies that can precisely estimate how well the pesticides' spraying covered the crops. A few strategies have been proposed in former works, yet their elevated costs and low portability do not permit their wide adoption. This work introduces and experimentally assesses a novel tool that functions over a smartphone-based mobile application, named DropLeaf - Spraying Meter. Tests performed using DropLeaf demonstrated that, notwithstanding its versatility, it can estimate the pesticide spraying with high precision. Our methodology is based on image analysis, and the assessment of spraying deposition measures is performed successfully over real and synthetic water-sensitive papers. The proposed tool can be extensively used by farmers and agronomists furnished with regular smartphones, improving the utilization of pesticides with well-being, ecological, and monetary advantages. DropLeaf can be easily used for spray drift assessment of different methods, including emerging UAV (Unmanned Aerial Vehicle) sprayers.
Superpixel Segmentation with Fully Convolutional Networks
Mar 29, 2020
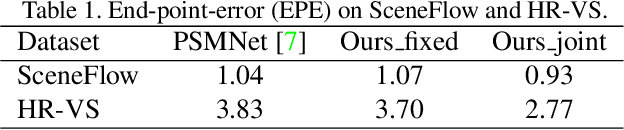

In computer vision, superpixels have been widely used as an effective way to reduce the number of image primitives for subsequent processing. But only a few attempts have been made to incorporate them into deep neural networks. One main reason is that the standard convolution operation is defined on regular grids and becomes inefficient when applied to superpixels. Inspired by an initialization strategy commonly adopted by traditional superpixel algorithms, we present a novel method that employs a simple fully convolutional network to predict superpixels on a regular image grid. Experimental results on benchmark datasets show that our method achieves state-of-the-art superpixel segmentation performance while running at about 50fps. Based on the predicted superpixels, we further develop a downsampling/upsampling scheme for deep networks with the goal of generating high-resolution outputs for dense prediction tasks. Specifically, we modify a popular network architecture for stereo matching to simultaneously predict superpixels and disparities. We show that improved disparity estimation accuracy can be obtained on public datasets.
Sketch-to-Art: Synthesizing Stylized Art Images From Sketches
Mar 03, 2020



We propose a new approach for synthesizing fully detailed art-stylized images from sketches. Given a sketch, with no semantic tagging, and a reference image of a specific style, the model can synthesize meaningful details with colors and textures. The model consists of three modules designed explicitly for better artistic style capturing and generation. Based on a GAN framework, a dual-masked mechanism is introduced to enforce the content constraints (from the sketch), and a feature-map transformation technique is developed to strengthen the style consistency (to the reference image). Finally, an inverse procedure of instance-normalization is proposed to disentangle the style and content information, therefore yields better synthesis performance. Experiments demonstrate a significant qualitative and quantitative boost over baselines based on previous state-of-the-art techniques, adopted for the proposed process.
SuperDeConFuse: A Supervised Deep Convolutional Transform based Fusion Framework for Financial Trading Systems
Nov 09, 2020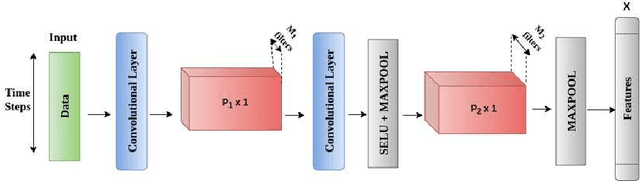
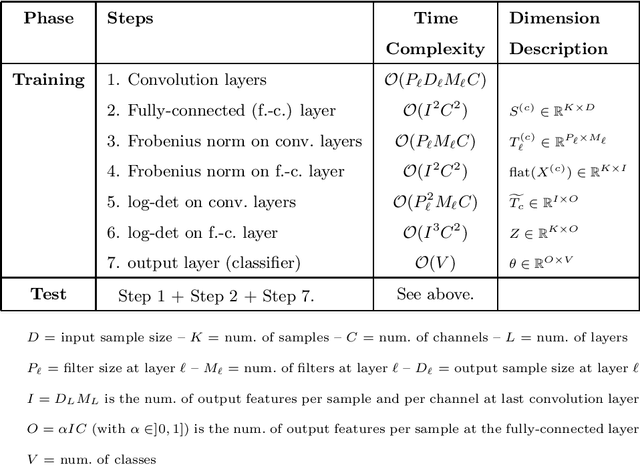
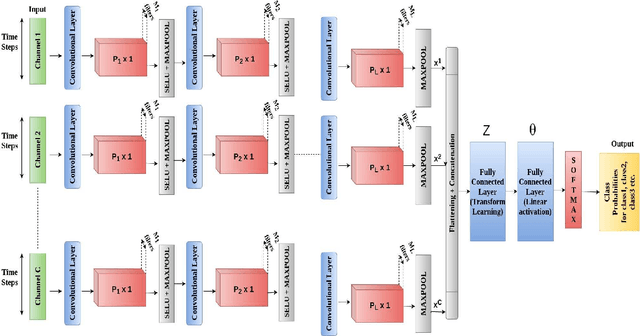
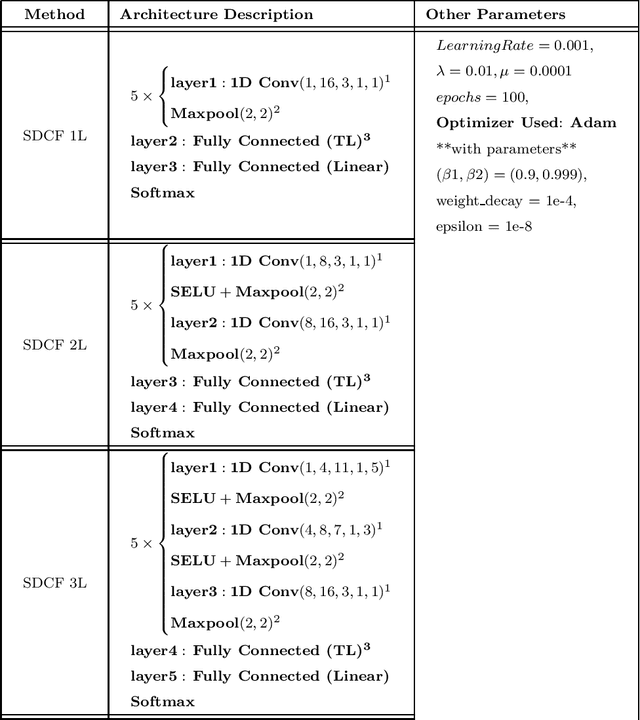
This work proposes a supervised multi-channel time-series learning framework for financial stock trading. Although many deep learning models have recently been proposed in this domain, most of them treat the stock trading time-series data as 2-D image data, whereas its true nature is 1-D time-series data. Since the stock trading systems are multi-channel data, many existing techniques treating them as 1-D time-series data are not suggestive of any technique to effectively fusion the information carried by the multiple channels. To contribute towards both of these shortcomings, we propose an end-to-end supervised learning framework inspired by the previously established (unsupervised) convolution transform learning framework. Our approach consists of processing the data channels through separate 1-D convolution layers, then fusing the outputs with a series of fully-connected layers, and finally applying a softmax classification layer. The peculiarity of our framework - SuperDeConFuse (SDCF), is that we remove the nonlinear activation located between the multi-channel convolution layers and the fully-connected layers, as well as the one located between the latter and the output layer. We compensate for this removal by introducing a suitable regularization on the aforementioned layer outputs and filters during the training phase. Specifically, we apply a logarithm determinant regularization on the layer filters to break symmetry and force diversity in the learnt transforms, whereas we enforce the non-negativity constraint on the layer outputs to mitigate the issue of dead neurons. This results in the effective learning of a richer set of features and filters with respect to a standard convolutional neural network. Numerical experiments confirm that the proposed model yields considerably better results than state-of-the-art deep learning techniques for real-world problem of stock trading.
Text Recognition -- Real World Data and Where to Find Them
Jul 06, 2020



We present a method for exploiting weakly annotated images to improve text extraction pipelines. The approach exploits an arbitrary existing end-to-end text recognition system to obtain text region proposals and their, possibly erroneous, transcriptions. A process that includes imprecise transcription to annotation matching and edit distance guided neighbourhood search produces nearly error-free, localised instances of scene text, which we treat as pseudo ground truth used for training. We apply the method to two weakly-annotated datasets and show that the process consistently improves the accuracy of a state of the art recognition model across different benchmark datasets (image domains) as well as providing a significant performance boost on the same dataset.
Clinically Translatable Direct Patlak Reconstruction from Dynamic PET with Motion Correction Using Convolutional Neural Network
Sep 13, 2020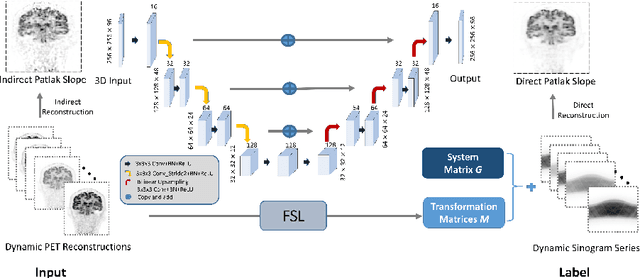

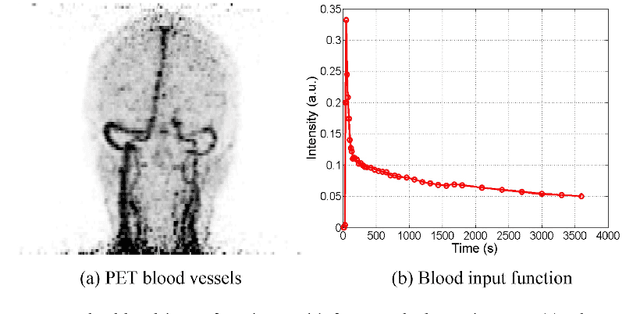
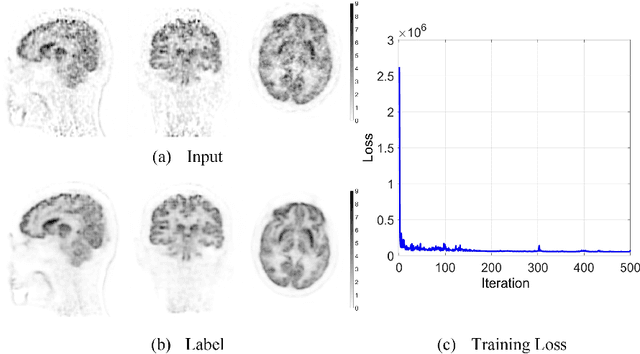
Patlak model is widely used in 18F-FDG dynamic positron emission tomography (PET) imaging, where the estimated parametric images reveal important biochemical and physiology information. Because of better noise modeling and more information extracted from raw sinogram, direct Patlak reconstruction gains its popularity over the indirect approach which utilizes reconstructed dynamic PET images alone. As the prerequisite of direct Patlak methods, raw data from dynamic PET are rarely stored in clinics and difficult to obtain. In addition, the direct reconstruction is time-consuming due to the bottleneck of multiple-frame reconstruction. All of these impede the clinical adoption of direct Patlak reconstruction.In this work, we proposed a data-driven framework which maps the dynamic PET images to the high-quality motion-corrected direct Patlak images through a convolutional neural network. For the patient motion during the long period of dynamic PET scan, we combined the correction with the backward/forward projection in direct reconstruction to better fit the statistical model. Results based on fifteen clinical 18F-FDG dynamic brain PET datasets demonstrates the superiority of the proposed framework over Gaussian, nonlocal mean and BM4D denoising, regarding the image bias and contrast-to-noise ratio.
Category-Level 3D Non-Rigid Registration from Single-View RGB Images
Aug 17, 2020


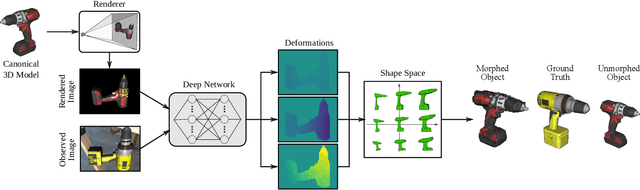
In this paper, we propose a novel approach to solve the 3D non-rigid registration problem from RGB images using Convolutional Neural Networks (CNNs). Our objective is to find a deformation field (typically used for transferring knowledge between instances, e.g., grasping skills) that warps a given 3D canonical model into a novel instance observed by a single-view RGB image. This is done by training a CNN that infers a deformation field for the visible parts of the canonical model and by employing a learned shape (latent) space for inferring the deformations of the occluded parts. As result of the registration, the observed model is reconstructed. Because our method does not need depth information, it can register objects that are typically hard to perceive with RGB-D sensors, e.g. with transparent or shiny surfaces. Even without depth data, our approach outperforms the Coherent Point Drift (CPD) registration method for the evaluated object categories.
Improving Relational Regularized Autoencoders with Spherical Sliced Fused Gromov Wasserstein
Oct 05, 2020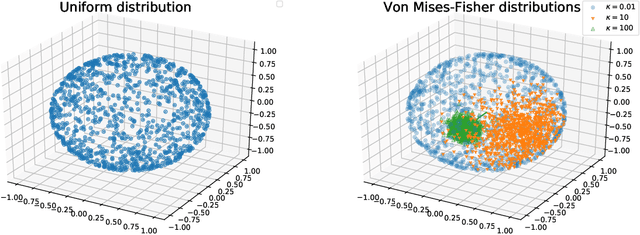
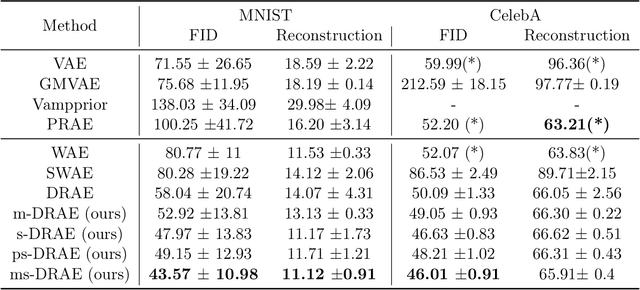
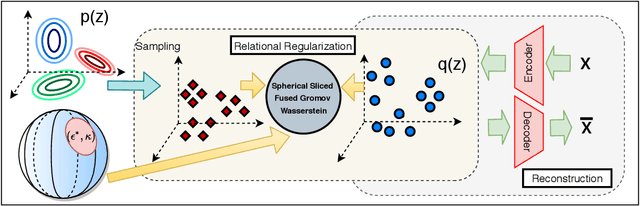
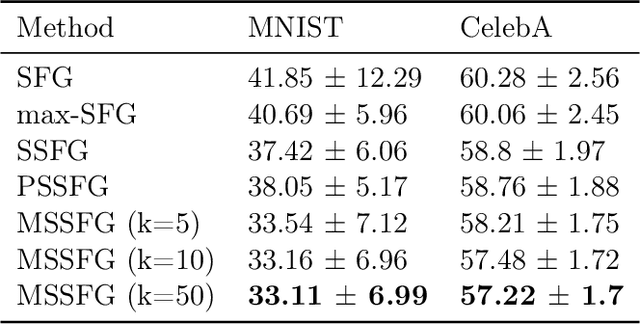
Relational regularized autoencoder (RAE) is a framework to learn the distribution of data by minimizing a reconstruction loss together with a relational regularization on the latent space. A recent attempt to reduce the inner discrepancy between the prior and aggregated posterior distributions is to incorporate sliced fused Gromov-Wasserstein (SFG) between these distributions. That approach has a weakness since it treats every slicing direction similarly, meanwhile several directions are not useful for the discriminative task. To improve the discrepancy and consequently the relational regularization, we propose a new relational discrepancy, named spherical sliced fused Gromov Wasserstein (SSFG), that can find an important area of projections characterized by a von Mises-Fisher distribution. Then, we introduce two variants of SSFG to improve its performance. The first variant, named mixture spherical sliced fused Gromov Wasserstein (MSSFG), replaces the vMF distribution by a mixture of von Mises-Fisher distributions to capture multiple important areas of directions that are far from each other. The second variant, named power spherical sliced fused Gromov Wasserstein (PSSFG), replaces the vMF distribution by a power spherical distribution to improve the sampling time in high dimension settings. We then apply the new discrepancies to the RAE framework to achieve its new variants. Finally, we conduct extensive experiments to show that the new proposed autoencoders have favorable performance in learning latent manifold structure, image generation, and reconstruction.
Understanding Anomaly Detection with Deep Invertible Networks through Hierarchies of Distributions and Features
Jun 25, 2020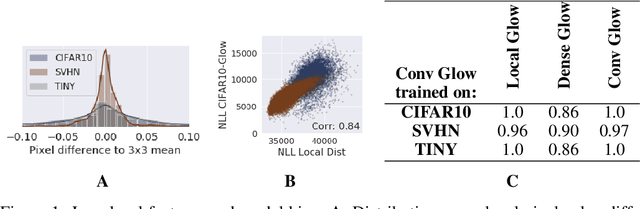
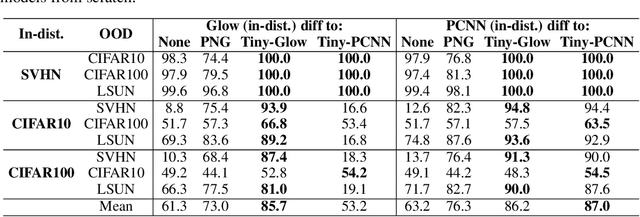
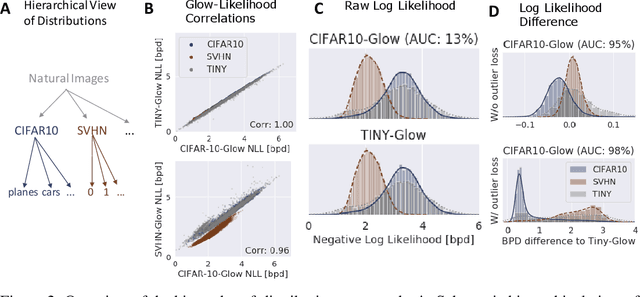
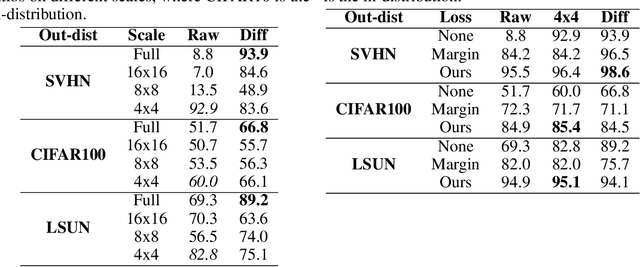
Deep generative networks trained via maximum likelihood on a natural image dataset like CIFAR10 often assign high likelihoods to images from datasets with different objects (e.g., SVHN). We refine previous investigations of this failure at anomaly detection for invertible generative networks and provide a clear explanation of it as a combination of model bias and domain prior: Convolutional networks learn similar low-level feature distributions when trained on any natural image dataset and these low-level features dominate the likelihood. Hence, when the discriminative features between inliers and outliers are on a high-level, e.g., object shapes, anomaly detection becomes particularly challenging. To remove the negative impact of model bias and domain prior on detecting high-level differences, we propose two methods, first, using the log likelihood ratios of two identical models, one trained on the in-distribution data (e.g., CIFAR10) and the other one on a more general distribution of images (e.g., 80 Million Tiny Images). We also derive a novel outlier loss for the in-distribution network on samples from the more general distribution to further improve the performance. Secondly, using a multi-scale model like Glow, we show that low-level features are mainly captured at early scales. Therefore, using only the likelihood contribution of the final scale performs remarkably well for detecting high-level feature differences of the out-of-distribution and the in-distribution. This method is especially useful if one does not have access to a suitable general distribution. Overall, our methods achieve strong anomaly detection performance in the unsupervised setting, reaching comparable performance as state-of-the-art classifier-based methods in the supervised setting.
Reversing the cycle: self-supervised deep stereo through enhanced monocular distillation
Aug 17, 2020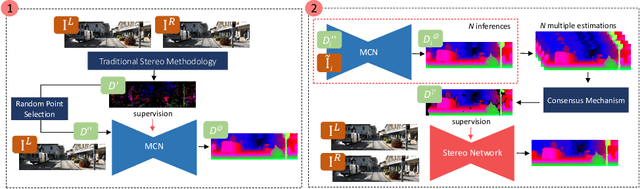
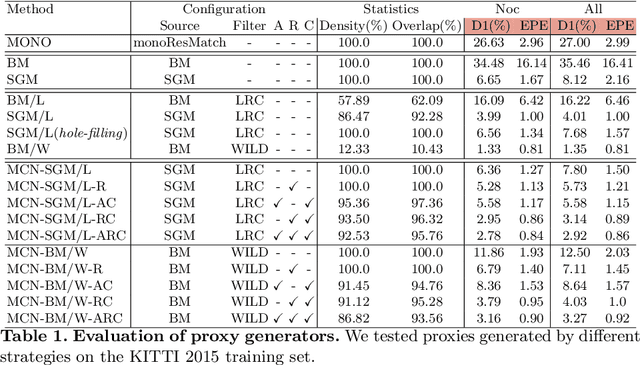

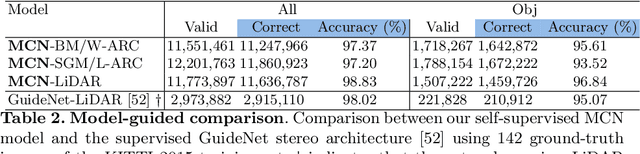
In many fields, self-supervised learning solutions are rapidly evolving and filling the gap with supervised approaches. This fact occurs for depth estimation based on either monocular or stereo, with the latter often providing a valid source of self-supervision for the former. In contrast, to soften typical stereo artefacts, we propose a novel self-supervised paradigm reversing the link between the two. Purposely, in order to train deep stereo networks, we distill knowledge through a monocular completion network. This architecture exploits single-image clues and few sparse points, sourced by traditional stereo algorithms, to estimate dense yet accurate disparity maps by means of a consensus mechanism over multiple estimations. We thoroughly evaluate with popular stereo datasets the impact of different supervisory signals showing how stereo networks trained with our paradigm outperform existing self-supervised frameworks. Finally, our proposal achieves notable generalization capabilities dealing with domain shift issues. Code available at https://github.com/FilippoAleotti/Reversing