 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Privacy-Preserving Object Detection & Localization Using Distributed Machine Learning: A Case Study of Infant Eyeblink Conditioning
Oct 14, 2020
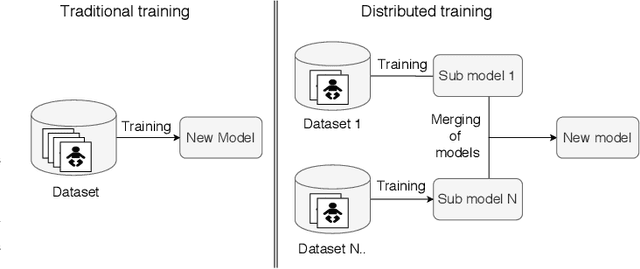
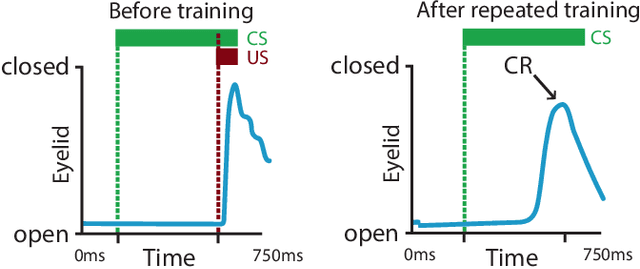
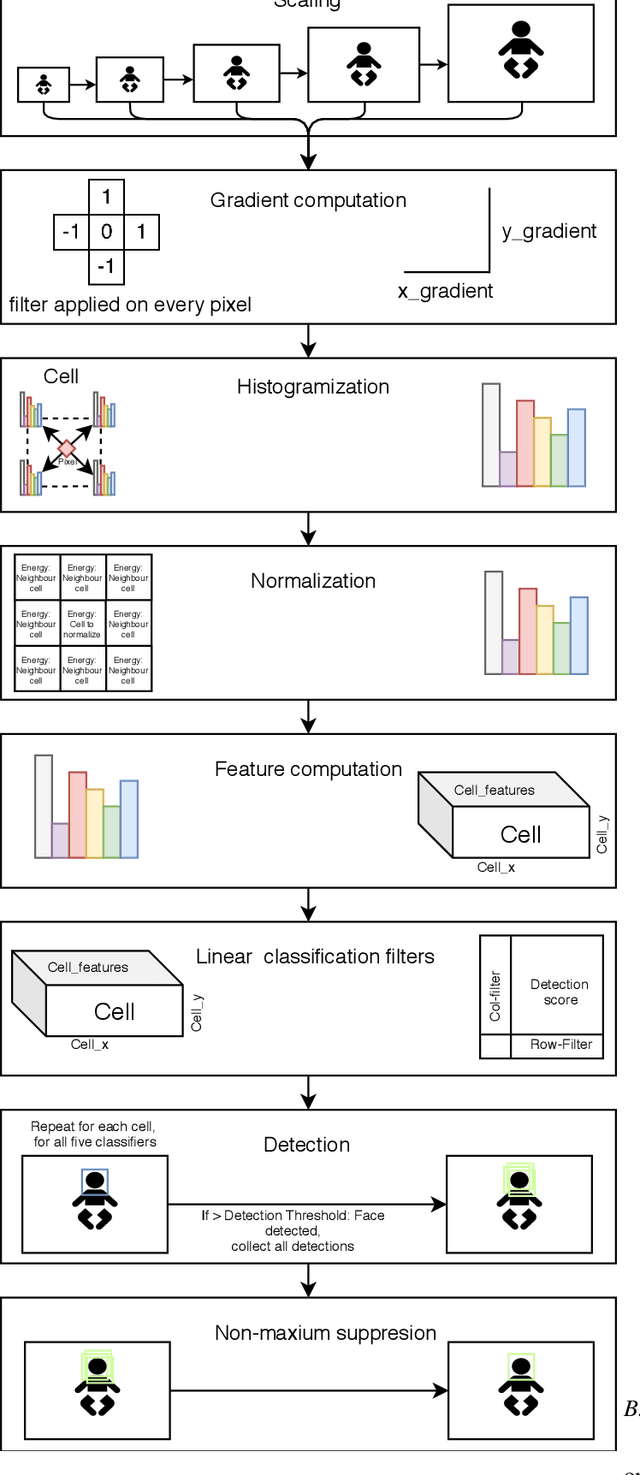
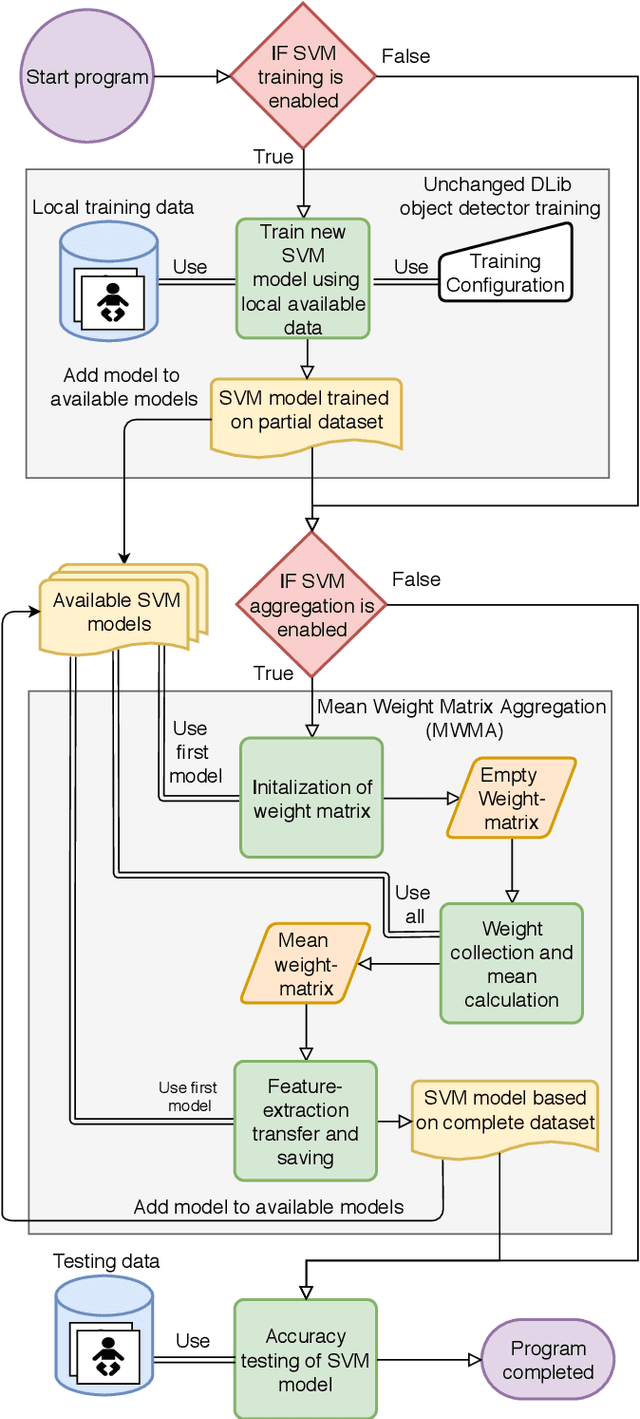
Distributed machine learning is becoming a popular model-training method due to privacy, computational scalability, and bandwidth capacities. In this work, we explore scalable distributed-training versions of two algorithms commonly used in object detection. A novel distributed training algorithm using Mean Weight Matrix Aggregation (MWMA) is proposed for Linear Support Vector Machine (L-SVM) object detection based in Histogram of Orientated Gradients (HOG). In addition, a novel Weighted Bin Aggregation (WBA) algorithm is proposed for distributed training of Ensemble of Regression Trees (ERT) landmark localization. Both algorithms do not restrict the location of model aggregation and allow custom architectures for model distribution. For this work, a Pool-Based Local Training and Aggregation (PBLTA) architecture for both algorithms is explored. The application of both algorithms in the medical field is examined using a paradigm from the fields of psychology and neuroscience - eyeblink conditioning with infants - where models need to be trained on facial images while protecting participant privacy. Using distributed learning, models can be trained without sending image data to other nodes. The custom software has been made available for public use on GitHub: https://github.com/SLWZwaard/DMT. Results show that the aggregation of models for the HOG algorithm using MWMA not only preserves the accuracy of the model but also allows for distributed learning with an accuracy increase of 0.9% compared with traditional learning. Furthermore, WBA allows for ERT model aggregation with an accuracy increase of 8% when compared to single-node models.
Unveiling the Dreams of Word Embeddings: Towards Language-Driven Image Generation
Nov 23, 2015


We introduce language-driven image generation, the task of generating an image visualizing the semantic contents of a word embedding, e.g., given the word embedding of grasshopper, we generate a natural image of a grasshopper. We implement a simple method based on two mapping functions. The first takes as input a word embedding (as produced, e.g., by the word2vec toolkit) and maps it onto a high-level visual space (e.g., the space defined by one of the top layers of a Convolutional Neural Network). The second function maps this abstract visual representation to pixel space, in order to generate the target image. Several user studies suggest that the current system produces images that capture general visual properties of the concepts encoded in the word embedding, such as color or typical environment, and are sufficient to discriminate between general categories of objects.
Reversing the cycle: self-supervised deep stereo through enhanced monocular distillation
Aug 17, 2020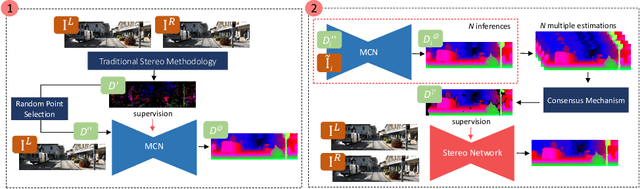
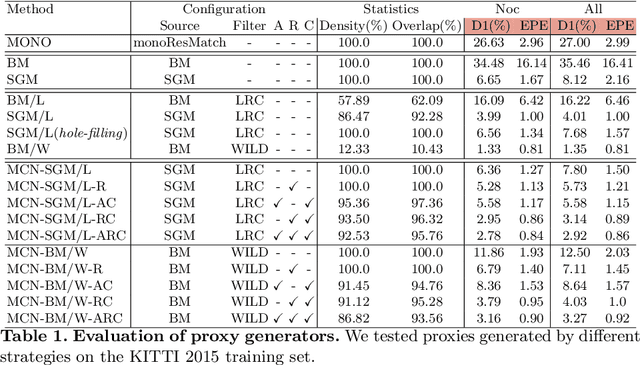

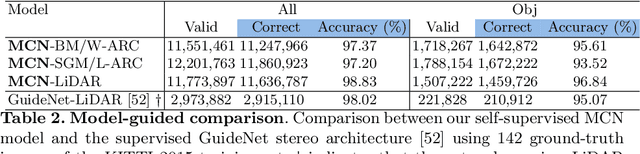
In many fields, self-supervised learning solutions are rapidly evolving and filling the gap with supervised approaches. This fact occurs for depth estimation based on either monocular or stereo, with the latter often providing a valid source of self-supervision for the former. In contrast, to soften typical stereo artefacts, we propose a novel self-supervised paradigm reversing the link between the two. Purposely, in order to train deep stereo networks, we distill knowledge through a monocular completion network. This architecture exploits single-image clues and few sparse points, sourced by traditional stereo algorithms, to estimate dense yet accurate disparity maps by means of a consensus mechanism over multiple estimations. We thoroughly evaluate with popular stereo datasets the impact of different supervisory signals showing how stereo networks trained with our paradigm outperform existing self-supervised frameworks. Finally, our proposal achieves notable generalization capabilities dealing with domain shift issues. Code available at https://github.com/FilippoAleotti/Reversing
Superpixel Segmentation with Fully Convolutional Networks
Mar 29, 2020
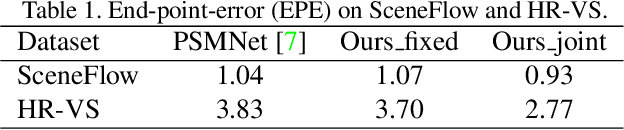

In computer vision, superpixels have been widely used as an effective way to reduce the number of image primitives for subsequent processing. But only a few attempts have been made to incorporate them into deep neural networks. One main reason is that the standard convolution operation is defined on regular grids and becomes inefficient when applied to superpixels. Inspired by an initialization strategy commonly adopted by traditional superpixel algorithms, we present a novel method that employs a simple fully convolutional network to predict superpixels on a regular image grid. Experimental results on benchmark datasets show that our method achieves state-of-the-art superpixel segmentation performance while running at about 50fps. Based on the predicted superpixels, we further develop a downsampling/upsampling scheme for deep networks with the goal of generating high-resolution outputs for dense prediction tasks. Specifically, we modify a popular network architecture for stereo matching to simultaneously predict superpixels and disparities. We show that improved disparity estimation accuracy can be obtained on public datasets.
Understanding Anomaly Detection with Deep Invertible Networks through Hierarchies of Distributions and Features
Jun 25, 2020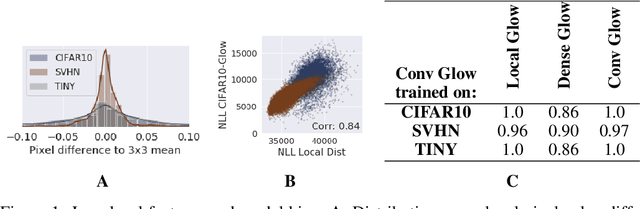
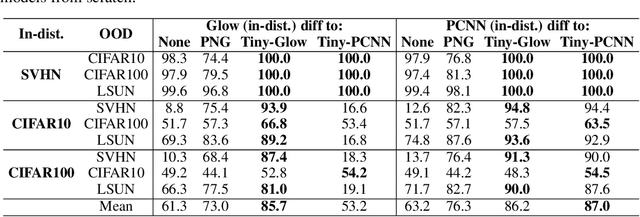
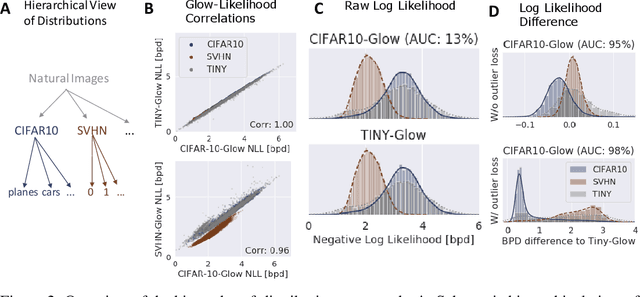
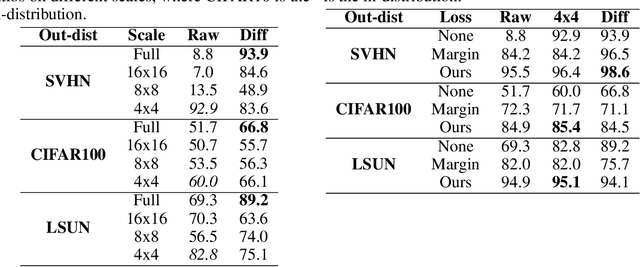
Deep generative networks trained via maximum likelihood on a natural image dataset like CIFAR10 often assign high likelihoods to images from datasets with different objects (e.g., SVHN). We refine previous investigations of this failure at anomaly detection for invertible generative networks and provide a clear explanation of it as a combination of model bias and domain prior: Convolutional networks learn similar low-level feature distributions when trained on any natural image dataset and these low-level features dominate the likelihood. Hence, when the discriminative features between inliers and outliers are on a high-level, e.g., object shapes, anomaly detection becomes particularly challenging. To remove the negative impact of model bias and domain prior on detecting high-level differences, we propose two methods, first, using the log likelihood ratios of two identical models, one trained on the in-distribution data (e.g., CIFAR10) and the other one on a more general distribution of images (e.g., 80 Million Tiny Images). We also derive a novel outlier loss for the in-distribution network on samples from the more general distribution to further improve the performance. Secondly, using a multi-scale model like Glow, we show that low-level features are mainly captured at early scales. Therefore, using only the likelihood contribution of the final scale performs remarkably well for detecting high-level feature differences of the out-of-distribution and the in-distribution. This method is especially useful if one does not have access to a suitable general distribution. Overall, our methods achieve strong anomaly detection performance in the unsupervised setting, reaching comparable performance as state-of-the-art classifier-based methods in the supervised setting.
Progressively Guided Alternate Refinement Network for RGB-D Salient Object Detection
Aug 17, 2020
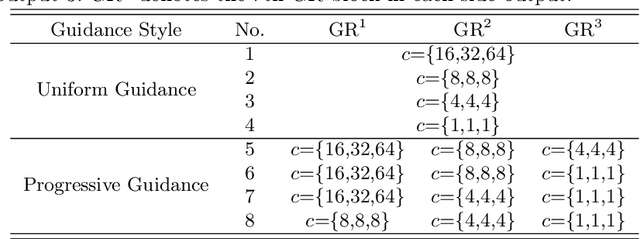
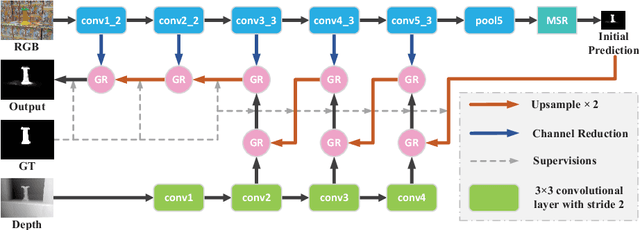
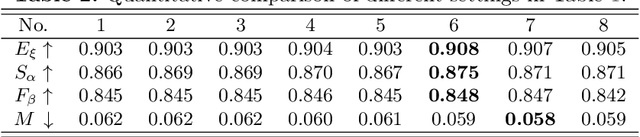
In this paper, we aim to develop an efficient and compact deep network for RGB-D salient object detection, where the depth image provides complementary information to boost performance in complex scenarios. Starting from a coarse initial prediction by a multi-scale residual block, we propose a progressively guided alternate refinement network to refine it. Instead of using ImageNet pre-trained backbone network, we first construct a lightweight depth stream by learning from scratch, which can extract complementary features more efficiently with less redundancy. Then, different from the existing fusion based methods, RGB and depth features are fed into proposed guided residual (GR) blocks alternately to reduce their mutual degradation. By assigning progressive guidance in the stacked GR blocks within each side-output, the false detection and missing parts can be well remedied. Extensive experiments on seven benchmark datasets demonstrate that our model outperforms existing state-of-the-art approaches by a large margin, and also shows superiority in efficiency (71 FPS) and model size (64.9 MB).
Sketch-to-Art: Synthesizing Stylized Art Images From Sketches
Mar 03, 2020



We propose a new approach for synthesizing fully detailed art-stylized images from sketches. Given a sketch, with no semantic tagging, and a reference image of a specific style, the model can synthesize meaningful details with colors and textures. The model consists of three modules designed explicitly for better artistic style capturing and generation. Based on a GAN framework, a dual-masked mechanism is introduced to enforce the content constraints (from the sketch), and a feature-map transformation technique is developed to strengthen the style consistency (to the reference image). Finally, an inverse procedure of instance-normalization is proposed to disentangle the style and content information, therefore yields better synthesis performance. Experiments demonstrate a significant qualitative and quantitative boost over baselines based on previous state-of-the-art techniques, adopted for the proposed process.
Weakly Supervised Domain Adaptation for Built-up Region Segmentation in Aerial and Satellite Imagery
Jul 05, 2020
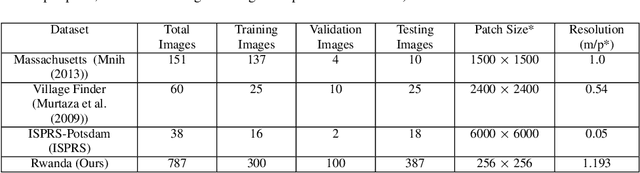


This paper proposes a novel domain adaptation algorithm to handle the challenges posed by the satellite and aerial imagery, and demonstrates its effectiveness on the built-up region segmentation problem. Built-up area estimation is an important component in understanding the human impact on the environment, the effect of public policy, and general urban population analysis. The diverse nature of aerial and satellite imagery and lack of labeled data covering this diversity makes machine learning algorithms difficult to generalize for such tasks, especially across multiple domains. On the other hand, due to the lack of strong spatial context and structure, in comparison to the ground imagery, the application of existing unsupervised domain adaptation methods results in the sub-optimal adaptation. We thoroughly study the limitations of existing domain adaptation methods and propose a weakly-supervised adaptation strategy where we assume image-level labels are available for the target domain. More specifically, we design a built-up area segmentation network (as encoder-decoder), with an image classification head added to guide the adaptation. The devised system is able to address the problem of visual differences in multiple satellite and aerial imagery datasets, ranging from high resolution (HR) to very high resolution (VHR). A realistic and challenging HR dataset is created by hand-tagging the 73.4 sq-km of Rwanda, capturing a variety of build-up structures over different terrain. The developed dataset is spatially rich compared to existing datasets and covers diverse built-up scenarios including built-up areas in forests and deserts, mud houses, tin, and colored rooftops. Extensive experiments are performed by adapting from the single-source domain, to segment out the target domain. We achieve high gains ranging 11.6%-52% in IoU over the existing state-of-the-art methods.
Semantic Bottleneck Scene Generation
Nov 26, 2019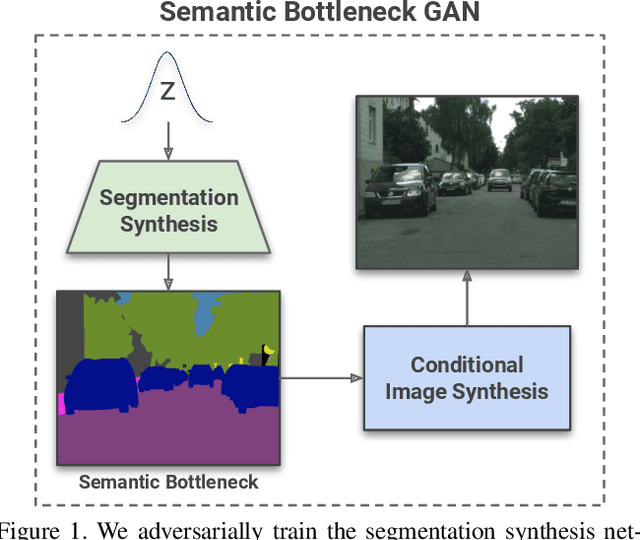
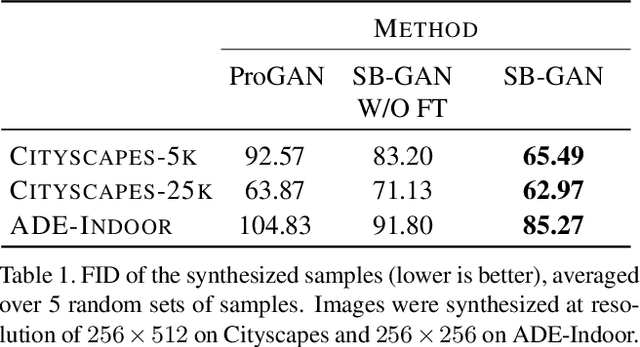
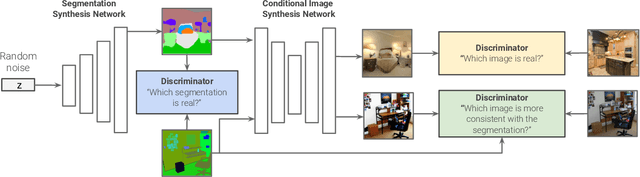
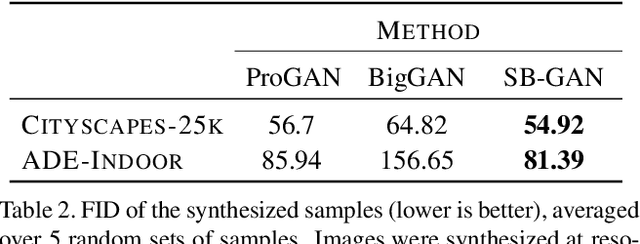
Coupling the high-fidelity generation capabilities of label-conditional image synthesis methods with the flexibility of unconditional generative models, we propose a semantic bottleneck GAN model for unconditional synthesis of complex scenes. We assume pixel-wise segmentation labels are available during training and use them to learn the scene structure. During inference, our model first synthesizes a realistic segmentation layout from scratch, then synthesizes a realistic scene conditioned on that layout. For the former, we use an unconditional progressive segmentation generation network that captures the distribution of realistic semantic scene layouts. For the latter, we use a conditional segmentation-to-image synthesis network that captures the distribution of photo-realistic images conditioned on the semantic layout. When trained end-to-end, the resulting model outperforms state-of-the-art generative models in unsupervised image synthesis on two challenging domains in terms of the Frechet Inception Distance and user-study evaluations. Moreover, we demonstrate the generated segmentation maps can be used as additional training data to strongly improve recent segmentation-to-image synthesis networks.
Natural Scene Image Segmentation Based on Multi-Layer Feature Extraction
Oct 11, 2016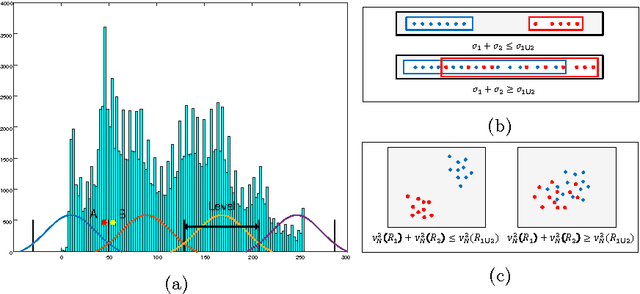
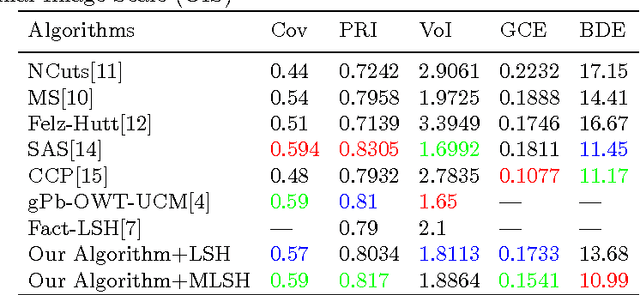


This paper addresses the problem of natural image segmentation by extracting information from a multi-layer array which is constructed based on color, gradient, and statistical properties of the local neighborhoods in an image. A Gaussian Mixture Model (GMM) is used to improve the effectiveness of local spectral histogram features. Grouping these features leads to forming a rough initial over-segmented layer which contains coherent regions of pixels. The regions are merged by using two proposed functions for calculating the distance between two neighboring regions and making decisions about their merging. Extensive experiments are performed on the Berkeley Segmentation Dataset to evaluate the performance of our proposed method and compare the results with the recent state-of-the-art methods. The experimental results indicate that our method achieves higher level of accuracy for natural images compared to recent methods.