 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Learning for Object Saliency Detection and Image Segmentation
May 05, 2015
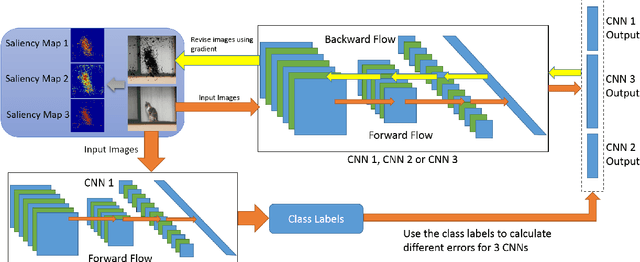
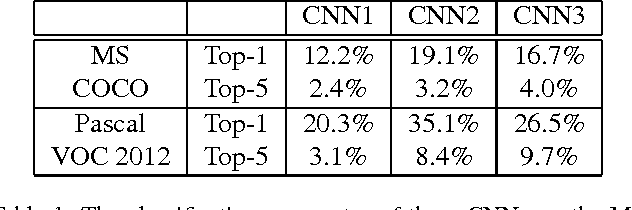
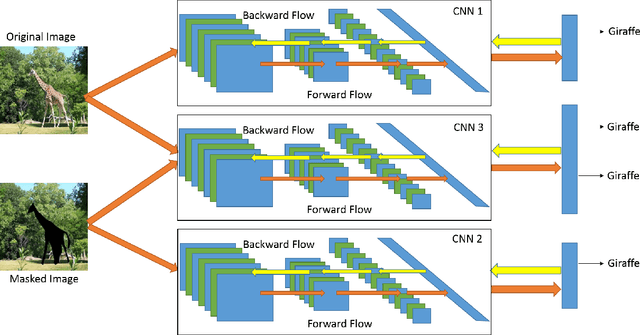
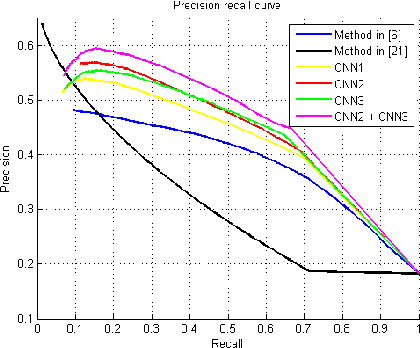
In this paper, we propose several novel deep learning methods for object saliency detection based on the powerful convolutional neural networks. In our approach, we use a gradient descent method to iteratively modify an input image based on the pixel-wise gradients to reduce a cost function measuring the class-specific objectness of the image. The pixel-wise gradients can be efficiently computed using the back-propagation algorithm. The discrepancy between the modified image and the original one may be used as a saliency map for the image. Moreover, we have further proposed several new training methods to learn saliency-specific convolutional nets for object saliency detection, in order to leverage the available pixel-wise segmentation information. Our methods are extremely computationally efficient (processing 20-40 images per second in one GPU). In this work, we use the computed saliency maps for image segmentation. Experimental results on two benchmark tasks, namely Microsoft COCO and Pascal VOC 2012, have shown that our proposed methods can generate high-quality salience maps, clearly outperforming many existing methods. In particular, our approaches excel in handling many difficult images, which contain complex background, highly-variable salient objects, multiple objects, and/or very small salient objects.
A fast patch-dictionary method for whole image recovery
Aug 16, 2014
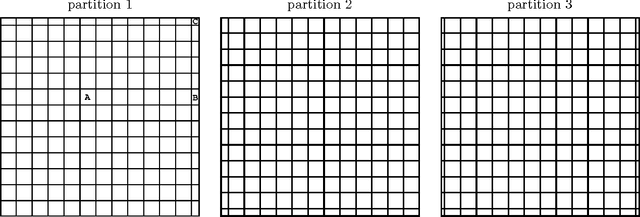
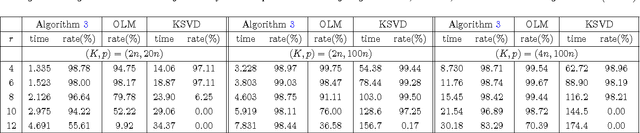

Various algorithms have been proposed for dictionary learning. Among those for image processing, many use image patches to form dictionaries. This paper focuses on whole-image recovery from corrupted linear measurements. We address the open issue of representing an image by overlapping patches: the overlapping leads to an excessive number of dictionary coefficients to determine. With very few exceptions, this issue has limited the applications of image-patch methods to the local kind of tasks such as denoising, inpainting, cartoon-texture decomposition, super-resolution, and image deblurring, for which one can process a few patches at a time. Our focus is global imaging tasks such as compressive sensing and medical image recovery, where the whole image is encoded together, making it either impossible or very ineffective to update a few patches at a time. Our strategy is to divide the sparse recovery into multiple subproblems, each of which handles a subset of non-overlapping patches, and then the results of the subproblems are averaged to yield the final recovery. This simple strategy is surprisingly effective in terms of both quality and speed. In addition, we accelerate computation of the learned dictionary by applying a recent block proximal-gradient method, which not only has a lower per-iteration complexity but also takes fewer iterations to converge, compared to the current state-of-the-art. We also establish that our algorithm globally converges to a stationary point. Numerical results on synthetic data demonstrate that our algorithm can recover a more faithful dictionary than two state-of-the-art methods. Combining our whole-image recovery and dictionary-learning methods, we numerically simulate image inpainting, compressive sensing recovery, and deblurring. Our recovery is more faithful than those of a total variation method and a method based on overlapping patches.
Visually Grounded Compound PCFGs
Sep 25, 2020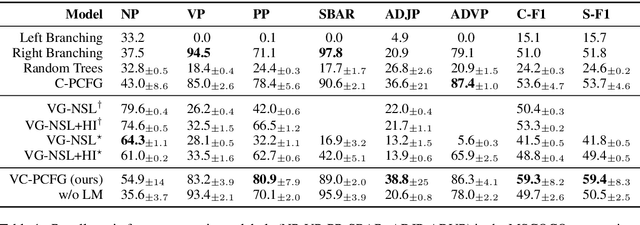
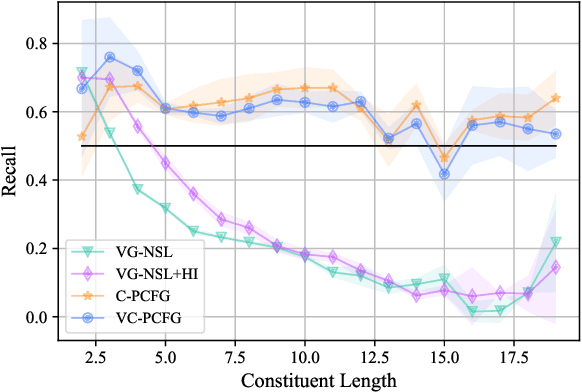
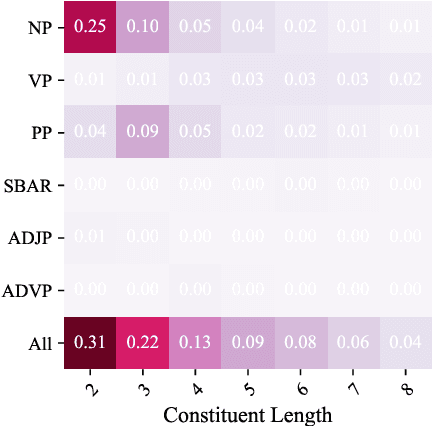
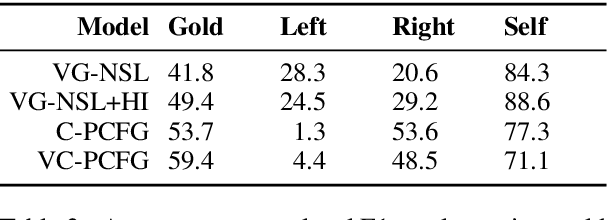
Exploiting visual groundings for language understanding has recently been drawing much attention. In this work, we study visually grounded grammar induction and learn a constituency parser from both unlabeled text and its visual groundings. Existing work on this task (Shi et al., 2019) optimizes a parser via Reinforce and derives the learning signal only from the alignment of images and sentences. While their model is relatively accurate overall, its error distribution is very uneven, with low performance on certain constituents types (e.g., 26.2% recall on verb phrases, VPs) and high on others (e.g., 79.6% recall on noun phrases, NPs). This is not surprising as the learning signal is likely insufficient for deriving all aspects of phrase-structure syntax and gradient estimates are noisy. We show that using an extension of probabilistic context-free grammar model we can do fully-differentiable end-to-end visually grounded learning. Additionally, this enables us to complement the image-text alignment loss with a language modeling objective. On the MSCOCO test captions, our model establishes a new state of the art, outperforming its non-grounded version and, thus, confirming the effectiveness of visual groundings in constituency grammar induction. It also substantially outperforms the previous grounded model, with largest improvements on more `abstract' categories (e.g., +55.1% recall on VPs).
RL-CycleGAN: Reinforcement Learning Aware Simulation-To-Real
Jun 16, 2020
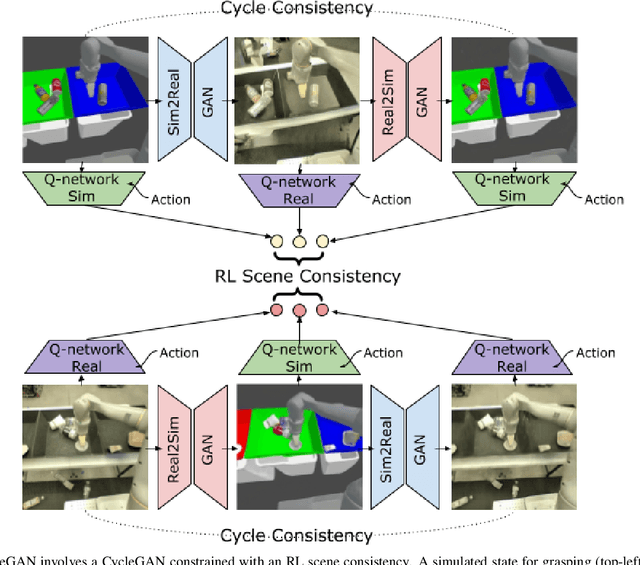


Deep neural network based reinforcement learning (RL) can learn appropriate visual representations for complex tasks like vision-based robotic grasping without the need for manually engineering or prior learning a perception system. However, data for RL is collected via running an agent in the desired environment, and for applications like robotics, running a robot in the real world may be extremely costly and time consuming. Simulated training offers an appealing alternative, but ensuring that policies trained in simulation can transfer effectively into the real world requires additional machinery. Simulations may not match reality, and typically bridging the simulation-to-reality gap requires domain knowledge and task-specific engineering. We can automate this process by employing generative models to translate simulated images into realistic ones. However, this sort of translation is typically task-agnostic, in that the translated images may not preserve all features that are relevant to the task. In this paper, we introduce the RL-scene consistency loss for image translation, which ensures that the translation operation is invariant with respect to the Q-values associated with the image. This allows us to learn a task-aware translation. Incorporating this loss into unsupervised domain translation, we obtain RL-CycleGAN, a new approach for simulation-to-real-world transfer for reinforcement learning. In evaluations of RL-CycleGAN on two vision-based robotics grasping tasks, we show that RL-CycleGAN offers a substantial improvement over a number of prior methods for sim-to-real transfer, attaining excellent real-world performance with only a modest number of real-world observations.
Loss Max-Pooling for Semantic Image Segmentation
Apr 10, 2017
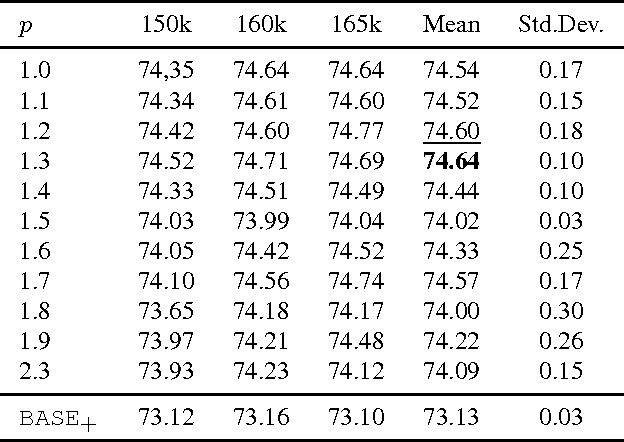
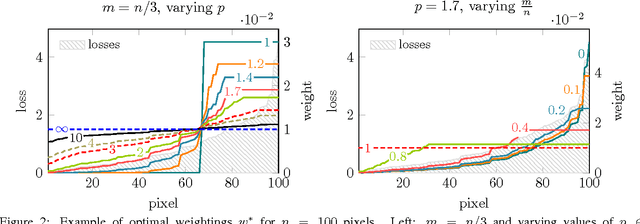

We introduce a novel loss max-pooling concept for handling imbalanced training data distributions, applicable as alternative loss layer in the context of deep neural networks for semantic image segmentation. Most real-world semantic segmentation datasets exhibit long tail distributions with few object categories comprising the majority of data and consequently biasing the classifiers towards them. Our method adaptively re-weights the contributions of each pixel based on their observed losses, targeting under-performing classification results as often encountered for under-represented object classes. Our approach goes beyond conventional cost-sensitive learning attempts through adaptive considerations that allow us to indirectly address both, inter- and intra-class imbalances. We provide a theoretical justification of our approach, complementary to experimental analyses on benchmark datasets. In our experiments on the Cityscapes and Pascal VOC 2012 segmentation datasets we find consistently improved results, demonstrating the efficacy of our approach.
Sparse Representation-based Image Quality Assessment
Jun 12, 2013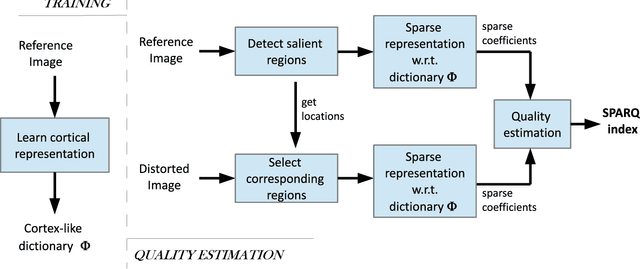

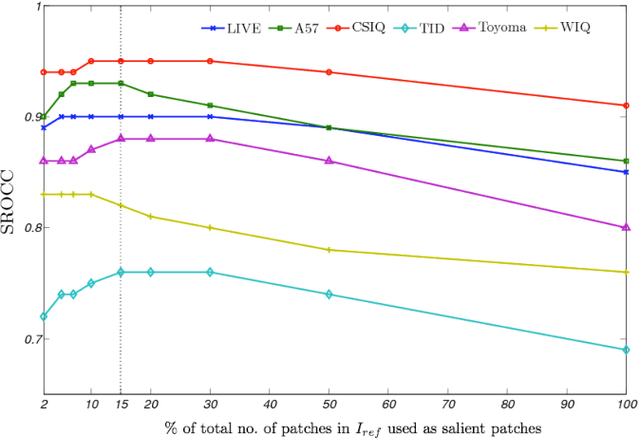
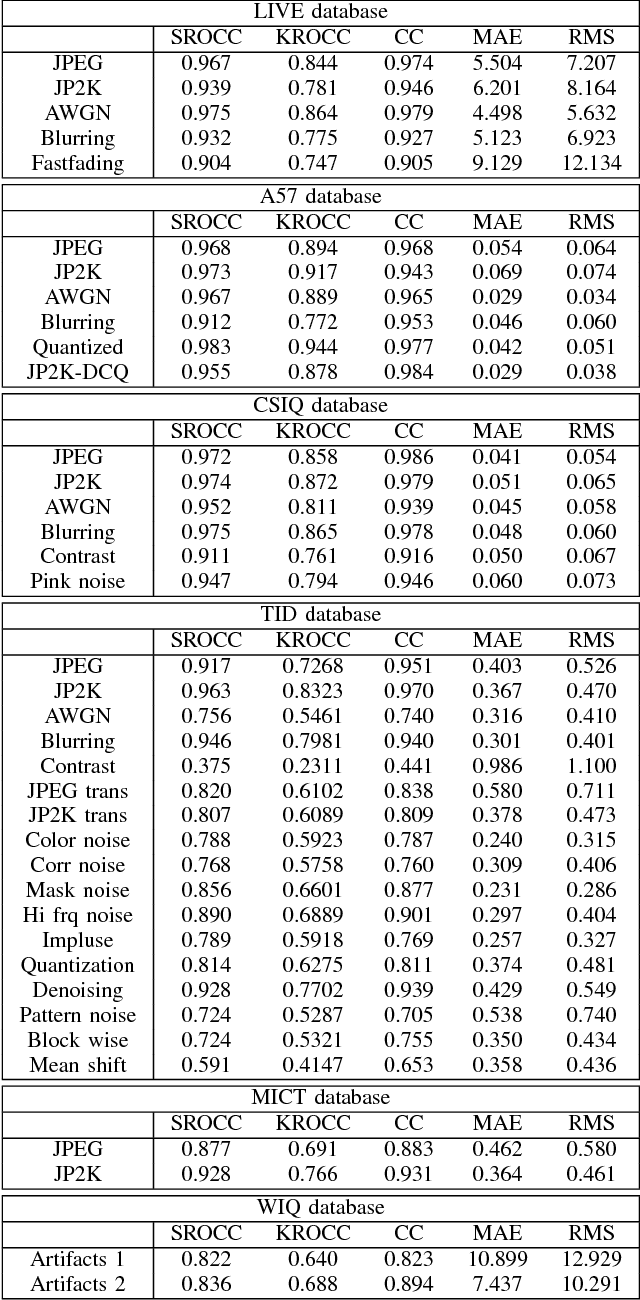
A successful approach to image quality assessment involves comparing the structural information between a distorted and its reference image. However, extracting structural information that is perceptually important to our visual system is a challenging task. This paper addresses this issue by employing a sparse representation-based approach and proposes a new metric called the \emph{sparse representation-based quality} (SPARQ) \emph{index}. The proposed method learns the inherent structures of the reference image as a set of basis vectors, such that any structure in the image can be represented by a linear combination of only a few of those basis vectors. This sparse strategy is employed because it is known to generate basis vectors that are qualitatively similar to the receptive field of the simple cells present in the mammalian primary visual cortex. The visual quality of the distorted image is estimated by comparing the structures of the reference and the distorted images in terms of the learnt basis vectors resembling cortical cells. Our approach is evaluated on six publicly available subject-rated image quality assessment datasets. The proposed SPARQ index consistently exhibits high correlation with the subjective ratings on all datasets and performs better or at par with the state-of-the-art.
Fusion of Camera Model and Source Device Specific Forensic Methods for Improved Tamper Detection
Feb 24, 2020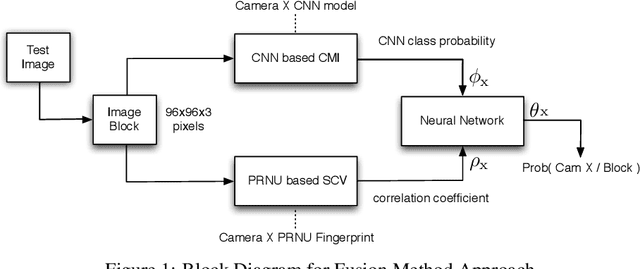


PRNU based camera recognition method is widely studied in the image forensic literature. In recent years, CNN based camera model recognition methods have been developed. These two methods also provide solutions to tamper localization problem. In this paper, we propose their combination via a Neural Network to achieve better small-scale tamper detection performance. According to the results, the fusion method performs better than underlying methods even under high JPEG compression. For forgeries as small as 100$\times$100 pixel size, the proposed method outperforms the state-of-the-art, which validates the usefulness of fusion for localization of small-size image forgeries. We believe the proposed approach is feasible for any tamper-detection pipeline using the PRNU based methodology.
Ashwin: Plug-and-Play System for Machine-Human Image Annotation
Sep 09, 2016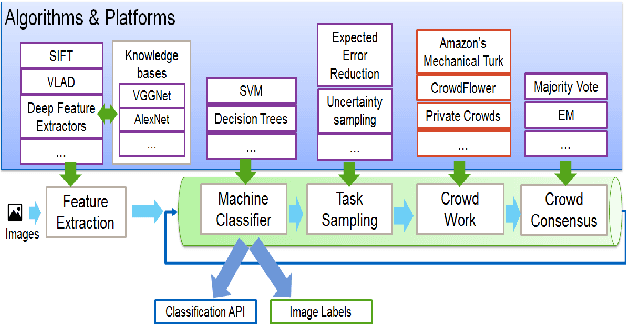
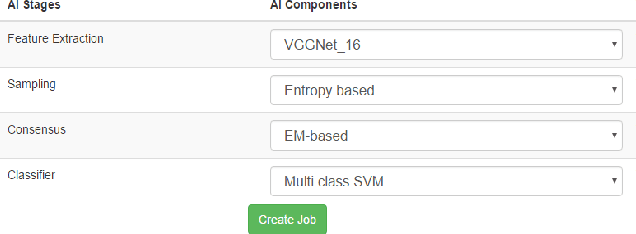
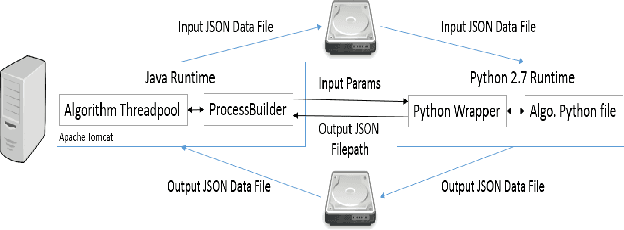
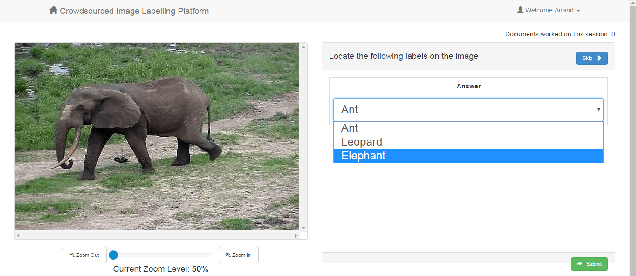
We present an end-to-end machine-human image annotation system where each component can be attached in a plug-and-play fashion. These components include Feature Extraction, Machine Classifier, Task Sampling and Crowd Consensus.
Deep Learning-based Human Detection for UAVs with Optical and Infrared Cameras: System and Experiments
Aug 10, 2020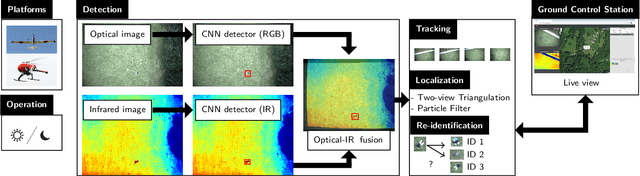

In this paper, we present our deep learning-based human detection system that uses optical (RGB) and long-wave infrared (LWIR) cameras to detect, track, localize, and re-identify humans from UAVs flying at high altitude. In each spectrum, a customized RetinaNet network with ResNet backbone provides human detections which are subsequently fused to minimize the overall false detection rate. We show that by optimizing the bounding box anchors and augmenting the image resolution the number of missed detections from high altitudes can be decreased by over 20 percent. Our proposed network is compared to different RetinaNet and YOLO variants, and to a classical optical-infrared human detection framework that uses hand-crafted features. Furthermore, along with the publication of this paper, we release a collection of annotated optical-infrared datasets recorded with different UAVs during search-and-rescue field tests and the source code of the implemented annotation tool.
Bone marrow cells detection: A technique for the microscopic image analysis
May 05, 2018
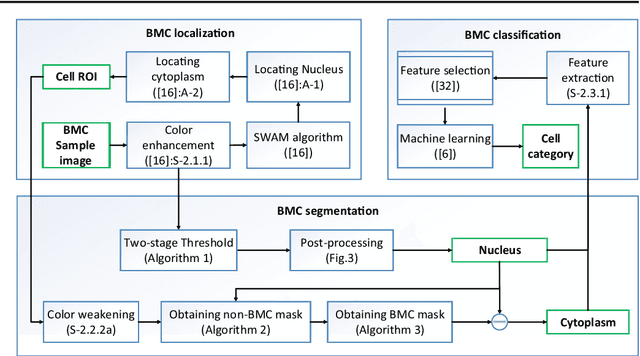

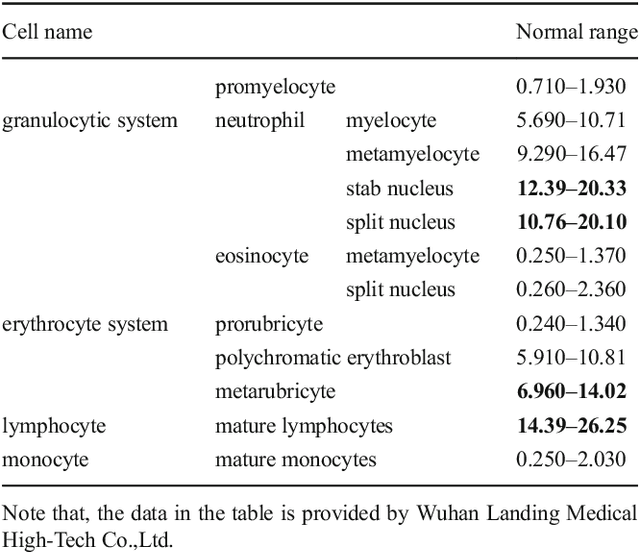
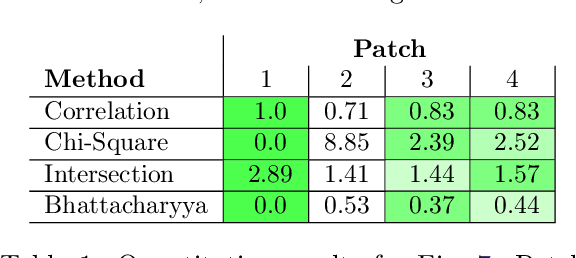
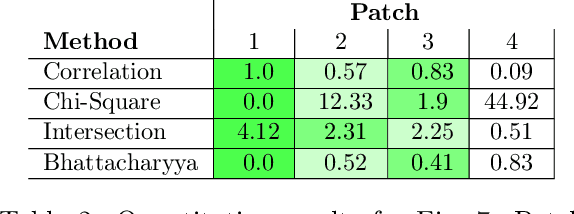
In the detection of myeloproliferative, the number of cells in each type of bone marrow cells (BMC) is an important parameter for the evaluation. In this study, we propose a new counting method, which also consists of three modules including localization, segmentation and classification. The localization of BMC is achieved from a color transformation enhanced BMC sample image and stepwise averaging method (SAM). In the nucleus segmentation, both SAM and Otsu's method will be applied to obtain a weighted threshold for segmenting the patch into nucleus and non-nucleus. In the cytoplasm segmentation, a color weakening transformation, an improved region growing method and the K-Means algorithm are used. The connected cells with BMC will be separated by the marker-controlled watershed algorithm. The features will be extracted for the classification after the segmentation. In this study, the BMC are classified using the SVM, Random Forest, Artificial Neural Networks, Adaboost and Bayesian Networks into five classes including one outlier, namely, neutrophilic split granulocyte, neutrophilic stab granulocyte, metarubricyte, mature lymphocytes and the outlier (all other cells not listed). Our experimental results show that the best average recognition rate is 87.49% for the SVM.