 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Mixup-CAM: Weakly-supervised Semantic Segmentation via Uncertainty Regularization
Aug 03, 2020
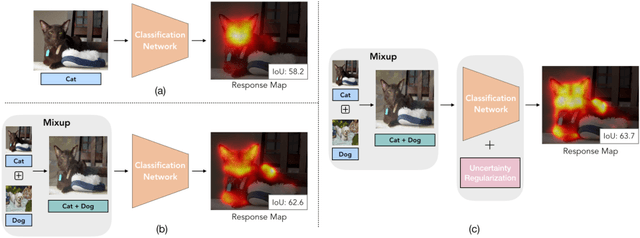
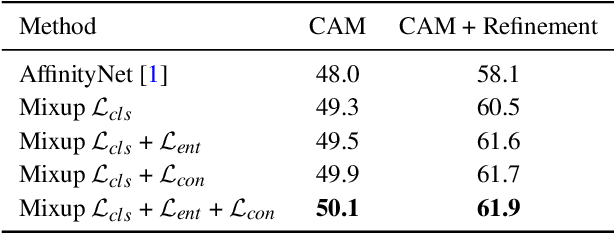
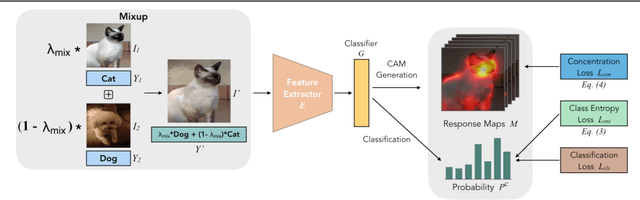
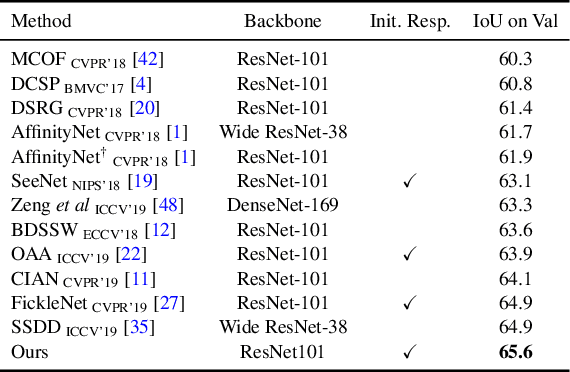
Obtaining object response maps is one important step to achieve weakly-supervised semantic segmentation using image-level labels. However, existing methods rely on the classification task, which could result in a response map only attending on discriminative object regions as the network does not need to see the entire object for optimizing the classification loss. To tackle this issue, we propose a principled and end-to-end train-able framework to allow the network to pay attention to other parts of the object, while producing a more complete and uniform response map. Specifically, we introduce the mixup data augmentation scheme into the classification network and design two uncertainty regularization terms to better interact with the mixup strategy. In experiments, we conduct extensive analysis to demonstrate the proposed method and show favorable performance against state-of-the-art approaches.
Completely Self-Supervised Crowd Counting via Distribution Matching
Sep 14, 2020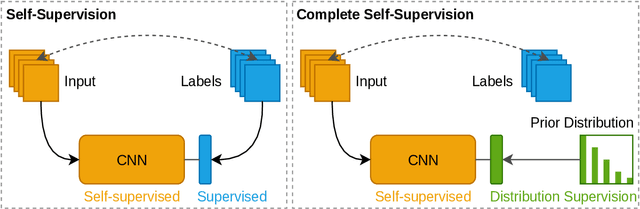
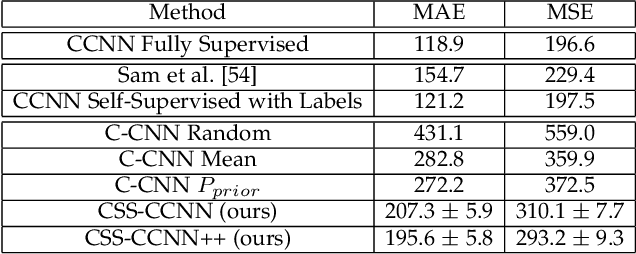
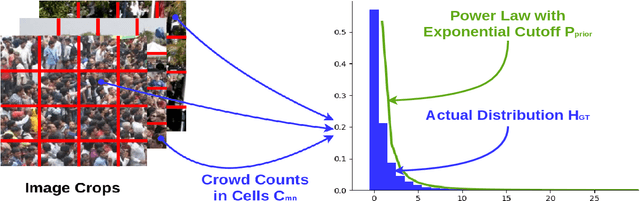
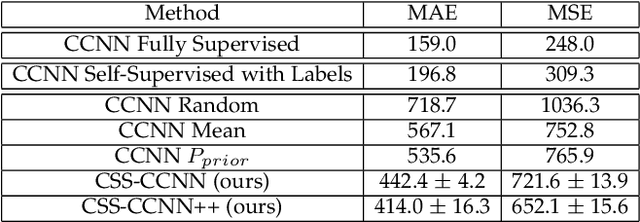
Dense crowd counting is a challenging task that demands millions of head annotations for training models. Though existing self-supervised approaches could learn good representations, they require some labeled data to map these features to the end task of density estimation. We mitigate this issue with the proposed paradigm of complete self-supervision, which does not need even a single labeled image. The only input required to train, apart from a large set of unlabeled crowd images, is the approximate upper limit of the crowd count for the given dataset. Our method dwells on the idea that natural crowds follow a power law distribution, which could be leveraged to yield error signals for backpropagation. A density regressor is first pretrained with self-supervision and then the distribution of predictions is matched to the prior by optimizing Sinkhorn distance between the two. Experiments show that this results in effective learning of crowd features and delivers significant counting performance. Furthermore, we establish the superiority of our method in less data setting as well. The code and models for our approach is available at https://github.com/val-iisc/css-ccnn.
Direct Adversarial Training for GANs
Aug 19, 2020
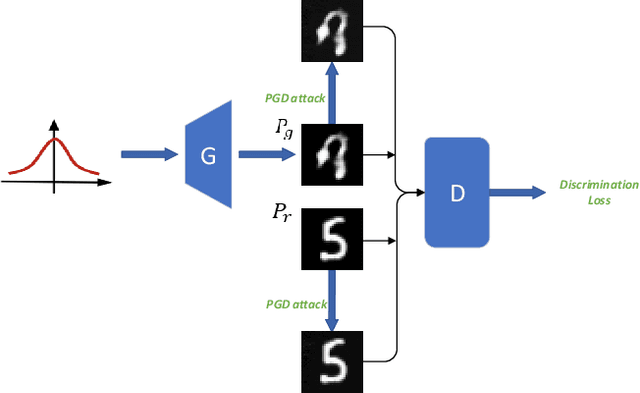
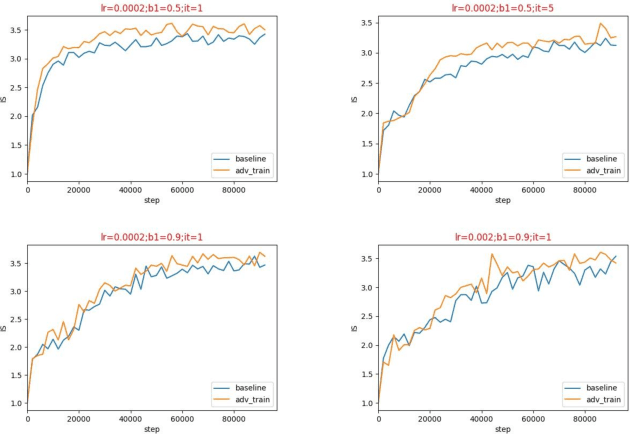
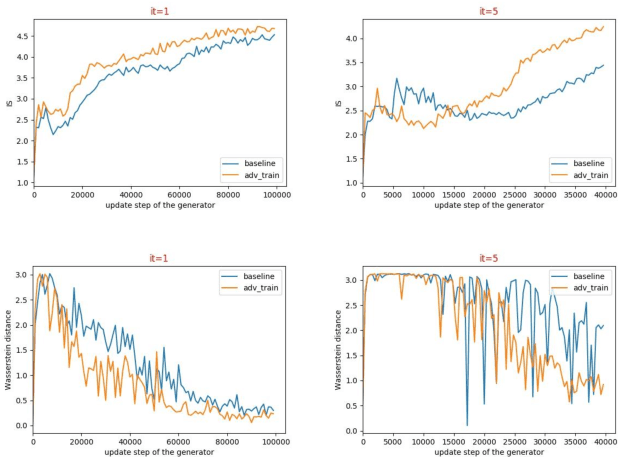
There is an interesting discovery that several neural networks are vulnerable to adversarial examples. That is, many machines learning models misclassify the samples with only a little change which will not be noticed by human eyes. Generative adversarial networks (GANs) are the most popular models for image generation by jointly optimizing discriminator and generator. With stability train, some regularization and normalization have been used to let the discriminator satisfy Lipschitz consistency. In this paper, we have analyzed that the generator may produce adversarial examples for discriminator during the training process, which may cause the unstable training of GANs. For this reason, we propose a direct adversarial training method for GANs. At the same time, we prove that this direct adversarial training can limit the lipschitz constant of the discriminator and accelerate the convergence of the generator. We have verified the advanced performs of the method on multiple baseline networks, such as DCGAN, WGAN, WGAN-GP, and WGAN-LP.
HydraMix-Net: A Deep Multi-task Semi-supervised Learning Approach for Cell Detection and Classification
Aug 11, 2020Semi-supervised techniques have removed the barriers of large scale labelled set by exploiting unlabelled data to improve the performance of a model. In this paper, we propose a semi-supervised deep multi-task classification and localization approach HydraMix-Net in the field of medical imagining where labelling is time consuming and costly. Firstly, the pseudo labels are generated using the model's prediction on the augmented set of unlabelled image with averaging. The high entropy predictions are further sharpened to reduced the entropy and are then mixed with the labelled set for training. The model is trained in multi-task learning manner with noise tolerant joint loss for classification localization and achieves better performance when given limited data in contrast to a simple deep model. On DLBCL data it achieves 80\% accuracy in contrast to simple CNN achieving 70\% accuracy when given only 100 labelled examples.
Generating Holistic 3D Scene Abstractions for Text-based Image Retrieval
Apr 11, 2017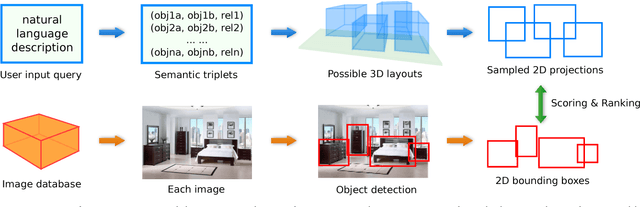

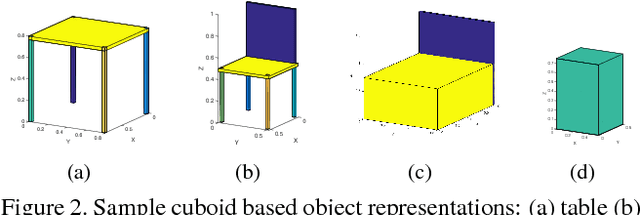
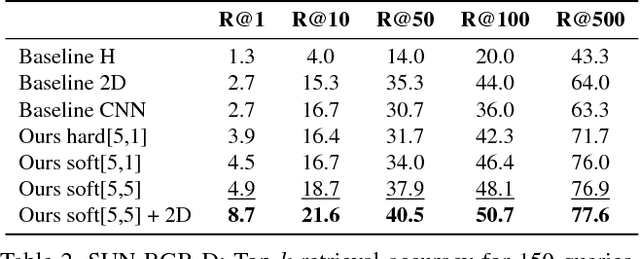
Spatial relationships between objects provide important information for text-based image retrieval. As users are more likely to describe a scene from a real world perspective, using 3D spatial relationships rather than 2D relationships that assume a particular viewing direction, one of the main challenges is to infer the 3D structure that bridges images with users' text descriptions. However, direct inference of 3D structure from images requires learning from large scale annotated data. Since interactions between objects can be reduced to a limited set of atomic spatial relations in 3D, we study the possibility of inferring 3D structure from a text description rather than an image, applying physical relation models to synthesize holistic 3D abstract object layouts satisfying the spatial constraints present in a textual description. We present a generic framework for retrieving images from a textual description of a scene by matching images with these generated abstract object layouts. Images are ranked by matching object detection outputs (bounding boxes) to 2D layout candidates (also represented by bounding boxes) which are obtained by projecting the 3D scenes with sampled camera directions. We validate our approach using public indoor scene datasets and show that our method outperforms baselines built upon object occurrence histograms and learned 2D pairwise relations.
FaceScape: a Large-scale High Quality 3D Face Dataset and Detailed Riggable 3D Face Prediction
Mar 31, 2020
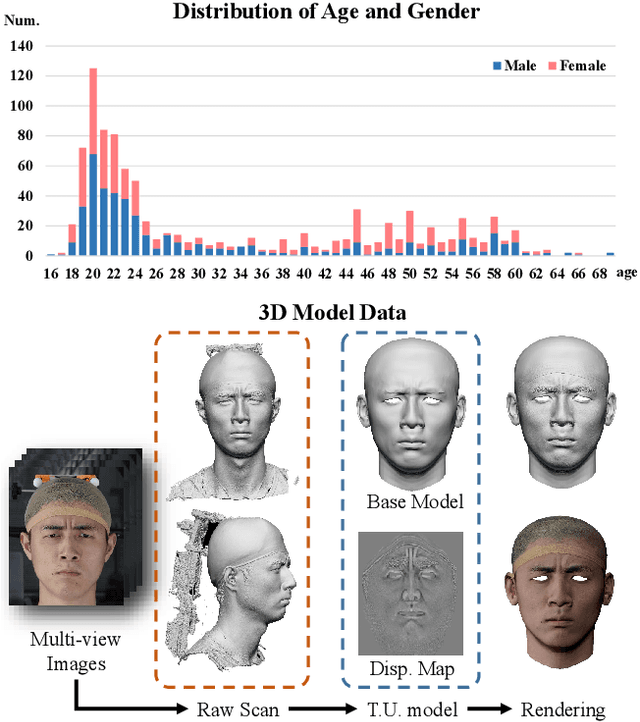
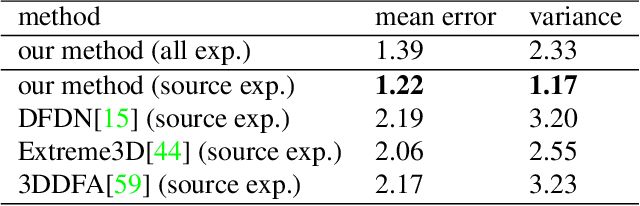
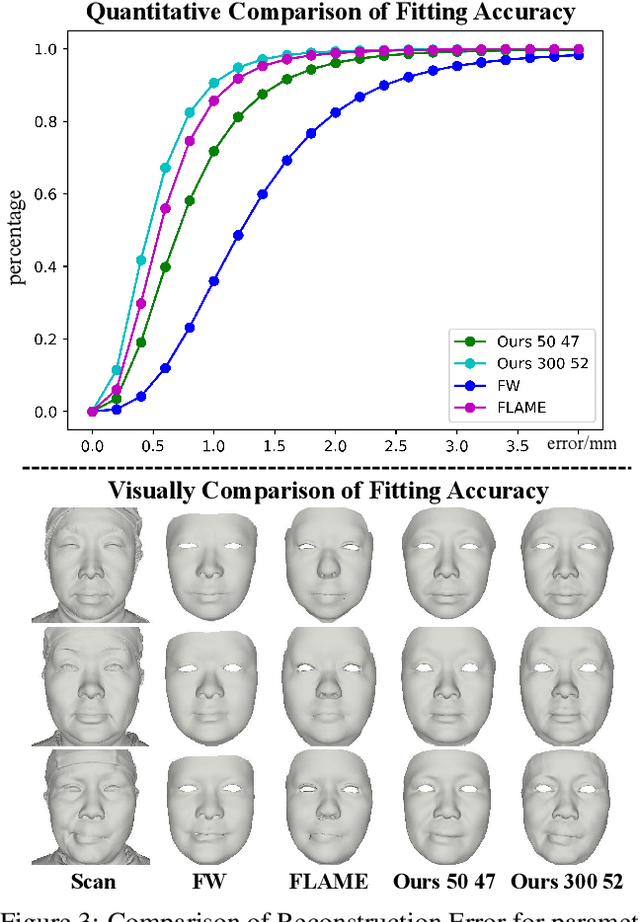
In this paper, we present a large-scale detailed 3D face dataset, FaceScape, and propose a novel algorithm that is able to predict elaborate riggable 3D face models from a single image input. FaceScape dataset provides 18,760 textured 3D faces, captured from 938 subjects and each with 20 specific expressions. The 3D models contain the pore-level facial geometry that is also processed to be topologically uniformed. These fine 3D facial models can be represented as a 3D morphable model for rough shapes and displacement maps for detailed geometry. Taking advantage of the large-scale and high-accuracy dataset, a novel algorithm is further proposed to learn the expression-specific dynamic details using a deep neural network. The learned relationship serves as the foundation of our 3D face prediction system from a single image input. Different than the previous methods, our predicted 3D models are riggable with highly detailed geometry under different expressions. The unprecedented dataset and code will be released to public for research purpose.
MS and PAN image fusion by combining Brovey and wavelet methods
Jan 08, 2017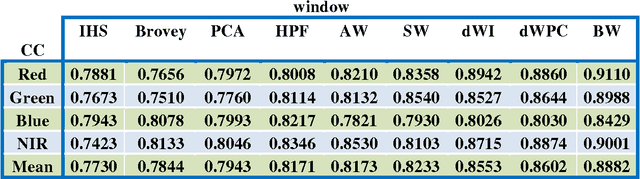


Among the existing fusion algorithms, the wavelet fusion method is the most frequently discussed one in recent publications because the wavelet approach preserves the spectral characteristics of the multispectral image better than other methods. The Brovey is also a popular fusion method used for its ability in preserving the spatial information of the PAN image. This study presents a new fusion approach that integrates the advantages of both the Brovey (which preserves a high degree of spatial information) and the wavelet (which preserves a high degree of spectral information) techniques to reduce the colour distortion of fusion results. Visual and statistical analyzes show that the proposed algorithm clearly improves the merging quality in terms of: correlation coefficient and UIQI; compared to fusion methods including, IHS, Brovey, PCA , HPF, discrete wavelet transform (DWT), and a-trous wavelet.
Partial local entropy and anisotropy in deep weight spaces
Jul 17, 2020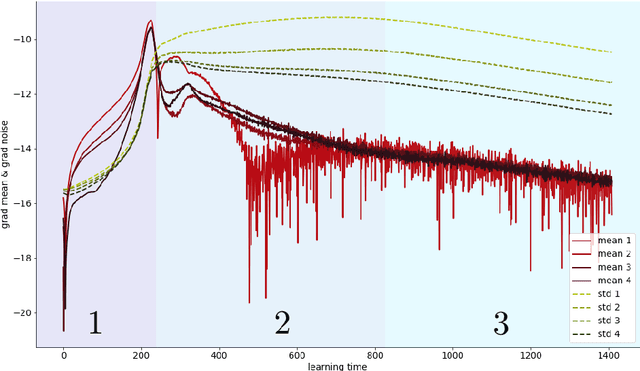
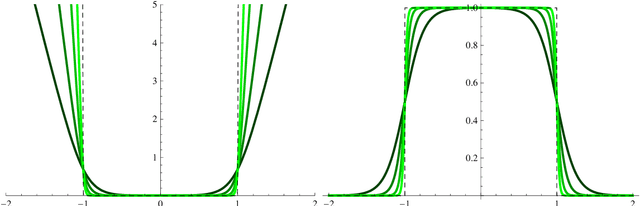
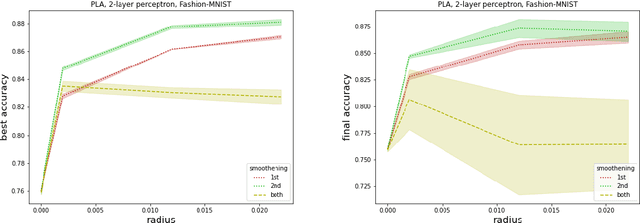
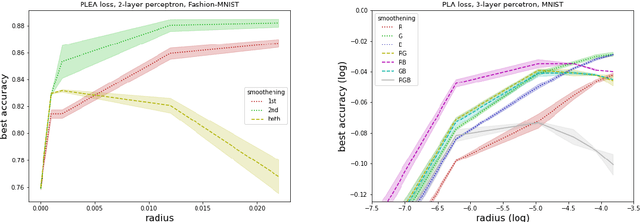
We refine a recently-proposed class of local entropic loss functions by restricting the smoothening regularization to only a subset of weights. The new loss functions are referred to as partial local entropies. They can adapt to the weight-space anisotropy, thus outperforming their isotropic counterparts. We support the theoretical analysis with experiments on image classification tasks performed with multi-layer, fully-connected neural networks. The present study suggests how to better exploit the anisotropic nature of deep landscapes and provides direct probes of the shape of the wide flat minima encountered by stochastic gradient descent algorithms. As a by-product, we observe an asymptotic dynamical regime at late training times where the temperature of all the layers obeys a common scaling rule.
Deep UAV Localization with Reference View Rendering
Aug 11, 2020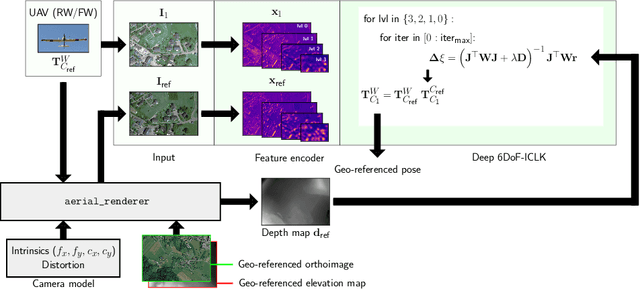
This paper presents a framework for the localization of Unmanned Aerial Vehicles (UAVs) in unstructured environments with the help of deep learning. A real-time rendering engine is introduced that generates optical and depth images given a six Degrees-of-Freedom (DoF) camera pose, camera model, geo-referenced orthoimage, and elevation map. The rendering engine is embedded into a learning-based six-DoF Inverse Compositional Lucas-Kanade (ICLK) algorithm that is able to robustly align the rendered and real-world image taken by the UAV. To learn the alignment under environmental changes, the architecture is trained using maps spanning multiple years at high resolution. The evaluation shows that the deep 6DoF-ICLK algorithm outperforms its non-trainable counterparts by a large margin. To further support the research in this field, the real-time rendering engine and accompanying datasets are released along with this publication.
Shape Adaptor: A Learnable Resizing Module
Aug 03, 2020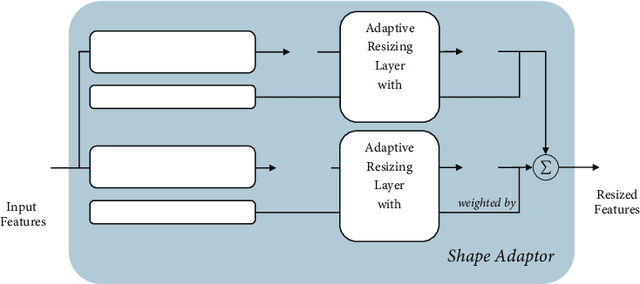
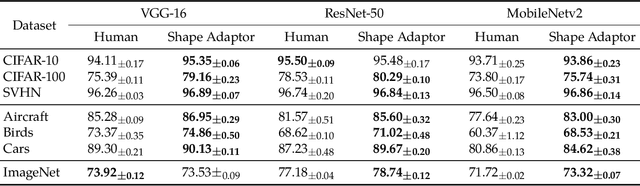
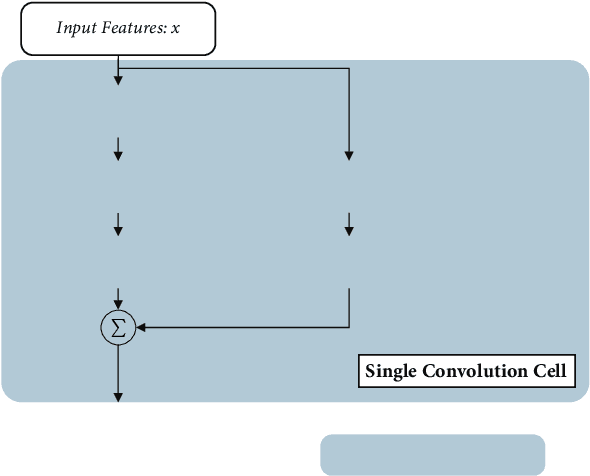

We present a novel resizing module for neural networks: shape adaptor, a drop-in enhancement built on top of traditional resizing layers, such as pooling, bilinear sampling, and strided convolution. Whilst traditional resizing layers have fixed and deterministic reshaping factors, our module allows for a learnable reshaping factor. Our implementation enables shape adaptors to be trained end-to-end without any additional supervision, through which network architectures can be optimised for each individual task, in a fully automated way. We performed experiments across seven image classification datasets, and results show that by simply using a set of our shape adaptors instead of the original resizing layers, performance increases consistently over human-designed networks, across all datasets. Additionally, we show the effectiveness of shape adaptors on two other applications: network compression and transfer learning. The source code is available at: github.com/lorenmt/shape-adaptor.