 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Perception Matters: Exploring Imperceptible and Transferable Anti-forensics for GAN-generated Fake Face Imagery Detection
Oct 29, 2020

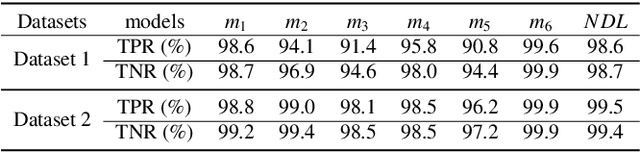
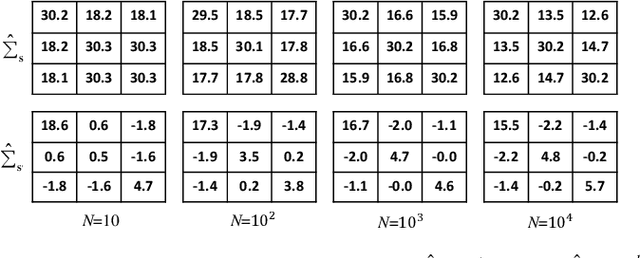
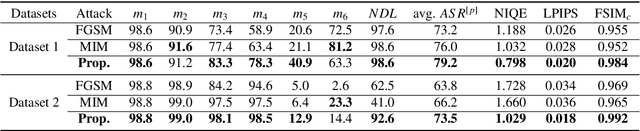
Recently, generative adversarial networks (GANs) can generate photo-realistic fake facial images which are perceptually indistinguishable from real face photos, promoting research on fake face detection. Though fake face forensics can achieve high detection accuracy, their anti-forensic counterparts are less investigated. Here we explore more \textit{imperceptible} and \textit{transferable} anti-forensics for fake face imagery detection based on adversarial attacks. Since facial and background regions are often smooth, even small perturbation could cause noticeable perceptual impairment in fake face images. Therefore it makes existing adversarial attacks ineffective as an anti-forensic method. Our perturbation analysis reveals the intuitive reason of the perceptual degradation issue when directly applying existing attacks. We then propose a novel adversarial attack method, better suitable for image anti-forensics, in the transformed color domain by considering visual perception. Simple yet effective, the proposed method can fool both deep learning and non-deep learning based forensic detectors, achieving higher attack success rate and significantly improved visual quality. Specially, when adversaries consider imperceptibility as a constraint, the proposed anti-forensic method can improve the average attack success rate by around 30\% on fake face images over two baseline attacks. \textit{More imperceptible} and \textit{more transferable}, the proposed method raises new security concerns to fake face imagery detection. We have released our code for public use, and hopefully the proposed method can be further explored in related forensic applications as an anti-forensic benchmark.
Funnel Activation for Visual Recognition
Jul 23, 2020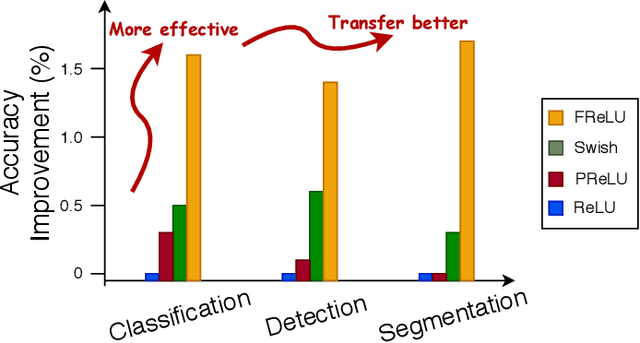
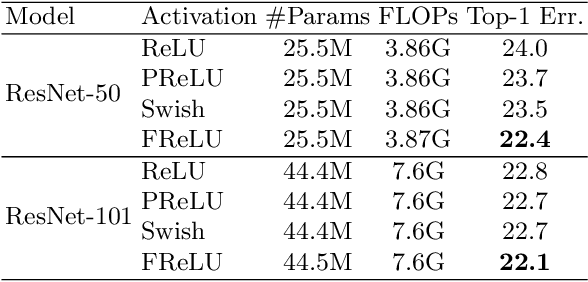
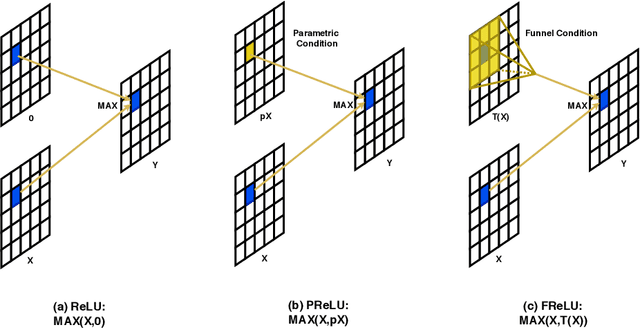
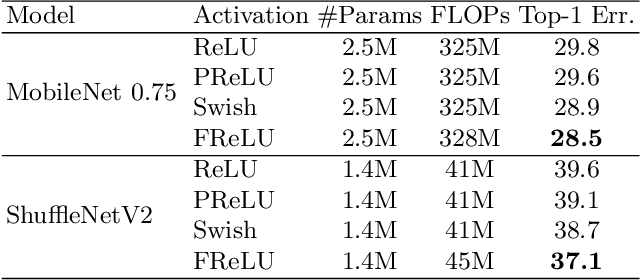
We present a conceptually simple but effective funnel activation for image recognition tasks, called Funnel activation (FReLU), that extends ReLU and PReLU to a 2D activation by adding a negligible overhead of spatial condition. The forms of ReLU and PReLU are y = max(x, 0) and y = max(x, px), respectively, while FReLU is in the form of y = max(x,T(x)), where T(x) is the 2D spatial condition. Moreover, the spatial condition achieves a pixel-wise modeling capacity in a simple way, capturing complicated visual layouts with regular convolutions. We conduct experiments on ImageNet, COCO detection, and semantic segmentation tasks, showing great improvements and robustness of FReLU in the visual recognition tasks.
On the application of Physically-Guided Neural Networks with Internal Variables to Continuum Problems
Nov 23, 2020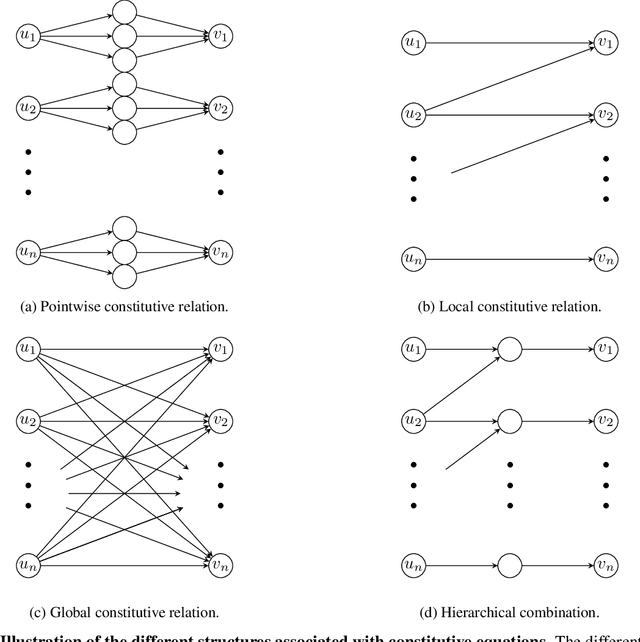

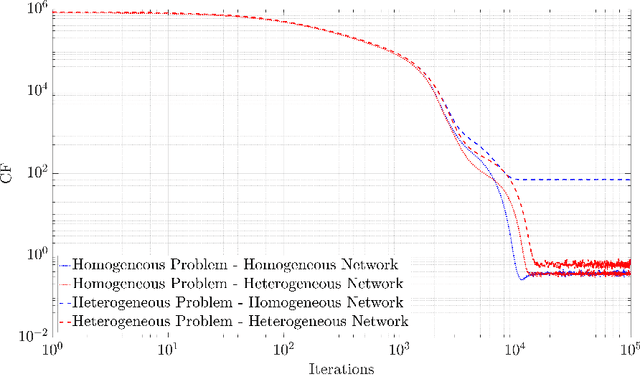
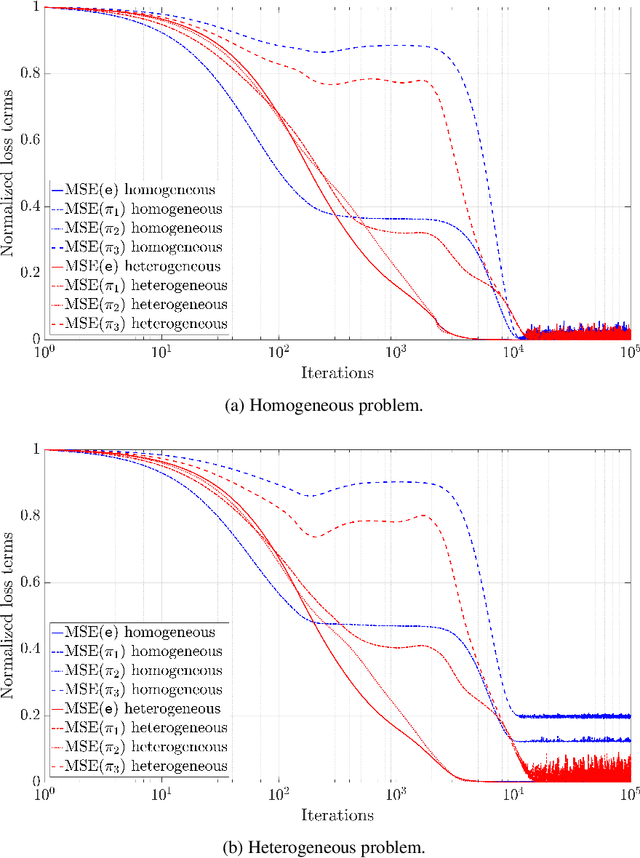
Predictive Physics has been historically based upon the development of mathematical models that describe the evolution of a system under certain external stimuli and constraints. The structure of such mathematical models relies on a set of hysical hypotheses that are assumed to be fulfilled by the system within a certain range of environmental conditions. A new perspective is now raising that uses physical knowledge to inform the data prediction capability of artificial neural networks. A particular extension of this data-driven approach is Physically-Guided Neural Networks with Internal Variables (PGNNIV): universal physical laws are used as constraints in the neural network, in such a way that some neuron values can be interpreted as internal state variables of the system. This endows the network with unraveling capacity, as well as better predictive properties such as faster convergence, fewer data needs and additional noise filtering. Besides, only observable data are used to train the network, and the internal state equations may be extracted as a result of the training processes, so there is no need to make explicit the particular structure of the internal state model. We extend this new methodology to continuum physical problems, showing again its predictive and explanatory capacities when only using measurable values in the training set. We show that the mathematical operators developed for image analysis in deep learning approaches can be used and extended to consider standard functional operators in continuum Physics, thus establishing a common framework for both. The methodology presented demonstrates its ability to discover the internal constitutive state equation for some problems, including heterogeneous and nonlinear features, while maintaining its predictive ability for the whole dataset coverage, with the cost of a single evaluation.
Passport-aware Normalization for Deep Model Protection
Oct 29, 2020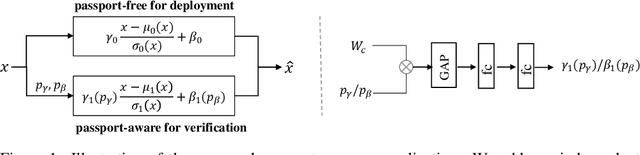

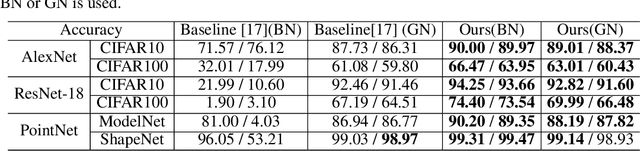
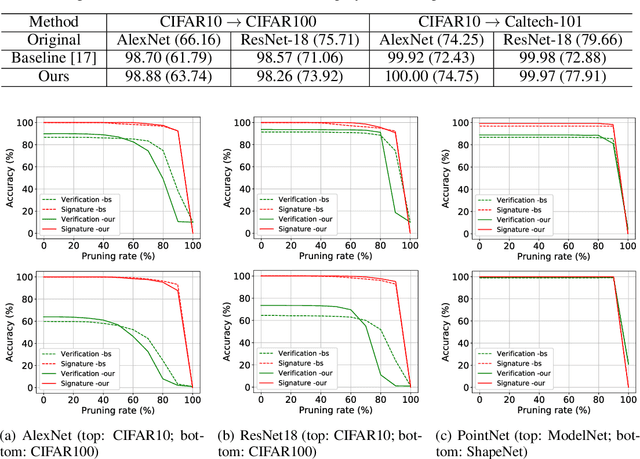
Despite tremendous success in many application scenarios, deep learning faces serious intellectual property (IP) infringement threats. Considering the cost of designing and training a good model, infringements will significantly infringe the interests of the original model owner. Recently, many impressive works have emerged for deep model IP protection. However, they either are vulnerable to ambiguity attacks, or require changes in the target network structure by replacing its original normalization layers and hence cause significant performance drops. To this end, we propose a new passport-aware normalization formulation, which is generally applicable to most existing normalization layers and only needs to add another passport-aware branch for IP protection. This new branch is jointly trained with the target model but discarded in the inference stage. Therefore it causes no structure change in the target model. Only when the model IP is suspected to be stolen by someone, the private passport-aware branch is added back for ownership verification. Through extensive experiments, we verify its effectiveness in both image and 3D point recognition models. It is demonstrated to be robust not only to common attack techniques like fine-tuning and model compression, but also to ambiguity attacks. By further combining it with trigger-set based methods, both black-box and white-box verification can be achieved for enhanced security of deep learning models deployed in real systems. Code can be found at https://github.com/ZJZAC/Passport-aware-Normalization.
Estimating the Brittleness of AI: Safety Integrity Levels and the Need for Testing Out-Of-Distribution Performance
Sep 02, 2020

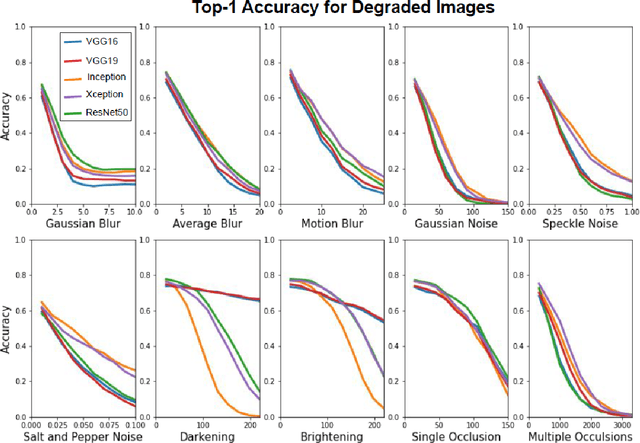
Test, Evaluation, Verification, and Validation (TEVV) for Artificial Intelligence (AI) is a challenge that threatens to limit the economic and societal rewards that AI researchers have devoted themselves to producing. A central task of TEVV for AI is estimating brittleness, where brittleness implies that the system functions well within some bounds and poorly outside of those bounds. This paper argues that neither of those criteria are certain of Deep Neural Networks. First, highly touted AI successes (eg. image classification and speech recognition) are orders of magnitude more failure-prone than are typically certified in critical systems even within design bounds (perfectly in-distribution sampling). Second, performance falls off only gradually as inputs become further Out-Of-Distribution (OOD). Enhanced emphasis is needed on designing systems that are resilient despite failure-prone AI components as well as on evaluating and improving OOD performance in order to get AI to where it can clear the challenging hurdles of TEVV and certification.
Collecting Image Description Datasets using Crowdsourcing
Nov 12, 2014



We describe our two new datasets with images described by humans. Both the datasets were collected using Amazon Mechanical Turk, a crowdsourcing platform. The two datasets contain significantly more descriptions per image than other existing datasets. One is based on a popular image description dataset called the UIUC Pascal Sentence Dataset, whereas the other is based on the Abstract Scenes dataset con- taining images made from clipart objects. In this paper we describe our interfaces, analyze some properties of and show example descriptions from our two datasets.
InterBERT: Vision-and-Language Interaction for Multi-modal Pretraining
Mar 30, 2020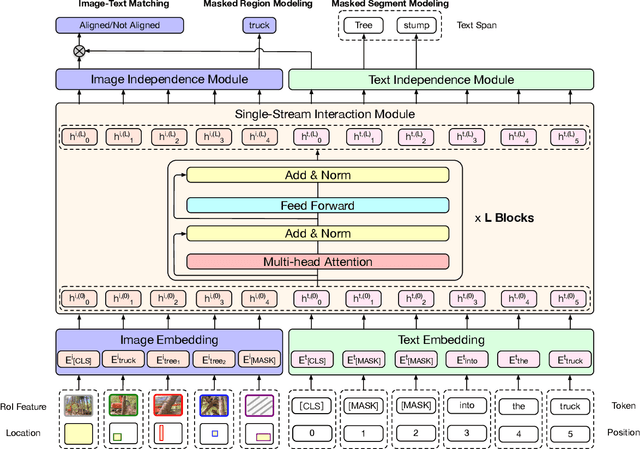
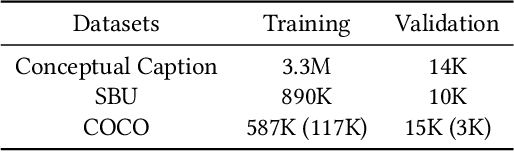


Multi-modal pretraining for learning high-level multi-modal representation is a further step towards deep learning and artificial intelligence. In this work, we propose a novel model, namely InterBERT (BERT for Interaction), which owns strong capability of modeling interaction between the information flows of different modalities. The single-stream interaction module is capable of effectively processing information of multiple modalilties, and the two-stream module on top preserves the independence of each modality to avoid performance downgrade in single-modal tasks. We pretrain the model with three pretraining tasks, including masked segment modeling (MSM), masked region modeling (MRM) and image-text matching (ITM); and finetune the model on a series of vision-and-language downstream tasks. Experimental results demonstrate that InterBERT outperforms a series of strong baselines, including the most recent multi-modal pretraining methods, and the analysis shows that MSM and MRM are effective for pretraining and our method can achieve performances comparable to BERT in single-modal tasks. Besides, we propose a large-scale dataset for multi-modal pretraining in Chinese, and we develop the Chinese InterBERT which is the first Chinese multi-modal pretrained model. We pretrain the Chinese InterBERT on our proposed dataset of 3.1M image-text pairs from the mobile Taobao, the largest Chinese e-commerce platform. We finetune the model for text-based image retrieval, and recently we deployed the model online for topic-based recommendation.
A Mobile App for Wound Localization using Deep Learning
Sep 15, 2020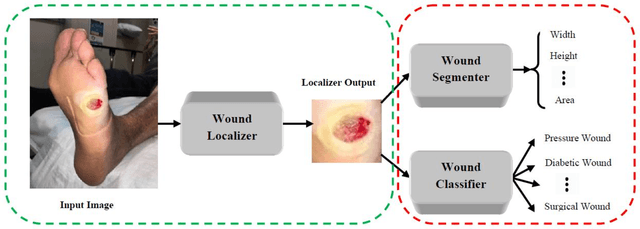
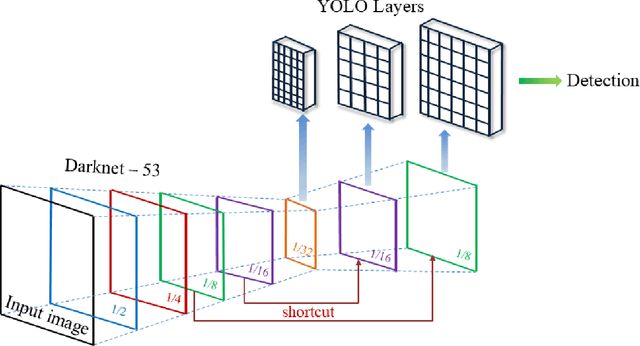
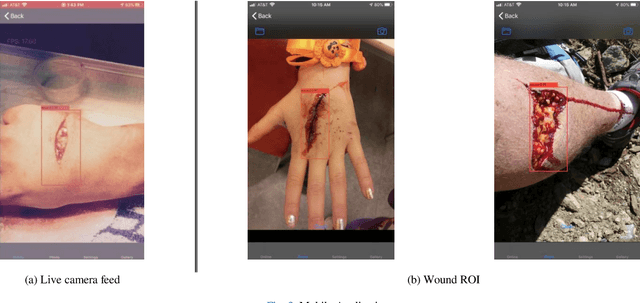
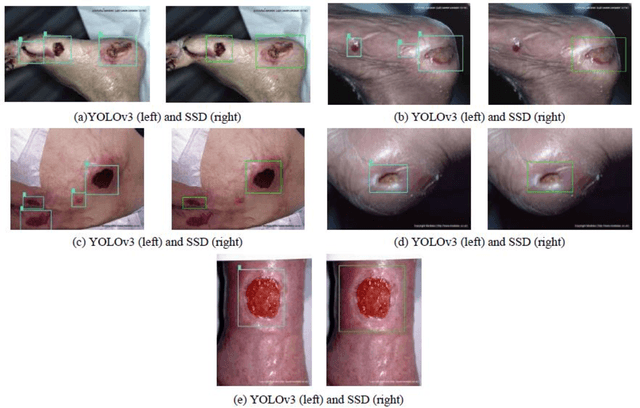
We present an automated wound localizer from 2D wound and ulcer images by using deep neural network, as the first step towards building an automated and complete wound diagnostic system. The wound localizer has been developed by using YOLOv3 model, which is then turned into an iOS mobile application. The developed localizer can detect the wound and its surrounding tissues and isolate the localized wounded region from images, which would be very helpful for future processing such as wound segmentation and classification due to the removal of unnecessary regions from wound images. For Mobile App development with video processing, a lighter version of YOLOv3 named tiny-YOLOv3 has been used. The model is trained and tested on our own image dataset in collaboration with AZH Wound and Vascular Center, Milwaukee, Wisconsin. The YOLOv3 model is compared with SSD model, showing that YOLOv3 gives a mAP value of 93.9%, which is much better than the SSD model (86.4%). The robustness and reliability of these models are also tested on a publicly available dataset named Medetec and shows a very good performance as well.
Surprise: Result List Truncation via Extreme Value Theory
Oct 19, 2020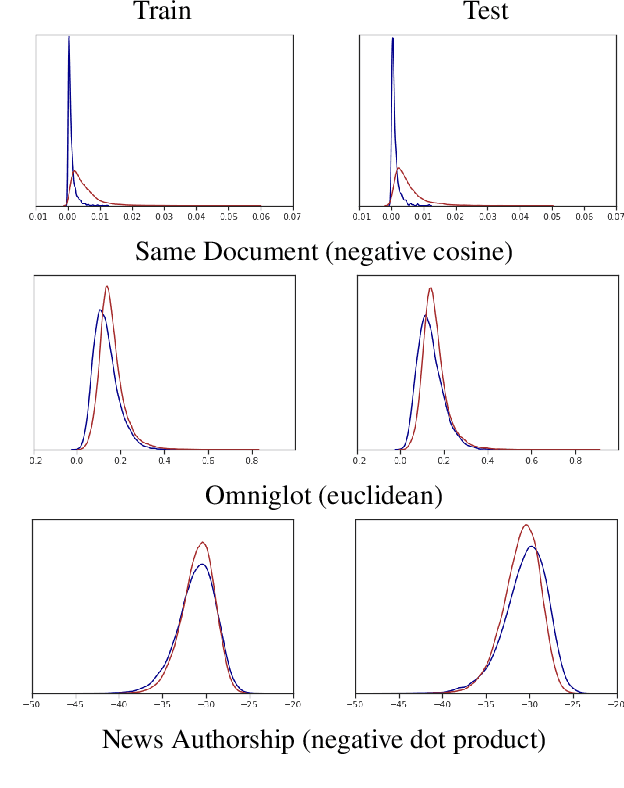
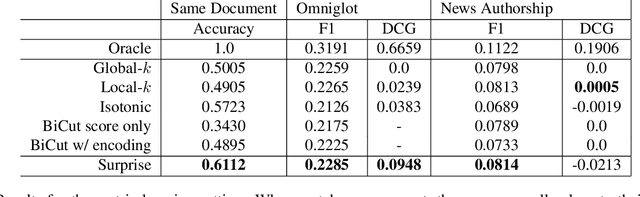
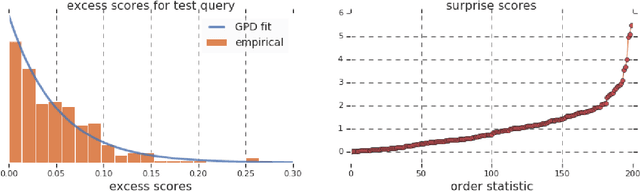
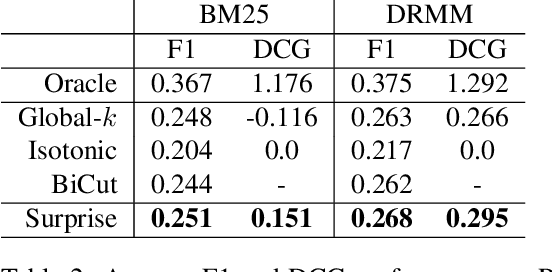
Work in information retrieval has largely been centered around ranking and relevance: given a query, return some number of results ordered by relevance to the user. The problem of result list truncation, or where to truncate the ranked list of results, however, has received less attention despite being crucial in a variety of applications. Such truncation is a balancing act between the overall relevance, or usefulness of the results, with the user cost of processing more results. Result list truncation can be challenging because relevance scores are often not well-calibrated. This is particularly true in large-scale IR systems where documents and queries are embedded in the same metric space and a query's nearest document neighbors are returned during inference. Here, relevance is inversely proportional to the distance between the query and candidate document, but what distance constitutes relevance varies from query to query and changes dynamically as more documents are added to the index. In this work, we propose Surprise scoring, a statistical method that leverages the Generalized Pareto distribution that arises in extreme value theory to produce interpretable and calibrated relevance scores at query time using nothing more than the ranked scores. We demonstrate its effectiveness on the result list truncation task across image, text, and IR datasets and compare it to both classical and recent baselines. We draw connections to hypothesis testing and $p$-values.
Rethinking the Extraction and Interaction of Multi-Scale Features for Vessel Segmentation
Oct 09, 2020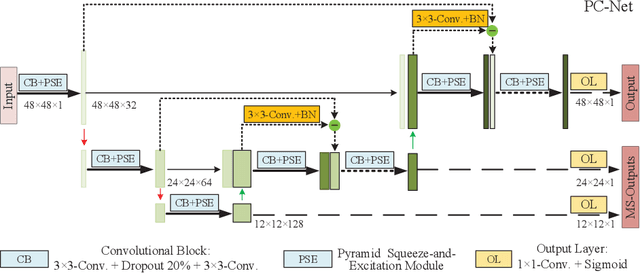
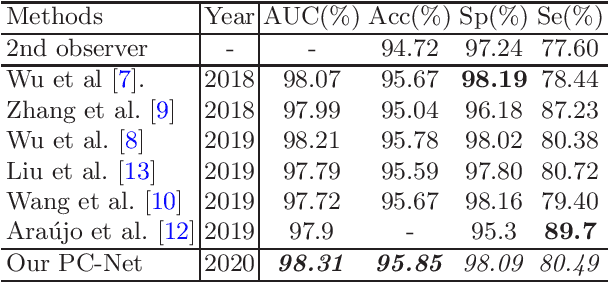
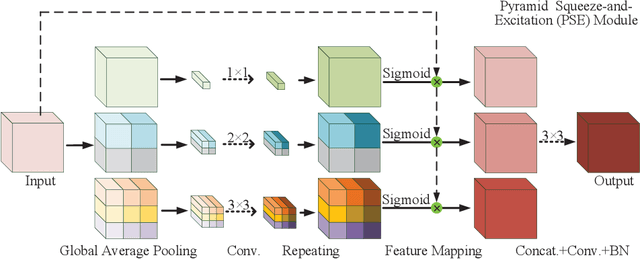
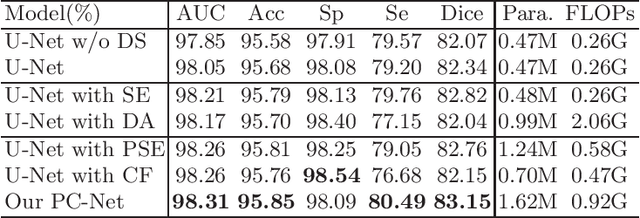
Analyzing the morphological attributes of blood vessels plays a critical role in the computer-aided diagnosis of many cardiovascular and ophthalmologic diseases. Although being extensively studied, segmentation of blood vessels, particularly thin vessels and capillaries, remains challenging mainly due to the lack of an effective interaction between local and global features. In this paper, we propose a novel deep learning model called PC-Net to segment retinal vessels and major arteries in 2D fundus image and 3D computed tomography angiography (CTA) scans, respectively. In PC-Net, the pyramid squeeze-and-excitation (PSE) module introduces spatial information to each convolutional block, boosting its ability to extract more effective multi-scale features, and the coarse-to-fine (CF) module replaces the conventional decoder to enhance the details of thin vessels and process hard-to-classify pixels again. We evaluated our PC-Net on the Digital Retinal Images for Vessel Extraction (DRIVE) database and an in-house 3D major artery (3MA) database against several recent methods. Our results not only demonstrate the effectiveness of the proposed PSE module and CF module, but also suggest that our proposed PC-Net sets new state of the art in the segmentation of retinal vessels (AUC: 98.31%) and major arteries (AUC: 98.35%) on both databases, respectively.