 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Object-centric Sampling for Fine-grained Image Classification
Dec 10, 2014
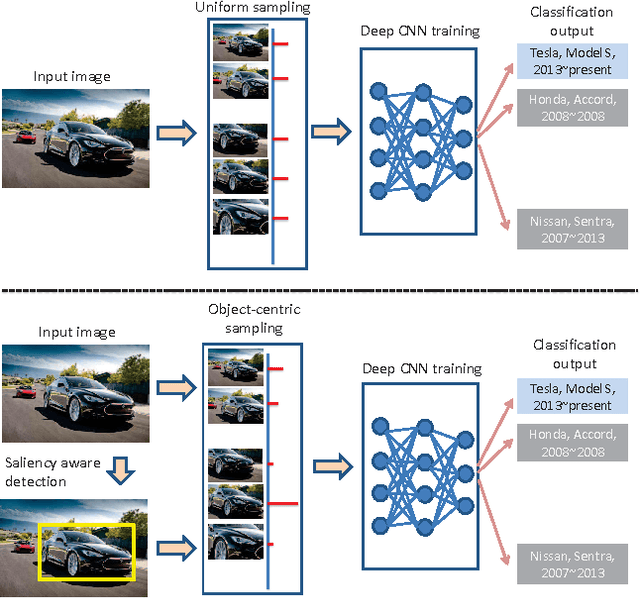
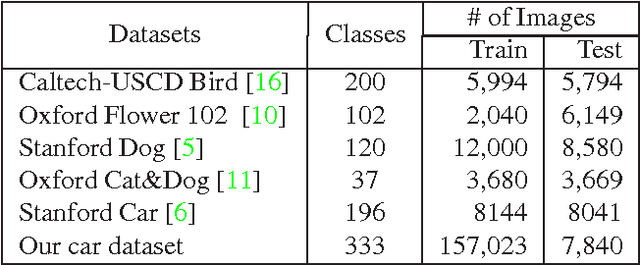

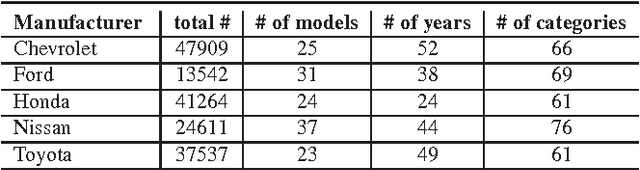
This paper proposes to go beyond the state-of-the-art deep convolutional neural network (CNN) by incorporating the information from object detection, focusing on dealing with fine-grained image classification. Unfortunately, CNN suffers from over-fiting when it is trained on existing fine-grained image classification benchmarks, which typically only consist of less than a few tens of thousands training images. Therefore, we first construct a large-scale fine-grained car recognition dataset that consists of 333 car classes with more than 150 thousand training images. With this large-scale dataset, we are able to build a strong baseline for CNN with top-1 classification accuracy of 81.6%. One major challenge in fine-grained image classification is that many classes are very similar to each other while having large within-class variation. One contributing factor to the within-class variation is cluttered image background. However, the existing CNN training takes uniform window sampling over the image, acting as blind on the location of the object of interest. In contrast, this paper proposes an \emph{object-centric sampling} (OCS) scheme that samples image windows based on the object location information. The challenge in using the location information lies in how to design powerful object detector and how to handle the imperfectness of detection results. To that end, we design a saliency-aware object detection approach specific for the setting of fine-grained image classification, and the uncertainty of detection results are naturally handled in our OCS scheme. Our framework is demonstrated to be very effective, improving top-1 accuracy to 89.3% (from 81.6%) on the large-scale fine-grained car classification dataset.
Disentangling in Latent Space by Harnessing a Pretrained Generator
May 15, 2020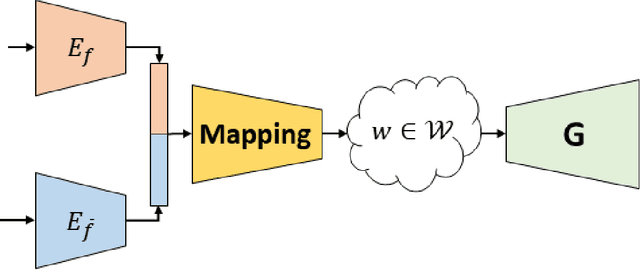


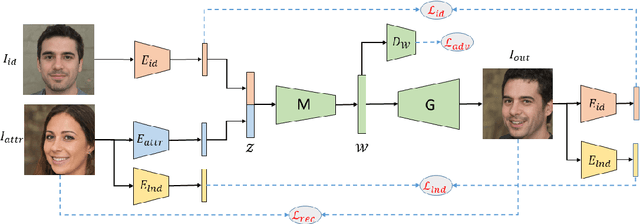
Learning disentangled representations of data is a fundamental problem in artificial intelligence. Specifically, disentangled latent representations allow generative models to control and compose the disentangled factors in the synthesis process. Current methods, however, require extensive supervision and training, or instead, noticeably compromise quality. In this paper, we present a method that learn show to represent data in a disentangled way, with minimal supervision, manifested solely using available pre-trained networks. Our key insight is to decouple the processes of disentanglement and synthesis, by employing a leading pre-trained unconditional image generator, such as StyleGAN. By learning to map into its latent space, we leverage both its state-of-the-art quality generative power, and its rich and expressive latent space, without the burden of training it.We demonstrate our approach on the complex and high dimensional domain of human heads. We evaluate our method qualitatively and quantitatively, and exhibit its success with de-identification operations and with temporal identity coherency in image sequences. Through this extensive experimentation, we show that our method successfully disentangles identity from other facial attributes, surpassing existing methods, even though they require more training and supervision.
Pix2Surf: Learning Parametric 3D Surface Models of Objects from Images
Aug 18, 2020
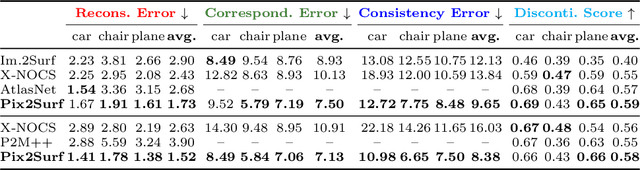
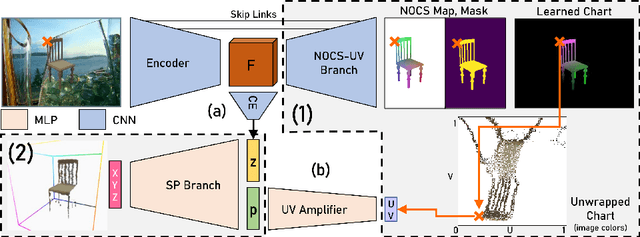
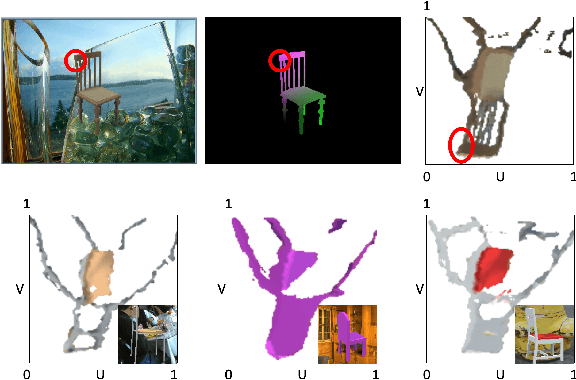
We investigate the problem of learning to generate 3D parametric surface representations for novel object instances, as seen from one or more views. Previous work on learning shape reconstruction from multiple views uses discrete representations such as point clouds or voxels, while continuous surface generation approaches lack multi-view consistency. We address these issues by designing neural networks capable of generating high-quality parametric 3D surfaces which are also consistent between views. Furthermore, the generated 3D surfaces preserve accurate image pixel to 3D surface point correspondences, allowing us to lift texture information to reconstruct shapes with rich geometry and appearance. Our method is supervised and trained on a public dataset of shapes from common object categories. Quantitative results indicate that our method significantly outperforms previous work, while qualitative results demonstrate the high quality of our reconstructions.
Geometric Uncertainty in Patient-Specific Cardiovascular Modeling with Convolutional Dropout Networks
Sep 16, 2020

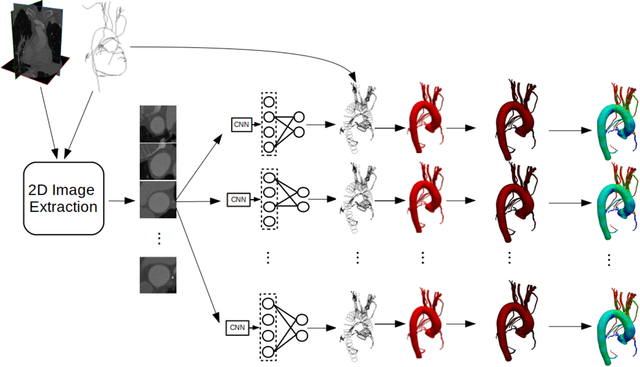
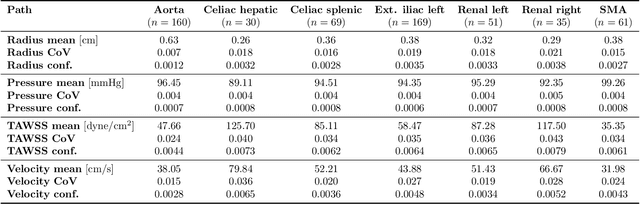
We propose a novel approach to generate samples from the conditional distribution of patient-specific cardiovascular models given a clinically aquired image volume. A convolutional neural network architecture with dropout layers is first trained for vessel lumen segmentation using a regression approach, to enable Bayesian estimation of vessel lumen surfaces. This network is then integrated into a path-planning patient-specific modeling pipeline to generate families of cardiovascular models. We demonstrate our approach by quantifying the effect of geometric uncertainty on the hemodynamics for three patient-specific anatomies, an aorto-iliac bifurcation, an abdominal aortic aneurysm and a sub-model of the left coronary arteries. A key innovation introduced in the proposed approach is the ability to learn geometric uncertainty directly from training data. The results show how geometric uncertainty produces coefficients of variation comparable to or larger than other sources of uncertainty for wall shear stress and velocity magnitude, but has limited impact on pressure. Specifically, this is true for anatomies characterized by small vessel sizes, and for local vessel lesions seen infrequently during network training.
FCN+RL: A Fully Convolutional Network followed by Refinement Layers to Offline Handwritten Signature Segmentation
May 28, 2020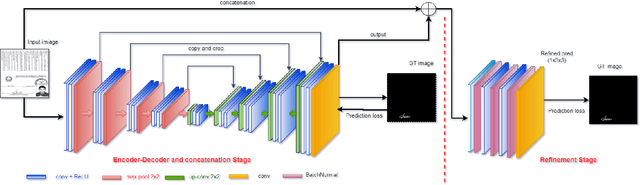

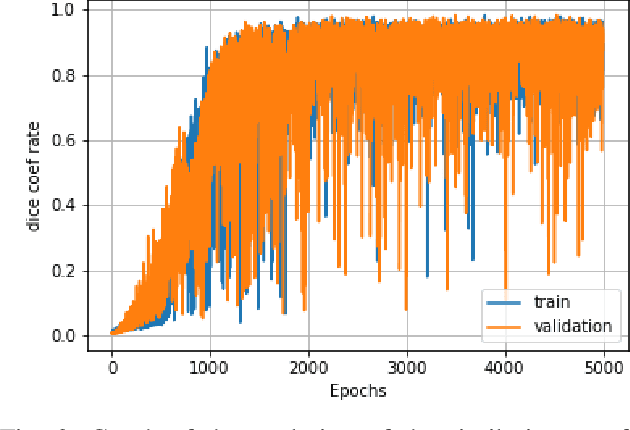
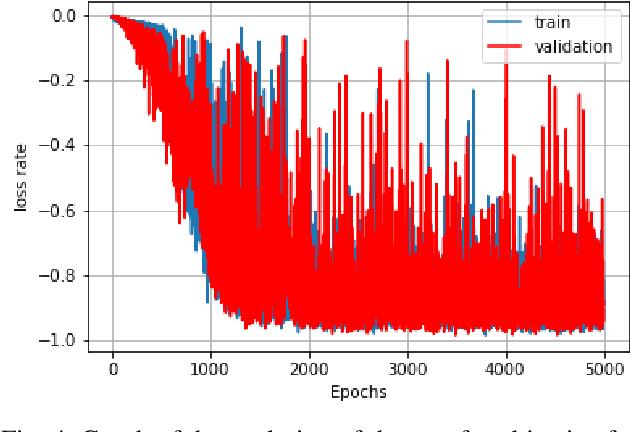
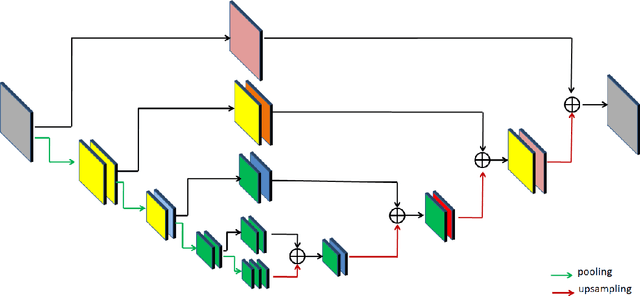
Although secular, handwritten signature is one of the most reliable biometric methods used by most countries. In the last ten years, the application of technology for verification of handwritten signatures has evolved strongly, including forensic aspects. Some factors, such as the complexity of the background and the small size of the region of interest - signature pixels - increase the difficulty of the targeting task. Other factors that make it challenging are the various variations present in handwritten signatures such as location, type of ink, color and type of pen, and the type of stroke. In this work, we propose an approach to locate and extract the pixels of handwritten signatures on identification documents, without any prior information on the location of the signatures. The technique used is based on a fully convolutional encoder-decoder network combined with a block of refinement layers for the alpha channel of the predicted image. The experimental results demonstrate that the technique outputs a clean signature with higher fidelity in the lines than the traditional approaches and preservation of the pertinent characteristics to the signer's spelling. To evaluate the quality of our proposal, we use the following image similarity metrics: SSIM, SIFT, and Dice Coefficient. The qualitative and quantitative results show a significant improvement in comparison with the baseline system.
Depth-aware Blending of Smoothed Images for Bokeh Effect Generation
May 28, 2020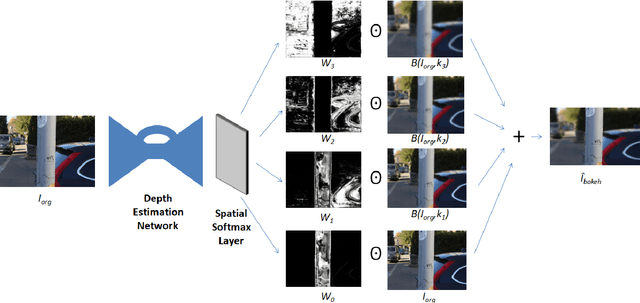
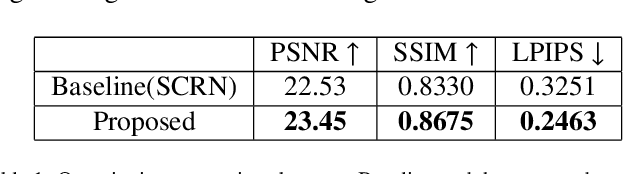
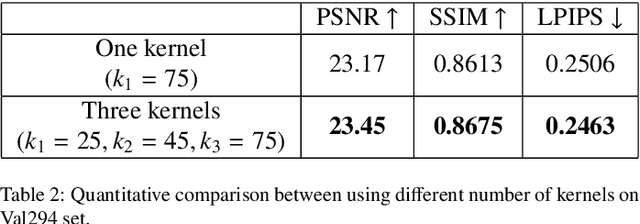
Bokeh effect is used in photography to capture images where the closer objects look sharp and every-thing else stays out-of-focus. Bokeh photos are generally captured using Single Lens Reflex cameras using shallow depth-of-field. Most of the modern smartphones can take bokeh images by leveraging dual rear cameras or a good auto-focus hardware. However, for smartphones with single-rear camera without a good auto-focus hardware, we have to rely on software to generate bokeh images. This kind of system is also useful to generate bokeh effect in already captured images. In this paper, an end-to-end deep learning framework is proposed to generate high-quality bokeh effect from images. The original image and different versions of smoothed images are blended to generate Bokeh effect with the help of a monocular depth estimation network. The proposed approach is compared against a saliency detection based baseline and a number of approaches proposed in AIM 2019 Challenge on Bokeh Effect Synthesis. Extensive experiments are shown in order to understand different parts of the proposed algorithm. The network is lightweight and can process an HD image in 0.03 seconds. This approach ranked second in AIM 2019 Bokeh effect challenge-Perceptual Track.
Perception Matters: Exploring Imperceptible and Transferable Anti-forensics for GAN-generated Fake Face Imagery Detection
Oct 29, 2020
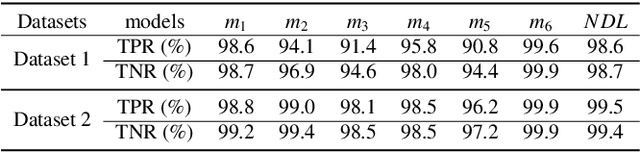
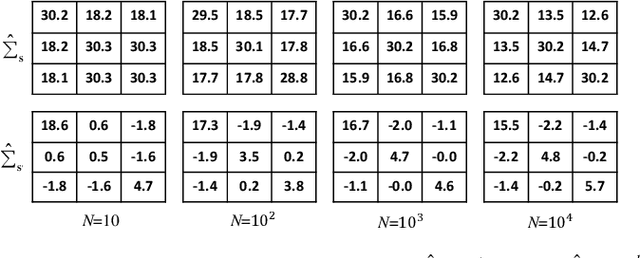
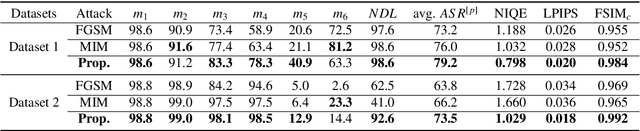
Recently, generative adversarial networks (GANs) can generate photo-realistic fake facial images which are perceptually indistinguishable from real face photos, promoting research on fake face detection. Though fake face forensics can achieve high detection accuracy, their anti-forensic counterparts are less investigated. Here we explore more \textit{imperceptible} and \textit{transferable} anti-forensics for fake face imagery detection based on adversarial attacks. Since facial and background regions are often smooth, even small perturbation could cause noticeable perceptual impairment in fake face images. Therefore it makes existing adversarial attacks ineffective as an anti-forensic method. Our perturbation analysis reveals the intuitive reason of the perceptual degradation issue when directly applying existing attacks. We then propose a novel adversarial attack method, better suitable for image anti-forensics, in the transformed color domain by considering visual perception. Simple yet effective, the proposed method can fool both deep learning and non-deep learning based forensic detectors, achieving higher attack success rate and significantly improved visual quality. Specially, when adversaries consider imperceptibility as a constraint, the proposed anti-forensic method can improve the average attack success rate by around 30\% on fake face images over two baseline attacks. \textit{More imperceptible} and \textit{more transferable}, the proposed method raises new security concerns to fake face imagery detection. We have released our code for public use, and hopefully the proposed method can be further explored in related forensic applications as an anti-forensic benchmark.
Analyzing Koopman approaches to physics-informed machine learning for long-term sea-surface temperature forecasting
Sep 15, 2020
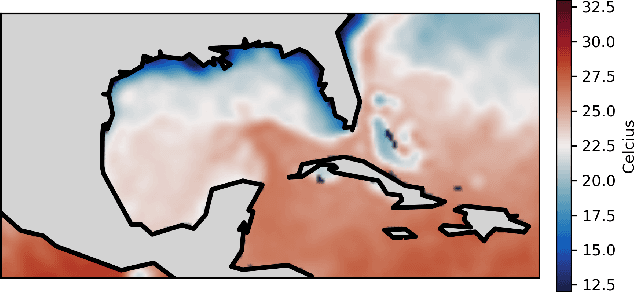
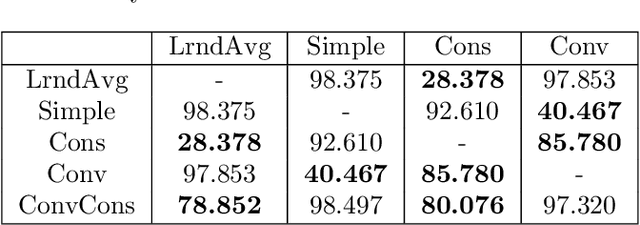

Accurately predicting sea-surface temperature weeks to months into the future is an important step toward long term weather forecasting. Standard atmosphere-ocean coupled numerical models provide accurate sea-surface forecasts on the scale of a few days to a few weeks, but many important weather systems require greater foresight. In this paper we propose machine-learning approaches sea-surface temperature forecasting that are accurate on the scale of dozens of weeks. Our approach is based in Koopman operator theory, a useful tool for dynamical systems modelling. With this approach, we predict sea surface temperature in the Gulf of Mexico up to 180 days into the future based on a present image of thermal conditions and three years of historical training data. We evaluate the combination of a basic Koopman method with a convolutional autoencoder, and a newly proposed "consistent Koopman" method, in various permutations. We show that the Koopman approach consistently outperforms baselines, and we discuss the utility of our additional assumptions and methods in this sea-surface temperature domain.
On the application of Physically-Guided Neural Networks with Internal Variables to Continuum Problems
Nov 23, 2020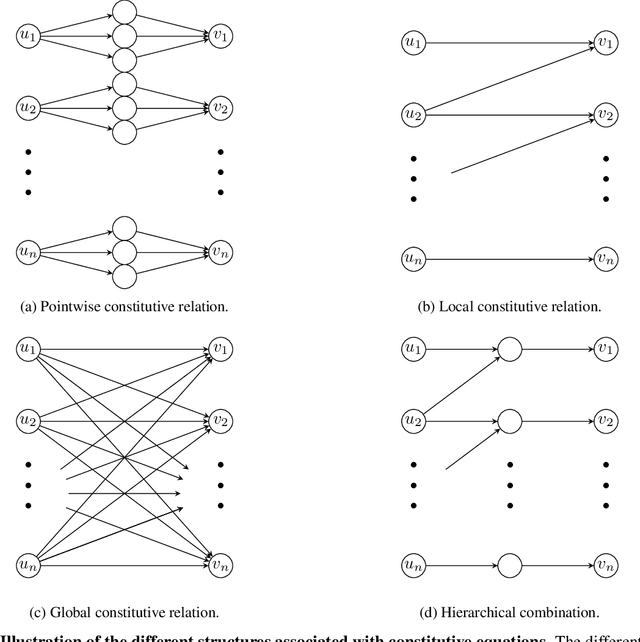

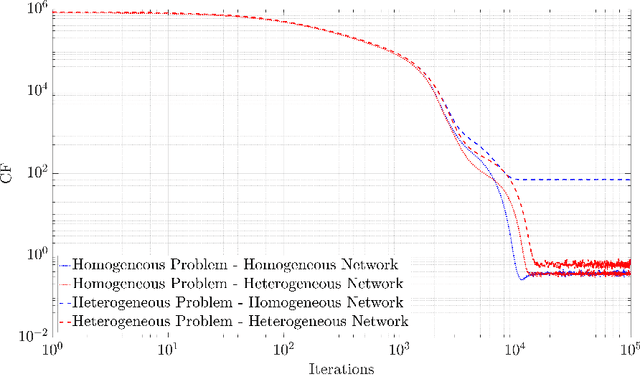
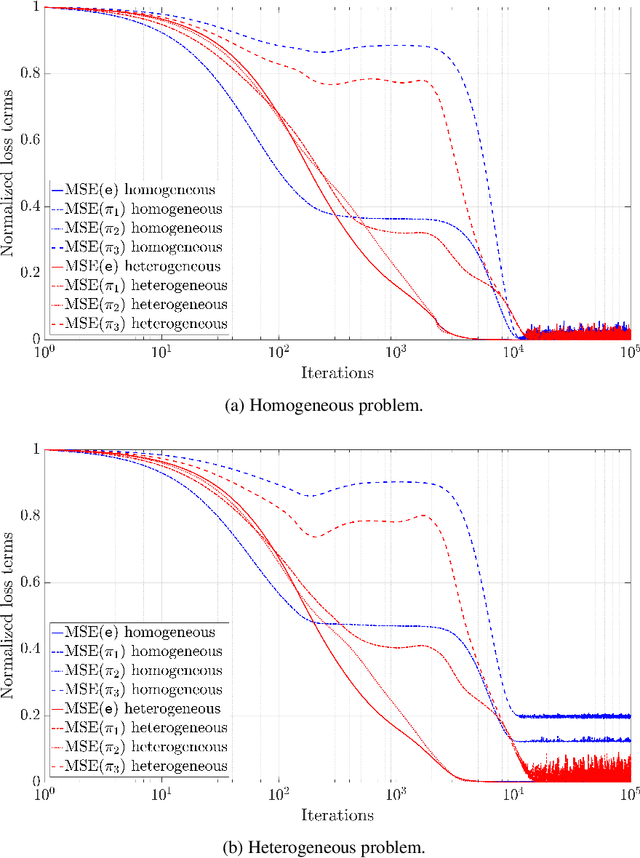
Predictive Physics has been historically based upon the development of mathematical models that describe the evolution of a system under certain external stimuli and constraints. The structure of such mathematical models relies on a set of hysical hypotheses that are assumed to be fulfilled by the system within a certain range of environmental conditions. A new perspective is now raising that uses physical knowledge to inform the data prediction capability of artificial neural networks. A particular extension of this data-driven approach is Physically-Guided Neural Networks with Internal Variables (PGNNIV): universal physical laws are used as constraints in the neural network, in such a way that some neuron values can be interpreted as internal state variables of the system. This endows the network with unraveling capacity, as well as better predictive properties such as faster convergence, fewer data needs and additional noise filtering. Besides, only observable data are used to train the network, and the internal state equations may be extracted as a result of the training processes, so there is no need to make explicit the particular structure of the internal state model. We extend this new methodology to continuum physical problems, showing again its predictive and explanatory capacities when only using measurable values in the training set. We show that the mathematical operators developed for image analysis in deep learning approaches can be used and extended to consider standard functional operators in continuum Physics, thus establishing a common framework for both. The methodology presented demonstrates its ability to discover the internal constitutive state equation for some problems, including heterogeneous and nonlinear features, while maintaining its predictive ability for the whole dataset coverage, with the cost of a single evaluation.
Passport-aware Normalization for Deep Model Protection
Oct 29, 2020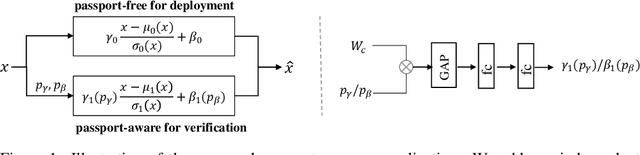

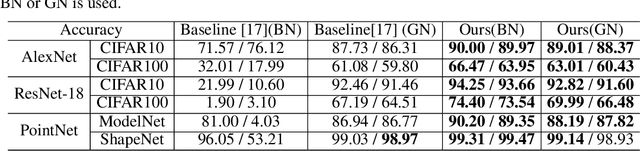
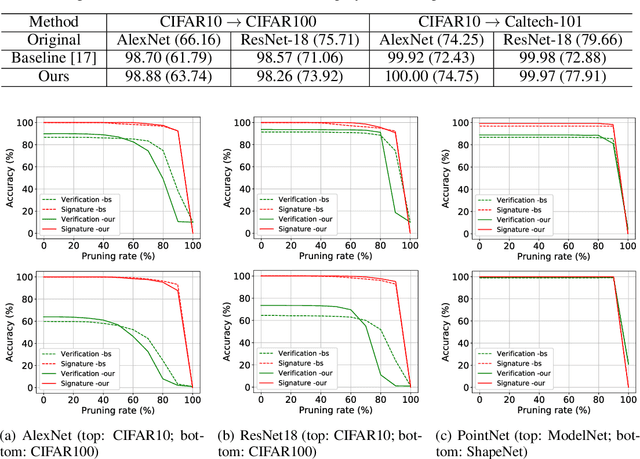
Despite tremendous success in many application scenarios, deep learning faces serious intellectual property (IP) infringement threats. Considering the cost of designing and training a good model, infringements will significantly infringe the interests of the original model owner. Recently, many impressive works have emerged for deep model IP protection. However, they either are vulnerable to ambiguity attacks, or require changes in the target network structure by replacing its original normalization layers and hence cause significant performance drops. To this end, we propose a new passport-aware normalization formulation, which is generally applicable to most existing normalization layers and only needs to add another passport-aware branch for IP protection. This new branch is jointly trained with the target model but discarded in the inference stage. Therefore it causes no structure change in the target model. Only when the model IP is suspected to be stolen by someone, the private passport-aware branch is added back for ownership verification. Through extensive experiments, we verify its effectiveness in both image and 3D point recognition models. It is demonstrated to be robust not only to common attack techniques like fine-tuning and model compression, but also to ambiguity attacks. By further combining it with trigger-set based methods, both black-box and white-box verification can be achieved for enhanced security of deep learning models deployed in real systems. Code can be found at https://github.com/ZJZAC/Passport-aware-Normalization.