 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning from Noisy Labels with Noise Modeling Network
May 01, 2020
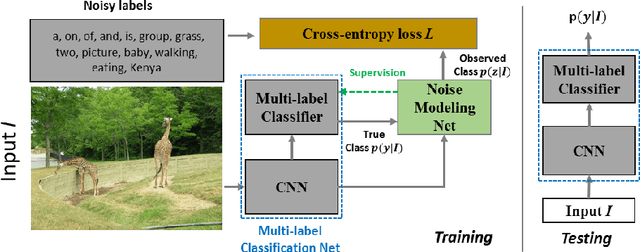
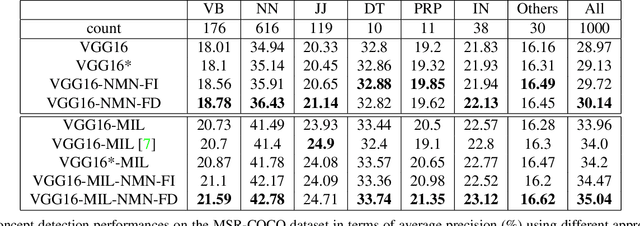
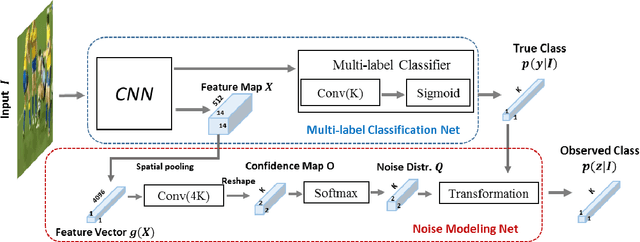
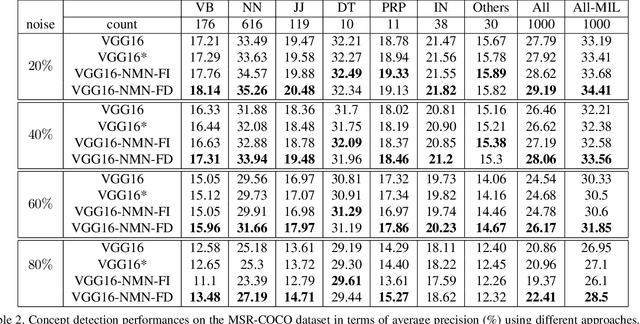
Multi-label image classification has generated significant interest in recent years and the performance of such systems often suffers from the not so infrequent occurrence of incorrect or missing labels in the training data. In this paper, we extend the state-of the-art of training classifiers to jointly deal with both forms of errorful data. We accomplish this by modeling noisy and missing labels in multi-label images with a new Noise Modeling Network (NMN) that follows our convolutional neural network (CNN), integrates with it, forming an end-to-end deep learning system, which can jointly learn the noise distribution and CNN parameters. The NMN learns the distribution of noise patterns directly from the noisy data without the need for any clean training data. The NMN can model label noise that depends only on the true label or is also dependent on the image features. We show that the integrated NMN/CNN learning system consistently improves the classification performance, for different levels of label noise, on the MSR-COCO dataset and MSR-VTT dataset. We also show that noise performance improvements are obtained when multiple instance learning methods are used.
Feature Binding with Category-Dependant MixUp for Semantic Segmentation and Adversarial Robustness
Aug 13, 2020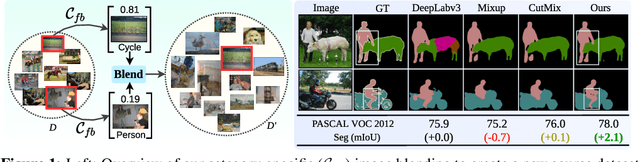

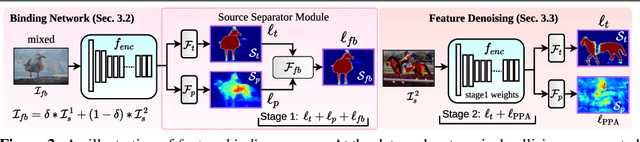
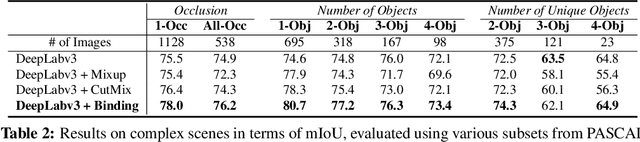
In this paper, we present a strategy for training convolutional neural networks to effectively resolve interference arising from competing hypotheses relating to inter-categorical information throughout the network. The premise is based on the notion of feature binding, which is defined as the process by which activation's spread across space and layers in the network are successfully integrated to arrive at a correct inference decision. In our work, this is accomplished for the task of dense image labelling by blending images based on their class labels, and then training a feature binding network, which simultaneously segments and separates the blended images. Subsequent feature denoising to suppress noisy activations reveals additional desirable properties and high degrees of successful predictions. Through this process, we reveal a general mechanism, distinct from any prior methods, for boosting the performance of the base segmentation network while simultaneously increasing robustness to adversarial attacks.
Epitome for Automatic Image Colorization
Oct 08, 2012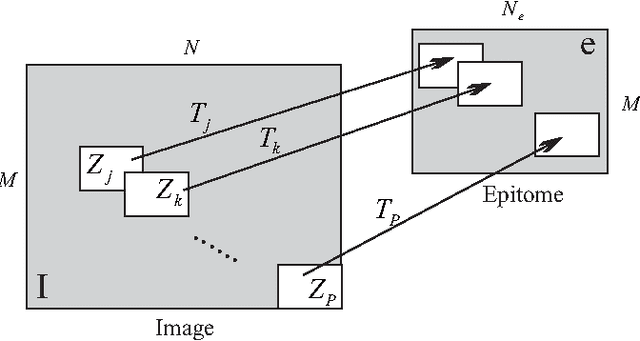


Image colorization adds color to grayscale images. It not only increases the visual appeal of grayscale images, but also enriches the information contained in scientific images that lack color information. Most existing methods of colorization require laborious user interaction for scribbles or image segmentation. To eliminate the need for human labor, we develop an automatic image colorization method using epitome. Built upon a generative graphical model, epitome is a condensed image appearance and shape model which also proves to be an effective summary of color information for the colorization task. We train the epitome from the reference images and perform inference in the epitome to colorize grayscale images, rendering better colorization results than previous method in our experiments.
Scene relighting with illumination estimation in the latent space on an encoder-decoder scheme
Jun 03, 2020
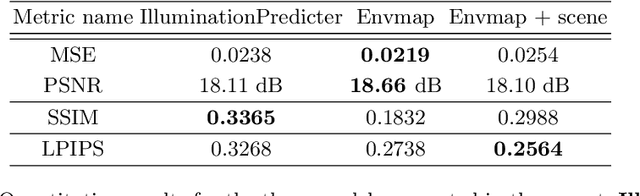

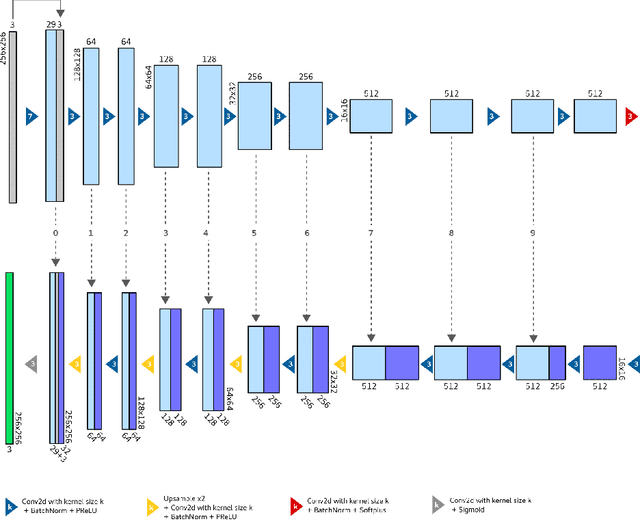
The image relighting task of transferring illumination conditions between two images offers an interesting and difficult challenge with potential applications in photography, cinematography and computer graphics. In this report we present methods that we tried to achieve that goal. Our models are trained on a rendered dataset of artificial locations with varied scene content, light source location and color temperature. With this dataset, we used a network with illumination estimation component aiming to infer and replace light conditions in the latent space representation of the concerned scenes.
Arbitrary Style Transfer via Multi-Adaptation Network
May 27, 2020


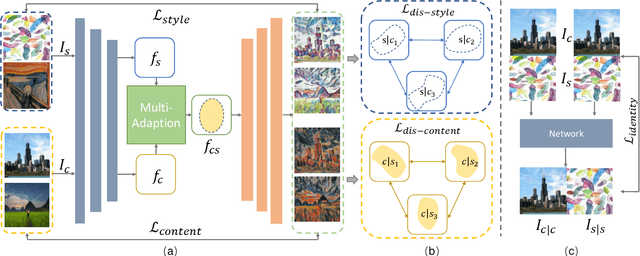
Arbitrary style transfer is a significant topic with both research value and application prospect.Given a content image and a referenced style painting, a desired style transfer would render the content image with the color tone and vivid stroke patterns of the style painting while synchronously maintain the detailed content structure information.Commonly, style transfer approaches would learn content and style representations of the content and style references first and then generate the stylized images guided by these representations.In this paper, we propose the multi-adaption network which involves two Self-Adaptation (SA) modules and one Co-Adaptation (CA) module: SA modules adaptively disentangles the content and style representations, i.e., content SA module uses the position-wise self-attention to enhance content representation and style SA module uses channel-wise self-attention to enhance style representation; CA module rearranges the distribution of style representation according to content representation distribution by calculating the local similarity between the disentangled content and style features in a non-local fashion.Moreover, a new disentanglement loss function enables our network to extract main style patterns to adapt to various content images and extract exact content features to adapt to various style images. Various qualitative and quantitative experiments demonstrate that the proposed multi-adaption network leads to better results than the state-of-the-art style transfer methods.
Generic Semi-Supervised Adversarial Subject Translation for Sensor-Based Human Activity Recognition
Nov 11, 2020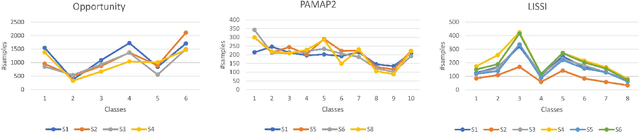
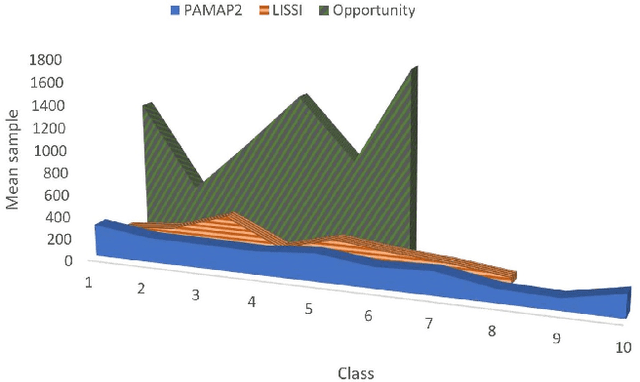
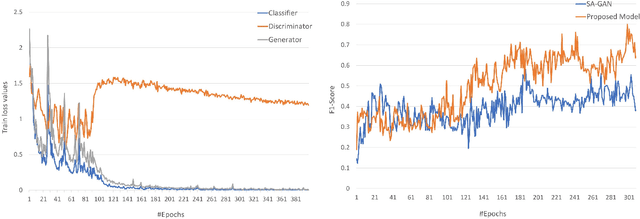
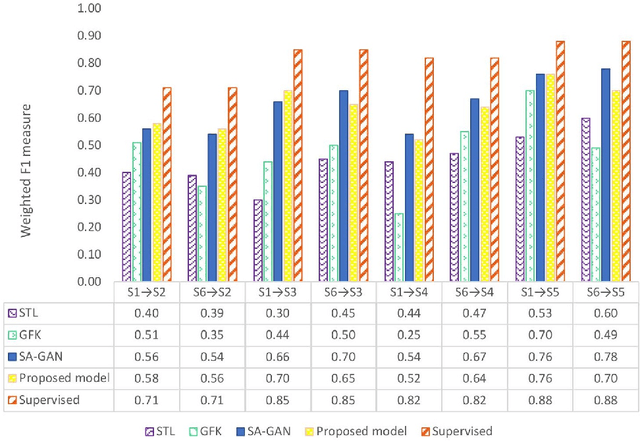
The performance of Human Activity Recognition (HAR) models, particularly deep neural networks, is highly contingent upon the availability of the massive amount of annotated training data which should be sufficiently labeled. Though, data acquisition and manual annotation in the HAR domain are prohibitively expensive due to skilled human resource requirements in both steps. Hence, domain adaptation techniques have been proposed to adapt the knowledge from the existing source of data. More recently, adversarial transfer learning methods have shown very promising results in image classification, yet limited for sensor-based HAR problems, which are still prone to the unfavorable effects of the imbalanced distribution of samples. This paper presents a novel generic and robust approach for semi-supervised domain adaptation in HAR, which capitalizes on the advantages of the adversarial framework to tackle the shortcomings, by leveraging knowledge from annotated samples exclusively from the source subject and unlabeled ones of the target subject. Extensive subject translation experiments are conducted on three large, middle, and small-size datasets with different levels of imbalance to assess the robustness and effectiveness of the proposed model to the scale as well as imbalance in the data. The results demonstrate the effectiveness of our proposed algorithms over state-of-the-art methods, which led in up to 13%, 4%, and 13% improvement of our high-level activities recognition metrics for Opportunity, LISSI, and PAMAP2 datasets, respectively. The LISSI dataset is the most challenging one owing to its less populated and imbalanced distribution. Compared to the SA-GAN adversarial domain adaptation method, the proposed approach enhances the final classification performance with an average of 7.5% for the three datasets, which emphasizes the effectiveness of micro-mini-batch training.
High Voltage Insulator Surface Evaluation Using Image Processing
Aug 19, 2017
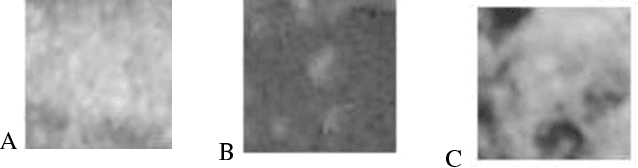
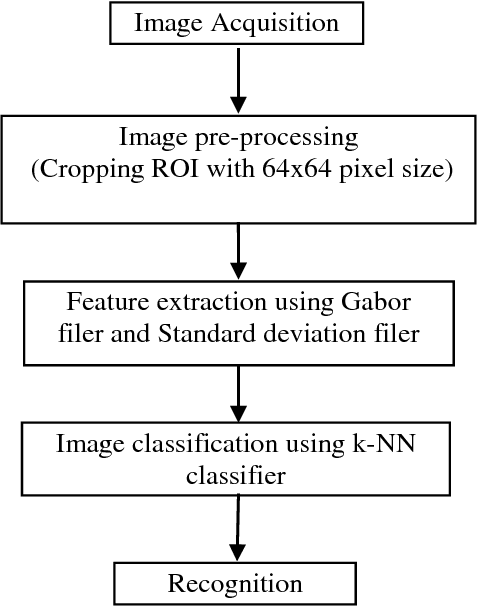
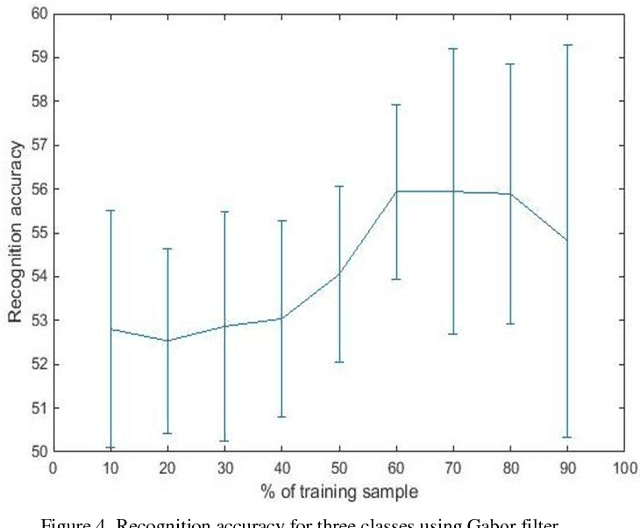
High voltage insulators are widely deployed in power systems to isolate the live- and dead-part of overhead lines as well as to support the power line conductors mechanically. Permanent, secure and safe operation of power transmission lines require that the high voltage insulators are inspected and monitor, regularly. Severe environment conditions will influence insulator surface and change creepage distance. Consequently, power utilities and transmission companies face significant problem in operation due to insulator damage or contamination. In this study, a new technique is developed for real-time inspection of insulator and estimating the snow, ice and water over the insulator surface which can be a potential risk of operation breakdown. To examine the proposed system, practical experiment is conducted using ceramic insulator for capturing the images with snow, ice and wet surface conditions. Gabor and Standard deviation filters are utilized for image feature extraction. The best achieved recognition accuracy rate was 87% using statistical approach the Standard deviation.
PointIso: Point Cloud Based Deep Learning Model for Detecting Arbitrary-Precision Peptide Features in LC-MS Map through Attention Based Segmentation
Sep 15, 2020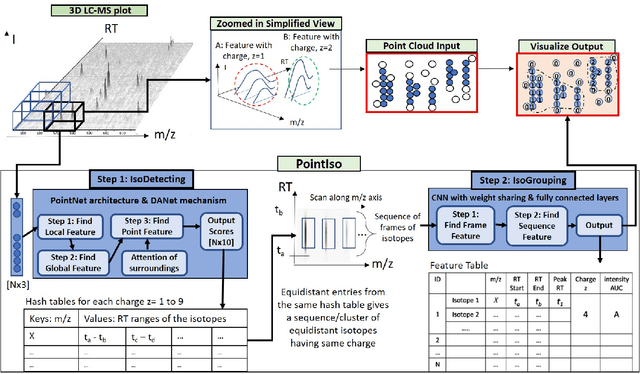

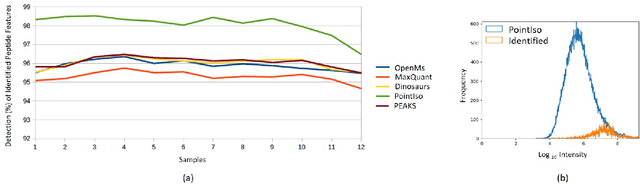

A promising technique of discovering disease biomarkers is to measure the relative protein abundance in multiple biofluid samples through liquid chromatography with tandem mass spectrometry (LC-MS/MS) based quantitative proteomics. The key step involves peptide feature detection in LC-MS map, along with its charge and intensity. Existing heuristic algorithms suffer from inaccurate parameters since different settings of the parameters result in significantly different outcomes. Therefore, we propose PointIso, to serve the necessity of an automated system for peptide feature detection that is able to find out the proper parameters itself, and is easily adaptable to different types of datasets. It consists of an attention based scanning step for segmenting the multi-isotopic pattern of peptide features along with charge and a sequence classification step for grouping those isotopes into potential peptide features. PointIso is the first point cloud based, arbitrary-precision deep learning network to address the problem and achieves 98% detection of high quality MS/MS identifications in a benchmark dataset, which is higher than several other widely used algorithms. Besides contributing to the proteomics study, we believe our novel segmentation technique should serve the general image processing domain as well.
Bone Suppression on Chest Radiographs With Adversarial Learning
Feb 08, 2020

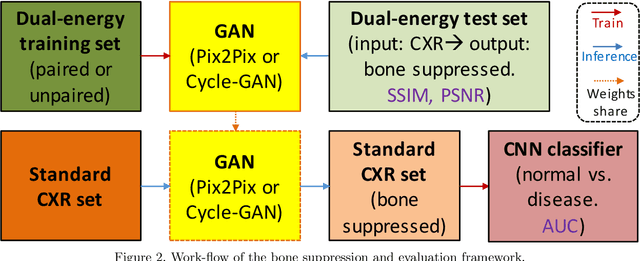
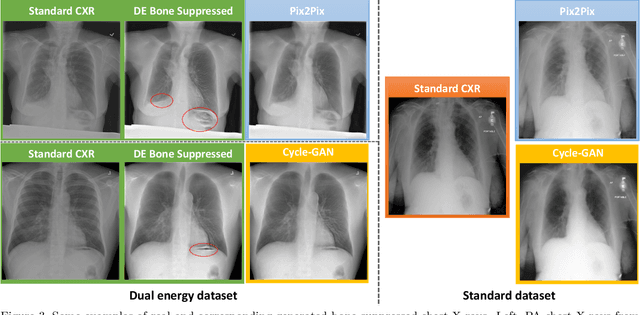
Dual-energy (DE) chest radiography provides the capability of selectively imaging two clinically relevant materials, namely soft tissues, and osseous structures, to better characterize a wide variety of thoracic pathology and potentially improve diagnosis in posteroanterior (PA) chest radiographs. However, DE imaging requires specialized hardware and a higher radiation dose than conventional radiography, and motion artifacts sometimes happen due to involuntary patient motion. In this work, we learn the mapping between conventional radiographs and bone suppressed radiographs. Specifically, we propose to utilize two variations of generative adversarial networks (GANs) for image-to-image translation between conventional and bone suppressed radiographs obtained by DE imaging technique. We compare the effectiveness of training with patient-wisely paired and unpaired radiographs. Experiments show both training strategies yield "radio-realistic'' radiographs with suppressed bony structures and few motion artifacts on a hold-out test set. While training with paired images yields slightly better performance than that of unpaired images when measuring with two objective image quality metrics, namely Structural Similarity Index (SSIM) and Peak Signal-to-Noise Ratio (PSNR), training with unpaired images demonstrates better generalization ability on unseen anteroposterior (AP) radiographs than paired training.
3D_DEN: Open-ended 3D Object Recognition using Dynamically Expandable Networks
Sep 15, 2020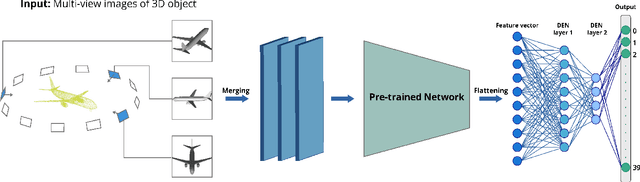
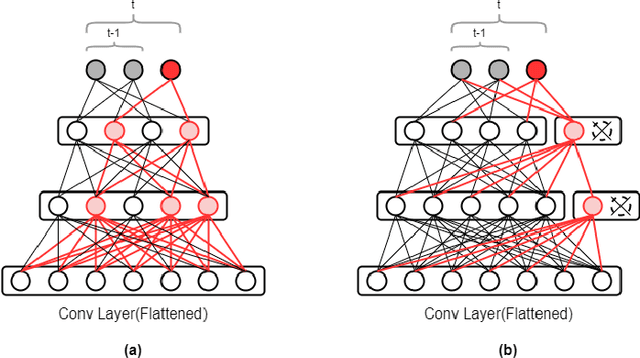
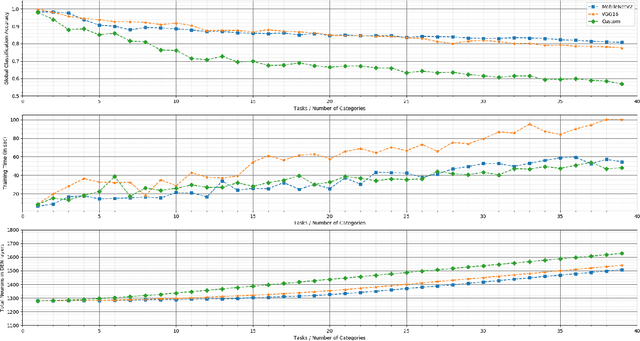
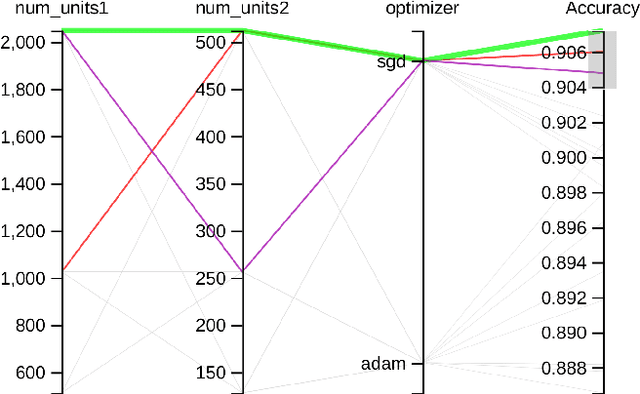
Service robots, in general, have to work independently and adapt to the dynamic changes in the environment. One important aspect in such scenarios is to continually learn to recognize new objects when they become available. This combines two main research problems namely continual learning and 3D object recognition. Most of the existing research approaches include the use of deep Convolutional Neural Networks (CNNs) focusing on image datasets. A modified approach might be needed for continually learning 3D objects. A major concern in using CNNs is the problem of catastrophic forgetting when a model tries to learn new data. In spite of various recent proposed solutions to mitigate this problem, there still exist a few side-effects (such as time/computational complexity) of such solutions. We propose a model capable of learning 3D objects in an open-ended fashion by employing deep transfer learning-based approach combined with dynamically expandable layers, which also makes sure that these side-effects are minimized to a great extent. We show that this model sets a new state-of-the-art standard not only with regards to accuracy but also for computational complexity.