 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robust cDNA microarray image segmentation and analysis technique based on Hough circle transform
Mar 23, 2016
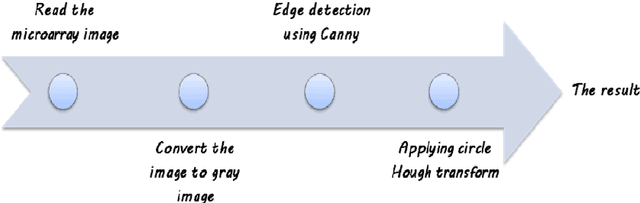
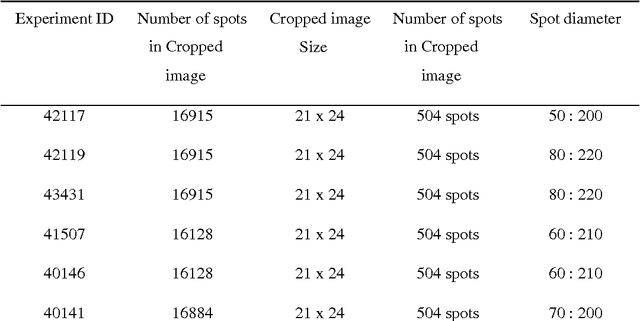
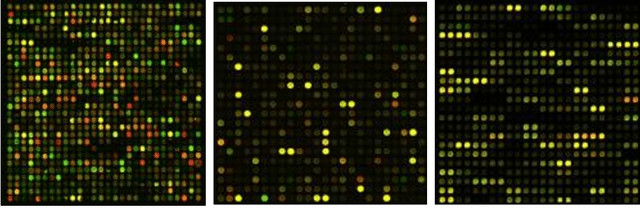
One of the most challenging tasks in microarray image analysis is spot segmentation. A solution to this problem is to provide an algorithm than can be used to find any spot within the microarray image. Circular Hough Transformation (CHT) is a powerful feature extraction technique used in image analysis, computer vision, and digital image processing. CHT algorithm is applied on the cDNA microarray images to develop the accuracy and the efficiency of the spots localization, addressing and segmentation process. The purpose of the applied technique is to find imperfect instances of spots within a certain class of circles by applying a voting procedure on the cDNA microarray images for spots localization, addressing and characterizing the pixels of each spot into foreground pixels and background simultaneously. Intensive experiments on the University of North Carolina (UNC) microarray database indicate that the proposed method is superior to the K-means method and the Support vector machine (SVM). Keywords: Hough circle transformation, cDNA microarray image analysis, cDNA microarray image segmentation, spots localization and addressing, spots segmentation
* 13 Pages,12 figures,FSP JOURNAL ISSN:1955-2068,Vol.9, Issue.7, part.1
Bimanual Regrasping for Suture Needles using Reinforcement Learning for Rapid Motion Planning
Nov 09, 2020
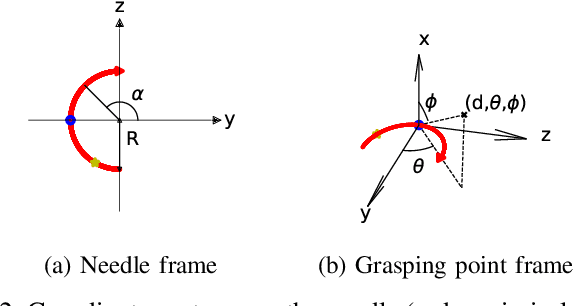
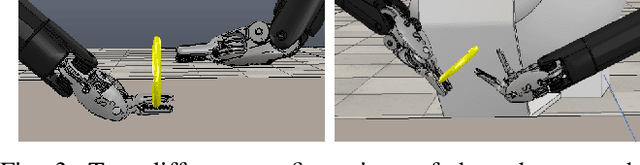
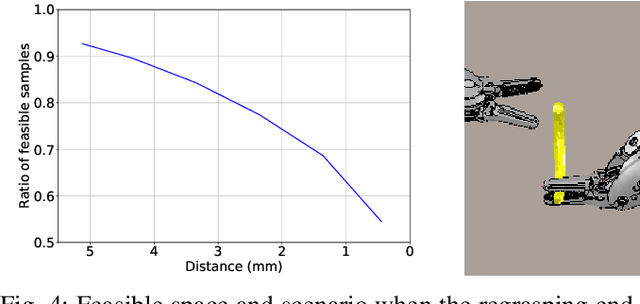
Regrasping a suture needle is an important process in suturing, and previous study has shown that it takes on average 7.4s before the needle is thrown again. To bring efficiency into suturing, prior work either designs a task-specific mechanism or guides the gripper toward some specific pick-up point for proper grasping of a needle. Yet, these methods are usually not deployable when the working space is changed. These prior efforts highlight the need for more efficient regrasping and more generalizability of a proposed method. Therefore, in this work, we present rapid trajectory generation for bimanual needle regrasping via reinforcement learning (RL). Demonstrations from a sampling-based motion planning algorithm is incorporated to speed up the learning. In addition, we propose the ego-centric state and action spaces for this bimanual planning problem, where the reference frames are on the end-effectors instead of some fixed frame. Thus, the learned policy can be directly applied to any robot configuration and even to different robot arms. Our experiments in simulation show that the success rate of a single pass is 97%, and the planning time is 0.0212s on average, which outperforms other widely used motion planning algorithms. For the real-world experiments, the success rate is 73.3% if the needle pose is reconstructed from an RGB image, with a planning time of 0.0846s and a run time of 5.1454s. If the needle pose is known beforehand, the success rate becomes 90.5%, with a planning time of 0.0807s and a run time of 2.8801s.
Classifying All Interacting Pairs in a Single Shot
Jan 13, 2020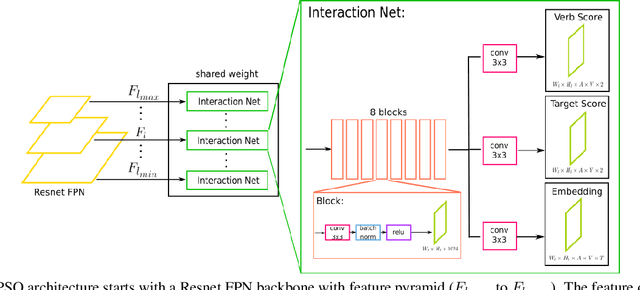


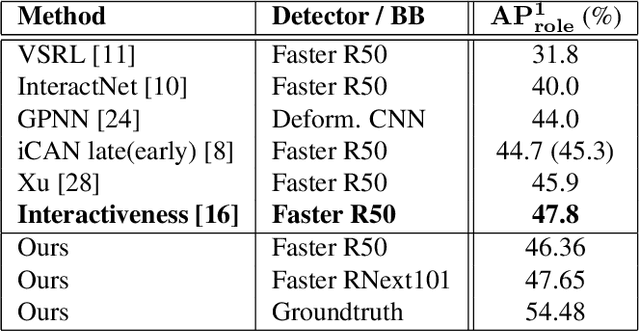
In this paper, we introduce a novel human interaction detection approach, based on CALIPSO (Classifying ALl Interacting Pairs in a Single shOt), a classifier of human-object interactions. This new single-shot interaction classifier estimates interactions simultaneously for all human-object pairs, regardless of their number and class. State-of-the-art approaches adopt a multi-shot strategy based on a pairwise estimate of interactions for a set of human-object candidate pairs, which leads to a complexity depending, at least, on the number of interactions or, at most, on the number of candidate pairs. In contrast, the proposed method estimates the interactions on the whole image. Indeed, it simultaneously estimates all interactions between all human subjects and object targets by performing a single forward pass throughout the image. Consequently, it leads to a constant complexity and computation time independent of the number of subjects, objects or interactions in the image. In detail, interaction classification is achieved on a dense grid of anchors thanks to a joint multi-task network that learns three complementary tasks simultaneously: (i) prediction of the types of interaction, (ii) estimation of the presence of a target and (iii) learning of an embedding which maps interacting subject and target to a same representation, by using a metric learning strategy. In addition, we introduce an object-centric passive-voice verb estimation which significantly improves results. Evaluations on the two well-known Human-Object Interaction image datasets, V-COCO and HICO-DET, demonstrate the competitiveness of the proposed method (2nd place) compared to the state-of-the-art while having constant computation time regardless of the number of objects and interactions in the image.
Single Image Super Resolution via Manifold Approximation
Mar 10, 2015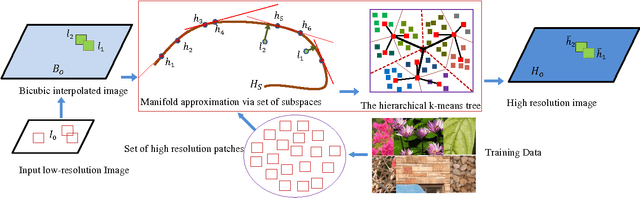
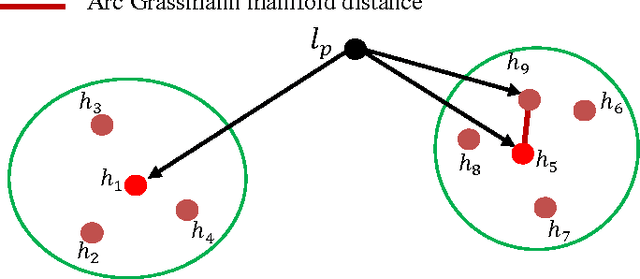

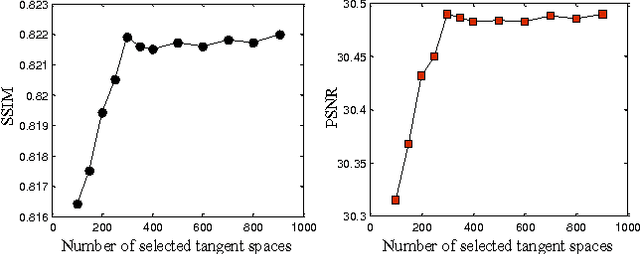
Image super-resolution remains an important research topic to overcome the limitations of physical acquisition systems, and to support the development of high resolution displays. Previous example-based super-resolution approaches mainly focus on analyzing the co-occurrence properties of low resolution and high-resolution patches. Recently, we proposed a novel single image super-resolution approach based on linear manifold approximation of the high-resolution image-patch space [1]. The image super-resolution problem is then formulated as an optimization problem of searching for the best matched high resolution patch in the manifold for a given low-resolution patch. We developed a novel technique based on the l1 norm sparse graph to learn a set of low dimensional affine spaces or tangent subspaces of the high-resolution patch manifold. The optimization problem is then solved based on the learned set of tangent subspaces. In this paper, we build on our recent work as follows. First, we consider and analyze each tangent subspace as one point in a Grassmann manifold, which helps to compute geodesic pairwise distances among these tangent subspaces. Second, we develop a min-max algorithm to select an optimal subset of tangent subspaces. This optimal subset reduces the computational cost while still preserving the quality of the reconstructed high-resolution image. Third, and to further achieve lower computational complexity, we perform hierarchical clustering on the optimal subset based on Grassmann manifold distances. Finally, we analytically prove the validity of the proposed Grassmann-distance based clustering. A comparison of the obtained results with other state-of-the-art methods clearly indicates the viability of the new proposed framework.
Decoupling Representation Learning from Reinforcement Learning
Sep 30, 2020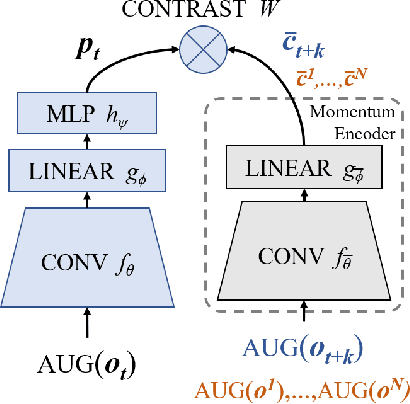

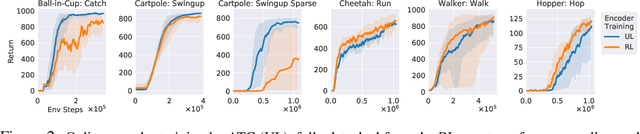
In an effort to overcome limitations of reward-driven feature learning in deep reinforcement learning (RL) from images, we propose decoupling representation learning from policy learning. To this end, we introduce a new unsupervised learning (UL) task, called Augmented Temporal Contrast (ATC), which trains a convolutional encoder to associate pairs of observations separated by a short time difference, under image augmentations and using a contrastive loss. In online RL experiments, we show that training the encoder exclusively using ATC matches or outperforms end-to-end RL in most environments. Additionally, we benchmark several leading UL algorithms by pre-training encoders on expert demonstrations and using them, with weights frozen, in RL agents; we find that agents using ATC-trained encoders outperform all others. We also train multi-task encoders on data from multiple environments and show generalization to different downstream RL tasks. Finally, we ablate components of ATC, and introduce a new data augmentation to enable replay of (compressed) latent images from pre-trained encoders when RL requires augmentation. Our experiments span visually diverse RL benchmarks in DeepMind Control, DeepMind Lab, and Atari, and our complete code is available at https://github.com/astooke/rlpyt/tree/master/rlpyt/ul.
A simple expression for the map of Asplund's distances with the multiplicative Logarithmic Image Processing (LIP) law
Jan 25, 2018We introduce a simple expression for the map of Asplund's distances with the multiplicative Logarithmic Image Processing (LIP) law. It is a difference between a morphological dilation and a morphological erosion with an additive structuring function which corresponds to a morphological gradient.
* Accepted to the 12th European Congress for Stereology and Image Analysis 2017, Kaiserslautern, Germany, September 11-14, 2017
An Analytical Study of different Document Image Binarization Methods
Jan 30, 2015



Document image has been the area of research for a couple of decades because of its potential application in the area of text recognition, line recognition or any other shape recognition from the image. For most of these purposes binarization of image becomes mandatory as far as recognition is concerned. Throughout couple decades standard algorithms have already been developed for this purpose. Some of these algorithms are applicable to degraded image also. Our objective behind this work is to study the existing techniques, compare them in view of advantages and disadvantages and modify some of these algorithms to optimize time or performance.
Incorrect by Construction: Fine Tuning Neural Networks for Guaranteed Performance on Finite Sets of Examples
Aug 03, 2020
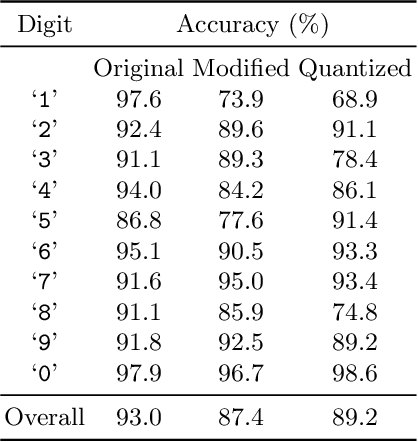
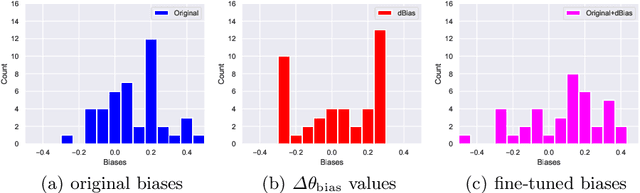
There is great interest in using formal methods to guarantee the reliability of deep neural networks. However, these techniques may also be used to implant carefully selected input-output pairs. We present initial results on a novel technique for using SMT solvers to fine tune the weights of a ReLU neural network to guarantee outcomes on a finite set of particular examples. This procedure can be used to ensure performance on key examples, but it could also be used to insert difficult-to-find incorrect examples that trigger unexpected performance. We demonstrate this approach by fine tuning an MNIST network to incorrectly classify a particular image and discuss the potential for the approach to compromise reliability of freely-shared machine learning models.
S3K: Self-Supervised Semantic Keypoints for Robotic Manipulation via Multi-View Consistency
Sep 30, 2020

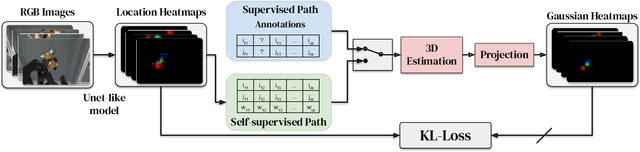
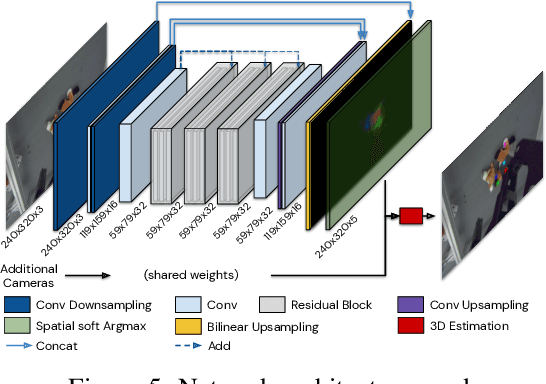
A robot's ability to act is fundamentally constrained by what it can perceive. Many existing approaches to visual representation learning utilize general-purpose training criteria, e.g. image reconstruction, smoothness in latent space, or usefulness for control, or else make use of large datasets annotated with specific features (bounding boxes, segmentations, etc.). However, both approaches often struggle to capture the fine-detail required for precision tasks on specific objects, e.g. grasping and mating a plug and socket. We argue that these difficulties arise from a lack of geometric structure in these models. In this work we advocate semantic 3D keypoints as a visual representation, and present a semi-supervised training objective that can allow instance or category-level keypoints to be trained to 1-5 millimeter-accuracy with minimal supervision. Furthermore, unlike local texture-based approaches, our model integrates contextual information from a large area and is therefore robust to occlusion, noise, and lack of discernible texture. We demonstrate that this ability to locate semantic keypoints enables high level scripting of human understandable behaviours. Finally we show that these keypoints provide a good way to define reward functions for reinforcement learning and are a good representation for training agents.
Improving Self-Organizing Maps with Unsupervised Feature Extraction
Sep 04, 2020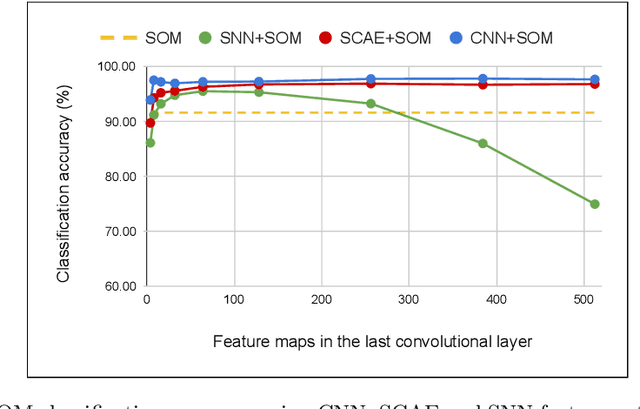

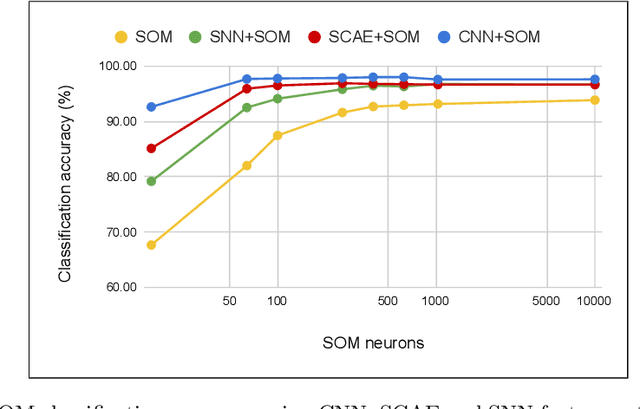

The Self-Organizing Map (SOM) is a brain-inspired neural model that is very promising for unsupervised learning, especially in embedded applications. However, it is unable to learn efficient prototypes when dealing with complex datasets. We propose in this work to improve the SOM performance by using extracted features instead of raw data. We conduct a comparative study on the SOM classification accuracy with unsupervised feature extraction using two different approaches: a machine learning approach with Sparse Convolutional Auto-Encoders using gradient-based learning, and a neuroscience approach with Spiking Neural Networks using Spike Timing Dependant Plasticity learning. The SOM is trained on the extracted features, then very few labeled samples are used to label the neurons with their corresponding class. We investigate the impact of the feature maps, the SOM size and the labeled subset size on the classification accuracy using the different feature extraction methods. We improve the SOM classification by +6.09\% and reach state-of-the-art performance on unsupervised image classification.