 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Models Genesis
Apr 09, 2020
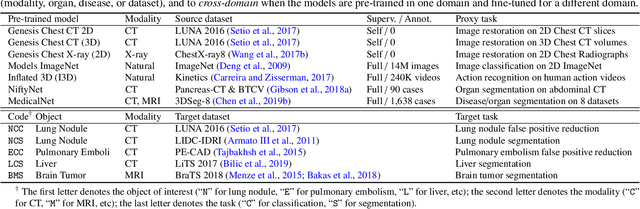
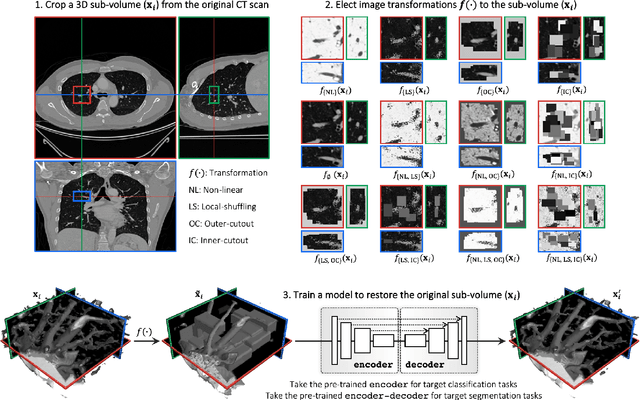
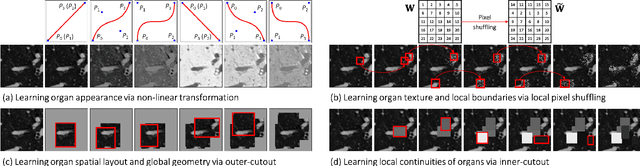
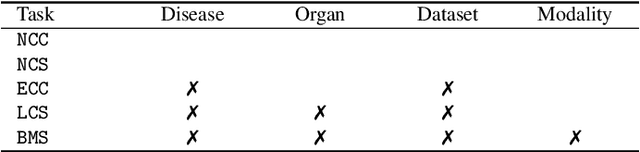
Transfer learning from natural image to medical image has been established as one of the most practical paradigms in deep learning for medical image analysis. To fit this paradigm, however, 3D imaging tasks in the most prominent imaging modalities (e.g., CT and MRI) have to be reformulated and solved in 2D, losing rich 3D anatomical information, thereby inevitably compromising its performance. To overcome this limitation, we have built a set of models, called Generic Autodidactic Models, nicknamed Models Genesis, because they are created ex nihilo (with no manual labeling), self-taught (learnt by self-supervision), and generic (served as source models for generating application-specific target models). Our extensive experiments demonstrate that our Models Genesis significantly outperform learning from scratch in all five target 3D applications covering both segmentation and classification. More importantly, learning a model from scratch simply in 3D may not necessarily yield performance better than transfer learning from ImageNet in 2D, but our Models Genesis consistently top any 2D/2.5D approaches including fine-tuning the models pre-trained from ImageNet as well as fine-tuning the 2D versions of our Models Genesis, confirming the importance of 3D anatomical information and significance of Models Genesis for 3D medical imaging. This performance is attributed to our unified self-supervised learning framework, built on a simple yet powerful observation: the sophisticated and recurrent anatomy in medical images can serve as strong yet free supervision signals for deep models to learn common anatomical representation automatically via self-supervision. As open science, all codes and pre-trained Models Genesis are available at https://github.com/MrGiovanni/ModelsGenesis
Brain Tumor Segmentation by Cascaded Deep Neural Networks Using Multiple Image Scales
Feb 05, 2020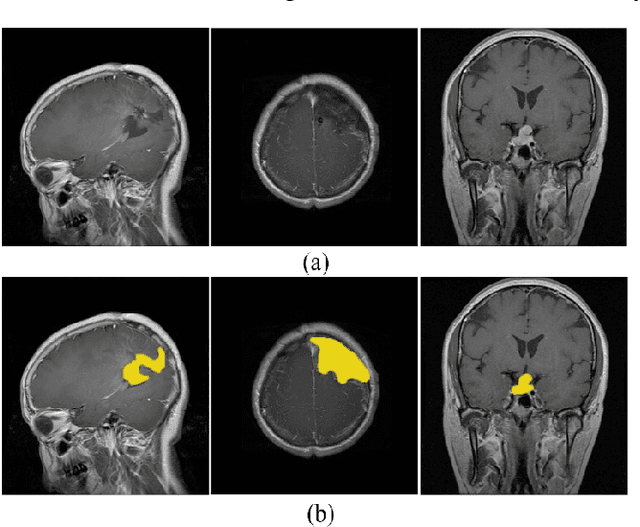
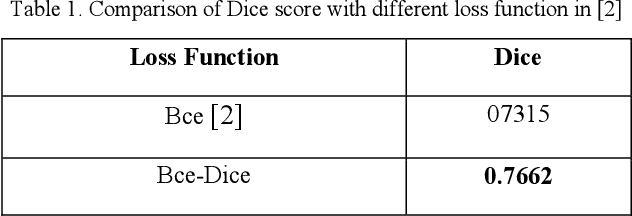
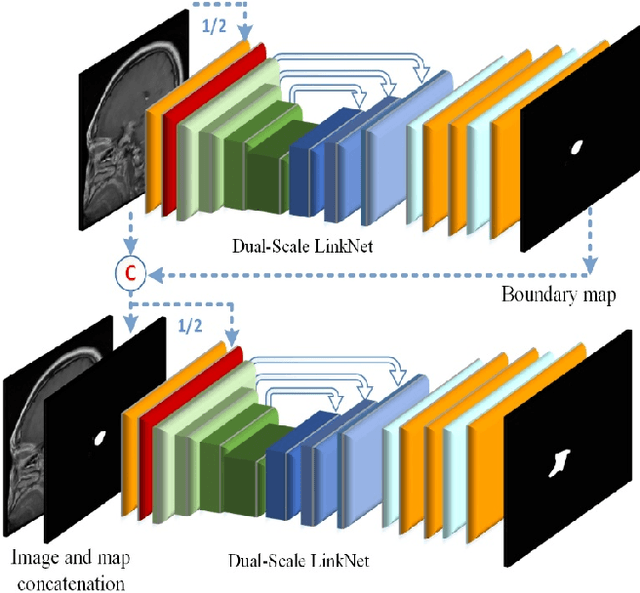
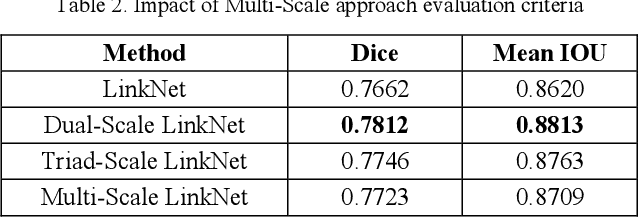
Intracranial tumors are groups of cells that usually grow uncontrollably. One out of four cancer deaths is due to brain tumors. Early detection and evaluation of brain tumors is an essential preventive medical step that is performed by magnetic resonance imaging (MRI). Many segmentation techniques exist for this purpose. Low segmentation accuracy is the main drawback of existing methods. In this paper, we use a deep learning method to boost the accuracy of tumor segmentation in MR images. Cascade approach is used with multiple scales of images to induce both local and global views and help the network to reach higher accuracies. Our experimental results show that using multiple scales and the utilization of two cascade networks is advantageous.
SliderGAN: Synthesizing Expressive Face Images by Sliding 3D Blendshape Parameters
Aug 26, 2019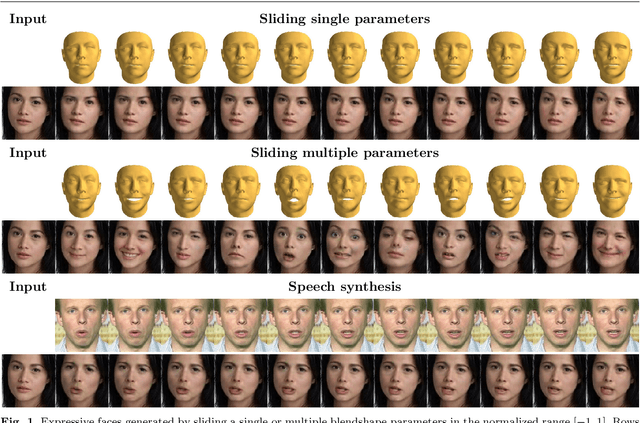
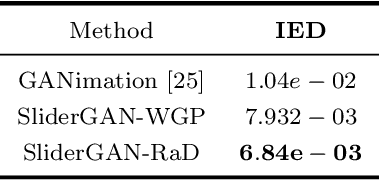


Image-to-image (i2i) translation is the dense regression problem of learning how to transform an input image into an output using aligned image pairs. Remarkable progress has been made in i2i translation with the advent of Deep Convolutional Neural Networks (DCNNs) and particular using the learning paradigm of Generative Adversarial Networks (GANs). In the absence of paired images, i2i translation is tackled with one or multiple domain transformations (i.e., CycleGAN, StarGAN etc.). In this paper, we study a new problem, that of image-to-image translation, under a set of continuous parameters that correspond to a model describing a physical process. In particular, we propose the SliderGAN which transforms an input face image into a new one according to the continuous values of a statistical blendshape model of facial motion. We show that it is possible to edit a facial image according to expression and speech blendshapes, using sliders that control the continuous values of the blendshape model. This provides much more flexibility in various tasks, including but not limited to face editing, expression transfer and face neutralisation, comparing to models based on discrete expressions or action units.
Cosmetic-Aware Makeup Cleanser
Apr 20, 2020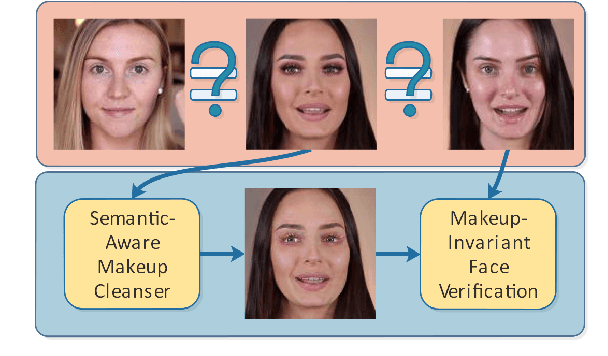
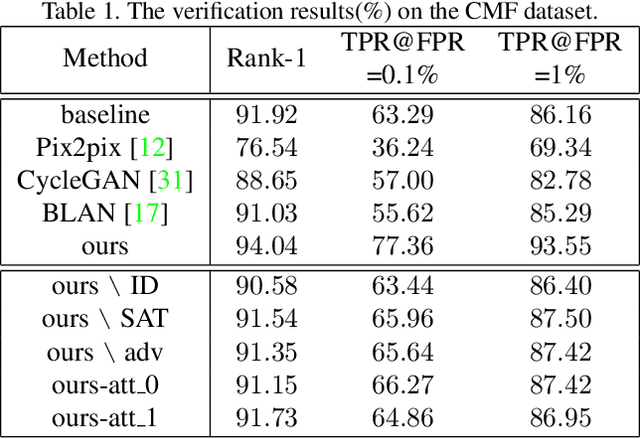
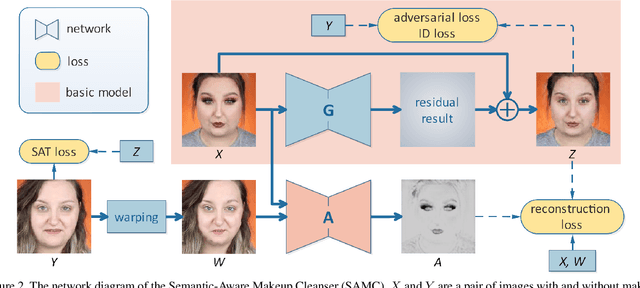

Face verification aims at determining whether a pair of face images belongs to the same identity. Recent studies have revealed the negative impact of facial makeup on the verification performance. With the rapid development of deep generative models, this paper proposes a semanticaware makeup cleanser (SAMC) to remove facial makeup under different poses and expressions and achieve verification via generation. The intuition lies in the fact that makeup is a combined effect of multiple cosmetics and tailored treatments should be imposed on different cosmetic regions. To this end, we present both unsupervised and supervised semantic-aware learning strategies in SAMC. At image level, an unsupervised attention module is jointly learned with the generator to locate cosmetic regions and estimate the degree. At feature level, we resort to the effort of face parsing merely in training phase and design a localized texture loss to serve complements and pursue superior synthetic quality. The experimental results on four makeuprelated datasets verify that SAMC not only produces appealing de-makeup outputs at a resolution of 256*256, but also facilitates makeup-invariant face verification through image generation.
Learning Diverse Latent Representations for Improving the Resilience to Adversarial Attacks
Jul 12, 2020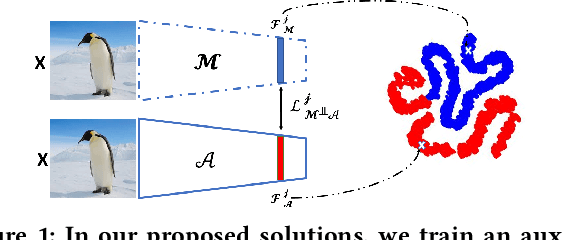
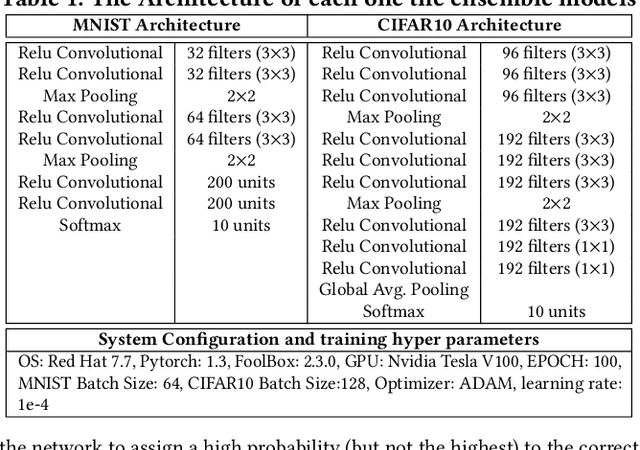
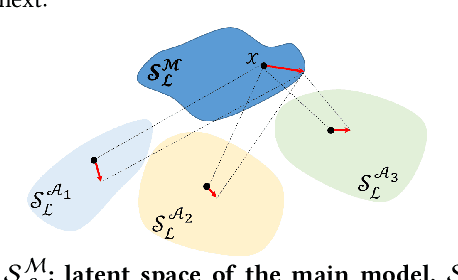
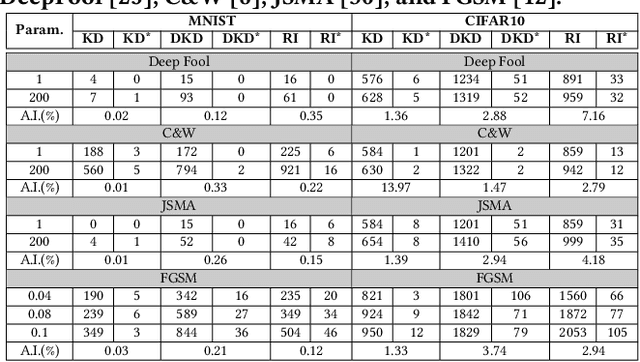
This paper proposes an ensemble learning model that is resistant to adversarial learning attacks. To build resilience, we proposed a training process where each member learns a radically different latent space. Member models are added one at a time to the ensemble. Each model is trained on data set to improve accuracy, while the loss function is regulated by a reverse knowledge distillation, forcing the new member to learn new features and map to a latent space safely distanced from those of existing members. We have evaluated the reliability and performance of the proposed solution on image classification tasks using CIFAR10 and MNIST datasets and show improved performance compared to the state of the art defense methods
Deep Convolutional Neural Network Features and the Original Image
Nov 06, 2016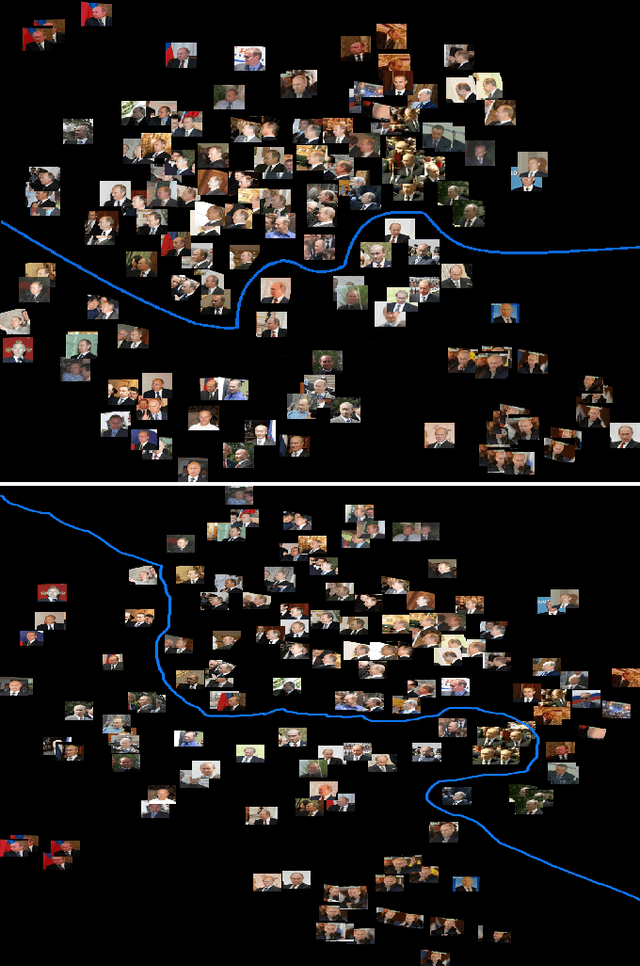
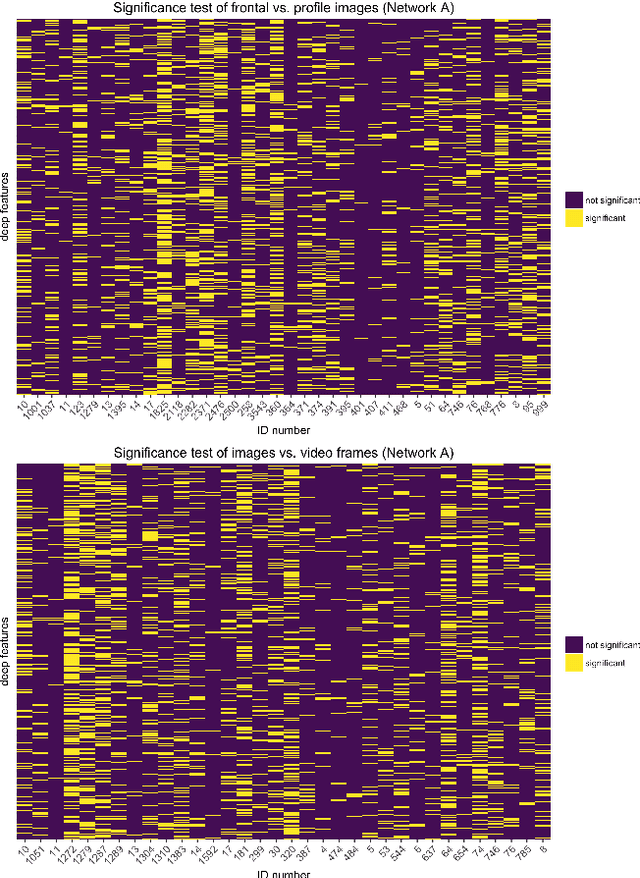


Face recognition algorithms based on deep convolutional neural networks (DCNNs) have made progress on the task of recognizing faces in unconstrained viewing conditions. These networks operate with compact feature-based face representations derived from learning a very large number of face images. While the learned features produced by DCNNs can be highly robust to changes in viewpoint, illumination, and appearance, little is known about the nature of the face code that emerges at the top level of such networks. We analyzed the DCNN features produced by two face recognition algorithms. In the first set of experiments we used the top-level features from the DCNNs as input into linear classifiers aimed at predicting metadata about the images. The results show that the DCNN features contain surprisingly accurate information about the yaw and pitch of a face, and about whether the face came from a still image or a video frame. In the second set of experiments, we measured the extent to which individual DCNN features operated in a view-dependent or view-invariant manner. We found that view-dependent coding was a characteristic of the identities rather than the DCNN features - with some identities coded consistently in a view-dependent way and others in a view-independent way. In our third analysis, we visualized the DCNN feature space for over 24,000 images of 500 identities. Images in the center of the space were uniformly of low quality (e.g., extreme views, face occlusion, low resolution). Image quality increased monotonically as a function of distance from the origin. This result suggests that image quality information is available in the DCNN features, such that consistently average feature values reflect coding failures that reliably indicate poor or unusable images. Combined, the results offer insight into the coding mechanisms that support robust representation of faces in DCNNs.
A Distributed Deep Representation Learning Model for Big Image Data Classification
Jul 02, 2016
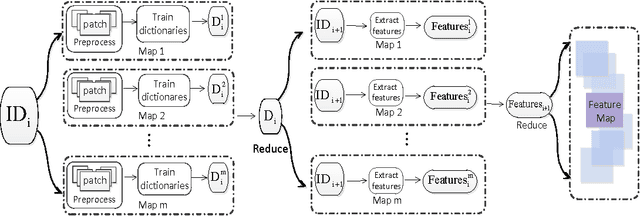
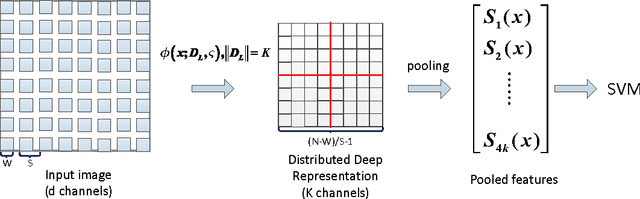

This paper describes an effective and efficient image classification framework nominated distributed deep representation learning model (DDRL). The aim is to strike the balance between the computational intensive deep learning approaches (tuned parameters) which are intended for distributed computing, and the approaches that focused on the designed parameters but often limited by sequential computing and cannot scale up. In the evaluation of our approach, it is shown that DDRL is able to achieve state-of-art classification accuracy efficiently on both medium and large datasets. The result implies that our approach is more efficient than the conventional deep learning approaches, and can be applied to big data that is too complex for parameter designing focused approaches. More specifically, DDRL contains two main components, i.e., feature extraction and selection. A hierarchical distributed deep representation learning algorithm is designed to extract image statistics and a nonlinear mapping algorithm is used to map the inherent statistics into abstract features. Both algorithms are carefully designed to avoid millions of parameters tuning. This leads to a more compact solution for image classification of big data. We note that the proposed approach is designed to be friendly with parallel computing. It is generic and easy to be deployed to different distributed computing resources. In the experiments, the largescale image datasets are classified with a DDRM implementation on Hadoop MapReduce, which shows high scalability and resilience.
IllumiNet: Transferring Illumination from Planar Surfaces to Virtual Objects in Augmented Reality
Jul 12, 2020
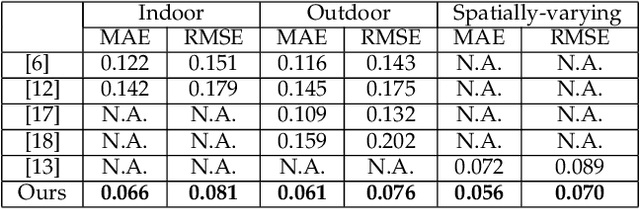
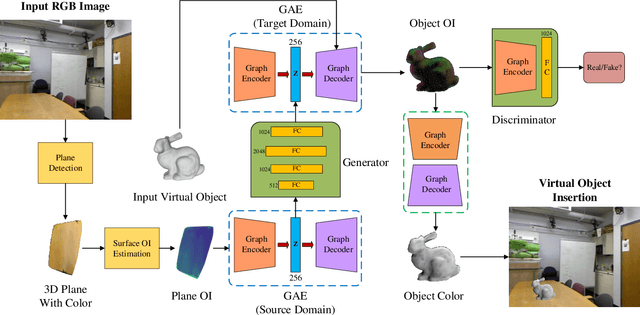

This paper presents an illumination estimation method for virtual objects in real environment by learning. While previous works tackled this problem by reconstructing high dynamic range (HDR) environment maps or the corresponding spherical harmonics, we do not seek to recover the lighting environment of the entire scene. Given a single RGB image, our method directly infers the relit virtual object by transferring the illumination features extracted from planar surfaces in the scene to the desired geometries. Compared to previous works, our approach is more robust as it works in both indoor and outdoor environments with spatially-varying illumination. Experiments and evaluation results show that our approach outperforms the state-of-the-art quantitatively and qualitatively, achieving realistic augmented experience.
Bounds for Learning Lossless Source Coding
Sep 18, 2020
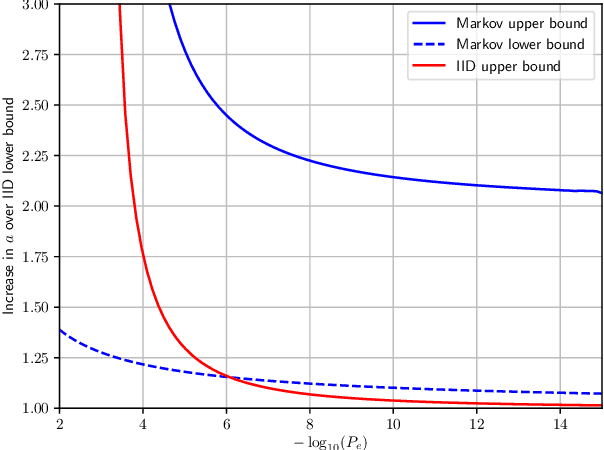
This paper asks a basic question: how much training is required to beat a universal source coder? Traditionally, there have been two types of source coders: fixed, optimum coders such as Huffman coders; and universal source coders, such as Lempel-Ziv The paper considers a third type of source coders: learned coders. These are coders that are trained on data of a particular type, and then used to encode new data of that type. This is a type of coder that has recently become very popular for (lossy) image and video coding. The paper consider two criteria for performance of learned coders: the average performance over training data, and a guaranteed performance over all training except for some error probability $P_e$. In both cases the coders are evaluated with respect to redundancy. The paper considers the IID binary case and binary Markov chains. In both cases it is shown that the amount of training data required is very moderate: to code sequences of length $l$ the amount of training data required to beat a universal source coder is $m=K\frac{l}{\log l}$, where the constant in front depends the case considered.
Exploring Racial Bias within Face Recognition via per-subject Adversarially-Enabled Data Augmentation
Apr 19, 2020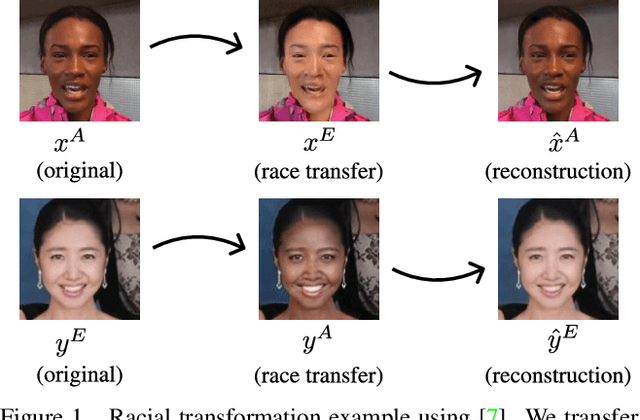
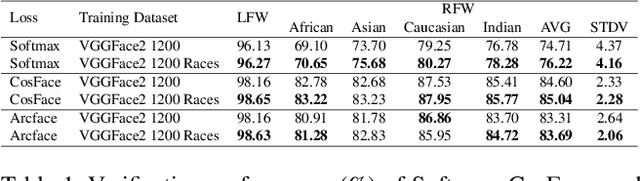
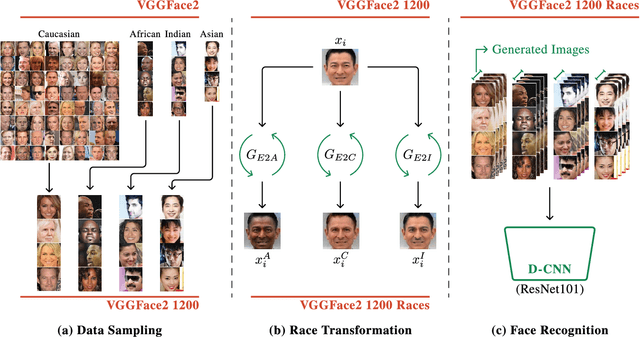

Whilst face recognition applications are becoming increasingly prevalent within our daily lives, leading approaches in the field still suffer from performance bias to the detriment of some racial profiles within society. In this study, we propose a novel adversarial derived data augmentation methodology that aims to enable dataset balance at a per-subject level via the use of image-to-image transformation for the transfer of sensitive racial characteristic facial features. Our aim is to automatically construct a synthesised dataset by transforming facial images across varying racial domains, while still preserving identity-related features, such that racially dependant features subsequently become irrelevant within the determination of subject identity. We construct our experiments on three significant face recognition variants: Softmax, CosFace and ArcFace loss over a common convolutional neural network backbone. In a side-by-side comparison, we show the positive impact our proposed technique can have on the recognition performance for (racial) minority groups within an originally imbalanced training dataset by reducing the pre-race variance in performance.