 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Quantum Annealing Approaches to the Phase-Unwrapping Problem in Synthetic-Aperture Radar Imaging
Oct 01, 2020
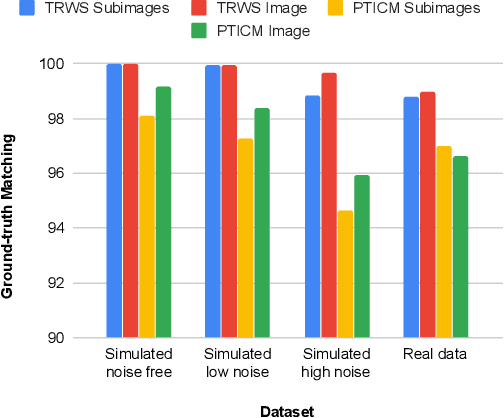
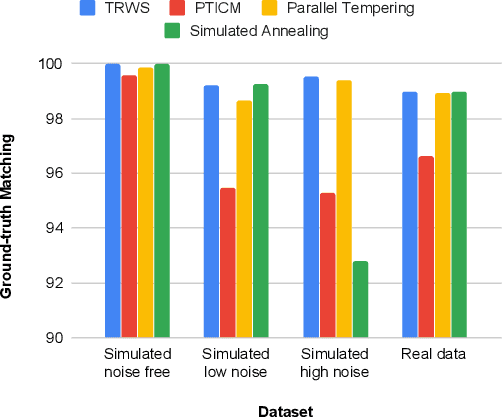
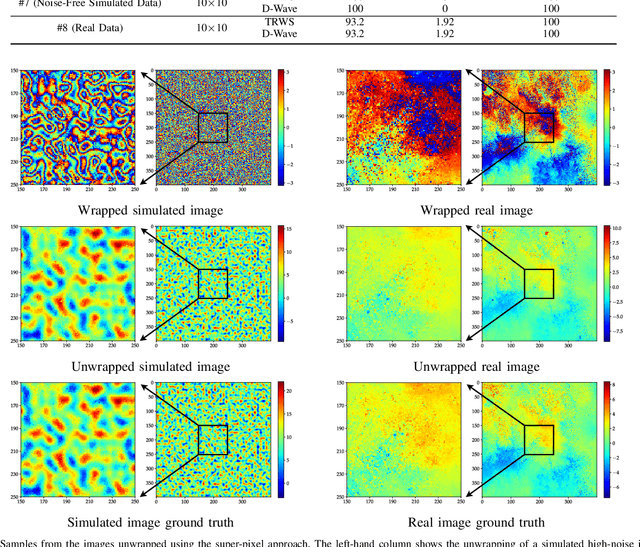
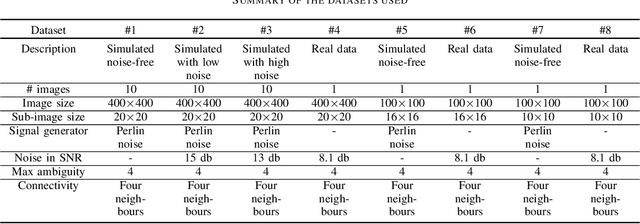
The focus of this work is to explore the use of quantum annealing solvers for the problem of phase unwrapping of synthetic aperture radar (SAR) images. Although solutions to this problem exist based on network programming, these techniques do not scale well to larger-sized images. Our approach involves formulating the problem as a quadratic unconstrained binary optimization (QUBO) problem, which can be solved using a quantum annealer. Given that present embodiments of quantum annealers remain limited in the number of qubits they possess, we decompose the problem into a set of subproblems that can be solved individually. These individual solutions are close to optimal up to an integer constant, with one constant per sub-image. In a second phase, these integer constants are determined as a solution to yet another QUBO problem. We test our approach with a variety of software-based QUBO solvers and on a variety of images, both synthetic and real. Additionally, we experiment using D-Wave Systems's quantum annealer, the D-Wave 2000Q. The software-based solvers obtain high-quality solutions comparable to state-of-the-art phase-unwrapping solvers. We are currently working on optimally mapping the problem onto the restricted topology of the quantum annealer to improve the quality of the solution.
Representativity and Consistency Measures for Deep Neural Network Explanations
Sep 07, 2020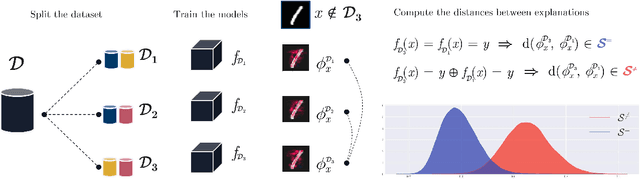
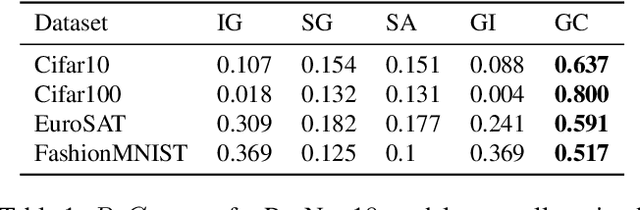
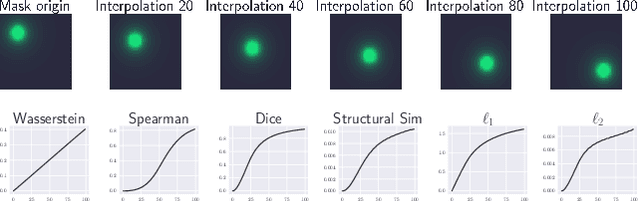
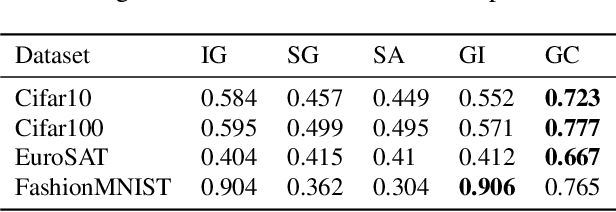
The adoption of machine learning in critical contexts requires a reliable explanation of why the algorithm makes certain predictions. To address this issue, many methods have been proposed to explain the predictions of these black box models. Despite the choice of those many methods, little effort has been made to ensure that the explanations produced are objectively relevant. While it is possible to establish a number of desirable properties of a good explanation, it is more difficult to evaluate them. As a result, no measures are actually associated with the properties of consistency and generalization of explanations. We are introducing a new procedure to compute two new measures, Relative Consistency ReCo and Mean Generalization M eGe, respectively for consistency and generalization of explanations. Our results on several image classification datasets using progressively degraded models allow us to validate empirically the reliability of those measures. We compare the results obtained with those of existing measures. Finally we demonstrate the potential of the measures by applying them to different families of models, revealing an interesting link between gradient-based explanations methods and 1-Lipschitz networks.
Pixel-wise Conditioning of Generative Adversarial Networks
Nov 02, 2019
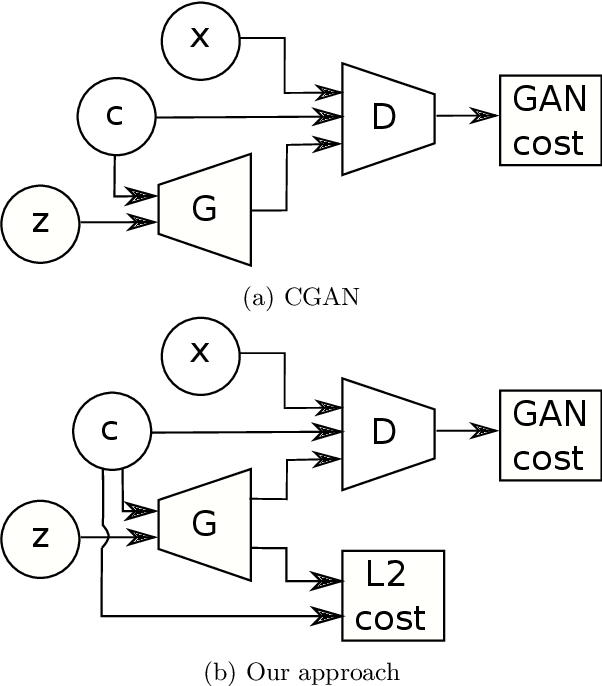
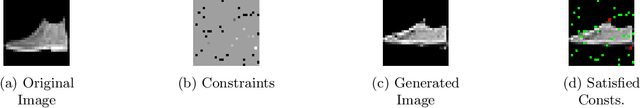
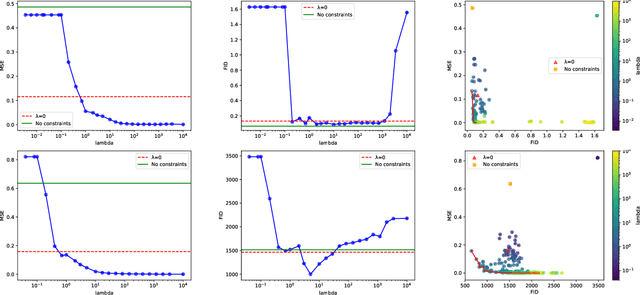
Generative Adversarial Networks (GANs) have proven successful for unsupervised image generation. Several works extended GANs to image inpainting by conditioning the generation with parts of the image one wants to reconstruct. However, these methods have limitations in settings where only a small subset of the image pixels is known beforehand. In this paper, we study the effectiveness of conditioning GANs by adding an explicit regularization term to enforce pixel-wise conditions when very few pixel values are provided. In addition, we also investigate the influence of this regularization term on the quality of the generated images and the satisfaction of the conditions. Conducted experiments on MNIST and FashionMNIST show evidence that this regularization term allows for controlling the trade-off between quality of the generated images and constraint satisfaction.
Grading the Severity of Arteriolosclerosis from Retinal Arterio-venous Crossing Patterns
Nov 07, 2020
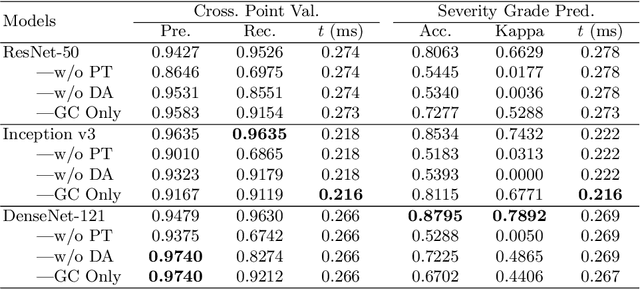
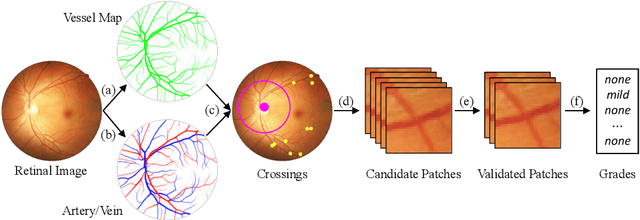
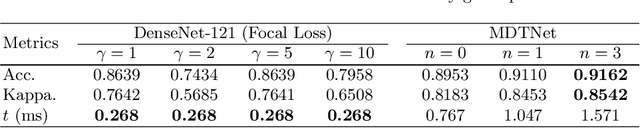
The status of retinal arteriovenous crossing is of great significance for clinical evaluation of arteriolosclerosis and systemic hypertension. As an ophthalmology diagnostic criteria, Scheie's classification has been used to grade the severity of arteriolosclerosis. In this paper, we propose a deep learning approach to support the diagnosis process, which, to the best of our knowledge, is one of the earliest attempts in medical imaging. The proposed pipeline is three-fold. First, we adopt segmentation and classification models to automatically obtain vessels in a retinal image with the corresponding artery/vein labels and find candidate arteriovenous crossing points. Second, we use a classification model to validate the true crossing point. At last, the grade of severity for the vessel crossings is classified. To better address the problem of label ambiguity and imbalanced label distribution, we propose a new model, named multi-diagnosis team network (MDTNet), in which the sub-models with different structures or different loss functions provide different decisions. MDTNet unifies these diverse theories to give the final decision with high accuracy. Our severity grading method was able to validate crossing points with precision and recall of 96.3% and 96.3%, respectively. Among correctly detected crossing points, the kappa value for the agreement between the grading by a retina specialist and the estimated score was 0.85, with an accuracy of 0.92. The numerical results demonstrate that our method can achieve a good performance in both arteriovenous crossing validation and severity grading tasks. By the proposed models, we could build a pipeline reproducing retina specialist's subjective grading without feature extractions. The code is available for reproducibility.
Improving the Evaluation of Generative Models with Fuzzy Logic
Feb 03, 2020
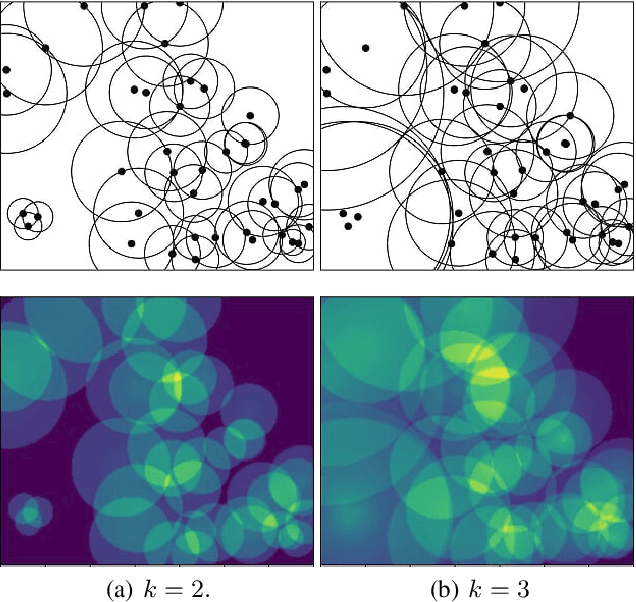
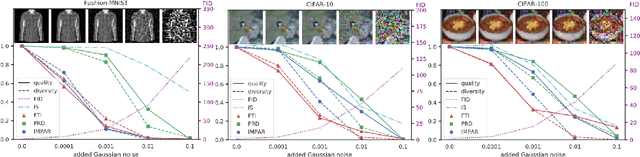
Objective and interpretable metrics to evaluate current artificial intelligent systems are of great importance, not only to analyze the current state of such systems but also to objectively measure progress in the future. In this work, we focus on the evaluation of image generation tasks. We propose a novel approach, called Fuzzy Topology Impact (FTI), that determines both the quality and diversity of an image set using topology representations combined with fuzzy logic. When compared to current evaluation methods, FTI shows better and more stable performance on multiple experiments evaluating the sensitivity to noise, mode dropping and mode inventing.
Supervised Segmentation of Retinal Vessel Structures Using ANN
Jan 15, 2020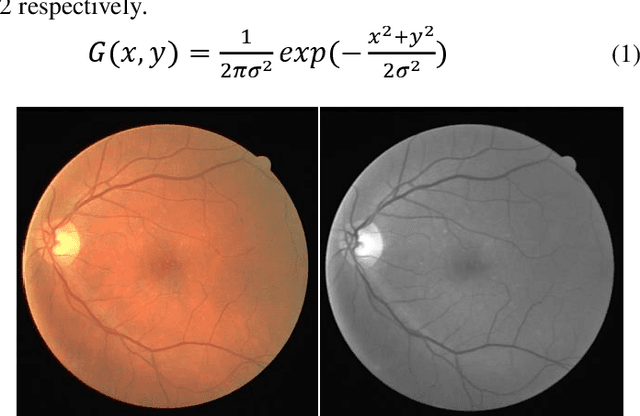
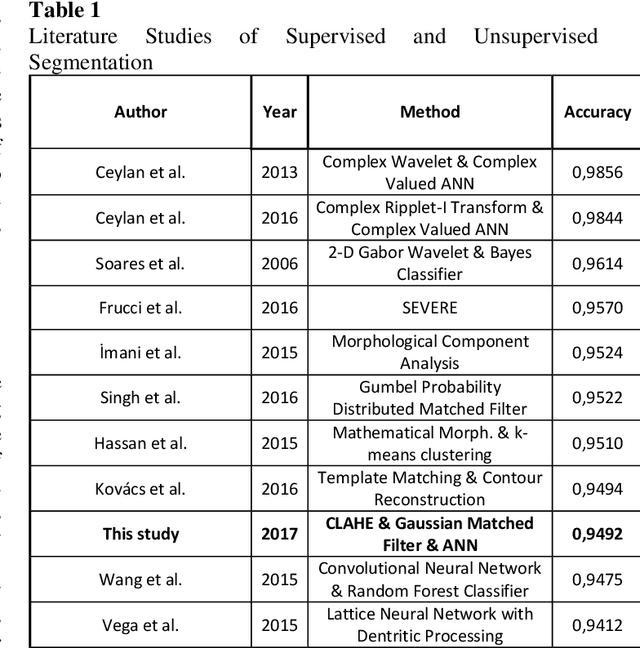
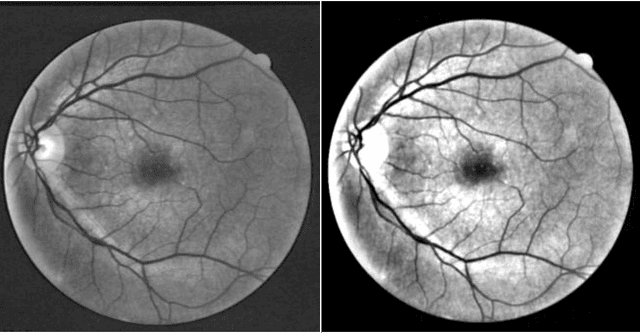
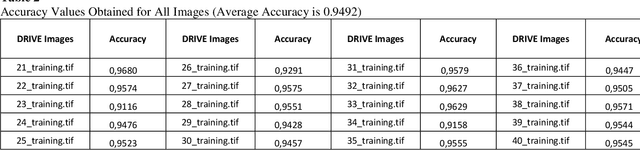
In this study, a supervised retina blood vessel segmentation process was performed on the green channel of the RGB image using artificial neural network (ANN). The green channel is preferred because the retinal vessel structures can be distinguished most clearly from the green channel of the RGB image. The study was performed using 20 images in the DRIVE data set which is one of the most common retina data sets known. The images went through some preprocessing stages like contrastlimited adaptive histogram equalization (CLAHE), color intensity adjustment, morphological operations and median and Gaussian filtering to obtain a good segmentation. Retinal vessel structures were highlighted with top-hat and bot-hat morphological operations and converted to binary image by using global thresholding. Then, the network was trained by the binary version of the images specified as training images in the dataset and the targets are the images segmented manually by a specialist. The average segmentation accuracy for 20 images was found as 0.9492.
Towards Faithful and Meaningful Interpretable Representations
Aug 16, 2020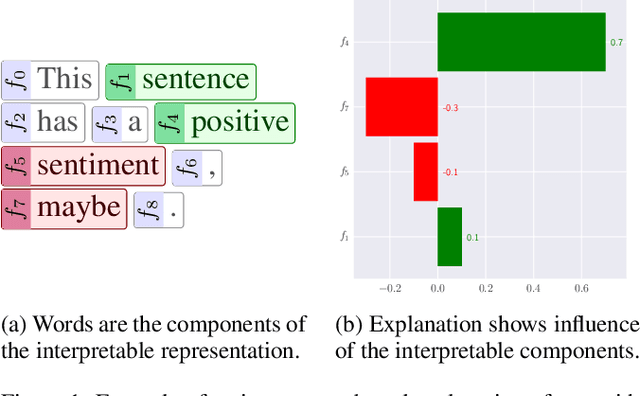
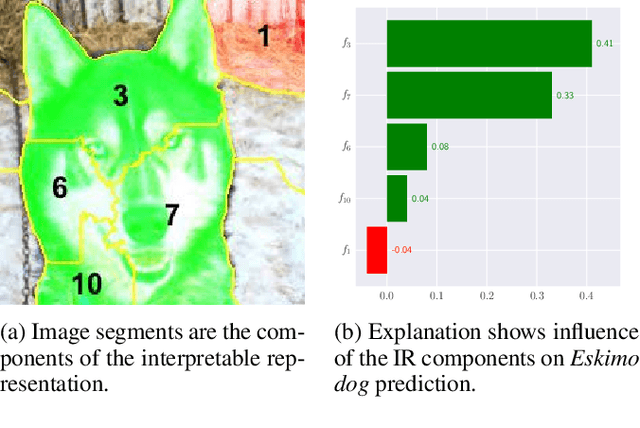

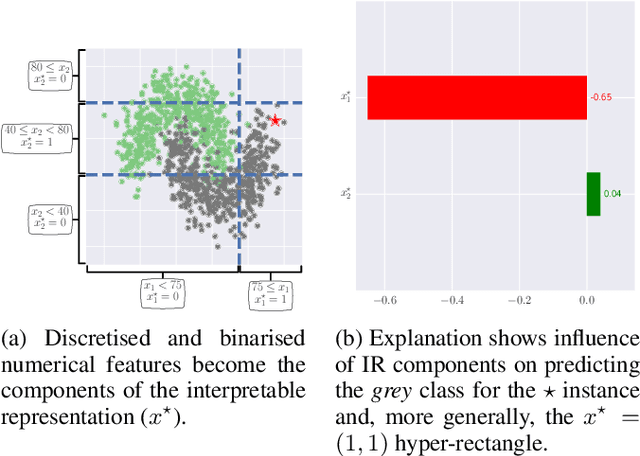
Interpretable representations are the backbone of many black-box explainers. They translate the low-level data representation necessary for good predictive performance into high-level human-intelligible concepts used to convey the explanation. Notably, the explanation type and its cognitive complexity are directly controlled by the interpretable representation, allowing to target a particular audience and use case. However, many explainers that rely on interpretable representations overlook their merit and fall back on default solutions, which may introduce implicit assumptions, thereby degrading the explanatory power of such techniques. To address this problem, we study properties of interpretable representations that encode presence and absence of human-comprehensible concepts. We show how they are operationalised for tabular, image and text data, discussing their strengths and weaknesses. Finally, we analyse their explanatory properties in the context of tabular data, where a linear model is used to quantify the importance of interpretable concepts.
Loss-rescaling VQA: Revisiting Language Prior Problem from a Class-imbalance View
Oct 30, 2020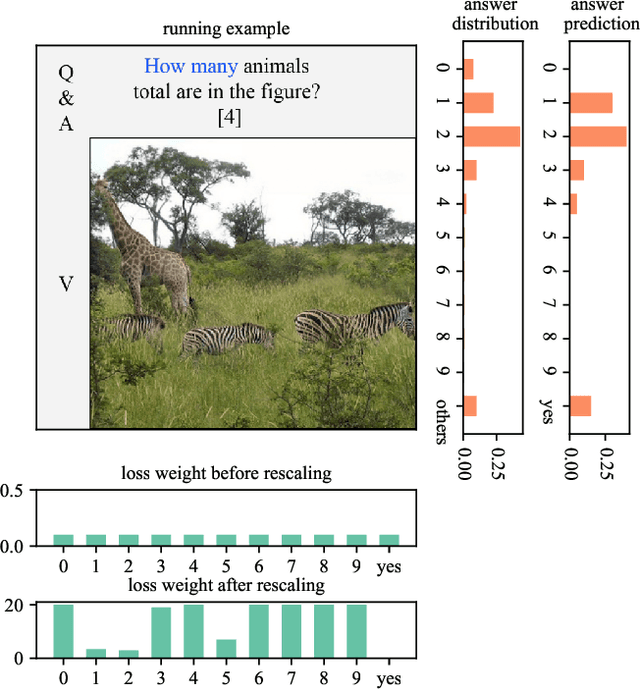
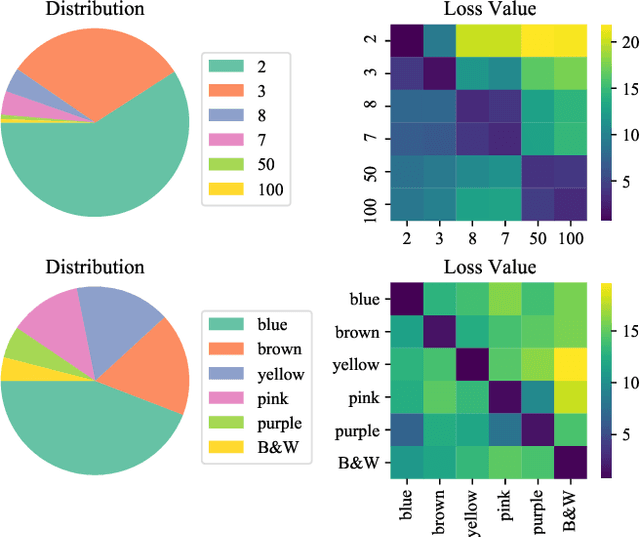
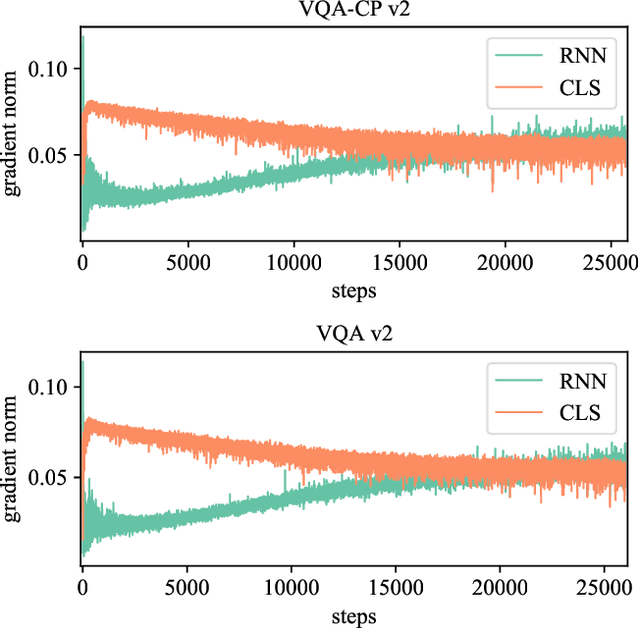
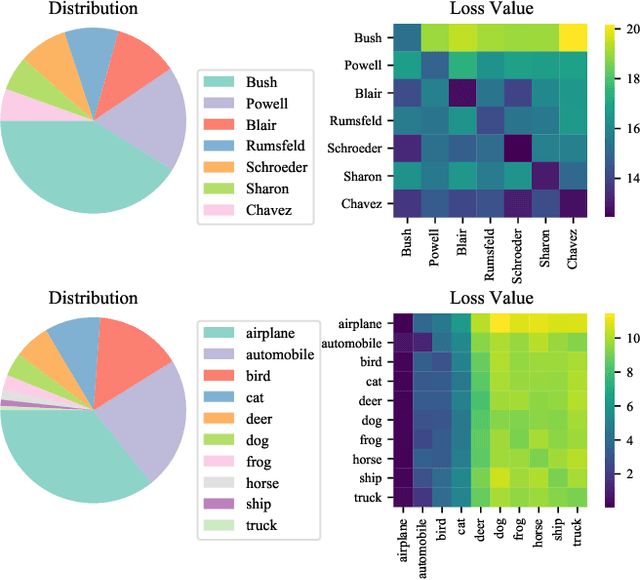
Recent studies have pointed out that many well-developed Visual Question Answering (VQA) models are heavily affected by the language prior problem, which refers to making predictions based on the co-occurrence pattern between textual questions and answers instead of reasoning visual contents. To tackle it, most existing methods focus on enhancing visual feature learning to reduce this superficial textual shortcut influence on VQA model decisions. However, limited effort has been devoted to providing an explicit interpretation for its inherent cause. It thus lacks a good guidance for the research community to move forward in a purposeful way, resulting in model construction perplexity in overcoming this non-trivial problem. In this paper, we propose to interpret the language prior problem in VQA from a class-imbalance view. Concretely, we design a novel interpretation scheme whereby the loss of mis-predicted frequent and sparse answers of the same question type is distinctly exhibited during the late training phase. It explicitly reveals why the VQA model tends to produce a frequent yet obviously wrong answer, to a given question whose right answer is sparse in the training set. Based upon this observation, we further develop a novel loss re-scaling approach to assign different weights to each answer based on the training data statistics for computing the final loss. We apply our approach into three baselines and the experimental results on two VQA-CP benchmark datasets evidently demonstrate its effectiveness. In addition, we also justify the validity of the class imbalance interpretation scheme on other computer vision tasks, such as face recognition and image classification.
SynCGAN: Using learnable class specific priors to generate synthetic data for improving classifier performance on cytological images
Mar 12, 2020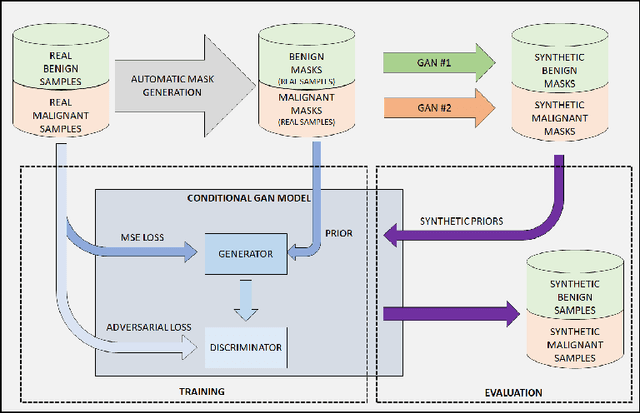

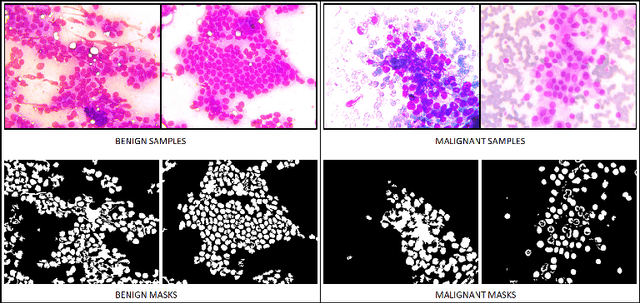

One of the most challenging aspects of medical image analysis is the lack of a high quantity of annotated data. This makes it difficult for deep learning algorithms to perform well due to a lack of variations in the input space. While generative adversarial networks have shown promise in the field of synthetic data generation, but without a carefully designed prior the generation procedure can not be performed well. In the proposed approach we have demonstrated the use of automatically generated segmentation masks as learnable class-specific priors to guide a conditional GAN for the generation of patho-realistic samples for cytology image. We have observed that augmentation of data using the proposed pipeline called "SynCGAN" improves the performance of state of the art classifiers such as ResNet-152, DenseNet-161, Inception-V3 significantly.
Unsupervised Domain Adaptation through Inter-modal Rotation for RGB-D Object Recognition
Apr 21, 2020
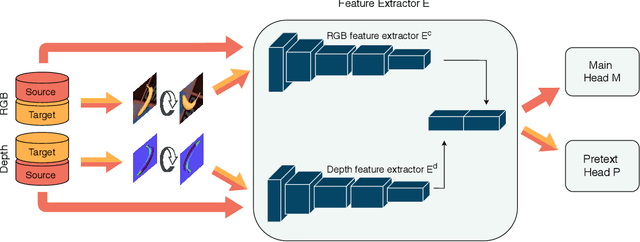


Unsupervised Domain Adaptation (DA) exploits the supervision of a label-rich source dataset to make predictions on an unlabeled target dataset by aligning the two data distributions. In robotics, DA is used to take advantage of automatically generated synthetic data, that come with "free" annotation, to make effective predictions on real data. However, existing DA methods are not designed to cope with the multi-modal nature of RGB-D data, which are widely used in robotic vision. We propose a novel RGB-D DA method that reduces the synthetic-to-real domain shift by exploiting the inter-modal relation between the RGB and depth image. Our method consists of training a convolutional neural network to solve, in addition to the main recognition task, the pretext task of predicting the relative rotation between the RGB and depth image. To evaluate our method and encourage further research in this area, we define two benchmark datasets for object categorization and instance recognition. With extensive experiments, we show the benefits of leveraging the inter-modal relations for RGB-D DA.