 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Controllable Disentangled Representations with Decorrelation Regularization
Dec 25, 2019
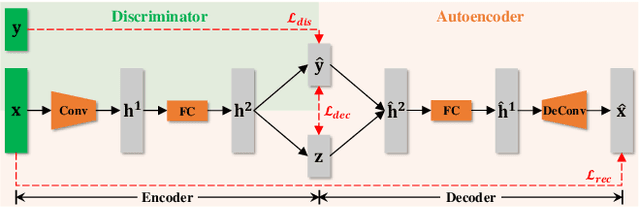
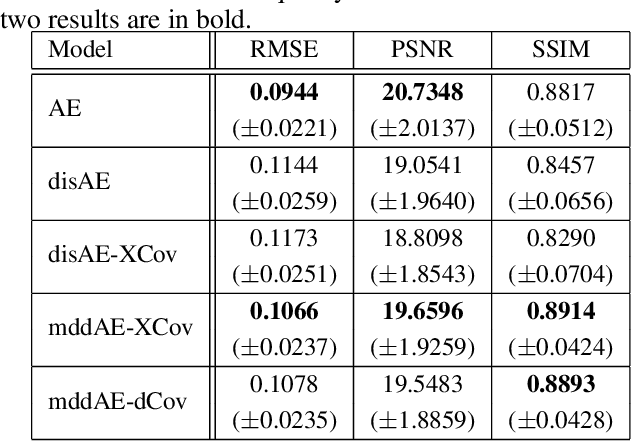
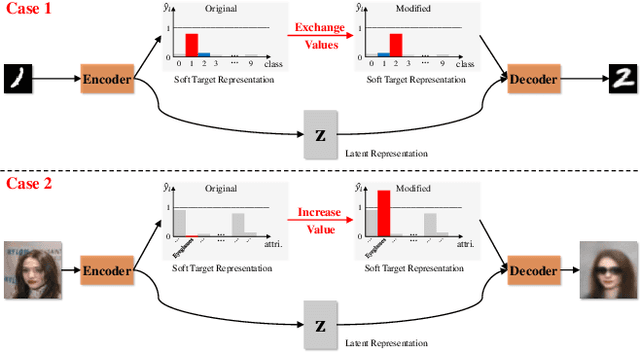
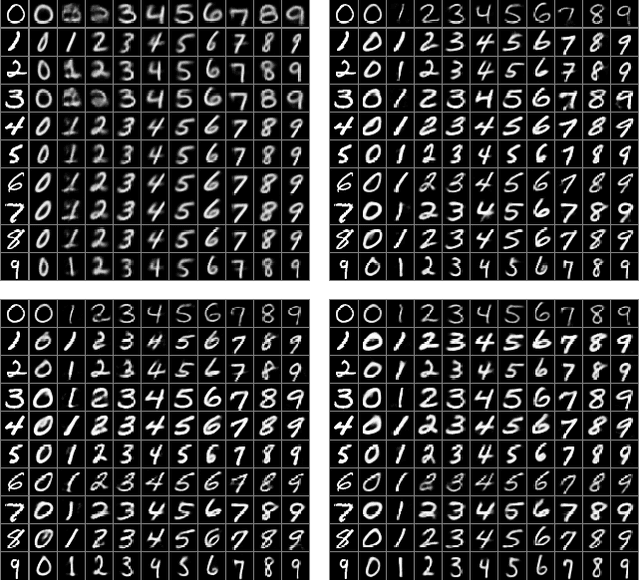
A crucial problem in learning disentangled image representations is controlling the degree of disentanglement during image editing, while preserving the identity of objects. In this work, we propose a simple yet effective model with the encoder-decoder architecture to address this challenge. To encourage disentanglement, we devise a distance covariance based decorrelation regularization. Further, for the reconstruction step, our model leverages a soft target representation combined with the latent image code. By exploiting the real-valued space of the soft target representations, we are able to synthesize novel images with the designated properties. We also design a classification based protocol to quantitatively evaluate the disentanglement strength of our model. Experimental results show that the proposed model competently disentangles factors of variation, and is able to manipulate face images to synthesize the desired attributes.
Sketchformer: Transformer-based Representation for Sketched Structure
Feb 24, 2020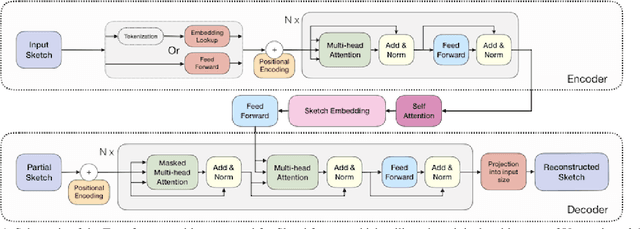
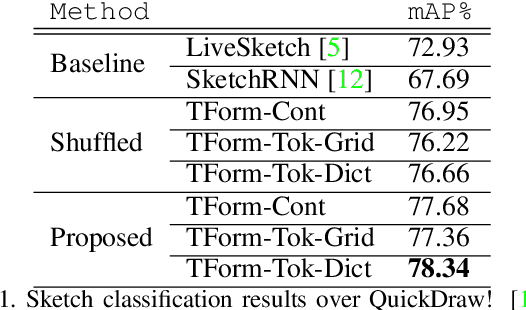
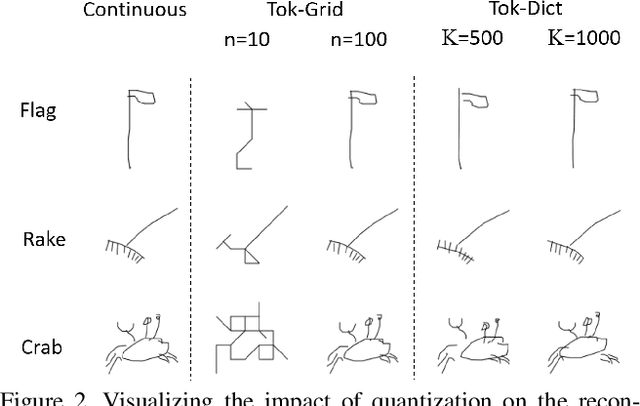
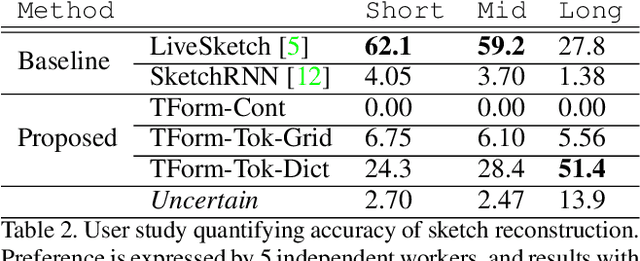
Sketchformer is a novel transformer-based representation for encoding free-hand sketches input in a vector form, i.e. as a sequence of strokes. Sketchformer effectively addresses multiple tasks: sketch classification, sketch based image retrieval (SBIR), and the reconstruction and interpolation of sketches. We report several variants exploring continuous and tokenized input representations, and contrast their performance. Our learned embedding, driven by a dictionary learning tokenization scheme, yields state of the art performance in classification and image retrieval tasks, when compared against baseline representations driven by LSTM sequence to sequence architectures: SketchRNN and derivatives. We show that sketch reconstruction and interpolation are improved significantly by the Sketchformer embedding for complex sketches with longer stroke sequences.
On Connections between Regularizations for Improving DNN Robustness
Jul 04, 2020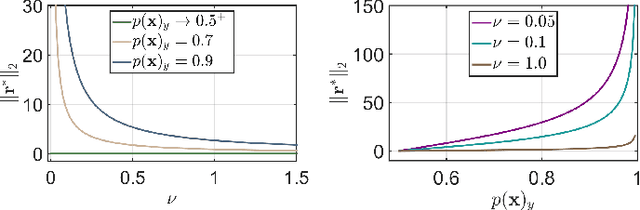
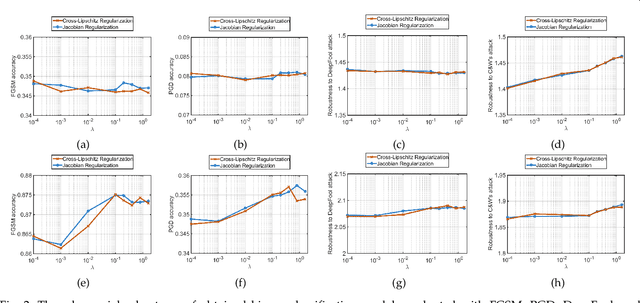
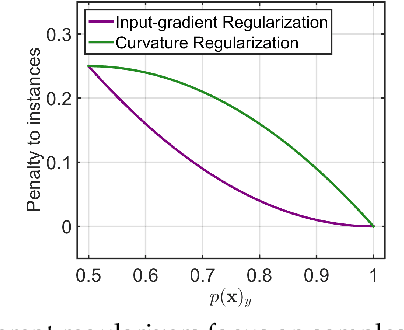
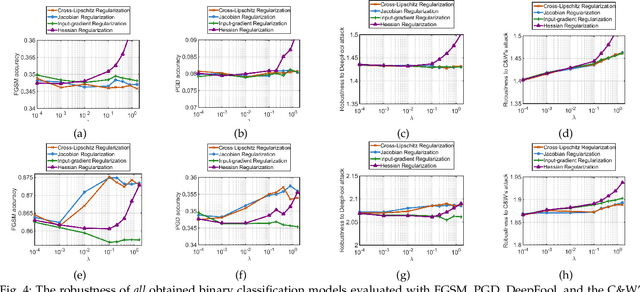
This paper analyzes regularization terms proposed recently for improving the adversarial robustness of deep neural networks (DNNs), from a theoretical point of view. Specifically, we study possible connections between several effective methods, including input-gradient regularization, Jacobian regularization, curvature regularization, and a cross-Lipschitz functional. We investigate them on DNNs with general rectified linear activations, which constitute one of the most prevalent families of models for image classification and a host of other machine learning applications. We shed light on essential ingredients of these regularizations and re-interpret their functionality. Through the lens of our study, more principled and efficient regularizations can possibly be invented in the near future.
Rethinking Softmax with Cross-Entropy: Neural Network Classifier as Mutual Information Estimator
Nov 25, 2019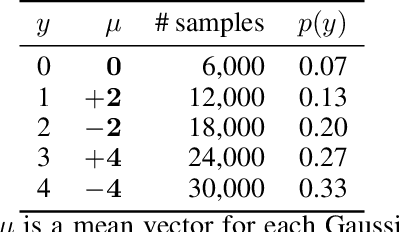
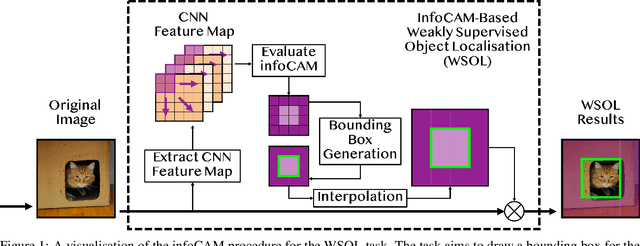
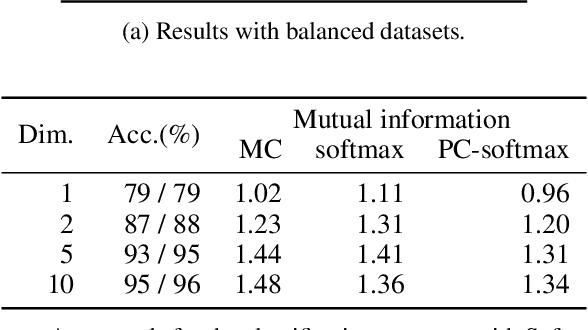

Mutual information is widely applied to learn latent representations of observations, whilst its implication in classification neural networks remain to be better explained. In this paper, we show that optimising the parameters of classification neural networks with softmax cross-entropy is equivalent to maximising the mutual information between inputs and labels under the balanced data assumption. Through the experiments on synthetic and real datasets, we show that softmax cross-entropy can estimate mutual information approximately. When applied to image classification, this relation helps approximate the point-wise mutual information between an input image and a label without modifying the network structure. In this end, we propose infoCAM, informative class activation map, which highlights regions of the input image that are the most relevant to a given label based on differences in information. The activation map helps localise the target object in an image. Through the experiments on the semi-supervised object localisation task with two real-world datasets, we evaluate the effectiveness of the information-theoretic approach.
Brain Tumor Segmentation by Cascaded Deep Neural Networks Using Multiple Image Scales
Feb 05, 2020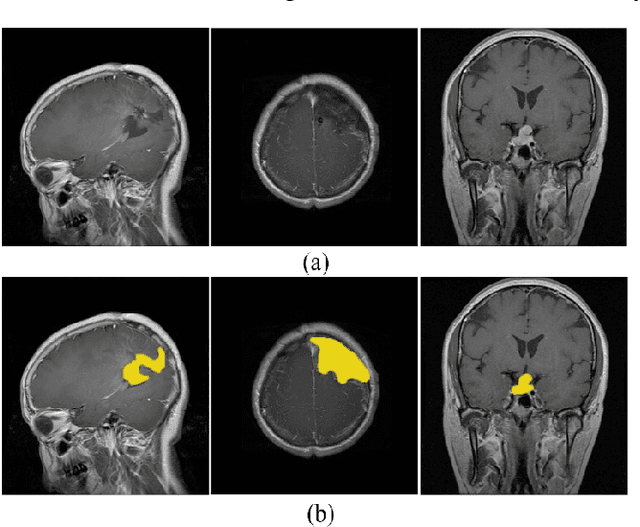
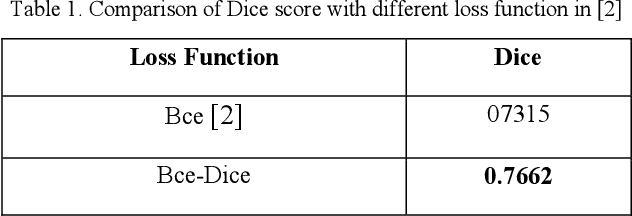
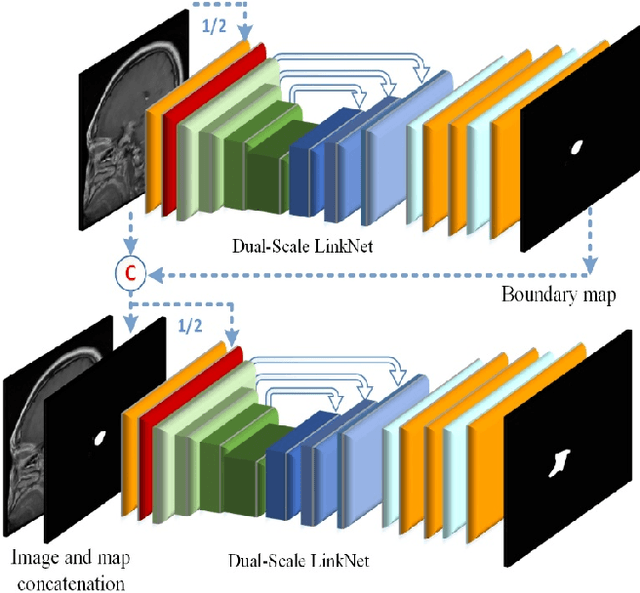
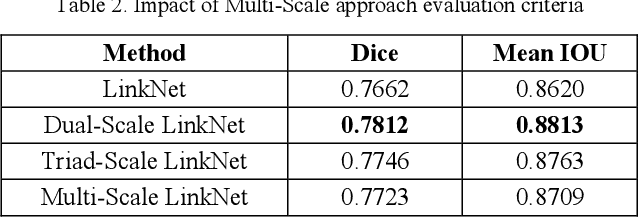
Intracranial tumors are groups of cells that usually grow uncontrollably. One out of four cancer deaths is due to brain tumors. Early detection and evaluation of brain tumors is an essential preventive medical step that is performed by magnetic resonance imaging (MRI). Many segmentation techniques exist for this purpose. Low segmentation accuracy is the main drawback of existing methods. In this paper, we use a deep learning method to boost the accuracy of tumor segmentation in MR images. Cascade approach is used with multiple scales of images to induce both local and global views and help the network to reach higher accuracies. Our experimental results show that using multiple scales and the utilization of two cascade networks is advantageous.
Understanding Integrated Gradients with SmoothTaylor for Deep Neural Network Attribution
Apr 22, 2020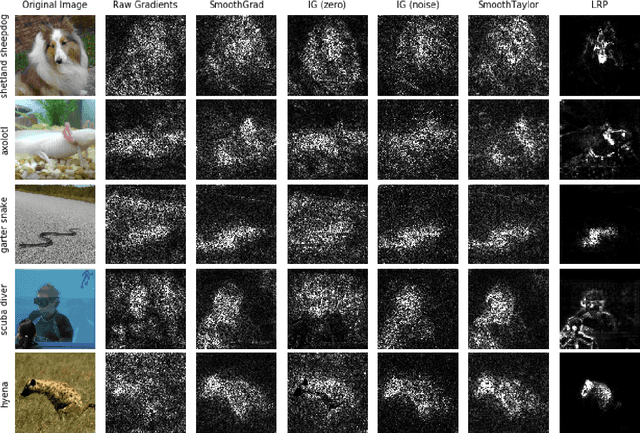
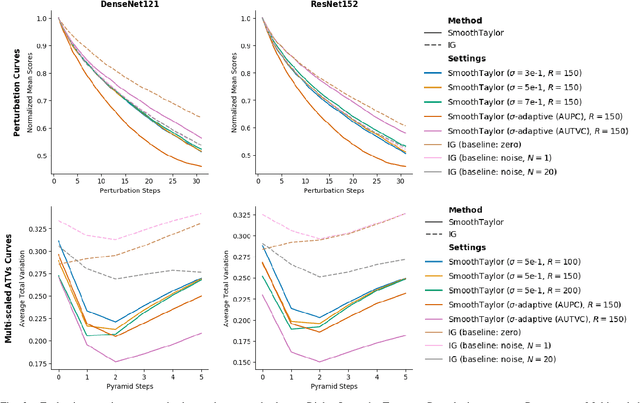
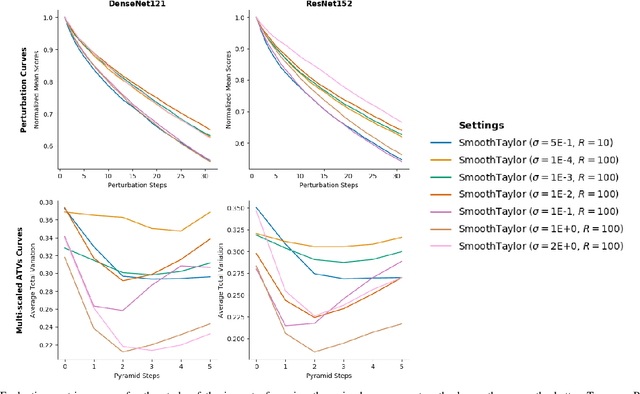
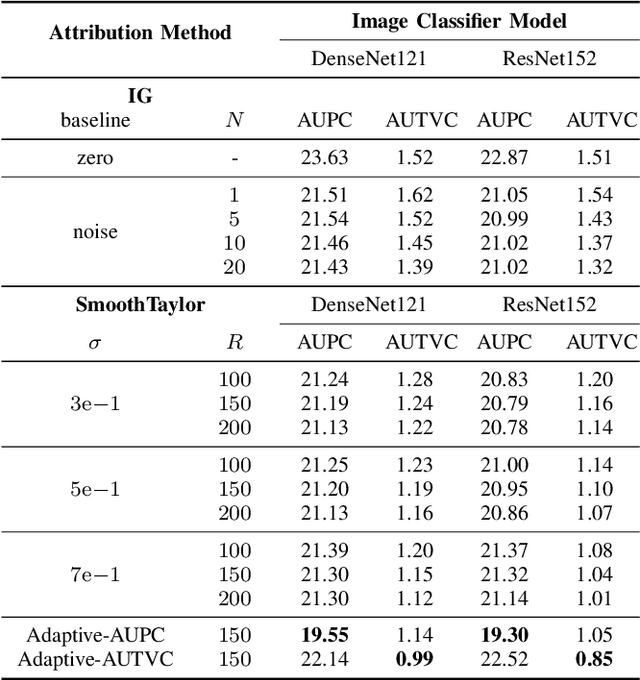
Integrated gradients as an attribution method for deep neural network models offers simple implementability. However, it also suffers from noisiness of explanations, which affects the ease of interpretability. In this paper, we present Smooth Integrated Gradients as a statistically improved attribution method inspired by Taylor's theorem, which does not require a fixed baseline to be chosen. We apply both methods to the image classification problem, using the ILSVRC2012 ImageNet object recognition dataset, and a couple of pretrained image models to generate attribution maps of their predictions. These attribution maps are visualized by saliency maps which can be evaluated qualitatively. We also empirically evaluate them using quantitative metrics such as perturbations-based score drops and multi-scaled total variance. We further propose adaptive noising to optimize for the noise scale hyperparameter value in our proposed method. From our experiments, we find that the Smooth Integrated Gradients approach together with adaptive noising is able to generate better quality saliency maps with lesser noise and higher sensitivity to the relevant points in the input space.
Towards Faithful and Meaningful Interpretable Representations
Aug 16, 2020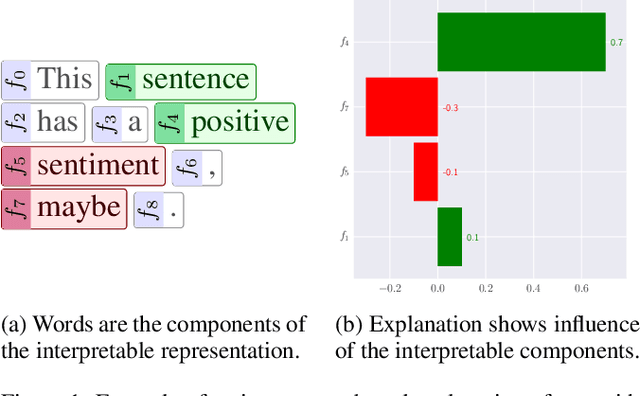
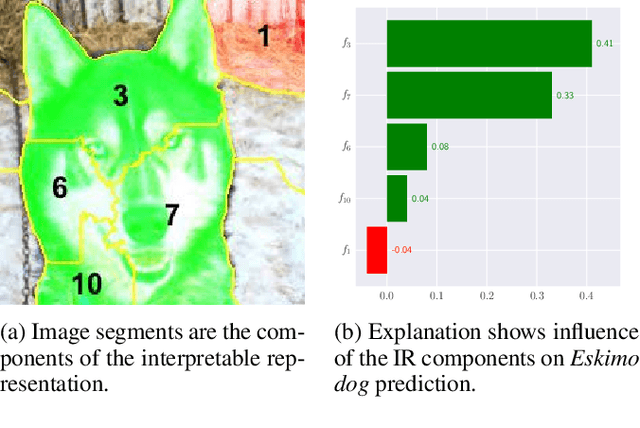

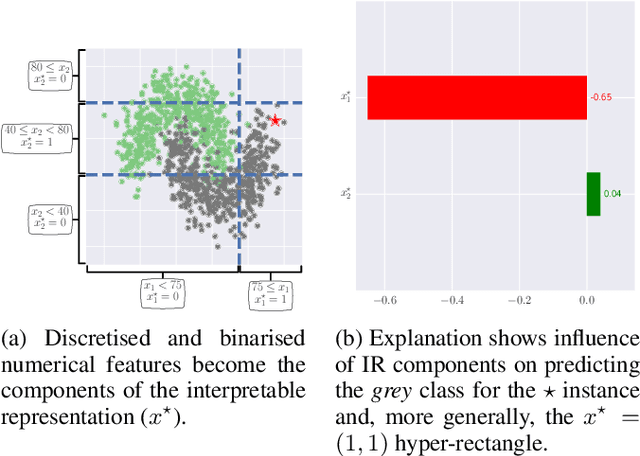
Interpretable representations are the backbone of many black-box explainers. They translate the low-level data representation necessary for good predictive performance into high-level human-intelligible concepts used to convey the explanation. Notably, the explanation type and its cognitive complexity are directly controlled by the interpretable representation, allowing to target a particular audience and use case. However, many explainers that rely on interpretable representations overlook their merit and fall back on default solutions, which may introduce implicit assumptions, thereby degrading the explanatory power of such techniques. To address this problem, we study properties of interpretable representations that encode presence and absence of human-comprehensible concepts. We show how they are operationalised for tabular, image and text data, discussing their strengths and weaknesses. Finally, we analyse their explanatory properties in the context of tabular data, where a linear model is used to quantify the importance of interpretable concepts.
Pareto-depth for Multiple-query Image Retrieval
Feb 21, 2014
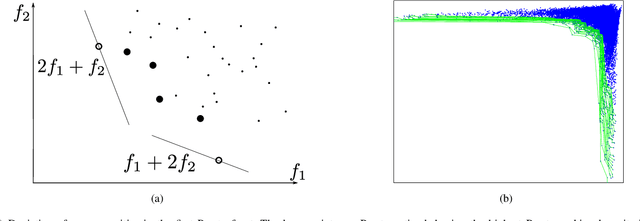
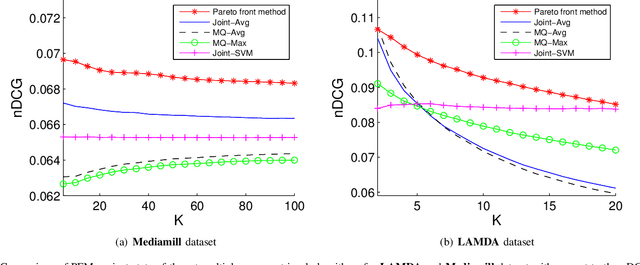
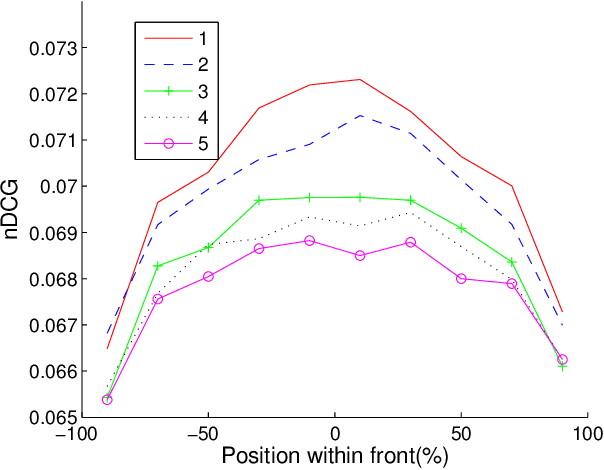
Most content-based image retrieval systems consider either one single query, or multiple queries that include the same object or represent the same semantic information. In this paper we consider the content-based image retrieval problem for multiple query images corresponding to different image semantics. We propose a novel multiple-query information retrieval algorithm that combines the Pareto front method (PFM) with efficient manifold ranking (EMR). We show that our proposed algorithm outperforms state of the art multiple-query retrieval algorithms on real-world image databases. We attribute this performance improvement to concavity properties of the Pareto fronts, and prove a theoretical result that characterizes the asymptotic concavity of the fronts.
DVERGE: Diversifying Vulnerabilities for Enhanced Robust Generation of Ensembles
Sep 30, 2020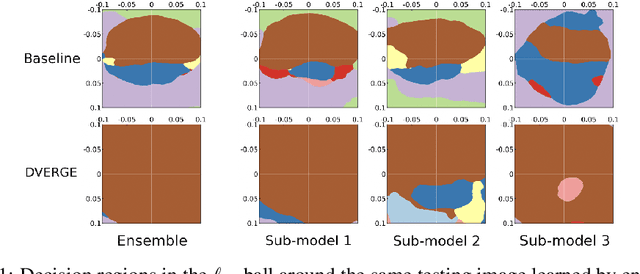

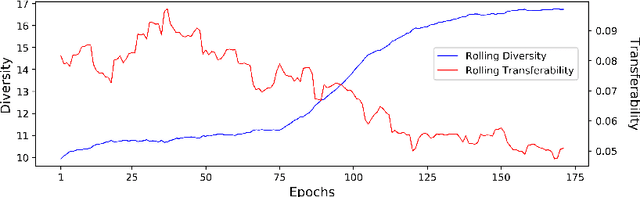

Recent research finds CNN models for image classification demonstrate overlapped adversarial vulnerabilities: adversarial attacks can mislead CNN models with small perturbations, which can effectively transfer between different models trained on the same dataset. Adversarial training, as a general robustness improvement technique, eliminates the vulnerability in a single model by forcing it to learn robust features. The process is hard, often requires models with large capacity, and suffers from significant loss on clean data accuracy. Alternatively, ensemble methods are proposed to induce sub-models with diverse outputs against a transfer adversarial example, making the ensemble robust against transfer attacks even if each sub-model is individually non-robust. Only small clean accuracy drop is observed in the process. However, previous ensemble training methods are not efficacious in inducing such diversity and thus ineffective on reaching robust ensemble. We propose DVERGE, which isolates the adversarial vulnerability in each sub-model by distilling non-robust features, and diversifies the adversarial vulnerability to induce diverse outputs against a transfer attack. The novel diversity metric and training procedure enables DVERGE to achieve higher robustness against transfer attacks comparing to previous ensemble methods, and enables the improved robustness when more sub-models are added to the ensemble.
A Bayesian Hyperprior Approach for Joint Image Denoising and Interpolation, with an Application to HDR Imaging
Jun 10, 2017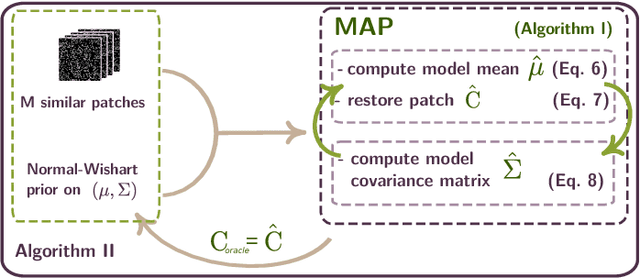



Recently, impressive denoising results have been achieved by Bayesian approaches which assume Gaussian models for the image patches. This improvement in performance can be attributed to the use of per-patch models. Unfortunately such an approach is particularly unstable for most inverse problems beyond denoising. In this work, we propose the use of a hyperprior to model image patches, in order to stabilize the estimation procedure. There are two main advantages to the proposed restoration scheme: Firstly it is adapted to diagonal degradation matrices, and in particular to missing data problems (e.g. inpainting of missing pixels or zooming). Secondly it can deal with signal dependent noise models, particularly suited to digital cameras. As such, the scheme is especially adapted to computational photography. In order to illustrate this point, we provide an application to high dynamic range imaging from a single image taken with a modified sensor, which shows the effectiveness of the proposed scheme.