 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Contrastive Clustering
Sep 21, 2020
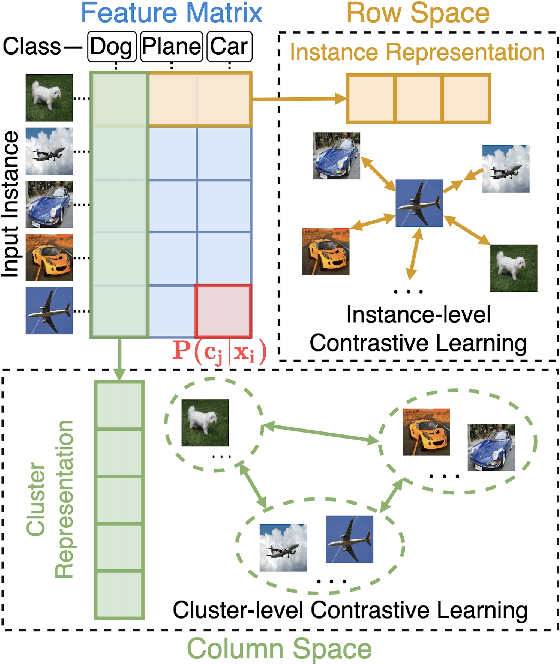
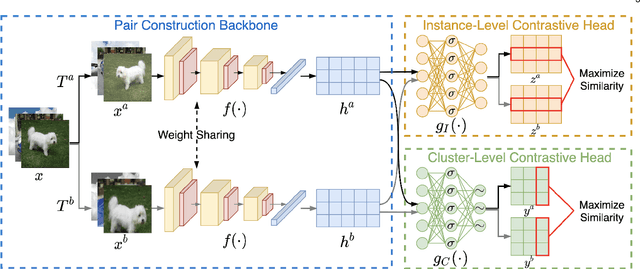
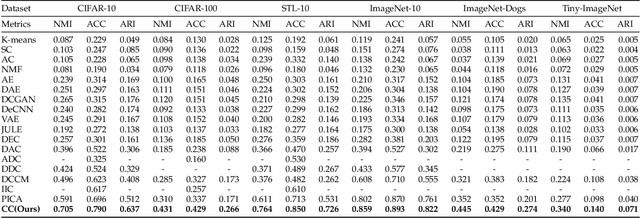
In this paper, we propose a one-stage online clustering method called Contrastive Clustering (CC) which explicitly performs the instance- and cluster-level contrastive learning. To be specific, for a given dataset, the positive and negative instance pairs are constructed through data augmentations and then projected into a feature space. Therein, the instance- and cluster-level contrastive learning are respectively conducted in the row and column space by maximizing the similarities of positive pairs while minimizing those of negative ones. Our key observation is that the rows of the feature matrix could be regarded as soft labels of instances, and accordingly the columns could be further regarded as cluster representations. By simultaneously optimizing the instance- and cluster-level contrastive loss, the model jointly learns representations and cluster assignments in an end-to-end manner. Extensive experimental results show that CC remarkably outperforms 17 competitive clustering methods on six challenging image benchmarks. In particular, CC achieves an NMI of 0.705 (0.431) on the CIFAR-10 (CIFAR-100) dataset, which is an up to 19\% (39\%) performance improvement compared with the best baseline.
Natural Image Manipulation for Autoregressive Models Using Fisher Scores
Nov 25, 2019



Deep autoregressive models are one of the most powerful models that exist today which achieve state-of-the-art bits per dim. However, they lie at a strict disadvantage when it comes to controlled sample generation compared to latent variable models. Latent variable models such as VAEs and normalizing flows allow meaningful semantic manipulations in latent space, which autoregressive models do not have. In this paper, we propose using Fisher scores as a method to extract embeddings from an autoregressive model to use for interpolation and show that our method provides more meaningful sample manipulation compared to alternate embeddings such as network activations.
Generative Imagination Elevates Machine Translation
Sep 21, 2020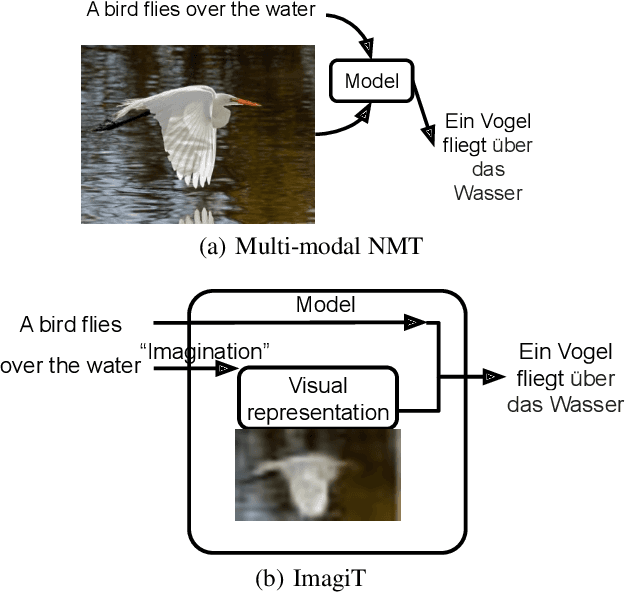
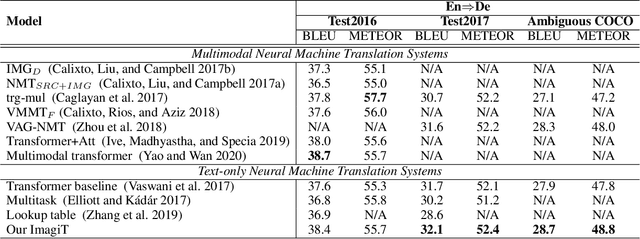
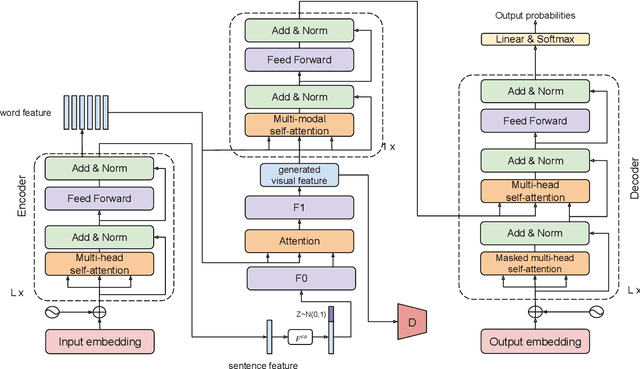
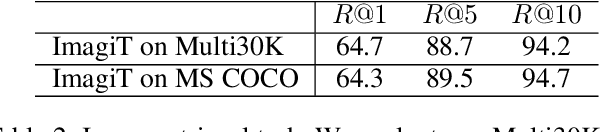
There are thousands of languages on earth, but visual perception is shared among peoples. Existing multimodal neural machine translation (MNMT) methods achieve knowledge transfer by enforcing one encoder to learn shared representation across textual and visual modalities. However, the training and inference process heavily relies on well-aligned bilingual sentence - image triplets as input, which are often limited in quantity. In this paper, we hypothesize that visual imagination via synthesizing visual representation from source text could help the neural model map two languages with different symbols, thus helps the translation task. Our proposed end-to-end imagination-based machine translation model (ImagiT) first learns to generate semantic-consistent visual representation from source sentence, and then generate target sentence based on both text representation and imagined visual representation. Experiments demonstrate that our translation model benefits from visual imagination and significantly outperforms the text-only neural machine translation (NMT) baseline. We also conduct analyzing experiments, and the results show that imagination can help fill in missing information when performing the degradation strategy.
VisCode: Embedding Information in Visualization Images using Encoder-Decoder Network
Sep 07, 2020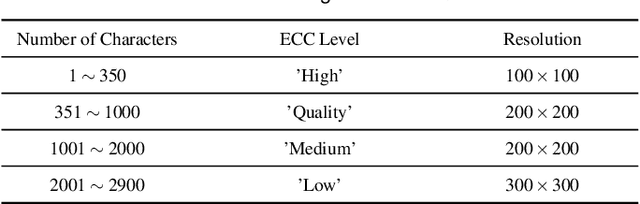
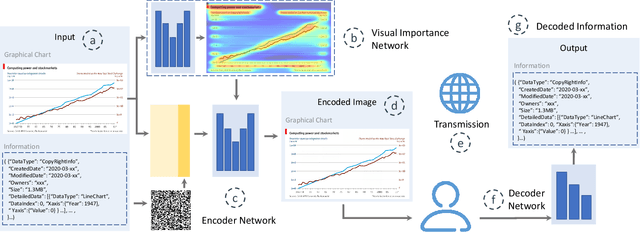
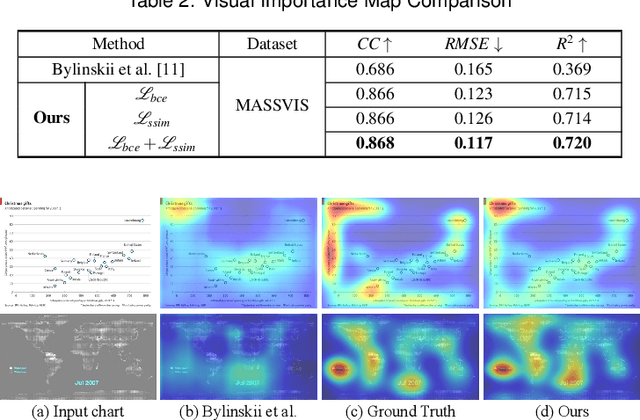
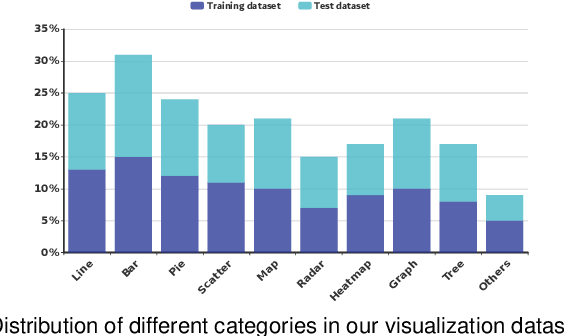
We present an approach called VisCode for embedding information into visualization images. This technology can implicitly embed data information specified by the user into a visualization while ensuring that the encoded visualization image is not distorted. The VisCode framework is based on a deep neural network. We propose to use visualization images and QR codes data as training data and design a robust deep encoder-decoder network. The designed model considers the salient features of visualization images to reduce the explicit visual loss caused by encoding. To further support large-scale encoding and decoding, we consider the characteristics of information visualization and propose a saliency-based QR code layout algorithm. We present a variety of practical applications of VisCode in the context of information visualization and conduct a comprehensive evaluation of the perceptual quality of encoding, decoding success rate, anti-attack capability, time performance, etc. The evaluation results demonstrate the effectiveness of VisCode.
Improving colonoscopy lesion classification using semi-supervised deep learning
Sep 07, 2020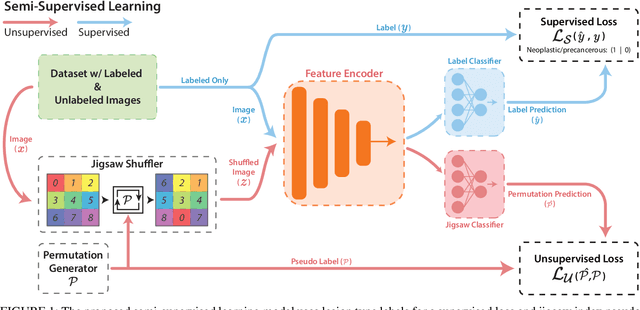
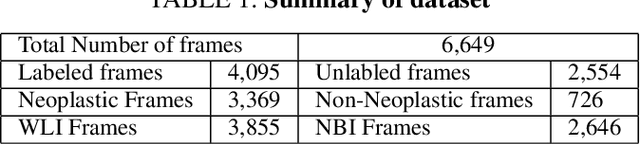
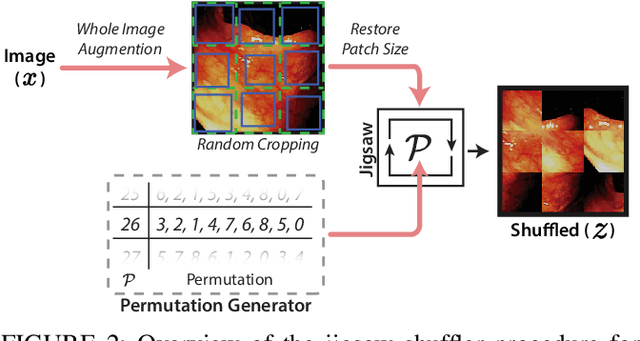

While data-driven approaches excel at many image analysis tasks, the performance of these approaches is often limited by a shortage of annotated data available for training. Recent work in semi-supervised learning has shown that meaningful representations of images can be obtained from training with large quantities of unlabeled data, and that these representations can improve the performance of supervised tasks. Here, we demonstrate that an unsupervised jigsaw learning task, in combination with supervised training, results in up to a 9.8% improvement in correctly classifying lesions in colonoscopy images when compared to a fully-supervised baseline. We additionally benchmark improvements in domain adaptation and out-of-distribution detection, and demonstrate that semi-supervised learning outperforms supervised learning in both cases. In colonoscopy applications, these metrics are important given the skill required for endoscopic assessment of lesions, the wide variety of endoscopy systems in use, and the homogeneity that is typical of labeled datasets.
Cardiac Segmentation with Strong Anatomical Guarantees
Jun 15, 2020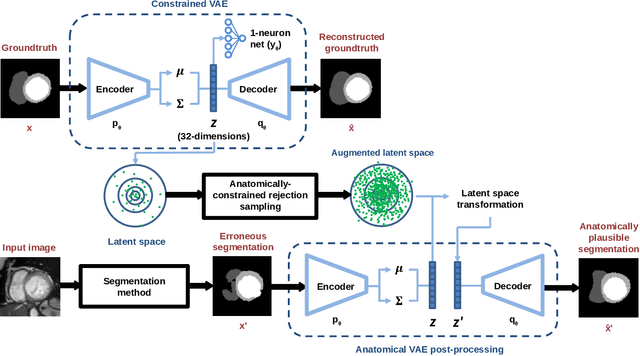
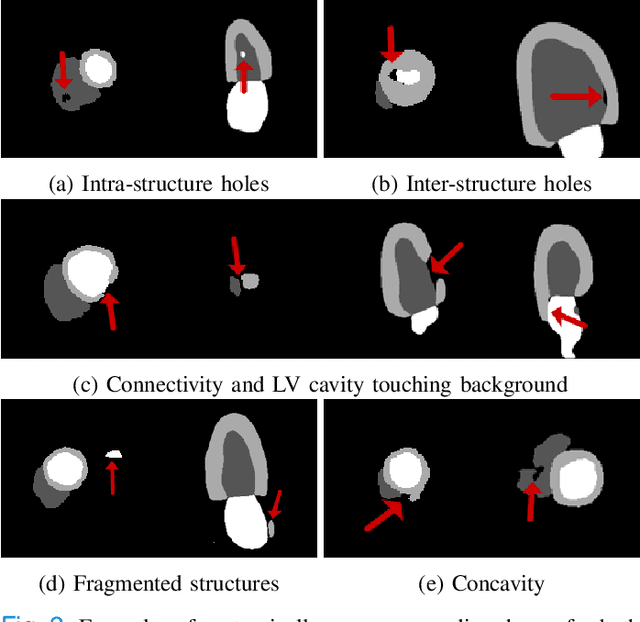
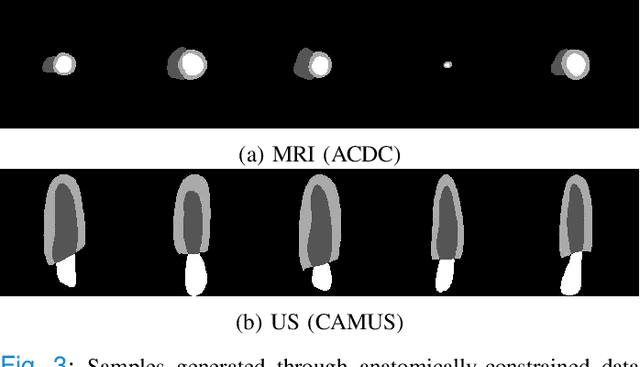
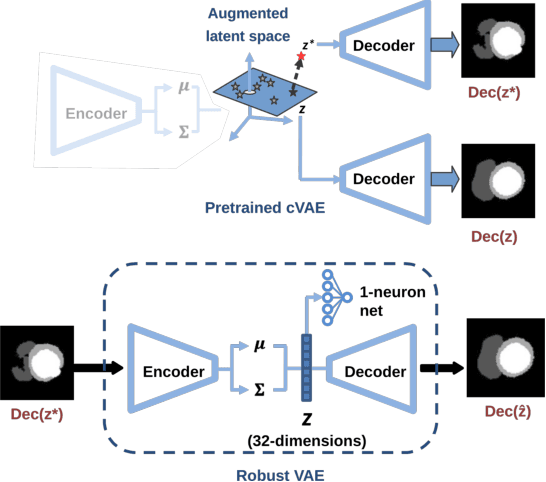
Convolutional neural networks (CNN) have had unprecedented success in medical imaging and, in particular, in medical image segmentation. However, despite the fact that segmentation results are closer than ever to the inter-expert variability, CNNs are not immune to producing anatomically inaccurate segmentations, even when built upon a shape prior. In this paper, we present a framework for producing cardiac image segmentation maps that are guaranteed to respect pre-defined anatomical criteria, while remaining within the inter-expert variability. The idea behind our method is to use a well-trained CNN, have it process cardiac images, identify the anatomically implausible results and warp these results toward the closest anatomically valid cardiac shape. This warping procedure is carried out with a constrained variational autoencoder (cVAE) trained to learn a representation of valid cardiac shapes through a smooth, yet constrained, latent space. With this cVAE, we can project any implausible shape into the cardiac latent space and steer it toward the closest correct shape. We tested our framework on short-axis MRI as well as apical two and four-chamber view ultrasound images, two modalities for which cardiac shapes are drastically different. With our method, CNNs can now produce results that are both within the inter-expert variability and always anatomically plausible without having to rely on a shape prior.
COBRA: Contrastive Bi-Modal Representation Algorithm
May 07, 2020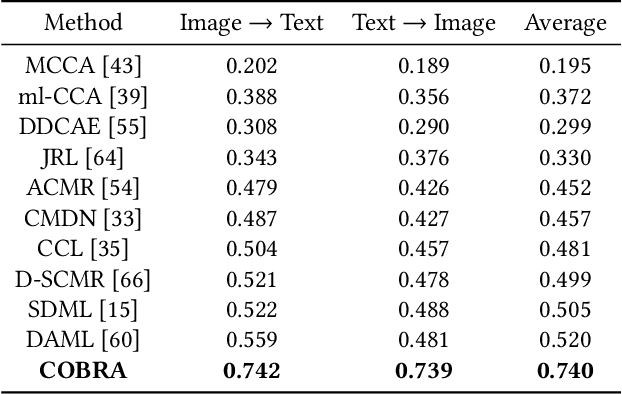
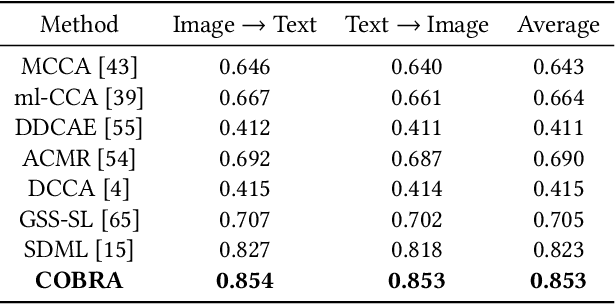
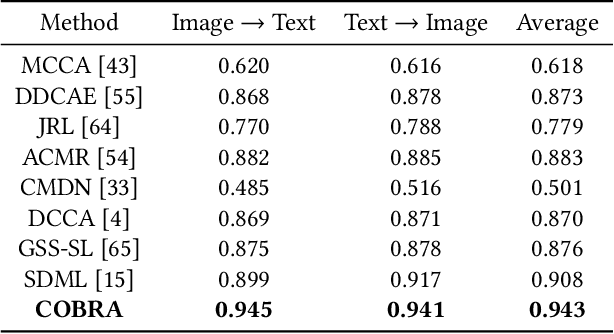
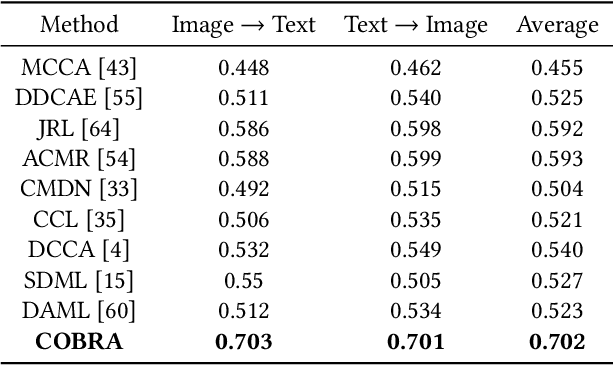
There are a wide range of applications that involve multi-modal data, such as cross-modal retrieval, visual question-answering, and image captioning. Such applications are primarily dependent on aligned distributions of the different constituent modalities. Existing approaches generate latent embeddings for each modality in a joint fashion by representing them in a common manifold. However these joint embedding spaces fail to sufficiently reduce the modality gap, which affects the performance in downstream tasks. We hypothesize that these embeddings retain the intra-class relationships but are unable to preserve the inter-class dynamics. In this paper, we present a novel framework COBRA that aims to train two modalities (image and text) in a joint fashion inspired by the Contrastive Predictive Coding (CPC) and Noise Contrastive Estimation (NCE) paradigms which preserve both inter and intra-class relationships. We empirically show that this framework reduces the modality gap significantly and generates a robust and task agnostic joint-embedding space. We outperform existing work on four diverse downstream tasks spanning across seven benchmark cross-modal datasets.
Dynamic Horizon Value Estimation for Model-based Reinforcement Learning
Sep 21, 2020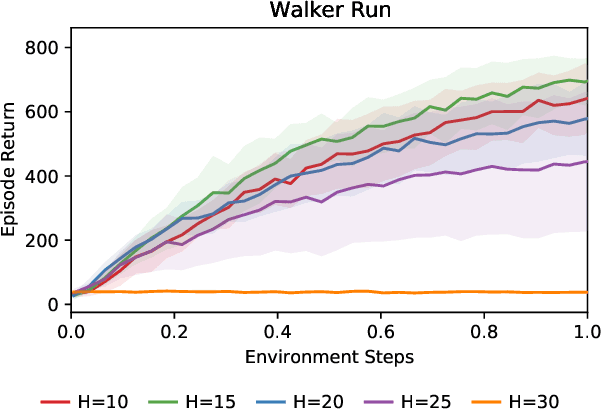
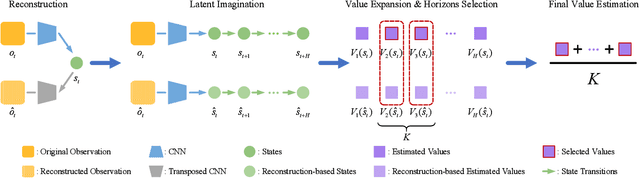
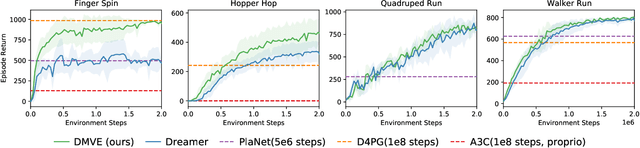
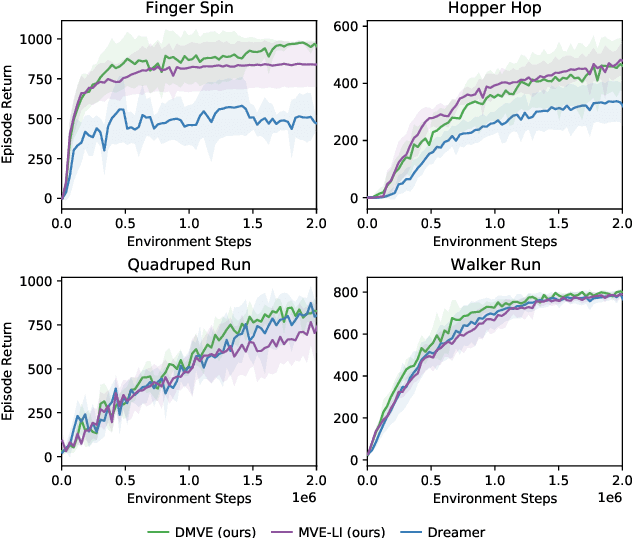
Existing model-based value expansion methods typically leverage a world model for value estimation with a fixed rollout horizon to assist policy learning. However, the fixed rollout with an inaccurate model has a potential to harm the learning process. In this paper, we investigate the idea of using the model knowledge for value expansion adaptively. We propose a novel method called Dynamic-horizon Model-based Value Expansion (DMVE) to adjust the world model usage with different rollout horizons. Inspired by reconstruction-based techniques that can be applied for visual data novelty detection, we utilize a world model with a reconstruction module for image feature extraction, in order to acquire more precise value estimation. The raw and the reconstructed images are both used to determine the appropriate horizon for adaptive value expansion. On several benchmark visual control tasks, experimental results show that DMVE outperforms all baselines in sample efficiency and final performance, indicating that DMVE can achieve more effective and accurate value estimation than state-of-the-art model-based methods.
Passport-aware Normalization for Deep Model Protection
Nov 03, 2020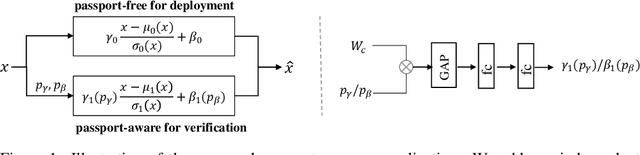

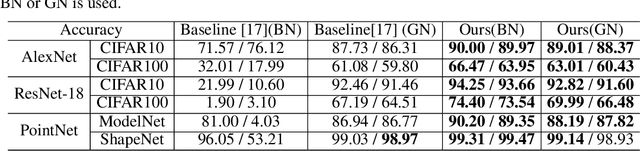
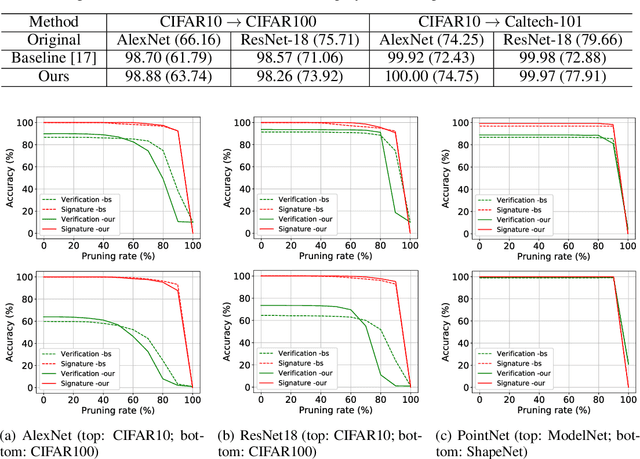
Despite tremendous success in many application scenarios, deep learning faces serious intellectual property (IP) infringement threats. Considering the cost of designing and training a good model, infringements will significantly infringe the interests of the original model owner. Recently, many impressive works have emerged for deep model IP protection. However, they either are vulnerable to ambiguity attacks, or require changes in the target network structure by replacing its original normalization layers and hence cause significant performance drops. To this end, we propose a new passport-aware normalization formulation, which is generally applicable to most existing normalization layers and only needs to add another passport-aware branch for IP protection. This new branch is jointly trained with the target model but discarded in the inference stage. Therefore it causes no structure change in the target model. Only when the model IP is suspected to be stolen by someone, the private passport-aware branch is added back for ownership verification. Through extensive experiments, we verify its effectiveness in both image and 3D point recognition models. It is demonstrated to be robust not only to common attack techniques like fine-tuning and model compression, but also to ambiguity attacks. By further combining it with trigger-set based methods, both black-box and white-box verification can be achieved for enhanced security of deep learning models deployed in real systems. Code can be found at https://github.com/ZJZAC/Passport-aware-Normalization.
Neural Network for Low-Memory IoT Devices and MNIST Image Recognition Using Kernels Based on Logistic Map
Jun 04, 2020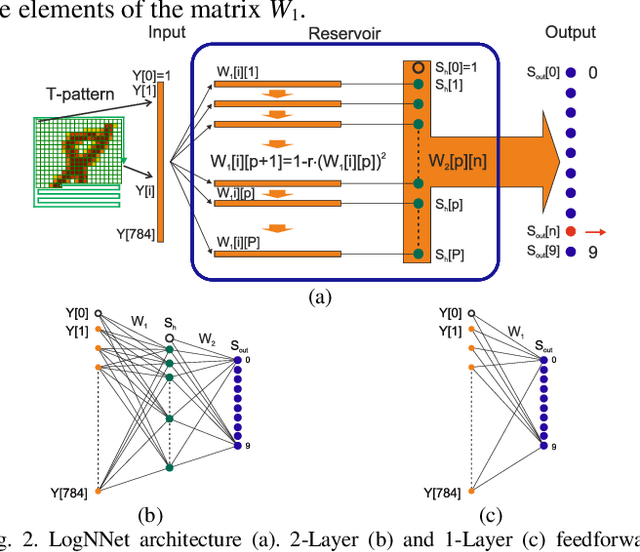
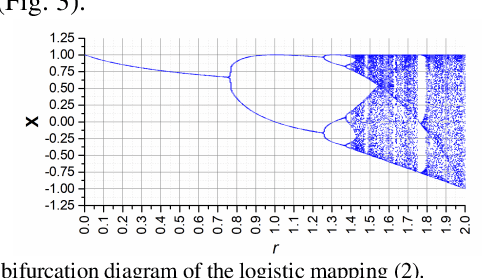
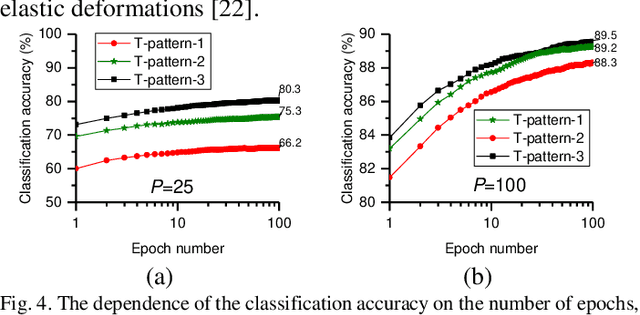
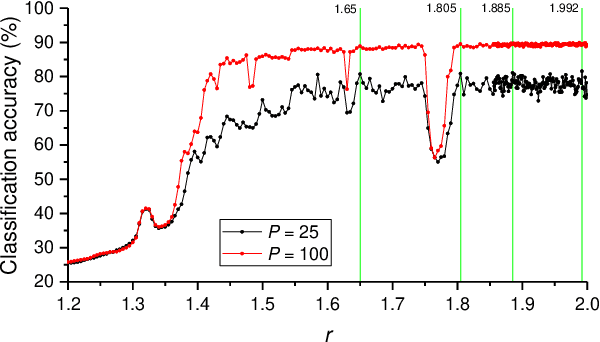
The study presents a neural network, which uses filters based on logistic mapping (LogNNet). LogNNet has a feedforward network structure, but possesses the properties of reservoir neural networks. The input weight matrix, set by a recurrent logistic mapping, forms the kernels that transform the input space to the higher-dimensional feature space. The most effective MNIST handwritten digit recognition occurs under chaotic behavior of logistic map. An advantage of LogNNet implementation on IoT Devices is the significant savings in used memory (more than 10 times) compared to other neural networks. The presented network architecture uses an array of weights with a total memory size from 1 kB to 29 kB and achieves a classification accuracy of 80.3-96.3 %.