 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Controllable Disentangled Representations with Decorrelation Regularization
Dec 25, 2019
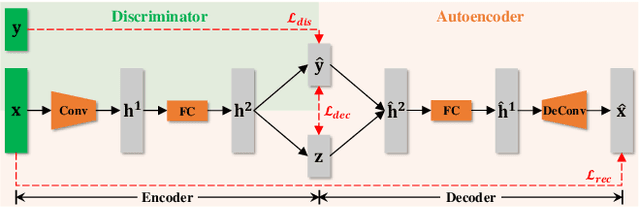
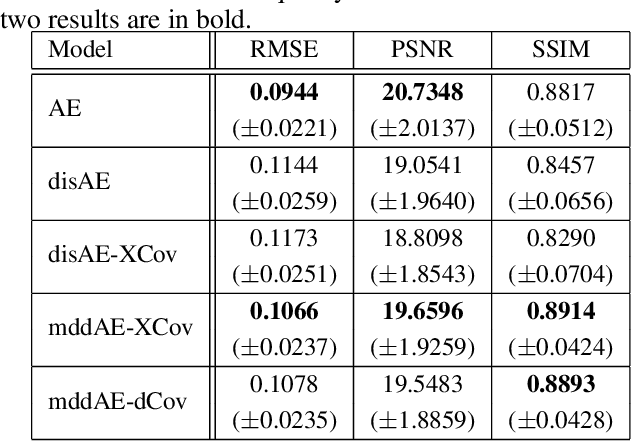
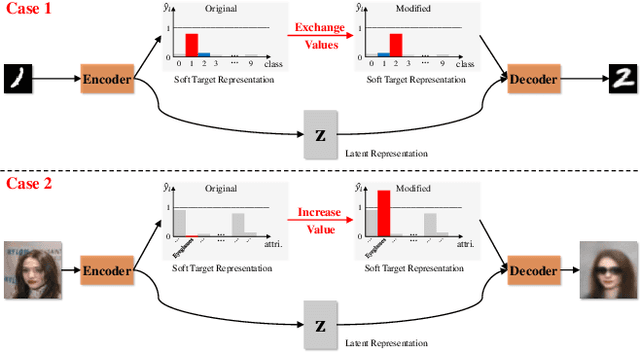
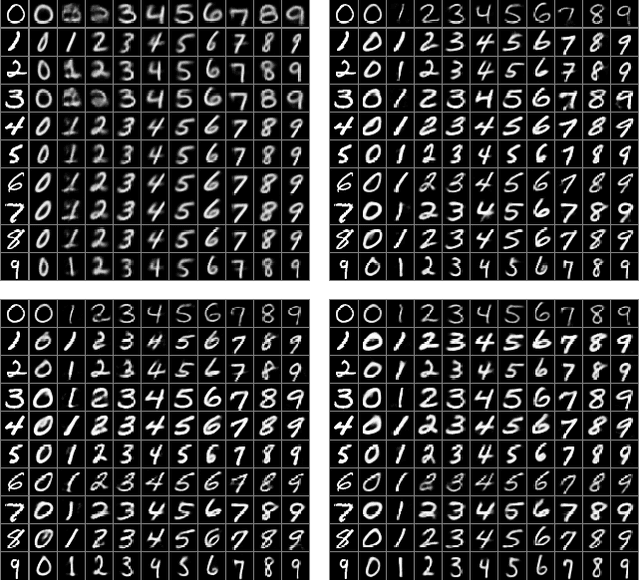
A crucial problem in learning disentangled image representations is controlling the degree of disentanglement during image editing, while preserving the identity of objects. In this work, we propose a simple yet effective model with the encoder-decoder architecture to address this challenge. To encourage disentanglement, we devise a distance covariance based decorrelation regularization. Further, for the reconstruction step, our model leverages a soft target representation combined with the latent image code. By exploiting the real-valued space of the soft target representations, we are able to synthesize novel images with the designated properties. We also design a classification based protocol to quantitatively evaluate the disentanglement strength of our model. Experimental results show that the proposed model competently disentangles factors of variation, and is able to manipulate face images to synthesize the desired attributes.
Simultaneous Enhancement and Super-Resolution of Underwater Imagery for Improved Visual Perception
Feb 04, 2020


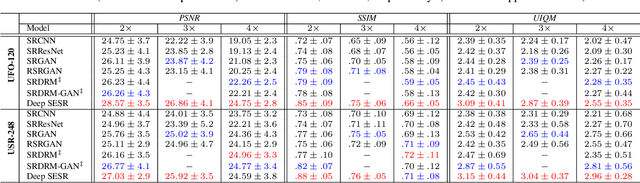
In this paper, we introduce and tackle the simultaneous enhancement and super-resolution (SESR) problem for underwater robot vision and provide an efficient solution for near real-time applications. We present Deep SESR, a residual-in-residual network-based generative model that can learn to restore perceptual image qualities at 2x, 3x, or 4x higher spatial resolution. We supervise its training by formulating a multi-modal objective function that addresses the chrominance-specific underwater color degradation, lack of image sharpness, and loss in high-level feature representation. It is also supervised to learn salient foreground regions in the image, which in turn guides the network to learn global contrast enhancement. We design an end-to-end training pipeline to jointly learn the saliency prediction and SESR on a shared hierarchical feature space for fast inference. Moreover, we present UFO-120, the first dataset to facilitate large-scale SESR learning; it contains over 1500 training samples and a benchmark test set of 120 samples. By thorough experimental evaluation on the UFO-120 and other standard datasets, we demonstrate that Deep SESR outperforms the existing solutions for underwater image enhancement and super-resolution. We also validate its generalization performance on several test cases that include underwater images with diverse spectral and spatial degradation levels, and also terrestrial images with unseen natural objects. Lastly, we analyze its computational feasibility for single-board deployments and demonstrate its operational benefits for visually-guided underwater robots. The model and dataset information will be available at: https://github.com/xahidbuffon/Deep-SESR.
Large-Scale Optimal Transport via Adversarial Training with Cycle-Consistency
Mar 14, 2020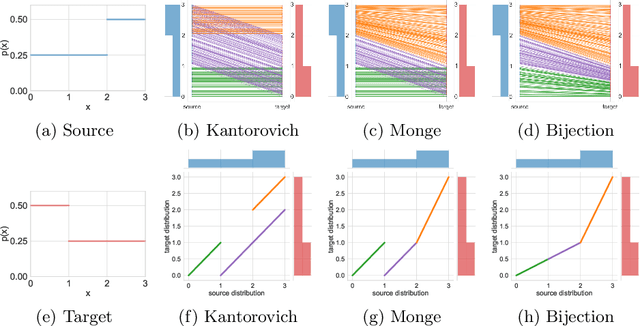
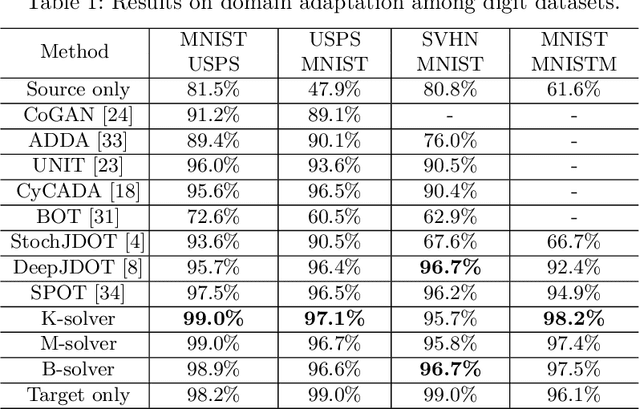
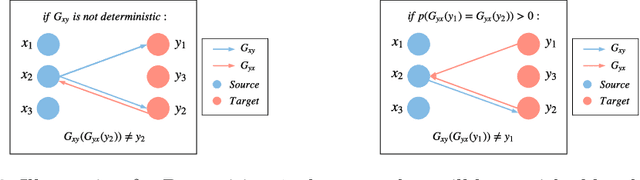
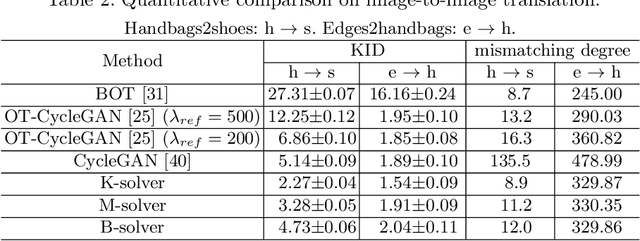
Recent advances in large-scale optimal transport have greatly extended its application scenarios in machine learning. However, existing methods either not explicitly learn the transport map or do not support general cost function. In this paper, we propose an end-to-end approach for large-scale optimal transport, which directly solves the transport map and is compatible with general cost function. It models the transport map via stochastic neural networks and enforces the constraint on the marginal distributions via adversarial training. The proposed framework can be further extended towards learning Monge map or optimal bijection via adopting cycle-consistency constraint(s). We verify the effectiveness of the proposed method and demonstrate its superior performance against existing methods with large-scale real-world applications, including domain adaptation, image-to-image translation, and color transfer.
Towards Effective Codebookless Model for Image Classification
Jul 20, 2015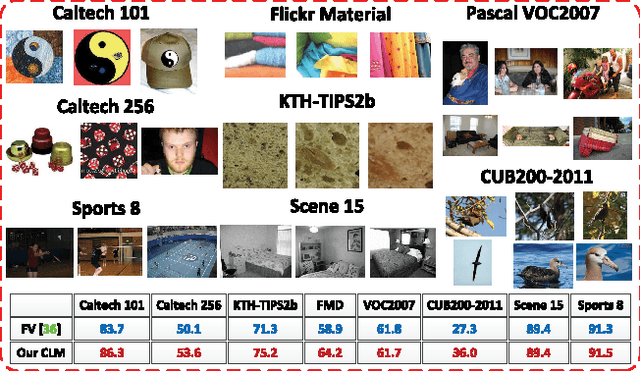
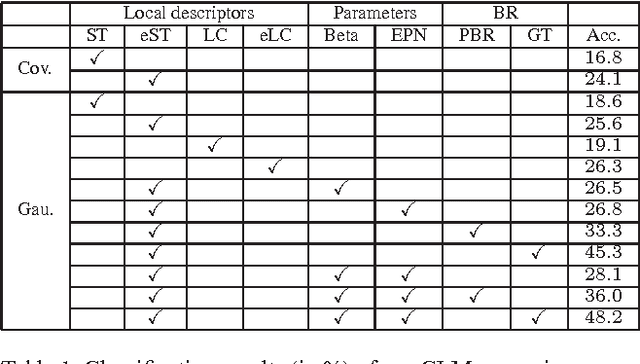
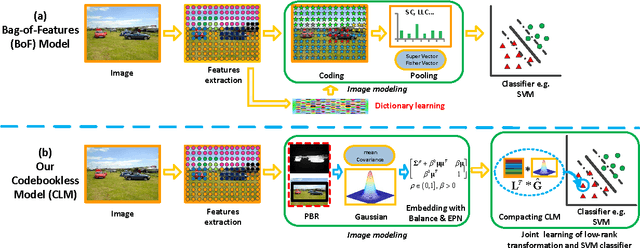

The bag-of-features (BoF) model for image classification has been thoroughly studied over the last decade. Different from the widely used BoF methods which modeled images with a pre-trained codebook, the alternative codebook free image modeling method, which we call Codebookless Model (CLM), attracted little attention. In this paper, we present an effective CLM that represents an image with a single Gaussian for classification. By embedding Gaussian manifold into a vector space, we show that the simple incorporation of our CLM into a linear classifier achieves very competitive accuracy compared with state-of-the-art BoF methods (e.g., Fisher Vector). Since our CLM lies in a high dimensional Riemannian manifold, we further propose a joint learning method of low-rank transformation with support vector machine (SVM) classifier on the Gaussian manifold, in order to reduce computational and storage cost. To study and alleviate the side effect of background clutter on our CLM, we also present a simple yet effective partial background removal method based on saliency detection. Experiments are extensively conducted on eight widely used databases to demonstrate the effectiveness and efficiency of our CLM method.
Neural Architecture Search with an Efficient Multiobjective Evolutionary Framework
Nov 09, 2020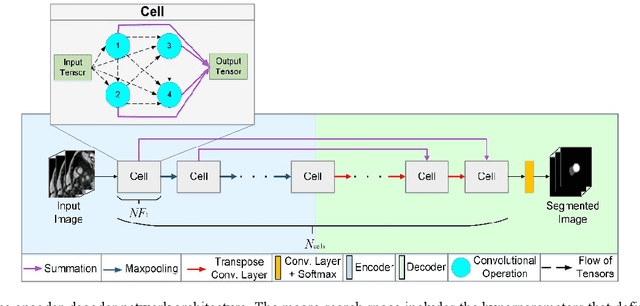

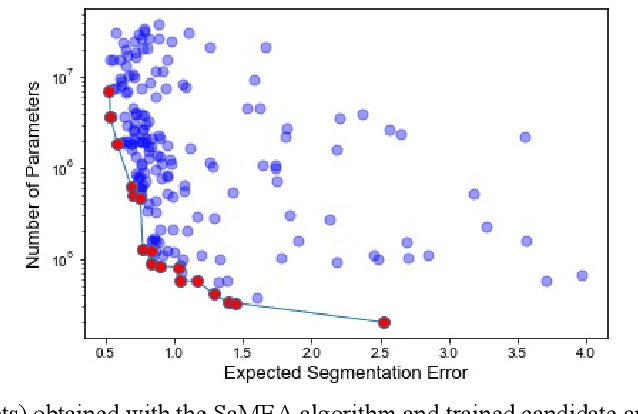
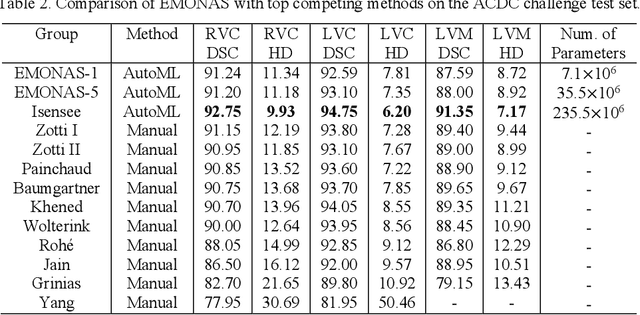
Deep learning methods have become very successful at solving many complex tasks such as image classification and segmentation, speech recognition and machine translation. Nevertheless, manually designing a neural network for a specific problem is very difficult and time-consuming due to the massive hyperparameter search space, long training times, and lack of technical guidelines for the hyperparameter selection. Moreover, most networks are highly complex, task specific and over-parametrized. Recently, multiobjective neural architecture search (NAS) methods have been proposed to automate the design of accurate and efficient architectures. However, they only optimize either the macro- or micro-structure of the architecture requiring the unset hyperparameters to be manually defined, and do not use the information produced during the optimization process to increase the efficiency of the search. In this work, we propose EMONAS, an Efficient MultiObjective Neural Architecture Search framework for the automatic design of neural architectures while optimizing the network's accuracy and size. EMONAS is composed of a search space that considers both the macro- and micro-structure of the architecture, and a surrogate-assisted multiobjective evolutionary based algorithm that efficiently searches for the best hyperparameters using a Random Forest surrogate and guiding selection probabilities. EMONAS is evaluated on the task of 3D cardiac segmentation from the MICCAI ACDC challenge, which is crucial for disease diagnosis, risk evaluation, and therapy decision. The architecture found with EMONAS is ranked within the top 10 submissions of the challenge in all evaluation metrics, performing better or comparable to other approaches while reducing the search time by more than 50% and having considerably fewer number of parameters.
Denoising and Regularization via Exploiting the Structural Bias of Convolutional Generators
Oct 31, 2019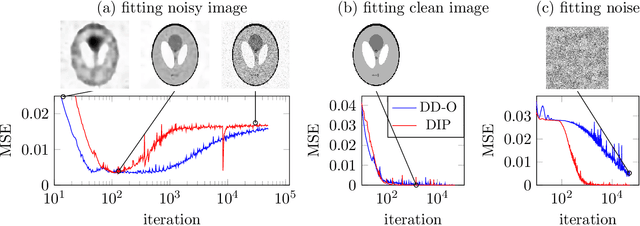


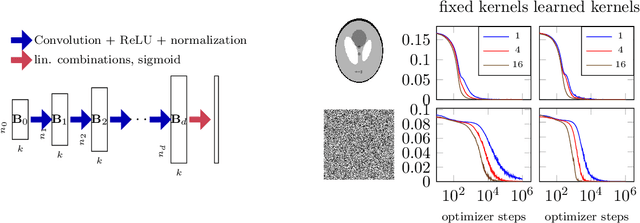
Convolutional Neural Networks (CNNs) have emerged as highly successful tools for image generation, recovery, and restoration. This success is often attributed to large amounts of training data. However, recent experimental findings challenge this view and instead suggest that a major contributing factor to this success is that convolutional networks impose strong prior assumptions about natural images. A surprising experiment that highlights this architectural bias towards natural images is that one can remove noise and corruptions from a natural image without using any training data, by simply fitting (via gradient descent) a randomly initialized, over-parameterized convolutional generator to the single corrupted image. While this over-parameterized network can fit the corrupted image perfectly, surprisingly after a few iterations of gradient descent one obtains the uncorrupted image. This intriguing phenomenon enables state-of-the-art CNN-based denoising and regularization of linear inverse problems such as compressive sensing. In this paper, we take a step towards demystifying this experimental phenomenon by attributing this effect to particular architectural choices of convolutional networks, namely convolutions with fixed interpolating filters. We then formally characterize the dynamics of fitting a two-layer convolutional generator to a noisy signal and prove that early-stopped gradient descent denoises/regularizes. This result relies on showing that convolutional generators fit the structured part of an image significantly faster than the corrupted portion.
CoInGP: Convolutional Inpainting with Genetic Programming
Apr 23, 2020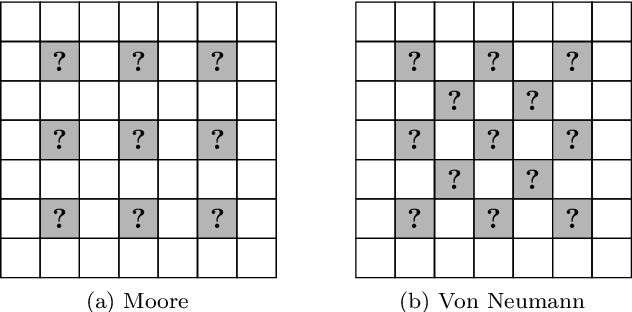
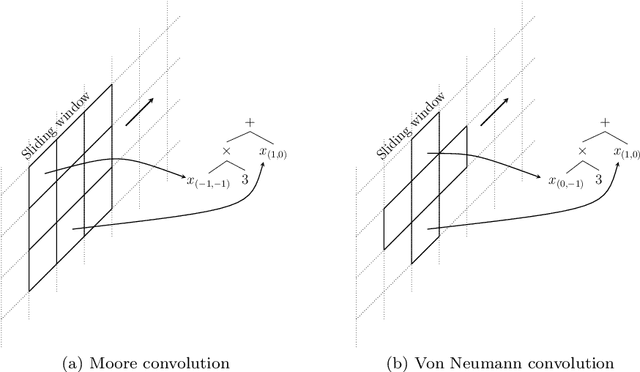


We investigate the use of Genetic Programming (GP) as a convolutional predictor for supervised learning tasks in signal processing, focusing on the use case of predicting missing pixels in images. The training is performed by sweeping a small sliding window on the available pixels: all pixels in the window except for the central one are fed in input to a GP tree whose output is taken as the predicted value for the central pixel. The best GP tree in the population scoring the lowest prediction error over all available pixels in the population is then tested on the actual missing pixels of the degraded image. We experimentally assess this approach by training over four target images, removing up to 20\% of the pixels for the testing phase. The results indicate that our method can learn to some extent the distribution of missing pixels in an image and that GP with Moore neighborhood works better than the Von Neumann neighborhood, although the latter allows for a larger training set size.
3D Solid Spherical Bispectrum CNNs for Biomedical Texture Analysis
Jun 02, 2020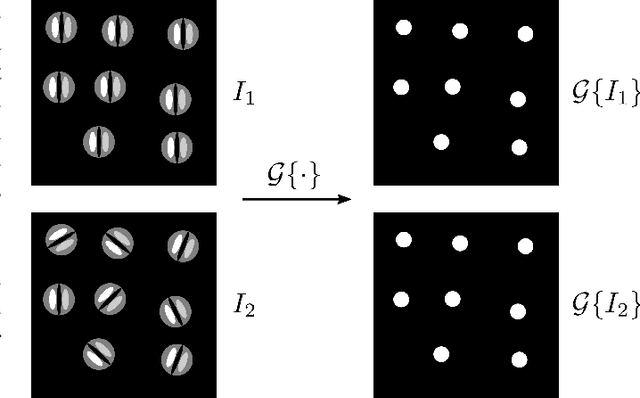
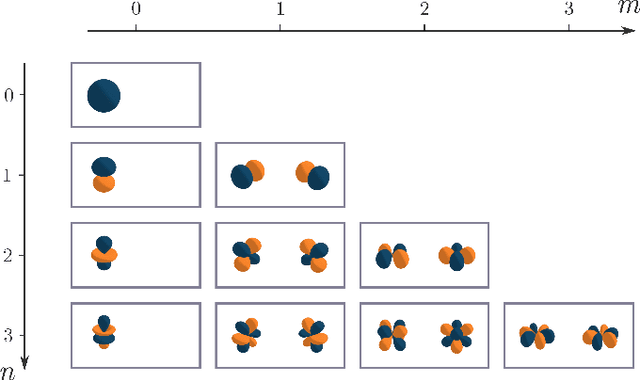
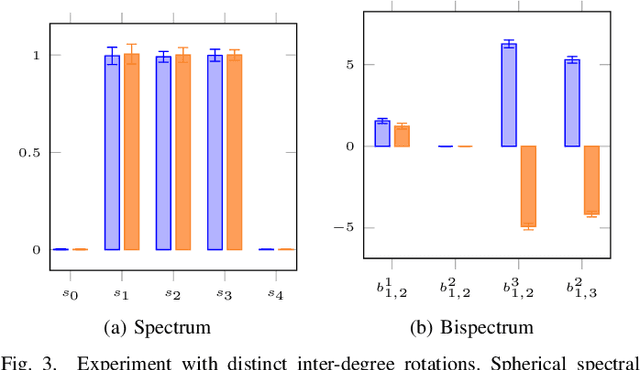
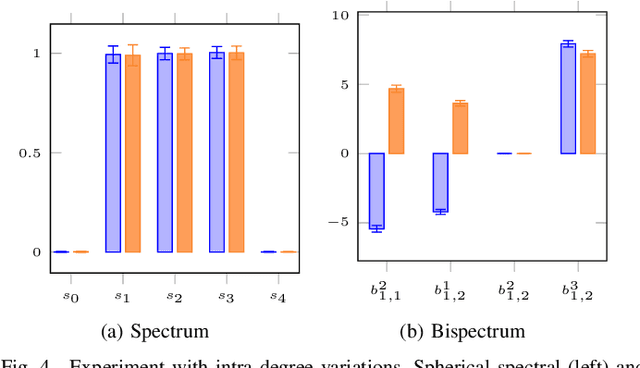
Locally Rotation Invariant (LRI) operators have shown great potential in biomedical texture analysis where patterns appear at random positions and orientations. LRI operators can be obtained by computing the responses to the discrete rotation of local descriptors, such as Local Binary Patterns (LBP) or the Scale Invariant Feature Transform (SIFT). Other strategies achieve this invariance using Laplacian of Gaussian or steerable wavelets for instance, preventing the introduction of sampling errors during the discretization of the rotations. In this work, we obtain LRI operators via the local projection of the image on the spherical harmonics basis, followed by the computation of the bispectrum, which shares and extends the invariance properties of the spectrum. We investigate the benefits of using the bispectrum over the spectrum in the design of a LRI layer embedded in a shallow Convolutional Neural Network (CNN) for 3D image analysis. The performance of each design is evaluated on two datasets and compared against a standard 3D CNN. The first dataset is made of 3D volumes composed of synthetically generated rotated patterns, while the second contains malignant and benign pulmonary nodules in Computed Tomography (CT) images. The results indicate that bispectrum CNNs allows for a significantly better characterization of 3D textures than both the spectral and standard CNN. In addition, it can efficiently learn with fewer training examples and trainable parameters when compared to a standard convolutional layer.
Orientation-aware Vehicle Re-identification with Semantics-guided Part Attention Network
Aug 26, 2020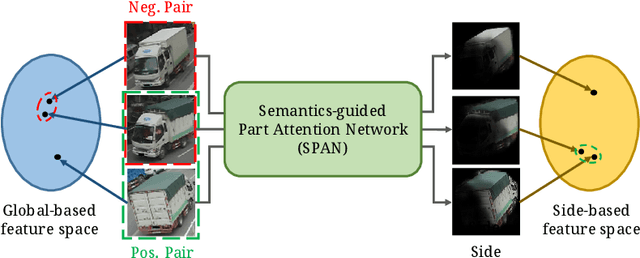


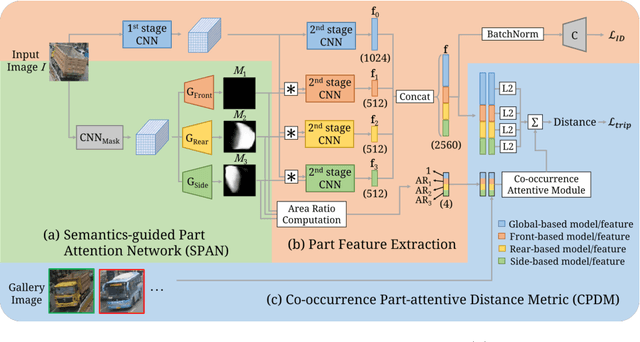
Vehicle re-identification (re-ID) focuses on matching images of the same vehicle across different cameras. It is fundamentally challenging because differences between vehicles are sometimes subtle. While several studies incorporate spatial-attention mechanisms to help vehicle re-ID, they often require expensive keypoint labels or suffer from noisy attention mask if not trained with expensive labels. In this work, we propose a dedicated Semantics-guided Part Attention Network (SPAN) to robustly predict part attention masks for different views of vehicles given only image-level semantic labels during training. With the help of part attention masks, we can extract discriminative features in each part separately. Then we introduce Co-occurrence Part-attentive Distance Metric (CPDM) which places greater emphasis on co-occurrence vehicle parts when evaluating the feature distance of two images. Extensive experiments validate the effectiveness of the proposed method and show that our framework outperforms the state-of-the-art approaches.
Kinematic-Structure-Preserved Representation for Unsupervised 3D Human Pose Estimation
Jun 24, 2020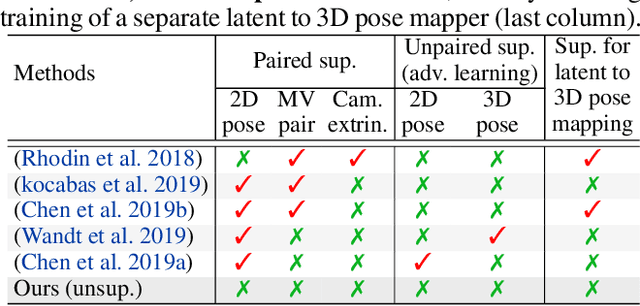
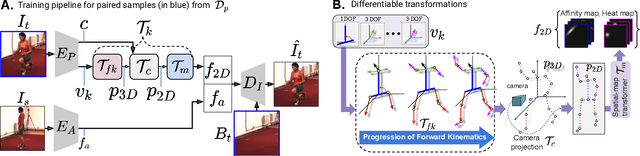
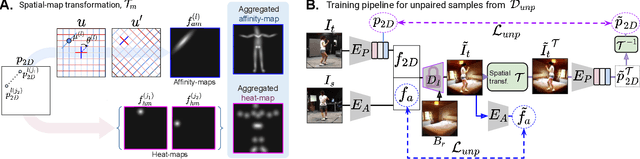
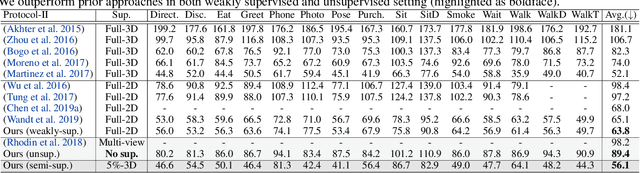
Estimation of 3D human pose from monocular image has gained considerable attention, as a key step to several human-centric applications. However, generalizability of human pose estimation models developed using supervision on large-scale in-studio datasets remains questionable, as these models often perform unsatisfactorily on unseen in-the-wild environments. Though weakly-supervised models have been proposed to address this shortcoming, performance of such models relies on availability of paired supervision on some related tasks, such as 2D pose or multi-view image pairs. In contrast, we propose a novel kinematic-structure-preserved unsupervised 3D pose estimation framework, which is not restrained by any paired or unpaired weak supervisions. Our pose estimation framework relies on a minimal set of prior knowledge that defines the underlying kinematic 3D structure, such as skeletal joint connectivity information with bone-length ratios in a fixed canonical scale. The proposed model employs three consecutive differentiable transformations named as forward-kinematics, camera-projection and spatial-map transformation. This design not only acts as a suitable bottleneck stimulating effective pose disentanglement but also yields interpretable latent pose representations avoiding training of an explicit latent embedding to pose mapper. Furthermore, devoid of unstable adversarial setup, we re-utilize the decoder to formalize an energy-based loss, which enables us to learn from in-the-wild videos, beyond laboratory settings. Comprehensive experiments demonstrate our state-of-the-art unsupervised and weakly-supervised pose estimation performance on both Human3.6M and MPI-INF-3DHP datasets. Qualitative results on unseen environments further establish our superior generalization ability.