 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Copy-Move Forgery Classification via Unsupervised Domain Adaptation
Nov 14, 2019
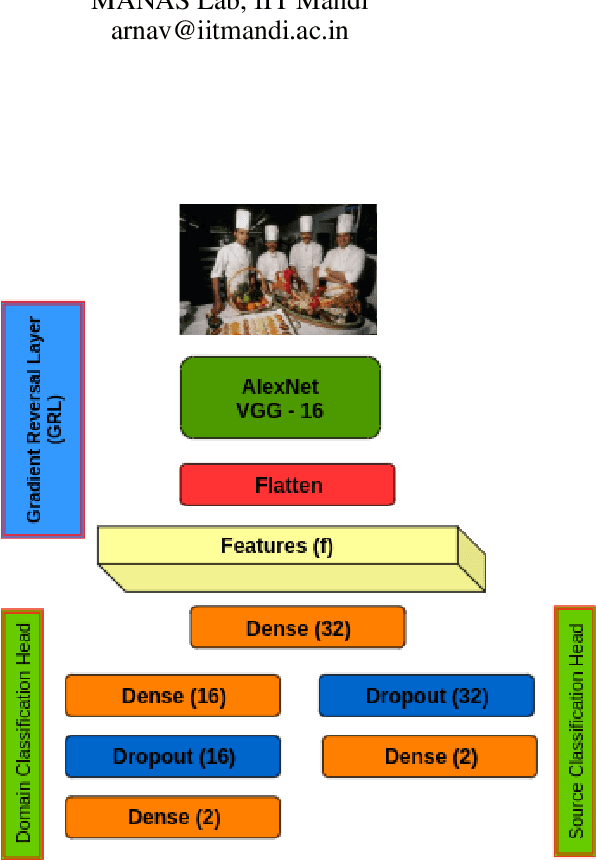
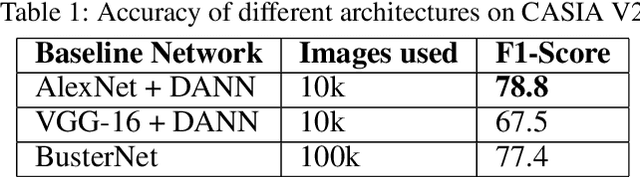

In the current era, image manipulation is becoming increasingly easier, yielding more natural looking images, owing to the modern tools in image processing and computer vision techniques. The task of the segregation of forged images has become very challenging. To tackle such problems, publicly available datasets are insufficient. In this paper, we propose to create a synthetic forged dataset using deep semantic image inpainting algorithm. Furthermore, we use an unsupervised domain adaptation network to detect copy-move forgery in images. Our approach can be helpful in those cases, where the classification of data is unavailable.
Kinematic-Structure-Preserved Representation for Unsupervised 3D Human Pose Estimation
Jun 24, 2020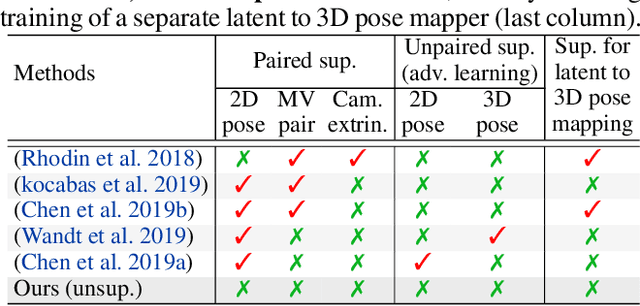
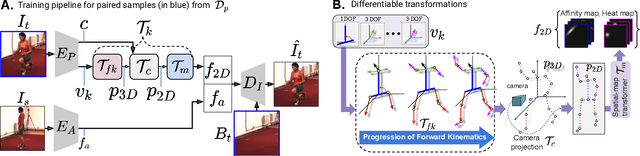
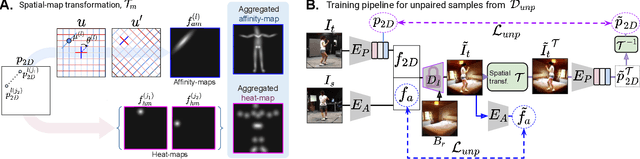
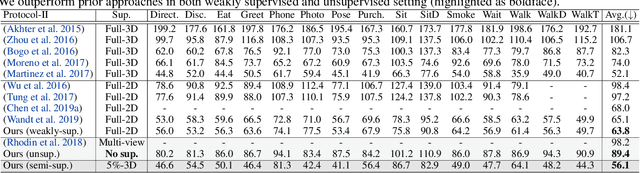
Estimation of 3D human pose from monocular image has gained considerable attention, as a key step to several human-centric applications. However, generalizability of human pose estimation models developed using supervision on large-scale in-studio datasets remains questionable, as these models often perform unsatisfactorily on unseen in-the-wild environments. Though weakly-supervised models have been proposed to address this shortcoming, performance of such models relies on availability of paired supervision on some related tasks, such as 2D pose or multi-view image pairs. In contrast, we propose a novel kinematic-structure-preserved unsupervised 3D pose estimation framework, which is not restrained by any paired or unpaired weak supervisions. Our pose estimation framework relies on a minimal set of prior knowledge that defines the underlying kinematic 3D structure, such as skeletal joint connectivity information with bone-length ratios in a fixed canonical scale. The proposed model employs three consecutive differentiable transformations named as forward-kinematics, camera-projection and spatial-map transformation. This design not only acts as a suitable bottleneck stimulating effective pose disentanglement but also yields interpretable latent pose representations avoiding training of an explicit latent embedding to pose mapper. Furthermore, devoid of unstable adversarial setup, we re-utilize the decoder to formalize an energy-based loss, which enables us to learn from in-the-wild videos, beyond laboratory settings. Comprehensive experiments demonstrate our state-of-the-art unsupervised and weakly-supervised pose estimation performance on both Human3.6M and MPI-INF-3DHP datasets. Qualitative results on unseen environments further establish our superior generalization ability.
Automatic Chronic Degenerative Diseases Identification Using Enteric Nervous System Images
Oct 31, 2020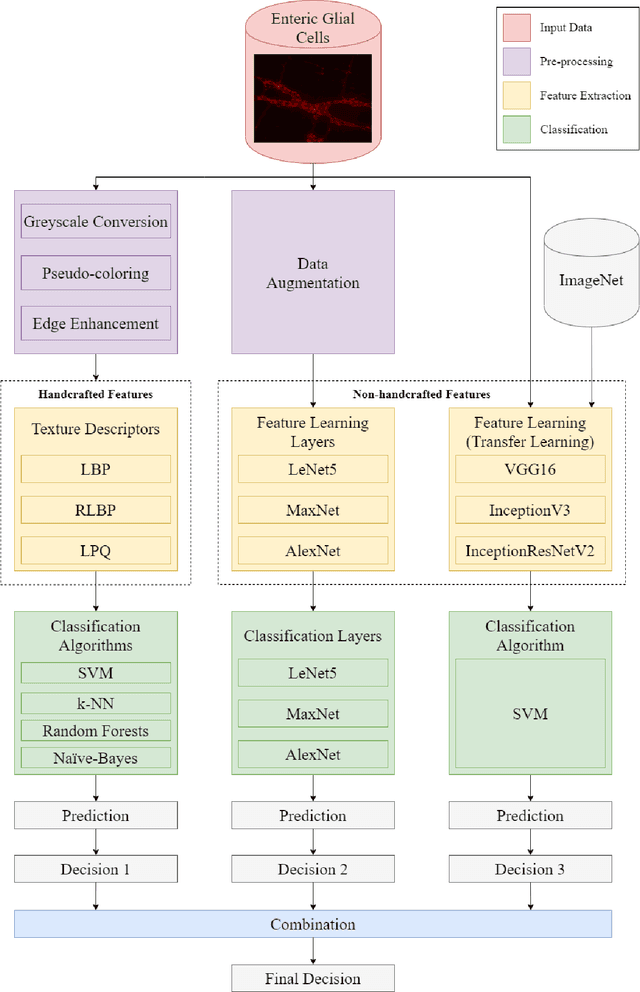

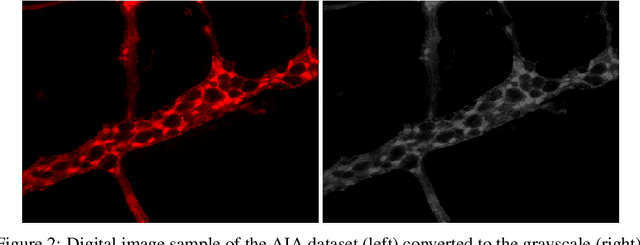
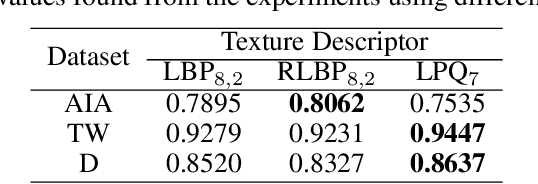
Studies recently accomplished on the Enteric Nervous System have shown that chronic degenerative diseases affect the Enteric Glial Cells (EGC) and, thus, the development of recognition methods able to identify whether or not the EGC are affected by these type of diseases may be helpful in its diagnoses. In this work, we propose the use of pattern recognition and machine learning techniques to evaluate if a given animal EGC image was obtained from a healthy individual or one affect by a chronic degenerative disease. In the proposed approach, we have performed the classification task with handcrafted features and deep learning based techniques, also known as non-handcrafted features. The handcrafted features were obtained from the textural content of the ECG images using texture descriptors, such as the Local Binary Pattern (LBP). Moreover, the representation learning techniques employed in the approach are based on different Convolutional Neural Network (CNN) architectures, such as AlexNet and VGG16, with and without transfer learning. The complementarity between the handcrafted and non-handcrafted features was also evaluated with late fusion techniques. The datasets of EGC images used in the experiments, which are also contributions of this paper, are composed of three different chronic degenerative diseases: Cancer, Diabetes Mellitus, and Rheumatoid Arthritis. The experimental results, supported by statistical analysis, shown that the proposed approach can distinguish healthy cells from the sick ones with a recognition rate of 89.30% (Rheumatoid Arthritis), 98.45% (Cancer), and 95.13% (Diabetes Mellitus), being achieved by combining classifiers obtained both feature scenarios.
Local Color Contrastive Descriptor for Image Classification
Aug 03, 2015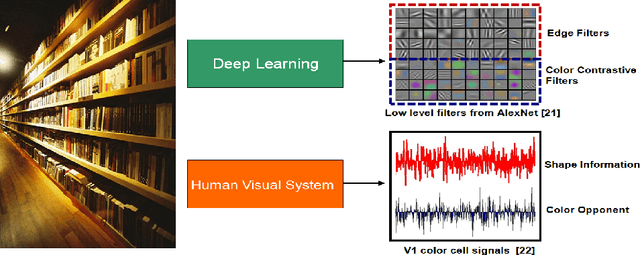
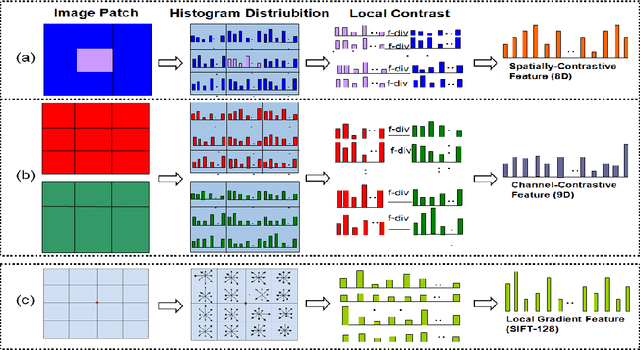
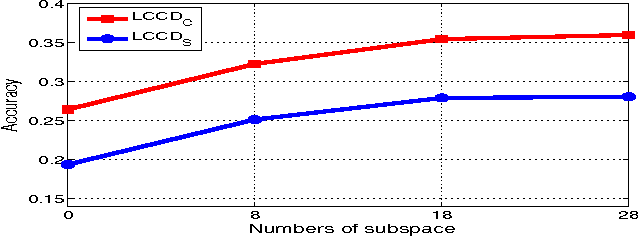
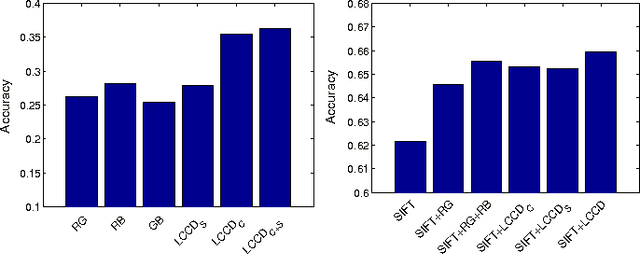
Image representation and classification are two fundamental tasks towards multimedia content retrieval and understanding. The idea that shape and texture information (e.g. edge or orientation) are the key features for visual representation is ingrained and dominated in current multimedia and computer vision communities. A number of low-level features have been proposed by computing local gradients (e.g. SIFT, LBP and HOG), and have achieved great successes on numerous multimedia applications. In this paper, we present a simple yet efficient local descriptor for image classification, referred as Local Color Contrastive Descriptor (LCCD), by leveraging the neural mechanisms of color contrast. The idea originates from the observation in neural science that color and shape information are linked inextricably in visual cortical processing. The color contrast yields key information for visual color perception and provides strong linkage between color and shape. We propose a novel contrastive mechanism to compute the color contrast in both spatial location and multiple channels. The color contrast is computed by measuring \emph{f}-divergence between the color distributions of two regions. Our descriptor enriches local image representation with both color and contrast information. We verified experimentally that it can compensate strongly for the shape based descriptor (e.g. SIFT), while keeping computationally simple. Extensive experimental results on image classification show that our descriptor improves the performance of SIFT substantially by combinations, and achieves the state-of-the-art performance on three challenging benchmark datasets. It improves recent Deep Learning model (DeCAF) [1] largely from the accuracy of 40.94% to 49.68% in the large scale SUN397 database. Codes for the LCCD will be available.
Captioning Images with Novel Objects via Online Vocabulary Expansion
Mar 06, 2020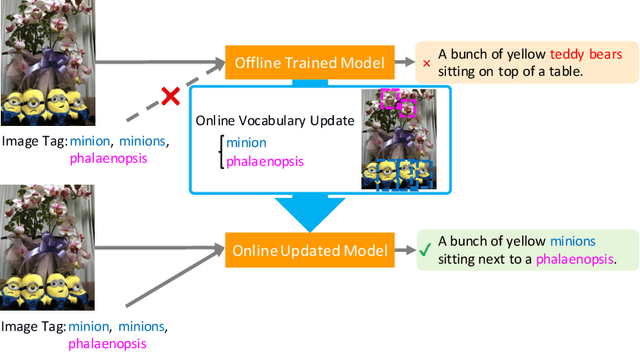

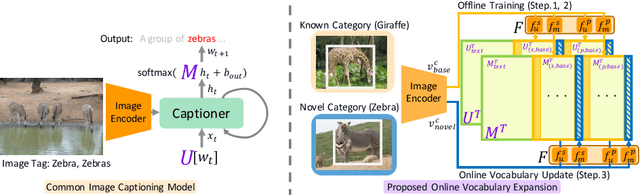

In this study, we introduce a low cost method for generating descriptions from images containing novel objects. Generally, constructing a model, which can explain images with novel objects, is costly because of the following: (1) collecting a large amount of data for each category, and (2) retraining the entire system. If humans see a small number of novel objects, they are able to estimate their properties by associating their appearance with known objects. Accordingly, we propose a method that can explain images with novel objects without retraining using the word embeddings of the objects estimated from only a small number of image features of the objects. The method can be integrated with general image-captioning models. The experimental results show the effectiveness of our approach.
FastSal: a Computationally Efficient Network for Visual Saliency Prediction
Aug 25, 2020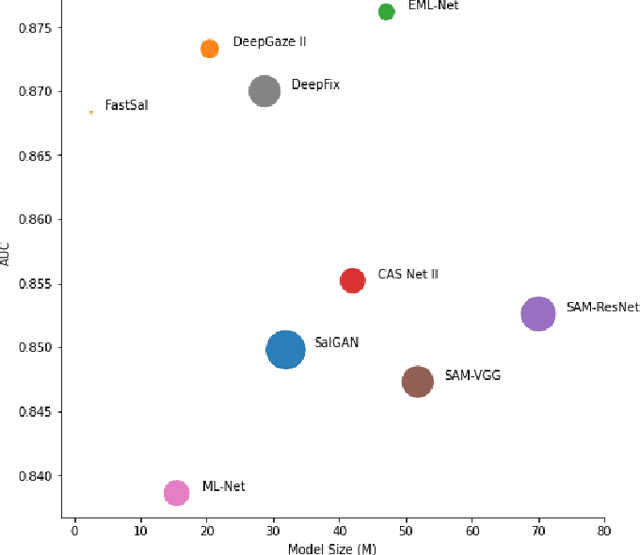
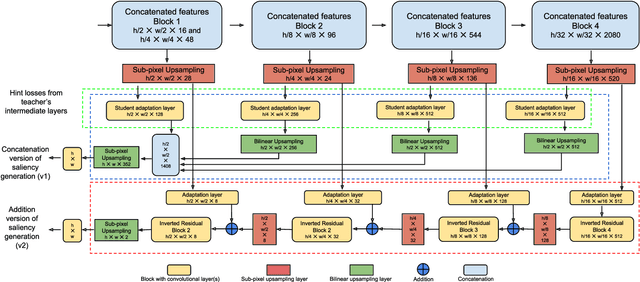
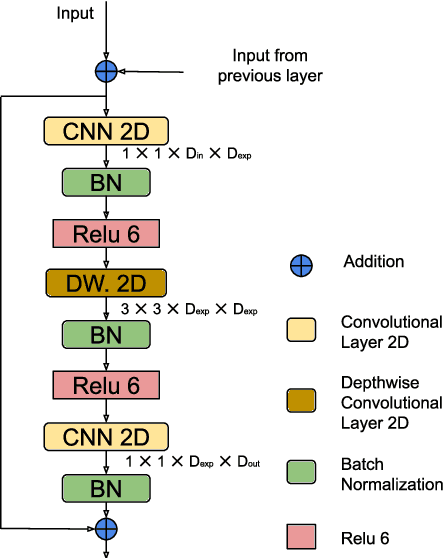
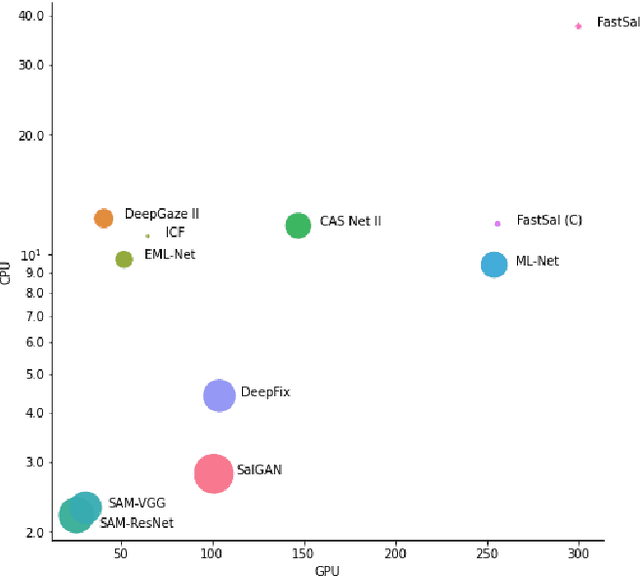
This paper focuses on the problem of visual saliency prediction, predicting regions of an image that tend to attract human visual attention, under a constrained computational budget. We modify and test various recent efficient convolutional neural network architectures like EfficientNet and MobileNetV2 and compare them with existing state-of-the-art saliency models such as SalGAN and DeepGaze II both in terms of standard accuracy metrics like AUC and NSS, and in terms of the computational complexity and model size. We find that MobileNetV2 makes an excellent backbone for a visual saliency model and can be effective even without a complex decoder. We also show that knowledge transfer from a more computationally expensive model like DeepGaze II can be achieved via pseudo-labelling an unlabelled dataset, and that this approach gives result on-par with many state-of-the-art algorithms with a fraction of the computational cost and model size. Source code is available at https://github.com/feiyanhu/FastSal.
Self-Driving Car Steering Angle Prediction Based on Image Recognition
Dec 11, 2019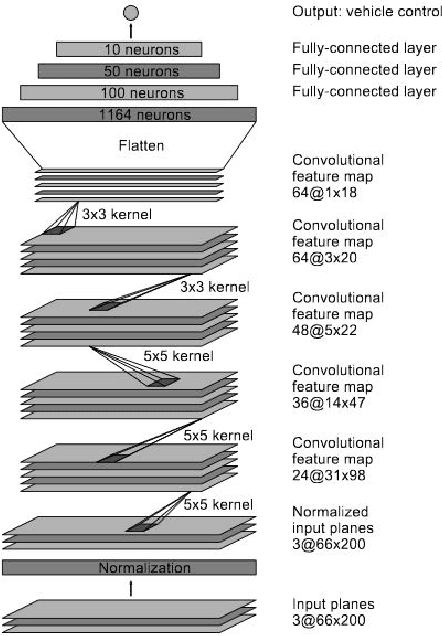
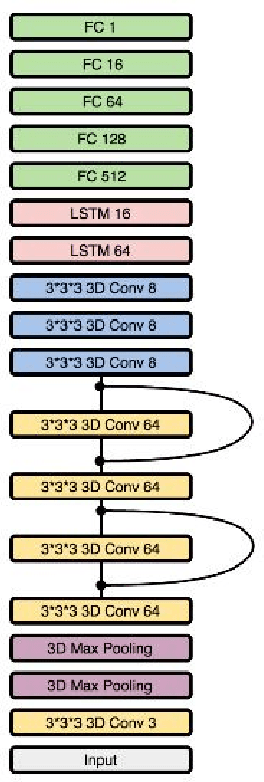
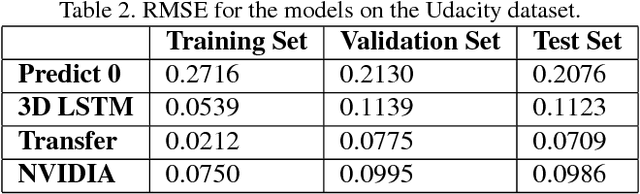
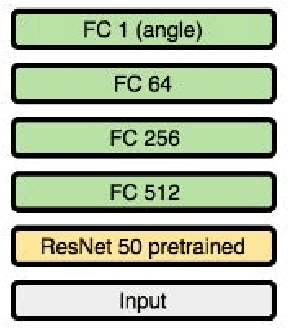
Self-driving vehicles have expanded dramatically over the last few years. Udacity has release a dataset containing, among other data, a set of images with the steering angle captured during driving. The Udacity challenge aimed to predict steering angle based on only the provided images. We explore two different models to perform high quality prediction of steering angles based on images using different deep learning techniques including Transfer Learning, 3D CNN, LSTM and ResNet. If the Udacity challenge was still ongoing, both of our models would have placed in the top ten of all entries.
Streaming Networks: Increase Noise Robustness and Filter Diversity via Hard-wired and Input-induced Sparsity
Apr 09, 2020
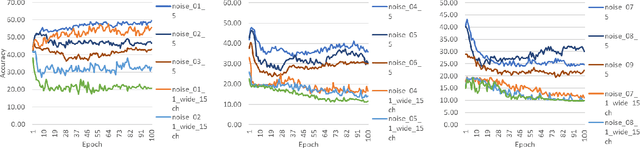
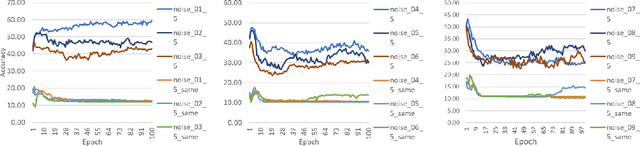
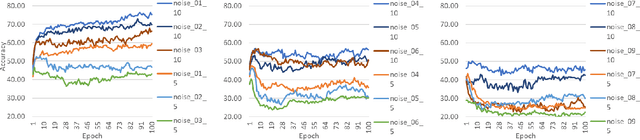
The CNNs have achieved a state-of-the-art performance in many applications. Recent studies illustrate that CNN's recognition accuracy drops drastically if images are noise corrupted. We focus on the problem of robust recognition accuracy of noise-corrupted images. We introduce a novel network architecture called Streaming Networks. Each stream is taking a certain intensity slice of the original image as an input, and stream parameters are trained independently. We use network capacity, hard-wired and input-induced sparsity as the dimensions for experiments. The results indicate that only the presence of both hard-wired and input-induces sparsity enables robust noisy image recognition. Streaming Nets is the only architecture which has both types of sparsity and exhibits higher robustness to noise. Finally, to illustrate increase in filter diversity we illustrate that a distribution of filter weights of the first conv layer gradually approaches uniform distribution as the degree of hard-wired and domain-induced sparsity and capacities increases.
Visual Reranking with Improved Image Graph
Jun 03, 2014
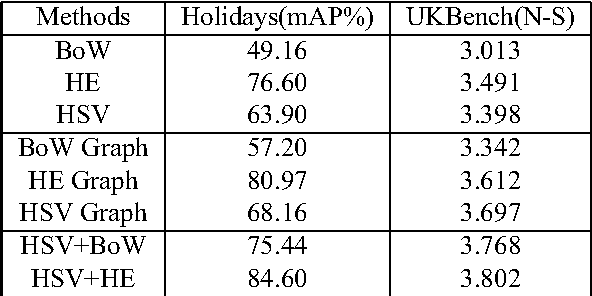


This paper introduces an improved reranking method for the Bag-of-Words (BoW) based image search. Built on [1], a directed image graph robust to outlier distraction is proposed. In our approach, the relevance among images is encoded in the image graph, based on which the initial rank list is refined. Moreover, we show that the rank-level feature fusion can be adopted in this reranking method as well. Taking advantage of the complementary nature of various features, the reranking performance is further enhanced. Particularly, we exploit the reranking method combining the BoW and color information. Experiments on two benchmark datasets demonstrate that ourmethod yields significant improvements and the reranking results are competitive to the state-of-the-art methods.
3D Solid Spherical Bispectrum CNNs for Biomedical Texture Analysis
Jun 02, 2020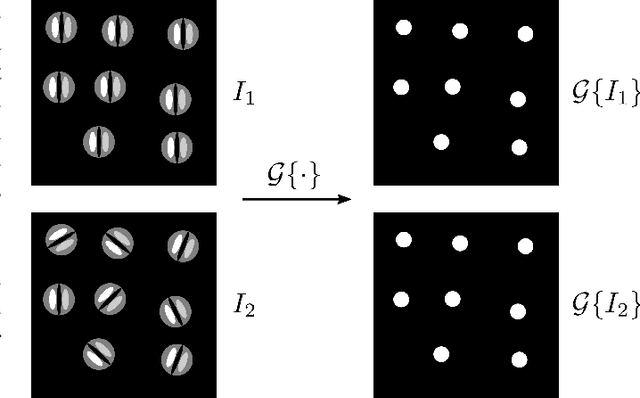
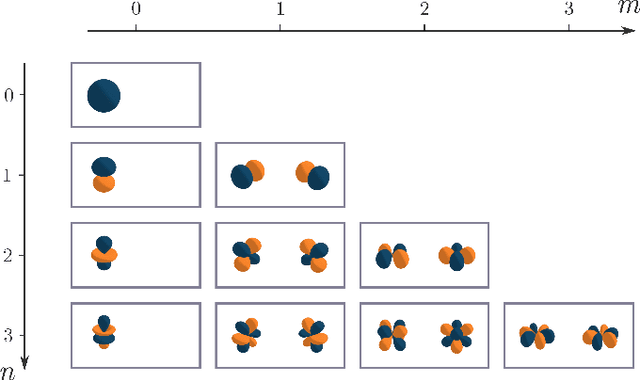
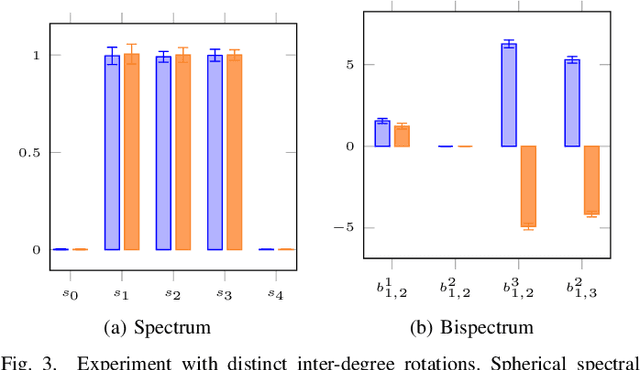
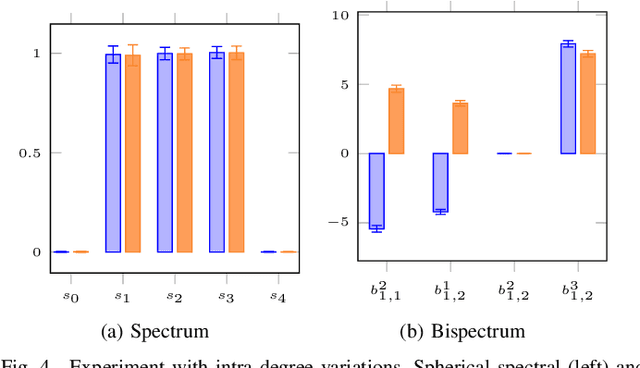
Locally Rotation Invariant (LRI) operators have shown great potential in biomedical texture analysis where patterns appear at random positions and orientations. LRI operators can be obtained by computing the responses to the discrete rotation of local descriptors, such as Local Binary Patterns (LBP) or the Scale Invariant Feature Transform (SIFT). Other strategies achieve this invariance using Laplacian of Gaussian or steerable wavelets for instance, preventing the introduction of sampling errors during the discretization of the rotations. In this work, we obtain LRI operators via the local projection of the image on the spherical harmonics basis, followed by the computation of the bispectrum, which shares and extends the invariance properties of the spectrum. We investigate the benefits of using the bispectrum over the spectrum in the design of a LRI layer embedded in a shallow Convolutional Neural Network (CNN) for 3D image analysis. The performance of each design is evaluated on two datasets and compared against a standard 3D CNN. The first dataset is made of 3D volumes composed of synthetically generated rotated patterns, while the second contains malignant and benign pulmonary nodules in Computed Tomography (CT) images. The results indicate that bispectrum CNNs allows for a significantly better characterization of 3D textures than both the spectral and standard CNN. In addition, it can efficiently learn with fewer training examples and trainable parameters when compared to a standard convolutional layer.