 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Inpainting with Learnable Bidirectional Attention Maps
Sep 05, 2019

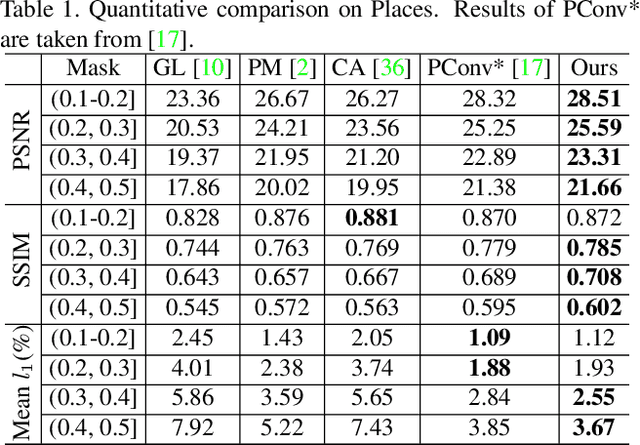
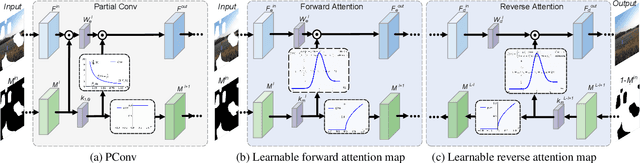

Most convolutional network (CNN)-based inpainting methods adopt standard convolution to indistinguishably treat valid pixels and holes, making them limited in handling irregular holes and more likely to generate inpainting results with color discrepancy and blurriness. Partial convolution has been suggested to address this issue, but it adopts handcrafted feature re-normalization, and only considers forward mask-updating. In this paper, we present a learnable attention map module for learning feature renormalization and mask-updating in an end-to-end manner, which is effective in adapting to irregular holes and propagation of convolution layers. Furthermore, learnable reverse attention maps are introduced to allow the decoder of U-Net to concentrate on filling in irregular holes instead of reconstructing both holes and known regions, resulting in our learnable bidirectional attention maps. Qualitative and quantitative experiments show that our method performs favorably against state-of-the-arts in generating sharper, more coherent and visually plausible inpainting results. The source code and pre-trained models will be available.
Q-FIT: The Quantifiable Feature Importance Technique for Explainable Machine Learning
Oct 26, 2020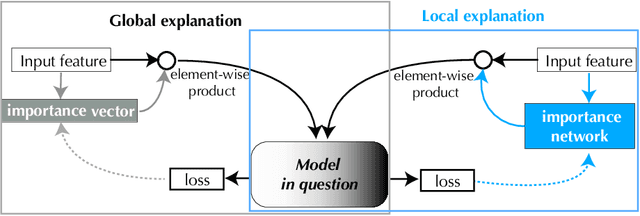
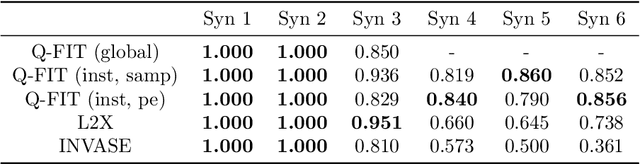
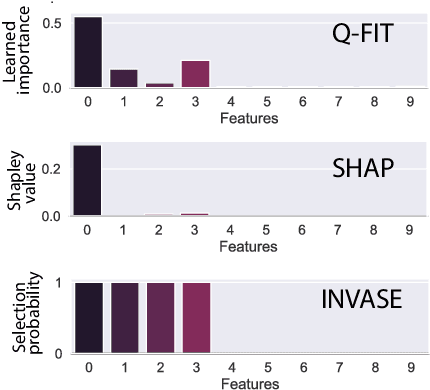

We introduce a novel framework to quantify the importance of each input feature for model explainability. A user of our framework can choose between two modes: (a) global explanation: providing feature importance globally across all the data points; and (b) local explanation: providing feature importance locally for each individual data point. The core idea of our method comes from utilizing the Dirichlet distribution to define a distribution over the importance of input features. This particular distribution is useful in ranking the importance of the input features as a sample from this distribution is a probability vector (i.e., the vector components sum to 1), Thus, the ranking uncovered by our framework which provides a \textit{quantifiable explanation} of how significant each input feature is to a model's output. This quantifiable explainability differentiates our method from existing feature-selection methods, which simply determine whether a feature is relevant or not. Furthermore, a distribution over the explanation allows to define a closed-form divergence to measure the similarity between learned feature importance under different models. We use this divergence to study how the feature importance trade-offs with essential notions in modern machine learning, such as privacy and fairness. We show the effectiveness of our method on a variety of synthetic and real datasets, taking into account both tabular and image datasets.
Convexity Shape Constraints for Image Segmentation
Sep 07, 2015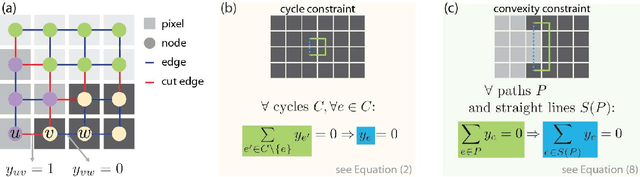

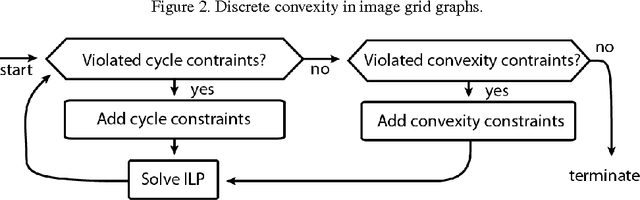

Segmenting an image into multiple components is a central task in computer vision. In many practical scenarios, prior knowledge about plausible components is available. Incorporating such prior knowledge into models and algorithms for image segmentation is highly desirable, yet can be non-trivial. In this work, we introduce a new approach that allows, for the first time, to constrain some or all components of a segmentation to have convex shapes. Specifically, we extend the Minimum Cost Multicut Problem by a class of constraints that enforce convexity. To solve instances of this APX-hard integer linear program to optimality, we separate the proposed constraints in the branch-and-cut loop of a state-of-the-art ILP solver. Results on natural and biological images demonstrate the effectiveness of the approach as well as its advantage over the state-of-the-art heuristic.
Joint Learning of Motion Estimation and Segmentation for Cardiac MR Image Sequences
Jun 11, 2018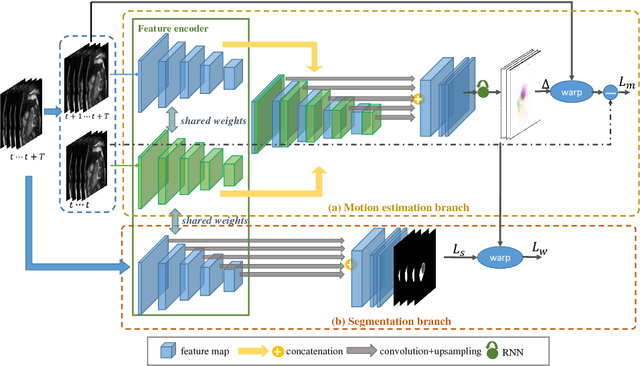

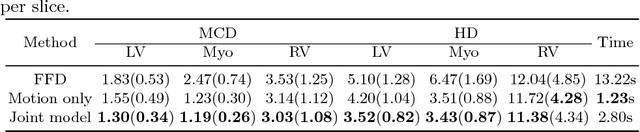
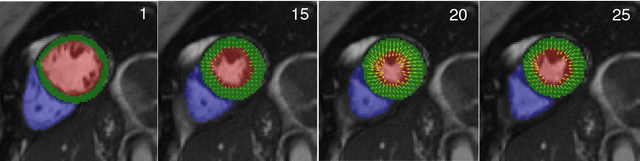
Cardiac motion estimation and segmentation play important roles in quantitatively assessing cardiac function and diagnosing cardiovascular diseases. In this paper, we propose a novel deep learning method for joint estimation of motion and segmentation from cardiac MR image sequences. The proposed network consists of two branches: a cardiac motion estimation branch which is built on a novel unsupervised Siamese style recurrent spatial transformer network, and a cardiac segmentation branch that is based on a fully convolutional network. In particular, a joint multi-scale feature encoder is learned by optimizing the segmentation branch and the motion estimation branch simultaneously. This enables the weakly-supervised segmentation by taking advantage of features that are unsupervisedly learned in the motion estimation branch from a large amount of unannotated data. Experimental results using cardiac MRI images from 220 subjects show that the joint learning of both tasks is complementary and the proposed models outperform the competing methods significantly in terms of accuracy and speed.
Overcoming Statistical Shortcuts for Open-ended Visual Counting
Jun 17, 2020



Machine learning models tend to over-rely on statistical shortcuts. These spurious correlations between parts of the input and the output labels does not hold in real-world settings. We target this issue on the recent open-ended visual counting task which is well suited to study statistical shortcuts. We aim to develop models that learn a proper mechanism of counting regardless of the output label. First, we propose the Modifying Count Distribution (MCD) protocol, which penalizes models that over-rely on statistical shortcuts. It is based on pairs of training and testing sets that do not follow the same count label distribution such as the odd-even sets. Intuitively, models that have learned a proper mechanism of counting on odd numbers should perform well on even numbers. Secondly, we introduce the Spatial Counting Network (SCN), which is dedicated to visual analysis and counting based on natural language questions. Our model selects relevant image regions, scores them with fusion and self-attention mechanisms, and provides a final counting score. We apply our protocol on the recent dataset, TallyQA, and show superior performances compared to state-of-the-art models. We also demonstrate the ability of our model to select the correct instances to count in the image. Code and datasets are available: https://github.com/cdancette/spatial-counting-network
Peak Detection On Data Independent Acquisition Mass Spectrometry Data With Semisupervised Convolutional Transformers
Oct 26, 2020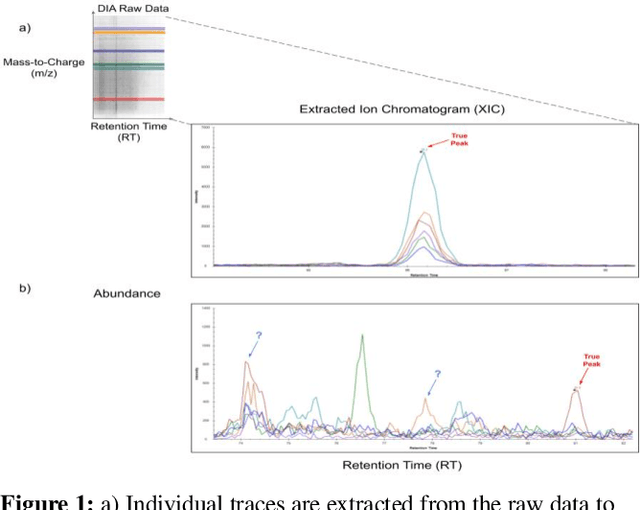

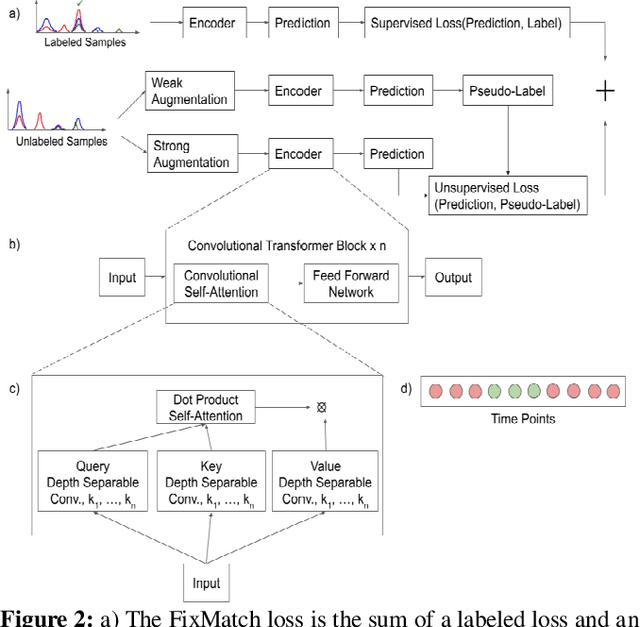

Liquid Chromatography coupled to Mass Spectrometry (LC-MS) based methods are commonly used for high-throughput, quantitative measurements of the proteome (i.e. the set of all proteins in a sample at a given time). Targeted LC-MS produces data in the form of a two-dimensional time series spectrum, with the mass to charge ratio of analytes (m/z) on one axis, and the retention time from the chromatography on the other. The elution of a peptide of interest produces highly specific patterns across multiple fragment ion traces (extracted ion chromatograms, or XICs). In this paper, we formulate this peak detection problem as a multivariate time series segmentation problem, and propose a novel approach based on the Transformer architecture. Here we augment Transformers, which are capable of capturing long distance dependencies with a global view, with Convolutional Neural Networks (CNNs), which can capture local context important to the task at hand, in the form of Transformers with Convolutional Self-Attention. We further train this model in a semisupervised manner by adapting state of the art semisupervised image classification techniques for multi-channel time series data. Experiments on a representative LC-MS dataset are benchmarked using manual annotations to showcase the encouraging performance of our method; it outperforms baseline neural network architectures and is competitive against the current state of the art in automated peak detection.
StarNet: towards weakly supervised few-shot detection and explainable few-shot classification
Mar 15, 2020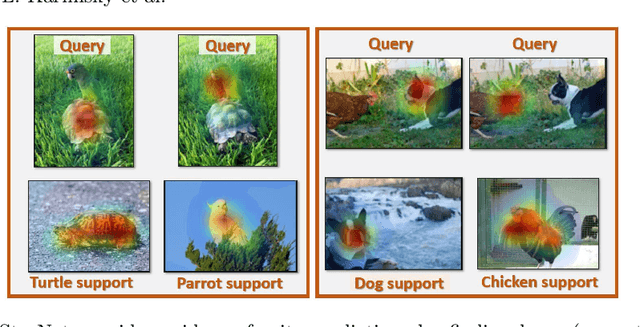
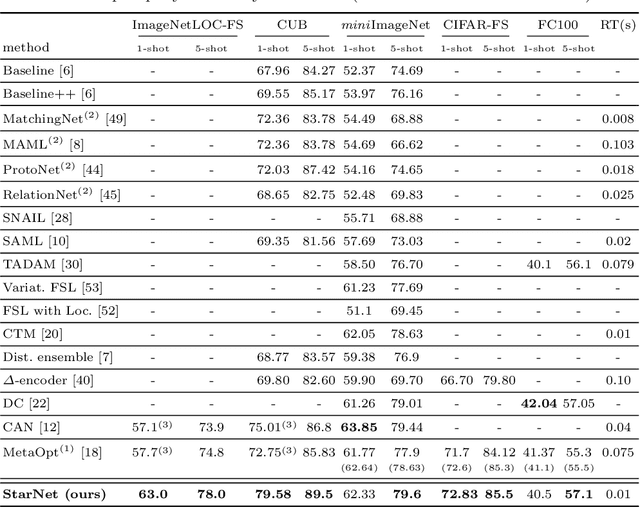
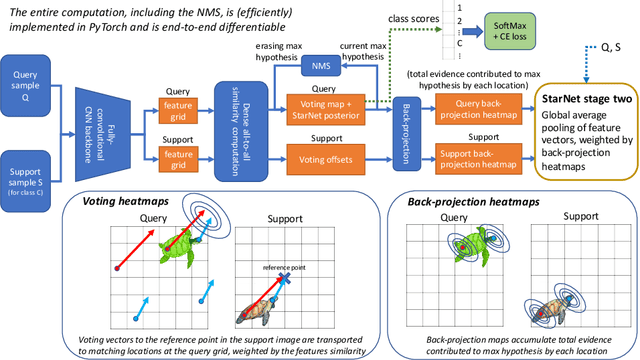
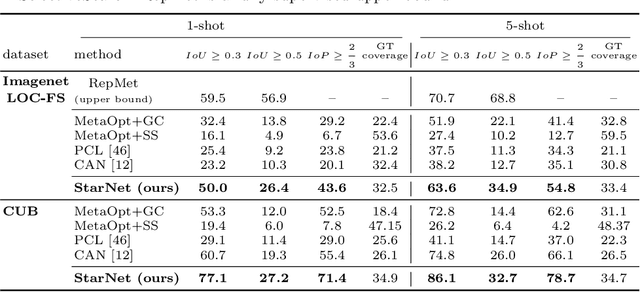
In this paper, we propose a new few-shot learning method called StarNet, which is an end-to-end trainable non-parametric star-model few-shot classifier. While being meta-trained using only image-level class labels, StarNet learns not only to predict the class labels for each query image of a few-shot task, but also to localize (via a heatmap) what it believes to be the key image regions supporting its prediction, thus effectively detecting the instances of the novel categories. The localization is enabled by the StarNet's ability to find large, arbitrarily shaped, semantically matching regions between all pairs of support and query images of a few-shot task. We evaluate StarNet on multiple few-shot classification benchmarks attaining significant state-of-the-art improvement on the CUB and ImageNetLOC-FS, and smaller improvements on other benchmarks. At the same time, in many cases, StarNet provides plausible explanations for its class label predictions, by highlighting the correctly paired novel category instances on the query and on its best matching support (for the predicted class). In addition, we test the proposed approach on the previously unexplored and challenging task of Weakly Supervised Few-Shot Object Detection (WS-FSOD), obtaining significant improvements over the baselines.
Memory-Efficient Design Strategy for a Parallel Embedded Integral Image Computation Engine
Oct 17, 2015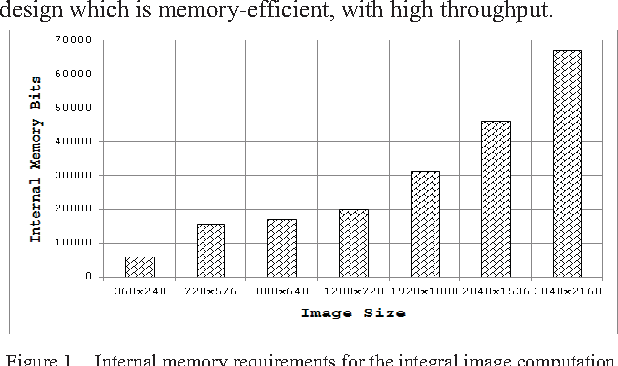
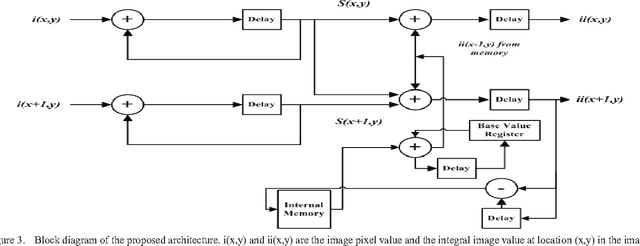
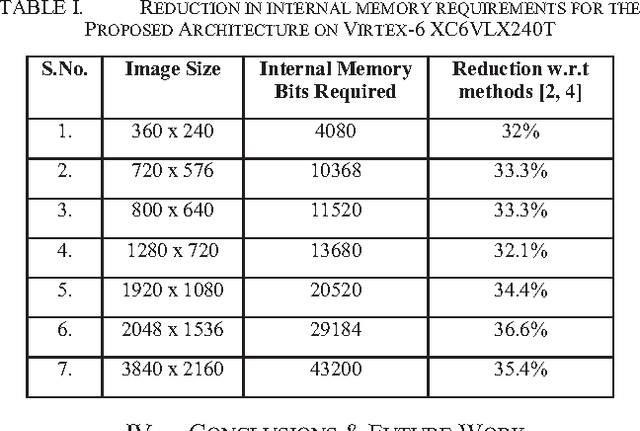
In embedded vision systems, parallel computation of the integral image presents several design challenges in terms of hardware resources, speed and power consumption. Although recursive equations significantly reduce the number of operations for computing the integral image, the required internal memory becomes prohibitively large for an embedded integral image computation engine for increasing image sizes. With the objective of achieving high-throughput with minimum hardware resources, this paper proposes a memory-efficient design strategy for a parallel embedded integral image computation engine. Results show that the design achieves nearly 35% reduction in memory for common HD video.
High Resolution Face Age Editing
May 09, 2020

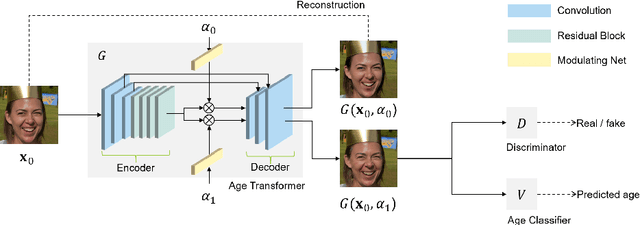
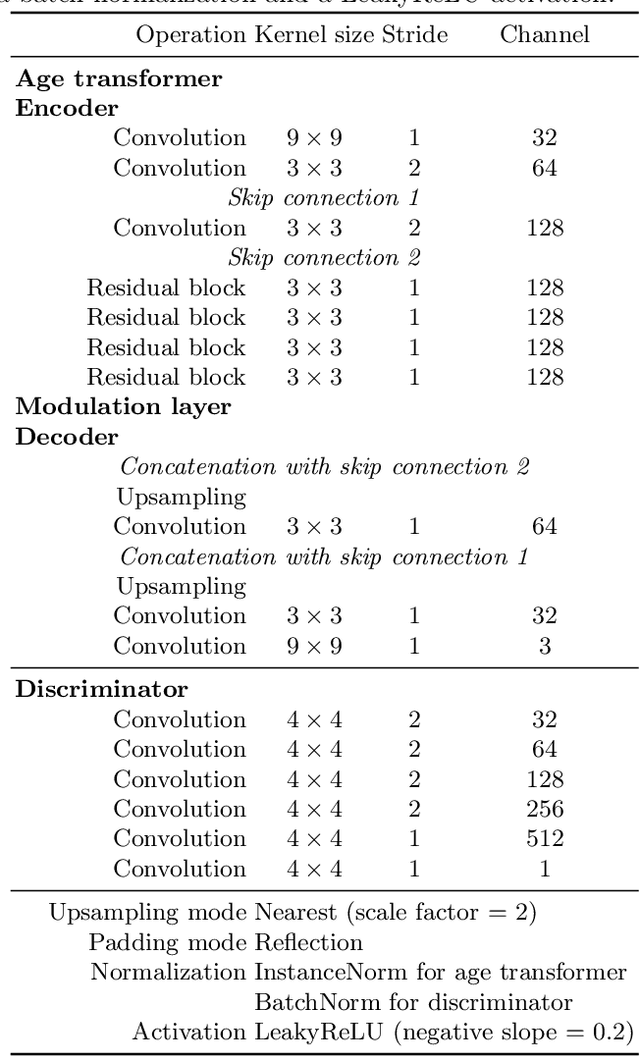
Face age editing has become a crucial task in film post-production, and is also becoming popular for general purpose photography. Recently, adversarial training has produced some of the most visually impressive results for image manipulation, including the face aging/de-aging task. In spite of considerable progress, current methods often present visual artifacts and can only deal with low-resolution images. In order to achieve aging/de-aging with the high quality and robustness necessary for wider use, these problems need to be addressed. This is the goal of the present work. We present an encoder-decoder architecture for face age editing. The core idea of our network is to create both a latent space containing the face identity, and a feature modulation layer corresponding to the age of the individual. We then combine these two elements to produce an output image of the person with a desired target age. Our architecture is greatly simplified with respect to other approaches, and allows for continuous age editing on high resolution images in a single unified model.
Investigation of REFINED CNN ensemble learning for anti-cancer drug sensitivity prediction
Sep 09, 2020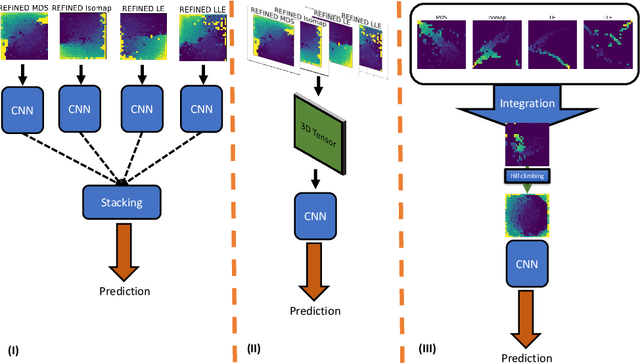
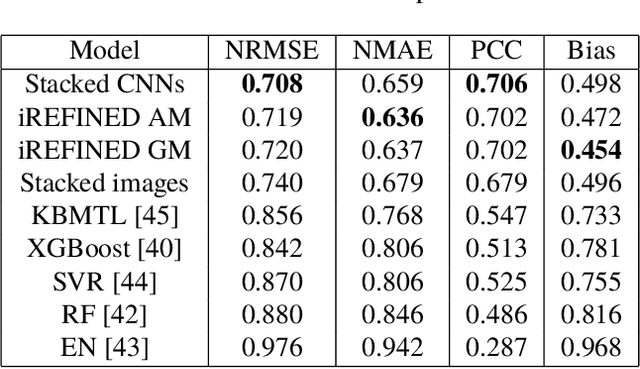
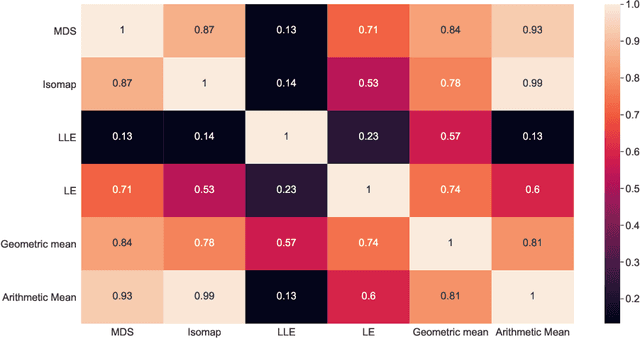
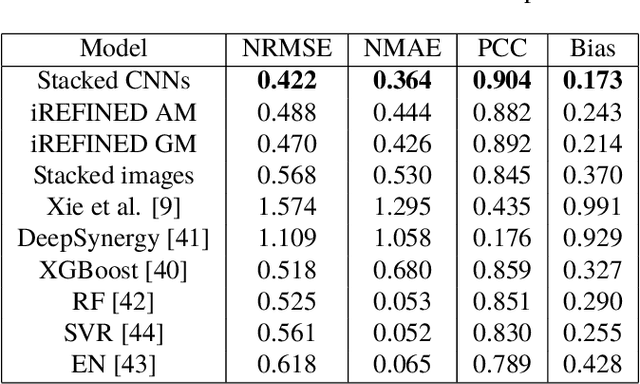
Anti-cancer drug sensitivity prediction using deep learning models for individual cell line is a significant challenge in personalized medicine. REFINED (REpresentation of Features as Images with NEighborhood Dependencies) CNN (Convolutional Neural Network) based models have shown promising results in drug sensitivity prediction. The primary idea behind REFINED CNN is representing high dimensional vectors as compact images with spatial correlations that can benefit from convolutional neural network architectures. However, the mapping from a vector to a compact 2D image is not unique due to variations in considered distance measures and neighborhoods. In this article, we consider predictions based on ensembles built from such mappings that can improve upon the best single REFINED CNN model prediction. Results illustrated using NCI60 and NCIALMANAC databases shows that the ensemble approaches can provide significant performance improvement as compared to individual models. We further illustrate that a single mapping created from the amalgamation of the different mappings can provide performance similar to stacking ensemble but with significantly lower computational complexity.