 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to Caricature via Semantic Shape Transform
Aug 12, 2020


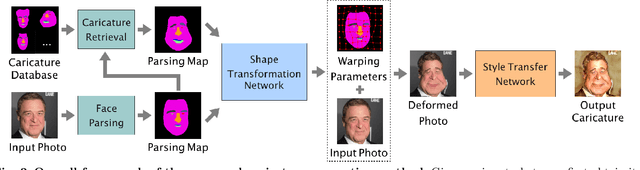
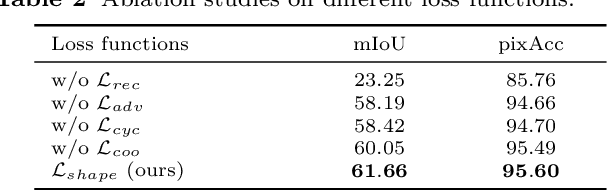
Caricature is an artistic drawing created to abstract or exaggerate facial features of a person. Rendering visually pleasing caricatures is a difficult task that requires professional skills, and thus it is of great interest to design a method to automatically generate such drawings. To deal with large shape changes, we propose an algorithm based on a semantic shape transform to produce diverse and plausible shape exaggerations. Specifically, we predict pixel-wise semantic correspondences and perform image warping on the input photo to achieve dense shape transformation. We show that the proposed framework is able to render visually pleasing shape exaggerations while maintaining their facial structures. In addition, our model allows users to manipulate the shape via the semantic map. We demonstrate the effectiveness of our approach on a large photograph-caricature benchmark dataset with comparisons to the state-of-the-art methods.
Deep learning mediated single time-point image-based prediction of embryo developmental outcome at the cleavage stage
May 21, 2020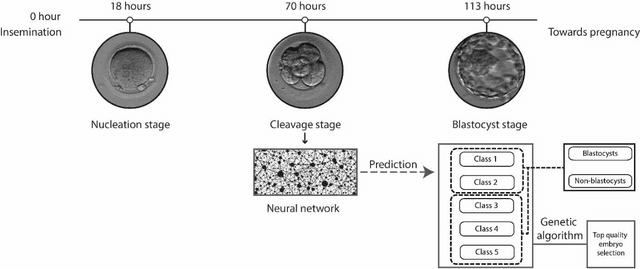
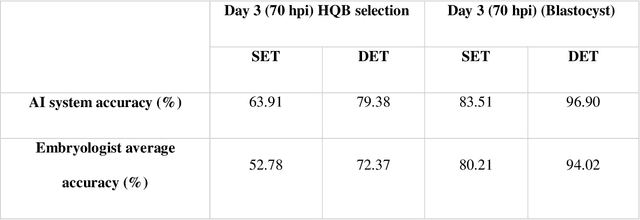
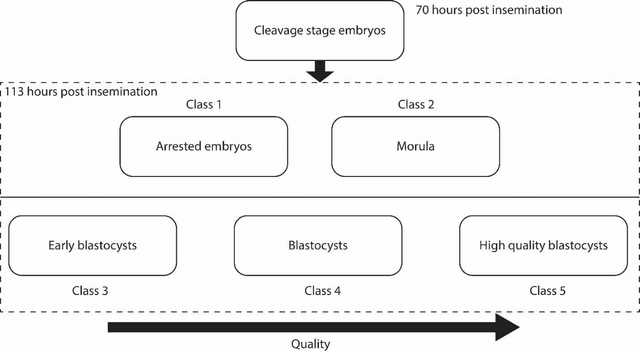
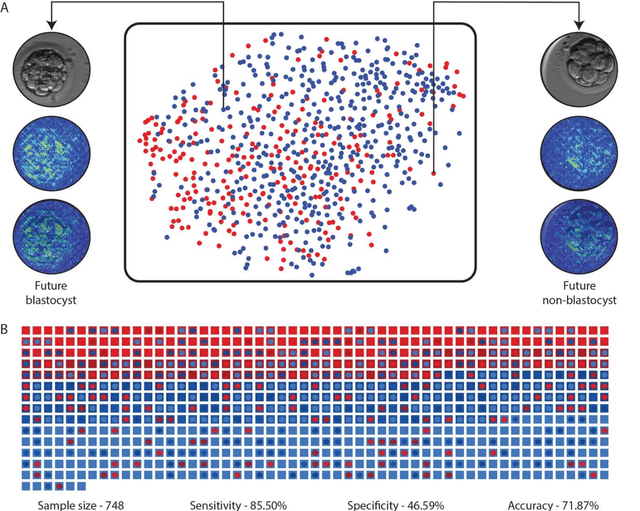
In conventional clinical in-vitro fertilization practices embryos are transferred either at the cleavage or blastocyst stages of development. Cleavage stage transfers, particularly, are beneficial for patients with relatively poor prognosis and at fertility centers in resource-limited settings where there is a higher chance of developmental failure in embryos in-vitro. However, one of the major limitations of embryo selections at the cleavage stage is the availability of very low number of manually discernable features to predict developmental outcomes. Although, time-lapse imaging systems have been proposed as possible solutions, they are cost-prohibitive and require bulky and expensive hardware, and labor-intensive. Advances in convolutional neural networks (CNNs) have been utilized to provide accurate classifications across many medical and non-medical object categories. Here, we report an automated system for classification and selection of human embryos at the cleavage stage using a trained CNN combined with a genetic algorithm. The system selected the cleavage stage embryo at 70 hours post insemination (hpi) that ultimately developed into top-quality blastocyst at 70 hpi with 64% accuracy, outperforming the abilities of embryologists in identifying embryos with the highest developmental potential. Such systems can have a significant impact on IVF procedures by empowering embryologists for accurate and consistent embryo assessment in both resource-poor and resource-rich settings.
Object Instance Mining for Weakly Supervised Object Detection
Feb 04, 2020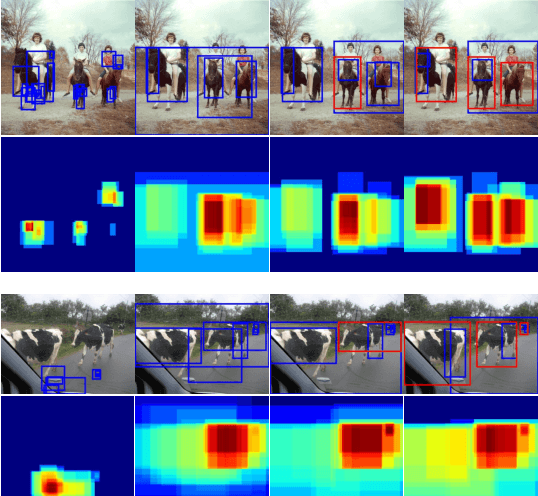
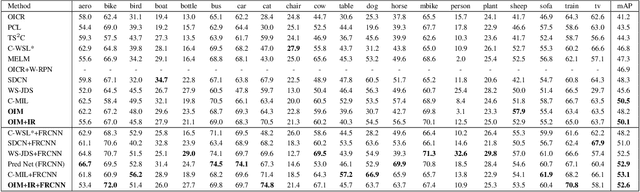
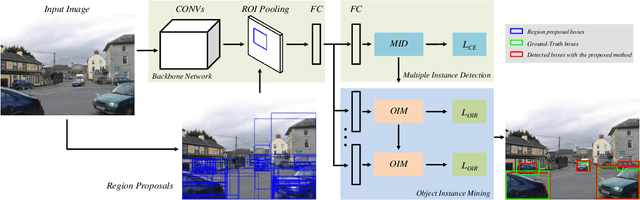
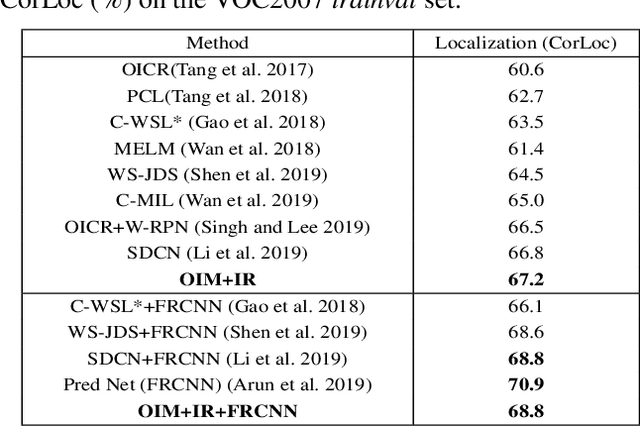
Weakly supervised object detection (WSOD) using only image-level annotations has attracted growing attention over the past few years. Existing approaches using multiple instance learning easily fall into local optima, because such mechanism tends to learn from the most discriminative object in an image for each category. Therefore, these methods suffer from missing object instances which degrade the performance of WSOD. To address this problem, this paper introduces an end-to-end object instance mining (OIM) framework for weakly supervised object detection. OIM attempts to detect all possible object instances existing in each image by introducing information propagation on the spatial and appearance graphs, without any additional annotations. During the iterative learning process, the less discriminative object instances from the same class can be gradually detected and utilized for training. In addition, we design an object instance reweighted loss to learn larger portion of each object instance to further improve the performance. The experimental results on two publicly available databases, VOC 2007 and 2012, demonstrate the efficacy of proposed approach.
Real Time Detection of Small Objects
Mar 17, 2020
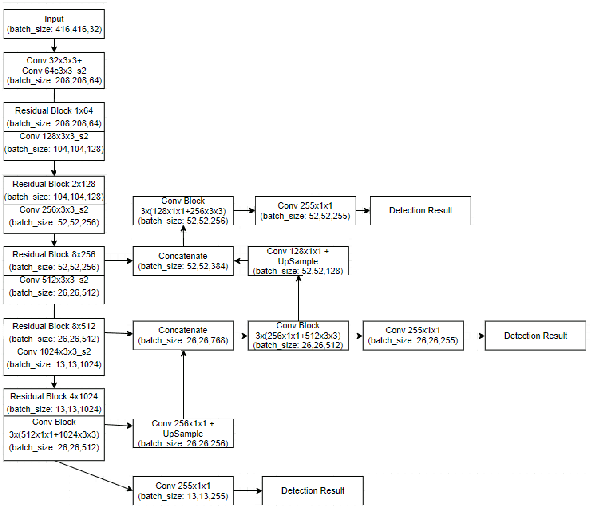
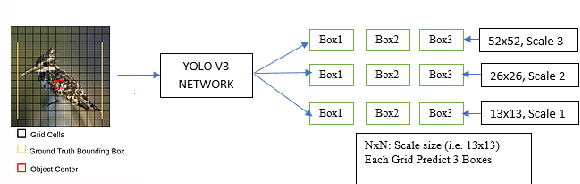
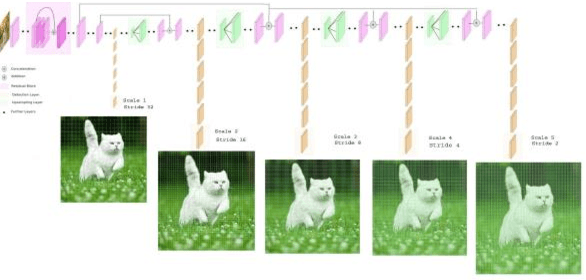
The existing real time object detection algorithm is based on the deep neural network of convolution need to perform multilevel convolution and pooling operations on the entire image to extract a deep semantic characteristic of the image. The detection models perform better for large objects. However, these models do not detect small objects with low resolution and noise, because the features of existing models do not fully represent the essential features of small objects after repeated convolution operations. We have introduced a novel real time detection algorithm which employs upsampling and skip connection to extract multiscale features at different convolution levels in a learning task resulting a remarkable performance in detecting small objects. The detection precision of the model is shown to be higher and faster than that of the state-of-the-art models.
* 7 pages, 9 figures
Multiple instance learning on deep features for weakly supervised object detection with extreme domain shifts
Aug 03, 2020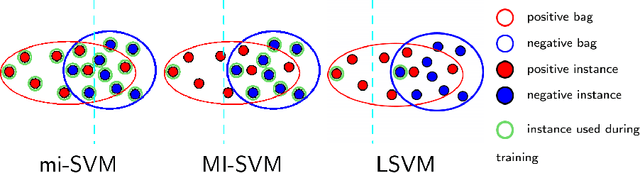
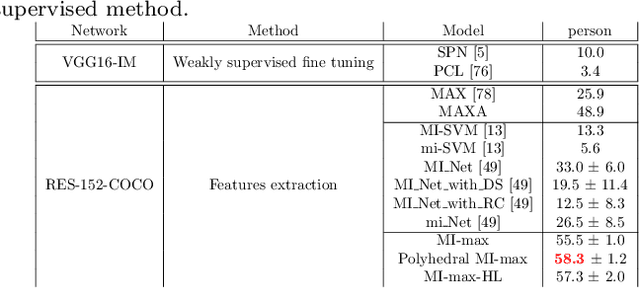
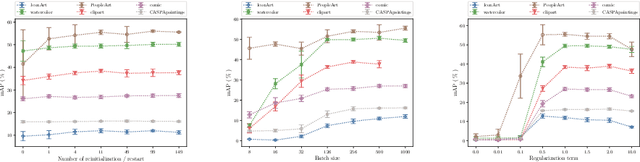
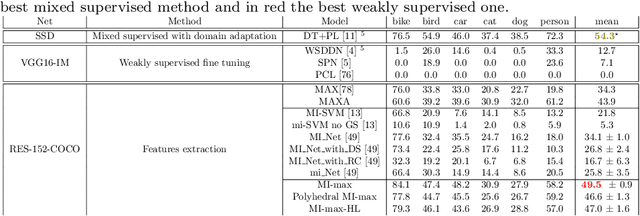
Weakly supervised object detection (WSOD) using only image-level annotations has attracted a growing attention over the past few years. Whereas such task is typically addressed with a domain-specific solution focused on natural images, we show that a simple multiple instance approach applied on pre-trained deep features yields excellent performances on non-photographic datasets, possibly including new classes. The approach does not include any fine-tuning or cross-domain learning and is therefore efficient and possibly applicable to arbitrary datasets and classes. We investigate several flavors of the proposed approach, some including multi-layers perceptron and polyhedral classifiers. Despite its simplicity, our method shows competitive results on a range of publicly available datasets, including paintings (People-Art, IconArt), watercolors, cliparts and comics and allows to quickly learn unseen visual categories.
Indirect Object-to-Robot Pose Estimation from an External Monocular RGB Camera
Aug 26, 2020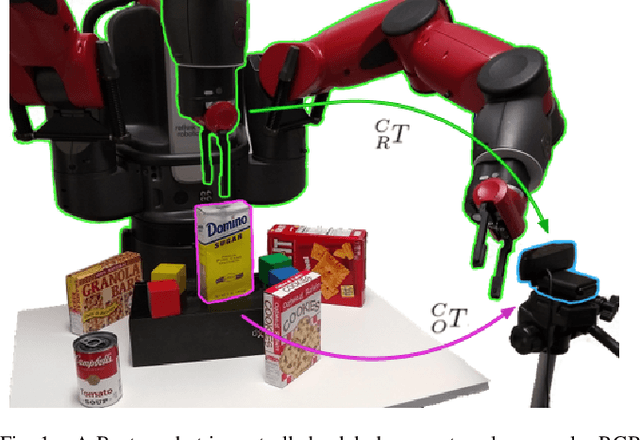


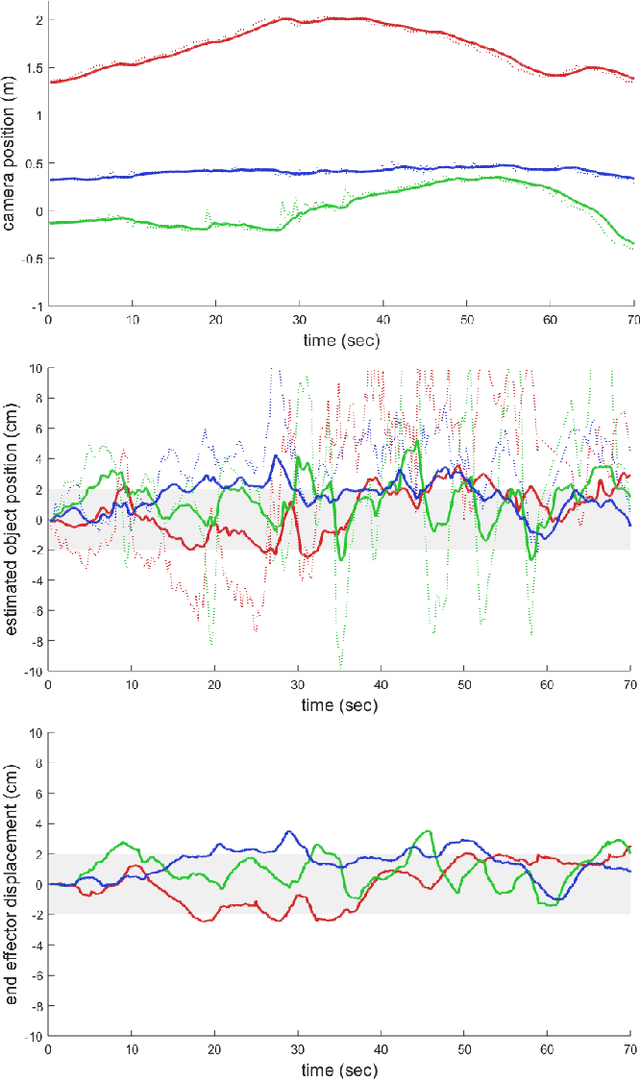
We present a robotic grasping system that uses a single external monocular RGB camera as input. The object-to-robot pose is computed indirectly by combining the output of two neural networks: one that estimates the object-to-camera pose, and another that estimates the robot-to-camera pose. Both networks are trained entirely on synthetic data, relying on domain randomization to bridge the sim-to-real gap. Because the latter network performs online camera calibration, the camera can be moved freely during execution without affecting the quality of the grasp. Experimental results analyze the effect of camera placement, image resolution, and pose refinement in the context of grasping several household objects. We also present results on a new set of 28 textured household toy grocery objects, which have been selected to be accessible to other researchers. To aid reproducibility of the research, we offer 3D scanned textured models, along with pre-trained weights for pose estimation.
Improving One-stage Visual Grounding by Recursive Sub-query Construction
Aug 03, 2020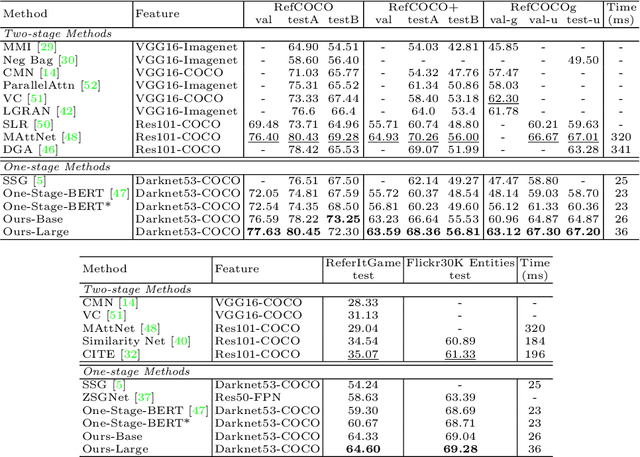

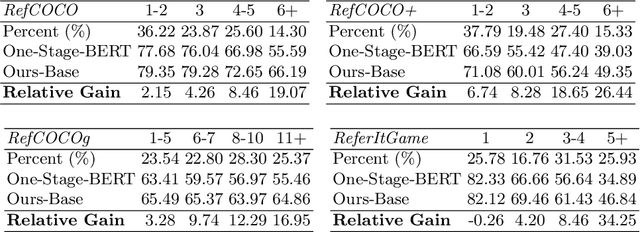
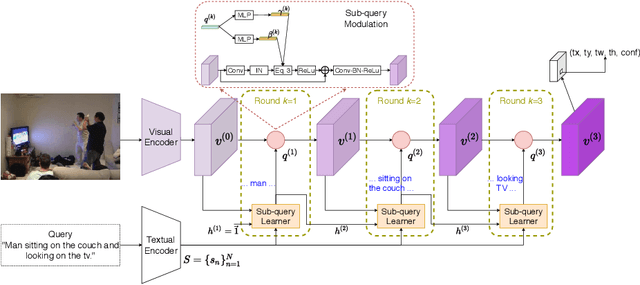
We improve one-stage visual grounding by addressing current limitations on grounding long and complex queries. Existing one-stage methods encode the entire language query as a single sentence embedding vector, e.g., taking the embedding from BERT or the hidden state from LSTM. This single vector representation is prone to overlooking the detailed descriptions in the query. To address this query modeling deficiency, we propose a recursive sub-query construction framework, which reasons between image and query for multiple rounds and reduces the referring ambiguity step by step. We show our new one-stage method obtains 5.0%, 4.5%, 7.5%, 12.8% absolute improvements over the state-of-the-art one-stage baseline on ReferItGame, RefCOCO, RefCOCO+, and RefCOCOg, respectively. In particular, superior performances on longer and more complex queries validates the effectiveness of our query modeling.
Pyramid Convolutional RNN for MRI Reconstruction
Dec 03, 2019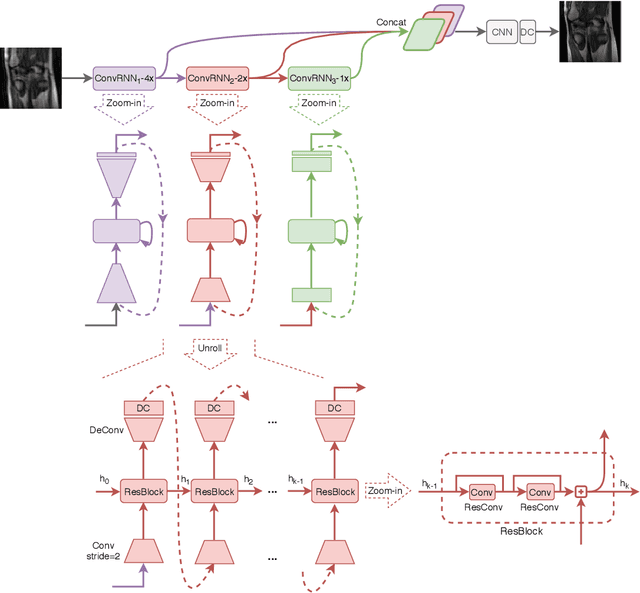
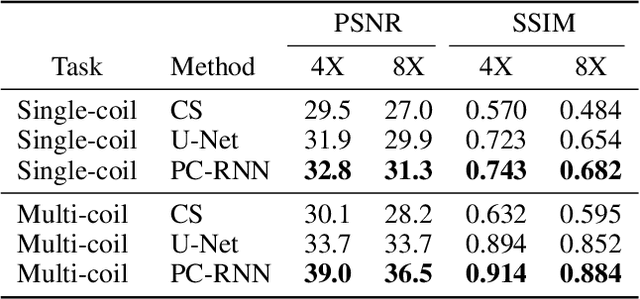
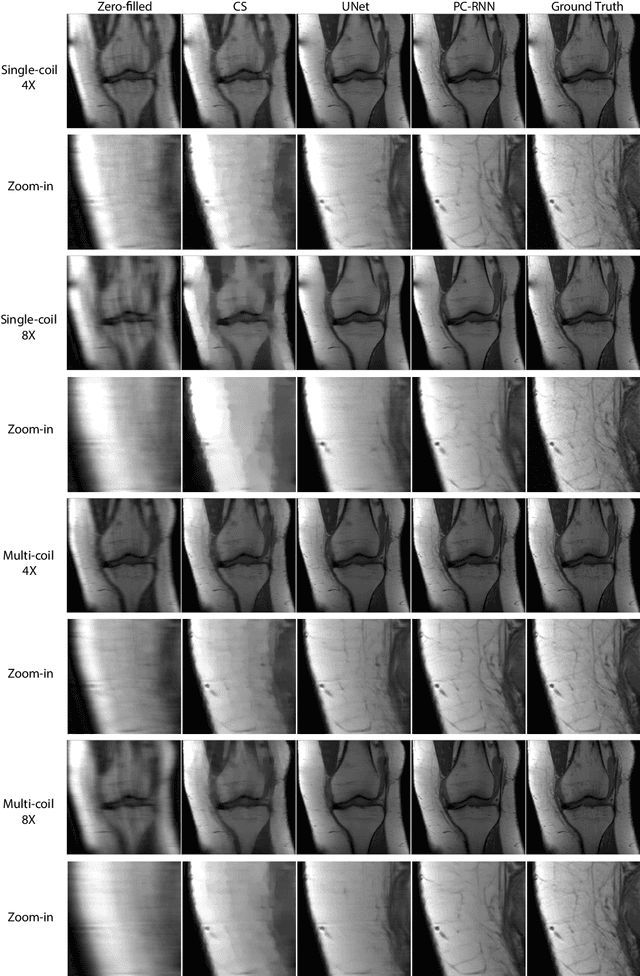
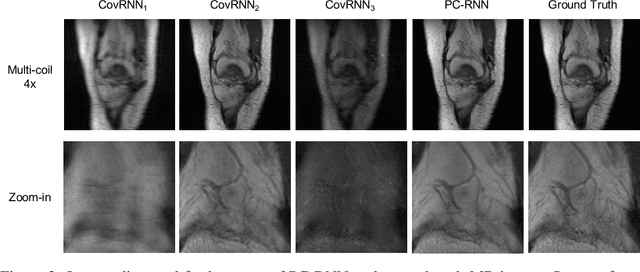
Fast and accurate MRI image reconstruction from undersampled data is critically important in clinical practice. Compressed sensing based methods are widely used in image reconstruction but the speed is slow due to the iterative algorithms. Deep learning based methods have shown promising advances in recent years. However, recovering the fine details from highly undersampled data is still challenging. In this paper, we introduce a novel deep learning-based method, Pyramid Convolutional RNN (PC-RNN), to reconstruct the image from multiple scales. We evaluated our model on the fastMRI dataset and the results show that the proposed model achieves significant improvements than other methods and can recover more fine details.
Mitigating Bias in Set Selection with Noisy Protected Attributes
Nov 09, 2020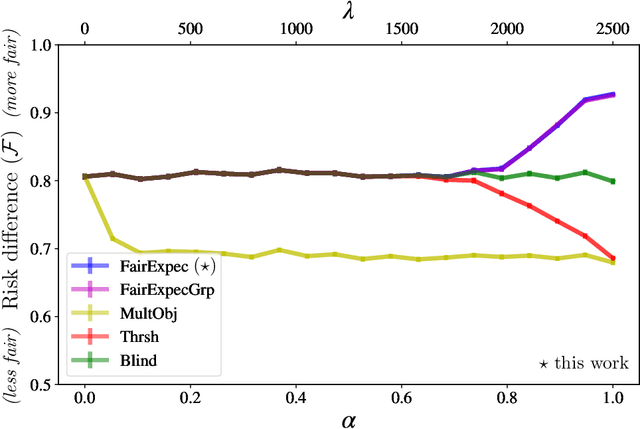
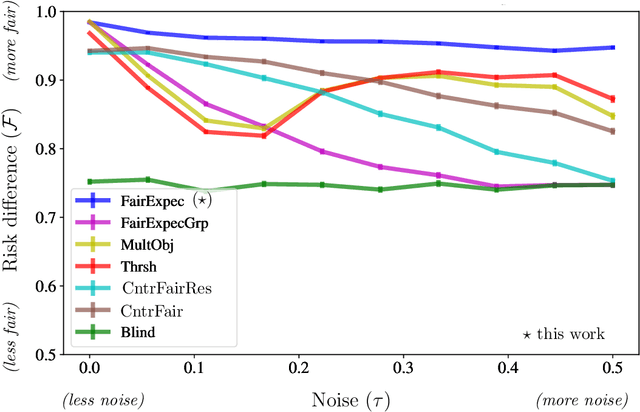
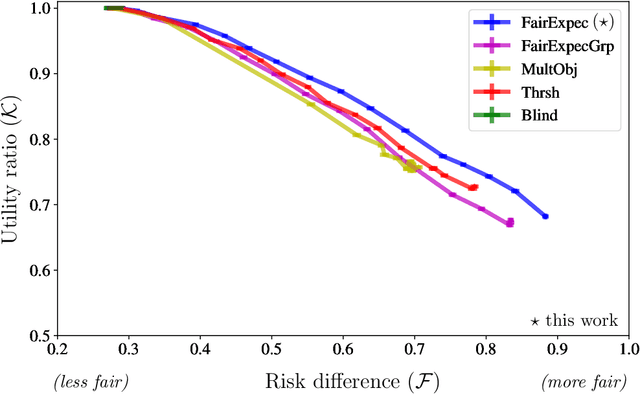

Subset selection algorithms are ubiquitous in AI-driven applications, including, online recruiting portals and image search engines, so it is imperative that these tools are not discriminatory on the basis of protected attributes such as gender or race. Currently, fair subset selection algorithms assume that the protected attributes are known as part of the dataset. However, attributes may be noisy due to errors during data collection or if they are imputed (as is often the case in real-world settings). While a wide body of work addresses the effect of noise on the performance of machine learning algorithms, its effect on fairness remains largely unexamined. We find that in the presence of noisy protected attributes, in attempting to increase fairness without considering noise, one can, in fact, decrease the fairness of the result! Towards addressing this, we consider an existing noise model in which there is probabilistic information about the protected attributes (e.g.,[19, 32, 56, 44]), and ask is fair selection is possible under noisy conditions? We formulate a ``denoised'' selection problem which functions for a large class of fairness metrics; given the desired fairness goal, the solution to the denoised problem violates the goal by at most a small multiplicative amount with high probability. Although the denoised problem turns out to be NP-hard, we give a linear-programming based approximation algorithm for it. We empirically evaluate our approach on both synthetic and real-world datasets. Our empirical results show that this approach can produce subsets which significantly improve the fairness metrics despite the presence of noisy protected attributes, and, compared to prior noise-oblivious approaches, has better Pareto-tradeoffs between utility and fairness.
Three-Dimensional Lip Motion Network for Text-Independent Speaker Recognition
Oct 13, 2020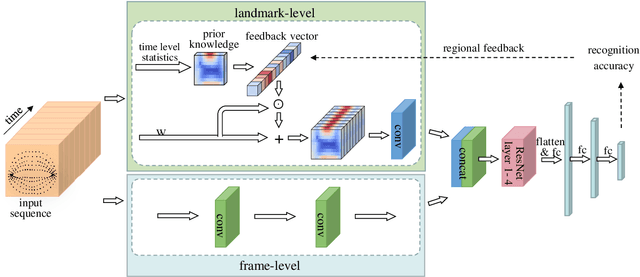
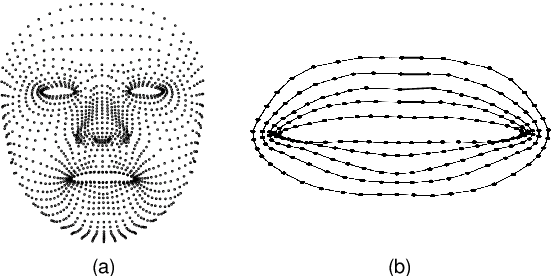

Lip motion reflects behavior characteristics of speakers, and thus can be used as a new kind of biometrics in speaker recognition. In the literature, lots of works used two-dimensional (2D) lip images to recognize speaker in a textdependent context. However, 2D lip easily suffers from various face orientations. To this end, in this work, we present a novel end-to-end 3D lip motion Network (3LMNet) by utilizing the sentence-level 3D lip motion (S3DLM) to recognize speakers in both the text-independent and text-dependent contexts. A new regional feedback module (RFM) is proposed to obtain attentions in different lip regions. Besides, prior knowledge of lip motion is investigated to complement RFM, where landmark-level and frame-level features are merged to form a better feature representation. Moreover, we present two methods, i.e., coordinate transformation and face posture correction to pre-process the LSD-AV dataset, which contains 68 speakers and 146 sentences per speaker. The evaluation results on this dataset demonstrate that our proposed 3LMNet is superior to the baseline models, i.e., LSTM, VGG-16 and ResNet-34, and outperforms the state-of-the-art using 2D lip image as well as the 3D face. The code of this work is released at https://github.com/wutong18/Three-Dimensional-Lip- Motion-Network-for-Text-Independent-Speaker-Recognition.