 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
NODIS: Neural Ordinary Differential Scene Understanding
Jan 14, 2020
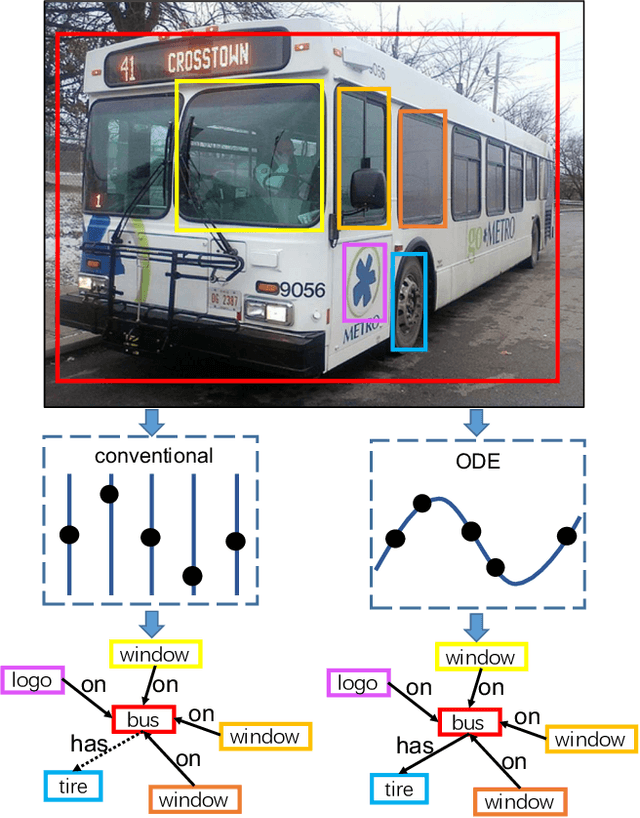
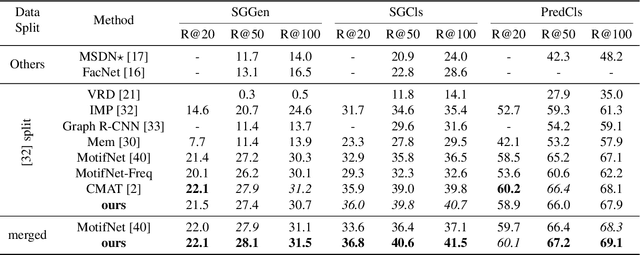
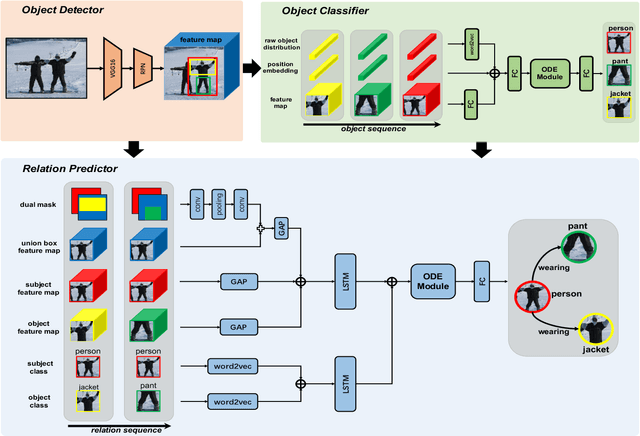

Semantic image understanding is a challenging topic in computer vision. It requires to detect all objects in an image, but also to identify all the relations between them. Detected objects, their labels and the discovered relations can be used to construct a scene graph which provides an abstract semantic interpretation of an image. In previous works, relations were identified by solving an assignment problem formulated as Mixed-Integer Linear Programs. In this work, we interpret that formulation as Ordinary Differential Equation (ODE). The proposed architecture performs scene graph inference by solving a neural variant of an ODE by end-to-end learning. It achieves state-of-the-art results on all three benchmark tasks: scene graph generation (SGGen), classification (SGCls) and visual relationship detection (PredCls) on Visual Genome benchmark.
Generation of High Dynamic Range Illumination from a Single Image for the Enhancement of Undesirably Illuminated Images
Aug 02, 2017



This paper presents an algorithm that enhances undesirably illuminated images by generating and fusing multi-level illuminations from a single image.The input image is first decomposed into illumination and reflectance components by using an edge-preserving smoothing filter. Then the reflectance component is scaled up to improve the image details in bright areas. The illumination component is scaled up and down to generate several illumination images that correspond to certain camera exposure values different from the original. The virtual multi-exposure illuminations are blended into an enhanced illumination, where we also propose a method to generate appropriate weight maps for the tone fusion. Finally, an enhanced image is obtained by multiplying the equalized illumination and enhanced reflectance. Experiments show that the proposed algorithm produces visually pleasing output and also yields comparable objective results to the conventional enhancement methods, while requiring modest computational loads.
Histopathological Stain Transfer using Style Transfer Network with Adversarial Loss
Oct 06, 2020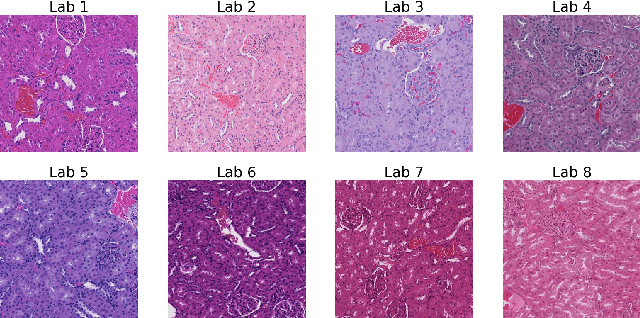

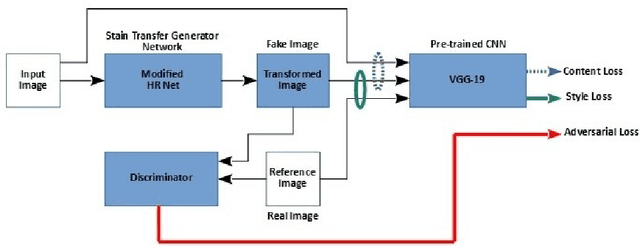
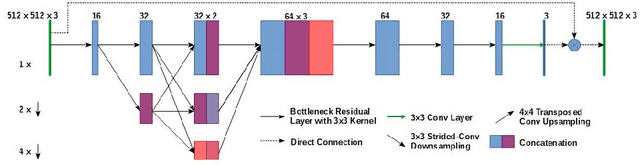
Deep learning models that are trained on histopathological images obtained from a single lab and/or scanner give poor inference performance on images obtained from another scanner/lab with a different staining protocol. In recent years, there has been a good amount of research done for image stain normalization to address this issue. In this work, we present a novel approach for the stain normalization problem using fast neural style transfer coupled with adversarial loss. We also propose a novel stain transfer generator network based on High-Resolution Network (HRNet) which requires less training time and gives good generalization with few paired training images of reference stain and test stain. This approach has been tested on Whole Slide Images (WSIs) obtained from 8 different labs, where images from one lab were treated as a reference stain. A deep learning model was trained on this stain and the rest of the images were transferred to it using the corresponding stain transfer generator network. Experimentation suggests that this approach is able to successfully perform stain normalization with good visual quality and provides better inference performance compared to not applying stain normalization.
Freehand Ultrasound Image Simulation with Spatially-Conditioned Generative Adversarial Networks
Jul 17, 2017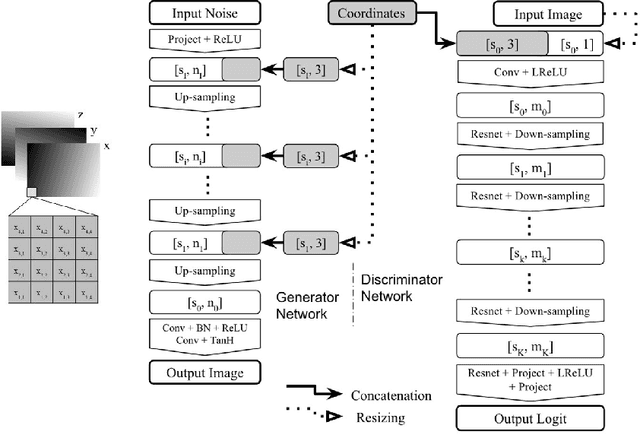
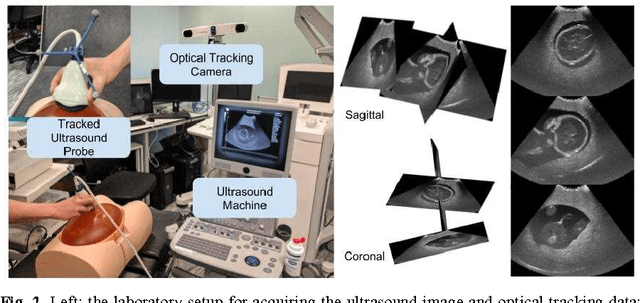
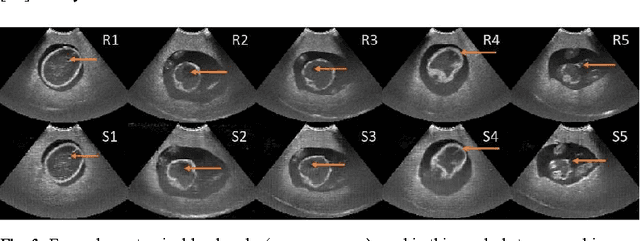
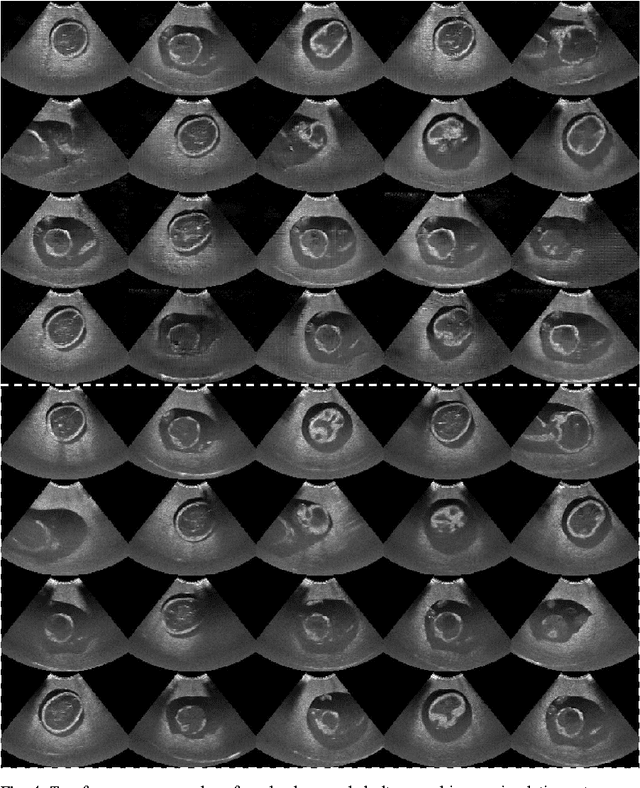
Sonography synthesis has a wide range of applications, including medical procedure simulation, clinical training and multimodality image registration. In this paper, we propose a machine learning approach to simulate ultrasound images at given 3D spatial locations (relative to the patient anatomy), based on conditional generative adversarial networks (GANs). In particular, we introduce a novel neural network architecture that can sample anatomically accurate images conditionally on spatial position of the (real or mock) freehand ultrasound probe. To ensure an effective and efficient spatial information assimilation, the proposed spatially-conditioned GANs take calibrated pixel coordinates in global physical space as conditioning input, and utilise residual network units and shortcuts of conditioning data in the GANs' discriminator and generator, respectively. Using optically tracked B-mode ultrasound images, acquired by an experienced sonographer on a fetus phantom, we demonstrate the feasibility of the proposed method by two sets of quantitative results: distances were calculated between corresponding anatomical landmarks identified in the held-out ultrasound images and the simulated data at the same locations unseen to the networks; a usability study was carried out to distinguish the simulated data from the real images. In summary, we present what we believe are state-of-the-art visually realistic ultrasound images, simulated by the proposed GAN architecture that is stable to train and capable of generating plausibly diverse image samples.
Semantic Adversarial Perturbations using Learnt Representations
Jan 29, 2020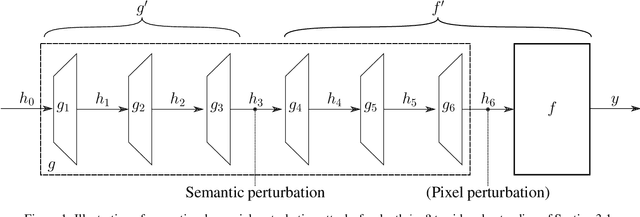
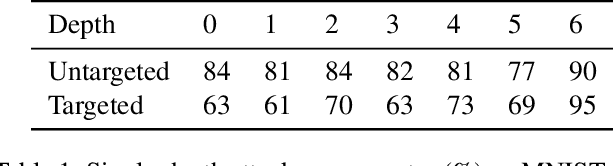
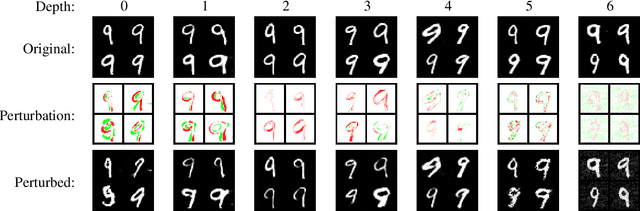
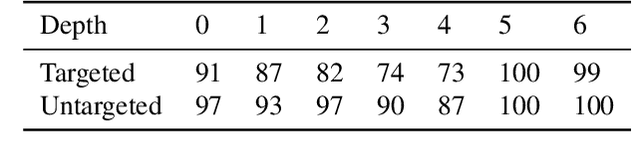
Adversarial examples for image classifiers are typically created by searching for a suitable norm-constrained perturbation to the pixels of an image. However, such perturbations represent only a small and rather contrived subset of possible adversarial inputs; robustness to norm-constrained pixel perturbations alone is insufficient. We introduce a novel method for the construction of a rich new class of semantic adversarial examples. Leveraging the hierarchical feature representations learnt by generative models, our procedure makes adversarial but realistic changes at different levels of semantic granularity. Unlike prior work, this is not an ad-hoc algorithm targeting a fixed category of semantic property. For instance, our approach perturbs the pose, location, size, shape, colour and texture of the objects in an image without manual encoding of these concepts. We demonstrate this new attack by creating semantic adversarial examples that fool state-of-the-art classifiers on the MNIST and ImageNet datasets.
Information Mandala: Statistical Distance Matrix with Its Clustering
Jun 07, 2020

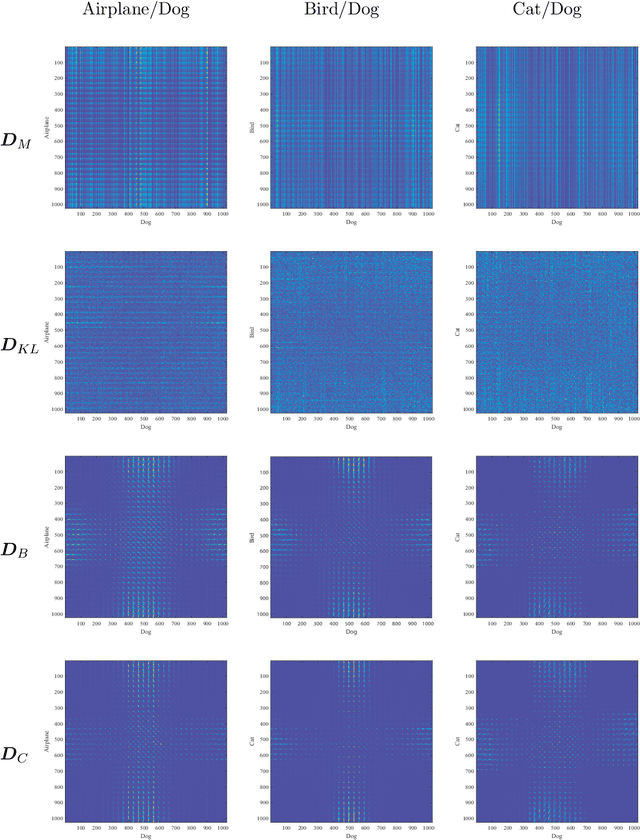
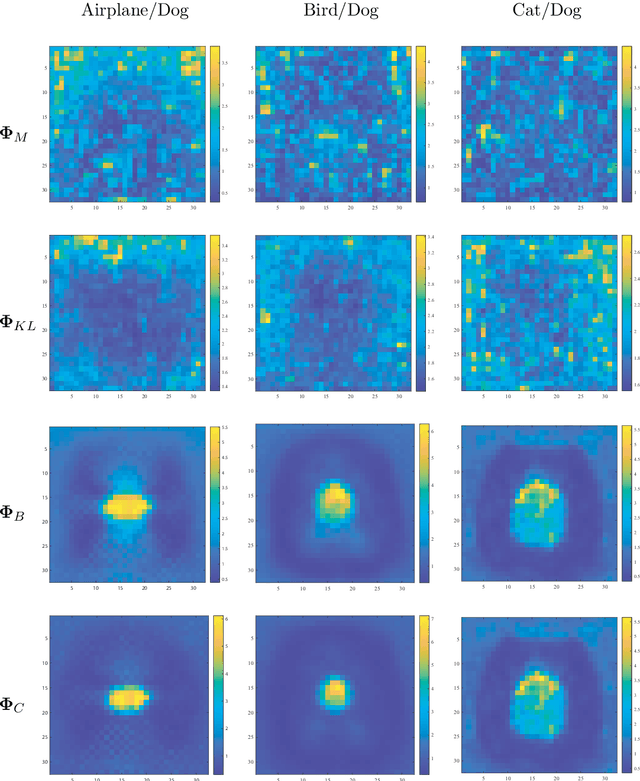
In machine learning, observation features are measured in a metric space to get their distance function for optimization. Given the similar features are many enough as a population in statistics, a statistical distance between two probability distributions can be calculated for more precise learning than before. Moreover, the statistical distance is still efficient enough, provided the observed features are multi-valued, but due to its scalar output it cannot be applied to represent detailed distances between feature elements. To resolve this problem, this paper extends the traditional statistical distance to a matrix form, referred as to statistical distance matrix, to achieve distance refinement. In experiments, the proposed statistical distance matrix performs so well in object recognition as to clearly and intuitively represent the differences between cat and dog images in the CIFAR dataset, even if it is directly calculated using the image pixels. By using the hierarchical clustering of the statistical distance matrix, the image pixels can be separated into several classes that are geometrically arranged around a center, like a Mandala pattern. The statistical distance matrix with its clustering called Information Mandala is beyond ordinary saliency map and helps to understand the basic principles of the convolution neural network.
Profile Based Sub-Image Search in Image Databases
Oct 07, 2010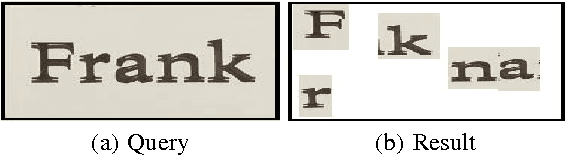
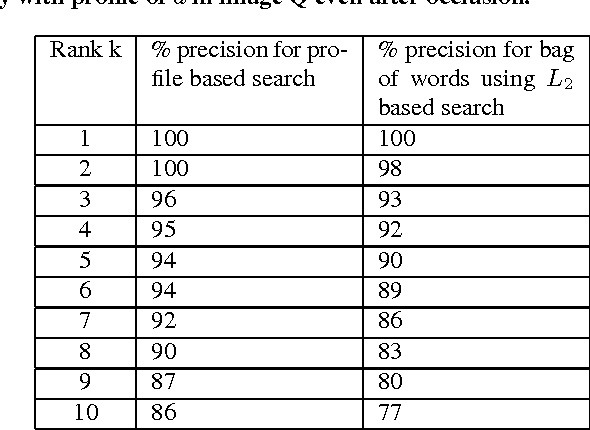

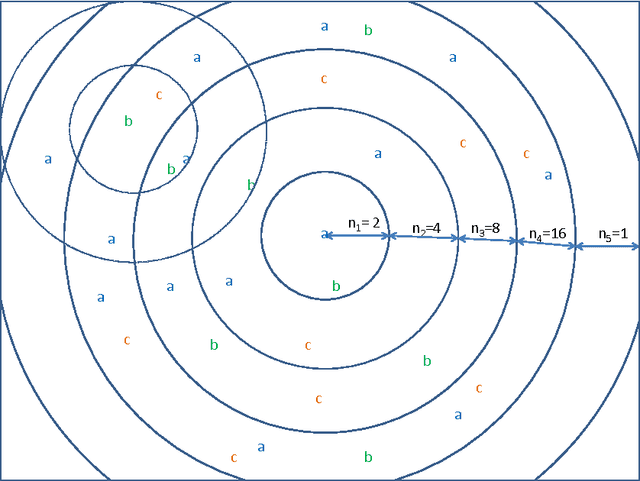
Sub-image search with high accuracy in natural images still remains a challenging problem. This paper proposes a new feature vector called profile for a keypoint in a bag of visual words model of an image. The profile of a keypoint captures the spatial geometry of all the other keypoints in an image with respect to itself, and is very effective in discriminating true matches from false matches. Sub-image search using profiles is a single-phase process requiring no geometric validation, yields high precision on natural images, and works well on small visual codebook. The proposed search technique differs from traditional methods that first generate a set of candidates disregarding spatial information and then verify them geometrically. Conventional methods also use large codebooks. We achieve a precision of 81% on a combined data set of synthetic and real natural images using a codebook size of 500 for top-10 queries; that is 31% higher than the conventional candidate generation approach.
Training Deep Neural Networks for Wireless Sensor Networks Using Loosely and Weakly Labeled Images
Oct 06, 2020
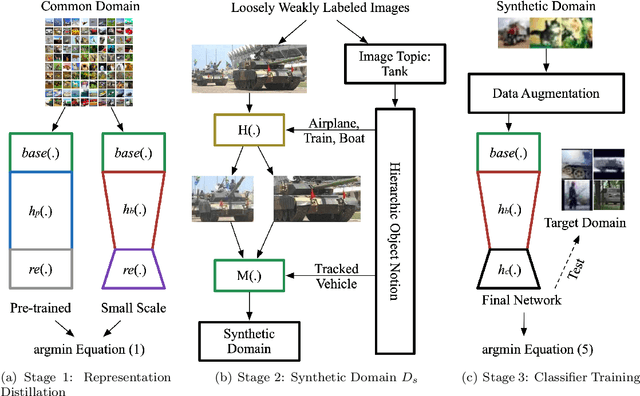

Although deep learning has achieved remarkable successes over the past years, few reports have been published about applying deep neural networks to Wireless Sensor Networks (WSNs) for image targets recognition where data, energy, computation resources are limited. In this work, a Cost-Effective Domain Generalization (CEDG) algorithm has been proposed to train an efficient network with minimum labor requirements. CEDG transfers networks from a publicly available source domain to an application-specific target domain through an automatically allocated synthetic domain. The target domain is isolated from parameters tuning and used for model selection and testing only. The target domain is significantly different from the source domain because it has new target categories and is consisted of low-quality images that are out of focus, low in resolution, low in illumination, low in photographing angle. The trained network has about 7M (ResNet-20 is about 41M) multiplications per prediction that is small enough to allow a digital signal processor chip to do real-time recognitions in our WSN. The category-level averaged error on the unseen and unbalanced target domain has been decreased by 41.12%.
Wasserstein Routed Capsule Networks
Jul 22, 2020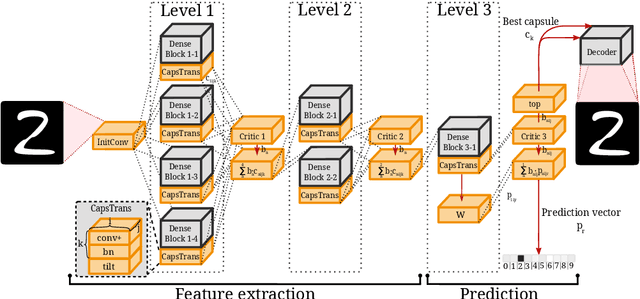
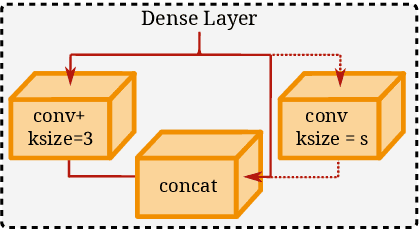
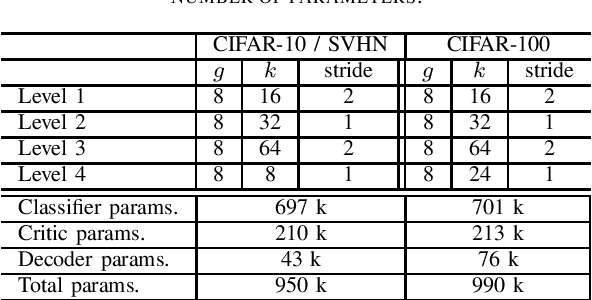

Capsule networks offer interesting properties and provide an alternative to today's deep neural network architectures. However, recent approaches have failed to consistently achieve competitive results across different image datasets. We propose a new parameter efficient capsule architecture, that is able to tackle complex tasks by using neural networks trained with an approximate Wasserstein objective to dynamically select capsules throughout the entire architecture. This approach focuses on implementing a robust routing scheme, which can deliver improved results using little overhead. We perform several ablation studies verifying the proposed concepts and show that our network is able to substantially outperform other capsule approaches by over 1.2 % on CIFAR-10, using fewer parameters.
Spatial Action Maps for Mobile Manipulation
Apr 20, 2020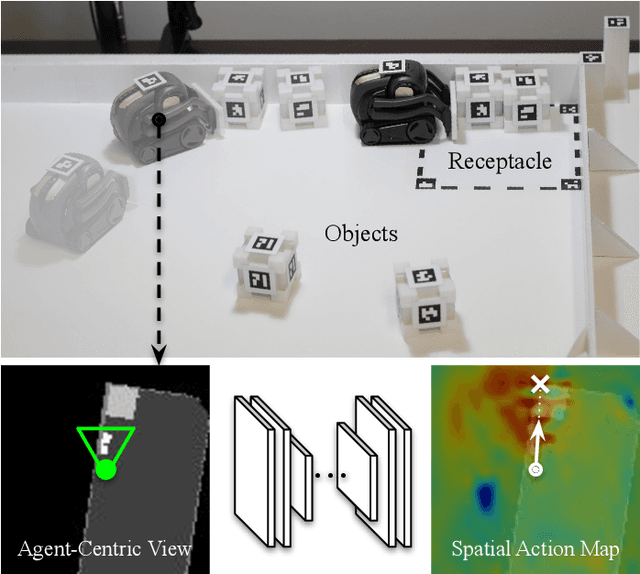


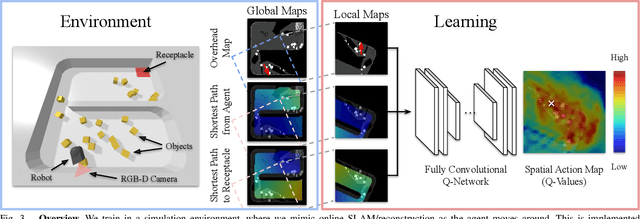
This paper proposes a new action representation for learning to perform complex mobile manipulation tasks. In a typical deep Q-learning setup, a convolutional neural network (ConvNet) is trained to map from an image representing the current state (e.g., a birds-eye view of a SLAM reconstruction of the scene) to predicted Q-values for a small set of steering command actions (step forward, turn right, turn left, etc.). Instead, we propose an action representation in the same domain as the state: "spatial action maps." In our proposal, the set of possible actions is represented by pixels of an image, where each pixel represents a trajectory to the corresponding scene location along a shortest path through obstacles of the partially reconstructed scene. A significant advantage of this approach is that the spatial position of each state-action value prediction represents a local milestone (local end-point) for the agent's policy, which may be easily recognizable in local visual patterns of the state image. A second advantage is that atomic actions can perform long-range plans (follow the shortest path to a point on the other side of the scene), and thus it is simpler to learn complex behaviors with a deep Q-network. A third advantage is that we can use a fully convolutional network (FCN) with skip connections to learn the mapping from state images to pixel-aligned action images efficiently. During experiments with a robot that learns to push objects to a goal location, we find that policies learned with this proposed action representation achieve significantly better performance than traditional alternatives.