 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
BlockGAN: Learning 3D Object-aware Scene Representations from Unlabelled Images
Feb 20, 2020
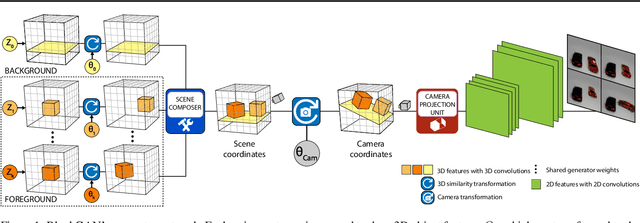

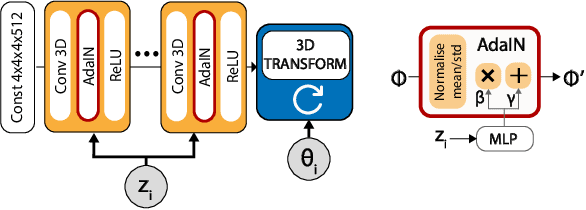

We present BlockGAN, an image generative model that learns object-aware 3D scene representations directly from unlabelled 2D images. Current work on scene representation learning either ignores scene background or treats the whole scene as one object. Meanwhile, work that considers scene compositionality treats scene objects only as image patches or 2D layers with alpha maps. Inspired by the computer graphics pipeline, we design BlockGAN to learn to first generate 3D features of background and foreground objects, then combine them into 3D features for the wholes cene, and finally render them into realistic images. This allows BlockGAN to reason over occlusion and interaction between objects' appearance, such as shadow and lighting, and provides control over each object's 3D pose and identity, while maintaining image realism. BlockGAN is trained end-to-end, using only unlabelled single images, without the need for 3D geometry, pose labels, object masks, or multiple views of the same scene. Our experiments show that using explicit 3D features to represent objects allows BlockGAN to learn disentangled representations both in terms of objects (foreground and background) and their properties (pose and identity).
Attention with Multiple Sources Knowledges for COVID-19 from CT Images
Sep 24, 2020
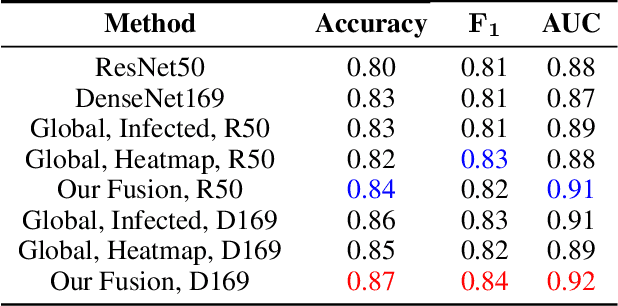
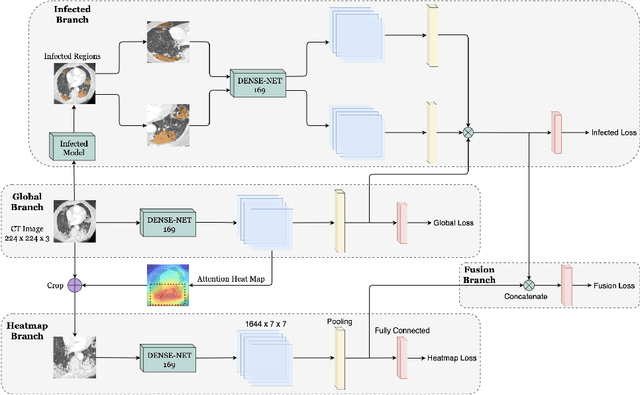
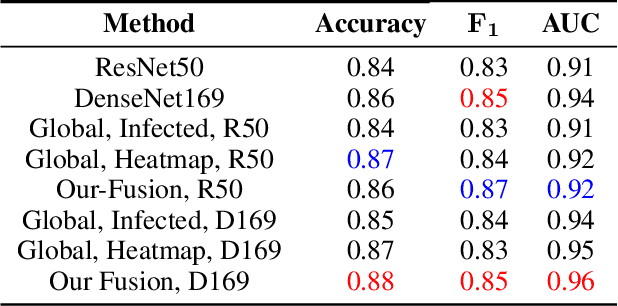
Until now, Coronavirus SARS-CoV-2 has caused more than 850,000 deaths and infected more than 27 million individuals in over 120 countries. Besides principal polymerase chain reaction (PCR) tests, automatically identifying positive samples based on computed tomography (CT) scans can present a promising option in the early diagnosis of COVID-19. Recently, there have been increasing efforts to utilize deep networks for COVID-19 diagnosis based on CT scans. While these approaches mostly focus on introducing novel architectures, transfer learning techniques, or construction large scale data, we propose a novel strategy to improve the performance of several baselines by leveraging multiple useful information sources relevant to doctors' judgments. Specifically, infected regions and heat maps extracted from learned networks are integrated with the global image via an attention mechanism during the learning process. This procedure not only makes our system more robust to noise but also guides the network focusing on local lesion areas. Extensive experiments illustrate the superior performance of our approach compared to recent baselines. Furthermore, our learned network guidance presents an explainable feature to doctors as we can understand the connection between input and output in a grey-box model.
Pose Guided Attention for Multi-label Fashion Image Classification
Nov 12, 2019
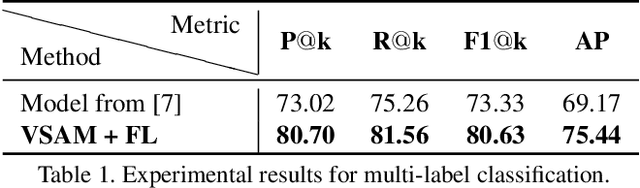

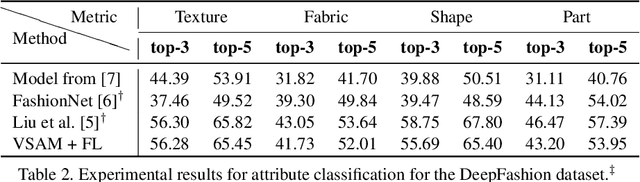
We propose a compact framework with guided attention for multi-label classification in the fashion domain. Our visual semantic attention model (VSAM) is supervised by automatic pose extraction creating a discriminative feature space. VSAM outperforms the state of the art for an in-house dataset and performs on par with previous works on the DeepFashion dataset, even without using any landmark annotations. Additionally, we show that our semantic attention module brings robustness to large quantities of wrong annotations and provides more interpretable results.
CaDIS: Cataract Dataset for Image Segmentation
Jul 01, 2019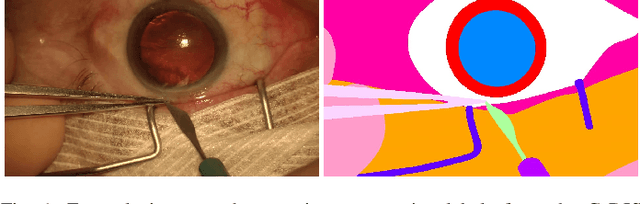
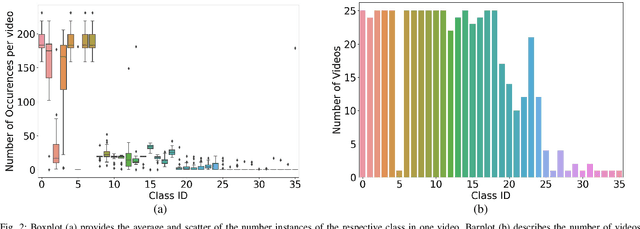
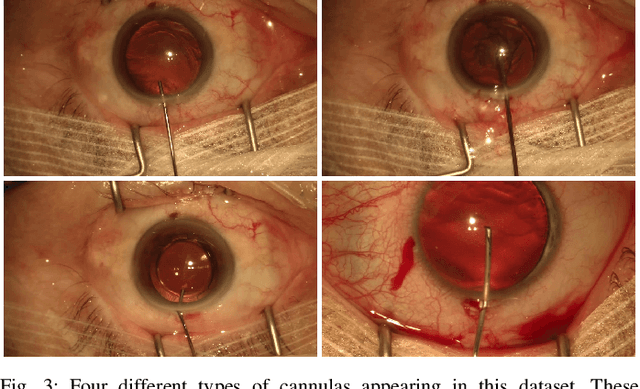

Video signals provide a wealth of information about surgical procedures and are the main sensory cue for surgeons. Video processing and understanding can be used to empower computer assisted interventions (CAI) as well as the development of detailed post-operative analysis of the surgical intervention. A fundamental building block to such capabilities is the ability to understand and segment video into semantic labels that differentiate and localize tissue types and different instruments. Deep learning has advanced semantic segmentation techniques dramatically in recent years but is fundamentally reliant on the availability of labelled datasets used to train models. In this paper, we introduce a high quality dataset for semantic segmentation in Cataract surgery. We generated this dataset from the CATARACTS challenge dataset, which is publicly available. To the best of our knowledge, this dataset has the highest quality annotation in surgical data to date. We introduce the dataset and then show the automatic segmentation performance of state-of-the-art models on that dataset as a benchmark.
Optimization of Structural Similarity in Mathematical Imaging
Feb 07, 2020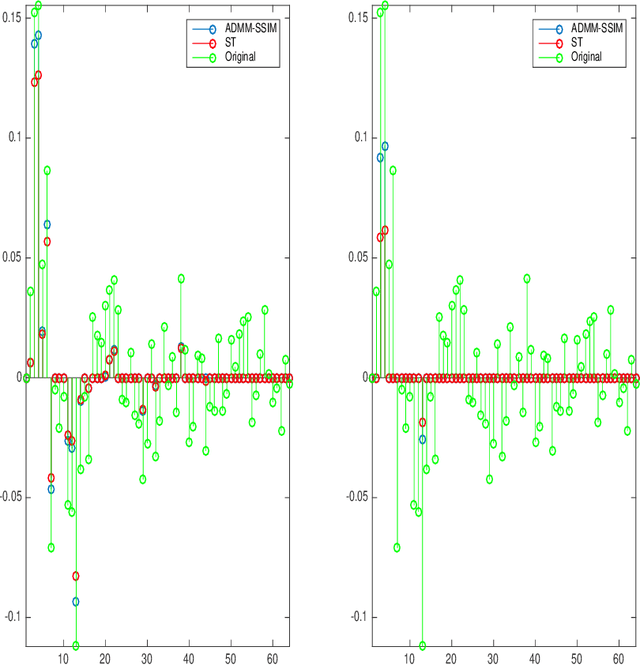
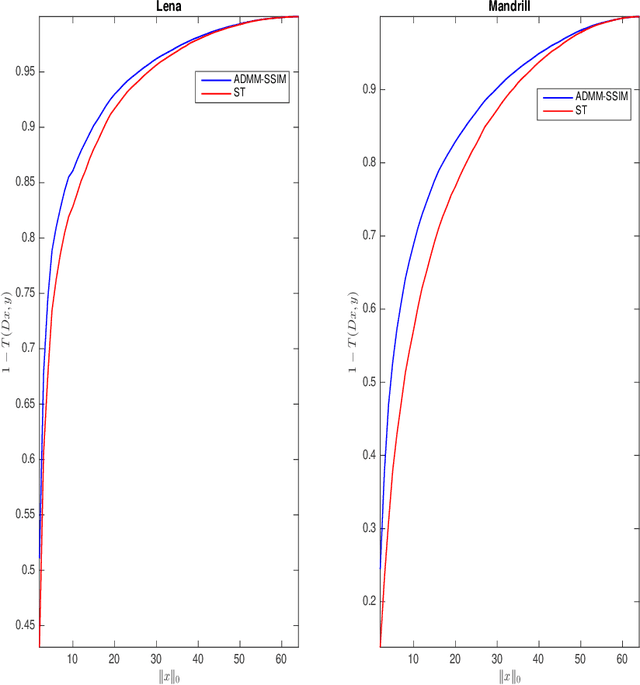
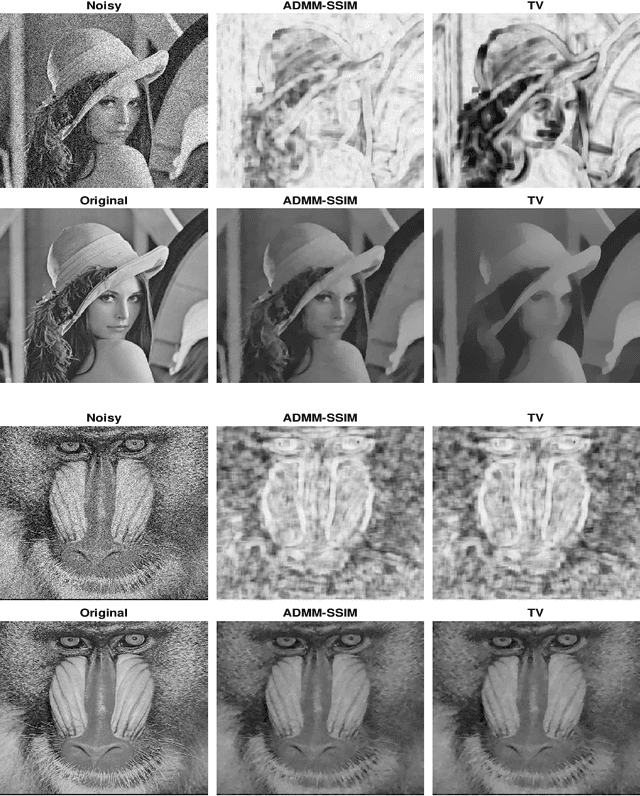
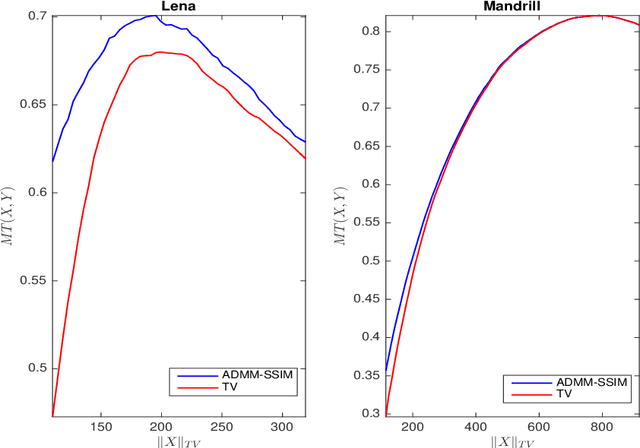
It is now generally accepted that Euclidean-based metrics may not always adequately represent the subjective judgement of a human observer. As a result, many image processing methodologies have been recently extended to take advantage of alternative visual quality measures, the most prominent of which is the Structural Similarity Index Measure (SSIM). The superiority of the latter over Euclidean-based metrics have been demonstrated in several studies. However, being focused on specific applications, the findings of such studies often lack generality which, if otherwise acknowledged, could have provided a useful guidance for further development of SSIM-based image processing algorithms. Accordingly, instead of focusing on a particular image processing task, in this paper, we introduce a general framework that encompasses a wide range of imaging applications in which the SSIM can be employed as a fidelity measure. Subsequently, we show how the framework can be used to cast some standard as well as original imaging tasks into optimization problems, followed by a discussion of a number of novel numerical strategies for their solution.
A Multimodal Late Fusion Model for E-Commerce Product Classification
Aug 14, 2020
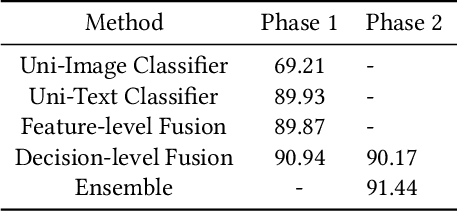
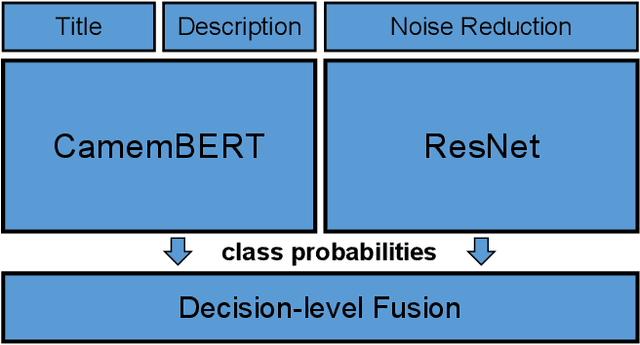

The cataloging of product listings is a fundamental problem for most e-commerce platforms. Despite promising results obtained by unimodal-based methods, it can be expected that their performance can be further boosted by the consideration of multimodal product information. In this study, we investigated a multimodal late fusion approach based on text and image modalities to categorize e-commerce products on Rakuten. Specifically, we developed modal specific state-of-the-art deep neural networks for each input modal, and then fused them at the decision level. Experimental results on Multimodal Product Classification Task of SIGIR 2020 E-Commerce Workshop Data Challenge demonstrate the superiority and effectiveness of our proposed method compared with unimodal and other multimodal methods. Our team named pa_curis won the 1st place with a macro-F1 of 0.9144 on the final leaderboard.
Inspector Gadget: A Data Programming-based Labeling System for Industrial Images
Apr 07, 2020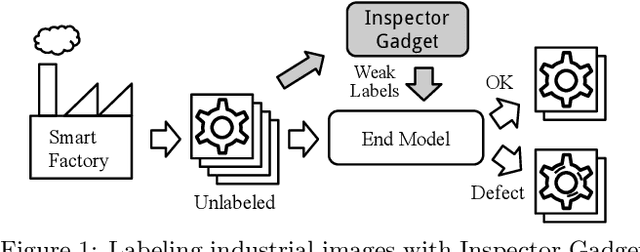
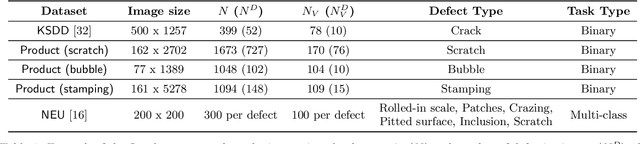
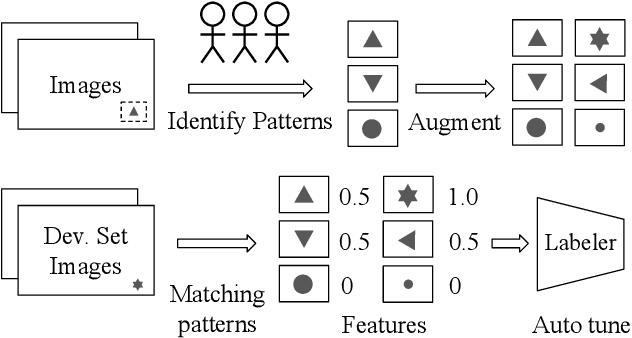
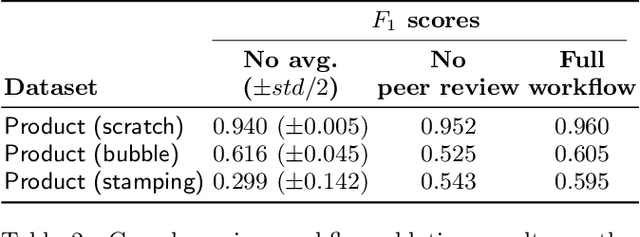
As machine learning for images becomes democratized in the Software 2.0 era, one of the serious bottlenecks is securing enough labeled data for training. This problem is especially critical in a manufacturing setting where smart factories rely on machine learning for product quality control by analyzing industrial images. Such images are typically large and may only need to be partially analyzed where only a small portion is problematic (e.g., identifying defects on a surface). Since manual labeling these images is expensive, weak supervision is an attractive alternative where the idea is to generate weak labels that are not perfect, but can be produced at scale. Data programming is a recent paradigm in this category where it uses human knowledge in the form of labeling functions and combines them into a generative model. Data programming has been successful in applications based on text or structured data and can also be applied to images usually if one can find a way to convert them into structured data. In this work, we expand the horizon of data programming by directly applying it to images without this conversion, which is a common scenario for industrial applications. We propose Inspector Gadget, an image labeling system that combines crowdsourcing, data augmentation, and data programming to produce weak labels at scale for image classification. We perform experiments on real industrial image datasets and show that Inspector Gadget obtains better accuracy than state-of-the-art techniques: Snuba, GOGGLES, and self-learning baselines using convolutional neural networks (CNNs) without pre-training.
Comparison of Neuronal Attention Models
Dec 07, 2019
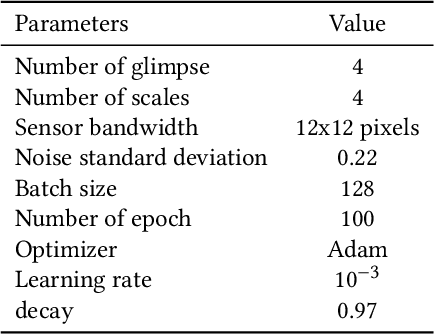
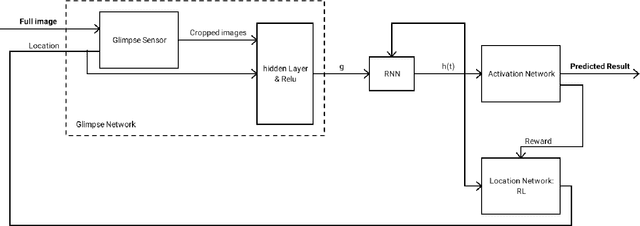
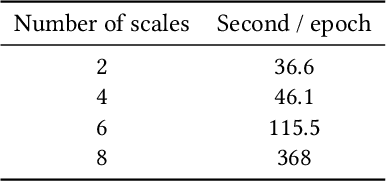
Recent models for image processing are using the Convolutional neural network (CNN) which requires a pixel per pixel analysis of the input image. This method works well. However, it is time-consuming if we have large images. To increase the performance, by improving the training time or the accuracy, we need a size-independent method. As a solution, we can add a Neuronal Attention model (NAM). The power of this new approach is that it can efficiently choose several small regions from the initial image to focus on. The purpose of this paper is to explain and also test each of the NAM's parameters.
An Analytical Study of different Document Image Binarization Methods
Jan 30, 2015



Document image has been the area of research for a couple of decades because of its potential application in the area of text recognition, line recognition or any other shape recognition from the image. For most of these purposes binarization of image becomes mandatory as far as recognition is concerned. Throughout couple decades standard algorithms have already been developed for this purpose. Some of these algorithms are applicable to degraded image also. Our objective behind this work is to study the existing techniques, compare them in view of advantages and disadvantages and modify some of these algorithms to optimize time or performance.
Comparisonal study of Deep Learning approaches on Retinal OCT Image
Dec 16, 2019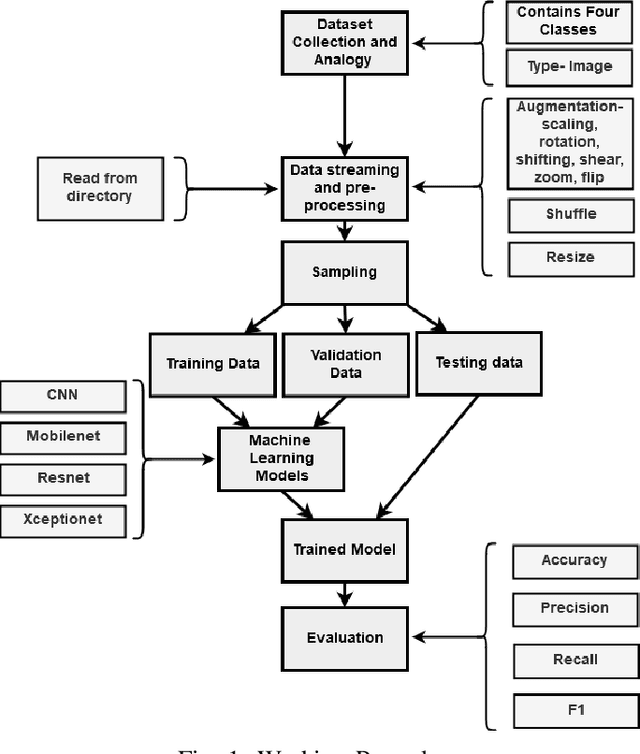
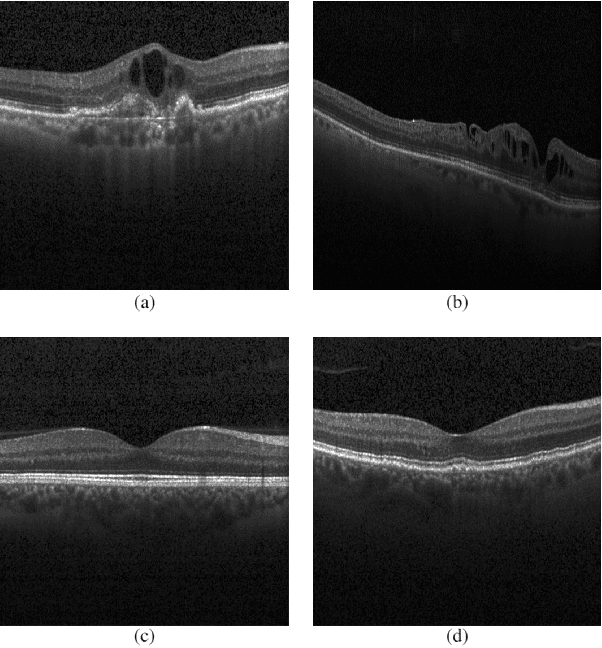
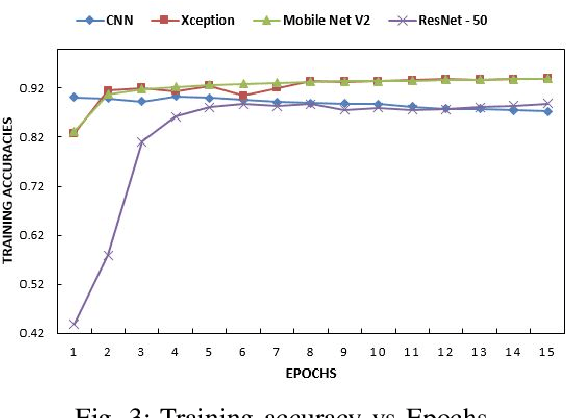
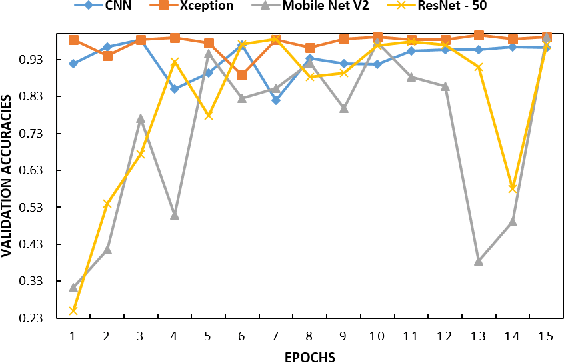
In medical science, the use of computer science in disease detection and diagnosis is gaining popularity. Previously, the detection of disease used to take a significant amount of time and was less reliable. Machine learning (ML) techniques employed in recent biomedical researches are making revolutionary changes by gaining higher accuracy with more concise timing. At present, it is even possible to automatically detect diseases from the scanned images with the help of ML. In this research, we have taken such an attempt to detect retinal diseases from optical coherence tomography (OCT) X-ray images. Here, we propose a deep learning (DL) based approach in detecting retinal diseases from OCT images which can identify three conditions of the retina. Four different models used in this approach are compared with each other. On the test set, the detection accuracy is 98.00\% for a vanilla convolutional neural network (CNN) model, 99.07\% for Xception model, 97.00\% for ResNet50 model, and 99.17\% for MobileNetV2 model. The MobileNetV2 model acquires the highest accuracy, and the closest to the highest is the Xception model. The proposed approach has a potential impact on creating a tool for automatically detecting retinal diseases.