 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Tomographic Image Reconstruction using Training images
Aug 17, 2015



We describe and examine an algorithm for tomographic image reconstruction where prior knowledge about the solution is available in the form of training images. We first construct a nonnegative dictionary based on prototype elements from the training images; this problem is formulated as a regularized non-negative matrix factorization. Incorporating the dictionary as a prior in a convex reconstruction problem, we then find an approximate solution with a sparse representation in the dictionary. The dictionary is applied to non-overlapping patches of the image, which reduces the computational complexity compared to other algorithms. Computational experiments clarify the choice and interplay of the model parameters and the regularization parameters, and we show that in few-projection low-dose settings our algorithm is competitive with total variation regularization and tends to include more texture and more correct edges.
Single Image Super Resolution via Manifold Approximation
Mar 10, 2015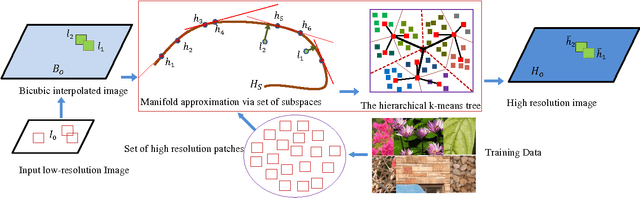
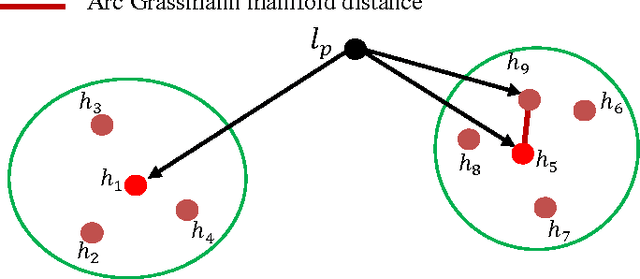

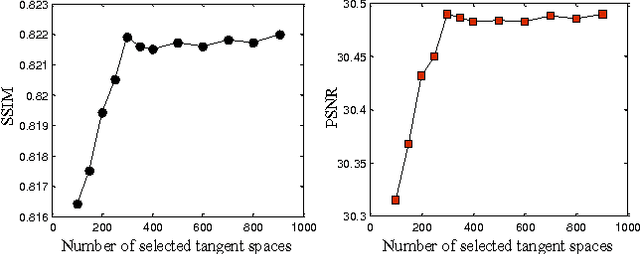
Image super-resolution remains an important research topic to overcome the limitations of physical acquisition systems, and to support the development of high resolution displays. Previous example-based super-resolution approaches mainly focus on analyzing the co-occurrence properties of low resolution and high-resolution patches. Recently, we proposed a novel single image super-resolution approach based on linear manifold approximation of the high-resolution image-patch space [1]. The image super-resolution problem is then formulated as an optimization problem of searching for the best matched high resolution patch in the manifold for a given low-resolution patch. We developed a novel technique based on the l1 norm sparse graph to learn a set of low dimensional affine spaces or tangent subspaces of the high-resolution patch manifold. The optimization problem is then solved based on the learned set of tangent subspaces. In this paper, we build on our recent work as follows. First, we consider and analyze each tangent subspace as one point in a Grassmann manifold, which helps to compute geodesic pairwise distances among these tangent subspaces. Second, we develop a min-max algorithm to select an optimal subset of tangent subspaces. This optimal subset reduces the computational cost while still preserving the quality of the reconstructed high-resolution image. Third, and to further achieve lower computational complexity, we perform hierarchical clustering on the optimal subset based on Grassmann manifold distances. Finally, we analytically prove the validity of the proposed Grassmann-distance based clustering. A comparison of the obtained results with other state-of-the-art methods clearly indicates the viability of the new proposed framework.
autoTICI: Automatic Brain Tissue Reperfusion Scoring on 2D DSA Images of Acute Ischemic Stroke Patients
Oct 06, 2020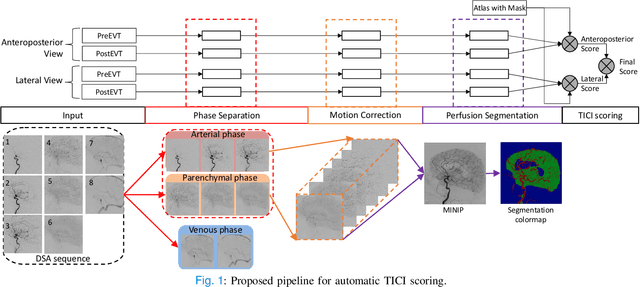
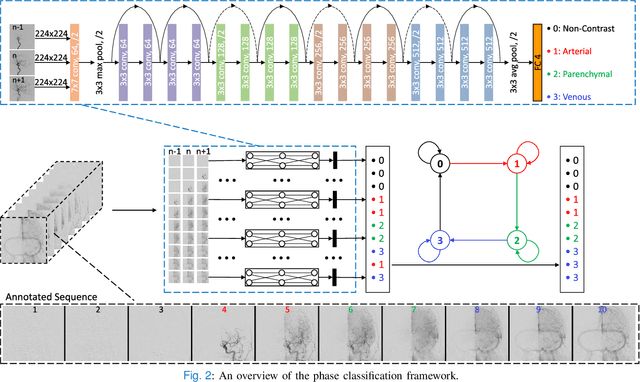
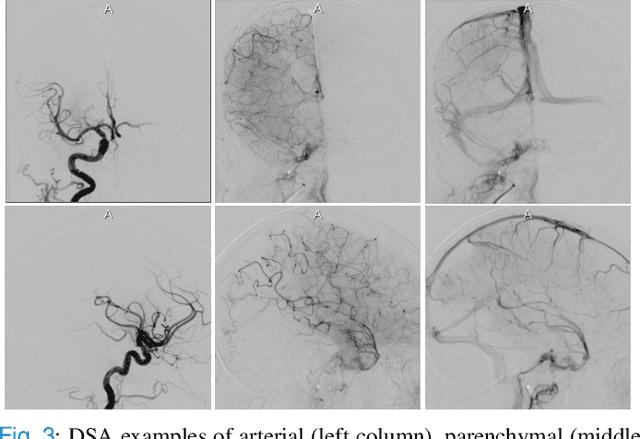
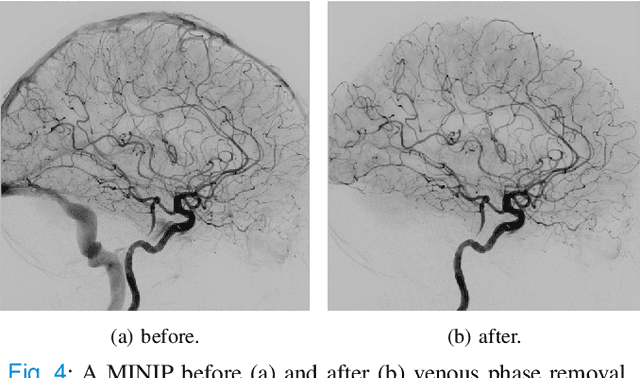
The Thrombolysis in Cerebral Infarction (TICI) score is an important metric for reperfusion therapy assessment in acute ischemic stroke. It is commonly used as a technical outcome measure after endovascular treatment (EVT). Existing TICI scores are defined in coarse ordinal grades based on visual inspection, leading to inter- and intra-observer variation. In this work, we present autoTICI, an automatic and quantitative TICI scoring method. First, each digital subtraction angiography (DSA) sequence is separated into four phases (non-contrast, arterial, parenchymal and venous phase) using a multi-path convolutional neural network (CNN), which exploits spatio-temporal features. The network also incorporates sequence level label dependencies in the form of a state-transition matrix. Next, a minimum intensity map (MINIP) is computed using the motion corrected arterial and parenchymal frames. On the MINIP image, vessel, perfusion and background pixels are segmented. Finally, we quantify the autoTICI score as the ratio of reperfused pixels after EVT. On a routinely acquired multi-center dataset, the proposed autoTICI shows good correlation with the extended TICI (eTICI) reference with an average area under the curve (AUC) score of 0.81. The AUC score is 0.90 with respect to the dichotomized eTICI. In terms of clinical outcome prediction, we demonstrate that autoTICI is overall comparable to eTICI.
On the surprising similarities between supervised and self-supervised models
Oct 16, 2020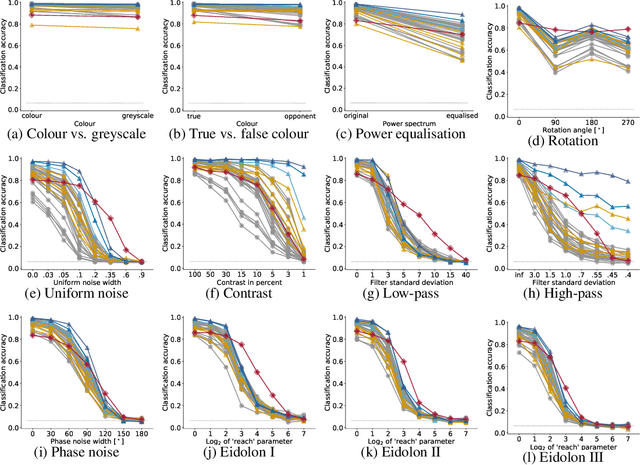
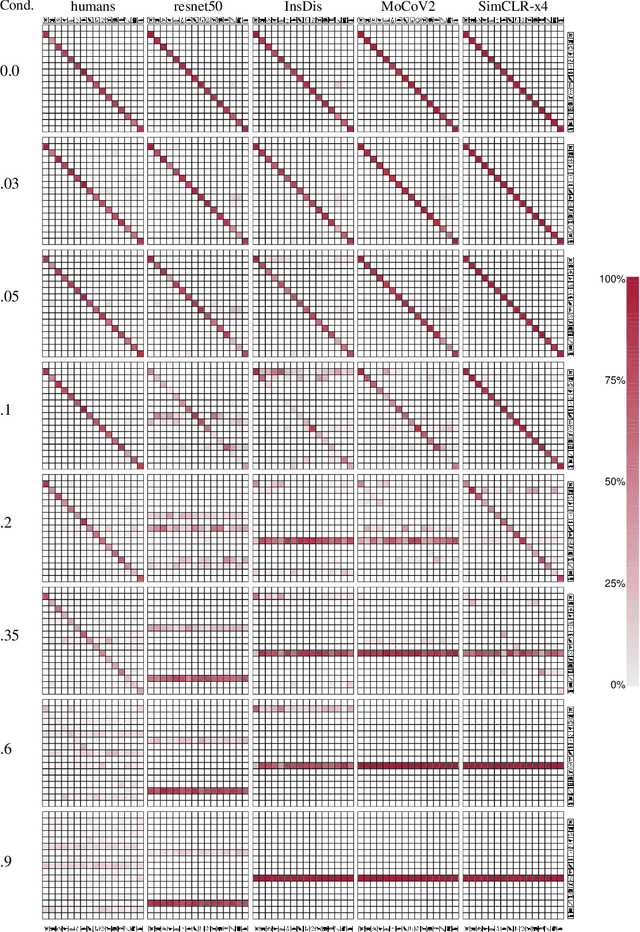
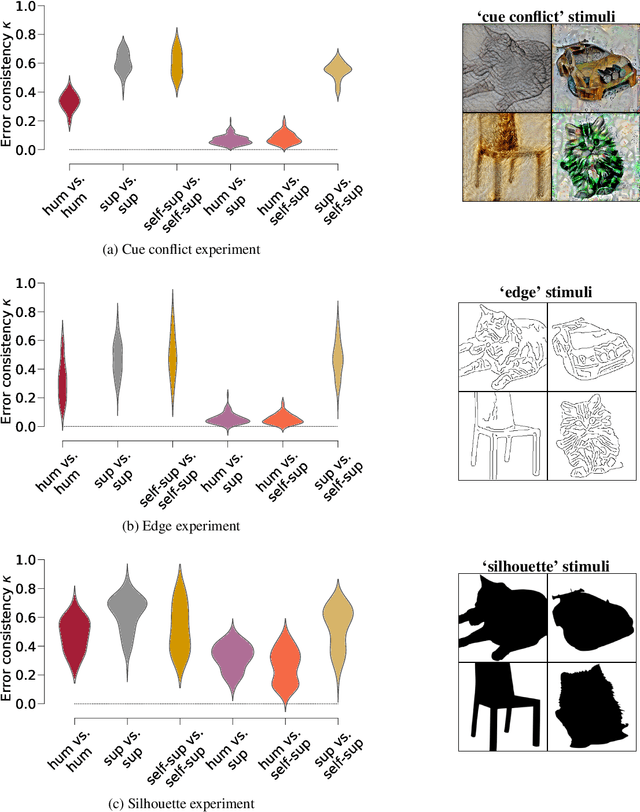
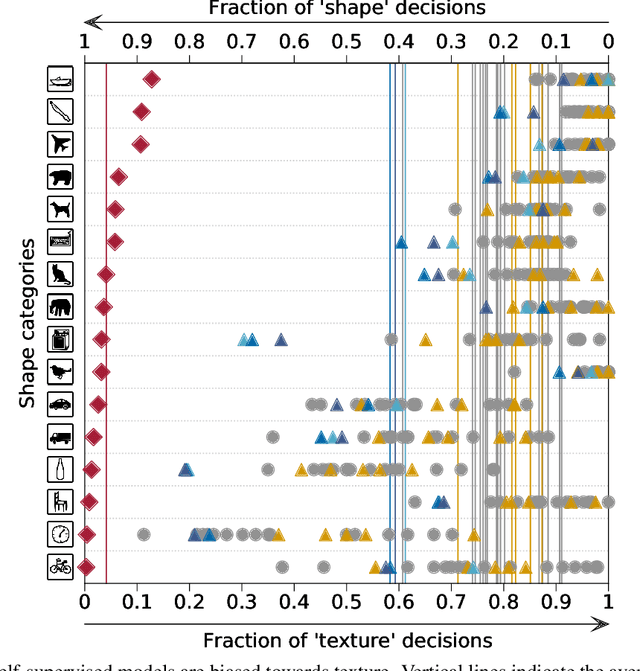
How do humans learn to acquire a powerful, flexible and robust representation of objects? While much of this process remains unknown, it is clear that humans do not require millions of object labels. Excitingly, recent algorithmic advancements in self-supervised learning now enable convolutional neural networks (CNNs) to learn useful visual object representations without supervised labels, too. In the light of this recent breakthrough, we here compare self-supervised networks to supervised models and human behaviour. We tested models on 15 generalisation datasets for which large-scale human behavioural data is available (130K highly controlled psychophysical trials). Surprisingly, current self-supervised CNNs share four key characteristics of their supervised counterparts: (1.) relatively poor noise robustness (with the notable exception of SimCLR), (2.) non-human category-level error patterns, (3.) non-human image-level error patterns (yet high similarity to supervised model errors) and (4.) a bias towards texture. Taken together, these results suggest that the strategies learned through today's supervised and self-supervised training objectives end up being surprisingly similar, but distant from human-like behaviour. That being said, we are clearly just at the beginning of what could be called a self-supervised revolution of machine vision, and we are hopeful that future self-supervised models behave differently from supervised ones, and---perhaps---more similar to robust human object recognition.
Deep Spatial Regression Model for Image Crowd Counting
Oct 26, 2017
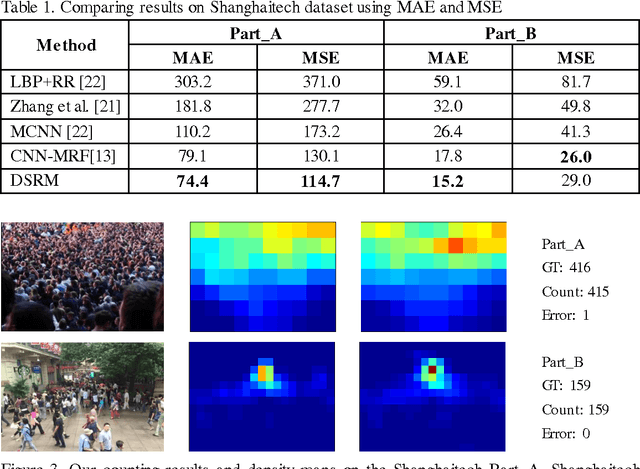
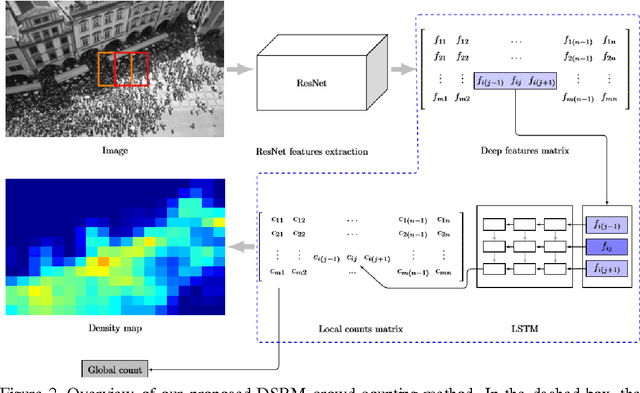
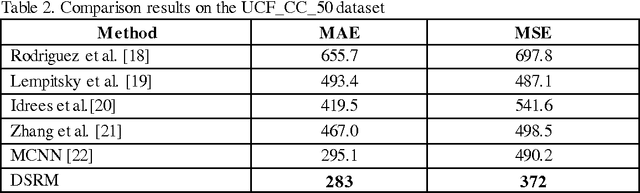
Computer vision techniques have been used to produce accurate and generic crowd count estimators in recent years. Due to severe occlusions, appearance variations, perspective distortions and illumination conditions, crowd counting is a very challenging task. To this end, we propose a deep spatial regression model(DSRM) for counting the number of individuals present in a still image with arbitrary perspective and arbitrary resolution. Our proposed model is based on Convolutional Neural Network (CNN) and long short term memory (LSTM). First, we put the images into a pretrained CNN to extract a set of high-level features. Then the features in adjacent regions are used to regress the local counts with a LSTM structure which takes the spatial information into consideration. The final global count is obtained by a sum of the local patches. We apply our framework on several challenging crowd counting datasets, and the experiment results illustrate that our method on the crowd counting and density estimation problem outperforms state-of-the-art methods in terms of reliability and effectiveness.
VD-BERT: A Unified Vision and Dialog Transformer with BERT
Apr 29, 2020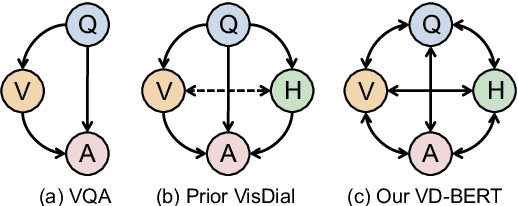
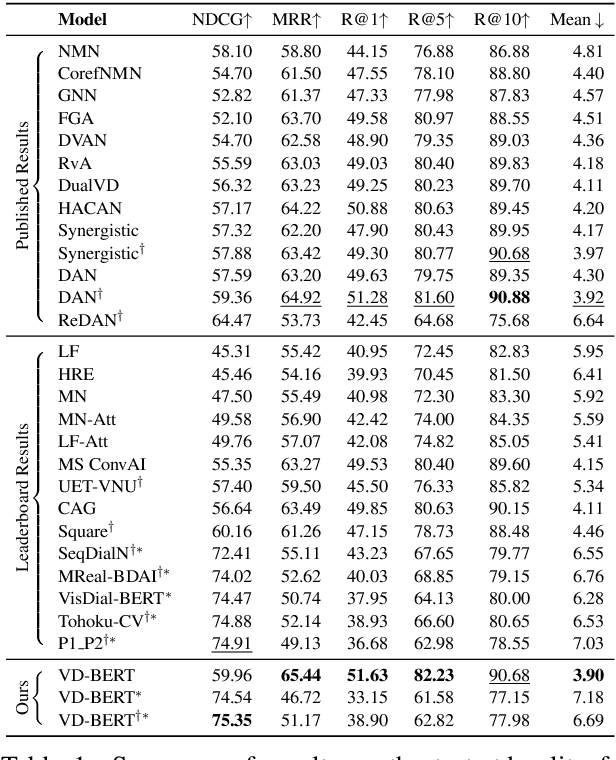
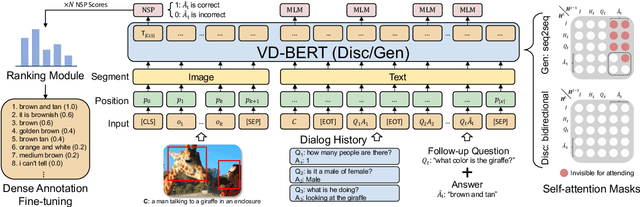
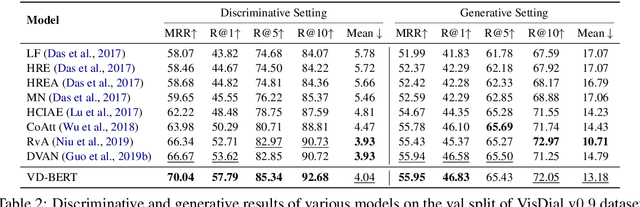
Visual dialog is a challenging vision-language task, where a dialog agent needs to answer a series of questions through reasoning on the image content and dialog history. Prior work has mostly focused on various attention mechanisms to model such intricate interactions. By contrast, in this work, we propose VD-BERT, a simple yet effective framework of unified vision-dialog Transformer that leverages the pretrained BERT language models for Visual Dialog tasks. The model is unified in that (1) it captures all the interactions between the image and the multi-turn dialog using a single-stream Transformer encoder, and (2) it supports both answer ranking and answer generation seamlessly through the same architecture. More crucially, we adapt BERT for the effective fusion of vision and dialog contents via visually grounded training. Without the need of pretraining on external vision-language data, our model yields new state of the art, achieving the top position in both single-model and ensemble settings (74.54 and 75.35 NDCG scores) on the visual dialog leaderboard.
Anyone here? Smart embedded low-resolution omnidirectional video sensor to measure room occupancy
Jul 09, 2020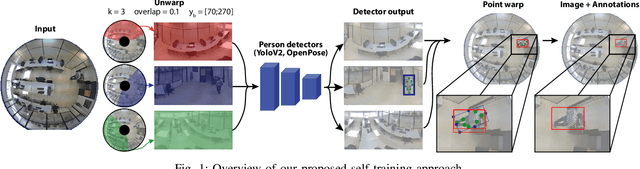


In this paper, we present a room occupancy sensing solution with unique properties: (i) It is based on an omnidirectional vision camera, capturing rich scene info over a wide angle, enabling to count the number of people in a room and even their position. (ii) Although it uses a camera-input, no privacy issues arise because its extremely low image resolution, rendering people unrecognisable. (iii) The neural network inference is running entirely on a low-cost processing platform embedded in the sensor, reducing the privacy risk even further. (iv) Limited manual data annotation is needed, because of the self-training scheme we propose. Such a smart room occupancy rate sensor can be used in e.g. meeting rooms and flex-desks. Indeed, by encouraging flex-desking, the required office space can be reduced significantly. In some cases, however, a flex-desk that has been reserved remains unoccupied without an update in the reservation system. A similar problem occurs with meeting rooms, which are often under-occupied. By optimising the occupancy rate a huge reduction in costs can be achieved. Therefore, in this paper, we develop such system which determines the number of people present in office flex-desks and meeting rooms. Using an omnidirectional camera mounted in the ceiling, combined with a person detector, the company can intelligently update the reservation system based on the measured occupancy. Next to the optimisation and embedded implementation of such a self-training omnidirectional people detection algorithm, in this work we propose a novel approach that combines spatial and temporal image data, improving performance of our system on extreme low-resolution images.
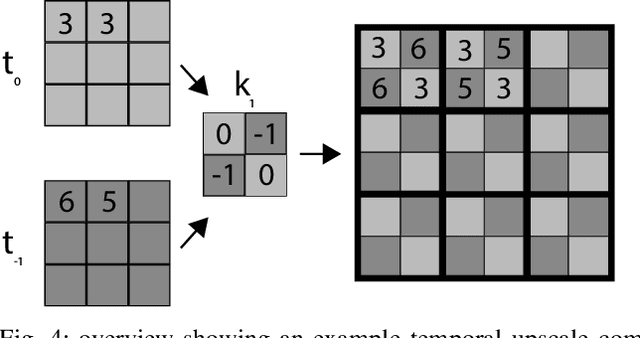
Detecting Cross-Modal Inconsistency to Defend Against Neural Fake News
Sep 24, 2020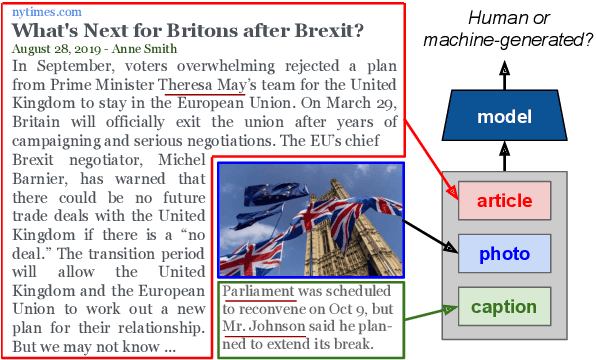
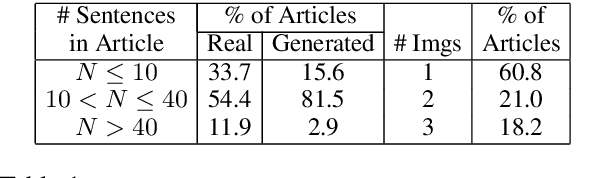
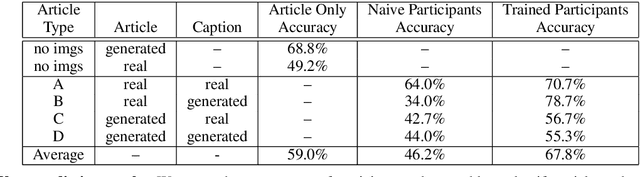
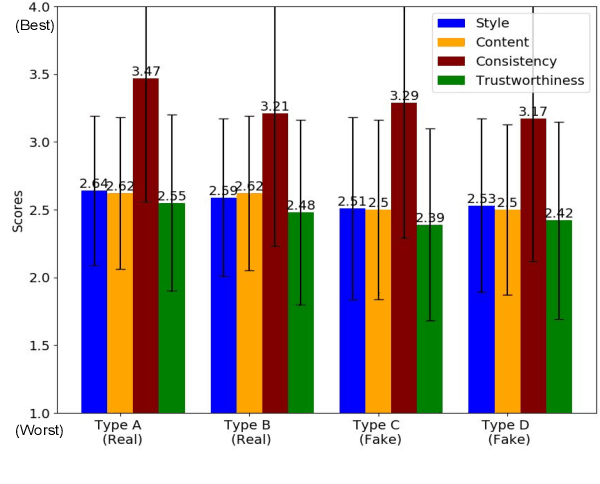
Large-scale dissemination of disinformation online intended to mislead or deceive the general population is a major societal problem. Rapid progression in image, video, and natural language generative models has only exacerbated this situation and intensified our need for an effective defense mechanism. While existing approaches have been proposed to defend against neural fake news, they are generally constrained to the very limited setting where articles only have text and metadata such as the title and authors. In this paper, we introduce the more realistic and challenging task of defending against machine-generated news that also includes images and captions. To identify the possible weaknesses that adversaries can exploit, we create a NeuralNews dataset composed of 4 different types of generated articles as well as conduct a series of human user study experiments based on this dataset. In addition to the valuable insights gleaned from our user study experiments, we provide a relatively effective approach based on detecting visual-semantic inconsistencies, which will serve as an effective first line of defense and a useful reference for future work in defending against machine-generated disinformation.
Modified Alpha-Rooting Color Image Enhancement Method On The Two-Side 2-D Quaternion Discrete Fourier Transform And The 2-D Discrete Fourier Transform
Jul 15, 2017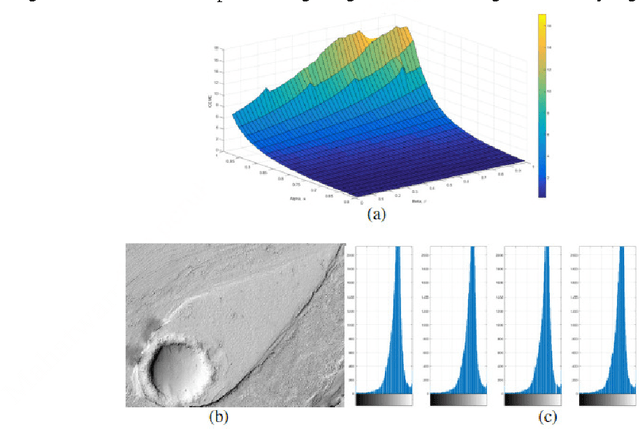


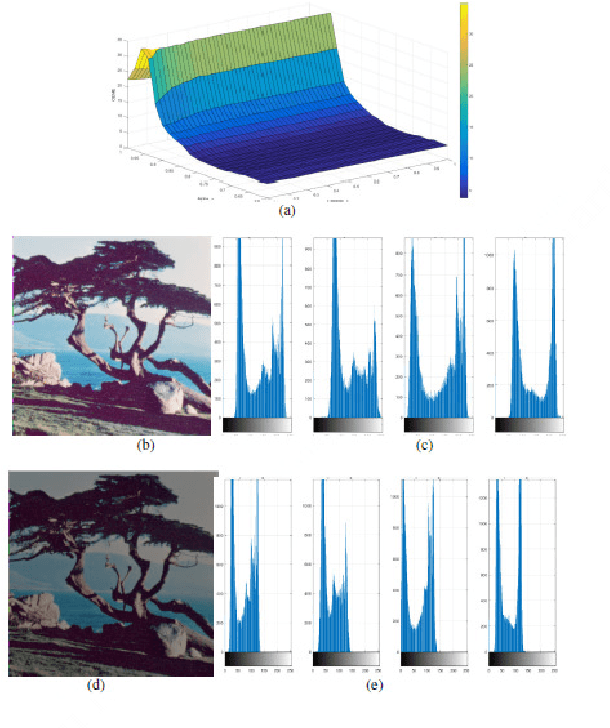
Color in an image is resolved into 3 or 4 color components and 2-Dimages of these components are stored in separate channels. Most of the color image enhancement algorithms are applied channel-by-channel on each image. But such a system of color image processing is not processing the original color. When a color image is represented as a quaternion image, processing is done in original colors. This paper proposes an implementation of the quaternion approach of enhancement algorithm for enhancing color images and is referred as the modified alpha-rooting by the two-dimensional quaternion discrete Fourier transform (2-D QDFT). Enhancement results of this proposed method are compared with the channel-by-channel image enhancement by the 2-D DFT. Enhancements in color images are quantitatively measured by the color enhancement measure estimation (CEME), which allows for selecting optimum parameters for processing by the genetic algorithm. Enhancement of color images by the quaternion based method allows for obtaining images which are closer to the genuine representation of the real original color.
* 16 pages, 53 figures (including sub-figures)
CIMON: Towards High-quality Hash Codes
Oct 16, 2020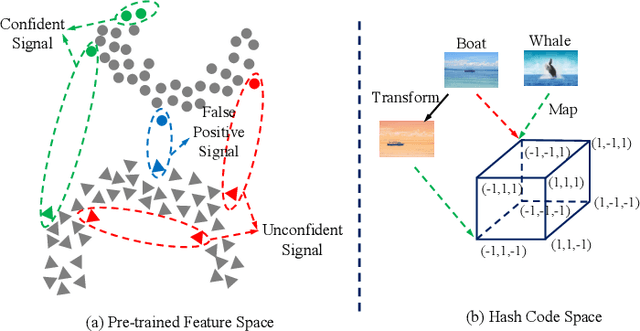
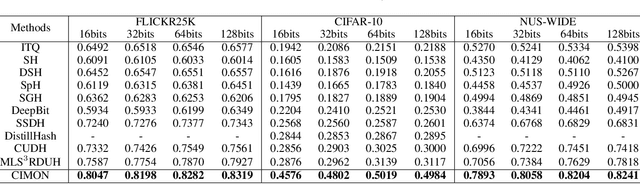
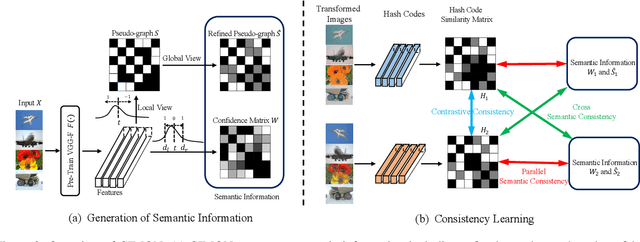
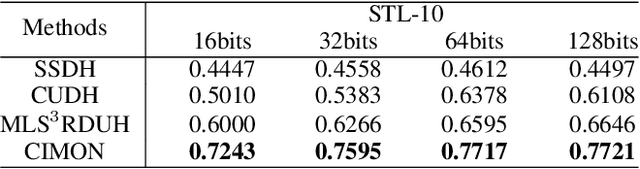
Recently, hashing is widely-used in approximate nearest neighbor search for its storage and computational efficiency. Due to the lack of labeled data in practice, many studies focus on unsupervised hashing. Most of the unsupervised hashing methods learn to map images into semantic similarity-preserving hash codes by constructing local semantic similarity structure from the pre-trained model as guiding information, i.e., treating each point pair similar if their distance is small in feature space. However, due to the inefficient representation ability of the pre-trained model, many false positives and negatives in local semantic similarity will be introduced and lead to error propagation during hash code learning. Moreover, most of hashing methods ignore the basic characteristics of hash codes such as collisions, which will cause instability of hash codes to disturbance. In this paper, we propose a new method named Comprehensive sImilarity Mining and cOnsistency learNing (CIMON). First, we use global constraint learning and similarity statistical distribution to obtain reliable and smooth guidance. Second, image augmentation and consistency learning will be introduced to explore both semantic and contrastive consistency to derive robust hash codes with fewer collisions. Extensive experiments on several benchmark datasets show that the proposed method consistently outperforms a wide range of state-of-the-art methods in both retrieval performance and robustness.