 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Object-QA: Towards High Reliable Object Quality Assessment
May 27, 2020

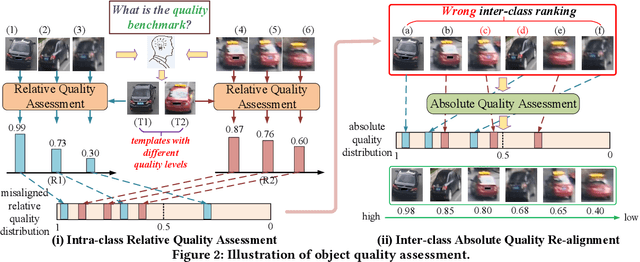
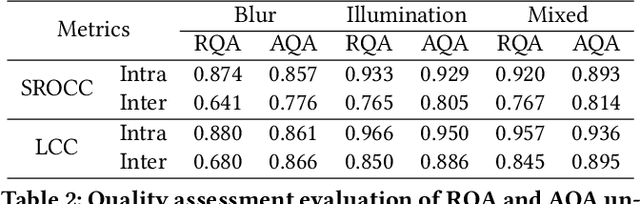
In object recognition applications, object images usually appear with different quality levels. Practically, it is very important to indicate object image qualities for better application performance, e.g. filtering out low-quality object image frames to maintain robust video object recognition results and speed up inference. However, no previous works are explicitly proposed for addressing the problem. In this paper, we define the problem of object quality assessment for the first time and propose an effective approach named Object-QA to assess high-reliable quality scores for object images. Concretely, Object-QA first employs a well-designed relative quality assessing module that learns the intra-class-level quality scores by referring to the difference between object images and their estimated templates. Then an absolute quality assessing module is designed to generate the final quality scores by aligning the quality score distributions in inter-class. Besides, Object-QA can be implemented with only object-level annotations, and is also easily deployed to a variety of object recognition tasks. To our best knowledge this is the first work to put forward the definition of this problem and conduct quantitative evaluations. Validations on 5 different datasets show that Object-QA can not only assess high-reliable quality scores according with human cognition, but also improve application performance.
Exploring Integral Image Word Length Reduction Techniques for SURF Detector
Apr 29, 2015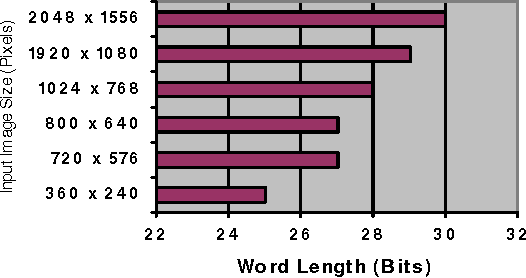
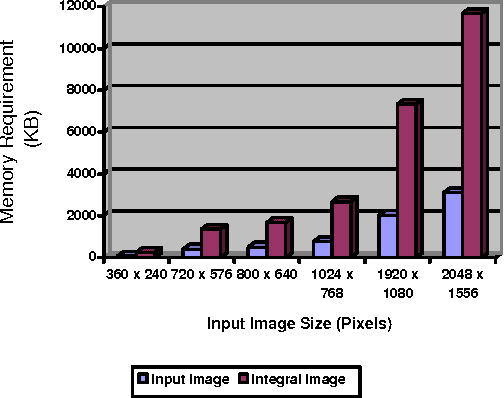
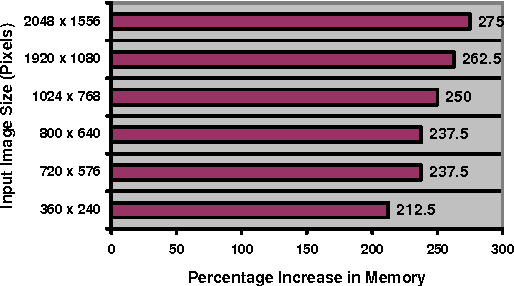
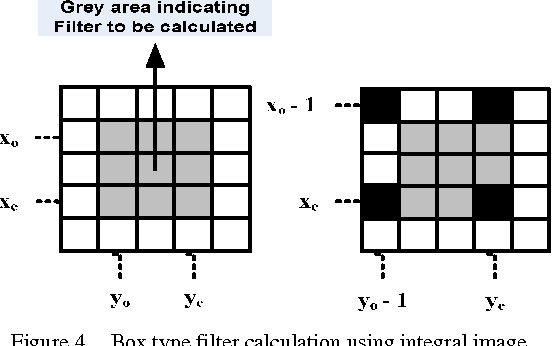
Speeded Up Robust Features (SURF) is a state of the art computer vision algorithm that relies on integral image representation for performing fast detection and description of image features that are scale and rotation invariant. Integral image representation, however, has major draw back of large binary word length that leads to substantial increase in memory size. When designing a dedicated hardware to achieve real-time performance for the SURF algorithm, it is imperative to consider the adverse effects of integral image on memory size, bus width and computational resources. With the objective of minimizing hardware resources, this paper presents a novel implementation concept of a reduced word length integral image based SURF detector. It evaluates two existing word length reduction techniques for the particular case of SURF detector and extends one of these to achieve more reduction in word length. This paper also introduces a novel method to achieve integral image word length reduction for SURF detector.
MeshMVS: Multi-View Stereo Guided Mesh Reconstruction
Oct 17, 2020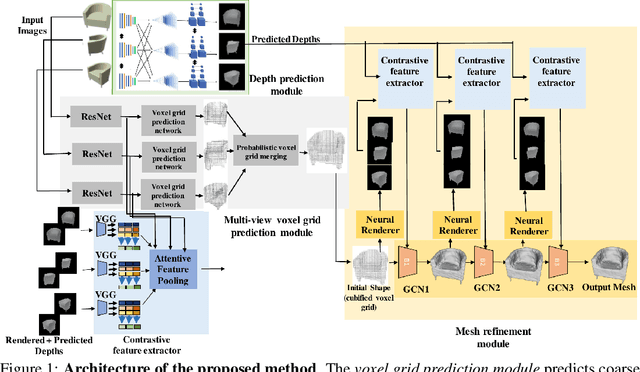
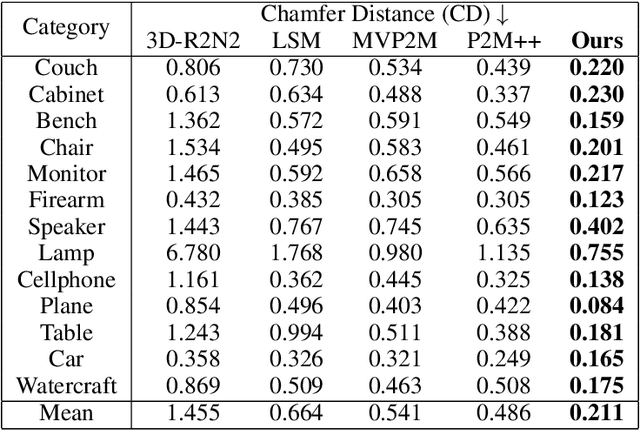


Deep learning based 3D shape generation methods generally utilize latent features extracted from color images to encode the objects' semantics and guide the shape generation process. These color image semantics only implicitly encode 3D information, potentially limiting the accuracy of the generated shapes. In this paper we propose a multi-view mesh generation method which incorporates geometry information in the color images explicitly by using the features from intermediate 2.5D depth representations of the input images and regularizing the 3D shapes against these depth images. Our system first predicts a coarse 3D volume from the color images by probabilistically merging voxel occupancy grids from individual views. Depth images corresponding to the multi-view color images are predicted which along with the rendered depth images of the coarse shape are used as a contrastive input whose features guide the refinement of the coarse shape through a series of graph convolution networks. Attention-based multi-view feature pooling is proposed to fuse the contrastive depth features from different viewpoints which are fed to the graph convolution networks. We validate the proposed multi-view mesh generation method on ShapeNet, where we obtain a significant improvement with 34% decrease in chamfer distance to ground truth and 14% increase in the F1-score compared with the state-of-the-art multi-view shape generation method.
Intuitive, Interactive Beard and Hair Synthesis with Generative Models
Apr 15, 2020



We present an interactive approach to synthesizing realistic variations in facial hair in images, ranging from subtle edits to existing hair to the addition of complex and challenging hair in images of clean-shaven subjects. To circumvent the tedious and computationally expensive tasks of modeling, rendering and compositing the 3D geometry of the target hairstyle using the traditional graphics pipeline, we employ a neural network pipeline that synthesizes realistic and detailed images of facial hair directly in the target image in under one second. The synthesis is controlled by simple and sparse guide strokes from the user defining the general structural and color properties of the target hairstyle. We qualitatively and quantitatively evaluate our chosen method compared to several alternative approaches. We show compelling interactive editing results with a prototype user interface that allows novice users to progressively refine the generated image to match their desired hairstyle, and demonstrate that our approach also allows for flexible and high-fidelity scalp hair synthesis.
Video-based Facial Expression Recognition using Graph Convolutional Networks
Oct 26, 2020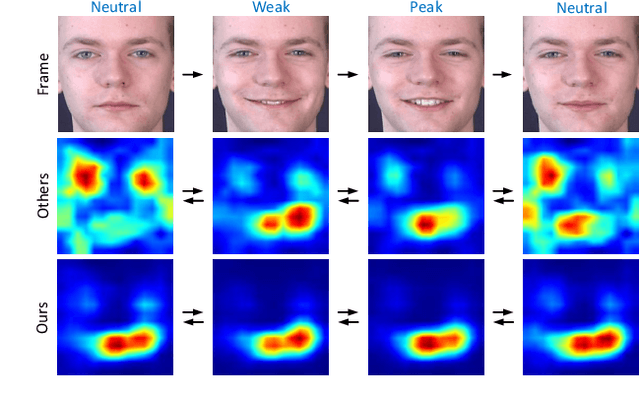
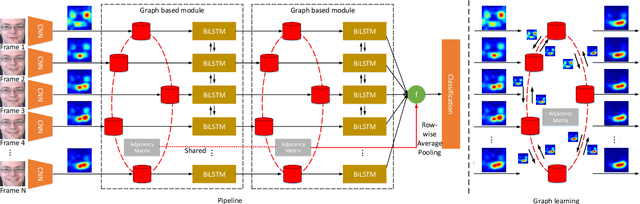

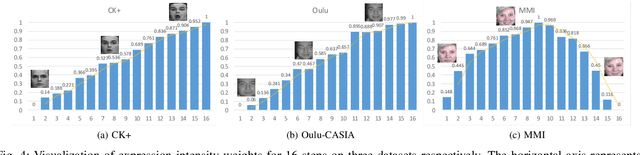
Facial expression recognition (FER), aiming to classify the expression present in the facial image or video, has attracted a lot of research interests in the field of artificial intelligence and multimedia. In terms of video based FER task, it is sensible to capture the dynamic expression variation among the frames to recognize facial expression. However, existing methods directly utilize CNN-RNN or 3D CNN to extract the spatial-temporal features from different facial units, instead of concentrating on a certain region during expression variation capturing, which leads to limited performance in FER. In our paper, we introduce a Graph Convolutional Network (GCN) layer into a common CNN-RNN based model for video-based FER. First, the GCN layer is utilized to learn more significant facial expression features which concentrate on certain regions after sharing information between extracted CNN features of nodes. Then, a LSTM layer is applied to learn long-term dependencies among the GCN learned features to model the variation. In addition, a weight assignment mechanism is also designed to weight the output of different nodes for final classification by characterizing the expression intensities in each frame. To the best of our knowledge, it is the first time to use GCN in FER task. We evaluate our method on three widely-used datasets, CK+, Oulu-CASIA and MMI, and also one challenging wild dataset AFEW8.0, and the experimental results demonstrate that our method has superior performance to existing methods.
When Autonomous Systems Meet Accuracy and Transferability through AI: A Survey
Mar 29, 2020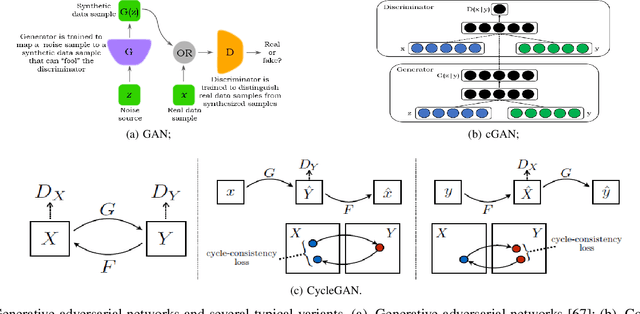
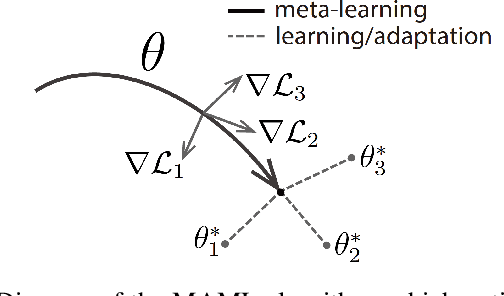


With widespread applications of artificial intelligence (AI), the capabilities of the perception, understanding, decision-making and control for autonomous systems have improved significantly in the past years. When autonomous systems consider the performance of accuracy and transferability simultaneously, several AI methods, like adversarial learning, reinforcement learning (RL) and meta-learning, show their powerful performance. Here, we review the learning-based approaches in autonomous systems from the perspectives of accuracy and transferability. Accuracy means that a well-trained model shows good results during the testing phase, in which the testing set shares a same task or a data distribution with the training set. Transferability means that when an trained model is transferred to other testing domains, the accuracy is still good. Firstly, we introduce some basic concepts of transfer learning and then present some preliminaries of adversarial learning, RL and meta-learning. Secondly, we focus on reviewing the accuracy and transferability to show the advantages of adversarial learning, like generative adversarial networks (GANs), in typical computer vision tasks in autonomous systems, including image style transfer, image super-resolution, image deblurring/dehazing/rain removal, semantic segmentation, depth estimation and person re-identification. Then, we further review the performance of RL and meta-learning from the aspects of accuracy and transferability in autonomous systems, involving robot navigation and robotic manipulation. Finally, we discuss several challenges and future topics for using adversarial learning, RL and meta-learning in autonomous systems.
Image reconstruction with imperfect forward models and applications in deblurring
Oct 23, 2017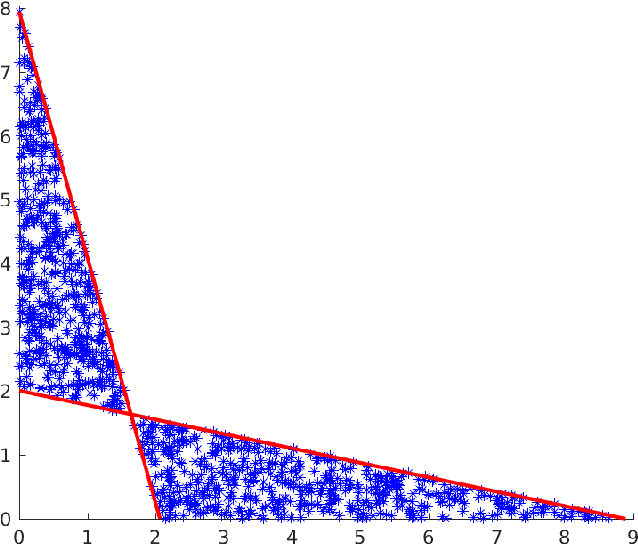
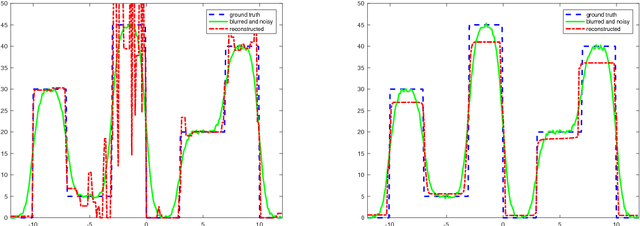

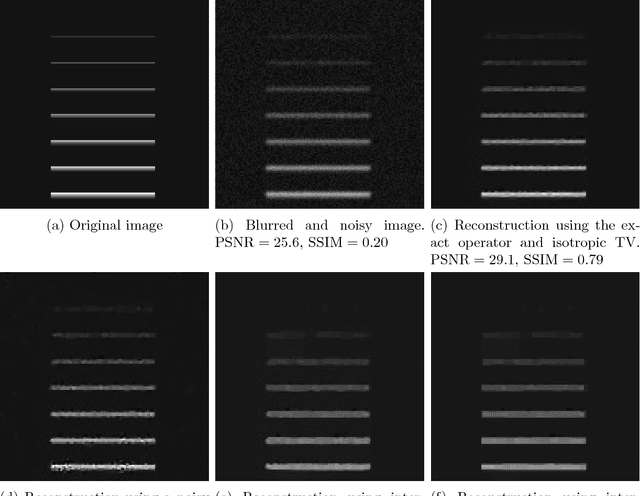
We present and analyse an approach to image reconstruction problems with imperfect forward models based on partially ordered spaces - Banach lattices. In this approach, errors in the data and in the forward models are described using order intervals. The method can be characterised as the lattice analogue of the residual method, where the feasible set is defined by linear inequality constraints. The study of this feasible set is the main contribution of this paper. Convexity of this feasible set is examined in several settings and modifications for introducing additional information about the forward operator are considered. Numerical examples demonstrate the performance of the method in deblurring with errors in the blurring kernel.
Leveraging Localization for Multi-camera Association
Aug 07, 2020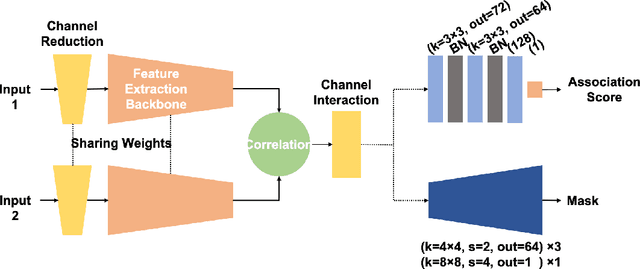
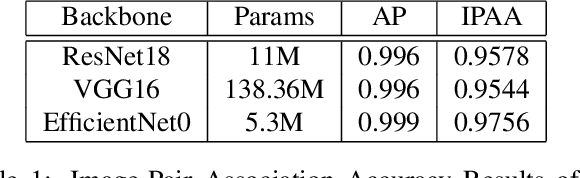
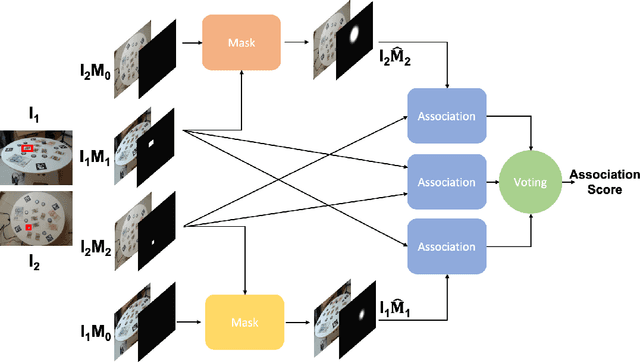
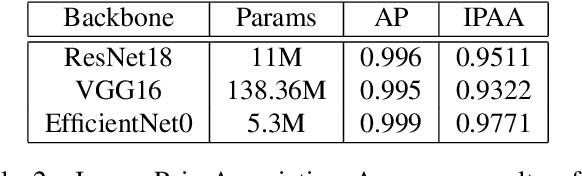
We present McAssoc, a deep learning approach to the as-sociation of detection bounding boxes in different views ofa multi-camera system. The vast majority of the academiahas been developing single-camera computer vision algo-rithms, however, little research attention has been directedto incorporating them into a multi-camera system. In thispaper, we designed a 3-branch architecture that leveragesdirect association and additional cross localization infor-mation. A new metric, image-pair association accuracy(IPAA) is designed specifically for performance evaluationof cross-camera detection association. We show in the ex-periments that localization information is critical to suc-cessful cross-camera association, especially when similar-looking objects are present. This paper is an experimentalwork prior to MessyTable, which is a large-scale bench-mark for instance association in mutliple cameras.
autoTICI: Automatic Brain Tissue Reperfusion Scoring on 2D DSA Images of Acute Ischemic Stroke Patients
Oct 06, 2020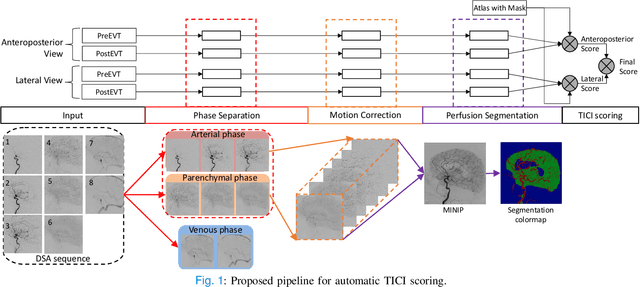
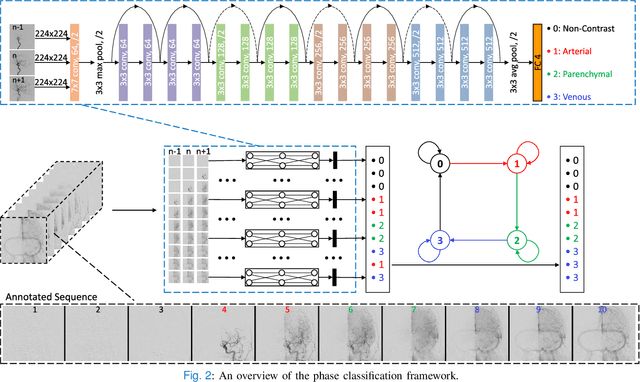
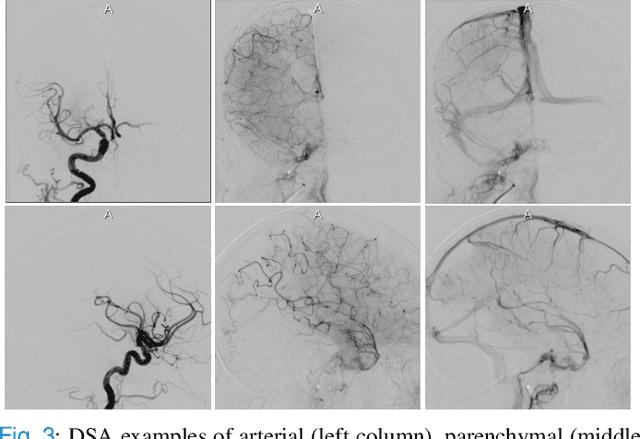
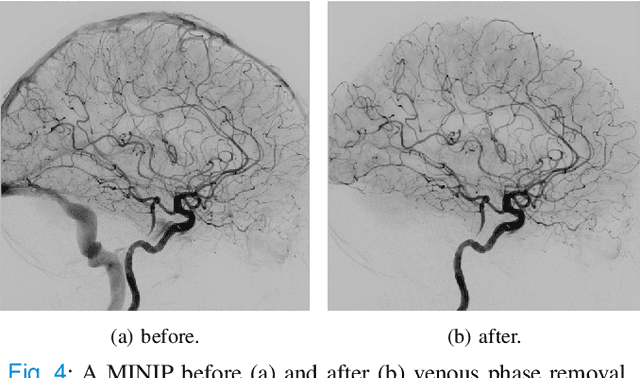
The Thrombolysis in Cerebral Infarction (TICI) score is an important metric for reperfusion therapy assessment in acute ischemic stroke. It is commonly used as a technical outcome measure after endovascular treatment (EVT). Existing TICI scores are defined in coarse ordinal grades based on visual inspection, leading to inter- and intra-observer variation. In this work, we present autoTICI, an automatic and quantitative TICI scoring method. First, each digital subtraction angiography (DSA) sequence is separated into four phases (non-contrast, arterial, parenchymal and venous phase) using a multi-path convolutional neural network (CNN), which exploits spatio-temporal features. The network also incorporates sequence level label dependencies in the form of a state-transition matrix. Next, a minimum intensity map (MINIP) is computed using the motion corrected arterial and parenchymal frames. On the MINIP image, vessel, perfusion and background pixels are segmented. Finally, we quantify the autoTICI score as the ratio of reperfused pixels after EVT. On a routinely acquired multi-center dataset, the proposed autoTICI shows good correlation with the extended TICI (eTICI) reference with an average area under the curve (AUC) score of 0.81. The AUC score is 0.90 with respect to the dichotomized eTICI. In terms of clinical outcome prediction, we demonstrate that autoTICI is overall comparable to eTICI.
On the surprising similarities between supervised and self-supervised models
Oct 16, 2020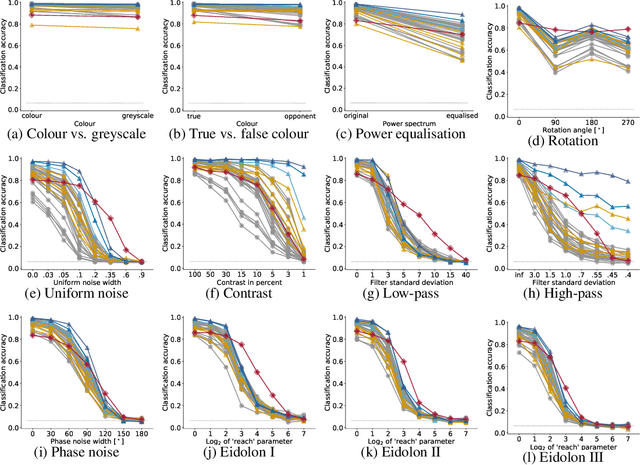
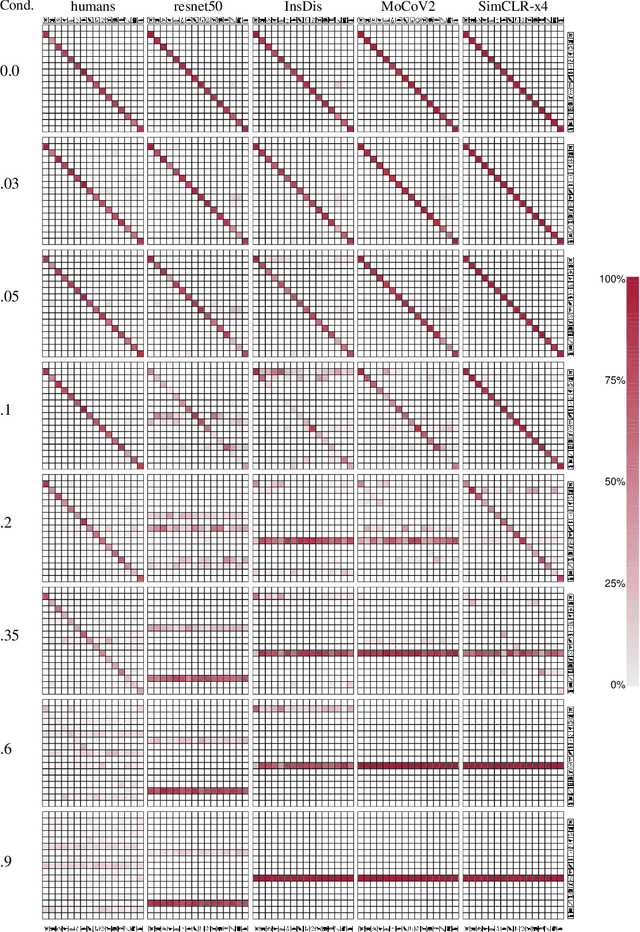
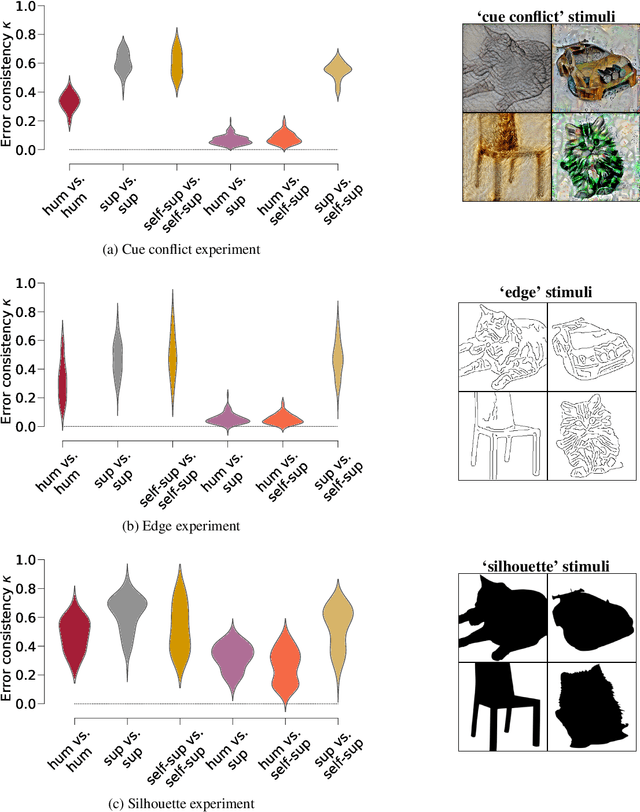
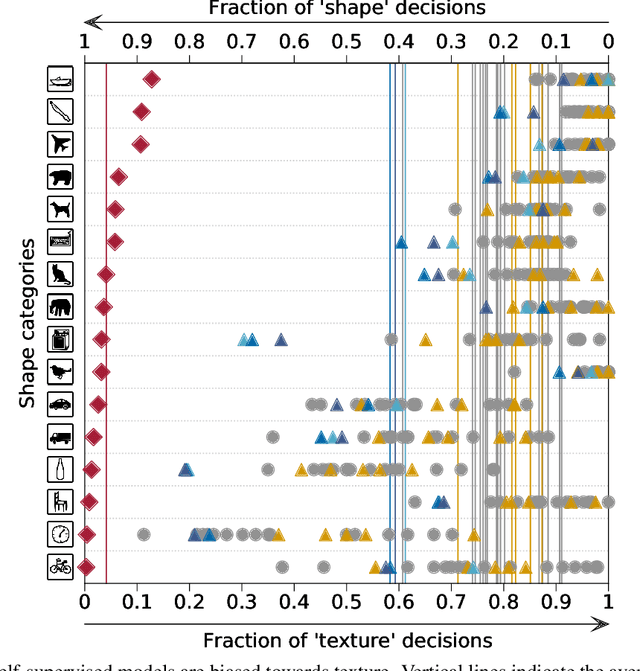
How do humans learn to acquire a powerful, flexible and robust representation of objects? While much of this process remains unknown, it is clear that humans do not require millions of object labels. Excitingly, recent algorithmic advancements in self-supervised learning now enable convolutional neural networks (CNNs) to learn useful visual object representations without supervised labels, too. In the light of this recent breakthrough, we here compare self-supervised networks to supervised models and human behaviour. We tested models on 15 generalisation datasets for which large-scale human behavioural data is available (130K highly controlled psychophysical trials). Surprisingly, current self-supervised CNNs share four key characteristics of their supervised counterparts: (1.) relatively poor noise robustness (with the notable exception of SimCLR), (2.) non-human category-level error patterns, (3.) non-human image-level error patterns (yet high similarity to supervised model errors) and (4.) a bias towards texture. Taken together, these results suggest that the strategies learned through today's supervised and self-supervised training objectives end up being surprisingly similar, but distant from human-like behaviour. That being said, we are clearly just at the beginning of what could be called a self-supervised revolution of machine vision, and we are hopeful that future self-supervised models behave differently from supervised ones, and---perhaps---more similar to robust human object recognition.