 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Automated Image Analysis Framework for the High-Throughput Determination of Grapevine Berry Sizes Using Conditional Random Fields
Dec 15, 2017
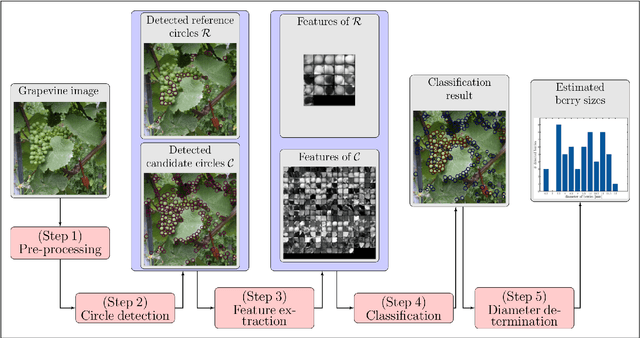
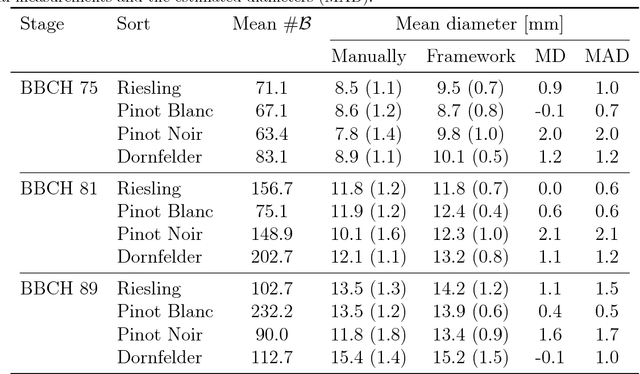
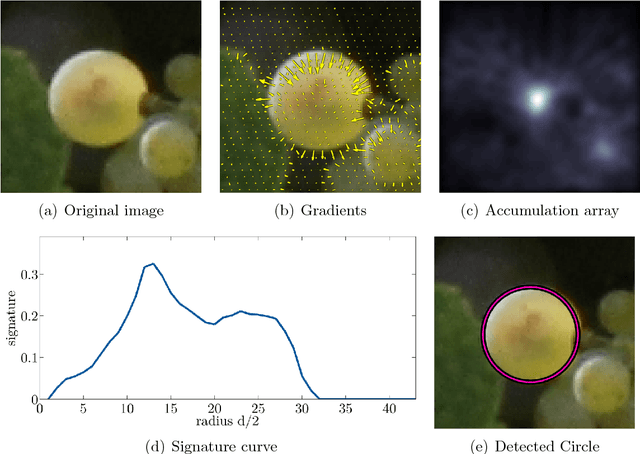

The berry size is one of the most important fruit traits in grapevine breeding. Non-invasive, image-based phenotyping promises a fast and precise method for the monitoring of the grapevine berry size. In the present study an automated image analyzing framework was developed in order to estimate the size of grapevine berries from images in a high-throughput manner. The framework includes (i) the detection of circular structures which are potentially berries and (ii) the classification of these into the class 'berry' or 'non-berry' by utilizing a conditional random field. The approach used the concept of a one-class classification, since only the target class 'berry' is of interest and needs to be modeled. Moreover, the classification was carried out by using an automated active learning approach, i.e no user interaction is required during the classification process and in addition, the process adapts automatically to changing image conditions, e.g. illumination or berry color. The framework was tested on three datasets consisting in total of 139 images. The images were taken in an experimental vineyard at different stages of grapevine growth according to the BBCH scale. The mean berry size of a plant estimated by the framework correlates with the manually measured berry size by $0.88$.
Contextual Fusion For Adversarial Robustness
Nov 18, 2020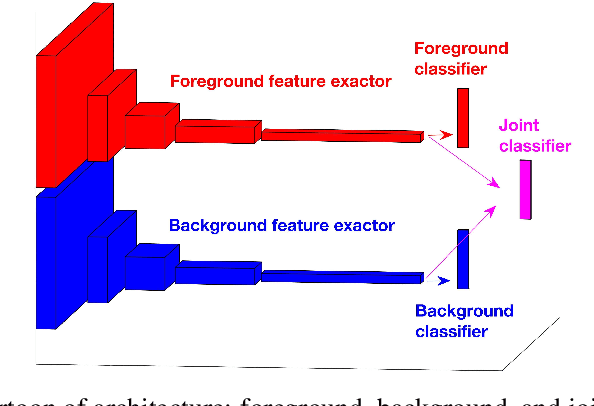
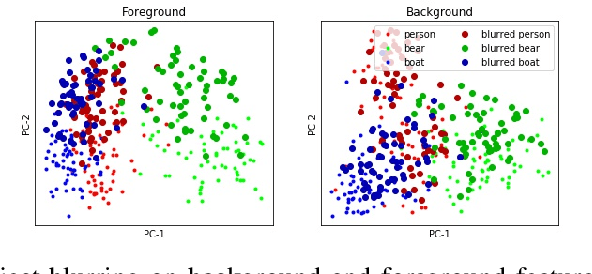
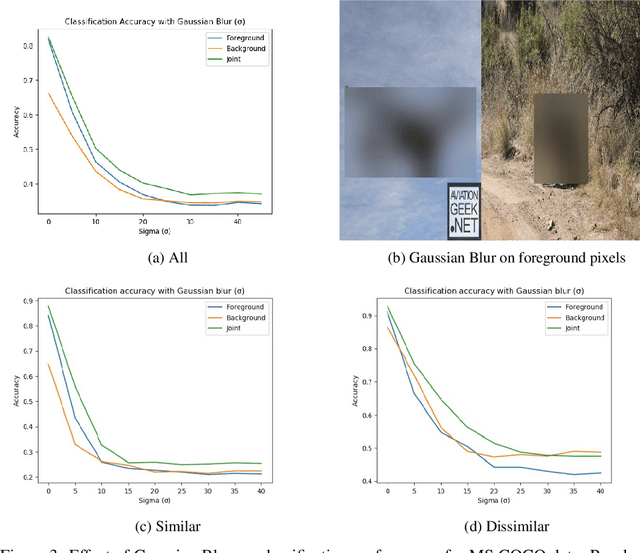
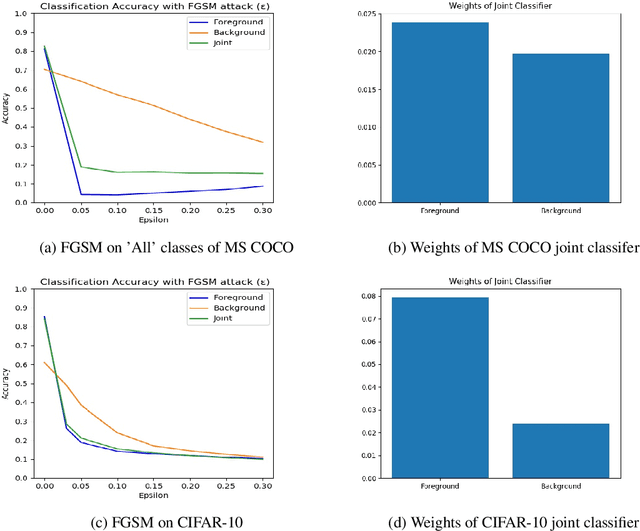
Mammalian brains handle complex reasoning tasks in a gestalt manner by integrating information from regions of the brain that are specialised to individual sensory modalities. This allows for improved robustness and better generalisation ability. In contrast, deep neural networks are usually designed to process one particular information stream and susceptible to various types of adversarial perturbations. While many methods exist for detecting and defending against adversarial attacks, they do not generalise across a range of attacks and negatively affect performance on clean, unperturbed data. We developed a fusion model using a combination of background and foreground features extracted in parallel from Places-CNN and Imagenet-CNN. We tested the benefits of the fusion approach on preserving adversarial robustness for human perceivable (e.g., Gaussian blur) and network perceivable (e.g., gradient-based) attacks for CIFAR-10 and MS COCO data sets. For gradient based attacks, our results show that fusion allows for significant improvements in classification without decreasing performance on unperturbed data and without need to perform adversarial retraining. Our fused model revealed improvements for Gaussian blur type perturbations as well. The increase in performance from fusion approach depended on the variability of the image contexts; larger increases were seen for classes of images with larger differences in their contexts. We also demonstrate the effect of regularization to bias the classifier decision in the presence of a known adversary. We propose that this biologically inspired approach to integrate information across multiple modalities provides a new way to improve adversarial robustness that can be complementary to current state of the art approaches.
Diverse and Accurate Image Description Using a Variational Auto-Encoder with an Additive Gaussian Encoding Space
Nov 19, 2017
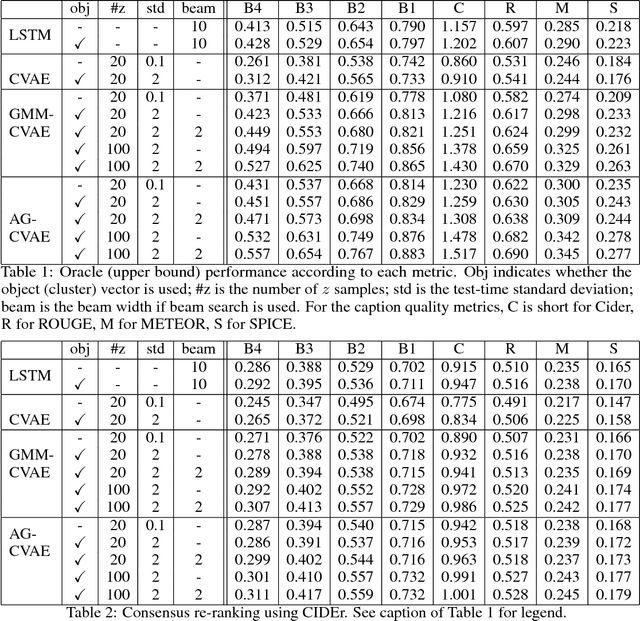

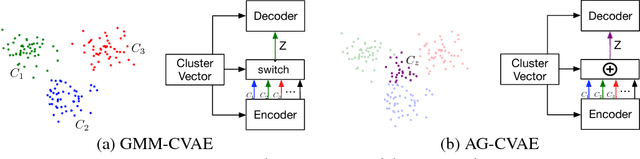
This paper explores image caption generation using conditional variational auto-encoders (CVAEs). Standard CVAEs with a fixed Gaussian prior yield descriptions with too little variability. Instead, we propose two models that explicitly structure the latent space around $K$ components corresponding to different types of image content, and combine components to create priors for images that contain multiple types of content simultaneously (e.g., several kinds of objects). Our first model uses a Gaussian Mixture model (GMM) prior, while the second one defines a novel Additive Gaussian (AG) prior that linearly combines component means. We show that both models produce captions that are more diverse and more accurate than a strong LSTM baseline or a "vanilla" CVAE with a fixed Gaussian prior, with AG-CVAE showing particular promise.
DeepSym: Deep Symbol Generation and Rule Learning from Unsupervised Continuous Robot Interaction for Planning
Dec 04, 2020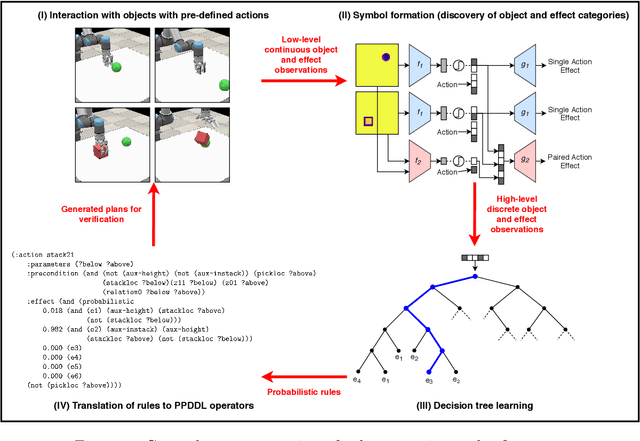
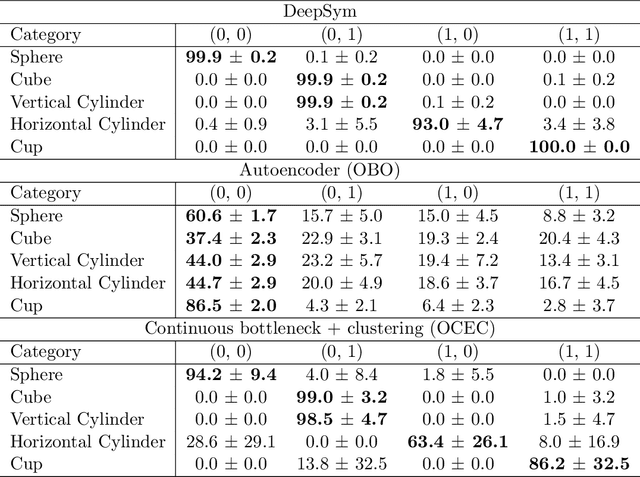
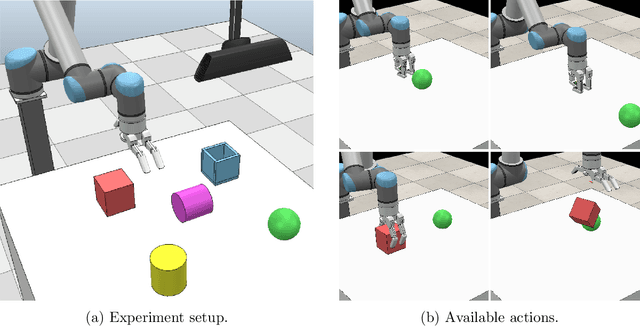

Autonomous discovery of discrete symbols and rules from continuous interaction experience is a crucial building block of robot AI, but remains a challenging problem. Solving it will overcome the limitations in scalability, flexibility, and robustness of manually-designed symbols and rules, and will constitute a substantial advance towards autonomous robots that can learn and reason at abstract levels in open-ended environments. Towards this goal, we propose a novel and general method that finds action-grounded, discrete object and effect categories and builds probabilistic rules over them that can be used in complex action planning. Our robot interacts with single and multiple objects using a given action repertoire and observes the effects created in the environment. In order to form action-grounded object, effect, and relational categories, we employ a binarized bottleneck layer of a predictive, deep encoder-decoder network that takes as input the image of the scene and the action applied, and generates the resulting object displacements in the scene (action effects) in pixel coordinates. The binary latent vector represents a learned, action-driven categorization of objects. To distill the knowledge represented by the neural network into rules useful for symbolic reasoning, we train a decision tree to reproduce its decoder function. From its branches we extract probabilistic rules and represent them in PPDDL, allowing off-the-shelf planners to operate on the robot's sensorimotor experience. Our system is verified in a physics-based 3d simulation environment where a robot arm-hand system learned symbols that can be interpreted as 'rollable', 'insertable', 'larger-than' from its push and stack actions; and generated effective plans to achieve goals such as building towers from given cubes, balls, and cups using off-the-shelf probabilistic planners.
Exploring the Efficacy of Transfer Learning in Mining Image-Based Software Artifacts
Mar 03, 2020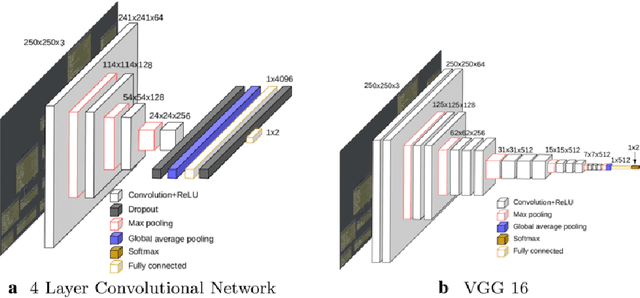
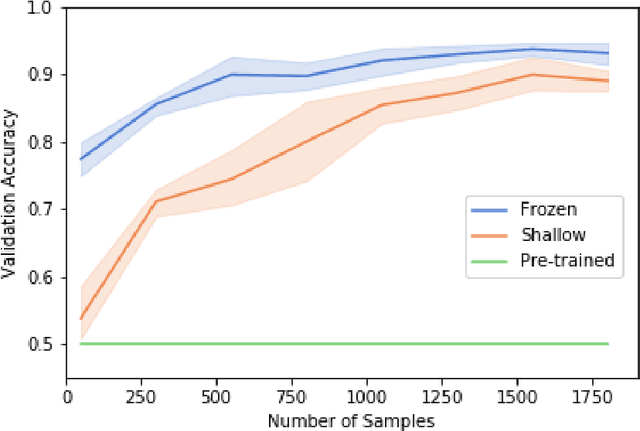
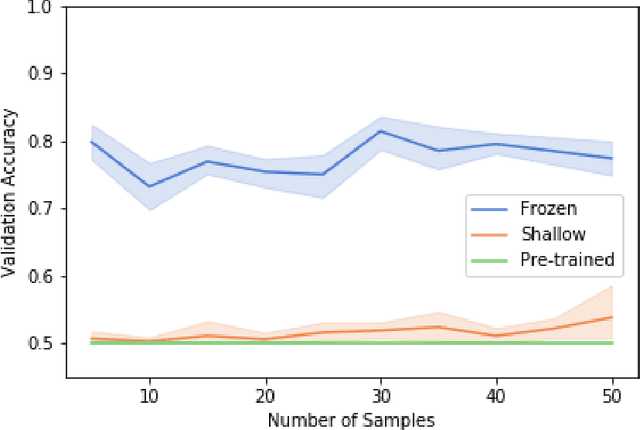
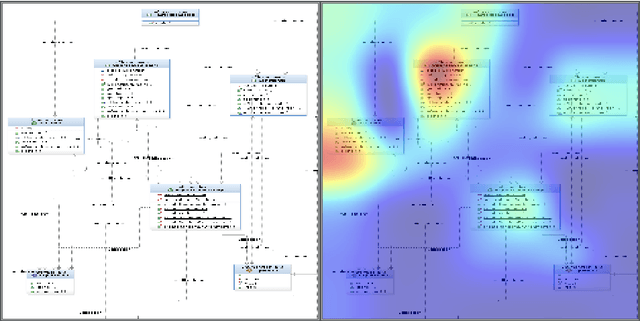
Transfer learning allows us to train deep architectures requiring a large number of learned parameters, even if the amount of available data is limited, by leveraging existing models previously trained for another task. Here we explore the applicability of transfer learning utilizing models pre-trained on non-software engineering data applied to the problem of classifying software UML diagrams. Our experimental results show training reacts positively to transfer learning as related to sample size, even though the pre-trained model was not exposed to training instances from the software domain. We contrast the transferred network with other networks to show its advantage on different sized training sets, which indicates that transfer learning is equally effective to custom deep architectures when large amounts of training data is not available.
A Dual Sparse Decomposition Method for Image Denoising
Apr 24, 2017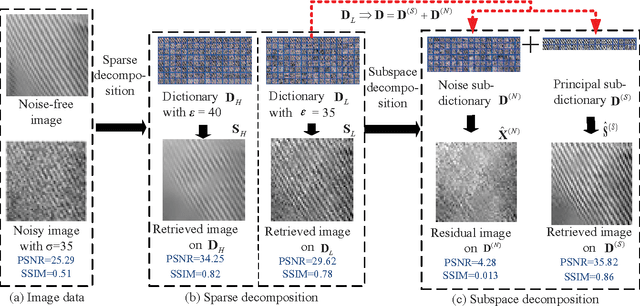
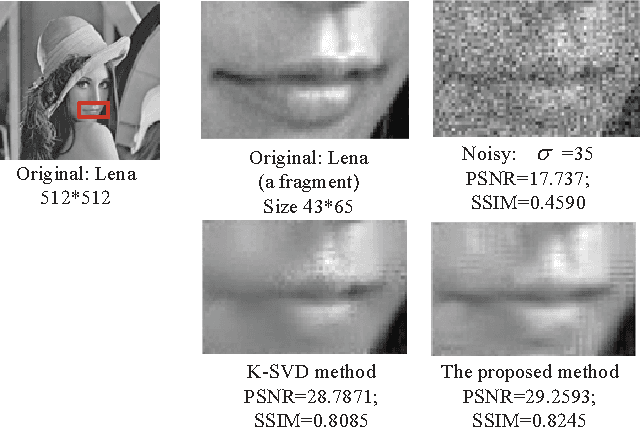

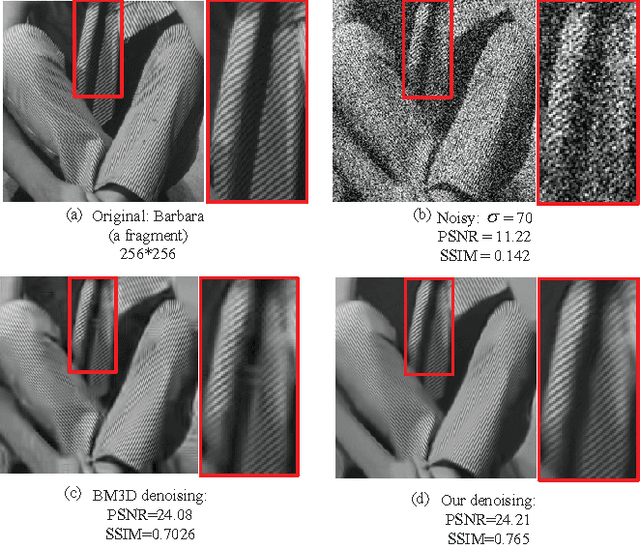
This article addresses the image denoising problem in the situations of strong noise. We propose a dual sparse decomposition method. This method makes a sub-dictionary decomposition on the over-complete dictionary in the sparse decomposition. The sub-dictionary decomposition makes use of a novel criterion based on the occurrence frequency of atoms of the over-complete dictionary over the data set. The experimental results demonstrate that the dual-sparse-decomposition method surpasses state-of-art denoising performance in terms of both peak-signal-to-noise ratio and structural-similarity-index-metric, and also at subjective visual quality.
ZoomCount: A Zooming Mechanism for Crowd Counting in Static Images
Feb 27, 2020


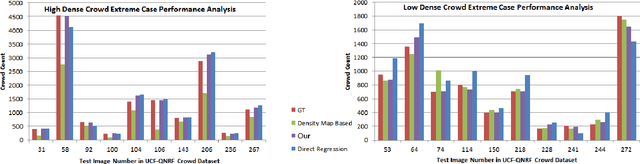
This paper proposes a novel approach for crowd counting in low to high density scenarios in static images. Current approaches cannot handle huge crowd diversity well and thus perform poorly in extreme cases, where the crowd density in different regions of an image is either too low or too high, leading to crowd underestimation or overestimation. The proposed solution is based on the observation that detecting and handling such extreme cases in a specialized way leads to better crowd estimation. Additionally, existing methods find it hard to differentiate between the actual crowd and the cluttered background regions, resulting in further count overestimation. To address these issues, we propose a simple yet effective modular approach, where an input image is first subdivided into fixed-size patches and then fed to a four-way classification module labeling each image patch as low, medium, high-dense or no-crowd. This module also provides a count for each label, which is then analyzed via a specifically devised novel decision module to decide whether the image belongs to any of the two extreme cases (very low or very high density) or a normal case. Images, specified as high- or low-density extreme or a normal case, pass through dedicated zooming or normal patch-making blocks respectively before routing to the regressor in the form of fixed-size patches for crowd estimate. Extensive experimental evaluations demonstrate that the proposed approach outperforms the state-of-the-art methods on four benchmarks under most of the evaluation criteria.
Player Identification in Hockey Broadcast Videos
Sep 14, 2020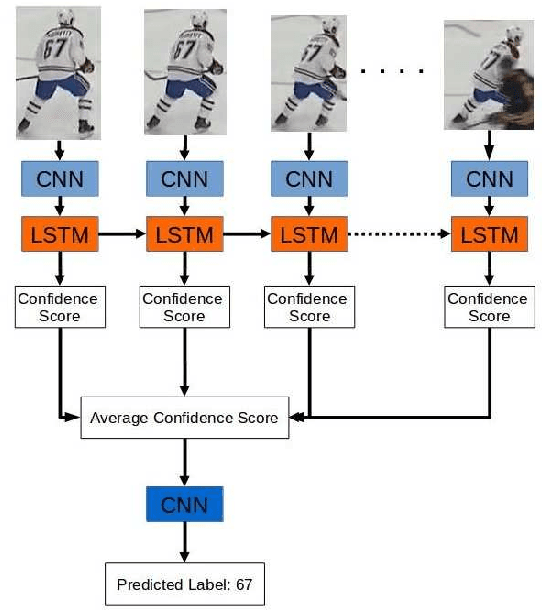
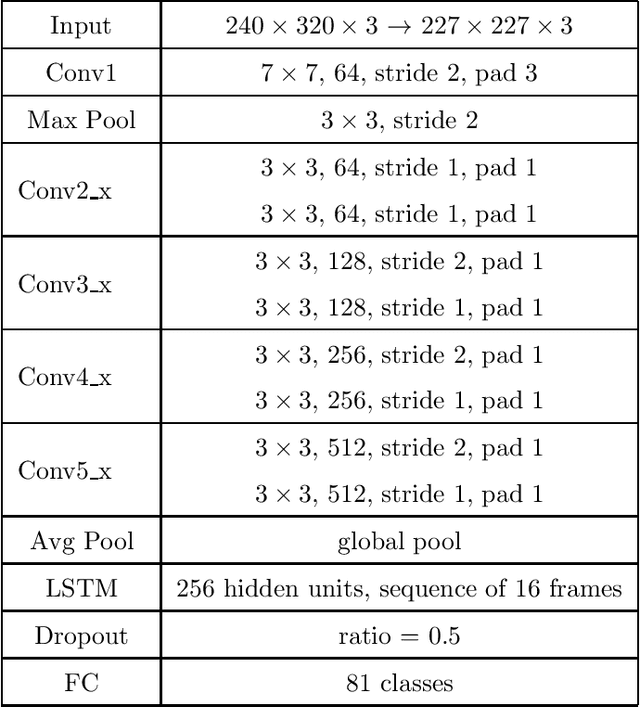
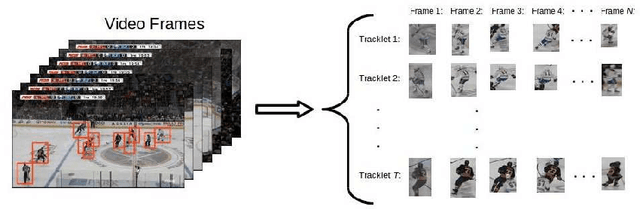
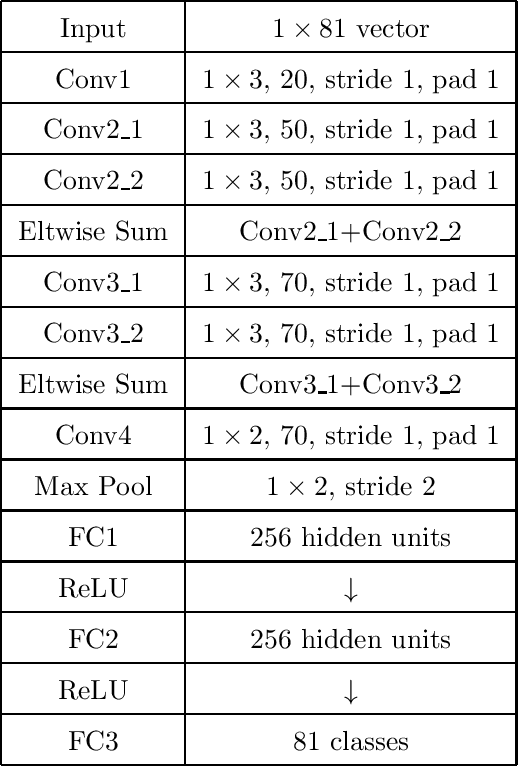
We present a deep recurrent convolutional neural network (CNN) approach to solve the problem of hockey player identification in NHL broadcast videos. Player identification is a difficult computer vision problem mainly because of the players' similar appearance, occlusion, and blurry facial and physical features. However, we can observe players' jersey numbers over time by processing variable length image sequences of players (aka 'tracklets'). We propose an end-to-end trainable ResNet+LSTM network, with a residual network (ResNet) base and a long short-term memory (LSTM) layer, to discover spatio-temporal features of jersey numbers over time and learn long-term dependencies. For this work, we created a new hockey player tracklet dataset that contains sequences of hockey player bounding boxes. Additionally, we employ a secondary 1-dimensional convolutional neural network classifier as a late score-level fusion method to classify the output of the ResNet+LSTM network. This achieves an overall player identification accuracy score over 87% on the test split of our new dataset.
Mutual Information Regularized Identity-aware Facial ExpressionRecognition in Compressed Video
Oct 20, 2020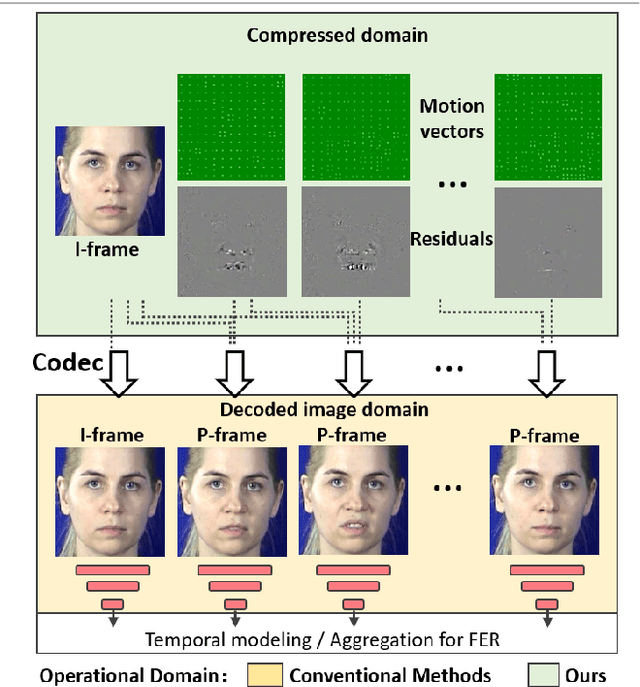
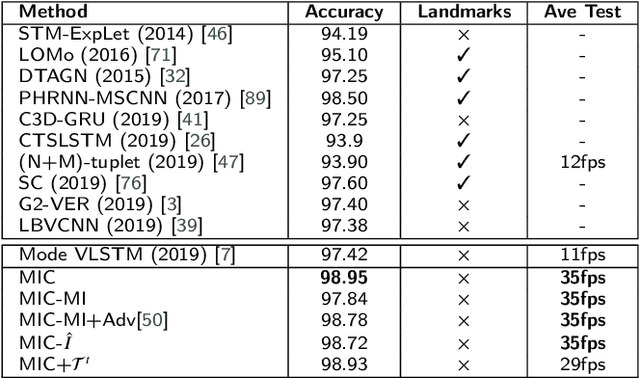
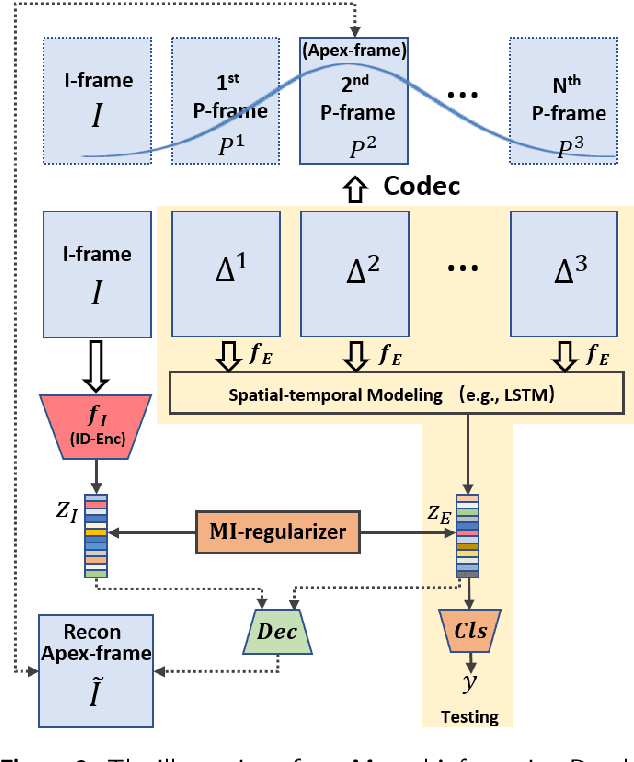
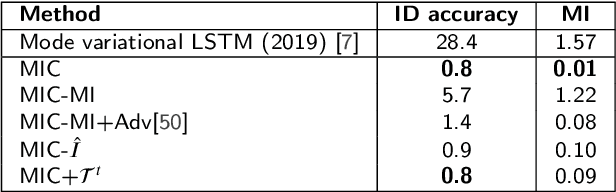
This paper targets to explore the inter-subject variations eliminated facial expression representation in the compressed video domain. Most of the previous methods process the RGB images of a sequence, while the off-the-shelf and valuable expression-related muscle movement already embedded in the compression format. In the up to two orders of magnitude compressed domain, we can explicitly infer the expression from the residual frames and possible to extract identity factors from the I frame with a pre-trained face recognition network. By enforcing the marginal independent of them, the expression feature is expected to be purer for the expression and be robust to identity shifts. Specifically, we propose a novel collaborative min-min game for mutual information (MI) minimization in latent space. We do not need the identity label or multiple expression samples from the same person for identity elimination. Moreover, when the apex frame is annotated in the dataset, the complementary constraint can be further added to regularize the feature-level game. In testing, only the compressed residual frames are required to achieve expression prediction. Our solution can achieve comparable or better performance than the recent decoded image-based methods on the typical FER benchmarks with about 3 times faster inference.
Three-branch and Mutil-scale learning for Fine-grained Image Recognition (TBMSL-Net)
Mar 27, 2020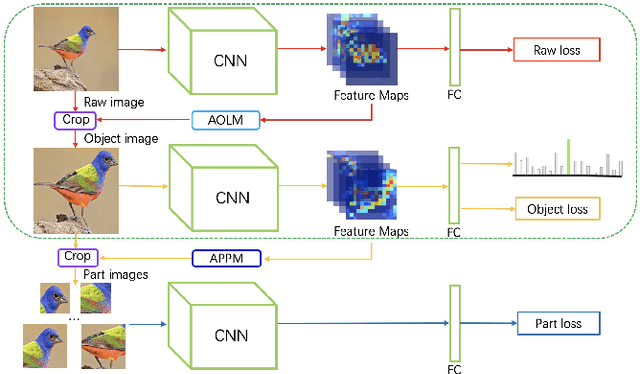
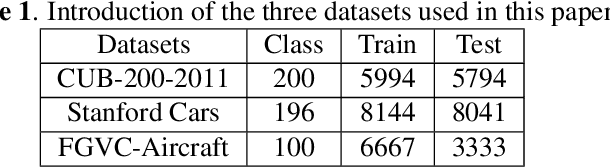
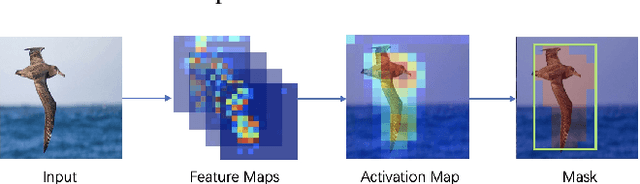
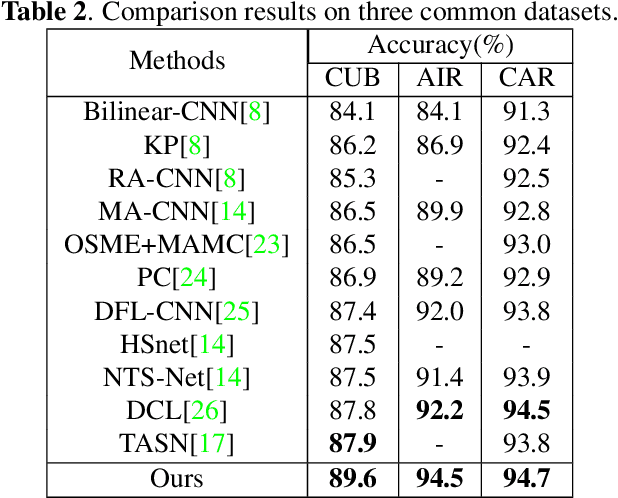
ImageNet Large Scale Visual Recognition Challenge (ILSVRC) is one of the most authoritative academic competitions in the field of Computer Vision (CV) in recent years, but it can not achieve good result to directly migrate the champions of the annual competition, to fine-grained visual categorization (FGVC) tasks. The small interclass variations and the large intraclass variations caused by the fine-grained nature makes it a challenging problem. The proposed method can be effectively localize object and useful part regions without the need of bounding-box and part annotations by attention object location module (AOLM) and attention part proposal module (APPM). The obtained object images contain both the whole structure and more details, the part images have many different scales and have more fine-grained features, and the raw images contain the complete object. The three kinds of training images are supervised by our three-branch network structure. The model has good classification ability, good generalization and robustness for different scale object images. Our approach is end-to-end training, through the comprehensive experiments demonstrate that our approach achieves state-of-the-art results on CUB-200-2011, Stanford Cars and FGVC-Aircraft datasets.