 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Reinforcing Short-Length Hashing
Apr 24, 2020
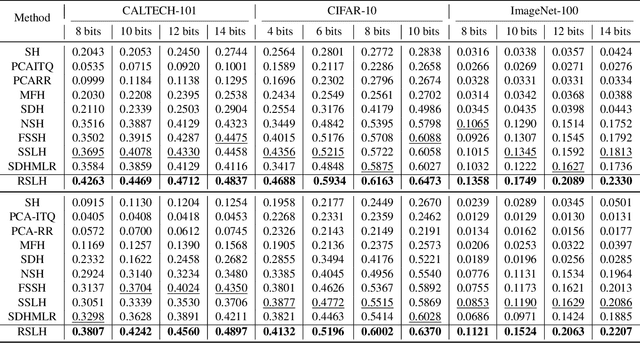
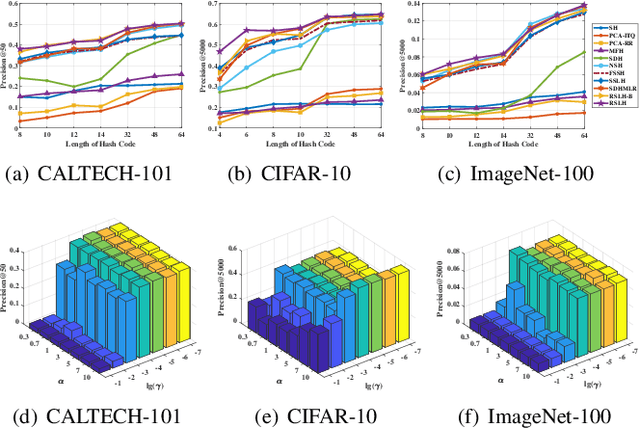
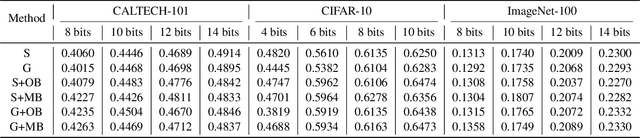
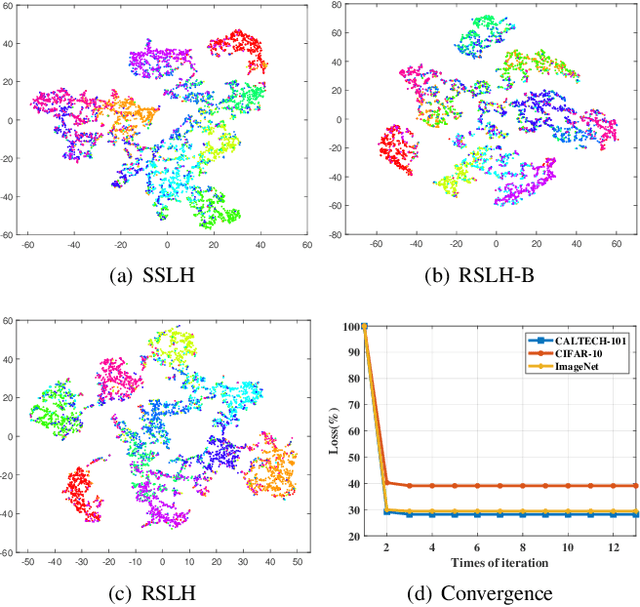
Due to the compelling efficiency in retrieval and storage, similarity-preserving hashing has been widely applied to approximate nearest neighbor search in large-scale image retrieval. However, existing methods have poor performance in retrieval using an extremely short-length hash code due to weak ability of classification and poor distribution of hash bit. To address this issue, in this study, we propose a novel reinforcing short-length hashing (RSLH). In this proposed RSLH, mutual reconstruction between the hash representation and semantic labels is performed to preserve the semantic information. Furthermore, to enhance the accuracy of hash representation, a pairwise similarity matrix is designed to make a balance between accuracy and training expenditure on memory. In addition, a parameter boosting strategy is integrated to reinforce the precision with hash bits fusion. Extensive experiments on three large-scale image benchmarks demonstrate the superior performance of RSLH under various short-length hashing scenarios.
Implementation of Deep Convolutional Neural Network in Multi-class Categorical Image Classification
Jan 03, 2018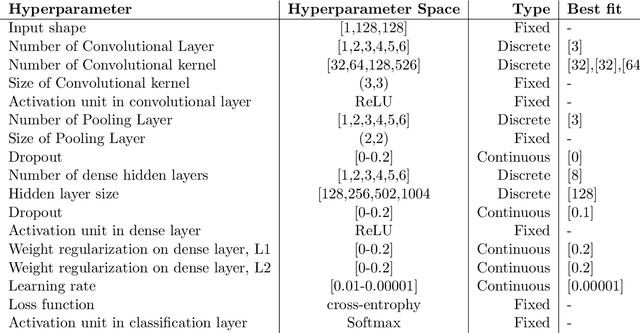
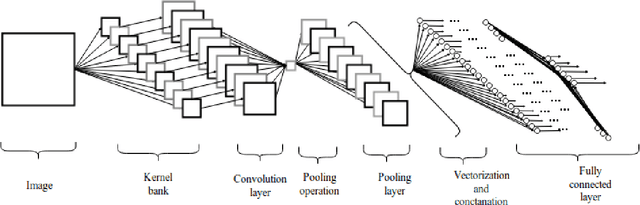
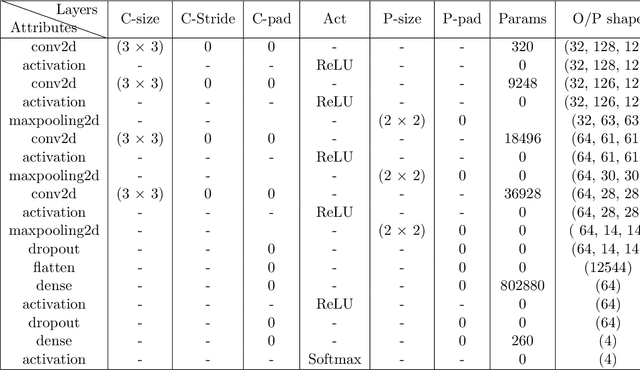
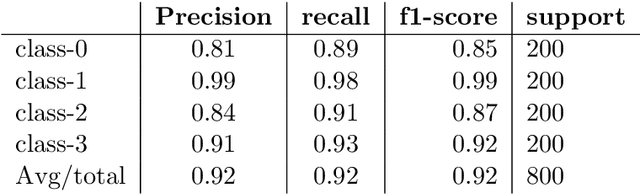
Convolutional Neural Networks has been implemented in many complex machine learning takes such as image classification, object identification, autonomous vehicle and robotic vision tasks. However, ConvNet architecture efficiency and accuracy depend on a large number of fac- tors. Also, the complex architecture requires a significant amount of data to train and involves with a large number of hyperparameters that increases the computational expenses and difficul- ties. Hence, it is necessary to address the limitations and techniques to overcome the barriers to ensure that the architecture performs well in complex visual tasks. This article is intended to develop an efficient ConvNet architecture for multi-class image categorical classification applica- tion. In the development of the architecture, large pool of grey scale images are taken as input information images and split into training and test datasets. The numerously available technique is implemented to reduce the overfitting and poor generalization of the network. The hyperpa- rameters of determined by Bayesian Optimization with Gaussian Process prior algorithm. ReLu non-linear activation function is implemented after the convolutional layers. Max pooling op- eration is carried out to downsampling the data points in pooling layers. Cross-entropy loss function is used to measure the performance of the architecture where the softmax is used in the classification layer. Mini-batch gradient descent with Adam optimizer algorithm is used for backpropagation. Developed architecture is validated with confusion matrix and classification report.
Multi-scale Image Fusion Between Pre-operative Clinical CT and X-ray Microtomography of Lung Pathology
Feb 27, 2017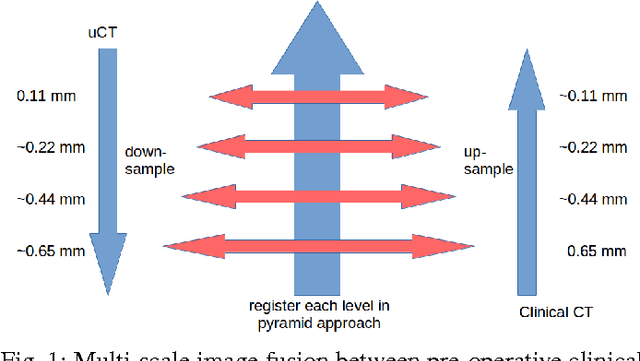
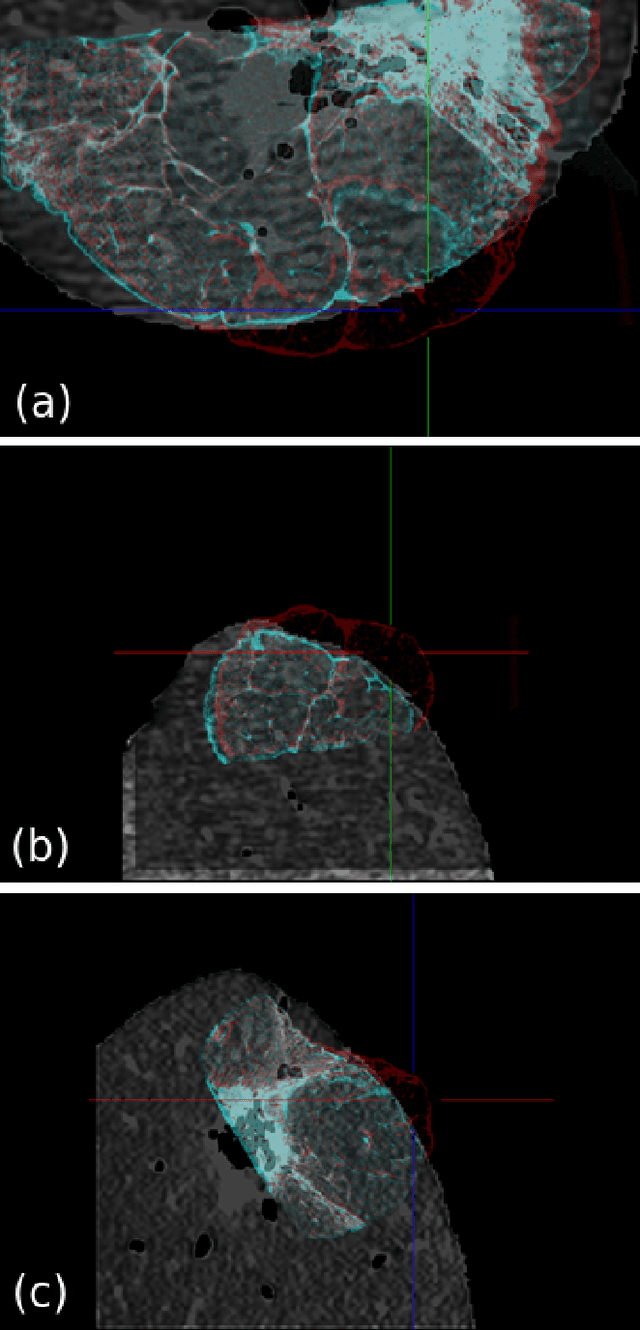
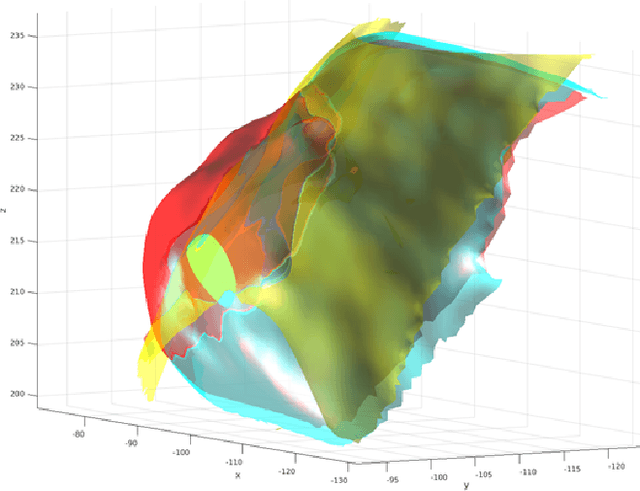
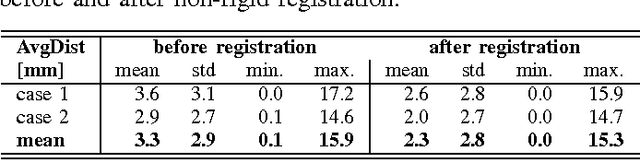
Computational anatomy allows the quantitative analysis of organs in medical images. However, most analysis is constrained to the millimeter scale because of the limited resolution of clinical computed tomography (CT). X-ray microtomography ($\mu$CT) on the other hand allows imaging of ex-vivo tissues at a resolution of tens of microns. In this work, we use clinical CT to image lung cancer patients before partial pneumonectomy (resection of pathological lung tissue). The resected specimen is prepared for $\mu$CT imaging at a voxel resolution of 50 $\mu$m (0.05 mm). This high-resolution image of the lung cancer tissue allows further insides into understanding of tumor growth and categorization. For making full use of this additional information, image fusion (registration) needs to be performed in order to re-align the $\mu$CT image with clinical CT. We developed a multi-scale non-rigid registration approach. After manual initialization using a few landmark points and rigid alignment, several levels of non-rigid registration between down-sampled (in the case of $\mu$CT) and up-sampled (in the case of clinical CT) representations of the image are performed. Any non-lung tissue is ignored during the computation of the similarity measure used to guide the registration during optimization. We are able to recover the volume differences introduced by the resection and preparation of the lung specimen. The average ($\pm$ std. dev.) minimum surface distance between $\mu$CT and clinical CT at the resected lung surface is reduced from 3.3 $\pm$ 2.9 (range: [0.1, 15.9]) to 2.3 mm $\pm$ 2.8 (range: [0.0, 15.3]) mm. The alignment of clinical CT with $\mu$CT will allow further registration with even finer resolutions of $\mu$CT (up to 10 $\mu$m resolution) and ultimately with histopathological microscopy images for further macro to micro image fusion that can aid medical image analysis.
Deep Lighting Environment Map Estimation from Spherical Panoramas
May 16, 2020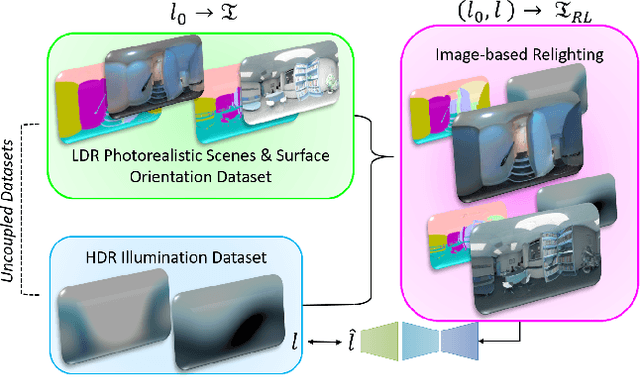
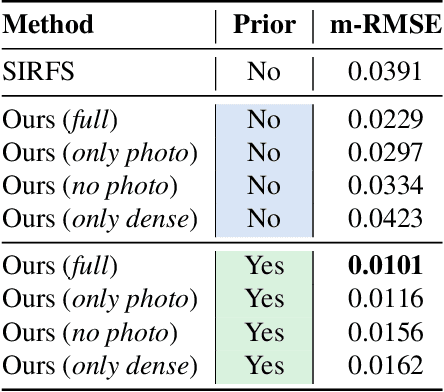


Estimating a scene's lighting is a very important task when compositing synthetic content within real environments, with applications in mixed reality and post-production. In this work we present a data-driven model that estimates an HDR lighting environment map from a single LDR monocular spherical panorama. In addition to being a challenging and ill-posed problem, the lighting estimation task also suffers from a lack of facile illumination ground truth data, a fact that hinders the applicability of data-driven methods. We approach this problem differently, exploiting the availability of surface geometry to employ image-based relighting as a data generator and supervision mechanism. This relies on a global Lambertian assumption that helps us overcome issues related to pre-baked lighting. We relight our training data and complement the model's supervision with a photometric loss, enabled by a differentiable image-based relighting technique. Finally, since we predict spherical spectral coefficients, we show that by imposing a distribution prior on the predicted coefficients, we can greatly boost performance. Code and models available at https://vcl3d.github.io/DeepPanoramaLighting.
Enhanced detection of fetal pose in 3D MRI by Deep Reinforcement Learning with physical structure priors on anatomy
Jul 16, 2020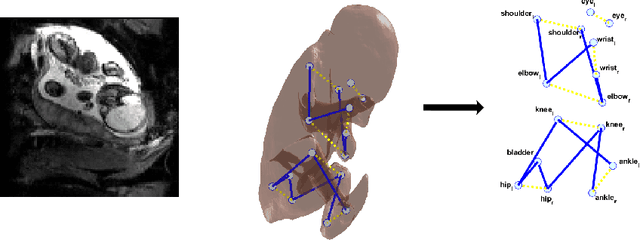
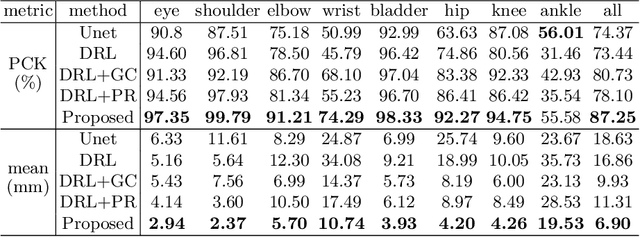
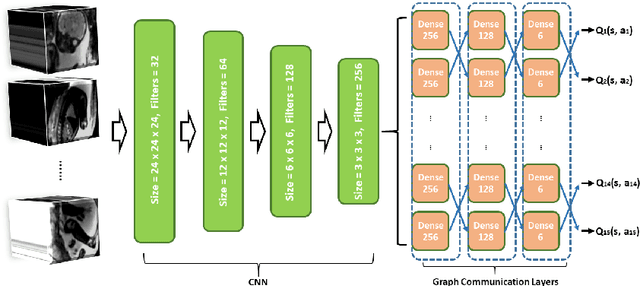
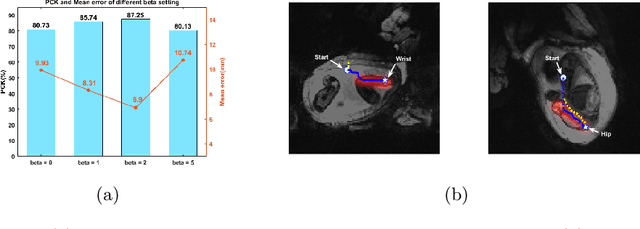
Fetal MRI is heavily constrained by unpredictable and substantial fetal motion that causes image artifacts and limits the set of viable diagnostic image contrasts. Current mitigation of motion artifacts is predominantly performed by fast, single-shot MRI and retrospective motion correction. Estimation of fetal pose in real time during MRI stands to benefit prospective methods to detect and mitigate fetal motion artifacts where inferred fetal motion is combined with online slice prescription with low-latency decision making. Current developments of deep reinforcement learning (DRL), offer a novel approach for fetal landmarks detection. In this task 15 agents are deployed to detect 15 landmarks simultaneously by DRL. The optimization is challenging, and here we propose an improved DRL that incorporates priors on physical structure of the fetal body. First, we use graph communication layers to improve the communication among agents based on a graph where each node represents a fetal-body landmark. Further, additional reward based on the distance between agents and physical structures such as the fetal limbs is used to fully exploit physical structure. Evaluation of this method on a repository of 3-mm resolution in vivo data demonstrates a mean accuracy of landmark estimation within 10 mm of ground truth as 87.3%, and a mean error of 6.9 mm. The proposed DRL for fetal pose landmark search demonstrates a potential clinical utility for online detection of fetal motion that guides real-time mitigation of motion artifacts as well as health diagnosis during MRI of the pregnant mother.
Feature learning based on visual similarity triplets in medical image analysis: A case study of emphysema in chest CT scans
Jun 19, 2018



Supervised feature learning using convolutional neural networks (CNNs) can provide concise and disease relevant representations of medical images. However, training CNNs requires annotated image data. Annotating medical images can be a time-consuming task and even expert annotations are subject to substantial inter- and intra-rater variability. Assessing visual similarity of images instead of indicating specific pathologies or estimating disease severity could allow non-experts to participate, help uncover new patterns, and possibly reduce rater variability. We consider the task of assessing emphysema extent in chest CT scans. We derive visual similarity triplets from visually assessed emphysema extent and learn a low dimensional embedding using CNNs. We evaluate the networks on 973 images, and show that the CNNs can learn disease relevant feature representations from derived similarity triplets. To our knowledge this is the first medical image application where similarity triplets has been used to learn a feature representation that can be used for embedding unseen test images
Importance-Aware Semantic Segmentation in Self-Driving with Discrete Wasserstein Training
Oct 21, 2020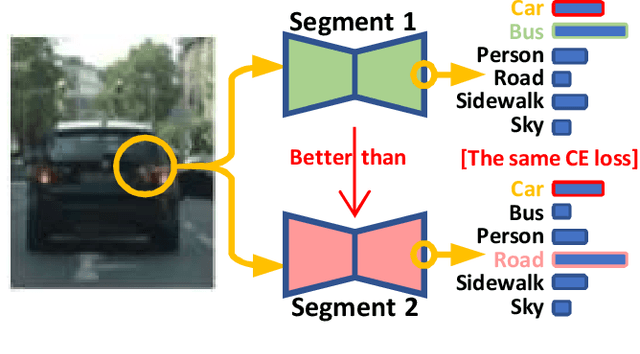
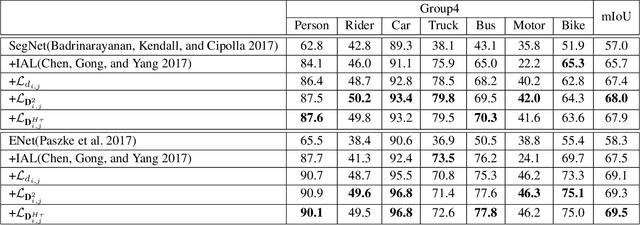
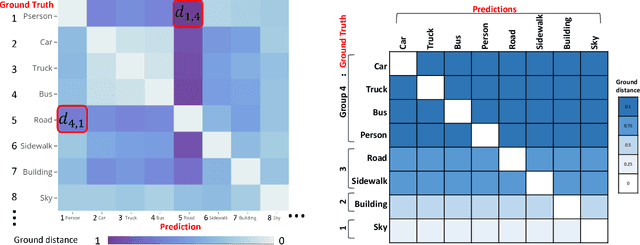
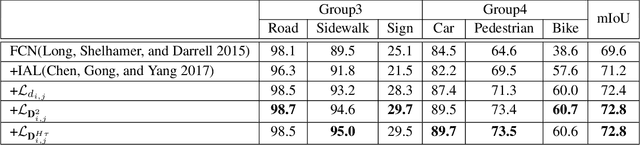
Semantic segmentation (SS) is an important perception manner for self-driving cars and robotics, which classifies each pixel into a pre-determined class. The widely-used cross entropy (CE) loss-based deep networks has achieved significant progress w.r.t. the mean Intersection-over Union (mIoU). However, the cross entropy loss can not take the different importance of each class in an self-driving system into account. For example, pedestrians in the image should be much more important than the surrounding buildings when make a decisions in the driving, so their segmentation results are expected to be as accurate as possible. In this paper, we propose to incorporate the importance-aware inter-class correlation in a Wasserstein training framework by configuring its ground distance matrix. The ground distance matrix can be pre-defined following a priori in a specific task, and the previous importance-ignored methods can be the particular cases. From an optimization perspective, we also extend our ground metric to a linear, convex or concave increasing function $w.r.t.$ pre-defined ground distance. We evaluate our method on CamVid and Cityscapes datasets with different backbones (SegNet, ENet, FCN and Deeplab) in a plug and play fashion. In our extenssive experiments, Wasserstein loss demonstrates superior segmentation performance on the predefined critical classes for safe-driving.
Beyond Language: Learning Commonsense from Images for Reasoning
Oct 10, 2020

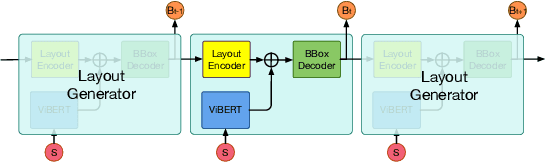
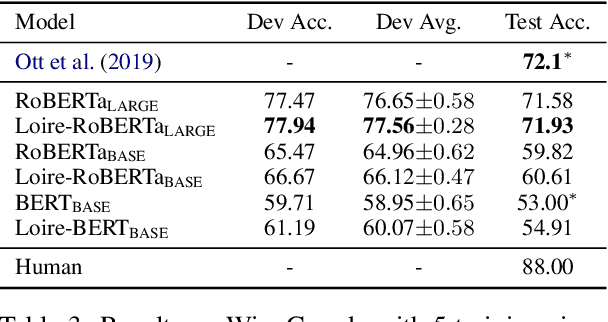
This paper proposes a novel approach to learn commonsense from images, instead of limited raw texts or costly constructed knowledge bases, for the commonsense reasoning problem in NLP. Our motivation comes from the fact that an image is worth a thousand words, where richer scene information could be leveraged to help distill the commonsense knowledge, which is often hidden in languages. Our approach, namely Loire, consists of two stages. In the first stage, a bi-modal sequence-to-sequence approach is utilized to conduct the scene layout generation task, based on a text representation model ViBERT. In this way, the required visual scene knowledge, such as spatial relations, will be encoded in ViBERT by the supervised learning process with some bi-modal data like COCO. Then ViBERT is concatenated with a pre-trained language model to perform the downstream commonsense reasoning tasks. Experimental results on two commonsense reasoning problems, i.e. commonsense question answering and pronoun resolution, demonstrate that Loire outperforms traditional language-based methods. We also give some case studies to show what knowledge is learned from images and explain how the generated scene layout helps the commonsense reasoning process.
Multi-Scale Superpatch Matching using Dual Superpixel Descriptors
Mar 09, 2020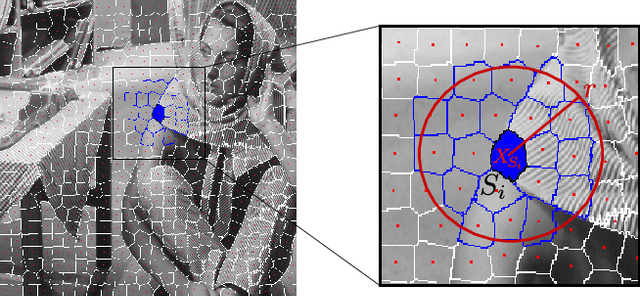
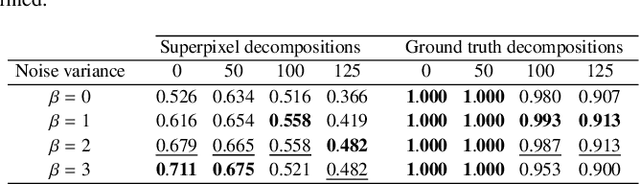
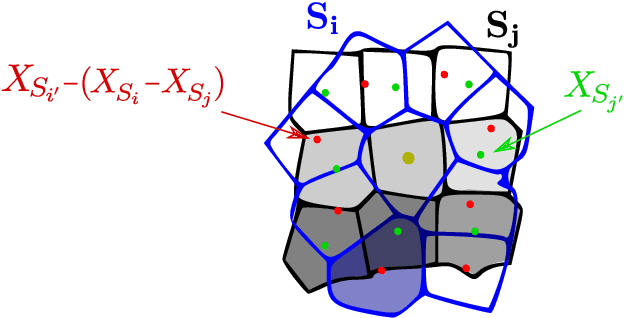
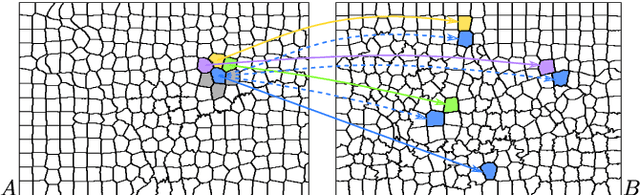
Over-segmentation into superpixels is a very effective dimensionality reduction strategy, enabling fast dense image processing. The main issue of this approach is the inherent irregularity of the image decomposition compared to standard hierarchical multi-resolution schemes, especially when searching for similar neighboring patterns. Several works have attempted to overcome this issue by taking into account the region irregularity into their comparison model. Nevertheless, they remain sub-optimal to provide robust and accurate superpixel neighborhood descriptors, since they only compute features within each region, poorly capturing contour information at superpixel borders. In this work, we address these limitations by introducing the dual superpatch, a novel superpixel neighborhood descriptor. This structure contains features computed in reduced superpixel regions, as well as at the interfaces of multiple superpixels to explicitly capture contour structure information. A fast multi-scale non-local matching framework is also introduced for the search of similar descriptors at different resolution levels in an image dataset. The proposed dual superpatch enables to more accurately capture similar structured patterns at different scales, and we demonstrate the robustness and performance of this new strategy on matching and supervised labeling applications.
Adversarial Training with Fast Gradient Projection Method against Synonym Substitution based Text Attacks
Sep 14, 2020



Adversarial training is the most empirically successful approach in improving the robustness of deep neural networks for image classification. For text classification, however, existing synonym substitution based adversarial attacks are effective but not efficient to be incorporated into practical text adversarial training. Gradient-based attacks, which are very efficient for images, are hard to be implemented for synonym substitution based text attacks due to the lexical, grammatical and semantic constraints and the discrete text input space. Thereby, we propose a fast text adversarial attack method called Fast Gradient Projection Method (FGPM) based on synonym substitution, which is about 20 times faster than existing text attack methods and could achieve similar attack performance. We then incorporate FGPM with adversarial training and propose a text defense method called Adversarial Training with FGPM enhanced by Logit pairing (ATFL). Experiments show that ATFL could significantly improve the model robustness and block the transferability of adversarial examples.