 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Lightweight Lane Detection by Optimizing Spatial Embedding
Aug 19, 2020
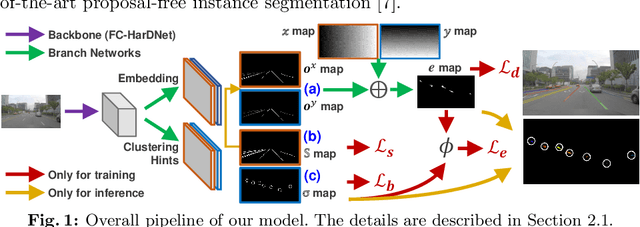
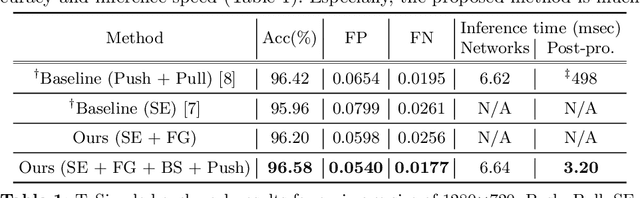
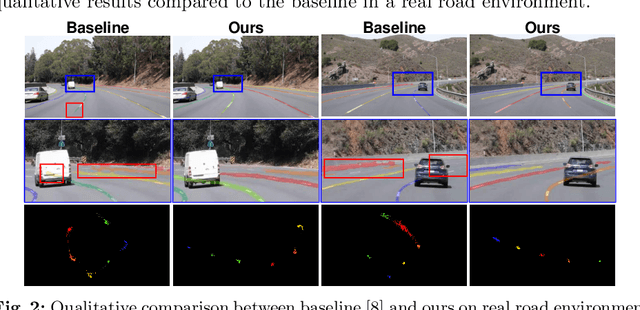
A number of lane detection methods depend on a proposal-free instance segmentation because of its adaptability to flexible object shape, occlusion, and real-time application. This paper addresses the problem that pixel embedding in proposal-free instance segmentation based lane detection is difficult to optimize. A translation invariance of convolution, which is one of the supposed strengths, causes challenges in optimizing pixel embedding. In this work, we propose a lane detection method based on proposal-free instance segmentation, directly optimizing spatial embedding of pixels using image coordinate. Our proposed method allows the post-processing step for center localization and optimizes clustering in an end-to-end manner. The proposed method enables real-time lane detection through the simplicity of post-processing and the adoption of a lightweight backbone. Our proposed method demonstrates competitive performance on public lane detection datasets.
Exemplar Normalization for Learning Deep Representation
Mar 20, 2020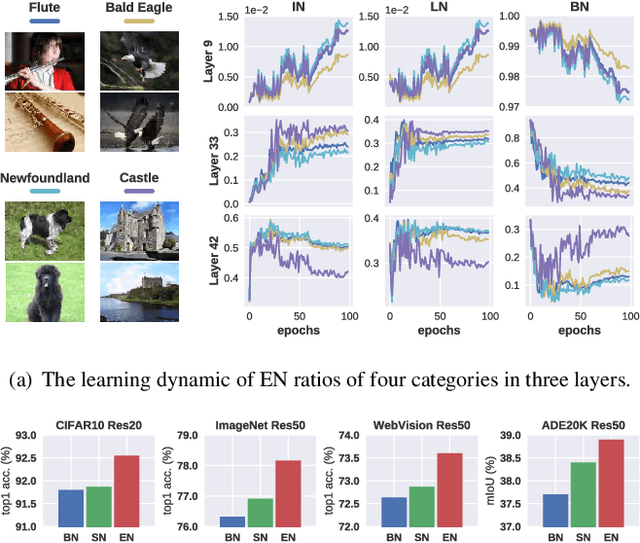
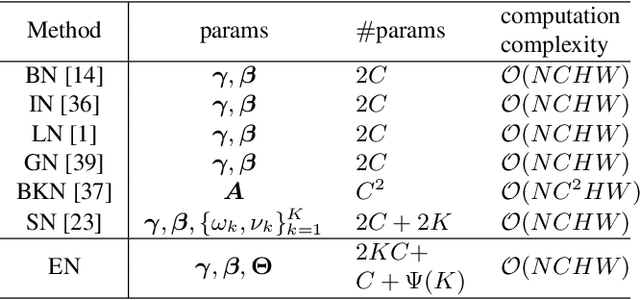
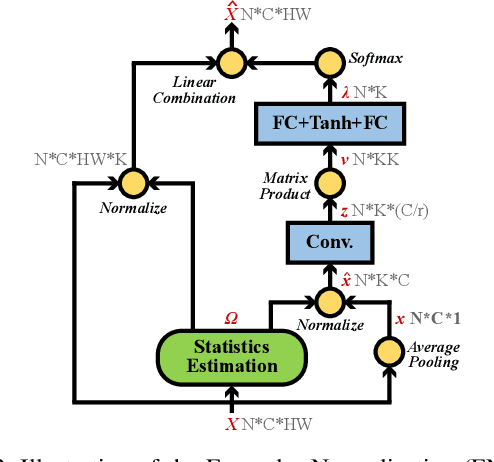
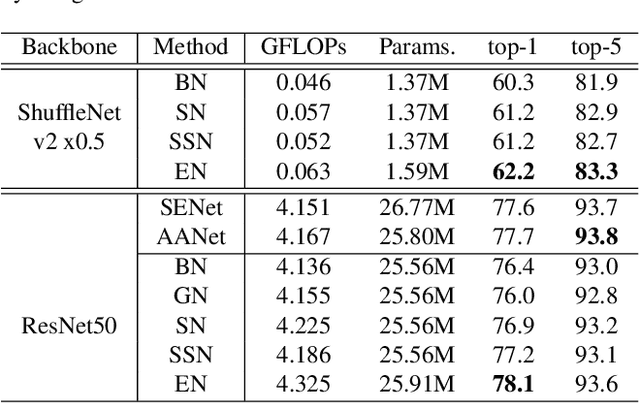
Normalization techniques are important in different advanced neural networks and different tasks. This work investigates a novel dynamic learning-to-normalize (L2N) problem by proposing Exemplar Normalization (EN), which is able to learn different normalization methods for different convolutional layers and image samples of a deep network. EN significantly improves flexibility of the recently proposed switchable normalization (SN), which solves a static L2N problem by linearly combining several normalizers in each normalization layer (the combination is the same for all samples). Instead of directly employing a multi-layer perceptron (MLP) to learn data-dependent parameters as conditional batch normalization (cBN) did, the internal architecture of EN is carefully designed to stabilize its optimization, leading to many appealing benefits. (1) EN enables different convolutional layers, image samples, categories, benchmarks, and tasks to use different normalization methods, shedding light on analyzing them in a holistic view. (2) EN is effective for various network architectures and tasks. (3) It could replace any normalization layers in a deep network and still produce stable model training. Extensive experiments demonstrate the effectiveness of EN in a wide spectrum of tasks including image recognition, noisy label learning, and semantic segmentation. For example, by replacing BN in the ordinary ResNet50, improvement produced by EN is 300% more than that of SN on both ImageNet and the noisy WebVision dataset.
Tomographic Image Reconstruction using Training images
Aug 17, 2015



We describe and examine an algorithm for tomographic image reconstruction where prior knowledge about the solution is available in the form of training images. We first construct a nonnegative dictionary based on prototype elements from the training images; this problem is formulated as a regularized non-negative matrix factorization. Incorporating the dictionary as a prior in a convex reconstruction problem, we then find an approximate solution with a sparse representation in the dictionary. The dictionary is applied to non-overlapping patches of the image, which reduces the computational complexity compared to other algorithms. Computational experiments clarify the choice and interplay of the model parameters and the regularization parameters, and we show that in few-projection low-dose settings our algorithm is competitive with total variation regularization and tends to include more texture and more correct edges.
Captum: A unified and generic model interpretability library for PyTorch
Sep 16, 2020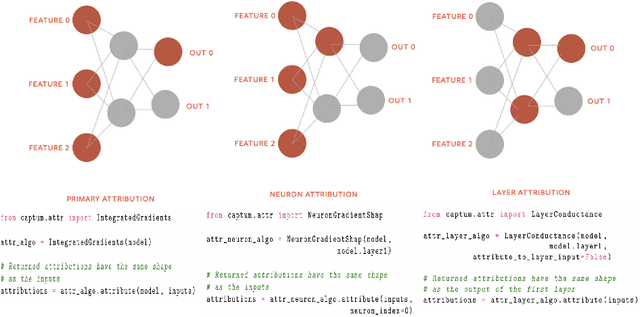

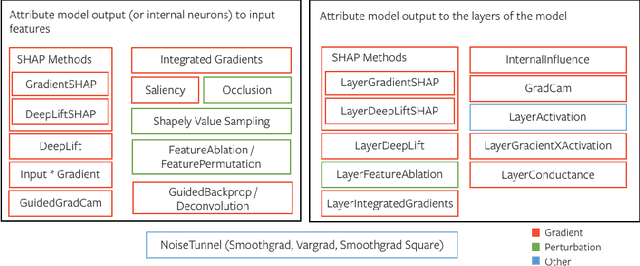
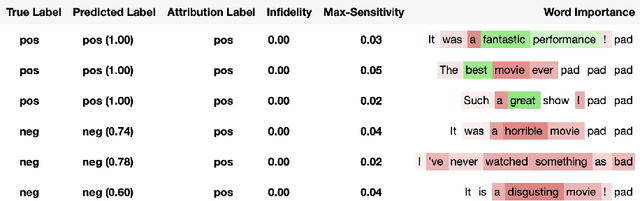
In this paper we introduce a novel, unified, open-source model interpretability library for PyTorch [12]. The library contains generic implementations of a number of gradient and perturbation-based attribution algorithms, also known as feature, neuron and layer importance algorithms, as well as a set of evaluation metrics for these algorithms. It can be used for both classification and non-classification models including graph-structured models built on Neural Networks (NN). In this paper we give a high-level overview of supported attribution algorithms and show how to perform memory-efficient and scalable computations. We emphasize that the three main characteristics of the library are multimodality, extensibility and ease of use. Multimodality supports different modality of inputs such as image, text, audio or video. Extensibility allows adding new algorithms and features. The library is also designed for easy understanding and use. Besides, we also introduce an interactive visualization tool called Captum Insights that is built on top of Captum library and allows sample-based model debugging and visualization using feature importance metrics.
Group-Representative Functional Network Estimation from Multi-Subject fMRI Data via MRF-based Image Segmentation
Aug 29, 2018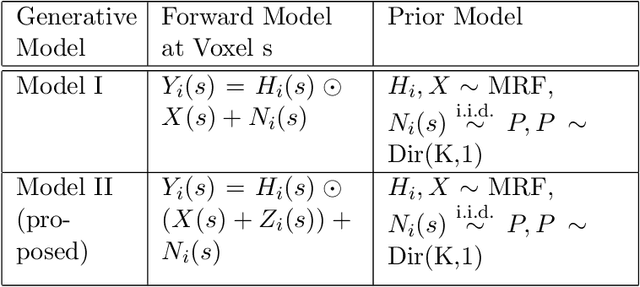
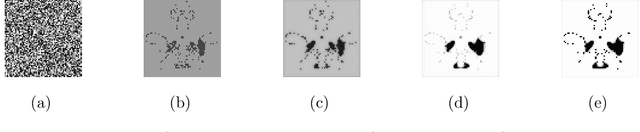

We propose a novel two-phase approach to functional network estimation of multi-subject functional Magnetic Resonance Imaging (fMRI) data, which applies model-based image segmentation to determine a group-representative connectivity map. In our approach, we first improve clustering-based Independent Component Analysis (ICA) to generate maps of components occurring consistently across subjects, and then estimate the group-representative map through MAP-MRF (Maximum a priori - Markov random field) labeling. For the latter, we provide a novel and efficient variational Bayes algorithm. We study the performance of the proposed method using synthesized data following a theoretical model, and demonstrate its viability in blind extraction of group-representative functional networks using simulated fMRI data. We anticipate the proposed method will be applied in identifying common neuronal characteristics in a population, and could be further extended to real-world clinical diagnosis.
Learning Attentive Pairwise Interaction for Fine-Grained Classification
Feb 24, 2020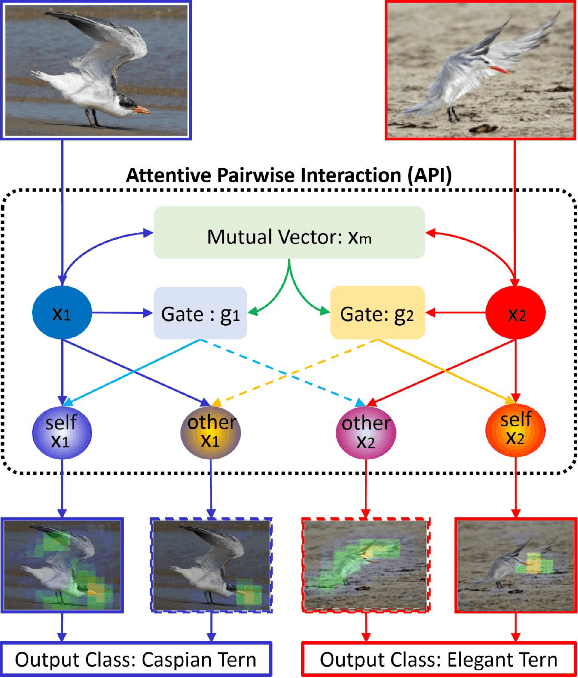

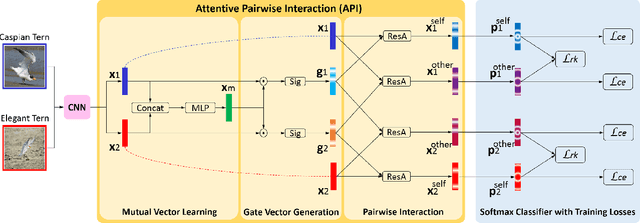

Fine-grained classification is a challenging problem, due to subtle differences among highly-confused categories. Most approaches address this difficulty by learning discriminative representation of individual input image. On the other hand, humans can effectively identify contrastive clues by comparing image pairs. Inspired by this fact, this paper proposes a simple but effective Attentive Pairwise Interaction Network (API-Net), which can progressively recognize a pair of fine-grained images by interaction. Specifically, API-Net first learns a mutual feature vector to capture semantic differences in the input pair. It then compares this mutual vector with individual vectors to generate gates for each input image. These distinct gate vectors inherit mutual context on semantic differences, which allow API-Net to attentively capture contrastive clues by pairwise interaction between two images. Additionally, we train API-Net in an end-to-end manner with a score ranking regularization, which can further generalize API-Net by taking feature priorities into account. We conduct extensive experiments on five popular benchmarks in fine-grained classification. API-Net outperforms the recent SOTA methods, i.e., CUB-200-2011 (90.0%), Aircraft(93.9%), Stanford Cars (95.3%), Stanford Dogs (90.3%), and NABirds (88.1%).
Collaborative Group Learning
Sep 16, 2020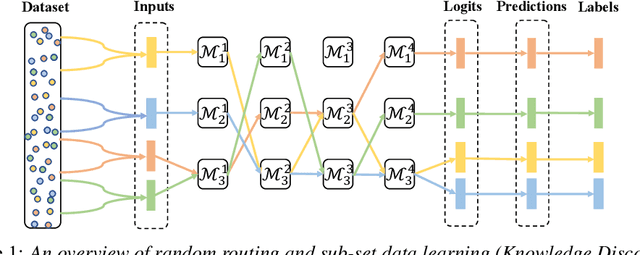


Collaborative learning has successfully applied knowledge transfer to guiding a pool of small student networks towards robust local minima. However, previous approaches typically struggle with drastically aggravated student homogenization and rapidly growing computational complexity when the number of students rises. In this paper, we propose Collaborative Group Learning, an efficient framework that aims to maximize student population without sacrificing generalization performance and computational efficiency. First, each student is established by randomly routing on a modular neural network, which is not only parameter-efficient but also facilitates flexible knowledge communication between students due to random levels of representation sharing and branching. Second, to resist homogenization and further reduce the computational cost, students first compose diverse feature sets by exploiting the inductive bias from sub-sets of training data, and then aggregate and distill supplementary knowledge by choosing a random sub-group of students at each time step. Empirical evaluations on both image and text tasks indicate that our method significantly outperforms various state-of-the-art collaborative approaches whilst enhancing computational efficiency.
Modified Alpha-Rooting Color Image Enhancement Method On The Two-Side 2-D Quaternion Discrete Fourier Transform And The 2-D Discrete Fourier Transform
Jul 15, 2017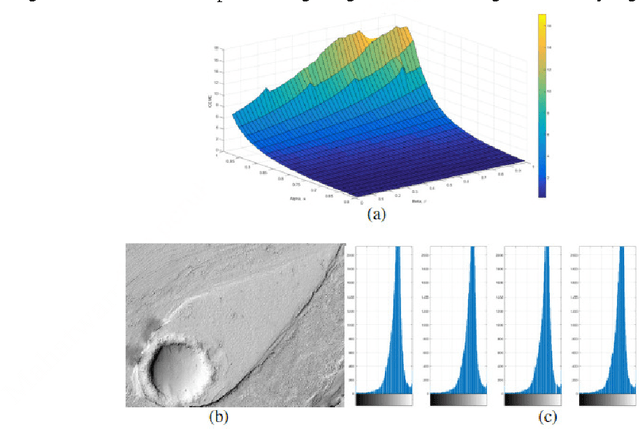


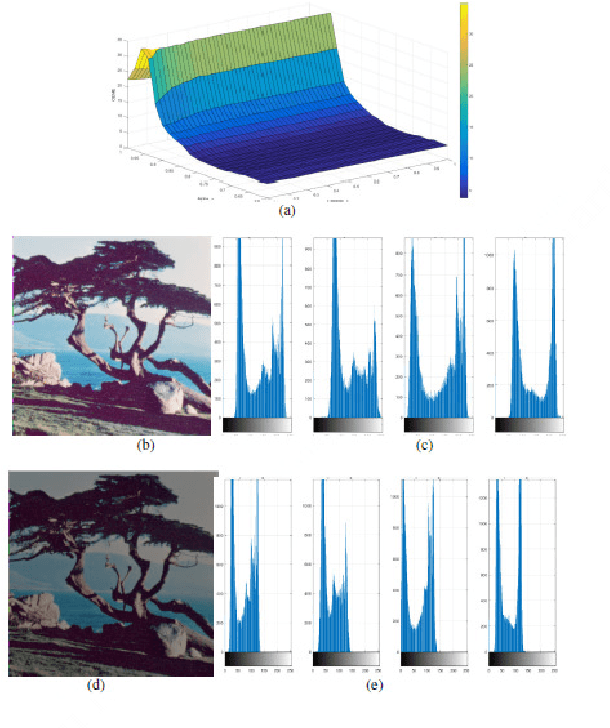
Color in an image is resolved into 3 or 4 color components and 2-Dimages of these components are stored in separate channels. Most of the color image enhancement algorithms are applied channel-by-channel on each image. But such a system of color image processing is not processing the original color. When a color image is represented as a quaternion image, processing is done in original colors. This paper proposes an implementation of the quaternion approach of enhancement algorithm for enhancing color images and is referred as the modified alpha-rooting by the two-dimensional quaternion discrete Fourier transform (2-D QDFT). Enhancement results of this proposed method are compared with the channel-by-channel image enhancement by the 2-D DFT. Enhancements in color images are quantitatively measured by the color enhancement measure estimation (CEME), which allows for selecting optimum parameters for processing by the genetic algorithm. Enhancement of color images by the quaternion based method allows for obtaining images which are closer to the genuine representation of the real original color.
* 16 pages, 53 figures (including sub-figures)
generating annotated high-fidelity images containing multiple coherent objects
Jun 22, 2020
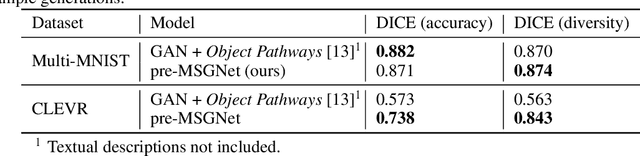
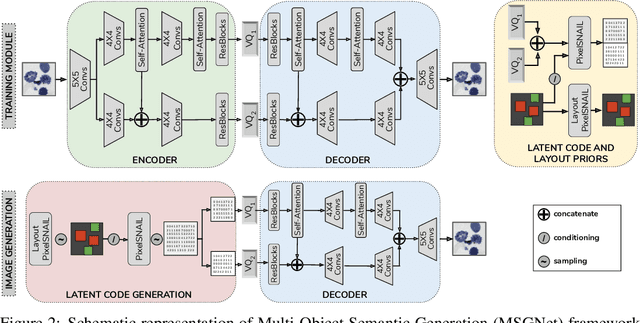
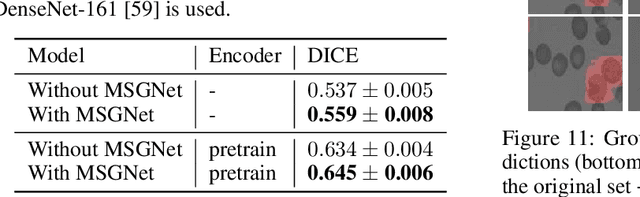
Recent developments related to generative models have made it possible to generate diverse high-fidelity images. In particular, layout-to-image generation models have gained significant attention due to their capability to generate realistic complex images containing distinct objects. These models are generally conditioned on either semantic layouts or textual descriptions. However, unlike natural images, providing auxiliary information can be extremely hard in domains such as biomedical imaging and remote sensing. In this work, we propose a multi-object generation framework that can synthesize images with multiple objects without explicitly requiring their contextual information during the generation process. Based on a vector-quantized variational autoencoder (VQ-VAE) backbone, our model learns to preserve spatial coherency within an image as well as semantic coherency between the objects and the background through two powerful autoregressive priors: PixelSNAIL and LayoutPixelSNAIL. While the PixelSNAIL learns the distribution of the latent encodings of the VQ-VAE, the LayoutPixelSNAIL is used to specifically learn the semantic distribution of the objects. An implicit advantage of our approach is that the generated samples are accompanied by object-level annotations. We demonstrate how coherency and fidelity are preserved with our method through experiments on the Multi-MNIST and CLEVR datasets; thereby outperforming state-of-the-art multi-object generative methods. The efficacy of our approach is demonstrated through application on medical imaging datasets, where we show that augmenting the training set with generated samples using our approach improves the performance of existing models.
Dueling Deep Q-Network for Unsupervised Inter-frame Eye Movement Correction in Optical Coherence Tomography Volumes
Jul 03, 2020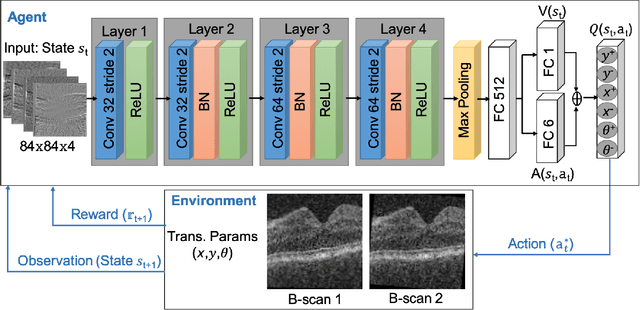
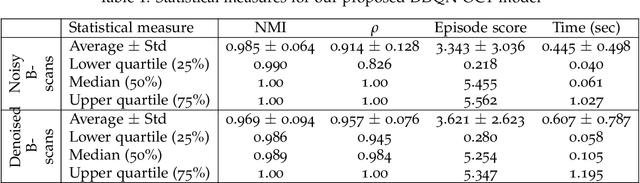
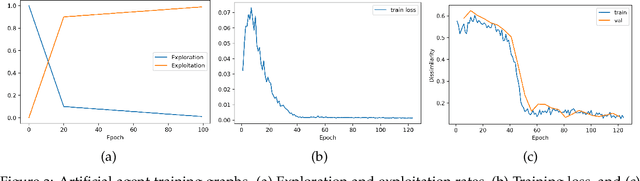
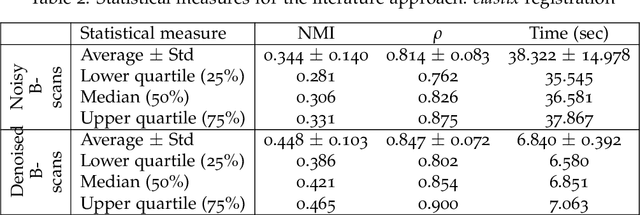
In optical coherence tomography (OCT) volumes of retina, the sequential acquisition of the individual slices makes this modality prone to motion artifacts, misalignments between adjacent slices being the most noticeable. Any distortion in OCT volumes can bias structural analysis and influence the outcome of longitudinal studies. On the other hand, presence of speckle noise that is characteristic of this imaging modality, leads to inaccuracies when traditional registration techniques are employed. Also, the lack of a well-defined ground truth makes supervised deep-learning techniques ill-posed to tackle the problem. In this paper, we tackle these issues by using deep reinforcement learning to correct inter-frame movements in an unsupervised manner. Specifically, we use dueling deep Q-network to train an artificial agent to find the optimal policy, i.e. a sequence of actions, that best improves the alignment by maximizing the sum of reward signals. Instead of relying on the ground-truth of transformation parameters to guide the rewarding system, for the first time, we use a combination of intensity based image similarity metrics. Further, to avoid the agent bias towards speckle noise, we ensure the agent can see retinal layers as part of the interacting environment. For quantitative evaluation, we simulate the eye movement artifacts by applying 2D rigid transformations on individual B-scans. The proposed model achieves an average of 0.985 and 0.914 for normalized mutual information and correlation coefficient, respectively. We also compare our model with elastix intensity based medical image registration approach, where significant improvement is achieved by our model for both noisy and denoised volumes.