 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CNN-based fast source device identification
Jan 31, 2020
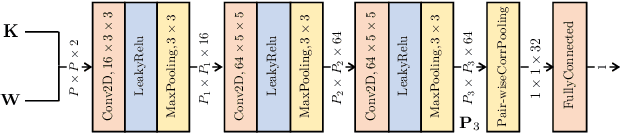
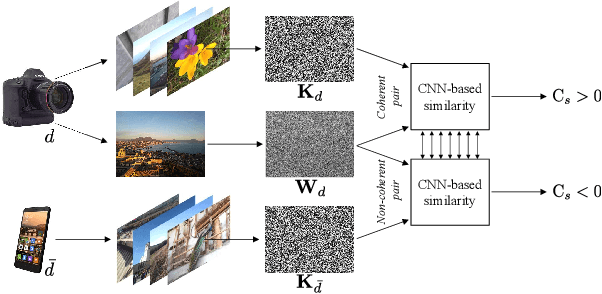
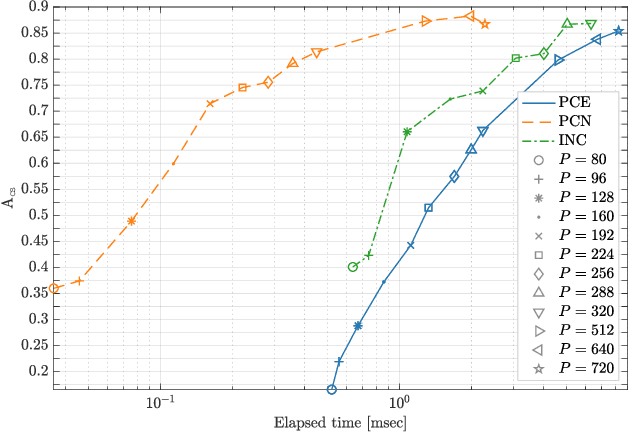
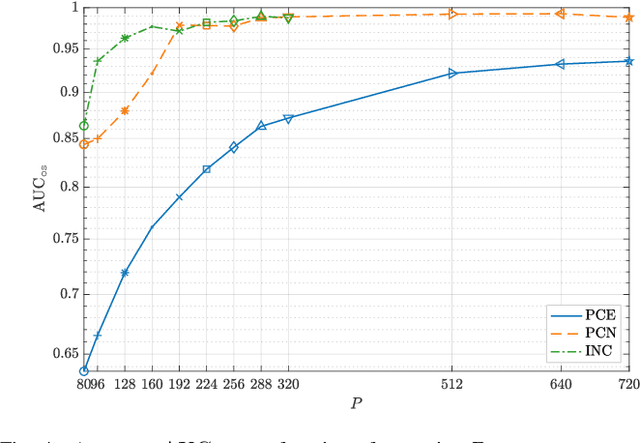
Source identification is an important topic in image forensics, since it allows to trace back the origin of an image. This represents a precious information to claim intellectual property but also to reveal the authors of illicit materials. In this paper we address the problem of device identification based on sensor noise and propose a fast and accurate solution using convolutional neural networks (CNNs). Specifically, we propose a 2-channel-based CNN that learns a way of comparing camera fingerprint and image noise at patch level. The proposed solution turns out to be much faster than the conventional approach and to ensure an increased accuracy. This makes the approach particularly suitable in scenarios where large databases of images are analyzed, like over social networks. In this vein, since images uploaded on social media usually undergo at least two compression stages, we include investigations on double JPEG compressed images, always reporting higher accuracy than standard approaches.
Robots of the Lost Arc: Learning to Dynamically Manipulate Fixed-Endpoint Ropes and Cables
Nov 10, 2020



High-speed arm motions can dynamically manipulate ropes and cables to vault over obstacles, knock objects from pedestals, and weave between obstacles. In this paper, we propose a self-supervised learning pipeline that enables a UR5 robot to perform these three tasks. The pipeline trains a deep convolutional neural network that takes as input an image of the scene with object and target. It computes a 3D apex point for the robot arm, which, together with a task-specific trajectory function, defines an arcing motion for a manipulator arm to dynamically manipulate the cable to perform a task with varying obstacle and target locations. The trajectory function computes high-speed minimum-jerk arcing motions that are constrained to remain within joint limits and to travel through the 3D apex point by repeatedly solving quadratic programs for shorter time horizons to find the shortest and fastest feasible motion. We experiment with the proposed pipeline on 5 physical cables with different thickness and mass and compare performance with two baselines in which a human chooses the apex point. Results suggest that the robot using the learned apex point can achieve success rates of 81.7% in vaulting, 65.0% in knocking, and 60.0% in weaving, while a baseline with a fixed apex across the three tasks achieves respective success rates of 51.7%, 36.7%, and 15.0%, and a baseline with human-specified task-specific apex points achieves 66.7%, 56.7%, and 15.0% success rate respectively. Code, data, and supplementary materials are available at https: //sites.google.com/berkeley.edu/dynrope/home
Tree-based Visualization and Optimization for Image Collection
Jul 17, 2015
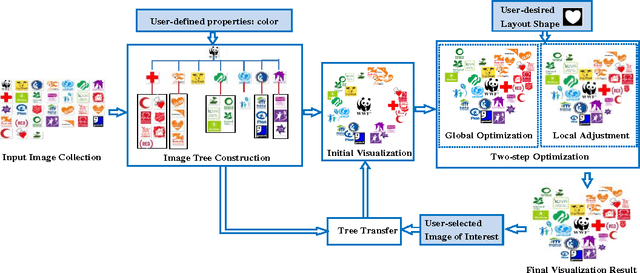

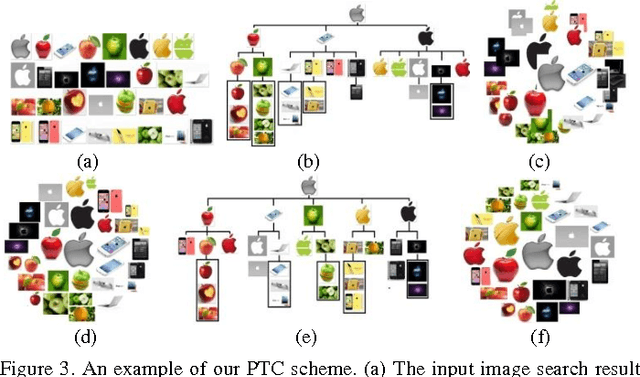
The visualization of an image collection is the process of displaying a collection of images on a screen under some specific layout requirements. This paper focuses on an important problem that is not well addressed by the previous methods: visualizing image collections into arbitrary layout shapes while arranging images according to user-defined semantic or visual correlations (e.g., color or object category). To this end, we first propose a property-based tree construction scheme to organize images of a collection into a tree structure according to user-defined properties. In this way, images can be adaptively placed with the desired semantic or visual correlations in the final visualization layout. Then, we design a two-step visualization optimization scheme to further optimize image layouts. As a result, multiple layout effects including layout shape and image overlap ratio can be effectively controlled to guarantee a satisfactory visualization. Finally, we also propose a tree-transfer scheme such that visualization layouts can be adaptively changed when users select different "images of interest". We demonstrate the effectiveness of our proposed approach through the comparisons with state-of-the-art visualization techniques.
Convexity Shape Constraints for Image Segmentation
Sep 07, 2015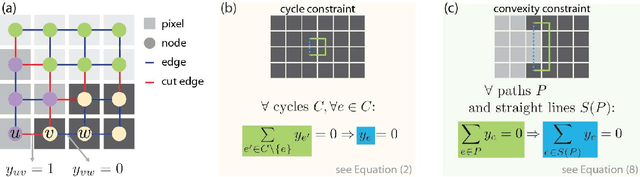

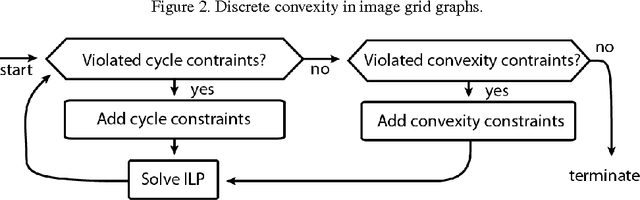

Segmenting an image into multiple components is a central task in computer vision. In many practical scenarios, prior knowledge about plausible components is available. Incorporating such prior knowledge into models and algorithms for image segmentation is highly desirable, yet can be non-trivial. In this work, we introduce a new approach that allows, for the first time, to constrain some or all components of a segmentation to have convex shapes. Specifically, we extend the Minimum Cost Multicut Problem by a class of constraints that enforce convexity. To solve instances of this APX-hard integer linear program to optimality, we separate the proposed constraints in the branch-and-cut loop of a state-of-the-art ILP solver. Results on natural and biological images demonstrate the effectiveness of the approach as well as its advantage over the state-of-the-art heuristic.
Bimanual Regrasping for Suture Needles using Reinforcement Learning for Rapid Motion Planning
Nov 09, 2020
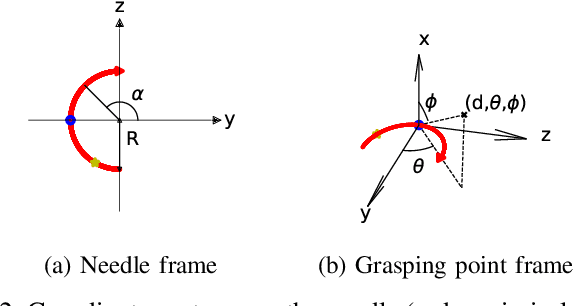
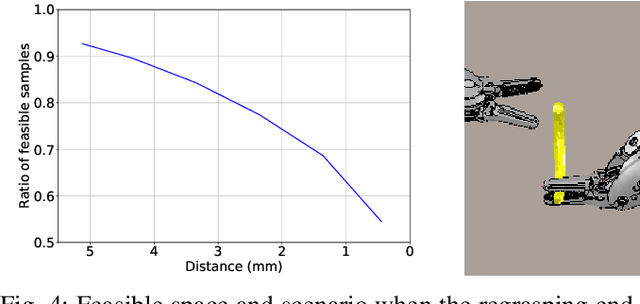
Regrasping a suture needle is an important process in suturing, and previous study has shown that it takes on average 7.4s before the needle is thrown again. To bring efficiency into suturing, prior work either designs a task-specific mechanism or guides the gripper toward some specific pick-up point for proper grasping of a needle. Yet, these methods are usually not deployable when the working space is changed. These prior efforts highlight the need for more efficient regrasping and more generalizability of a proposed method. Therefore, in this work, we present rapid trajectory generation for bimanual needle regrasping via reinforcement learning (RL). Demonstrations from a sampling-based motion planning algorithm is incorporated to speed up the learning. In addition, we propose the ego-centric state and action spaces for this bimanual planning problem, where the reference frames are on the end-effectors instead of some fixed frame. Thus, the learned policy can be directly applied to any robot configuration and even to different robot arms. Our experiments in simulation show that the success rate of a single pass is 97%, and the planning time is 0.0212s on average, which outperforms other widely used motion planning algorithms. For the real-world experiments, the success rate is 73.3% if the needle pose is reconstructed from an RGB image, with a planning time of 0.0846s and a run time of 5.1454s. If the needle pose is known beforehand, the success rate becomes 90.5%, with a planning time of 0.0807s and a run time of 2.8801s.
Memory-Efficient Design Strategy for a Parallel Embedded Integral Image Computation Engine
Oct 17, 2015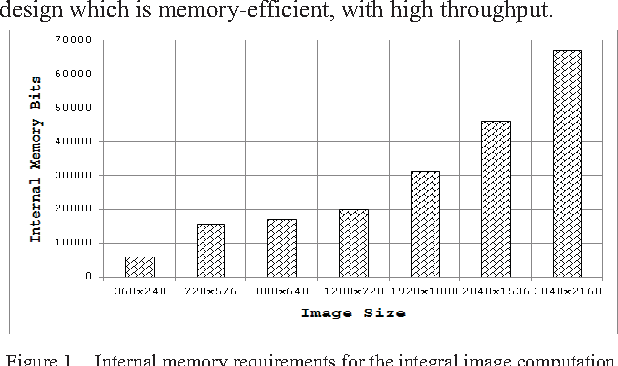
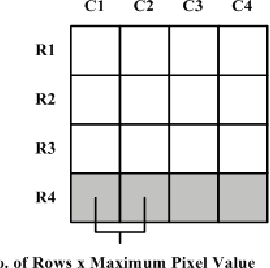
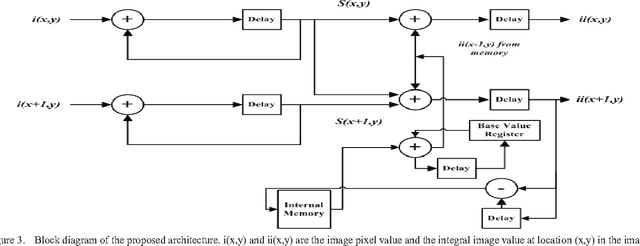
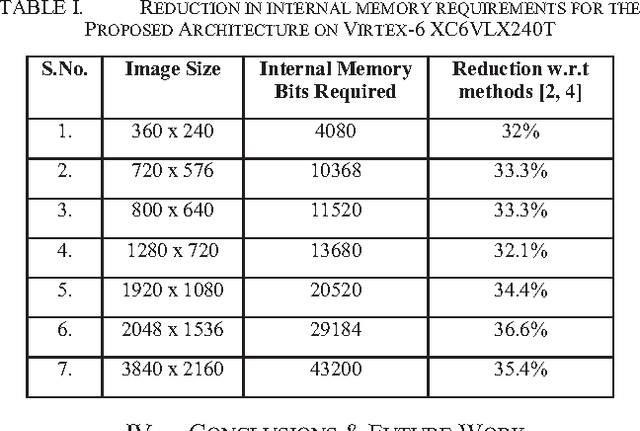
In embedded vision systems, parallel computation of the integral image presents several design challenges in terms of hardware resources, speed and power consumption. Although recursive equations significantly reduce the number of operations for computing the integral image, the required internal memory becomes prohibitively large for an embedded integral image computation engine for increasing image sizes. With the objective of achieving high-throughput with minimum hardware resources, this paper proposes a memory-efficient design strategy for a parallel embedded integral image computation engine. Results show that the design achieves nearly 35% reduction in memory for common HD video.
Google Landmarks Dataset v2 -- A Large-Scale Benchmark for Instance-Level Recognition and Retrieval
Apr 03, 2020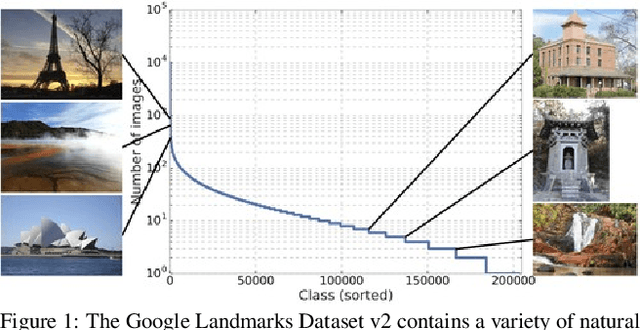
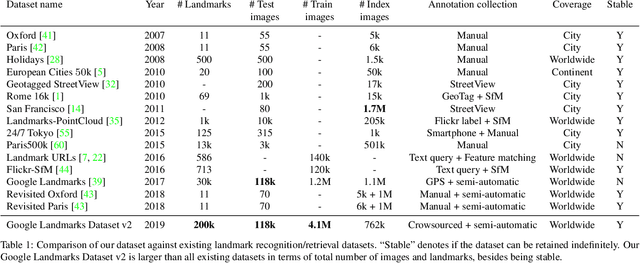
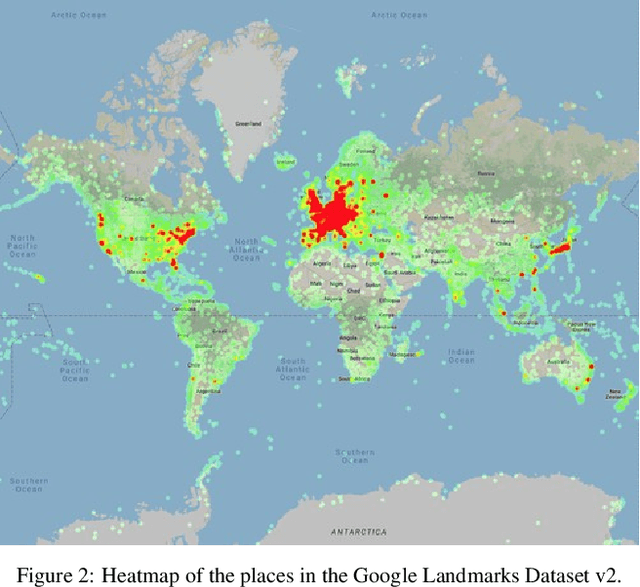

While image retrieval and instance recognition techniques are progressing rapidly, there is a need for challenging datasets to accurately measure their performance -- while posing novel challenges that are relevant for practical applications. We introduce the Google Landmarks Dataset v2 (GLDv2), a new benchmark for large-scale, fine-grained instance recognition and image retrieval in the domain of human-made and natural landmarks. GLDv2 is the largest such dataset to date by a large margin, including over 5M images and 200k distinct instance labels. Its test set consists of 118k images with ground truth annotations for both the retrieval and recognition tasks. The ground truth construction involved over 800 hours of human annotator work. Our new dataset has several challenging properties inspired by real world applications that previous datasets did not consider: An extremely long-tailed class distribution, a large fraction of out-of-domain test photos and large intra-class variability. The dataset is sourced from Wikimedia Commons, the world's largest crowdsourced collection of landmark photos. We provide baseline results for both recognition and retrieval tasks based on state-of-the-art methods as well as competitive results from a public challenge. We further demonstrate the suitability of the dataset for transfer learning by showing that image embeddings trained on it achieve competitive retrieval performance on independent datasets. The dataset images, ground-truth and metric scoring code are available at https://github.com/cvdfoundation/google-landmark.
Pseudo-healthy synthesis with pathology disentanglement and adversarial learning
May 05, 2020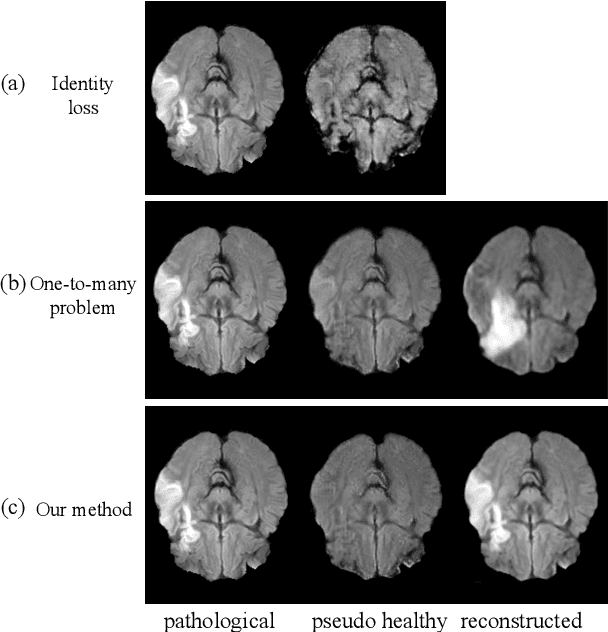
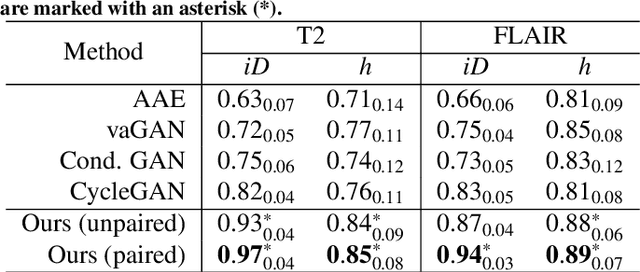
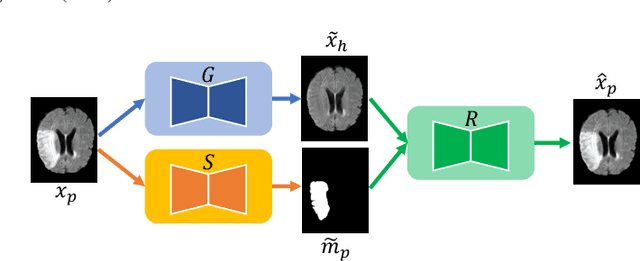
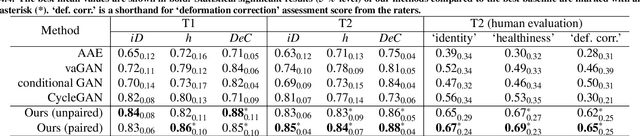
Pseudo-healthy synthesis is the task of creating a subject-specific `healthy' image from a pathological one. Such images can be helpful in tasks such as anomaly detection and understanding changes induced by pathology and disease. In this paper, we present a model that is encouraged to disentangle the information of pathology from what seems to be healthy. We disentangle what appears to be healthy and where disease is as a segmentation map, which are then recombined by a network to reconstruct the input disease image. We train our models adversarially using either paired or unpaired settings, where we pair disease images and maps when available. We quantitatively and subjectively, with a human study, evaluate the quality of pseudo-healthy images using several criteria. We show in a series of experiments, performed on ISLES, BraTS and Cam-CAN datasets, that our method is better than several baselines and methods from the literature. We also show that due to better training processes we could recover deformations, on surrounding tissue, caused by disease. Our implementation is publicly available at \url{https://tobeprovided.upon.acceptance}
Visual Camera Re-Localization from RGB and RGB-D Images Using DSAC
Feb 27, 2020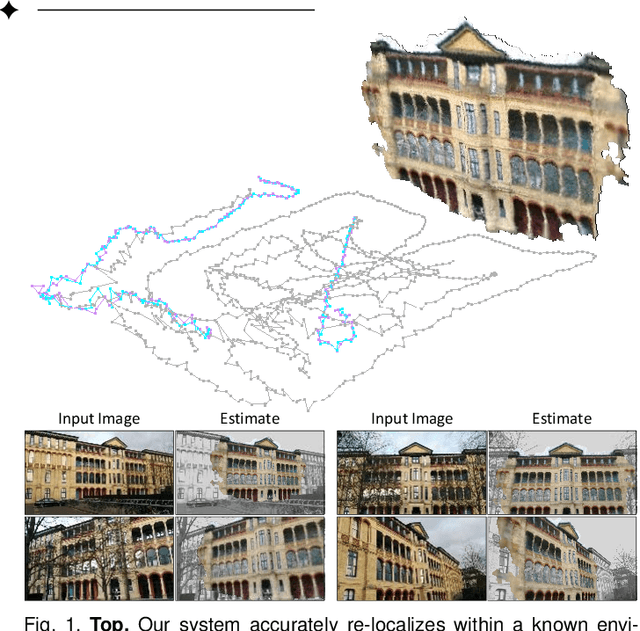

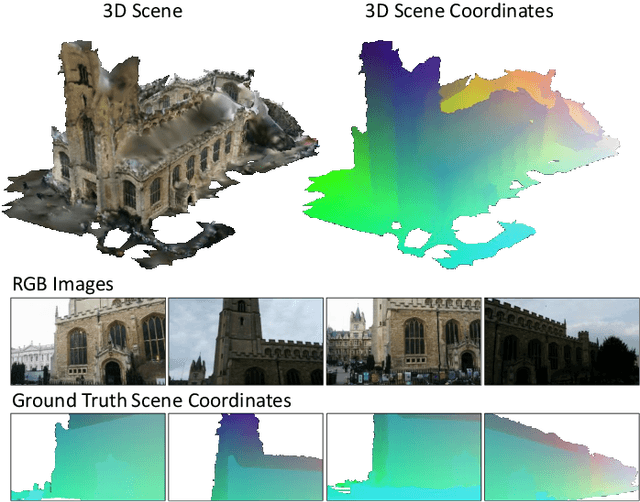
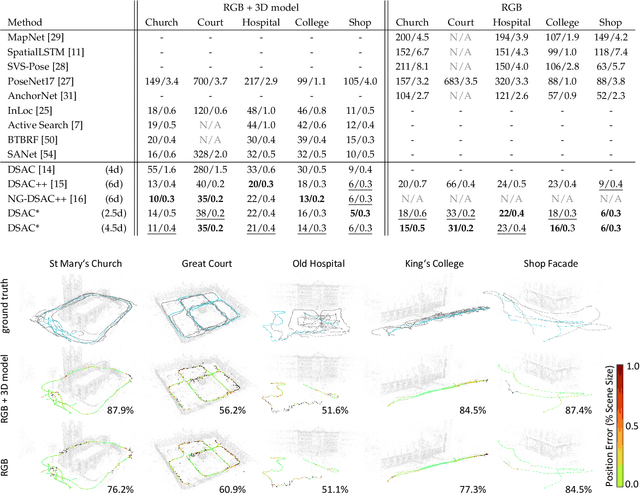
We describe a learning-based system that estimates the camera position and orientation from a single input image relative to a known environment. The system is flexible w.r.t. the amount of information available at test and at training time, catering to different applications. Input images can be RGB-D or RGB, and a 3D model of the environment can be utilized for training but is not necessary. In the minimal case, our system requires only RGB images and ground truth poses at training time, and it requires only a single RGB image at test time. The framework consists of a deep neural network and fully differentiable pose optimization. The neural network predicts so called scene coordinates, i.e. dense correspondences between the input image and 3D scene space of the environment. The pose optimization implements robust fitting of pose parameters using differentiable RANSAC (DSAC) to facilitate end-to-end training. The system, an extension of DSAC++ and referred to as DSAC*, achieves state-of-the-art accuracy an various public datasets for RGB-based re-localization, and competitive accuracy for RGB-D based re-localization.
Blacklight: Defending Black-Box Adversarial Attacks on Deep Neural Networks
Jun 24, 2020

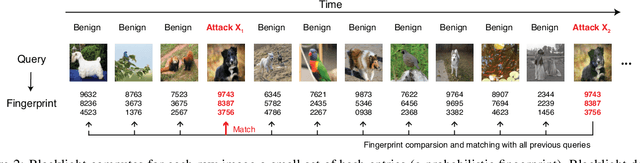

The vulnerability of deep neural networks (DNNs) to adversarial examples is well documented. Under the strong white-box threat model, where attackers have full access to DNN internals, recent work has produced continual advancements in defenses, often followed by more powerful attacks that break them. Meanwhile, research on the more realistic black-box threat model has focused almost entirely on reducing the query-cost of attacks, making them increasingly practical for ML models already deployed today. This paper proposes and evaluates Blacklight, a new defense against black-box adversarial attacks. Blacklight targets a key property of black-box attacks: to compute adversarial examples, they produce sequences of highly similar images while trying to minimize the distance from some initial benign input. To detect an attack, Blacklight computes for each query image a compact set of one-way hash values that form a probabilistic fingerprint. Variants of an image produce nearly identical fingerprints, and fingerprint generation is robust against manipulation. We evaluate Blacklight on 5 state-of-the-art black-box attacks, across a variety of models and classification tasks. While the most efficient attacks take thousands or tens of thousands of queries to complete, Blacklight identifies them all, often after only a handful of queries. Blacklight is also robust against several powerful countermeasures, including an optimal black-box attack that approximates white-box attacks in efficiency. Finally, Blacklight significantly outperforms the only known alternative in both detection coverage of attack queries and resistance against persistent attackers.