 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fast Class-wise Updating for Online Hashing
Dec 01, 2020
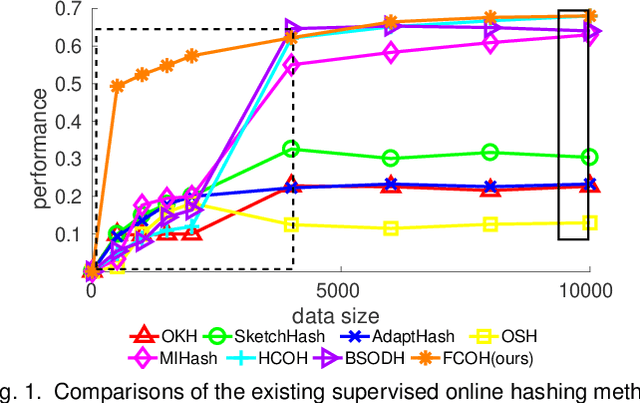
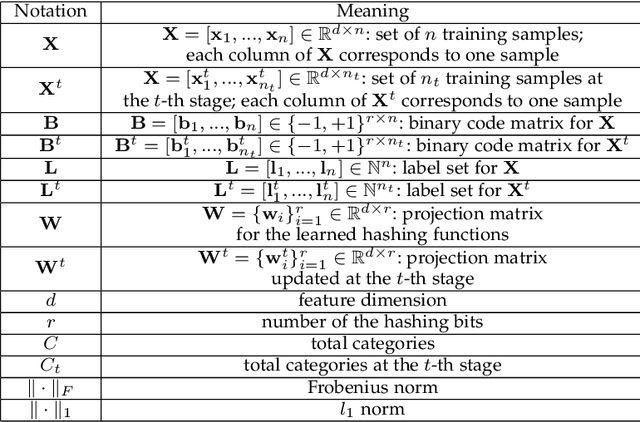
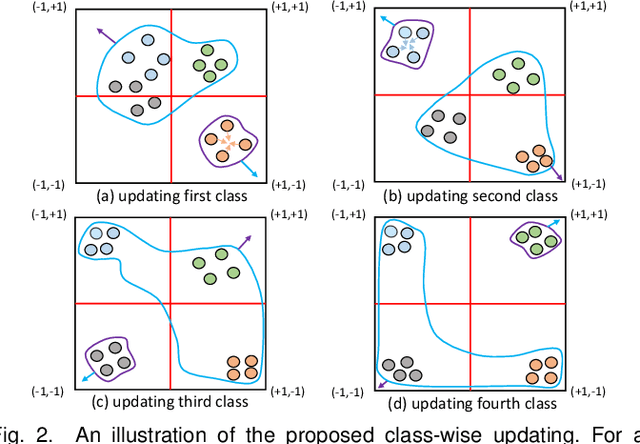
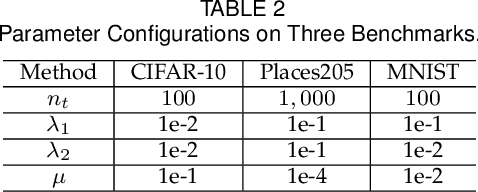
Online image hashing has received increasing research attention recently, which processes large-scale data in a streaming fashion to update the hash functions on-the-fly. To this end, most existing works exploit this problem under a supervised setting, i.e., using class labels to boost the hashing performance, which suffers from the defects in both adaptivity and efficiency: First, large amounts of training batches are required to learn up-to-date hash functions, which leads to poor online adaptivity. Second, the training is time-consuming, which contradicts with the core need of online learning. In this paper, a novel supervised online hashing scheme, termed Fast Class-wise Updating for Online Hashing (FCOH), is proposed to address the above two challenges by introducing a novel and efficient inner product operation. To achieve fast online adaptivity, a class-wise updating method is developed to decompose the binary code learning and alternatively renew the hash functions in a class-wise fashion, which well addresses the burden on large amounts of training batches. Quantitatively, such a decomposition further leads to at least 75% storage saving. To further achieve online efficiency, we propose a semi-relaxation optimization, which accelerates the online training by treating different binary constraints independently. Without additional constraints and variables, the time complexity is significantly reduced. Such a scheme is also quantitatively shown to well preserve past information during updating hashing functions. We have quantitatively demonstrated that the collective effort of class-wise updating and semi-relaxation optimization provides a superior performance comparing to various state-of-the-art methods, which is verified through extensive experiments on three widely-used datasets.
Automatically Designing CNN Architectures Using Genetic Algorithm for Image Classification
Aug 11, 2018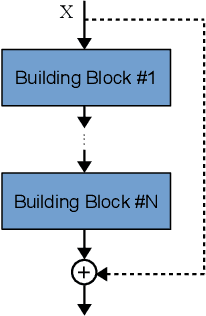
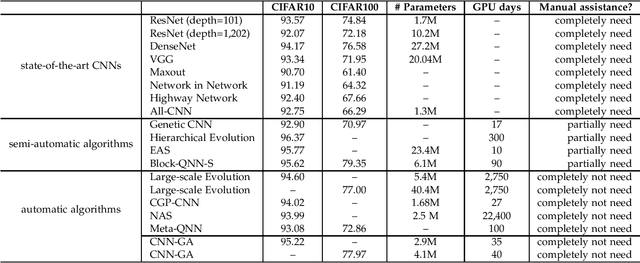

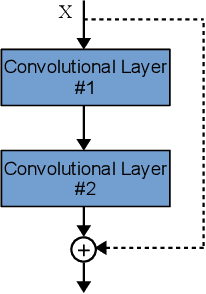
Convolutional Neural Networks (CNNs) have gained a remarkable success on many real-world problems in recent years. However, the performance of CNNs is highly relied on their architectures. For some state-of-the-art CNNs, their architectures are hand-crafted with expertise in both CNNs and the investigated problems. To this end, it is difficult for researchers, who have no extended expertise in CNNs, to explore CNNs for their own problems of interest. In this paper, we propose an automatic architecture design method for CNNs by using genetic algorithms, which is capable of discovering a promising architecture of a CNN on handling image classification tasks. The proposed algorithm does not need any pre-processing before it works, nor any post-processing on the discovered CNN, which means it is completely automatic. The proposed algorithm is validated on widely used benchmark datasets, by comparing to the state-of-the-art peer competitors covering eight manually designed CNNs, four semi-automatically designed CNNs and additional four automatically designed CNNs. The experimental results indicate that the proposed algorithm achieves the best classification accuracy consistently among manually and automatically designed CNNs. Furthermore, the proposed algorithm also shows the competitive classification accuracy to the semi-automatic peer competitors, while reducing 10 times of the parameters. In addition, on the average the proposed algorithm takes only one percentage of computational resource compared to that of all the other architecture discovering algorithms.
Switchable Deep Beamformer
Sep 04, 2020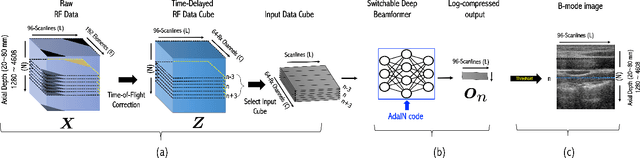
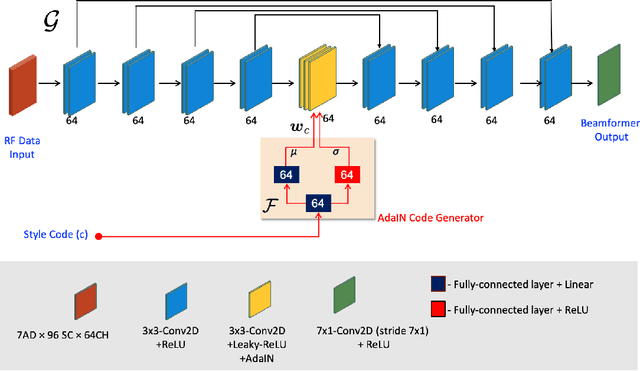
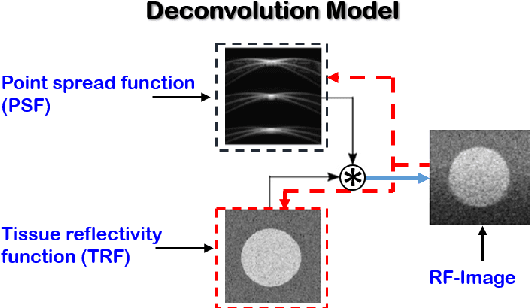

Recent proposals of deep beamformers using deep neural networks have attracted significant attention as computational efficient alternatives to adaptive and compressive beamformers. Moreover, deep beamformers are versatile in that image post-processing algorithms can be combined with the beamforming. Unfortunately, in the current technology, a separate beamformer should be trained and stored for each application, demanding significant scanner resources. To address this problem, here we propose a {\em switchable} deep beamformer that can produce various types of output such as DAS, speckle removal, deconvolution, etc., using a single network with a simple switch. In particular, the switch is implemented through Adaptive Instance Normalization (AdaIN) layers, so that various output can be generated by merely changing the AdaIN code. Experimental results using B-mode focused ultrasound confirm the flexibility and efficacy of the proposed methods for various applications.
Graph-based Multi-view Binary Learning for Image Clustering
Dec 11, 2019
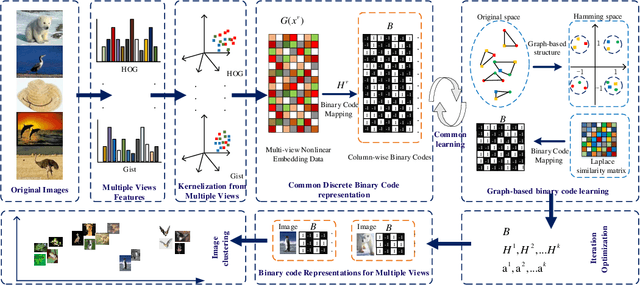


Hashing techniques, also known as binary code learning, have recently gained increasing attention in large-scale data analysis and storage. Generally, most existing hash clustering methods are single-view ones, which lack complete structure or complementary information from multiple views. For cluster tasks, abundant prior researches mainly focus on learning discrete hash code while few works take original data structure into consideration. To address these problems, we propose a novel binary code algorithm for clustering, which adopts graph embedding to preserve the original data structure, called (Graph-based Multi-view Binary Learning) GMBL in this paper. GMBL mainly focuses on encoding the information of multiple views into a compact binary code, which explores complementary information from multiple views. In particular, in order to maintain the graph-based structure of the original data, we adopt a Laplacian matrix to preserve the local linear relationship of the data and map it to the Hamming space. Considering different views have distinctive contributions to the final clustering results, GMBL adopts a strategy of automatically assign weights for each view to better guide the clustering. Finally, An alternating iterative optimization method is adopted to optimize discrete binary codes directly instead of relaxing the binary constraint in two steps. Experiments on five public datasets demonstrate the superiority of our proposed method compared with previous approaches in terms of clustering performance.
Breaking Moravec's Paradox: Visual-Based Distribution in Smart Fashion Retail
Jul 10, 2020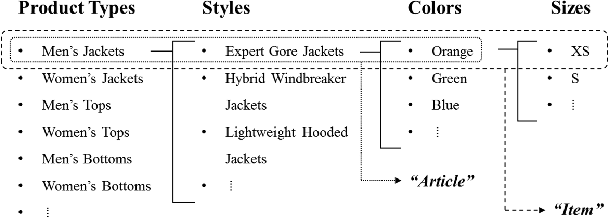
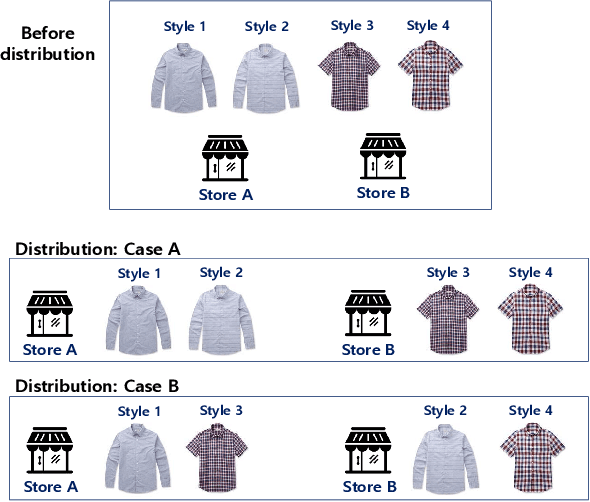
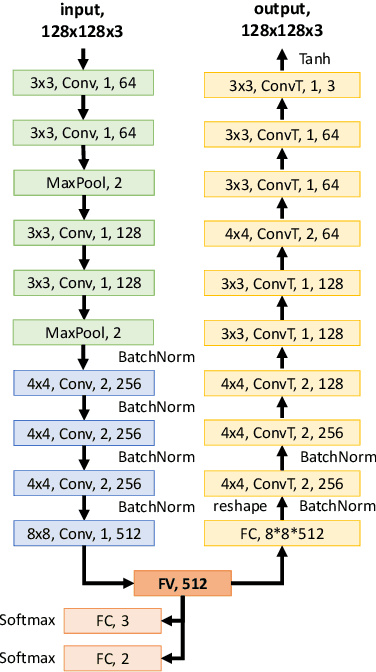

In this paper, we report an industry-academia collaborative study on the distribution method of fashion products using an artificial intelligence (AI) technique combined with an optimization method. To meet the current fashion trend of short product lifetimes and an increasing variety of styles, the company produces limited volumes of a large variety of styles. However, due to the limited volume of each style, some styles may not be distributed to some off-line stores. As a result, this high-variety, low-volume strategy presents another challenge to distribution managers. We collaborated with KOLON F/C, one of the largest fashion business units in South Korea, to develop models and an algorithm to optimally distribute the products to the stores based on the visual images of the products. The team developed a deep learning model that effectively represents the styles of clothes based on their visual image. Moreover, the team created an optimization model that effectively determines the product mix for each store based on the image representation of clothes. In the past, computers were only considered to be useful for conducting logical calculations, and visual perception and cognition were considered to be difficult computational tasks. The proposed approach is significant in that it uses both AI (perception and cognition) and mathematical optimization (logical calculation) to address a practical supply chain problem, which is why the study was called "Breaking Moravec's Paradox."
MGD-GAN: Text-to-Pedestrian generation through Multi-Grained Discrimination
Oct 02, 2020

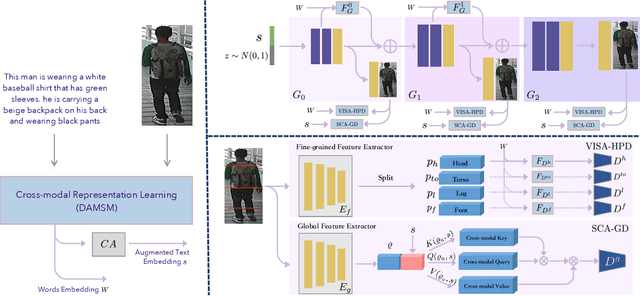

In this paper, we investigate the problem of text-to-pedestrian synthesis, which has many potential applications in art, design, and video surveillance. Existing methods for text-to-bird/flower synthesis are still far from solving this fine-grained image generation problem, due to the complex structure and heterogeneous appearance that the pedestrians naturally take on. To this end, we propose the Multi-Grained Discrimination enhanced Generative Adversarial Network, that capitalizes a human-part-based Discriminator (HPD) and a self-cross-attended (SCA) global Discriminator in order to capture the coherence of the complex body structure. A fined-grained word-level attention mechanism is employed in the HPD module to enforce diversified appearance and vivid details. In addition, two pedestrian generation metrics, named Pose Score and Pose Variance, are devised to evaluate the generation quality and diversity, respectively. We conduct extensive experiments and ablation studies on the caption-annotated pedestrian dataset, CUHK Person Description Dataset. The substantial improvement over the various metrics demonstrates the efficacy of MGD-GAN on the text-to-pedestrian synthesis scenario.
Learning Propagation Rules for Attribution Map Generation
Oct 14, 2020
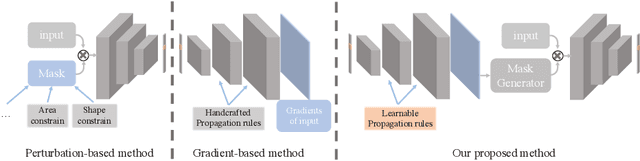
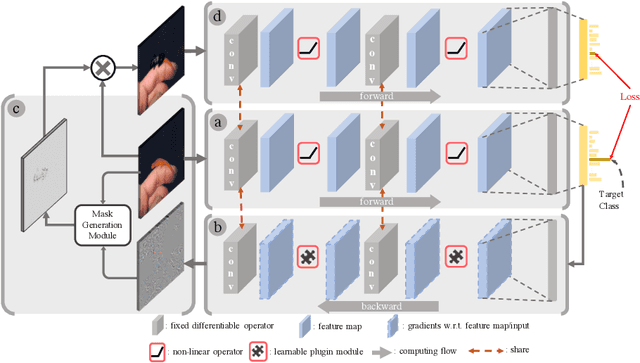
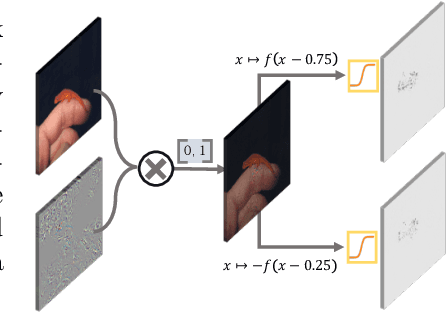
Prior gradient-based attribution-map methods rely on handcrafted propagation rules for the non-linear/activation layers during the backward pass, so as to produce gradients of the input and then the attribution map. Despite the promising results achieved, such methods are sensitive to the non-informative high-frequency components and lack adaptability for various models and samples. In this paper, we propose a dedicated method to generate attribution maps that allow us to learn the propagation rules automatically, overcoming the flaws of the handcrafted ones. Specifically, we introduce a learnable plugin module, which enables adaptive propagation rules for each pixel, to the non-linear layers during the backward pass for mask generating. The masked input image is then fed into the model again to obtain new output that can be used as a guidance when combined with the original one. The introduced learnable module can be trained under any auto-grad framework with higher-order differential support. As demonstrated on five datasets and six network architectures, the proposed method yields state-of-the-art results and gives cleaner and more visually plausible attribution maps.
Improving the Reconstruction of Disentangled Representation Learners via Multi-Stage Modelling
Oct 25, 2020

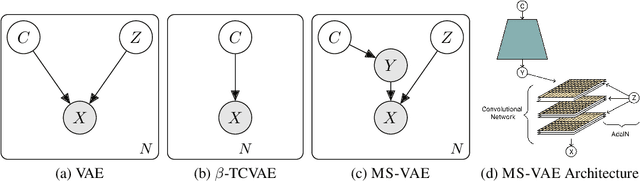

Current autoencoder-based disentangled representation learning methods achieve disentanglement by penalizing the (aggregate) posterior to encourage statistical independence of the latent factors. This approach introduces a trade-off between disentangled representation learning and reconstruction quality since the model does not have enough capacity to learn correlated latent variables that capture detail information present in most image data. To overcome this trade-off, we present a novel multi-stage modelling approach where the disentangled factors are first learned using a preexisting disentangled representation learning method (such as $\beta$-TCVAE); then, the low-quality reconstruction is improved with another deep generative model that is trained to model the missing correlated latent variables, adding detail information while maintaining conditioning on the previously learned disentangled factors. Taken together, our multi-stage modelling approach results in a single, coherent probabilistic model that is theoretically justified by the principal of D-separation and can be realized with a variety of model classes including likelihood-based models such as variational autoencoders, implicit models such as generative adversarial networks, and tractable models like normalizing flows or mixtures of Gaussians. We demonstrate that our multi-stage model has much higher reconstruction quality than current state-of-the-art methods with equivalent disentanglement performance across multiple standard benchmarks.
Learning Deep Features in Instrumental Variable Regression
Oct 14, 2020
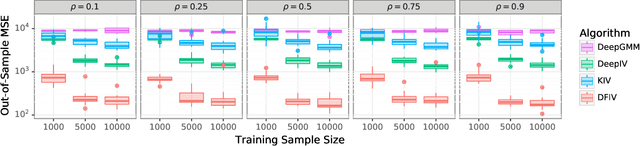

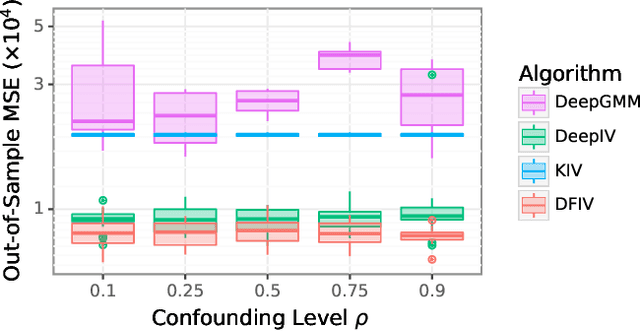
Instrumental variable (IV) regression is a standard strategy for learning causal relationships between confounded treatment and outcome variables by utilizing an instrumental variable, which is conditionally independent of the outcome given the treatment. In classical IV regression, learning proceeds in two stages: stage 1 performs linear regression from the instrument to the treatment; and stage 2 performs linear regression from the treatment to the outcome, conditioned on the instrument. We propose a novel method, {\it deep feature instrumental variable regression (DFIV)}, to address the case where relations between instruments, treatments, and outcomes may be nonlinear. In this case, deep neural nets are trained to define informative nonlinear features on the instruments and treatments. We propose an alternating training regime for these features to ensure good end-to-end performance when composing stages 1 and 2, thus obtaining highly flexible feature maps in a computationally efficient manner. DFIV outperforms recent state-of-the-art methods on challenging IV benchmarks, including settings involving high dimensional image data. DFIV also exhibits competitive performance in off-policy policy evaluation for reinforcement learning, which can be understood as an IV regression task.
Combining PRNU and noiseprint for robust and efficient device source identification
Jan 17, 2020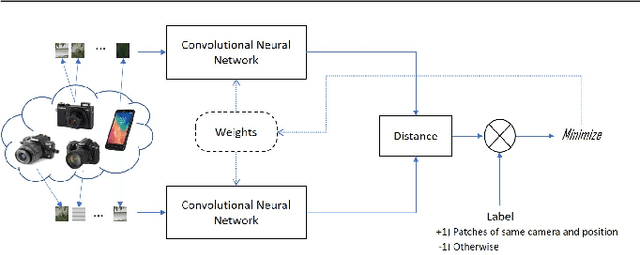
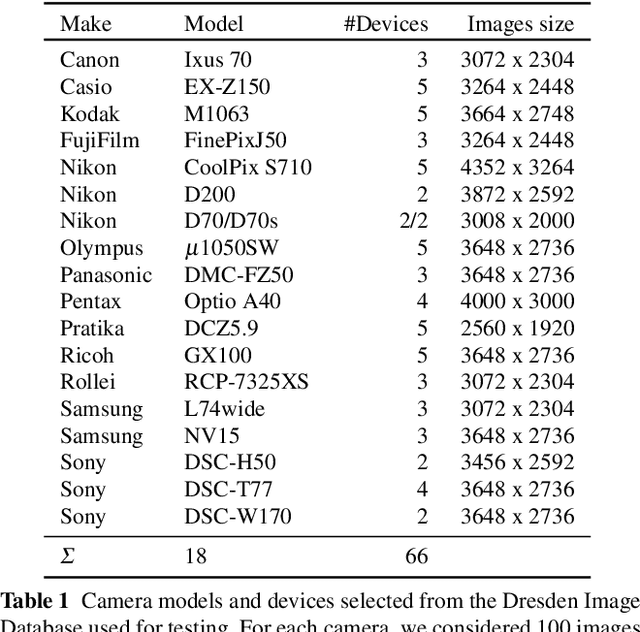

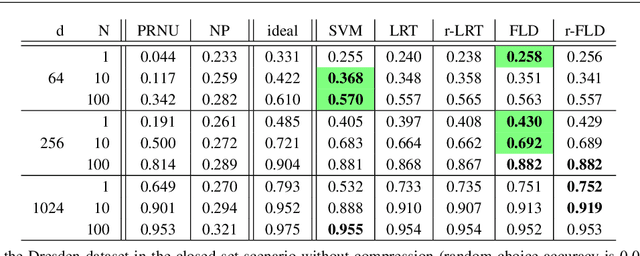
PRNU-based image processing is a key asset in digital multimedia forensics. It allows for reliable device identification and effective detection and localization of image forgeries, in very general conditions. However, performance impairs significantly in challenging conditions involving low quality and quantity of data. These include working on compressed and cropped images, or estimating the camera PRNU pattern based on only a few images. To boost the performance of PRNU-based analyses in such conditions we propose to leverage the image noiseprint, a recently proposed camera-model fingerprint that has proved effective for several forensic tasks. Numerical experiments on datasets widely used for source identification prove that the proposed method ensures a significant performance improvement in a wide range of challenging situations.