 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Comparison of Optimization Algorithms for Deep Learning
Jul 28, 2020
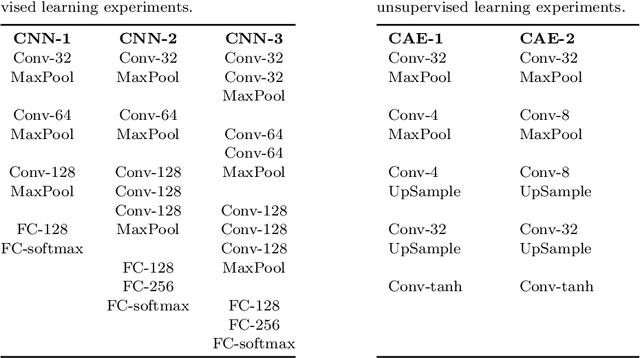
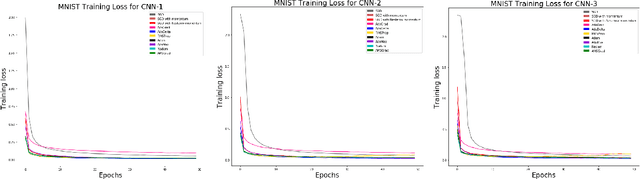
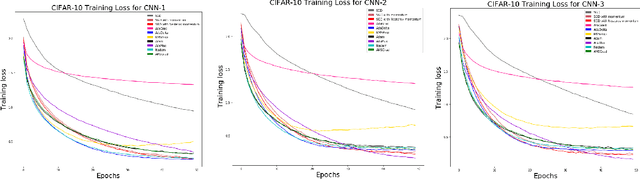
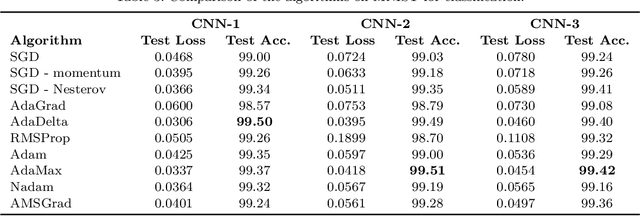
In recent years, we have witnessed the rise of deep learning. Deep neural networks have proved their success in many areas. However, the optimization of these networks has become more difficult as neural networks going deeper and datasets becoming bigger. Therefore, more advanced optimization algorithms have been proposed over the past years. In this study, widely used optimization algorithms for deep learning are examined in detail. To this end, these algorithms called adaptive gradient methods are implemented for both supervised and unsupervised tasks. The behaviour of the algorithms during training and results on four image datasets, namely, MNIST, CIFAR-10, Kaggle Flowers and Labeled Faces in the Wild are compared by pointing out their differences against basic optimization algorithms.
CPOT: Channel Pruning via Optimal Transport
May 21, 2020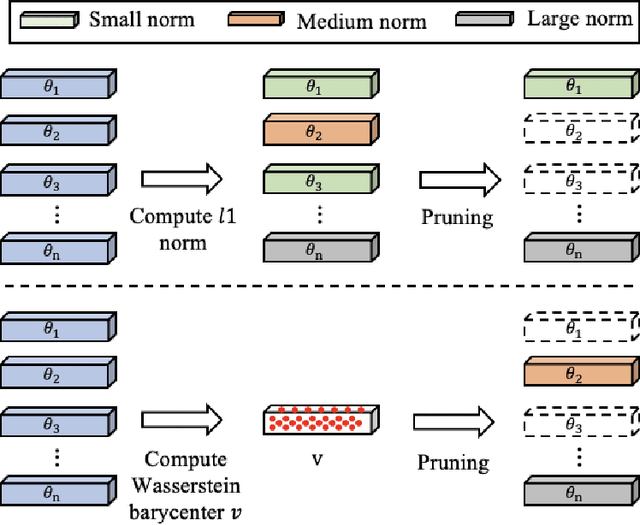

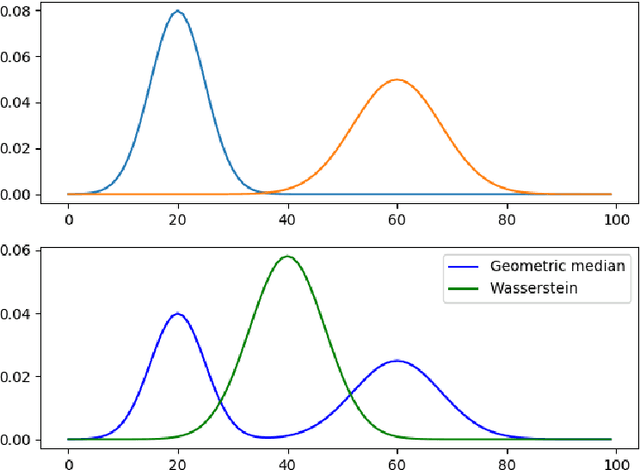
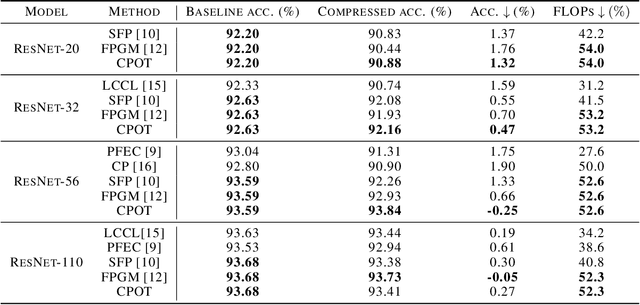
Recent advances in deep neural networks (DNNs) lead to tremendously growing network parameters, making the deployments of DNNs on platforms with limited resources extremely difficult. Therefore, various pruning methods have been developed to compress the deep network architectures and accelerate the inference process. Most of the existing channel pruning methods discard the less important filters according to well-designed filter ranking criteria. However, due to the limited interpretability of deep learning models, designing an appropriate ranking criterion to distinguish redundant filters is difficult. To address such a challenging issue, we propose a new technique of Channel Pruning via Optimal Transport, dubbed CPOT. Specifically, we locate the Wasserstein barycenter for channels of each layer in the deep models, which is the mean of a set of probability distributions under the optimal transport metric. Then, we prune the redundant information located by Wasserstein barycenters. At last, we empirically demonstrate that, for classification tasks, CPOT outperforms the state-of-the-art methods on pruning ResNet-20, ResNet-32, ResNet-56, and ResNet-110. Furthermore, we show that the proposed CPOT technique is good at compressing the StarGAN models by pruning in the more difficult case of image-to-image translation tasks.
Evaluating Progress on Machine Learning for Longitudinal Electronic Healthcare Data
Oct 02, 2020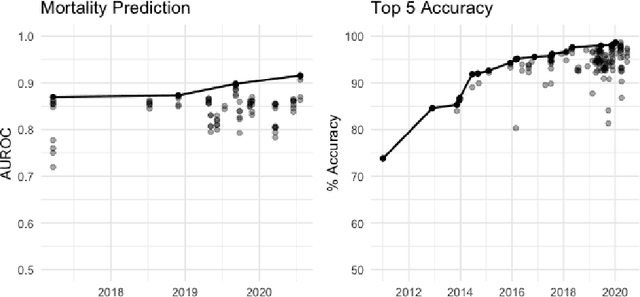
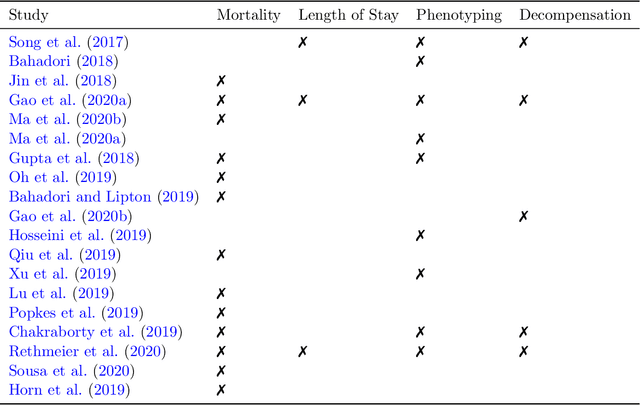
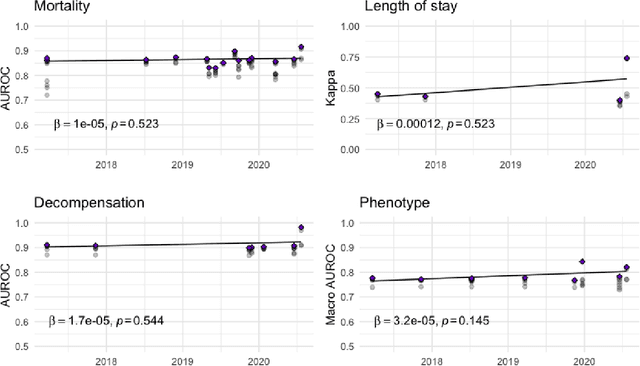

The Large Scale Visual Recognition Challenge based on the well-known Imagenet dataset catalyzed an intense flurry of progress in computer vision. Benchmark tasks have propelled other sub-fields of machine learning forward at an equally impressive pace, but in healthcare it has primarily been image processing tasks, such as in dermatology and radiology, that have experienced similar benchmark-driven progress. In the present study, we performed a comprehensive review of benchmarks in medical machine learning for structured data, identifying one based on the Medical Information Mart for Intensive Care (MIMIC-III) that allows the first direct comparison of predictive performance and thus the evaluation of progress on four clinical prediction tasks: mortality, length of stay, phenotyping, and patient decompensation. We find that little meaningful progress has been made over a 3 year period on these tasks, despite significant community engagement. Through our meta-analysis, we find that the performance of deep recurrent models is only superior to logistic regression on certain tasks. We conclude with a synthesis of these results, possible explanations, and a list of desirable qualities for future benchmarks in medical machine learning.
Semantics-Guided Clustering with Deep Progressive Learning for Semi-Supervised Person Re-identification
Oct 02, 2020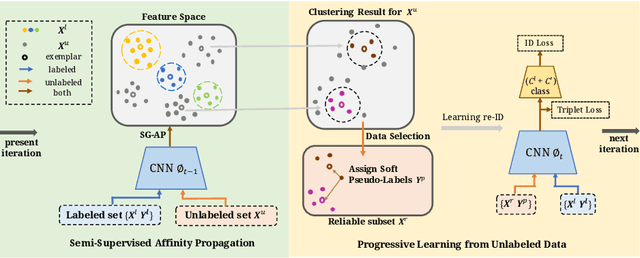
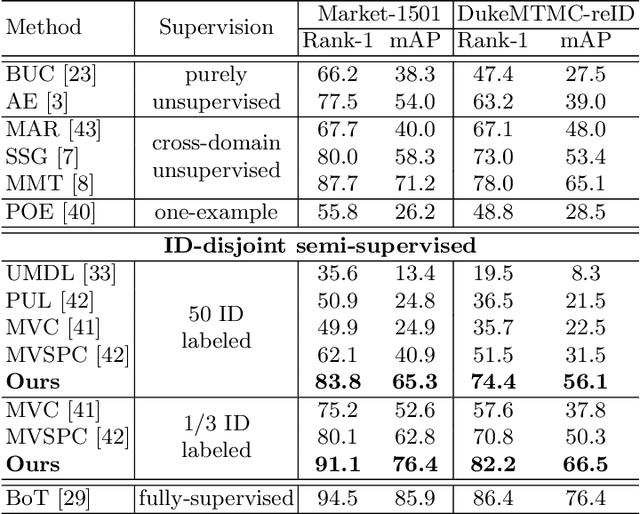
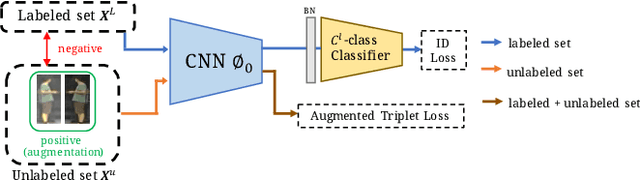
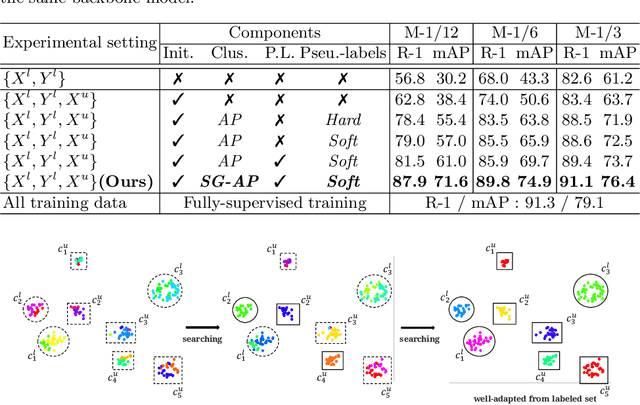
Person re-identification (re-ID) requires one to match images of the same person across camera views. As a more challenging task, semi-supervised re-ID tackles the problem that only a number of identities in training data are fully labeled, while the remaining are unlabeled. Assuming that such labeled and unlabeled training data share disjoint identity labels, we propose a novel framework of Semantics-Guided Clustering with Deep Progressive Learning (SGC-DPL) to jointly exploit the above data. By advancing the proposed Semantics-Guided Affinity Propagation (SG-AP), we are able to assign pseudo-labels to selected unlabeled data in a progressive fashion, under the semantics guidance from the labeled ones. As a result, our approach is able to augment the labeled training data in the semi-supervised setting. Our experiments on two large-scale person re-ID benchmarks demonstrate the superiority of our SGC-DPL over state-of-the-art methods across different degrees of supervision. In extension, the generalization ability of our SGC-DPL is also verified in other tasks like vehicle re-ID or image retrieval with the semi-supervised setting.
Tailoring: encoding inductive biases by optimizing unsupervised objectives at prediction time
Oct 14, 2020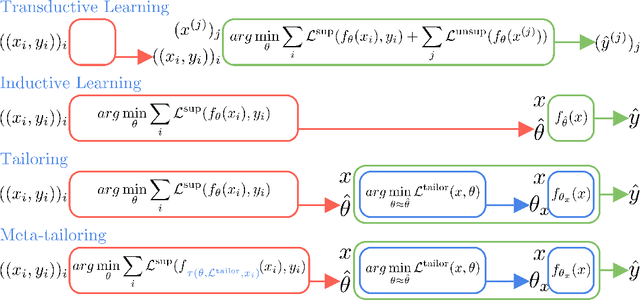
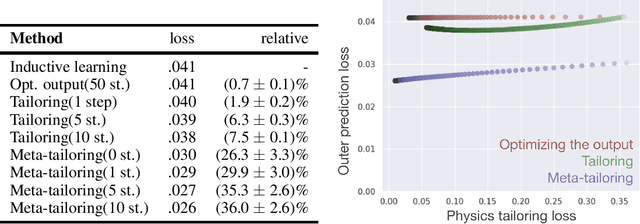
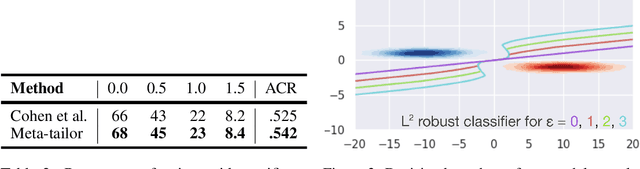
From CNNs to attention mechanisms, encoding inductive biases into neural networks has been a fruitful source of improvement in machine learning. Auxiliary losses are a general way of encoding biases in order to help networks learn better representations by adding extra terms to the loss function. However, since they are minimized on the training data, they suffer from the same generalization gap as regular task losses. Moreover, by changing the loss function, the network is optimizing a different objective than the one we care about. In this work we solve both problems: first, we take inspiration from \textit{transductive learning} and note that, after receiving an input but before making a prediction, we can fine-tune our models on any unsupervised objective. We call this process tailoring, because we customize the model to each input. Second, we formulate a nested optimization (similar to those in meta-learning) and train our models to perform well on the task loss after adapting to the tailoring loss. The advantages of tailoring and meta-tailoring are discussed theoretically and demonstrated empirically on several diverse examples: encoding inductive conservation laws from physics to improve predictions, improving local smoothness to increase robustness to adversarial examples, and using contrastive losses on the query image to improve generalization.
Transform Domain Pyramidal Dilated Convolution Networks For Restoration of Under Display Camera Images
Sep 20, 2020
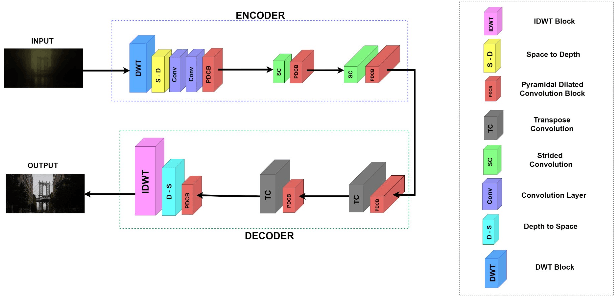
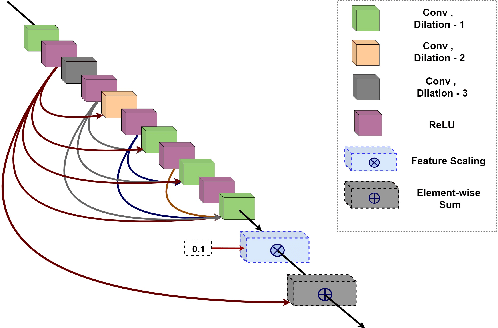
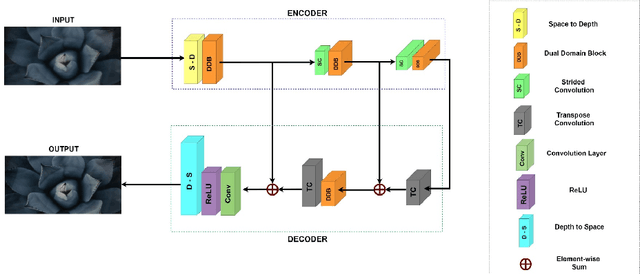
Under-display camera (UDC) is a novel technology that can make digital imaging experience in handheld devices seamless by providing large screen-to-body ratio. UDC images are severely degraded owing to their positioning under a display screen. This work addresses the restoration of images degraded as a result of UDC imaging. Two different networks are proposed for the restoration of images taken with two types of UDC technologies. The first method uses a pyramidal dilated convolution within a wavelet decomposed convolutional neural network for pentile-organic LED (P-OLED) based display system. The second method employs pyramidal dilated convolution within a discrete cosine transform based dual domain network to restore images taken using a transparent-organic LED (T-OLED) based UDC system. The first method produced very good quality restored images and was the winning entry in European Conference on Computer Vision (ECCV) 2020 challenge on image restoration for Under-display Camera - Track 2 - P-OLED evaluated based on PSNR and SSIM. The second method scored fourth position in Track-1 (T-OLED) of the challenge evaluated based on the same metrics.
Real-time Lane detection and Motion Planning in Raspberry Pi and Arduino for an Autonomous Vehicle Prototype
Sep 20, 2020



This paper discusses a vehicle prototype that recognizes streets' lanes and plans its motion accordingly without any human input. Pi Camera 1.3 captures real-time video, which is then processed by Raspberry-Pi 3.0 Model B. The image processing algorithms are written in Python 3.7.4 with OpenCV 4.2. Arduino Uno is utilized to control the PID algorithm that controls the motor controller, which in turn controls the wheels. Algorithms that are used to detect the lanes are the Canny edge detection algorithm and Hough transformation. Elementary algebra is used to draw the detected lanes. After detection, the lanes are tracked using the Kalman filter prediction method. Then the midpoint of the two lanes is found, which is the initial steering direction. This initial steering direction is further smoothed by using the Past Accumulation Average Method and Kalman Filter Prediction Method. The prototype was tested in a controlled environment in real-time. Results from comprehensive testing suggest that this prototype can detect road lanes and plan its motion successfully.
End-to-End Domain Adaptive Attention Network for Cross-Domain Person Re-Identification
May 07, 2020
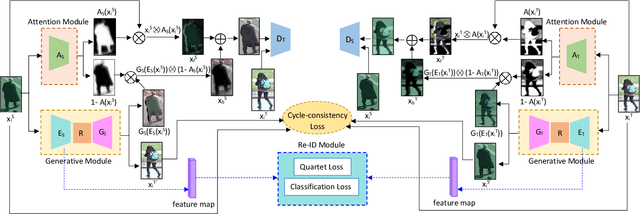
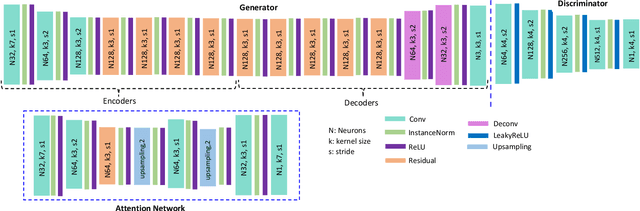

Person re-identification (re-ID) remains challenging in a real-world scenario, as it requires a trained network to generalise to totally unseen target data in the presence of variations across domains. Recently, generative adversarial models have been widely adopted to enhance the diversity of training data. These approaches, however, often fail to generalise to other domains, as existing generative person re-identification models have a disconnect between the generative component and the discriminative feature learning stage. To address the on-going challenges regarding model generalisation, we propose an end-to-end domain adaptive attention network to jointly translate images between domains and learn discriminative re-id features in a single framework. To address the domain gap challenge, we introduce an attention module for image translation from source to target domains without affecting the identity of a person. More specifically, attention is directed to the background instead of the entire image of the person, ensuring identifying characteristics of the subject are preserved. The proposed joint learning network results in a significant performance improvement over state-of-the-art methods on several benchmark datasets.
Noise Robust Generative Adversarial Networks
Nov 26, 2019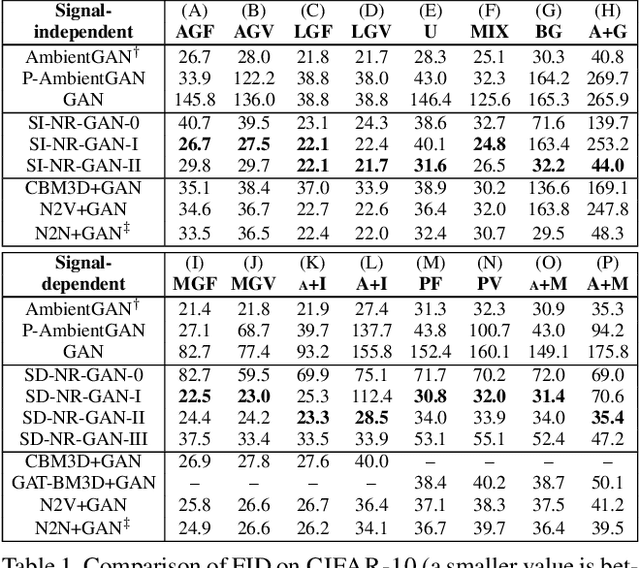

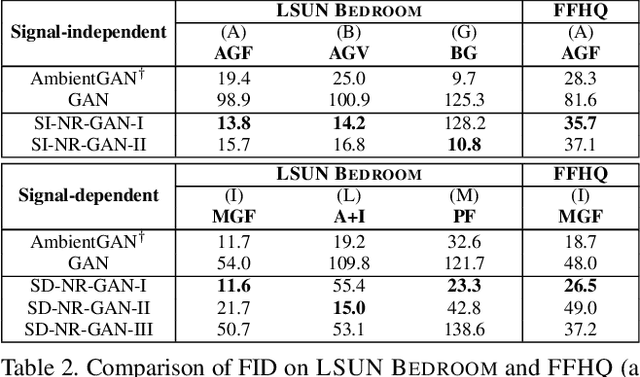
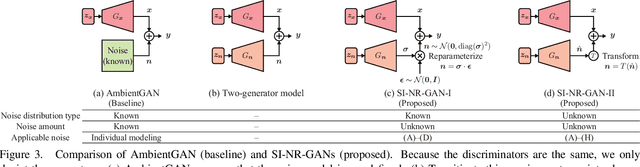
Generative adversarial networks (GANs) are neural networks that learn data distributions through adversarial training. In intensive studies, recent GANs have shown promising results for reproducing training data. However, in spite of noise, they reproduce data with fidelity. As an alternative, we propose a novel family of GANs called noise-robust GANs (NR-GANs), which can learn a clean image generator even when training data are noisy. In particular, NR-GANs can solve this problem without having complete noise information (e.g., the noise distribution type, noise amount, or signal-noise relation). To achieve this, we introduce a noise generator and train it along with a clean image generator. As it is difficult to generate an image and a noise separately without constraints, we propose distribution and transformation constraints that encourage the noise generator to capture only the noise-specific components. In particular, considering such constraints under different assumptions, we devise two variants of NR-GANs for signal-independent noise and three variants of NR-GANs for signal-dependent noise. On three benchmark datasets, we demonstrate the effectiveness of NR-GANs in noise robust image generation. Furthermore, we show the applicability of NR-GANs in image denoising.
Are all negatives created equal in contrastive instance discrimination?
Oct 13, 2020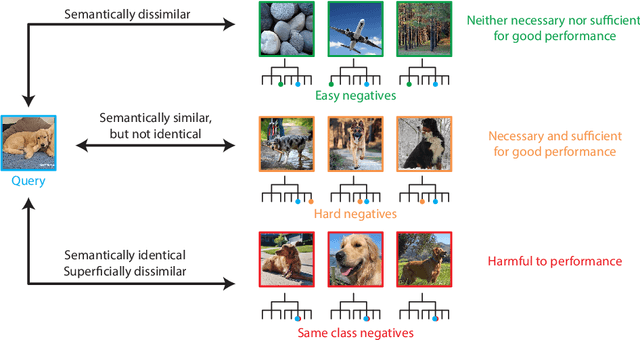
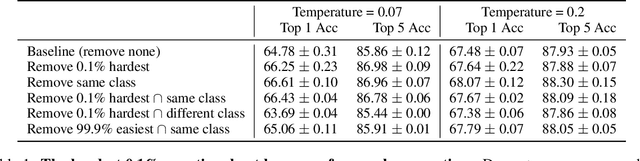
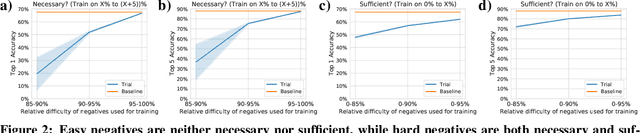
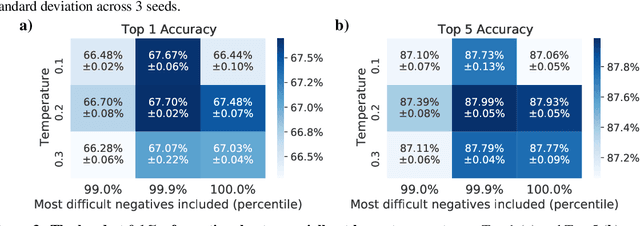
Self-supervised learning has recently begun to rival supervised learning on computer vision tasks. Many of the recent approaches have been based on contrastive instance discrimination (CID), in which the network is trained to recognize two augmented versions of the same instance (a query and positive) while discriminating against a pool of other instances (negatives). The learned representation is then used on downstream tasks such as image classification. Using methodology from MoCo v2 (Chen et al., 2020), we divided negatives by their difficulty for a given query and studied which difficulty ranges were most important for learning useful representations. We found a minority of negatives -- the hardest 5% -- were both necessary and sufficient for the downstream task to reach nearly full accuracy. Conversely, the easiest 95% of negatives were unnecessary and insufficient. Moreover, the very hardest 0.1% of negatives were unnecessary and sometimes detrimental. Finally, we studied the properties of negatives that affect their hardness, and found that hard negatives were more semantically similar to the query, and that some negatives were more consistently easy or hard than we would expect by chance. Together, our results indicate that negatives vary in importance and that CID may benefit from more intelligent negative treatment.