 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MELD: Meta-Reinforcement Learning from Images via Latent State Models
Oct 26, 2020

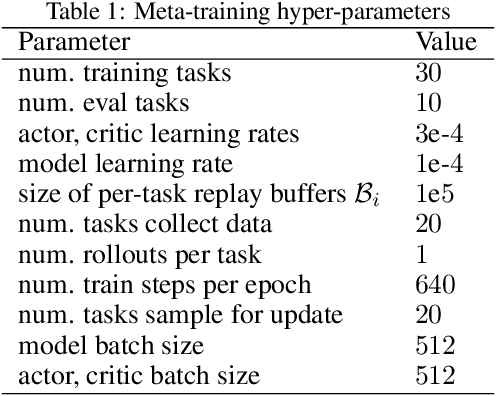
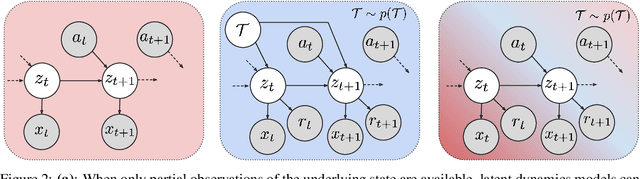
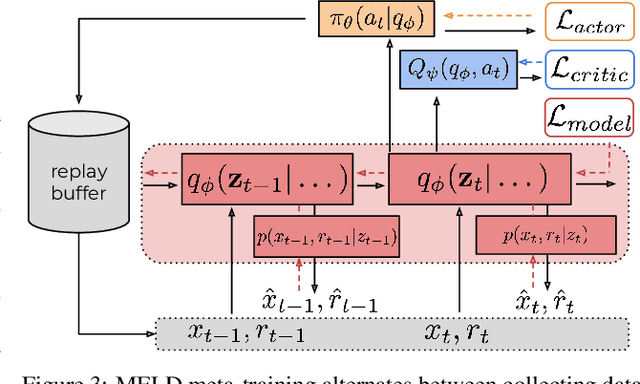
Meta-reinforcement learning algorithms can enable autonomous agents, such as robots, to quickly acquire new behaviors by leveraging prior experience in a set of related training tasks. However, the onerous data requirements of meta-training compounded with the challenge of learning from sensory inputs such as images have made meta-RL challenging to apply to real robotic systems. Latent state models, which learn compact state representations from a sequence of observations, can accelerate representation learning from visual inputs. In this paper, we leverage the perspective of meta-learning as task inference to show that latent state models can \emph{also} perform meta-learning given an appropriately defined observation space. Building on this insight, we develop meta-RL with latent dynamics (MELD), an algorithm for meta-RL from images that performs inference in a latent state model to quickly acquire new skills given observations and rewards. MELD outperforms prior meta-RL methods on several simulated image-based robotic control problems, and enables a real WidowX robotic arm to insert an Ethernet cable into new locations given a sparse task completion signal after only $8$ hours of real world meta-training. To our knowledge, MELD is the first meta-RL algorithm trained in a real-world robotic control setting from images.
Bayesian Neural Networks for Uncertainty Estimation of Imaging Biomarkers
Aug 28, 2020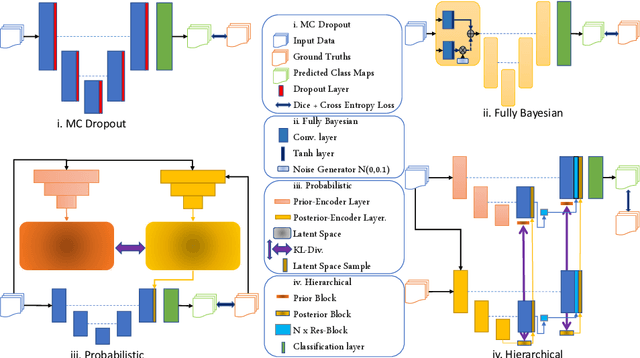
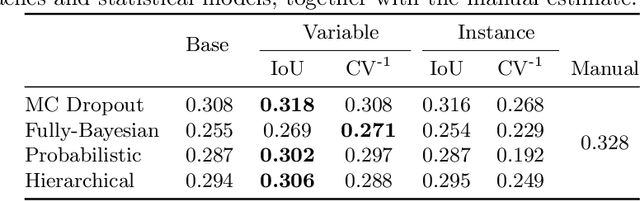
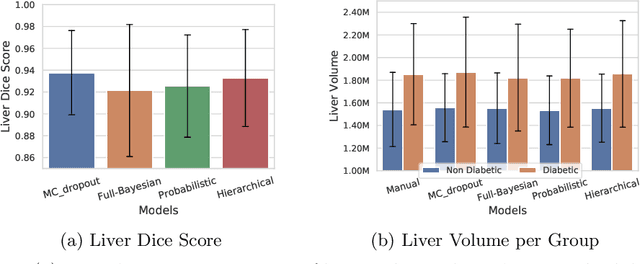
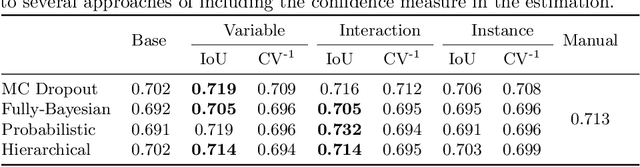
Image segmentation enables to extract quantitative measures from scans that can serve as imaging biomarkers for diseases. However, segmentation quality can vary substantially across scans, and therefore yield unfaithful estimates in the follow-up statistical analysis of biomarkers. The core problem is that segmentation and biomarker analysis are performed independently. We propose to propagate segmentation uncertainty to the statistical analysis to account for variations in segmentation confidence. To this end, we evaluate four Bayesian neural networks to sample from the posterior distribution and estimate the uncertainty. We then assign confidence measures to the biomarker and propose statistical models for its integration in group analysis and disease classification. Our results for segmenting the liver in patients with diabetes mellitus clearly demonstrate the improvement of integrating biomarker uncertainty in the statistical inference.
Chebyshev and Conjugate Gradient Filters for Graph Image Denoising
Sep 04, 2015

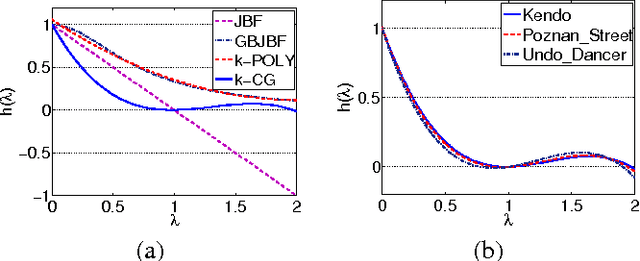
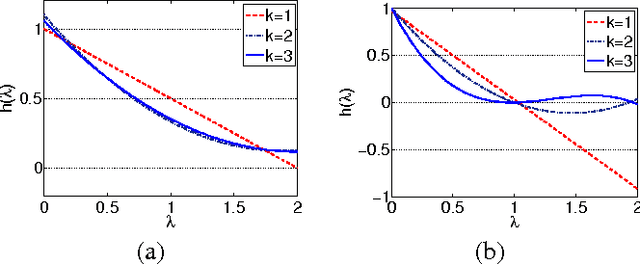
In 3D image/video acquisition, different views are often captured with varying noise levels across the views. In this paper, we propose a graph-based image enhancement technique that uses a higher quality view to enhance a degraded view. A depth map is utilized as auxiliary information to match the perspectives of the two views. Our method performs graph-based filtering of the noisy image by directly computing a projection of the image to be filtered onto a lower dimensional Krylov subspace of the graph Laplacian. We discuss two graph spectral denoising methods: first using Chebyshev polynomials, and second using iterations of the conjugate gradient algorithm. Our framework generalizes previously known polynomial graph filters, and we demonstrate through numerical simulations that our proposed technique produces subjectively cleaner images with about 1-3 dB improvement in PSNR over existing polynomial graph filters.
* 6 pages, 6 figures, accepted to 2014 IEEE International Conference on Multimedia and Expo Workshops (ICMEW)
UV-Net: Learning from Curve-Networks and Solids
Jun 18, 2020
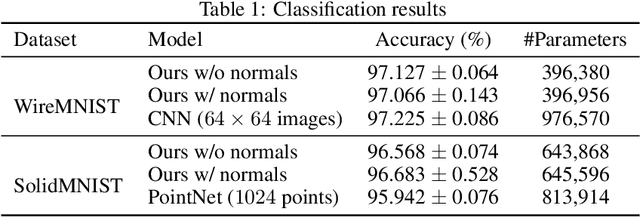
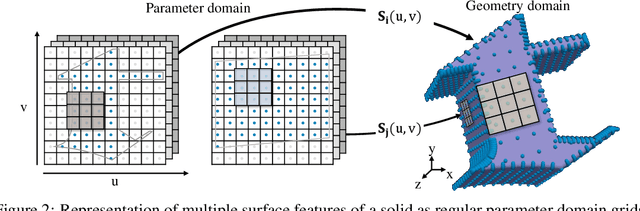
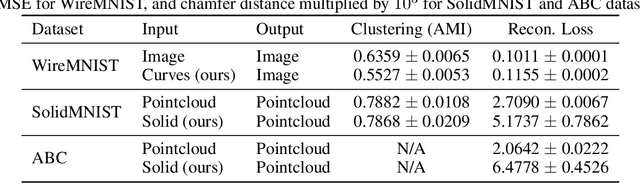
Parametric curves, surfaces and boundary representations are the basis for 2D vector graphics and 3D industrial designs. Despite their prevalence, there exists limited research on applying modern deep neural networks directly to such representations. The unique challenges in working with such representations arise from the combination of continuous non-Euclidean geometry domain and discrete topology, as well as a lack of labeled datasets, benchmarks and baseline models. In this paper, we propose a unified representation for parametric curve-networks and solids by exploiting the u- and uv-parameter domains of curve and surfaces, respectively, to model the geometry, and an adjacency graph to explicitly model the topology. This leads to a unique and efficient network architecture based on coupled image and graph convolutional neural networks to extract features from curve-networks and solids. Inspired by the MNIST image dataset, we create and publish WireMNIST (for 2D curve-networks) and SolidMNIST (for 3D solids), two related labeled datasets depicting alphabets to encourage future research in this area. We demonstrate the effectiveness of our method using supervised and self-supervised tasks on our new datasets, as well as the publicly available ABC dataset. The results demonstrate the effectiveness of our representation and provide a competitive baseline for learning tasks involving curve-networks and solids.
A Semi-Lagrangian two-level preconditioned Newton-Krylov solver for constrained diffeomorphic image registration
Feb 28, 2018
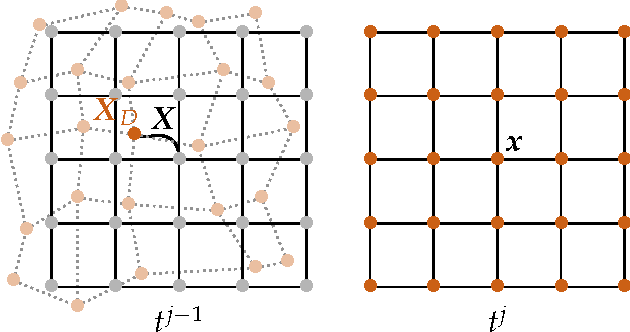
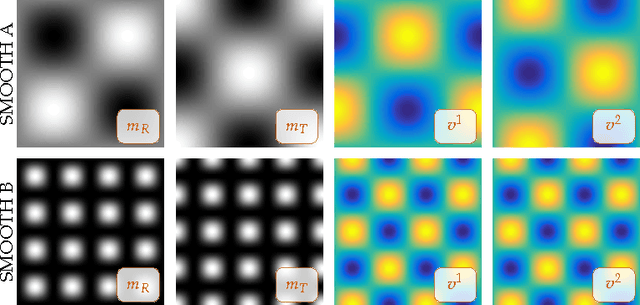
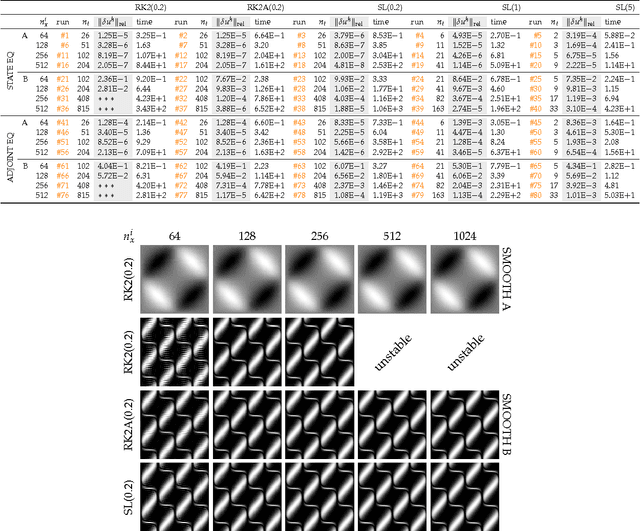
We propose an efficient numerical algorithm for the solution of diffeomorphic image registration problems. We use a variational formulation constrained by a partial differential equation (PDE), where the constraints are a scalar transport equation. We use a pseudospectral discretization in space and second-order accurate semi-Lagrangian time stepping scheme for the transport equations. We solve for a stationary velocity field using a preconditioned, globalized, matrix-free Newton-Krylov scheme. We propose and test a two-level Hessian preconditioner. We consider two strategies for inverting the preconditioner on the coarse grid: a nested preconditioned conjugate gradient method (exact solve) and a nested Chebyshev iterative method (inexact solve) with a fixed number of iterations. We test the performance of our solver in different synthetic and real-world two-dimensional application scenarios. We study grid convergence and computational efficiency of our new scheme. We compare the performance of our solver against our initial implementation that uses the same spatial discretization but a standard, explicit, second-order Runge-Kutta scheme for the numerical time integration of the transport equations and a single-level preconditioner. Our improved scheme delivers significant speedups over our original implementation. As a highlight, we observe a 20$\times$ speedup for a two dimensional, real world multi-subject medical image registration problem.
Does Data Augmentation Benefit from Split BatchNorms
Oct 15, 2020


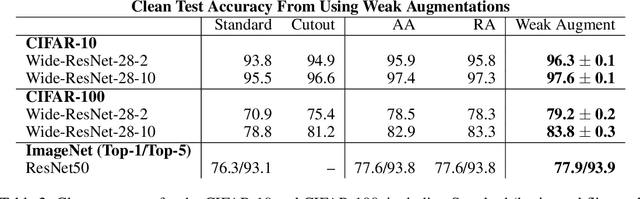
Data augmentation has emerged as a powerful technique for improving the performance of deep neural networks and led to state-of-the-art results in computer vision. However, state-of-the-art data augmentation strongly distorts training images, leading to a disparity between examples seen during training and inference. In this work, we explore a recently proposed training paradigm in order to correct for this disparity: using an auxiliary BatchNorm for the potentially out-of-distribution, strongly augmented images. Our experiments then focus on how to define the BatchNorm parameters that are used at evaluation. To eliminate the train-test disparity, we experiment with using the batch statistics defined by clean training images only, yet surprisingly find that this does not yield improvements in model performance. Instead, we investigate using BatchNorm parameters defined by weak augmentations and find that this method significantly improves the performance of common image classification benchmarks such as CIFAR-10, CIFAR-100, and ImageNet. We then explore a fundamental trade-off between accuracy and robustness coming from using different BatchNorm parameters, providing greater insight into the benefits of data augmentation on model performance.
Neural network-based on-chip spectroscopy using a scalable plasmonic encoder
Dec 01, 2020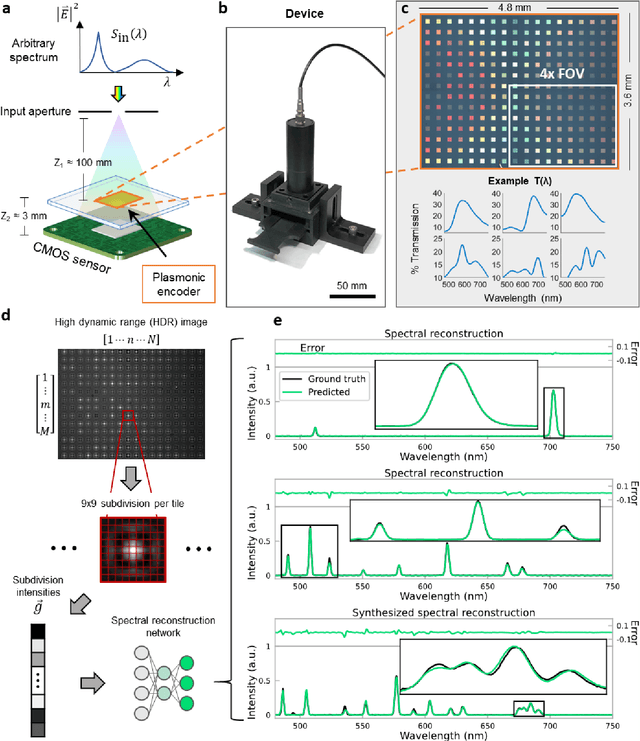
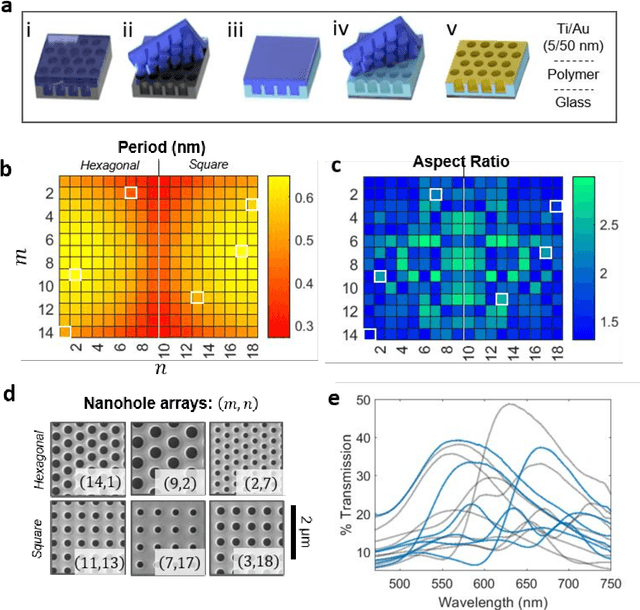
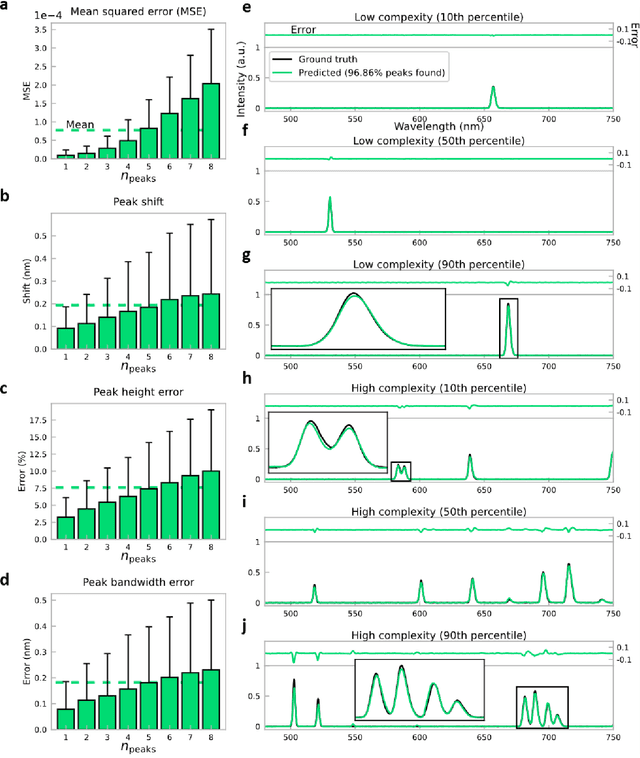
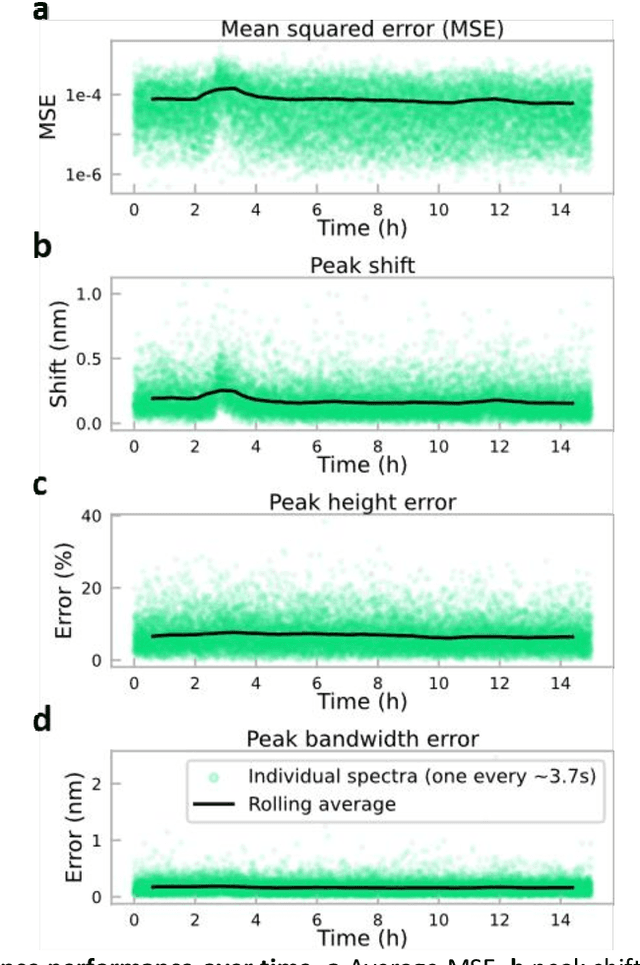
Conventional spectrometers are limited by trade-offs set by size, cost, signal-to-noise ratio (SNR), and spectral resolution. Here, we demonstrate a deep learning-based spectral reconstruction framework, using a compact and low-cost on-chip sensing scheme that is not constrained by the design trade-offs inherent to grating-based spectroscopy. The system employs a plasmonic spectral encoder chip containing 252 different tiles of nanohole arrays fabricated using a scalable and low-cost imprint lithography method, where each tile has a unique geometry and, thus, a unique optical transmission spectrum. The illumination spectrum of interest directly impinges upon the plasmonic encoder, and a CMOS image sensor captures the transmitted light, without any lenses, gratings, or other optical components in between, making the entire hardware highly compact, light-weight and field-portable. A trained neural network then reconstructs the unknown spectrum using the transmitted intensity information from the spectral encoder in a feed-forward and non-iterative manner. Benefiting from the parallelization of neural networks, the average inference time per spectrum is ~28 microseconds, which is orders of magnitude faster compared to other computational spectroscopy approaches. When blindly tested on unseen new spectra (N = 14,648) with varying complexity, our deep-learning based system identified 96.86% of the spectral peaks with an average peak localization error, bandwidth error, and height error of 0.19 nm, 0.18 nm, and 7.60%, respectively. This system is also highly tolerant to fabrication defects that may arise during the imprint lithography process, which further makes it ideal for applications that demand cost-effective, field-portable and sensitive high-resolution spectroscopy tools.
Data Augmentation via Structured Adversarial Perturbations
Nov 05, 2020
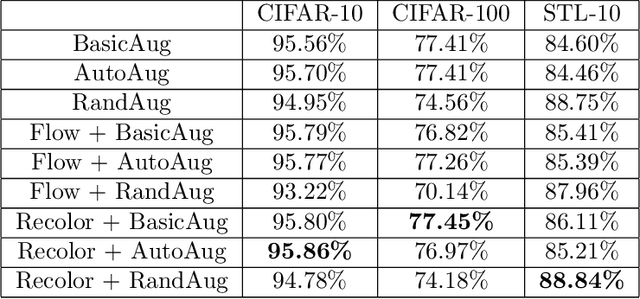

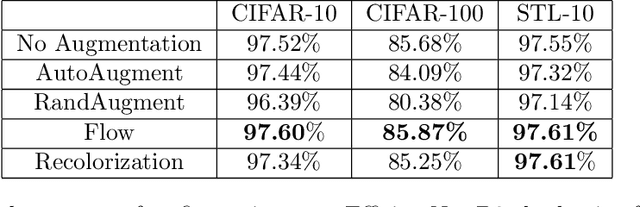
Data augmentation is a major component of many machine learning methods with state-of-the-art performance. Common augmentation strategies work by drawing random samples from a space of transformations. Unfortunately, such sampling approaches are limited in expressivity, as they are unable to scale to rich transformations that depend on numerous parameters due to the curse of dimensionality. Adversarial examples can be considered as an alternative scheme for data augmentation. By being trained on the most difficult modifications of the inputs, the resulting models are then hopefully able to handle other, presumably easier, modifications as well. The advantage of adversarial augmentation is that it replaces sampling with the use of a single, calculated perturbation that maximally increases the loss. The downside, however, is that these raw adversarial perturbations appear rather unstructured; applying them often does not produce a natural transformation, contrary to a desirable data augmentation technique. To address this, we propose a method to generate adversarial examples that maintain some desired natural structure. We first construct a subspace that only contains perturbations with the desired structure. We then project the raw adversarial gradient onto this space to select a structured transformation that would maximally increase the loss when applied. We demonstrate this approach through two types of image transformations: photometric and geometric. Furthermore, we show that training on such structured adversarial images improves generalization.
Synthesizing human-like sketches from natural images using a conditional convolutional decoder
Mar 16, 2020
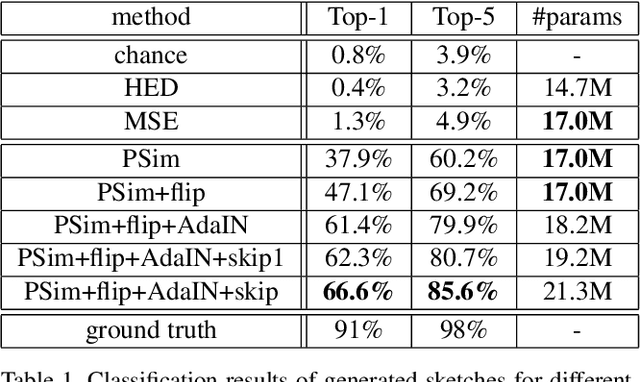
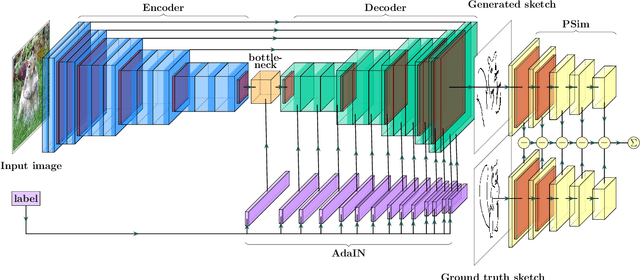

Humans are able to precisely communicate diverse concepts by employing sketches, a highly reduced and abstract shape based representation of visual content. We propose, for the first time, a fully convolutional end-to-end architecture that is able to synthesize human-like sketches of objects in natural images with potentially cluttered background. To enable an architecture to learn this highly abstract mapping, we employ the following key components: (1) a fully convolutional encoder-decoder structure, (2) a perceptual similarity loss function operating in an abstract feature space and (3) conditioning of the decoder on the label of the object that shall be sketched. Given the combination of these architectural concepts, we can train our structure in an end-to-end supervised fashion on a collection of sketch-image pairs. The generated sketches of our architecture can be classified with 85.6% Top-5 accuracy and we verify their visual quality via a user study. We find that deep features as a perceptual similarity metric enable image translation with large domain gaps and our findings further show that convolutional neural networks trained on image classification tasks implicitly learn to encode shape information. Code is available under https://github.com/kampelmuehler/synthesizing_human_like_sketches
Learning Colour Representations of Search Queries
Jun 17, 2020
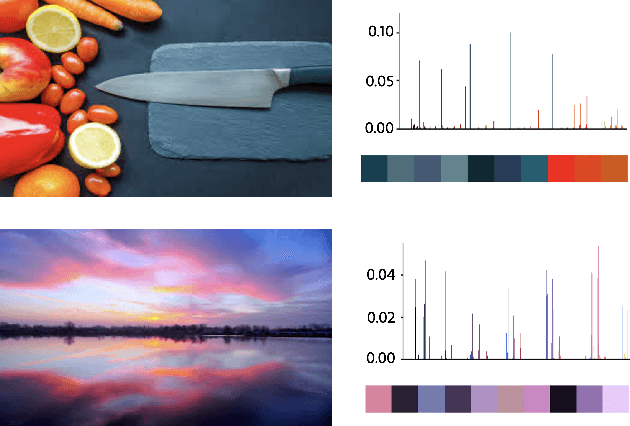

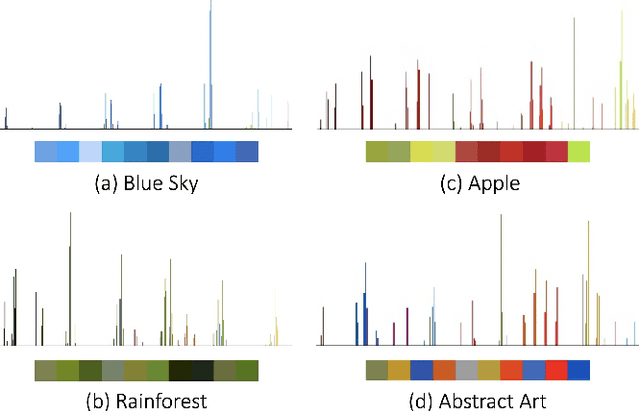
Image search engines rely on appropriately designed ranking features that capture various aspects of the content semantics as well as the historic popularity. In this work, we consider the role of colour in this relevance matching process. Our work is motivated by the observation that a significant fraction of user queries have an inherent colour associated with them. While some queries contain explicit colour mentions (such as 'black car' and 'yellow daisies'), other queries have implicit notions of colour (such as 'sky' and 'grass'). Furthermore, grounding queries in colour is not a mapping to a single colour, but a distribution in colour space. For instance, a search for 'trees' tends to have a bimodal distribution around the colours green and brown. We leverage historical clickthrough data to produce a colour representation for search queries and propose a recurrent neural network architecture to encode unseen queries into colour space. We also show how this embedding can be learnt alongside a cross-modal relevance ranker from impression logs where a subset of the result images were clicked. We demonstrate that the use of a query-image colour distance feature leads to an improvement in the ranker performance as measured by users' preferences of clicked versus skipped images.