 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Heteroscedastic Likelihood Model for Two-frame Optical Flow
Oct 14, 2020
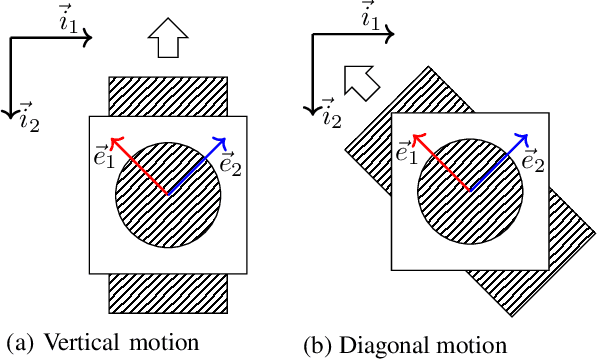

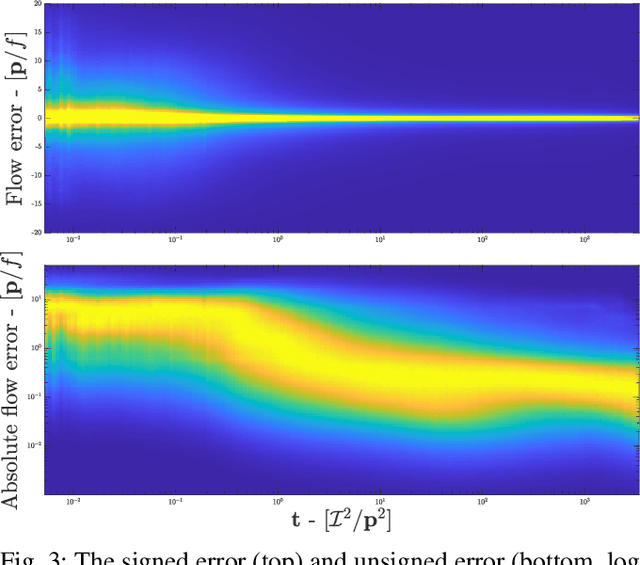
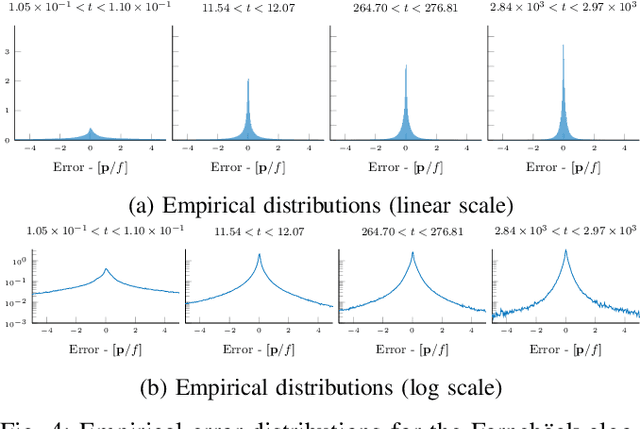
Machine vision is an important sensing technology used in mobile robotic systems. Advancing the autonomy of such systems requires accurate characterisation of sensor uncertainty. Vision includes intrinsic uncertainty due to the camera sensor and extrinsic uncertainty due to environmental lighting and texture, which propagate through the image processing algorithms used to produce visual measurements. To faithfully characterise visual measurements, we must take into account these uncertainties. In this paper, we propose a new class of likelihood functions that characterises the uncertainty of the error distribution of two-frame optical flow that enables a heteroscedastic dependence on texture. We employ the proposed class to characterise the Farneback and Lucas Kanade optical flow algorithms and achieve close agreement with their respective empirical error distributions over a wide range of texture in a simulated environment. The utility of the proposed likelihood model is demonstrated in a visual odometry ego-motion simulation study, which results in 30-83% reduction in position drift rate compared to traditional methods employing a Gaussian error assumption. The development of an empirically congruent likelihood model advances the requisite tool-set for vision-based Bayesian inference and enables sensor data fusion with GPS, LiDAR and IMU to advance robust autonomous navigation.
A smile I could recognise in a thousand: Automatic identification of identity from dental radiography
Jan 14, 2020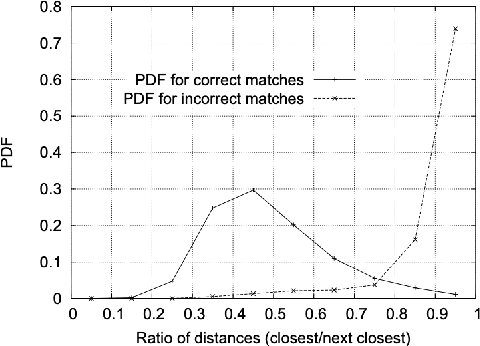
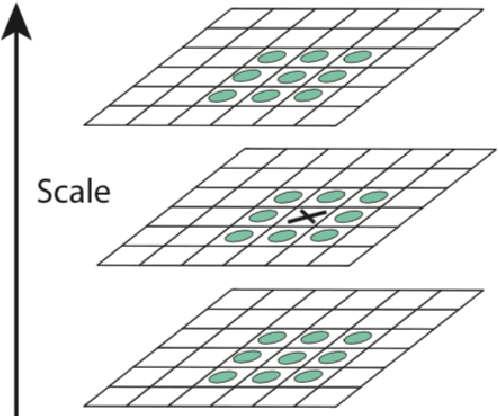
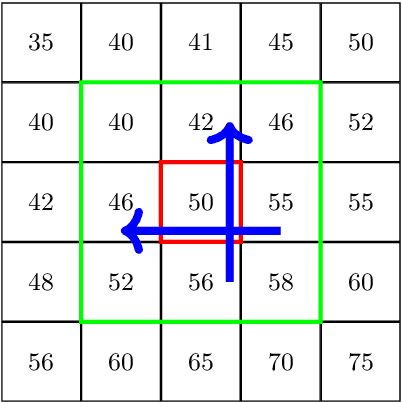
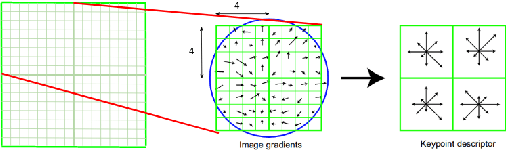
In this paper, we present a method to automatically compare multiple radiographs in order to find the identity of a patient out of the dental features. The method is based on the matching of image features, previously extracted by computer vision algorithms for image descriptor recognition. The principal application (being also our motivation to study the problem) of such a method would be in victim identification in mass disasters.
Learning Soft Labels via Meta Learning
Sep 20, 2020

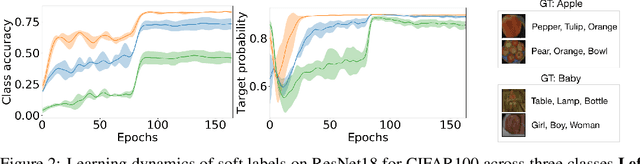

One-hot labels do not represent soft decision boundaries among concepts, and hence, models trained on them are prone to overfitting. Using soft labels as targets provide regularization, but different soft labels might be optimal at different stages of optimization. Also, training with fixed labels in the presence of noisy annotations leads to worse generalization. To address these limitations, we propose a framework, where we treat the labels as learnable parameters, and optimize them along with model parameters. The learned labels continuously adapt themselves to the model's state, thereby providing dynamic regularization. When applied to the task of supervised image-classification, our method leads to consistent gains across different datasets and architectures. For instance, dynamically learned labels improve ResNet18 by 2.1% on CIFAR100. When applied to dataset containing noisy labels, the learned labels correct the annotation mistakes, and improves over state-of-the-art by a significant margin. Finally, we show that learned labels capture semantic relationship between classes, and thereby improve teacher models for the downstream task of distillation.
Patch-Ordering as a Regularization for Inverse Problems in Image Processing
Feb 26, 2016


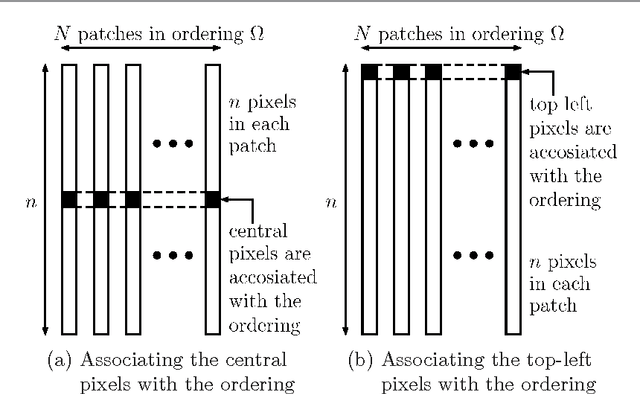
Recent work in image processing suggests that operating on (overlapping) patches in an image may lead to state-of-the-art results. This has been demonstrated for a variety of problems including denoising, inpainting, deblurring, and super-resolution. The work reported in [1,2] takes an extra step forward by showing that ordering these patches to form an approximate shortest path can be leveraged for better processing. The core idea is to apply a simple filter on the resulting 1D smoothed signal obtained after the patch-permutation. This idea has been also explored in combination with a wavelet pyramid, leading eventually to a sophisticated and highly effective regularizer for inverse problems in imaging. In this work we further study the patch-permutation concept, and harness it to propose a new simple yet effective regularization for image restoration problems. Our approach builds on the classic Maximum A'posteriori probability (MAP), with a penalty function consisting of a regular log-likelihood term and a novel permutation-based regularization term. Using a plain 1D Laplacian, the proposed regularization forces robust smoothness (L1) on the permuted pixels. Since the permutation originates from patch-ordering, we propose to accumulate the smoothness terms over all the patches' pixels. Furthermore, we take into account the found distances between adjacent patches in the ordering, by weighting the Laplacian outcome. We demonstrate the proposed scheme on a diverse set of problems: (i) severe Poisson image denoising, (ii) Gaussian image denoising, (iii) image deblurring, and (iv) single image super-resolution. In all these cases, we use recent methods that handle these problems as initialization to our scheme. This is followed by an L-BFGS optimization of the above-described penalty function, leading to state-of-the-art results, and especially so for highly ill-posed cases.
Out-of-focus: Learning Depth from Image Bokeh for Robotic Perception
May 02, 2017
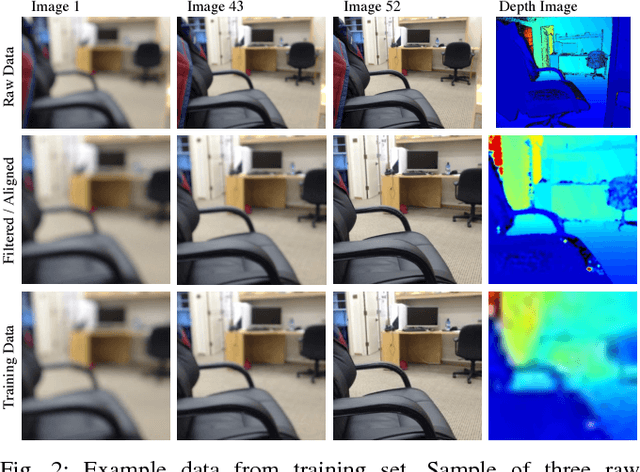

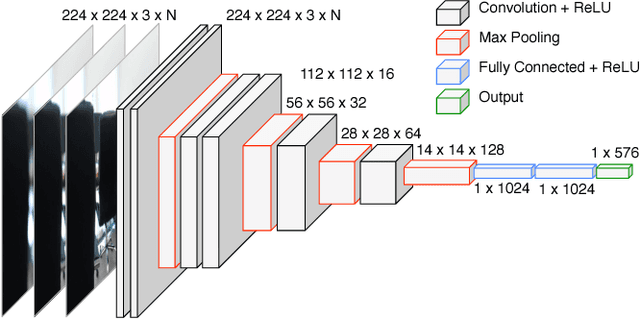
In this project, we propose a novel approach for estimating depth from RGB images. Traditionally, most work uses a single RGB image to estimate depth, which is inherently difficult and generally results in poor performance, even with thousands of data examples. In this work, we alternatively use multiple RGB images that were captured while changing the focus of the camera's lens. This method leverages the natural depth information correlated to the different patterns of clarity/blur in the sequence of focal images, which helps distinguish objects at different depths. Since no such data set exists for learning this mapping, we collect our own data set using customized hardware. We then use a convolutional neural network for learning the depth from the stacked focal images. Comparative studies were conducted on both a standard RGBD data set and our own data set (learning from both single and multiple images), and results verified that stacked focal images yield better depth estimation than using just single RGB image.
Implicit Feature Networks for Texture Completion from Partial 3D Data
Sep 20, 2020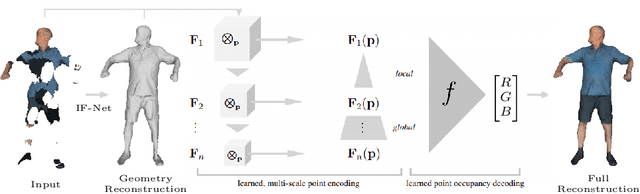
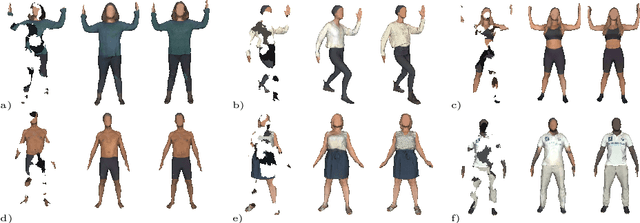

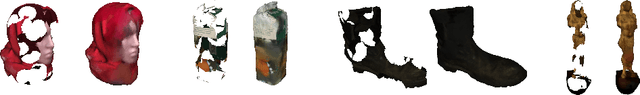
Prior work to infer 3D texture use either texture atlases, which require uv-mappings and hence have discontinuities, or colored voxels, which are memory inefficient and limited in resolution. Recent work, predicts RGB color at every XYZ coordinate forming a texture field, but focus on completing texture given a single 2D image. Instead, we focus on 3D texture and geometry completion from partial and incomplete 3D scans. IF-Nets have recently achieved state-of-the-art results on 3D geometry completion using a multi-scale deep feature encoding, but the outputs lack texture. In this work, we generalize IF-Nets to texture completion from partial textured scans of humans and arbitrary objects. Our key insight is that 3D texture completion benefits from incorporating local and global deep features extracted from both the 3D partial texture and completed geometry. Specifically, given the partial 3D texture and the 3D geometry completed with IF-Nets, our model successfully in-paints the missing texture parts in consistence with the completed geometry. Our model won the SHARP ECCV'20 challenge, achieving highest performance on all challenges.
* SHARP Workshop, European Conference on Computer Vision (ECCV), 2020
Compact Deep Aggregation for Set Retrieval
Mar 26, 2020
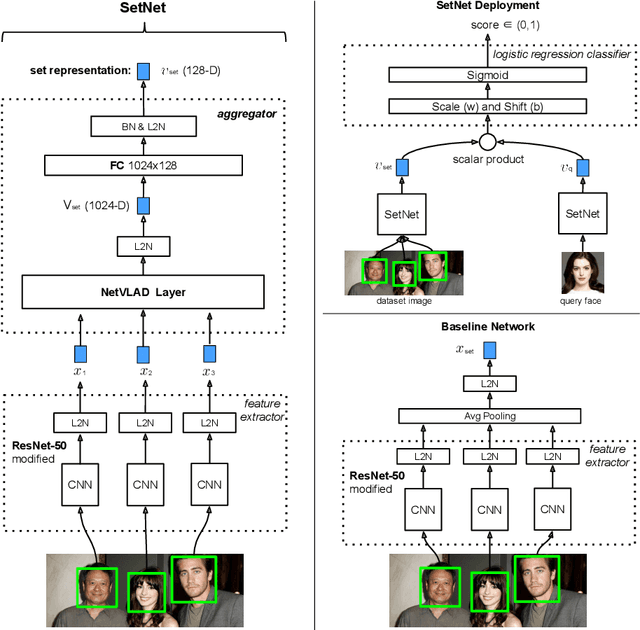
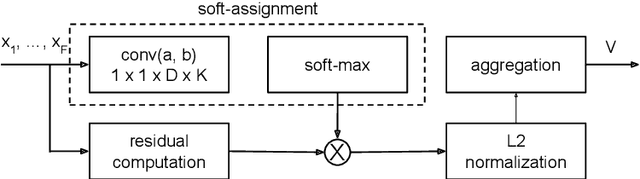

The objective of this work is to learn a compact embedding of a set of descriptors that is suitable for efficient retrieval and ranking, whilst maintaining discriminability of the individual descriptors. We focus on a specific example of this general problem -- that of retrieving images containing multiple faces from a large scale dataset of images. Here the set consists of the face descriptors in each image, and given a query for multiple identities, the goal is then to retrieve, in order, images which contain all the identities, all but one, \etc To this end, we make the following contributions: first, we propose a CNN architecture -- {\em SetNet} -- to achieve the objective: it learns face descriptors and their aggregation over a set to produce a compact fixed length descriptor designed for set retrieval, and the score of an image is a count of the number of identities that match the query; second, we show that this compact descriptor has minimal loss of discriminability up to two faces per image, and degrades slowly after that -- far exceeding a number of baselines; third, we explore the speed vs.\ retrieval quality trade-off for set retrieval using this compact descriptor; and, finally, we collect and annotate a large dataset of images containing various number of celebrities, which we use for evaluation and is publicly released.
Image Inpainting with Learnable Bidirectional Attention Maps
Sep 05, 2019
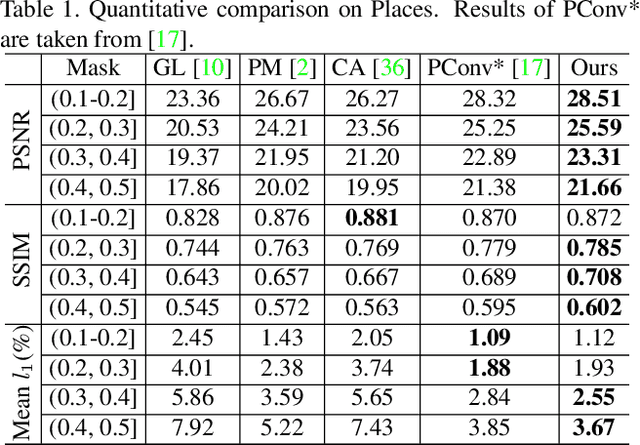
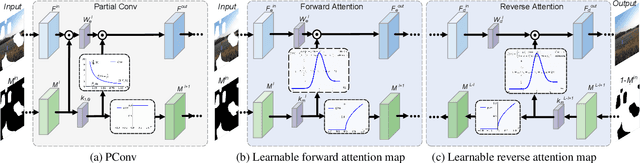

Most convolutional network (CNN)-based inpainting methods adopt standard convolution to indistinguishably treat valid pixels and holes, making them limited in handling irregular holes and more likely to generate inpainting results with color discrepancy and blurriness. Partial convolution has been suggested to address this issue, but it adopts handcrafted feature re-normalization, and only considers forward mask-updating. In this paper, we present a learnable attention map module for learning feature renormalization and mask-updating in an end-to-end manner, which is effective in adapting to irregular holes and propagation of convolution layers. Furthermore, learnable reverse attention maps are introduced to allow the decoder of U-Net to concentrate on filling in irregular holes instead of reconstructing both holes and known regions, resulting in our learnable bidirectional attention maps. Qualitative and quantitative experiments show that our method performs favorably against state-of-the-arts in generating sharper, more coherent and visually plausible inpainting results. The source code and pre-trained models will be available.
Three-branch and Mutil-scale learning for Fine-grained Image Recognition (TBMSL-Net)
Mar 20, 2020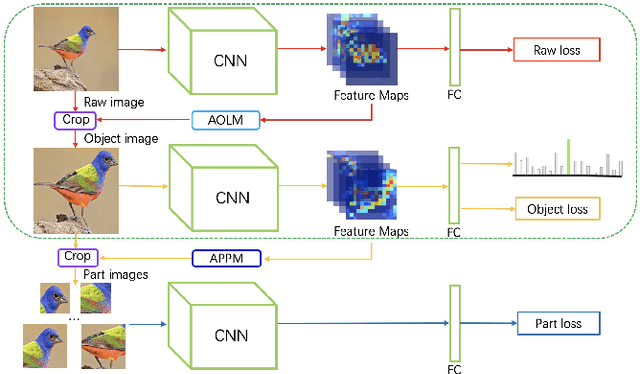
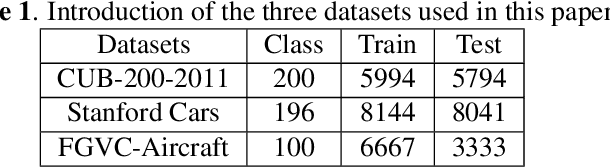
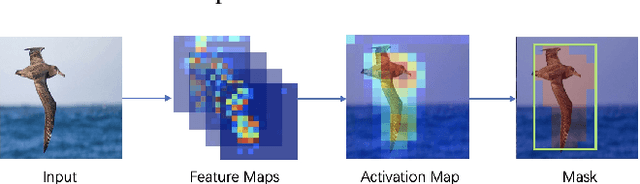
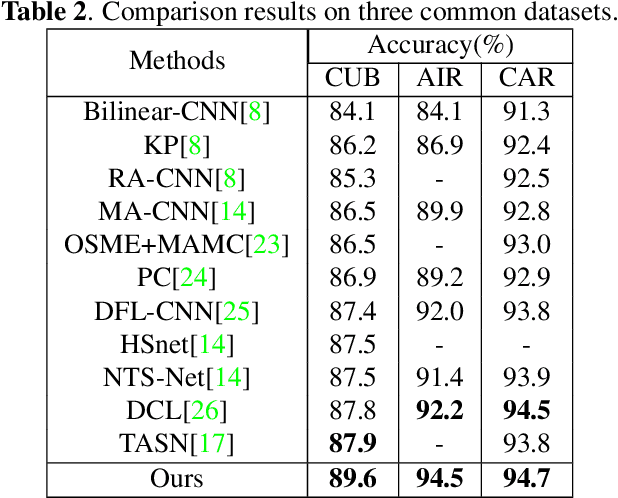
ImageNet Large Scale Visual Recognition Challenge (ILSVRC) is one of the most authoritative academic competitions in the field of Computer Vision (CV) in recent years, but it can not achieve good result to directly migrate the champions of the annual competition, to fine-grained visual categorization (FGVC) tasks. The small interclass variations and the large intraclass variations caused by the fine-grained nature makes it a challenging problem. The proposed method can be effectively localize object and useful part regions without the need of bounding-box and part annotations by attention object location module (AOLM) and attention part proposal module (APPM). The obtained object images contain both the whole structure and more details, the part images have many different scales and have more fine-grained features, and the raw images contain the complete object. The three kinds of training images are supervised by our three-branch network structure. The model has good classification ability, good generalization and robustness for different scale object images. Our approach is end-to-end training, through the comprehensive experiments demonstrate that our approach achieves state-of-the-art results on CUB-200-2011, Stanford Cars and FGVC-Aircraft datasets.
Tailoring: encoding inductive biases by optimizing unsupervised objectives at prediction time
Oct 14, 2020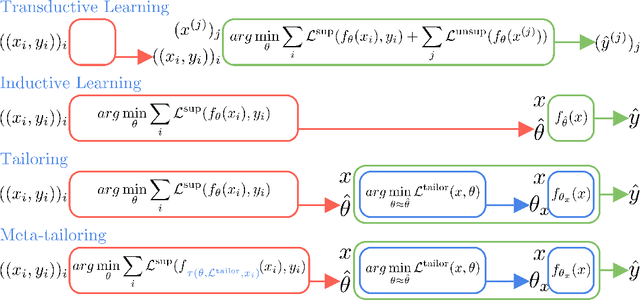
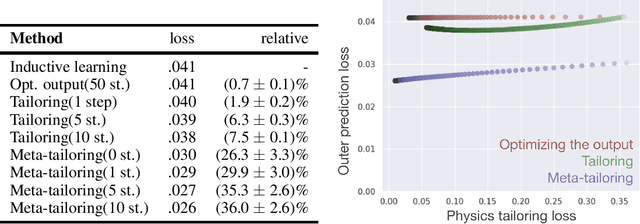
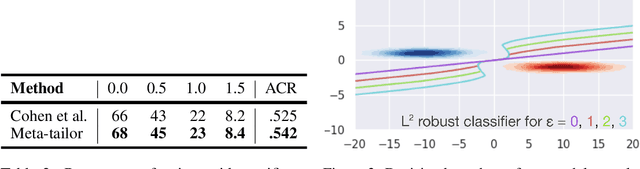
From CNNs to attention mechanisms, encoding inductive biases into neural networks has been a fruitful source of improvement in machine learning. Auxiliary losses are a general way of encoding biases in order to help networks learn better representations by adding extra terms to the loss function. However, since they are minimized on the training data, they suffer from the same generalization gap as regular task losses. Moreover, by changing the loss function, the network is optimizing a different objective than the one we care about. In this work we solve both problems: first, we take inspiration from \textit{transductive learning} and note that, after receiving an input but before making a prediction, we can fine-tune our models on any unsupervised objective. We call this process tailoring, because we customize the model to each input. Second, we formulate a nested optimization (similar to those in meta-learning) and train our models to perform well on the task loss after adapting to the tailoring loss. The advantages of tailoring and meta-tailoring are discussed theoretically and demonstrated empirically on several diverse examples: encoding inductive conservation laws from physics to improve predictions, improving local smoothness to increase robustness to adversarial examples, and using contrastive losses on the query image to improve generalization.