 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Somewhat Robust Image Watermark against Diffusion-based Editing Models
Dec 07, 2023
Recently, diffusion models (DMs) have become the state-of-the-art method for image synthesis. Editing models based on DMs, known for their high fidelity and precision, have inadvertently introduced new challenges related to image copyright infringement and malicious editing. Our work is the first to formalize and address this issue. After assessing and attempting to enhance traditional image watermarking techniques, we recognize their limitations in this emerging context. In response, we develop a novel technique, RIW (Robust Invisible Watermarking), to embed invisible watermarks leveraging adversarial example techniques. Our technique ensures a high extraction accuracy of $96\%$ for the invisible watermark after editing, compared to the $0\%$ offered by conventional methods. We provide access to our code at https://github.com/BennyTMT/RIW.
A Comprehensive Study of Vision Transformers in Image Classification Tasks
Dec 05, 2023
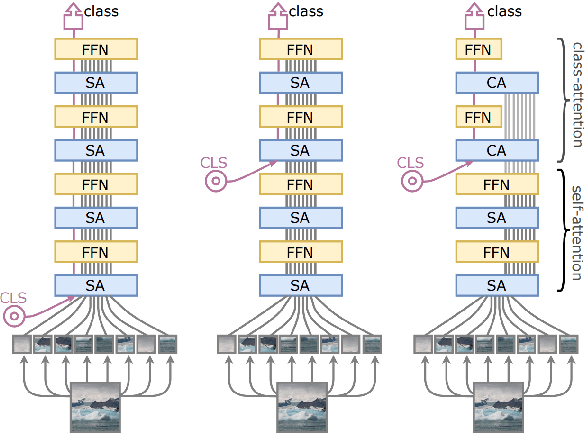
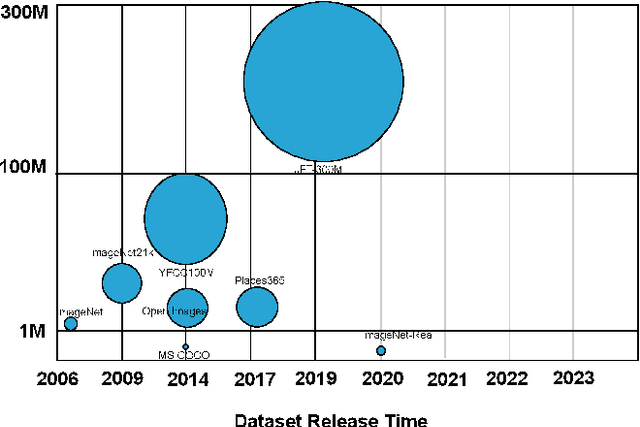
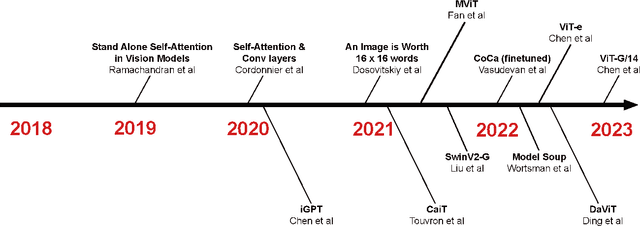
Image Classification is a fundamental task in the field of computer vision that frequently serves as a benchmark for gauging advancements in Computer Vision. Over the past few years, significant progress has been made in image classification due to the emergence of deep learning. However, challenges still exist, such as modeling fine-grained visual information, high computation costs, the parallelism of the model, and inconsistent evaluation protocols across datasets. In this paper, we conduct a comprehensive survey of existing papers on Vision Transformers for image classification. We first introduce the popular image classification datasets that influenced the design of models. Then, we present Vision Transformers models in chronological order, starting with early attempts at adapting attention mechanism to vision tasks followed by the adoption of vision transformers, as they have demonstrated success in capturing intricate patterns and long-range dependencies within images. Finally, we discuss open problems and shed light on opportunities for image classification to facilitate new research ideas.
CineMPC: A Fully Autonomous Drone Cinematography System Incorporating Zoom, Focus, Pose, and Scene Composition
Jan 10, 2024We present CineMPC, a complete cinematographic system that autonomously controls a drone to film multiple targets recording user-specified aesthetic objectives. Existing solutions in autonomous cinematography control only the camera extrinsics, namely its position, and orientation. In contrast, CineMPC is the first solution that includes the camera intrinsic parameters in the control loop, which are essential tools for controlling cinematographic effects like focus, depth-of-field, and zoom. The system estimates the relative poses between the targets and the camera from an RGB-D image and optimizes a trajectory for the extrinsic and intrinsic camera parameters to film the artistic and technical requirements specified by the user. The drone and the camera are controlled in a nonlinear Model Predicted Control (MPC) loop by re-optimizing the trajectory at each time step in response to current conditions in the scene. The perception system of CineMPC can track the targets' position and orientation despite the camera effects. Experiments in a photorealistic simulation and with a real platform demonstrate the capabilities of the system to achieve a full array of cinematographic effects that are not possible without the control of the intrinsics of the camera. Code for CineMPC is implemented following a modular architecture in ROS and released to the community.
Multi S-Graphs: an Efficient Real-time Distributed Semantic-Relational Collaborative SLAM
Jan 10, 2024Collaborative Simultaneous Localization and Mapping (CSLAM) is critical to enable multiple robots to operate in complex environments. Most CSLAM techniques rely on raw sensor measurement or low-level features such as keyframe descriptors, which can lead to wrong loop closures due to the lack of deep understanding of the environment. Moreover, the exchange of these measurements and low-level features among the robots requires the transmission of a significant amount of data, which limits the scalability of the system. To overcome these limitations, we present Multi S-Graphs, a decentralized CSLAM system that utilizes high-level semantic-relational information embedded in the four-layered hierarchical and optimizable situational graphs for cooperative map generation and localization while minimizing the information exchanged between the robots. To support this, we present a novel room-based descriptor which, along with its connected walls, is used to perform inter-robot loop closures, addressing the challenges of multi-robot kidnapped problem initialization. Multiple experiments in simulated and real environments validate the improvement in accuracy and robustness of the proposed approach while reducing the amount of data exchanged between robots compared to other state-of-the-art approaches. Software available within a docker image: https://github.com/snt-arg/multi_s_graphs_docker
REACT 2024: the Second Multiple Appropriate Facial Reaction Generation Challenge
Jan 10, 2024In dyadic interactions, humans communicate their intentions and state of mind using verbal and non-verbal cues, where multiple different facial reactions might be appropriate in response to a specific speaker behaviour. Then, how to develop a machine learning (ML) model that can automatically generate multiple appropriate, diverse, realistic and synchronised human facial reactions from an previously unseen speaker behaviour is a challenging task. Following the successful organisation of the first REACT challenge (REACT 2023), this edition of the challenge (REACT 2024) employs a subset used by the previous challenge, which contains segmented 30-secs dyadic interaction clips originally recorded as part of the NOXI and RECOLA datasets, encouraging participants to develop and benchmark Machine Learning (ML) models that can generate multiple appropriate facial reactions (including facial image sequences and their attributes) given an input conversational partner's stimulus under various dyadic video conference scenarios. This paper presents: (i) the guidelines of the REACT 2024 challenge; (ii) the dataset utilized in the challenge; and (iii) the performance of the baseline systems on the two proposed sub-challenges: Offline Multiple Appropriate Facial Reaction Generation and Online Multiple Appropriate Facial Reaction Generation, respectively. The challenge baseline code is publicly available at https://github.com/reactmultimodalchallenge/baseline_react2024.
Single Image Reflection Removal with Reflection Intensity Prior Knowledge
Dec 06, 2023Single Image Reflection Removal (SIRR) in real-world images is a challenging task due to diverse image degradations occurring on the glass surface during light transmission and reflection. Many existing methods rely on specific prior assumptions to resolve the problem. In this paper, we propose a general reflection intensity prior that captures the intensity of the reflection phenomenon and demonstrate its effectiveness. To learn the reflection intensity prior, we introduce the Reflection Prior Extraction Network (RPEN). By segmenting images into regional patches, RPEN learns non-uniform reflection prior in an image. We propose Prior-based Reflection Removal Network (PRRN) using a simple transformer U-Net architecture that adapts reflection prior fed from RPEN. Experimental results on real-world benchmarks demonstrate the effectiveness of our approach achieving state-of-the-art accuracy in SIRR.
Benchmark Analysis of Various Pre-trained Deep Learning Models on ASSIRA Cats and Dogs Dataset
Jan 09, 2024As the most basic application and implementation of deep learning, image classification has grown in popularity. Various datasets are provided by renowned data science communities for benchmarking machine learning algorithms and pre-trained models. The ASSIRA Cats & Dogs dataset is one of them and is being used in this research for its overall acceptance and benchmark standards. A comparison of various pre-trained models is demonstrated by using different types of optimizers and loss functions. Hyper-parameters are changed to gain the best result from a model. By applying this approach, we have got higher accuracy without major changes in the training model. To run the experiment, we used three different computer architectures: a laptop equipped with NVIDIA GeForce GTX 1070, a laptop equipped with NVIDIA GeForce RTX 3080Ti, and a desktop equipped with NVIDIA GeForce RTX 3090. The acquired results demonstrate supremacy in terms of accuracy over the previously done experiments on this dataset. From this experiment, the highest accuracy which is 99.65% is gained using the NASNet Large.
Learning to Prompt Segment Anything Models
Jan 09, 2024Segment Anything Models (SAMs) like SEEM and SAM have demonstrated great potential in learning to segment anything. The core design of SAMs lies with Promptable Segmentation, which takes a handcrafted prompt as input and returns the expected segmentation mask. SAMs work with two types of prompts including spatial prompts (e.g., points) and semantic prompts (e.g., texts), which work together to prompt SAMs to segment anything on downstream datasets. Despite the important role of prompts, how to acquire suitable prompts for SAMs is largely under-explored. In this work, we examine the architecture of SAMs and identify two challenges for learning effective prompts for SAMs. To this end, we propose spatial-semantic prompt learning (SSPrompt) that learns effective semantic and spatial prompts for better SAMs. Specifically, SSPrompt introduces spatial prompt learning and semantic prompt learning, which optimize spatial prompts and semantic prompts directly over the embedding space and selectively leverage the knowledge encoded in pre-trained prompt encoders. Extensive experiments show that SSPrompt achieves superior image segmentation performance consistently across multiple widely adopted datasets.
Memory-Efficient Personalization using Quantized Diffusion Model
Jan 09, 2024The rise of billion-parameter diffusion models like Stable Diffusion XL, Imagen, and Dall-E3 markedly advances the field of generative AI. However, their large-scale nature poses challenges in fine-tuning and deployment due to high resource demands and slow inference speed. This paper ventures into the relatively unexplored yet promising realm of fine-tuning quantized diffusion models. We establish a strong baseline by customizing three models: PEQA for fine-tuning quantization parameters, Q-Diffusion for post-training quantization, and DreamBooth for personalization. Our analysis reveals a notable trade-off between subject and prompt fidelity within the baseline model. To address these issues, we introduce two strategies, inspired by the distinct roles of different timesteps in diffusion models: S1 optimizing a single set of fine-tuning parameters exclusively at selected intervals, and S2 creating multiple fine-tuning parameter sets, each specialized for different timestep intervals. Our approach not only enhances personalization but also upholds prompt fidelity and image quality, significantly outperforming the baseline qualitatively and quantitatively. The code will be made publicly available.
Empirical Analysis of Anomaly Detection on Hyperspectral Imaging Using Dimension Reduction Methods
Jan 09, 2024Recent studies try to use hyperspectral imaging (HSI) to detect foreign matters in products because it enables to visualize the invisible wavelengths including ultraviolet and infrared. Considering the enormous image channels of the HSI, several dimension reduction methods-e.g., PCA or UMAP-can be considered to reduce but those cannot ease the fundamental limitations, as follows: (1) latency of HSI capturing. (2) less explanation ability of the important channels. In this paper, to circumvent the aforementioned methods, one of the ways to channel reduction, on anomaly detection proposed HSI. Different from feature extraction methods (i.e., PCA or UMAP), feature selection can sort the feature by impact and show better explainability so we might redesign the task-optimized and cost-effective spectroscopic camera. Via the extensive experiment results with synthesized MVTec AD dataset, we confirm that the feature selection method shows 6.90x faster at the inference phase compared with feature extraction-based approaches while preserving anomaly detection performance. Ultimately, we conclude the advantage of feature selection which is effective yet fast.