 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AvatarMe: Realistically Renderable 3D Facial Reconstruction "in-the-wild"
Mar 30, 2020
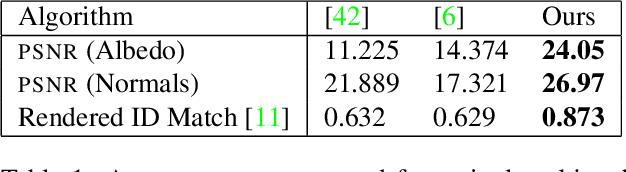


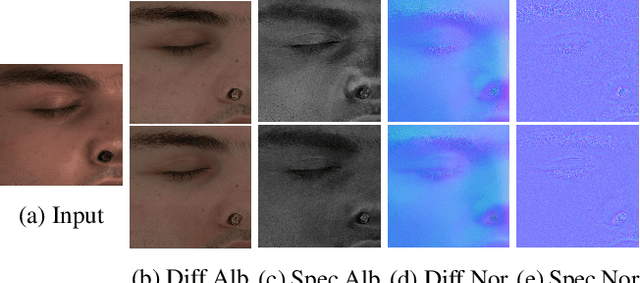
Over the last years, with the advent of Generative Adversarial Networks (GANs), many face analysis tasks have accomplished astounding performance, with applications including, but not limited to, face generation and 3D face reconstruction from a single "in-the-wild" image. Nevertheless, to the best of our knowledge, there is no method which can produce high-resolution photorealistic 3D faces from "in-the-wild" images and this can be attributed to the: (a) scarcity of available data for training, and (b) lack of robust methodologies that can successfully be applied on very high-resolution data. In this paper, we introduce AvatarMe, the first method that is able to reconstruct photorealistic 3D faces from a single "in-the-wild" image with an increasing level of detail. To achieve this, we capture a large dataset of facial shape and reflectance and build on a state-of-the-art 3D texture and shape reconstruction method and successively refine its results, while generating the per-pixel diffuse and specular components that are required for realistic rendering. As we demonstrate in a series of qualitative and quantitative experiments, AvatarMe outperforms the existing arts by a significant margin and reconstructs authentic, 4K by 6K-resolution 3D faces from a single low-resolution image that, for the first time, bridges the uncanny valley.
Designing Effective Inter-Pixel Information Flow for Natural Image Matting
Jul 17, 2017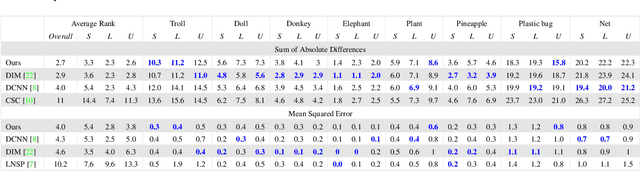


We present a novel, purely affinity-based natural image matting algorithm. Our method relies on carefully defined pixel-to-pixel connections that enable effective use of information available in the image. We control the information flow from the known-opacity regions into the unknown region, as well as within the unknown region itself, by utilizing multiple definitions of pixel affinities. Among other forms of information flow, we introduce color-mixture flow, which builds upon local linear embedding and effectively encapsulates the relation between different pixel opacities. Our resulting novel linear system formulation can be solved in closed-form and is robust against several fundamental challenges of natural matting such as holes and remote intricate structures. Our evaluation using the alpha matting benchmark suggests a significant performance improvement over the current methods. While our method is primarily designed as a standalone matting tool, we show that it can also be used for regularizing mattes obtained by sampling-based methods. We extend our formulation to layer color estimation and show that the use of multiple channels of flow increases the layer color quality. We also demonstrate our performance in green-screen keying and further analyze the characteristics of the affinities used in our method.
Semantic Image Based Geolocation Given a Map
Sep 01, 2016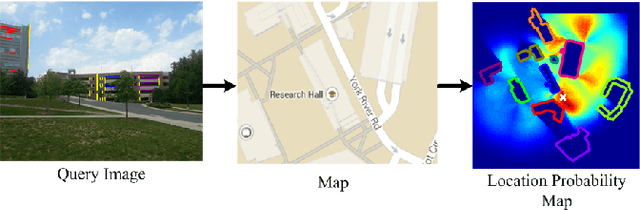
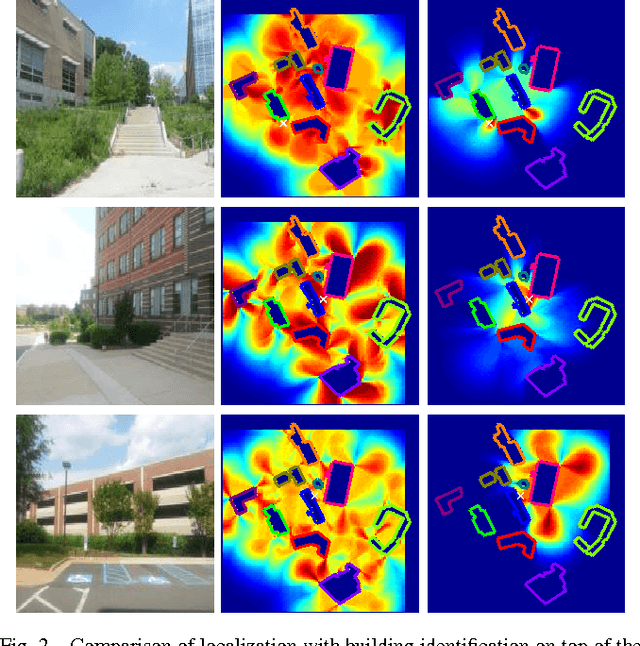
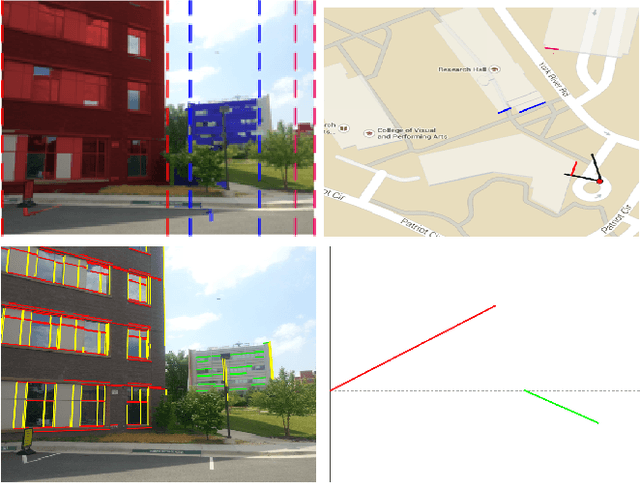
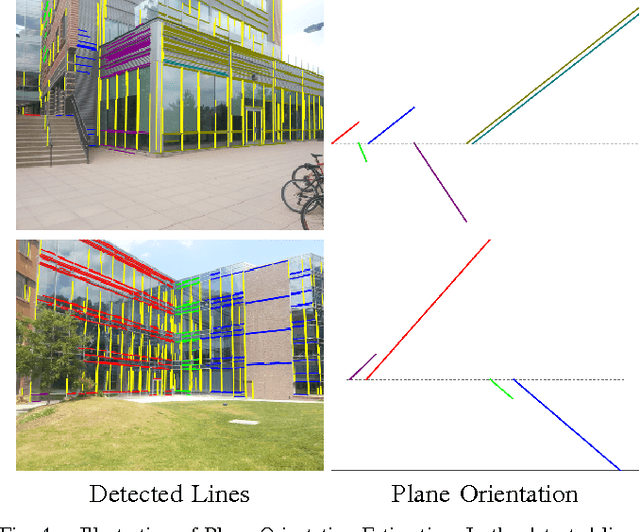
The problem visual place recognition is commonly used strategy for localization. Most successful appearance based methods typically rely on a large database of views endowed with local or global image descriptors and strive to retrieve the views of the same location. The quality of the results is often affected by the density of the reference views and the robustness of the image representation with respect to viewpoint variations, clutter and seasonal changes. In this work we present an approach for geo-locating a novel view and determining camera location and orientation using a map and a sparse set of geo-tagged reference views. We propose a novel technique for detection and identification of building facades from geo-tagged reference view using the map and geometry of the building facades. We compute the likelihood of camera location and orientation of the query images using the detected landmark (building) identities from reference views, 2D map of the environment, and geometry of building facades. We evaluate our approach for building identification and geo-localization on a new challenging outdoors urban dataset exhibiting large variations in appearance and viewpoint.
Generative Adversarial Image Synthesis with Decision Tree Latent Controller
May 27, 2018
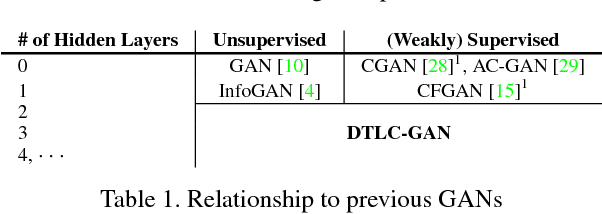

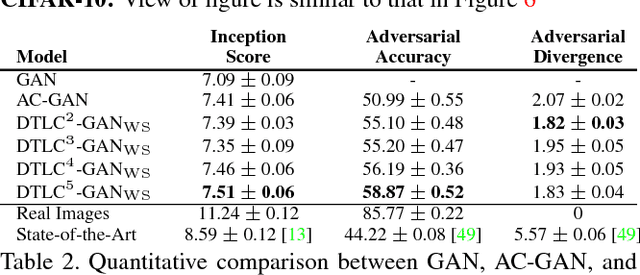
This paper proposes the decision tree latent controller generative adversarial network (DTLC-GAN), an extension of a GAN that can learn hierarchically interpretable representations without relying on detailed supervision. To impose a hierarchical inclusion structure on latent variables, we incorporate a new architecture called the DTLC into the generator input. The DTLC has a multiple-layer tree structure in which the ON or OFF of the child node codes is controlled by the parent node codes. By using this architecture hierarchically, we can obtain the latent space in which the lower layer codes are selectively used depending on the higher layer ones. To make the latent codes capture salient semantic features of images in a hierarchically disentangled manner in the DTLC, we also propose a hierarchical conditional mutual information regularization and optimize it with a newly defined curriculum learning method that we propose as well. This makes it possible to discover hierarchically interpretable representations in a layer-by-layer manner on the basis of information gain by only using a single DTLC-GAN model. We evaluated the DTLC-GAN on various datasets, i.e., MNIST, CIFAR-10, Tiny ImageNet, 3D Faces, and CelebA, and confirmed that the DTLC-GAN can learn hierarchically interpretable representations with either unsupervised or weakly supervised settings. Furthermore, we applied the DTLC-GAN to image-retrieval tasks and showed its effectiveness in representation learning.
Overcoming Statistical Shortcuts for Open-ended Visual Counting
Jul 01, 2020



Machine learning models tend to over-rely on statistical shortcuts. These spurious correlations between parts of the input and the output labels does not hold in real-world settings. We target this issue on the recent open-ended visual counting task which is well suited to study statistical shortcuts. We aim to develop models that learn a proper mechanism of counting regardless of the output label. First, we propose the Modifying Count Distribution (MCD) protocol, which penalizes models that over-rely on statistical shortcuts. It is based on pairs of training and testing sets that do not follow the same count label distribution such as the odd-even sets. Intuitively, models that have learned a proper mechanism of counting on odd numbers should perform well on even numbers. Secondly, we introduce the Spatial Counting Network (SCN), which is dedicated to visual analysis and counting based on natural language questions. Our model selects relevant image regions, scores them with fusion and self-attention mechanisms, and provides a final counting score. We apply our protocol on the recent dataset, TallyQA, and show superior performances compared to state-of-the-art models. We also demonstrate the ability of our model to select the correct instances to count in the image. Code and datasets are available: https://github.com/cdancette/spatial-counting-network
Considerations for a PAP Smear Image Analysis System with CNN Features
Jun 23, 2018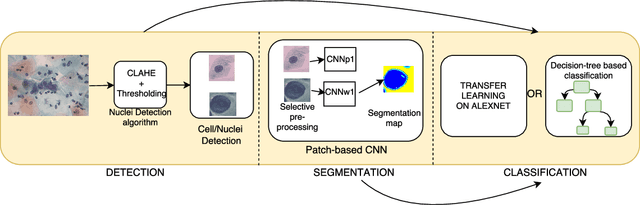

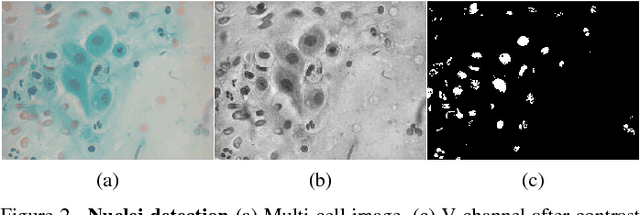
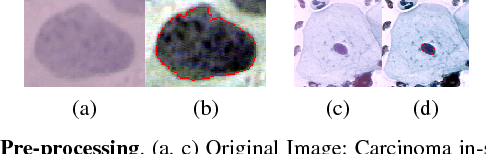
It has been shown that for automated PAP-smear image classification, nucleus features can be very informative. Therefore, the primary step for automated screening can be cell-nuclei detection followed by segmentation of nuclei in the resulting single cell PAP-smear images. We propose a patch based approach using CNN for segmentation of nuclei in single cell images. We then pose the question of ion of segmentation for classification using representation learning with CNN, and whether low-level CNN features may be useful for classification. We suggest a CNN-based feature level analysis and a transfer learning based approach for classification using both segmented as well full single cell images. We also propose a decision-tree based approach for classification. Experimental results demonstrate the effectiveness of the proposed algorithms individually (with low-level CNN features), and simultaneously proving the sufficiency of cell-nuclei detection (rather than accurate segmentation) for classification. Thus, we propose a system for analysis of multi-cell PAP-smear images consisting of a simple nuclei detection algorithm followed by classification using transfer learning.
Ranky : An Approach to Solve Distributed SVD on Large Sparse Matrices
Sep 21, 2020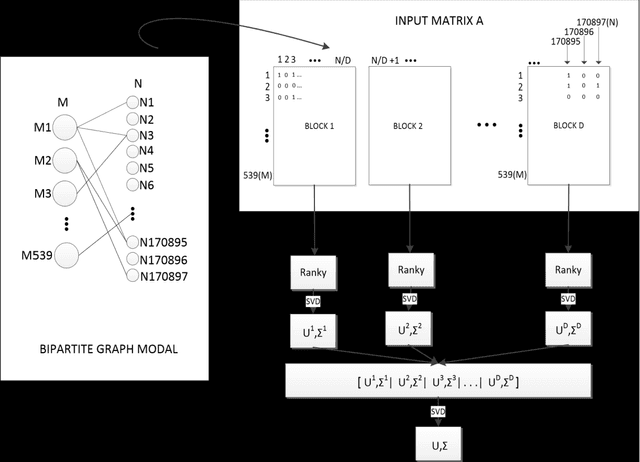
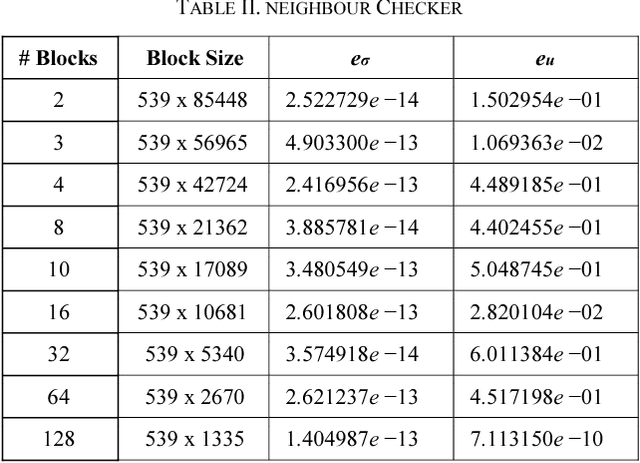
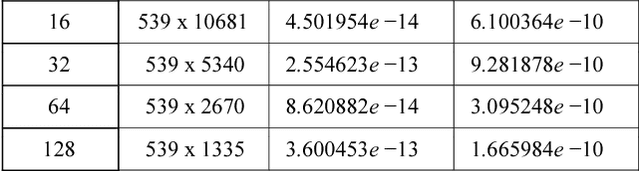
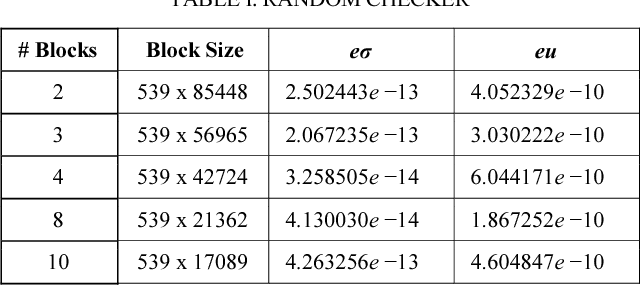
Singular Value Decomposition (SVD) is a well studied research topic in many fields and applications from data mining to image processing. Data arising from these applications can be represented as a matrix where it is large and sparse. Most existing algorithms are used to calculate singular values, left and right singular vectors of a large-dense matrix but not large and sparse matrix. Even if they can find SVD of a large matrix, calculation of large-dense matrix has high time complexity due to sequential algorithms. Distributed approaches are proposed for computing SVD of large matrices. However, rank of the matrix is still being a problem when solving SVD with these distributed algorithms. In this paper we propose Ranky, set of methods to solve rank problem on large and sparse matrices in a distributed manner. Experimental results show that the Ranky approach recovers singular values, singular left and right vectors of a given large and sparse matrix with negligible error.
Captioning Images Taken by People Who Are Blind
Feb 20, 2020
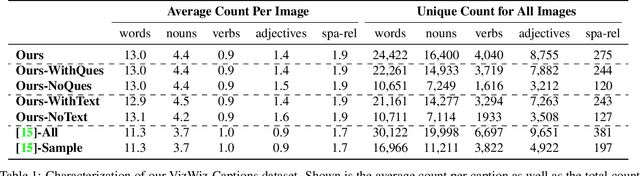
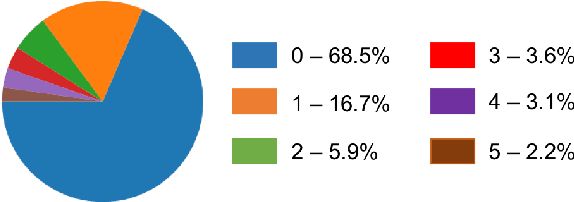
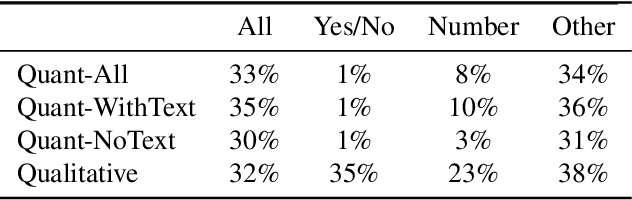
While an important problem in the vision community is to design algorithms that can automatically caption images, few publicly-available datasets for algorithm development directly address the interests of real users. Observing that people who are blind have relied on (human-based) image captioning services to learn about images they take for nearly a decade, we introduce the first image captioning dataset to represent this real use case. This new dataset, which we call VizWiz-Captions, consists of over 39,000 images originating from people who are blind that are each paired with five captions. We analyze this dataset to (1) characterize the typical captions, (2) characterize the diversity of content found in the images, and (3) compare its content to that found in eight popular vision datasets. We also analyze modern image captioning algorithms to identify what makes this new dataset challenging for the vision community. We publicly-share the dataset with captioning challenge instructions at https://vizwiz.org
Robust Semantic Segmentation in Adverse Weather Conditions by means of Fast Video-Sequence Segmentation
Jul 01, 2020
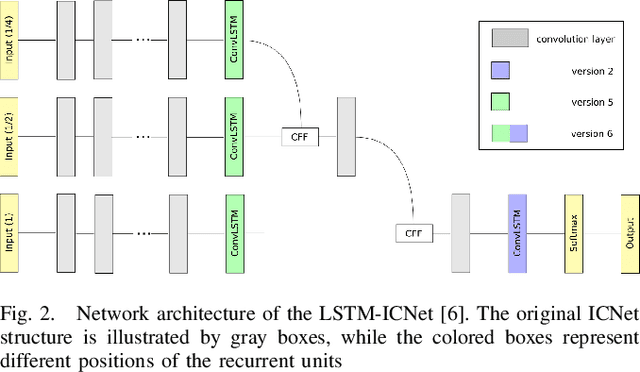
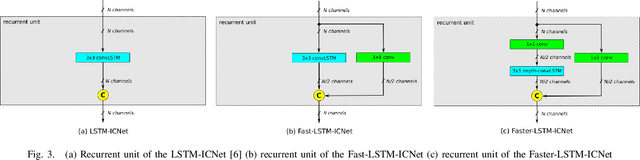
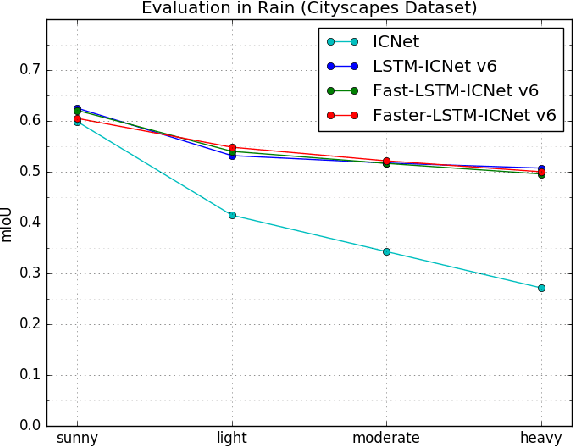
Computer vision tasks such as semantic segmentation perform very well in good weather conditions, but if the weather turns bad, they have problems to achieve this performance in these conditions. One possibility to obtain more robust and reliable results in adverse weather conditions is to use video-segmentation approaches instead of commonly used single-image segmentation methods. Video-segmentation approaches capture temporal information of the previous video-frames in addition to current image information, and hence, they are more robust against disturbances, especially if they occur in only a few frames of the video-sequence. However, video-segmentation approaches, which are often based on recurrent neural networks, cannot be applied in real-time applications anymore, since their recurrent structures in the network are computational expensive. For instance, the inference time of the LSTM-ICNet, in which recurrent units are placed at proper positions in the single-segmentation approach ICNet, increases up to 61 percent compared to the basic ICNet. Hence, in this work, the LSTM-ICNet is sped up by modifying the recurrent units of the network so that it becomes real-time capable again. Experiments on different datasets and various weather conditions show that the inference time can be decreased by about 23 percent by these modifications, while they achieve similar performance than the LSTM-ICNet and outperform the single-segmentation approach enormously in adverse weather conditions.
LadderNet: Multi-path networks based on U-Net for medical image segmentation
Oct 27, 2018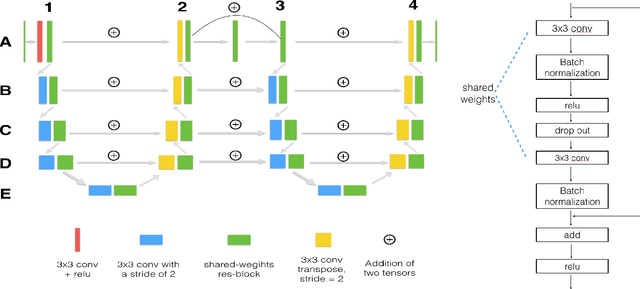
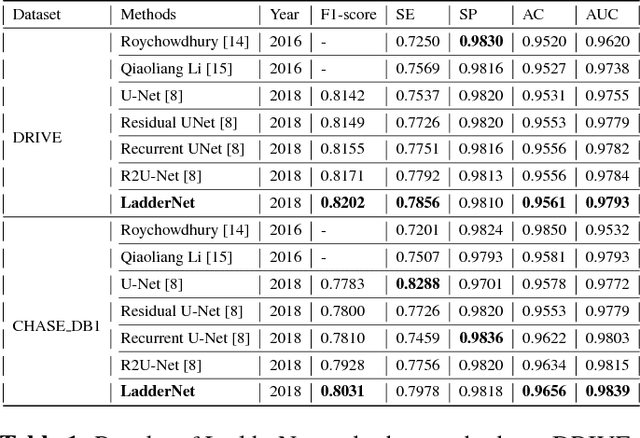
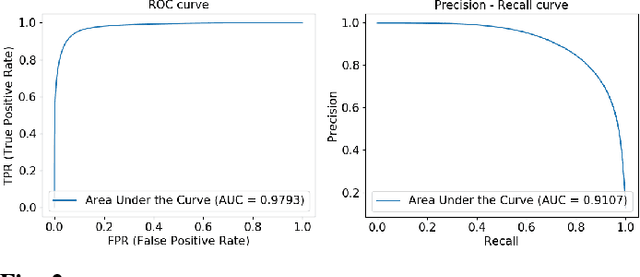
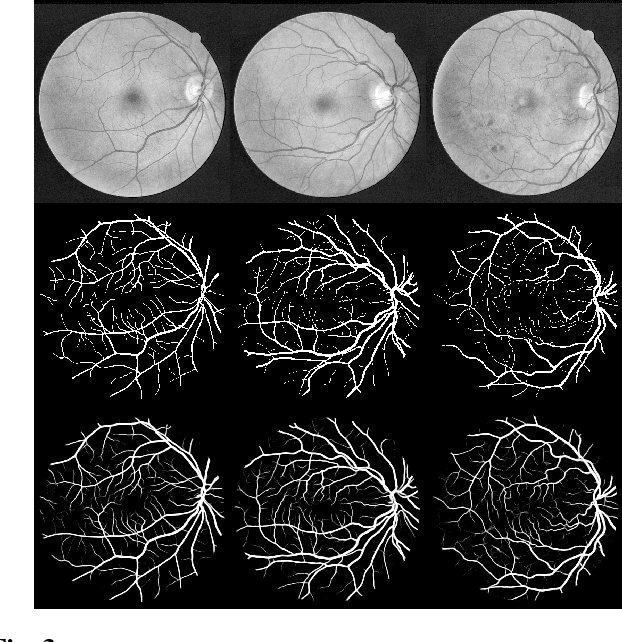
U-Net has been providing state-of-the-art performance in many medical image segmentation problems. Many modifications have been proposed for U-Net, such as attention U-Net, recurrent residual convolutional U-Net (R2-UNet), and U-Net with residual blocks or blocks with dense connections. However, all these modifications have an encoder-decoder structure with skip connections, and the number of paths for information flow is limited. We propose LadderNet in this paper, which can be viewed as a chain of multiple U-Nets. Instead of only one pair of encoder branch and decoder branch in U-Net, a LadderNet has multiple pairs of encoder-decoder branches, and has skip connections between every pair of adjacent decoder and decoder branches in each level. Inspired by the success of ResNet and R2-UNet, we use modified residual blocks where two convolutional layers in one block share the same weights. A LadderNet has more paths for information flow because of skip connections and residual blocks, and can be viewed as an ensemble of Fully Convolutional Networks (FCN). The equivalence to an ensemble of FCNs improves segmentation accuracy, while the shared weights within each residual block reduce parameter number. Semantic segmentation is essential for retinal disease detection. We tested LadderNet on two benchmark datasets for blood vessel segmentation in retinal images, and achieved superior performance over methods in the literature.