 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Residual 3D U-Net for Joint Segmentation and Texture Classification of Nodules in Lung
Jun 25, 2020
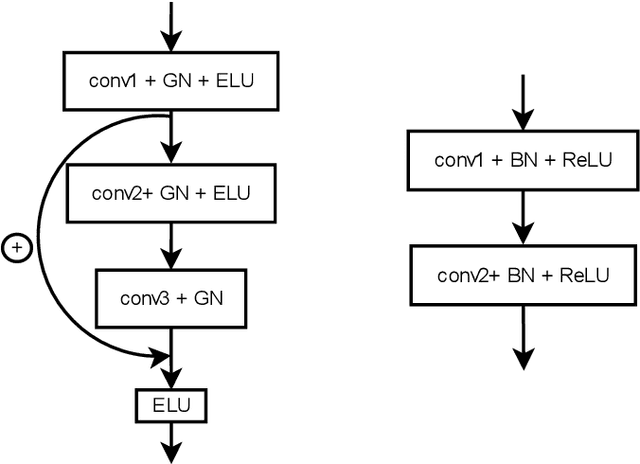
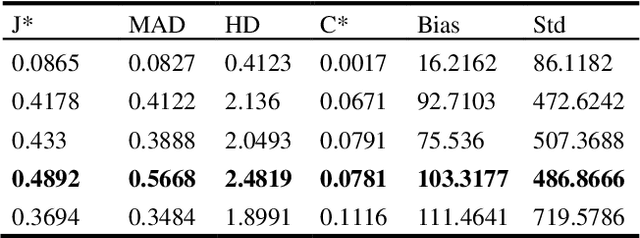
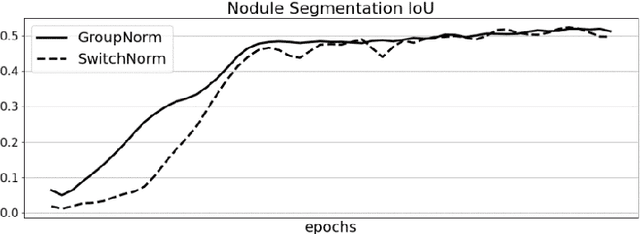
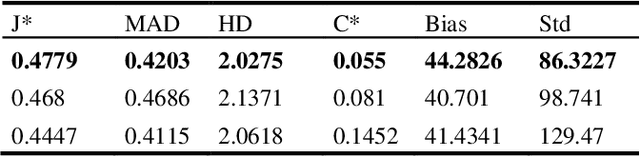
In this work we present a method for lung nodules segmentation, their texture classification and subsequent follow-up recommendation from the CT image of lung. Our method consists of neural network model based on popular U-Net architecture family but modified for the joint nodule segmentation and its texture classification tasks and an ensemble-based model for the fol-low-up recommendation. This solution was evaluated within the LNDb 2020 medical imaging challenge and produced the best nodule segmentation result on the final leaderboard.
* 10 pages, 5 figures, 2 tables, accepted for publication at ICIAR 2020(LNDb Grand Challenge)
ROSE: A Retinal OCT-Angiography Vessel Segmentation Dataset and New Model
Jul 10, 2020
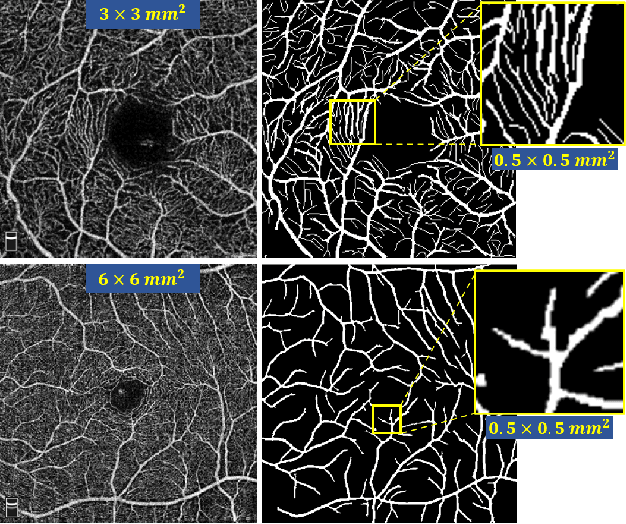
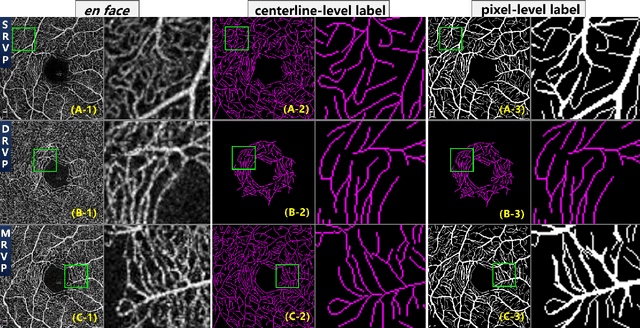
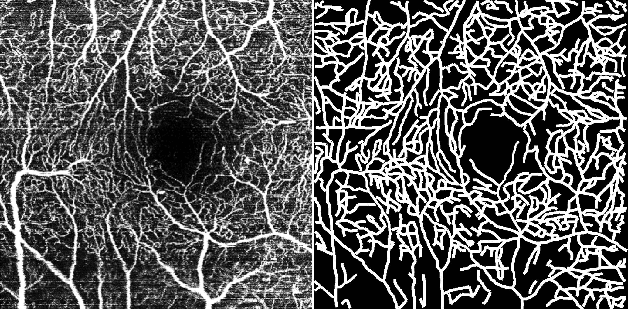
Optical Coherence Tomography Angiography (OCT-A) is a non-invasive imaging technique, and has been increasingly used to image the retinal vasculature at capillary level resolution. However, automated segmentation of retinal vessels in OCT-A has been under-studied due to various challenges such as low capillary visibility and high vessel complexity, despite its significance in understanding many eye-related diseases. In addition, there is no publicly available OCT-A dataset with manually graded vessels for training and validation. To address these issues, for the first time in the field of retinal image analysis we construct a dedicated Retinal OCT-A SEgmentation dataset (ROSE), which consists of 229 OCT-A images with vessel annotations at either centerline-level or pixel level. This dataset has been released for public access to assist researchers in the community in undertaking research in related topics. Secondly, we propose a novel Split-based Coarse-to-Fine vessel segmentation network (SCF-Net), with the ability to detect thick and thin vessels separately. In the SCF-Net, a split-based coarse segmentation (SCS) module is first introduced to produce a preliminary confidence map of vessels, and a split-based refinement (SRN) module is then used to optimize the shape/contour of the retinal microvasculature. Thirdly, we perform a thorough evaluation of the state-of-the-art vessel segmentation models and our SCF-Net on the proposed ROSE dataset. The experimental results demonstrate that our SCF-Net yields better vessel segmentation performance in OCT-A than both traditional methods and other deep learning methods.
Q-FIT: The Quantifiable Feature Importance Technique for Explainable Machine Learning
Oct 26, 2020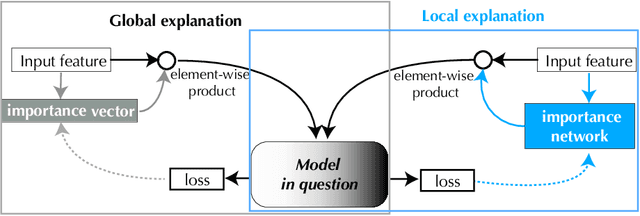
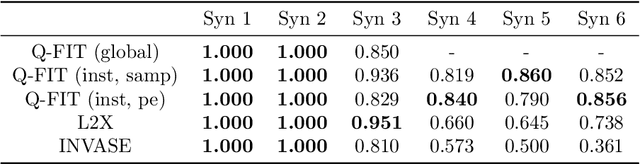
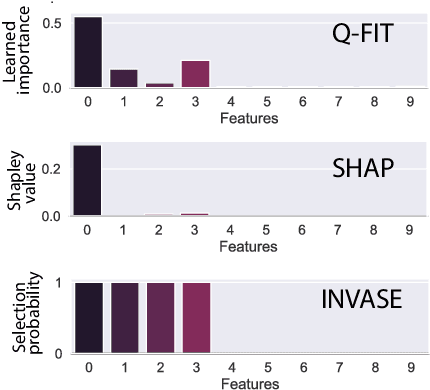

We introduce a novel framework to quantify the importance of each input feature for model explainability. A user of our framework can choose between two modes: (a) global explanation: providing feature importance globally across all the data points; and (b) local explanation: providing feature importance locally for each individual data point. The core idea of our method comes from utilizing the Dirichlet distribution to define a distribution over the importance of input features. This particular distribution is useful in ranking the importance of the input features as a sample from this distribution is a probability vector (i.e., the vector components sum to 1), Thus, the ranking uncovered by our framework which provides a \textit{quantifiable explanation} of how significant each input feature is to a model's output. This quantifiable explainability differentiates our method from existing feature-selection methods, which simply determine whether a feature is relevant or not. Furthermore, a distribution over the explanation allows to define a closed-form divergence to measure the similarity between learned feature importance under different models. We use this divergence to study how the feature importance trade-offs with essential notions in modern machine learning, such as privacy and fairness. We show the effectiveness of our method on a variety of synthetic and real datasets, taking into account both tabular and image datasets.
Peak Detection On Data Independent Acquisition Mass Spectrometry Data With Semisupervised Convolutional Transformers
Oct 26, 2020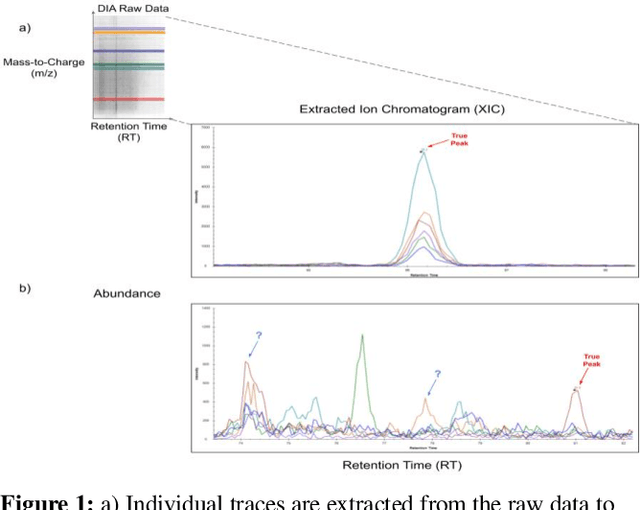

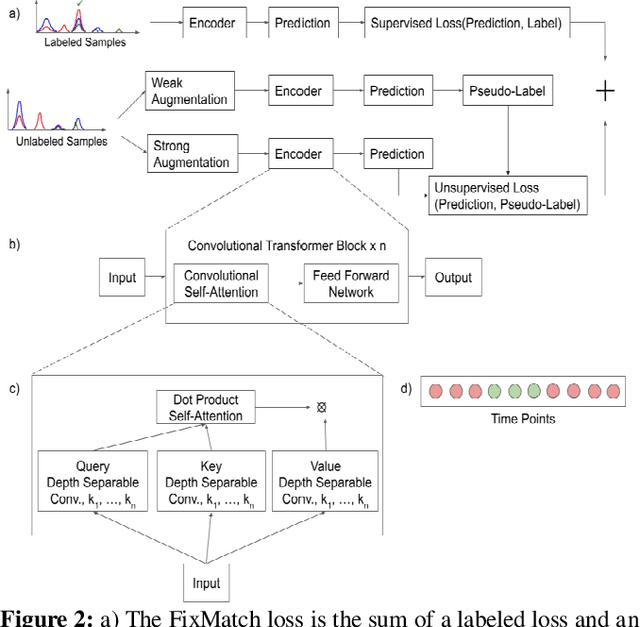

Liquid Chromatography coupled to Mass Spectrometry (LC-MS) based methods are commonly used for high-throughput, quantitative measurements of the proteome (i.e. the set of all proteins in a sample at a given time). Targeted LC-MS produces data in the form of a two-dimensional time series spectrum, with the mass to charge ratio of analytes (m/z) on one axis, and the retention time from the chromatography on the other. The elution of a peptide of interest produces highly specific patterns across multiple fragment ion traces (extracted ion chromatograms, or XICs). In this paper, we formulate this peak detection problem as a multivariate time series segmentation problem, and propose a novel approach based on the Transformer architecture. Here we augment Transformers, which are capable of capturing long distance dependencies with a global view, with Convolutional Neural Networks (CNNs), which can capture local context important to the task at hand, in the form of Transformers with Convolutional Self-Attention. We further train this model in a semisupervised manner by adapting state of the art semisupervised image classification techniques for multi-channel time series data. Experiments on a representative LC-MS dataset are benchmarked using manual annotations to showcase the encouraging performance of our method; it outperforms baseline neural network architectures and is competitive against the current state of the art in automated peak detection.
Constrained Dominant sets and Its applications in computer vision
Feb 12, 2020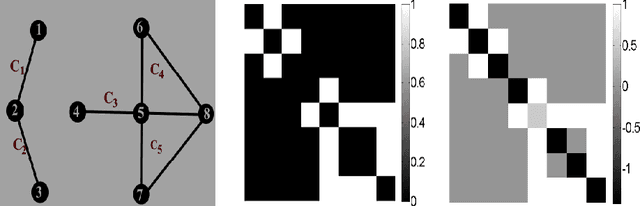

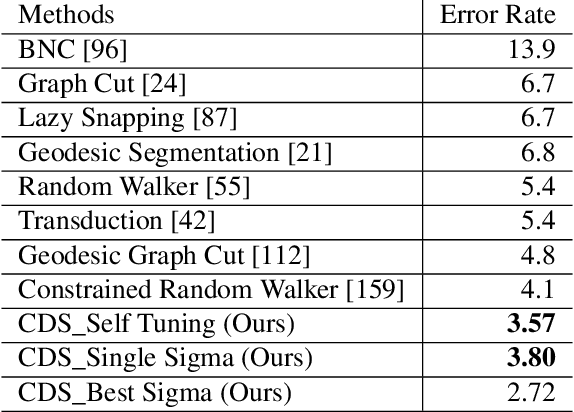
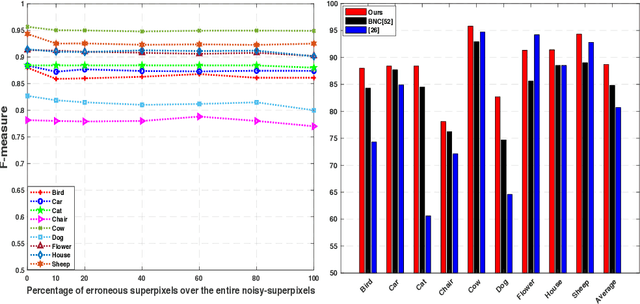
In this thesis, we present new schemes which leverage a constrained clustering method to solve several computer vision tasks ranging from image retrieval, image segmentation and co-segmentation, to person re-identification. In the last decades clustering methods have played a vital role in computer vision applications; herein, we focus on the extension, reformulation, and integration of a well-known graph and game theoretic clustering method known as Dominant Sets. Thus, we have demonstrated the validity of the proposed methods with extensive experiments which are conducted on several benchmark datasets.
Double-sided probing by map of Asplund's distances using Logarithmic Image Processing in the framework of Mathematical Morphology
Jan 25, 2018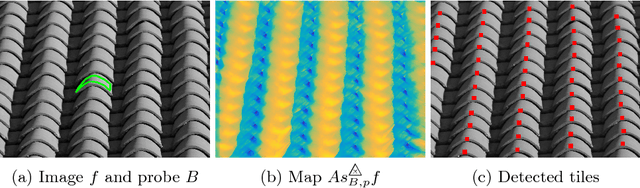
We establish the link between Mathematical Morphology and the map of Asplund's distances between a probe and a grey scale function, using the Logarithmic Image Processing scalar multiplication. We demonstrate that the map is the logarithm of the ratio between a dilation and an erosion of the function by a structuring function: the probe. The dilations and erosions are mappings from the lattice of the images into the lattice of the positive functions. Using a flat structuring element, the expression of the map of Asplund's distances can be simplified with a dilation and an erosion of the image; these mappings stays in the lattice of the images. We illustrate our approach by an example of pattern matching with a non-flat structuring function.
* The final publication is available at link.springer.com
Image denoising based on improved data-driven sparse representation
Mar 01, 2016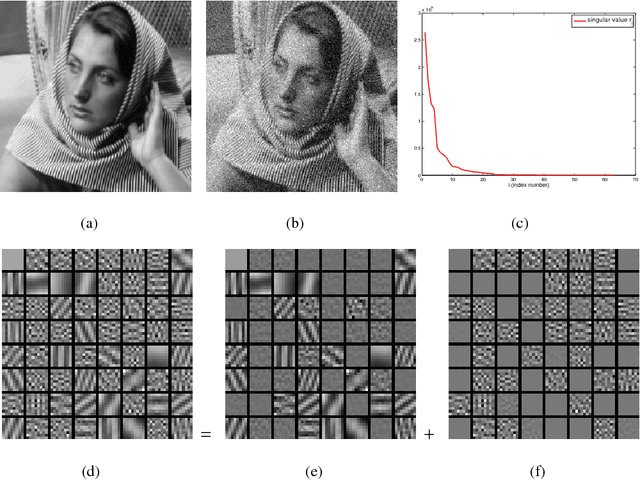


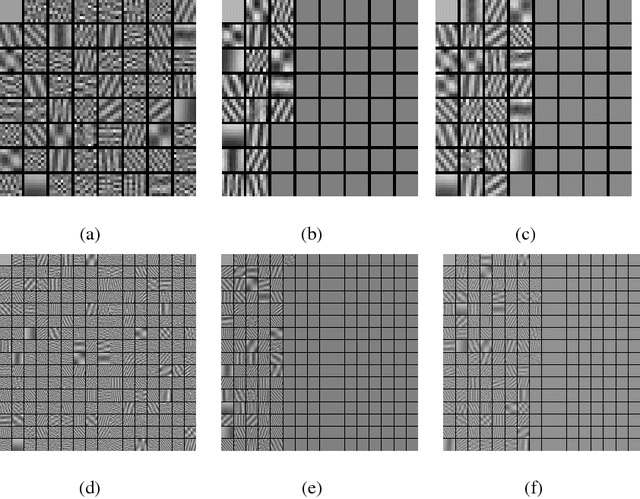
Sparse representation of images under certain transform domain has been playing a fundamental role in image restoration tasks. One such representative method is the widely used wavelet tight frame systems. Instead of adopting fixed filters for constructing a tight frame to sparsely model any input image, a data-driven tight frame was proposed for the sparse representation of images, and shown to be very efficient for image denoising very recently. However, in this method the number of framelet filters used for constructing a tight frame is the same as the length of filters. In fact, through further investigation it is found that part of these filters are unnecessary and even harmful to the recovery effect due to the influence of noise. Therefore, an improved data-driven sparse representation systems constructed with much less number of filters are proposed. Numerical results on denoising experiments demonstrate that the proposed algorithm overall outperforms the original data-driven tight frame construction scheme on both the recovery quality and computational time.
A Baseline for Few-Shot Image Classification
Sep 06, 2019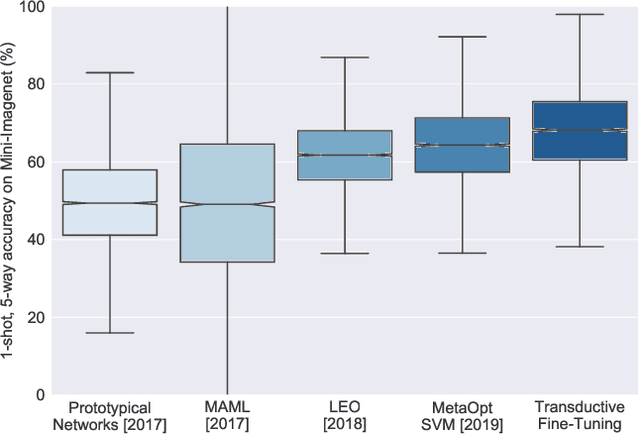
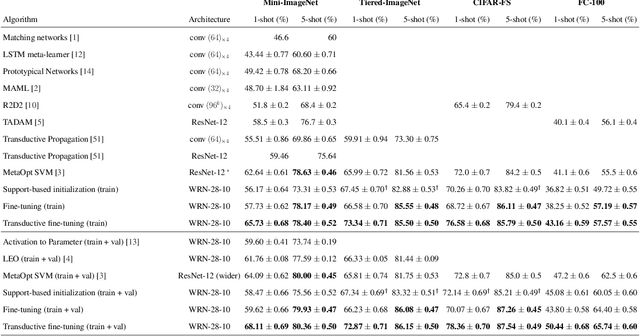

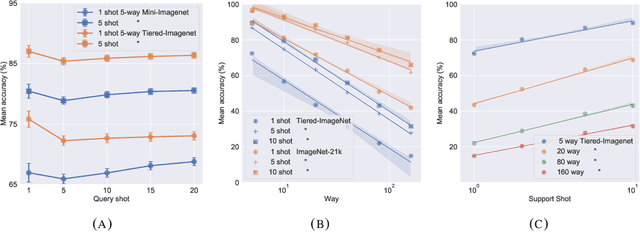
Fine-tuning a deep network trained with the standard cross-entropy loss is a strong baseline for few-shot learning. When fine-tuned transductively, this outperforms the current state-of-the-art on standard datasets such as Mini-Imagenet, Tiered-Imagenet, CIFAR-FS and FC-100 with the same hyper-parameters. The simplicity of this approach enables us to demonstrate the first few-shot learning results on the Imagenet-21k dataset. We find that using a large number of meta-training classes results in high few-shot accuracies even for a large number of test classes. We do not advocate our approach as the solution for few-shot learning, but simply use the results to highlight limitations of current benchmarks and few-shot protocols. We perform extensive studies on benchmark datasets to propose a metric that quantifies the "hardness" of a test episode. This metric can be used to report the performance of few-shot algorithms in a more systematic way.
Detecting Dominant Vanishing Points in Natural Scenes with Application to Composition-Sensitive Image Retrieval
May 13, 2017

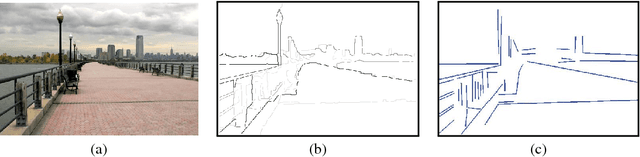
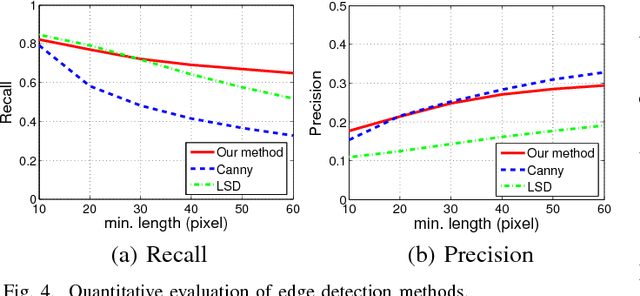
Linear perspective is widely used in landscape photography to create the impression of depth on a 2D photo. Automated understanding of linear perspective in landscape photography has several real-world applications, including aesthetics assessment, image retrieval, and on-site feedback for photo composition, yet adequate automated understanding has been elusive. We address this problem by detecting the dominant vanishing point and the associated line structures in a photo. However, natural landscape scenes pose great technical challenges because often the inadequate number of strong edges converging to the dominant vanishing point is inadequate. To overcome this difficulty, we propose a novel vanishing point detection method that exploits global structures in the scene via contour detection. We show that our method significantly outperforms state-of-the-art methods on a public ground truth landscape image dataset that we have created. Based on the detection results, we further demonstrate how our approach to linear perspective understanding provides on-site guidance to amateur photographers on their work through a novel viewpoint-specific image retrieval system.
Sky detection and log illumination refinement for PDE-based hazy image contrast enhancement
Mar 10, 2018
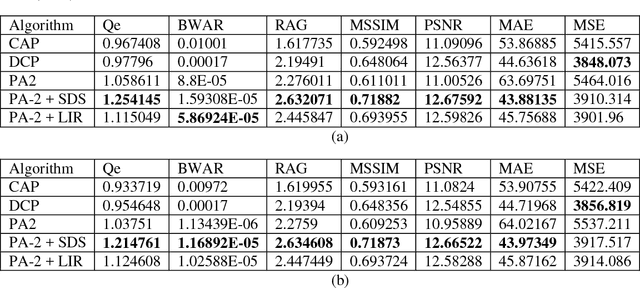
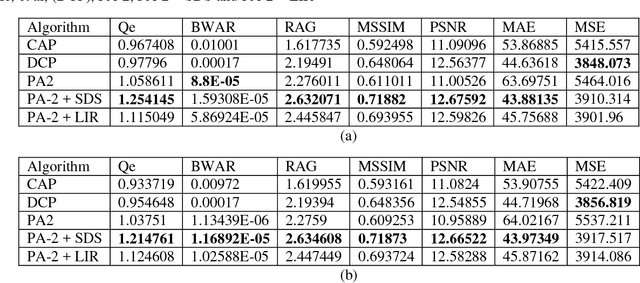
This report presents the results of a sky detection technique used to improve the performance of a previously developed partial differential equation (PDE)-based hazy image enhancement algorithm. Additionally, a proposed alternative method utilizes a function for log illumination refinement to improve de-hazing results while avoiding over-enhancement of sky or homogeneous regions. The algorithms were tested with several benchmark and calibration images and compared with several standard algorithms from the literature. Results indicate that the algorithms yield mostly consistent results and surpasses several of the other algorithms in terms of colour and contrast enhancement in addition to improved edge visibility.