 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Sparse Graph Laplacian with $K$ Eigenvector Prior via Iterative GLASSO and Projection
Oct 25, 2020

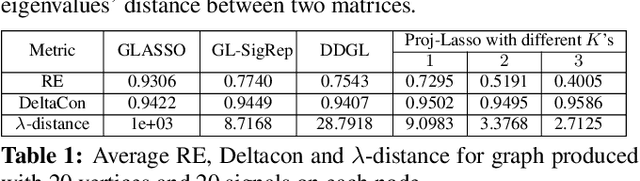
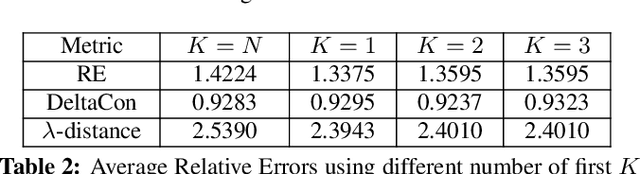
Learning a suitable graph is an important precursor to many graph signal processing (GSP) pipelines, such as graph spectral signal compression and denoising. Previous graph learning algorithms either i) make some assumptions on connectivity (e.g., graph sparsity), or ii) make simple graph edge assumptions such as positive edges only. In this paper, given an empirical covariance matrix $\bar{C}$ computed from data as input, we consider a structural assumption on the graph Laplacian matrix $L$: the first $K$ eigenvectors of $L$ are pre-selected, e.g., based on domain-specific criteria, such as computation requirement, and the remaining eigenvectors are then learned from data. One example use case is image coding, where the first eigenvector is pre-chosen to be constant, regardless of available observed data. We first prove that the subspace of symmetric positive semi-definite (PSD) matrices $H_{u}^+$ with the first $K$ eigenvectors being $\{u_k\}$ in a defined Hilbert space is a convex cone. We then construct an operator to project a given positive definite (PD) matrix $L$ to $H_{u}^+$, inspired by the Gram-Schmidt procedure. Finally, we design an efficient hybrid graphical lasso/projection algorithm to compute the most suitable graph Laplacian matrix $L^* \in H_{u}^+$ given $\bar{C}$. Experimental results show that given the first $K$ eigenvectors as a prior, our algorithm outperforms competing graph learning schemes using a variety of graph comparison metrics.
A Baseline for Few-Shot Image Classification
Sep 06, 2019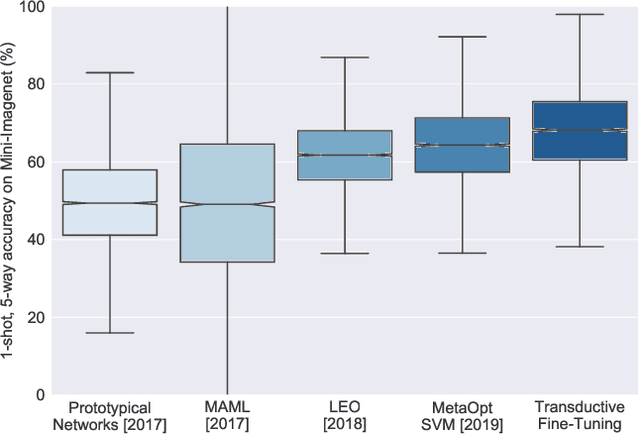
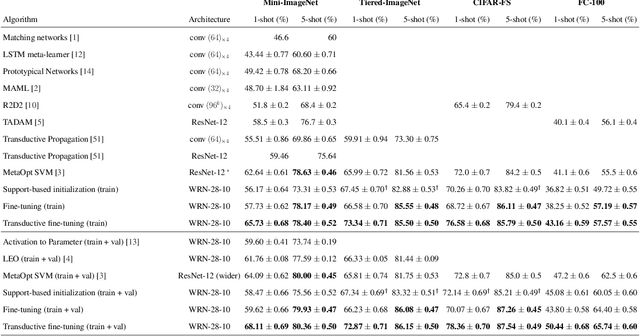

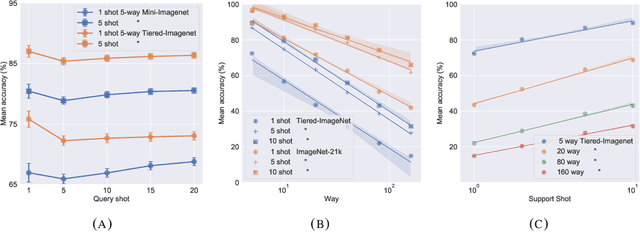
Fine-tuning a deep network trained with the standard cross-entropy loss is a strong baseline for few-shot learning. When fine-tuned transductively, this outperforms the current state-of-the-art on standard datasets such as Mini-Imagenet, Tiered-Imagenet, CIFAR-FS and FC-100 with the same hyper-parameters. The simplicity of this approach enables us to demonstrate the first few-shot learning results on the Imagenet-21k dataset. We find that using a large number of meta-training classes results in high few-shot accuracies even for a large number of test classes. We do not advocate our approach as the solution for few-shot learning, but simply use the results to highlight limitations of current benchmarks and few-shot protocols. We perform extensive studies on benchmark datasets to propose a metric that quantifies the "hardness" of a test episode. This metric can be used to report the performance of few-shot algorithms in a more systematic way.
Semi Few-Shot Attribute Translation
Oct 08, 2019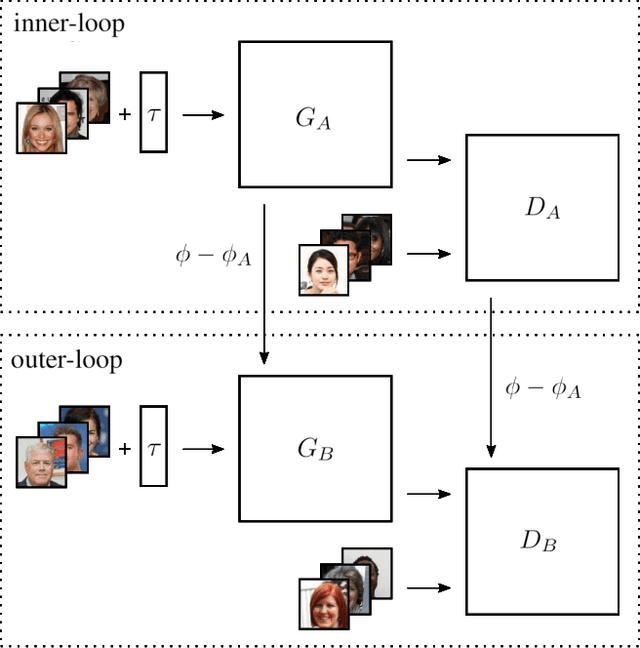
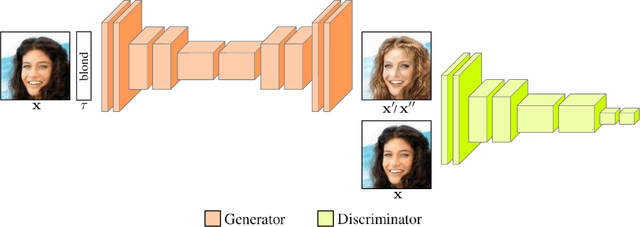


Recent studies have shown remarkable success in image-to-image translation for attribute transfer applications. However, most of existing approaches are based on deep learning and require an abundant amount of labeled data to produce good results, therefore limiting their applicability. In the same vein, recent advances in meta-learning have led to successful implementations with limited available data, allowing so-called few-shot learning. In this paper, we address this limitation of supervised methods, by proposing a novel approach based on GANs. These are trained in a meta-training manner, which allows them to perform image-to-image translations using just a few labeled samples from a new target class. This work empirically demonstrates the potential of training a GAN for few shot image-to-image translation on hair color attribute synthesis tasks, opening the door to further research on generative transfer learning.
Deep Residual 3D U-Net for Joint Segmentation and Texture Classification of Nodules in Lung
Jun 25, 2020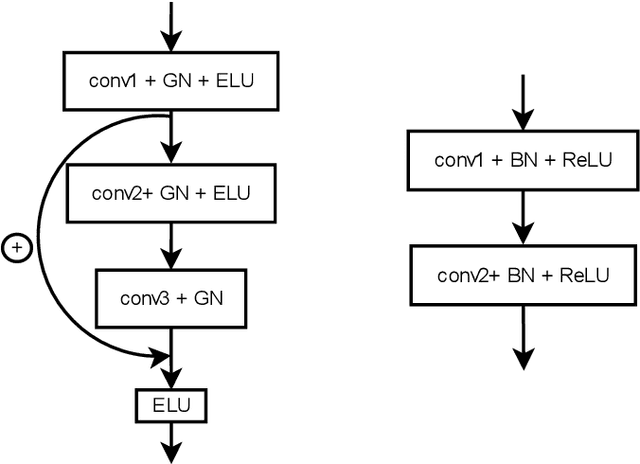
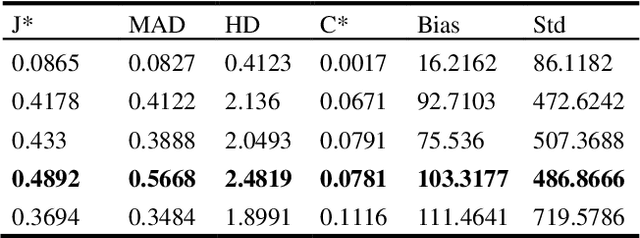
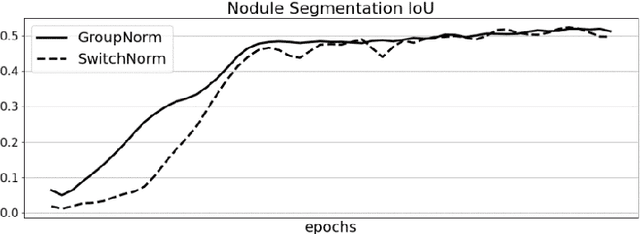
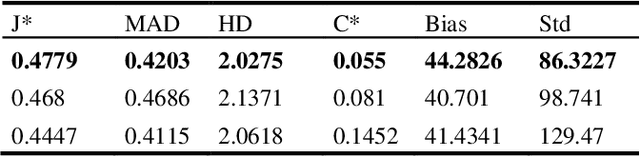
In this work we present a method for lung nodules segmentation, their texture classification and subsequent follow-up recommendation from the CT image of lung. Our method consists of neural network model based on popular U-Net architecture family but modified for the joint nodule segmentation and its texture classification tasks and an ensemble-based model for the fol-low-up recommendation. This solution was evaluated within the LNDb 2020 medical imaging challenge and produced the best nodule segmentation result on the final leaderboard.
* 10 pages, 5 figures, 2 tables, accepted for publication at ICIAR 2020(LNDb Grand Challenge)
Towards A Controllable Disentanglement Network
Jan 22, 2020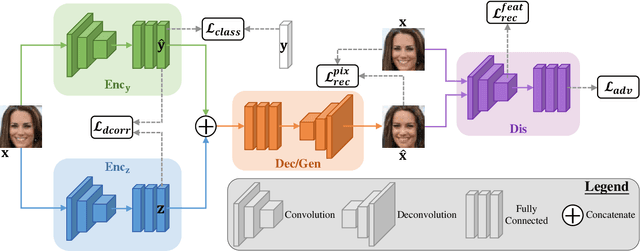
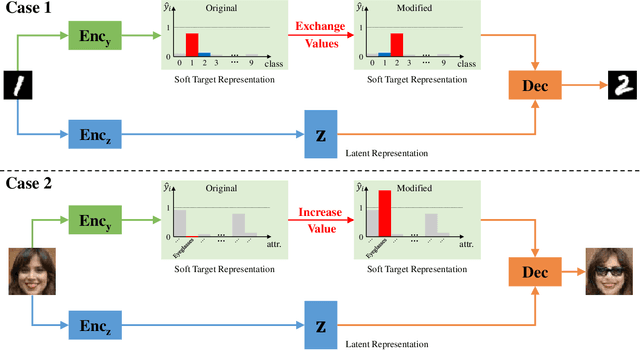


This paper addresses two crucial problems of learning disentangled image representations, namely controlling the degree of disentanglement during image editing, and balancing the disentanglement strength and the reconstruction quality. To encourage disentanglement, we devise a distance covariance based decorrelation regularization. Further, for the reconstruction step, our model leverages a soft target representation combined with the latent image code. By exploring the real-valued space of the soft target representation, we are able to synthesize novel images with the designated properties. To improve the perceptual quality of images generated by autoencoder (AE)-based models, we extend the encoder-decoder architecture with the generative adversarial network (GAN) by collapsing the AE decoder and the GAN generator into one. We also design a classification based protocol to quantitatively evaluate the disentanglement strength of our model. Experimental results showcase the benefits of the proposed model.
Variational Denoising Network: Toward Blind Noise Modeling and Removal
Sep 23, 2019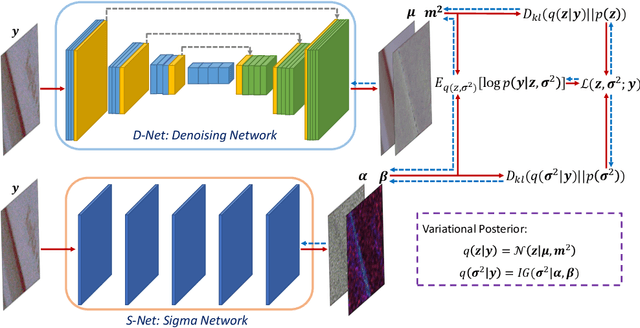
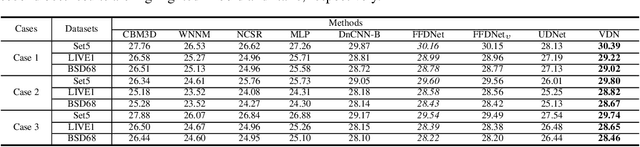
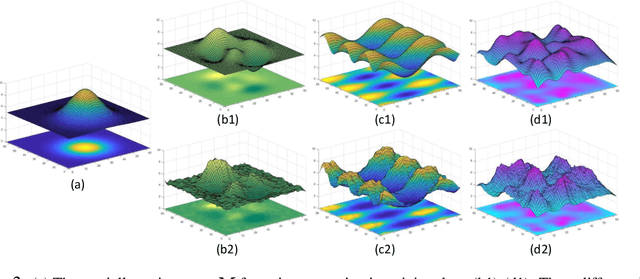
Blind image denoising is an important yet very challenging problem in computer vision due to the complicated acquisition process of real images. In this work we propose a new variational inference method, which integrates both noise estimation and image denoising into a unique Bayesian framework, for blind image denoising. Specifically, an approximate posterior, parameterized by deep neural networks, is presented by taking the intrinsic clean image and noise variances as latent variables conditioned on the input noisy image. This posterior provides explicit parametric forms for all its involved hyper-parameters, and thus can be easily implemented for blind image denoising with automatic noise estimation for the test noisy image. On one hand, as other data-driven deep learning methods, our method, namely variational denoising network (VDN), can perform denoising efficiently due to its explicit form of posterior expression. On the other hand, VDN inherits the advantages of traditional model-driven approaches, especially the good generalization capability of generative models. VDN has good interpretability and can be flexibly utilized to estimate and remove complicated non-i.i.d. noise collected in real scenarios. Comprehensive experiments are performed to substantiate the superiority of our method in blind image denoising.
Modeling Image Virality with Pairwise Spatial Transformer Networks
Sep 22, 2017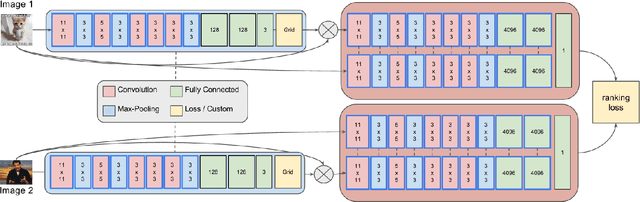
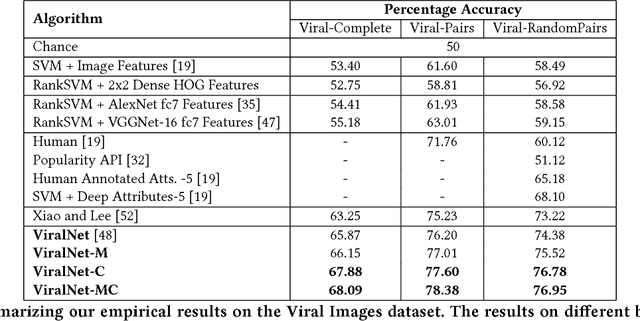
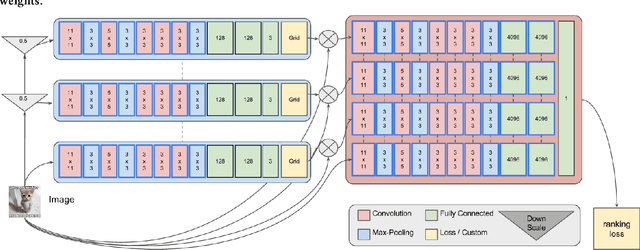
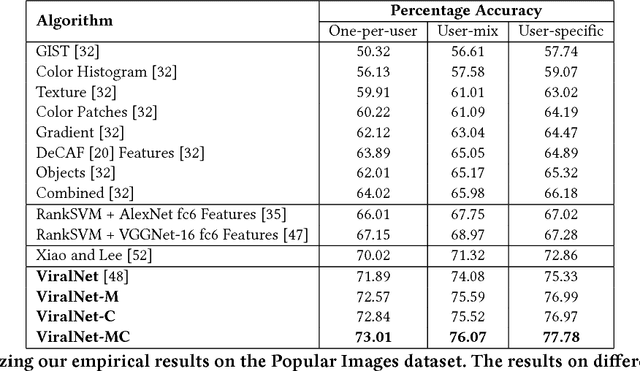
The study of virality and information diffusion online is a topic gaining traction rapidly in the computational social sciences. Computer vision and social network analysis research have also focused on understanding the impact of content and information diffusion in making content viral, with prior approaches not performing significantly well as other traditional classification tasks. In this paper, we present a novel pairwise reformulation of the virality prediction problem as an attribute prediction task and develop a novel algorithm to model image virality on online media using a pairwise neural network. Our model provides significant insights into the features that are responsible for promoting virality and surpasses the existing state-of-the-art by a 12% average improvement in prediction. We also investigate the effect of external category supervision on relative attribute prediction and observe an increase in prediction accuracy for the same across several attribute learning datasets.
DNA Image Pro -- A Tool for Generating Pixel Patterns using DNA Tile Assembly
Jul 12, 2016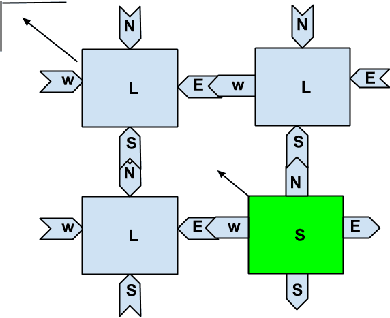
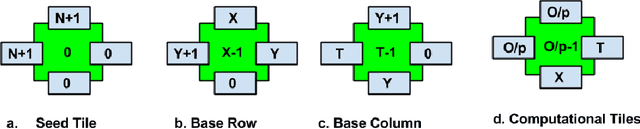
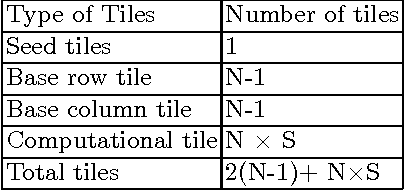
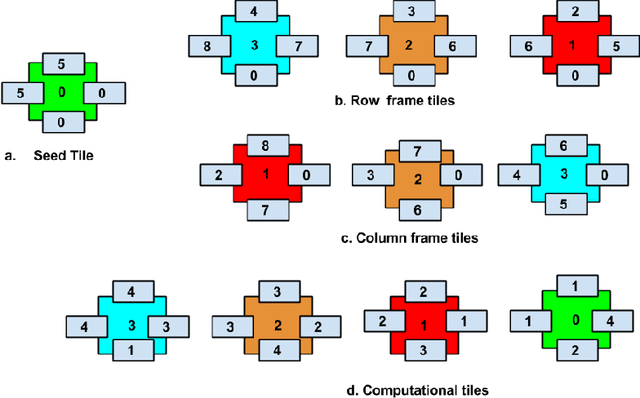
Self-assembly is a process found everywhere in the Nature. In particular, it is known that DNA self-assembly is Turing universal. Thus one can do arbitrary computations or build nano-structures using DNA self-assembly. In order to understand the DNA self-assembly process, many mathematical models have been proposed in the literature. In particular, abstract Tile Assembly Model (aTAM) received much attention. In this work, we investigate pixel pattern generation using aTAM. For a given image, a tile assembly system is given which can generate the image by self-assembly process. We also consider image blocks with specific cyclic pixel patterns (uniform shift and non uniform shift) self assembly. A software, DNA Image Pro, for generating pixel patterns using DNA tile assembly is also given.
Causal Adversarial Network for Learning Conditional and Interventional Distributions
Sep 21, 2020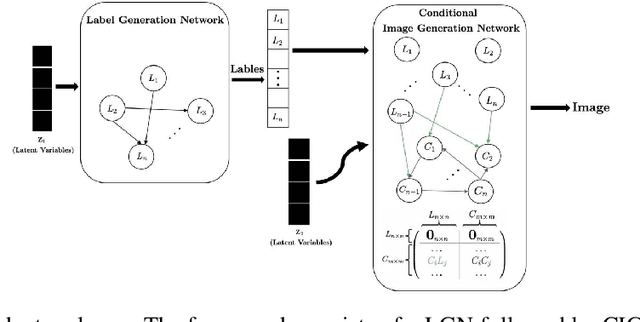
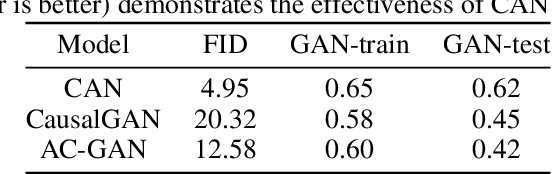


We propose a generative Causal Adversarial Network (CAN) for learning and sampling from conditional and interventional distributions. In contrast to the existing CausalGAN which requires the causal graph to be given, our proposed framework learns the causal relations from the data and generates samples accordingly. The proposed CAN comprises a two-fold process namely Label Generation Network (LGN) and Conditional Image Generation Network (CIGN). The LGN is a GAN-based architecture which learns and samples from the causal model over labels. The sampled labels are then fed to CIGN, a conditional GAN architecture, which learns the relationships amongst labels and pixels and pixels themselves and generates samples based on them. This framework is equipped with an intervention mechanism which enables. the model to generate samples from interventional distributions. We quantitatively and qualitatively assess the performance of CAN and empirically show that our model is able to generate both interventional and conditional samples without having access to the causal graph for the application of face generation on CelebA data.
Overcoming Statistical Shortcuts for Open-ended Visual Counting
Jun 17, 2020



Machine learning models tend to over-rely on statistical shortcuts. These spurious correlations between parts of the input and the output labels does not hold in real-world settings. We target this issue on the recent open-ended visual counting task which is well suited to study statistical shortcuts. We aim to develop models that learn a proper mechanism of counting regardless of the output label. First, we propose the Modifying Count Distribution (MCD) protocol, which penalizes models that over-rely on statistical shortcuts. It is based on pairs of training and testing sets that do not follow the same count label distribution such as the odd-even sets. Intuitively, models that have learned a proper mechanism of counting on odd numbers should perform well on even numbers. Secondly, we introduce the Spatial Counting Network (SCN), which is dedicated to visual analysis and counting based on natural language questions. Our model selects relevant image regions, scores them with fusion and self-attention mechanisms, and provides a final counting score. We apply our protocol on the recent dataset, TallyQA, and show superior performances compared to state-of-the-art models. We also demonstrate the ability of our model to select the correct instances to count in the image. Code and datasets are available: https://github.com/cdancette/spatial-counting-network