 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Q-FIT: The Quantifiable Feature Importance Technique for Explainable Machine Learning
Oct 26, 2020
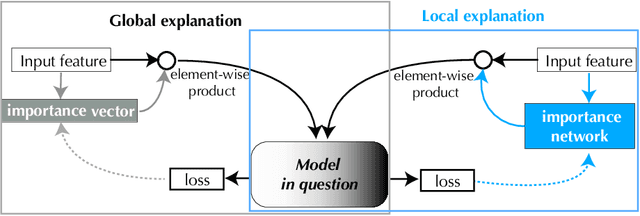
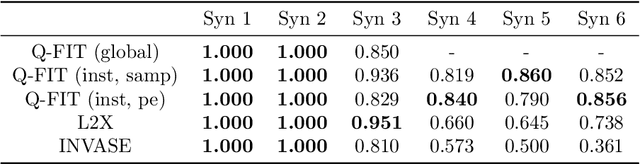
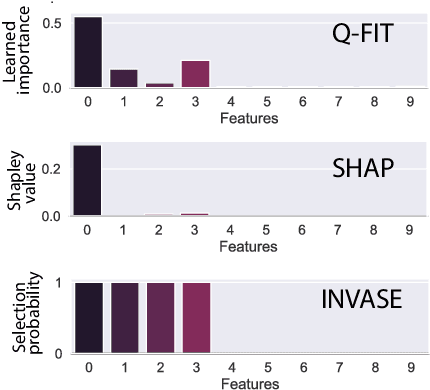

We introduce a novel framework to quantify the importance of each input feature for model explainability. A user of our framework can choose between two modes: (a) global explanation: providing feature importance globally across all the data points; and (b) local explanation: providing feature importance locally for each individual data point. The core idea of our method comes from utilizing the Dirichlet distribution to define a distribution over the importance of input features. This particular distribution is useful in ranking the importance of the input features as a sample from this distribution is a probability vector (i.e., the vector components sum to 1), Thus, the ranking uncovered by our framework which provides a \textit{quantifiable explanation} of how significant each input feature is to a model's output. This quantifiable explainability differentiates our method from existing feature-selection methods, which simply determine whether a feature is relevant or not. Furthermore, a distribution over the explanation allows to define a closed-form divergence to measure the similarity between learned feature importance under different models. We use this divergence to study how the feature importance trade-offs with essential notions in modern machine learning, such as privacy and fairness. We show the effectiveness of our method on a variety of synthetic and real datasets, taking into account both tabular and image datasets.
Peak Detection On Data Independent Acquisition Mass Spectrometry Data With Semisupervised Convolutional Transformers
Oct 26, 2020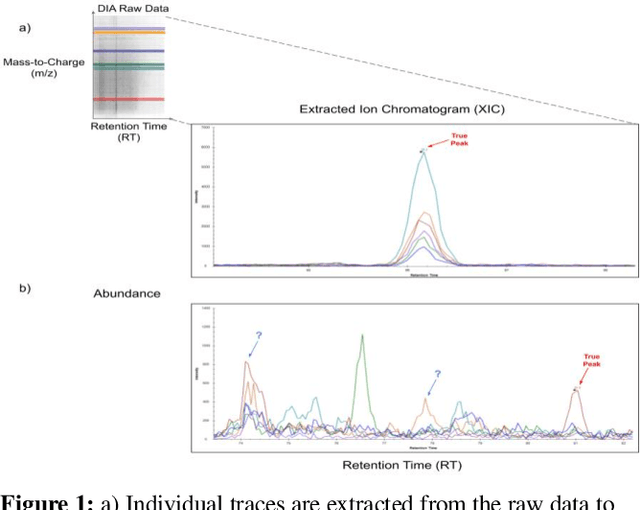

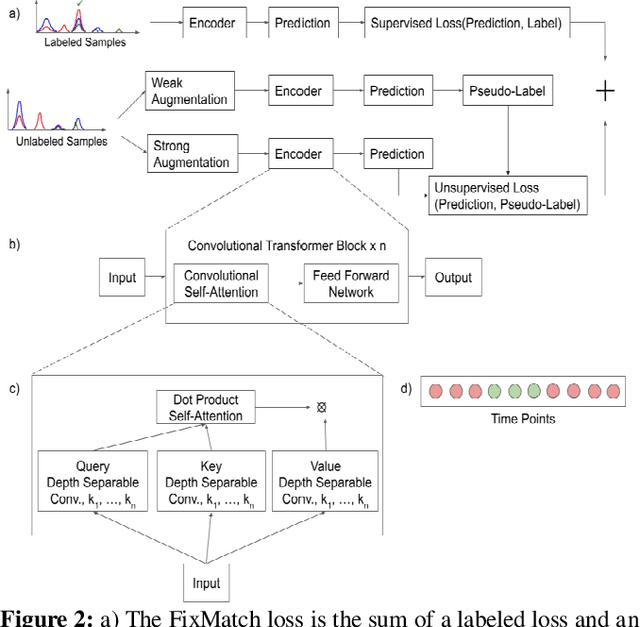

Liquid Chromatography coupled to Mass Spectrometry (LC-MS) based methods are commonly used for high-throughput, quantitative measurements of the proteome (i.e. the set of all proteins in a sample at a given time). Targeted LC-MS produces data in the form of a two-dimensional time series spectrum, with the mass to charge ratio of analytes (m/z) on one axis, and the retention time from the chromatography on the other. The elution of a peptide of interest produces highly specific patterns across multiple fragment ion traces (extracted ion chromatograms, or XICs). In this paper, we formulate this peak detection problem as a multivariate time series segmentation problem, and propose a novel approach based on the Transformer architecture. Here we augment Transformers, which are capable of capturing long distance dependencies with a global view, with Convolutional Neural Networks (CNNs), which can capture local context important to the task at hand, in the form of Transformers with Convolutional Self-Attention. We further train this model in a semisupervised manner by adapting state of the art semisupervised image classification techniques for multi-channel time series data. Experiments on a representative LC-MS dataset are benchmarked using manual annotations to showcase the encouraging performance of our method; it outperforms baseline neural network architectures and is competitive against the current state of the art in automated peak detection.
Diverse and Accurate Image Description Using a Variational Auto-Encoder with an Additive Gaussian Encoding Space
Nov 19, 2017
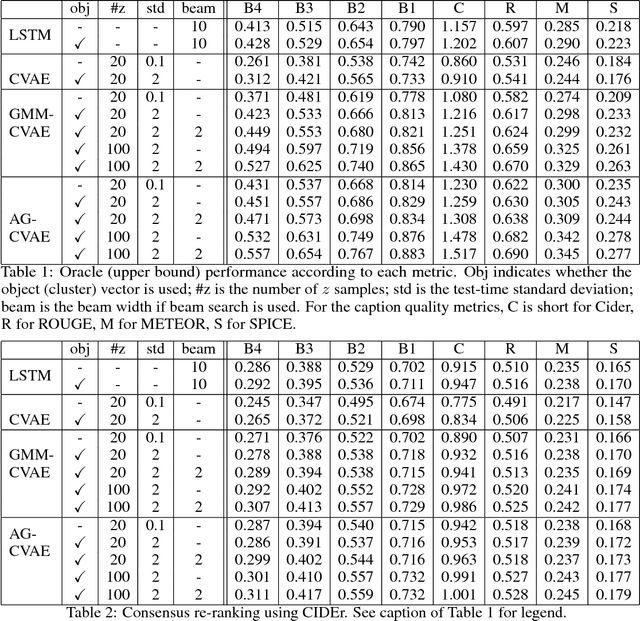

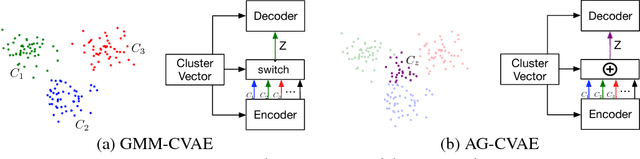
This paper explores image caption generation using conditional variational auto-encoders (CVAEs). Standard CVAEs with a fixed Gaussian prior yield descriptions with too little variability. Instead, we propose two models that explicitly structure the latent space around $K$ components corresponding to different types of image content, and combine components to create priors for images that contain multiple types of content simultaneously (e.g., several kinds of objects). Our first model uses a Gaussian Mixture model (GMM) prior, while the second one defines a novel Additive Gaussian (AG) prior that linearly combines component means. We show that both models produce captions that are more diverse and more accurate than a strong LSTM baseline or a "vanilla" CVAE with a fixed Gaussian prior, with AG-CVAE showing particular promise.
Wasserstein Routed Capsule Networks
Jul 22, 2020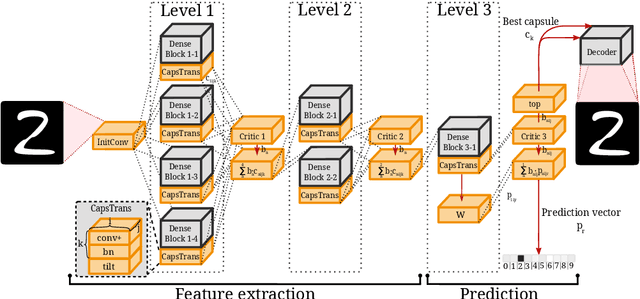
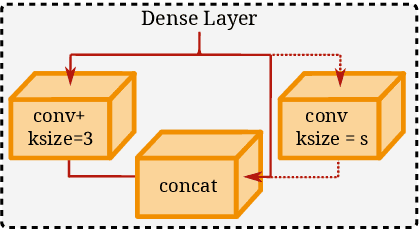

Capsule networks offer interesting properties and provide an alternative to today's deep neural network architectures. However, recent approaches have failed to consistently achieve competitive results across different image datasets. We propose a new parameter efficient capsule architecture, that is able to tackle complex tasks by using neural networks trained with an approximate Wasserstein objective to dynamically select capsules throughout the entire architecture. This approach focuses on implementing a robust routing scheme, which can deliver improved results using little overhead. We perform several ablation studies verifying the proposed concepts and show that our network is able to substantially outperform other capsule approaches by over 1.2 % on CIFAR-10, using fewer parameters.
Multiple View Generation and Classification of Mid-wave Infrared Images using Deep Learning
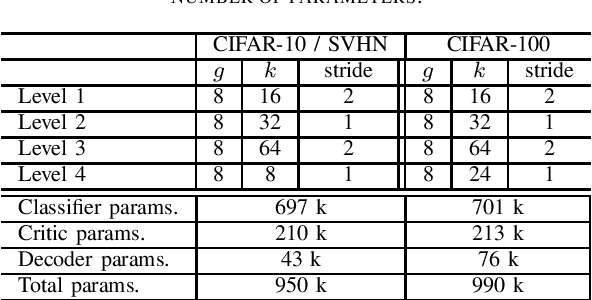
Aug 18, 2020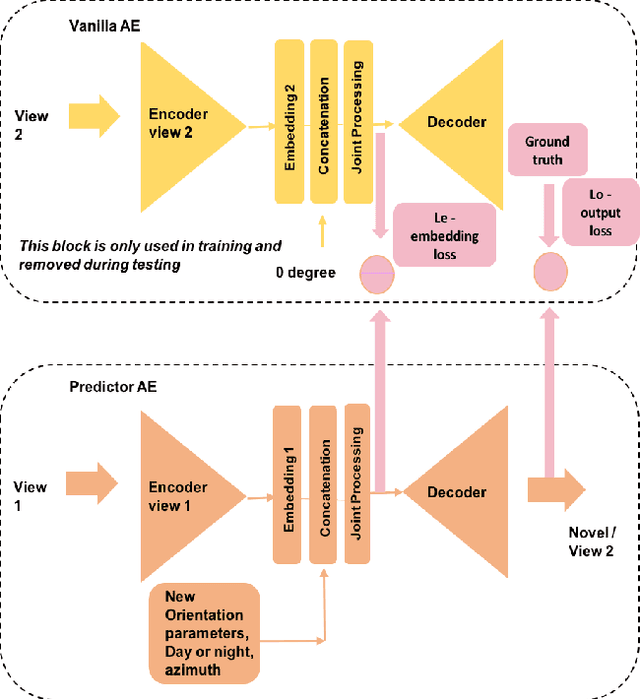
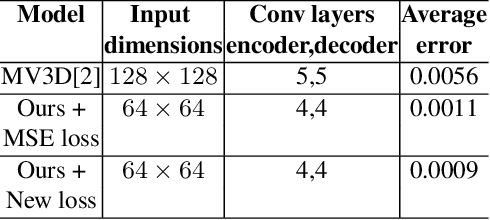
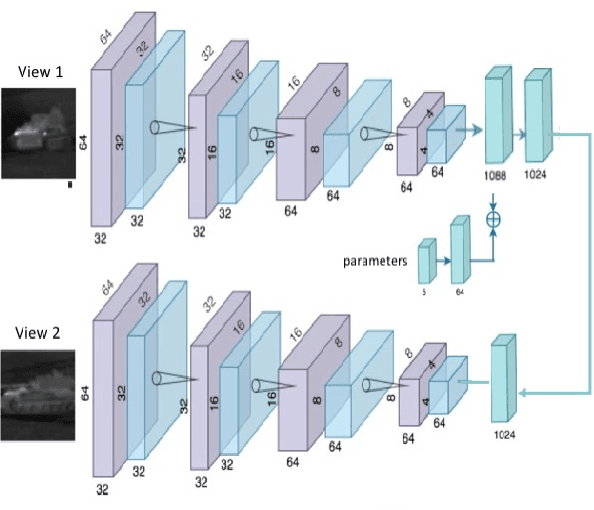

We propose a novel study of generating unseen arbitrary viewpoints for infrared imagery in the non-linear feature subspace . Current methods use synthetic images and often result in blurry and distorted outputs. Our approach on the contrary understands the semantic information in natural images and encapsulates it such that our predicted unseen views possess good 3D representations. We further explore the non-linear feature subspace and conclude that our network does not operate in the Euclidean subspace but rather in the Riemannian subspace. It does not learn the geometric transformation for predicting the position of the pixel in the new image but rather learns the manifold. To this end, we use t-SNE visualisations to conduct a detailed analysis of our network and perform classification of generated images as a low-shot learning task.
Pruning Convolutional Filters using Batch Bridgeout
Sep 23, 2020

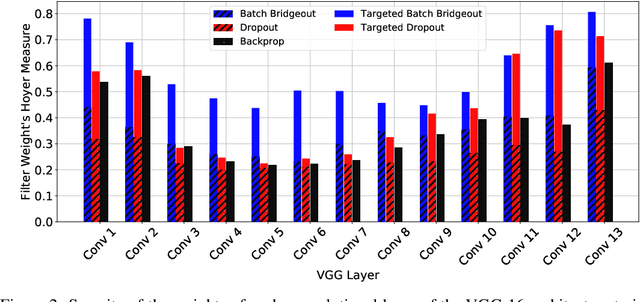
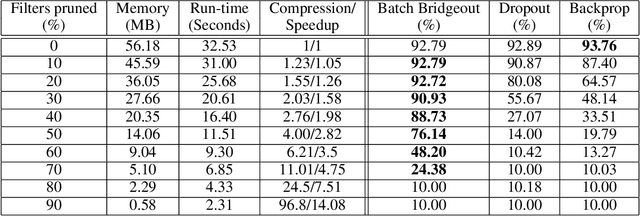
State-of-the-art computer vision models are rapidly increasing in capacity, where the number of parameters far exceeds the number required to fit the training set. This results in better optimization and generalization performance. However, the huge size of contemporary models results in large inference costs and limits their use on resource-limited devices. In order to reduce inference costs, convolutional filters in trained neural networks could be pruned to reduce the run-time memory and computational requirements during inference. However, severe post-training pruning results in degraded performance if the training algorithm results in dense weight vectors. We propose the use of Batch Bridgeout, a sparsity inducing stochastic regularization scheme, to train neural networks so that they could be pruned efficiently with minimal degradation in performance. We evaluate the proposed method on common computer vision models VGGNet, ResNet, and Wide-ResNet on the CIFAR image classification task. For all the networks, experimental results show that Batch Bridgeout trained networks achieve higher accuracy across a wide range of pruning intensities compared to Dropout and weight decay regularization.
Multi-Metric Evaluation of Thermal-to-Visual Face Recognition
Jul 22, 2020
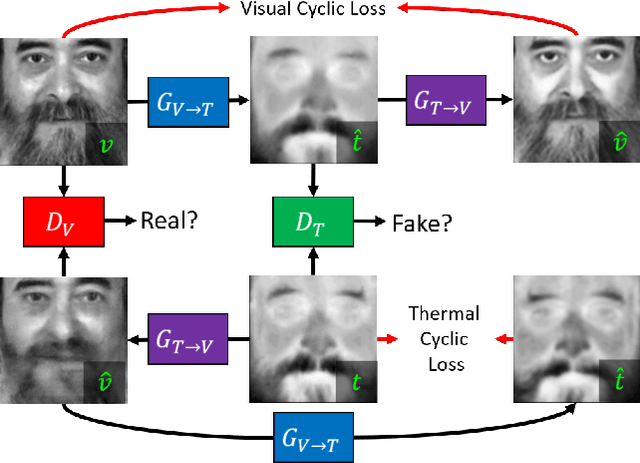
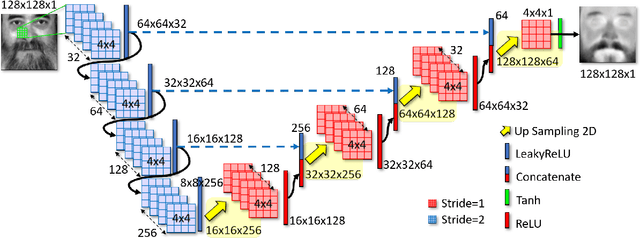
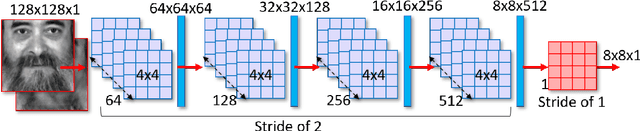
In this paper, we aim to address the problem of heterogeneous or cross-spectral face recognition using machine learning to synthesize visual spectrum face from infrared images. The synthesis of visual-band face images allows for more optimal extraction of facial features to be used for face identification and/or verification. We explore the ability to use Generative Adversarial Networks (GANs) for face image synthesis, and examine the performance of these images using pre-trained Convolutional Neural Networks (CNNs). The features extracted using CNNs are applied in face identification and verification. We explore the performance in terms of acceptance rate when using various similarity measures for face verification.
Online Extrinsic Camera Calibration for Temporally Consistent IPM Using Lane Boundary Observations with a Lane Width Prior
Aug 09, 2020
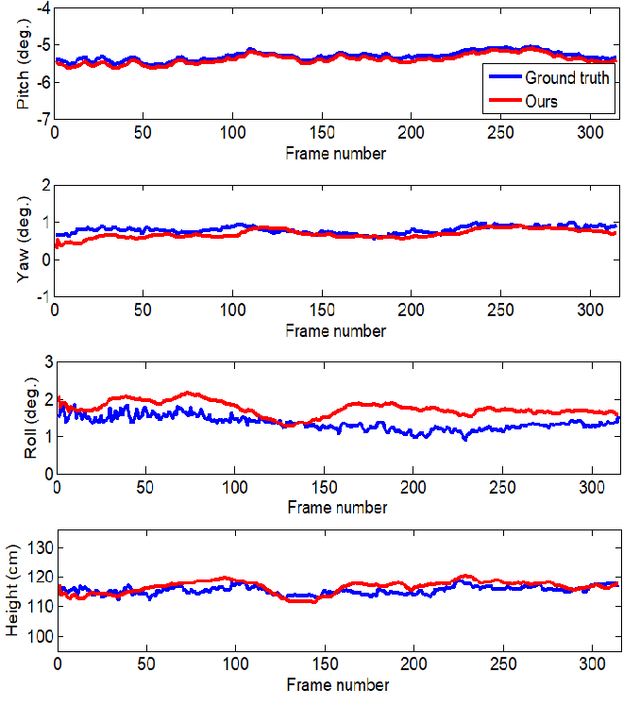

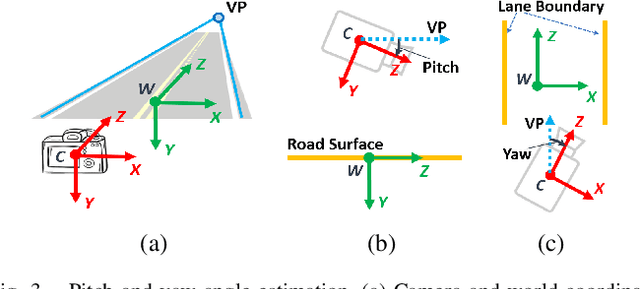
In this paper, we propose a method for online extrinsic camera calibration, i.e., estimating pitch, yaw, roll angles and camera height from road surface in sequential driving scene images. The proposed method estimates the extrinsic camera parameters in two steps: 1) pitch and yaw angles are estimated simultaneously using a vanishing point computed from a set of lane boundary observations, and then 2) roll angle and camera height are computed by minimizing difference between lane width observations and a lane width prior. The extrinsic camera parameters are sequentially updated using extended Kalman filtering (EKF) and are finally used to generate a temporally consistent bird-eye-view (BEV) image by inverse perspective mapping (IPM). We demonstrate the superiority of the proposed method in synthetic and real-world datasets.
A Dual Sparse Decomposition Method for Image Denoising
Apr 24, 2017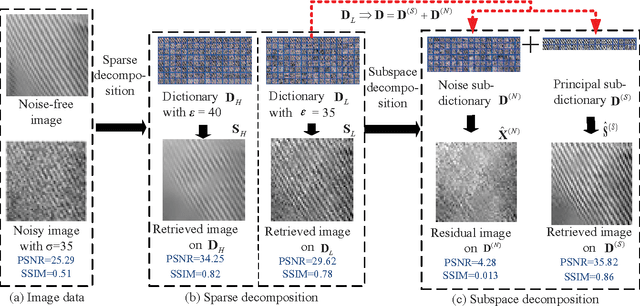
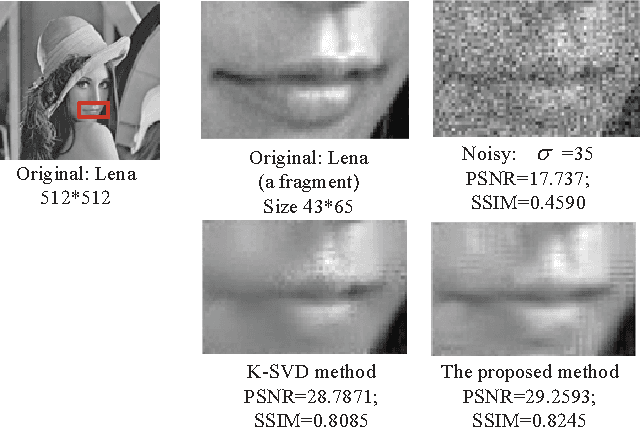

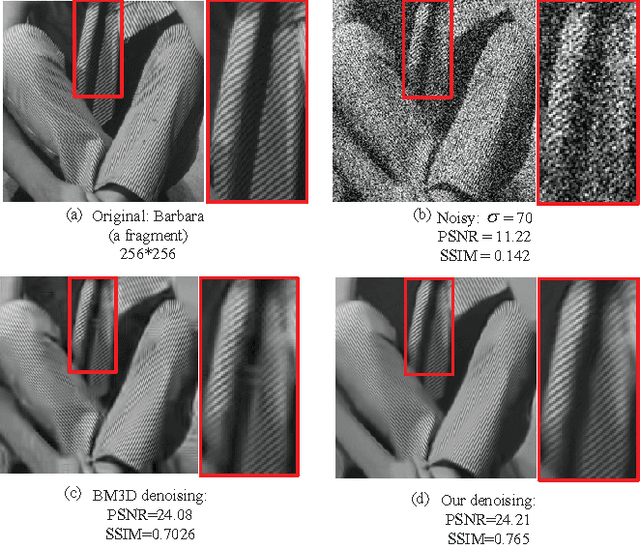
This article addresses the image denoising problem in the situations of strong noise. We propose a dual sparse decomposition method. This method makes a sub-dictionary decomposition on the over-complete dictionary in the sparse decomposition. The sub-dictionary decomposition makes use of a novel criterion based on the occurrence frequency of atoms of the over-complete dictionary over the data set. The experimental results demonstrate that the dual-sparse-decomposition method surpasses state-of-art denoising performance in terms of both peak-signal-to-noise ratio and structural-similarity-index-metric, and also at subjective visual quality.
Vision-Based Autonomous Drone Control using Supervised Learning in Simulation
Sep 09, 2020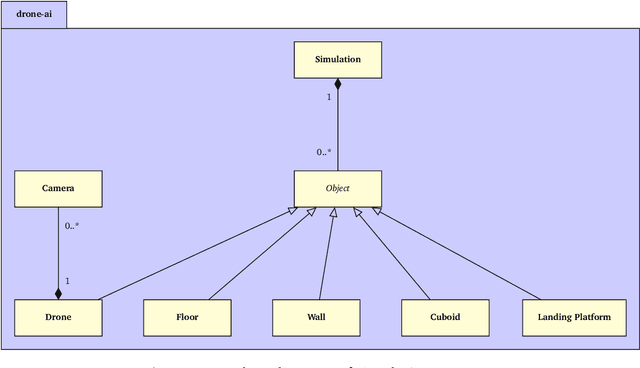

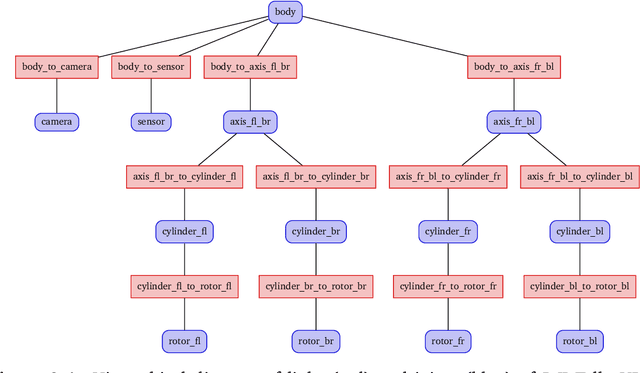
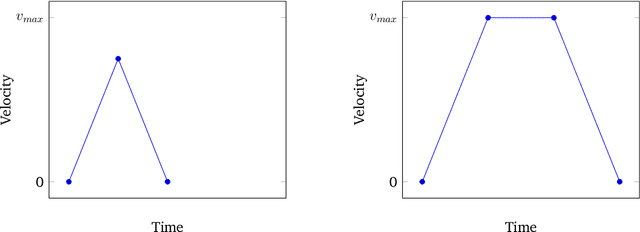
Limited power and computational resources, absence of high-end sensor equipment and GPS-denied environments are challenges faced by autonomous micro areal vehicles (MAVs). We address these challenges in the context of autonomous navigation and landing of MAVs in indoor environments and propose a vision-based control approach using Supervised Learning. To achieve this, we collected data samples in a simulation environment which were labelled according to the optimal control command determined by a path planning algorithm. Based on these data samples, we trained a Convolutional Neural Network (CNN) that maps low resolution image and sensor input to high-level control commands. We have observed promising results in both obstructed and non-obstructed simulation environments, showing that our model is capable of successfully navigating a MAV towards a landing platform. Our approach requires shorter training times than similar Reinforcement Learning approaches and can potentially overcome the limitations of manual data collection faced by comparable Supervised Learning approaches.