 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Topology-Preserving Deep Image Segmentation
Jun 12, 2019
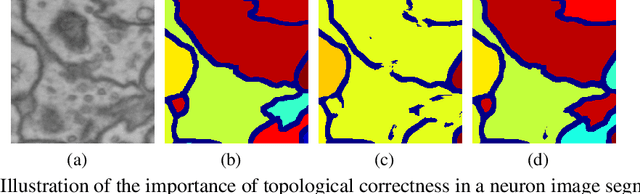
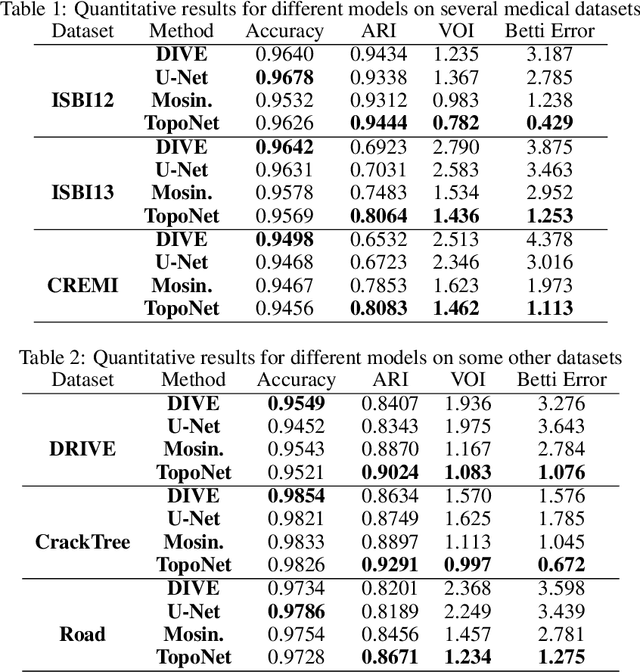
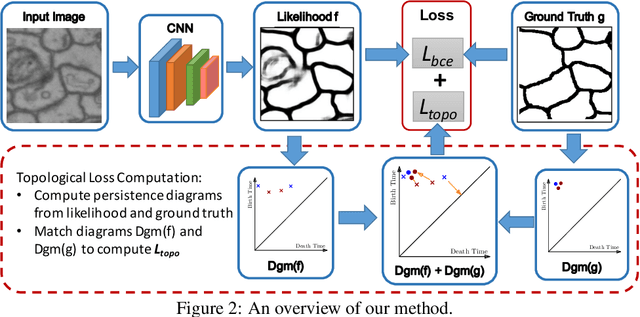
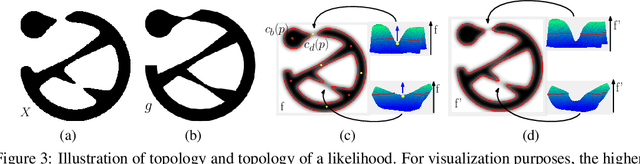
Segmentation algorithms are prone to make topological errors on fine-scale structures, e.g., broken connections. We propose a novel method that learns to segment with correct topology. In particular, we design a continuous-valued loss function that enforces a segmentation to have the same topology as the ground truth, i.e., having the same Betti number. The proposed topology-preserving loss function is differentiable and we incorporate it into end-to-end training of a deep neural network. Our method achieves much better performance on the Betti number error, which directly accounts for the topological correctness. It also performs superiorly on other topology-relevant metrics, e.g., the Adjusted Rand Index and the Variation of Information. We illustrate the effectiveness of the proposed method on a broad spectrum of natural and biomedical datasets.
Keeping Up Appearances: Computational Modeling of Face Acts in Persuasion Oriented Discussions
Sep 24, 2020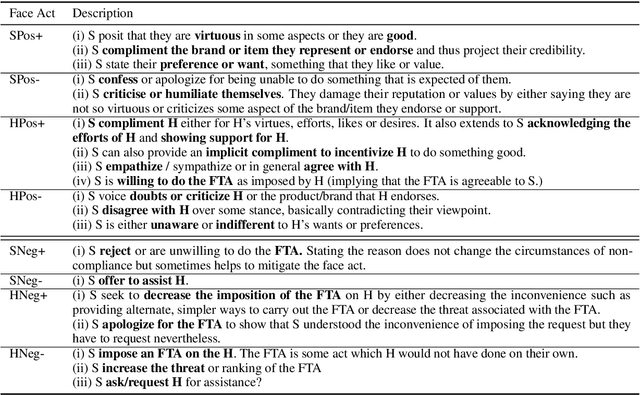
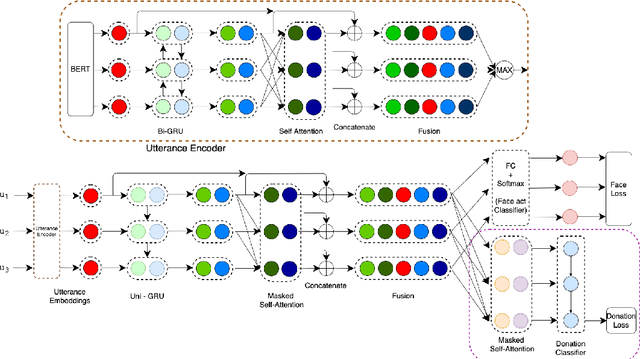
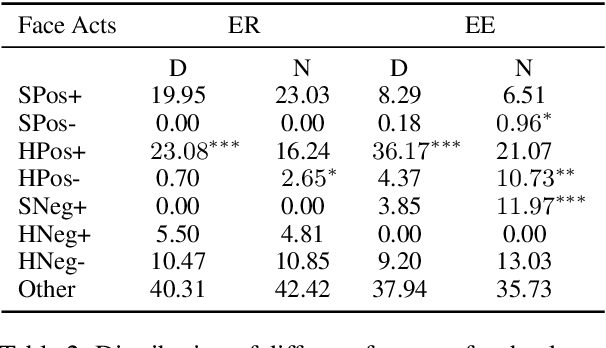
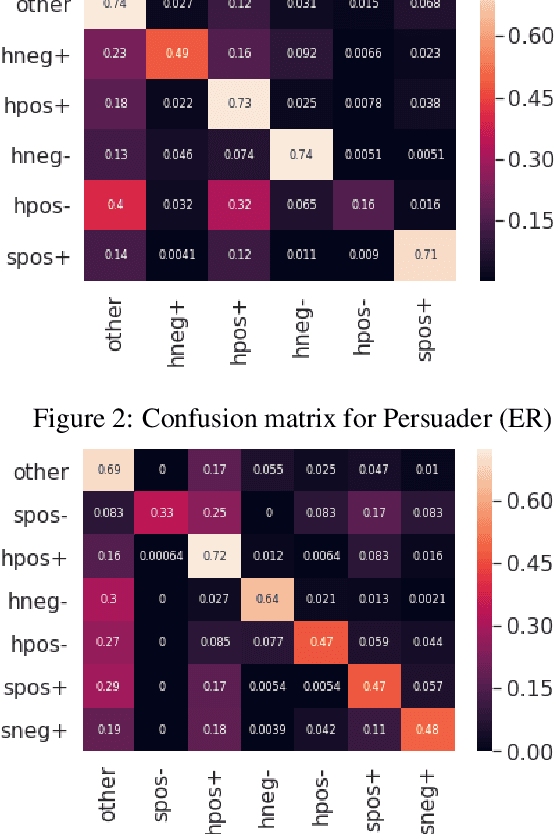
The notion of face refers to the public self-image of an individual that emerges both from the individual's own actions as well as from the interaction with others. Modeling face and understanding its state changes throughout a conversation is critical to the study of maintenance of basic human needs in and through interaction. Grounded in the politeness theory of Brown and Levinson (1978), we propose a generalized framework for modeling face acts in persuasion conversations, resulting in a reliable coding manual, an annotated corpus, and computational models. The framework reveals insights about differences in face act utilization between asymmetric roles in persuasion conversations. Using computational models, we are able to successfully identify face acts as well as predict a key conversational outcome (e.g. donation success). Finally, we model a latent representation of the conversational state to analyze the impact of predicted face acts on the probability of a positive conversational outcome and observe several correlations that corroborate previous findings.
Towards integrating spatial localization in convolutional neural networks for brain image segmentation
Apr 12, 2018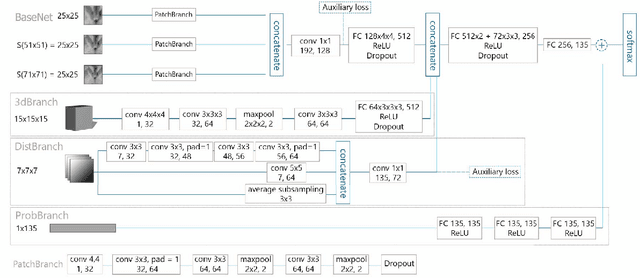
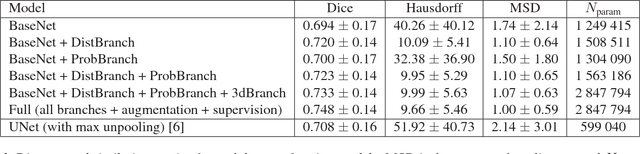

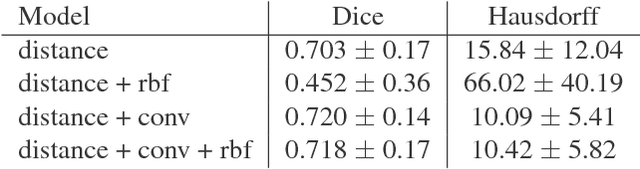
Semantic segmentation is an established while rapidly evolving field in medical imaging. In this paper we focus on the segmentation of brain Magnetic Resonance Images (MRI) into cerebral structures using convolutional neural networks (CNN). CNNs achieve good performance by finding effective high dimensional image features describing the patch content only. In this work, we propose different ways to introduce spatial constraints into the network to further reduce prediction inconsistencies. A patch based CNN architecture was trained, making use of multiple scales to gather contextual information. Spatial constraints were introduced within the CNN through a distance to landmarks feature or through the integration of a probability atlas. We demonstrate experimentally that using spatial information helps to reduce segmentation inconsistencies.
Deep DIH : Statistically Inferred Reconstruction of Digital In-Line Holography by Deep Learning
Apr 25, 2020
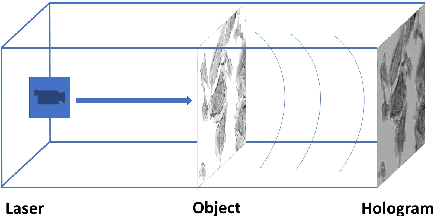
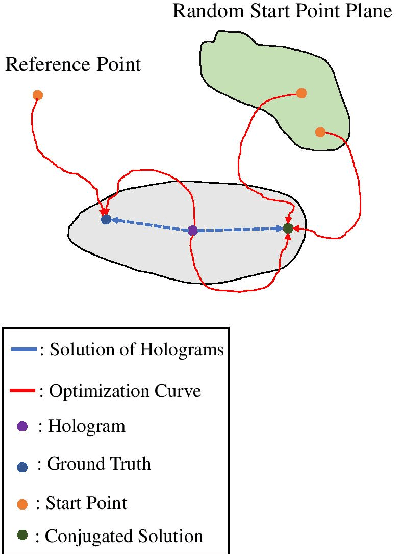
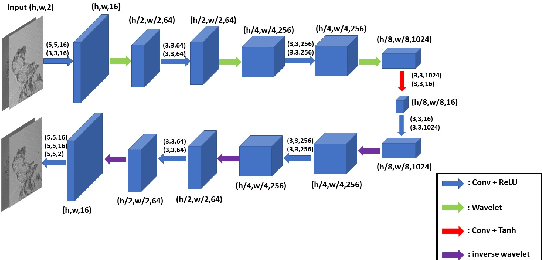
Digital in-line holography is commonly used to reconstruct 3D images from 2D holograms for microscopic objects. One of the technical challenges that arise in the signal processing stage is removing the twin image that is caused by the phase-conjugate wavefront from the recorded holograms. Twin image removal is typically formulated as a non-linear inverse problem due to the irreversible scattering process when generating the hologram. Recently, end-to-end deep learning-based methods have been utilized to reconstruct the object wavefront (as a surrogate for the 3D structure of the object) directly from a single-shot in-line digital hologram. However, massive data pairs are required to train deep learning models for acceptable reconstruction precision. In contrast to typical image processing problems, well-curated datasets for in-line digital holography does not exist. Also, the trained model highly influenced by the morphological properties of the object and hence can vary for different applications. Therefore, data collection can be prohibitively cumbersome in practice as a major hindrance to using deep learning for digital holography. In this paper, we proposed a novel implementation of autoencoder-based deep learning architecture for single-shot hologram reconstruction solely based on the current sample without the need for massive datasets to train the model. The simulations results demonstrate the superior performance of the proposed method compared to the state of the art single-shot compressive digital in-line hologram reconstruction method.
3D-DEEP: 3-Dimensional Deep-learning based on elevation patterns forroad scene interpretation
Sep 01, 2020

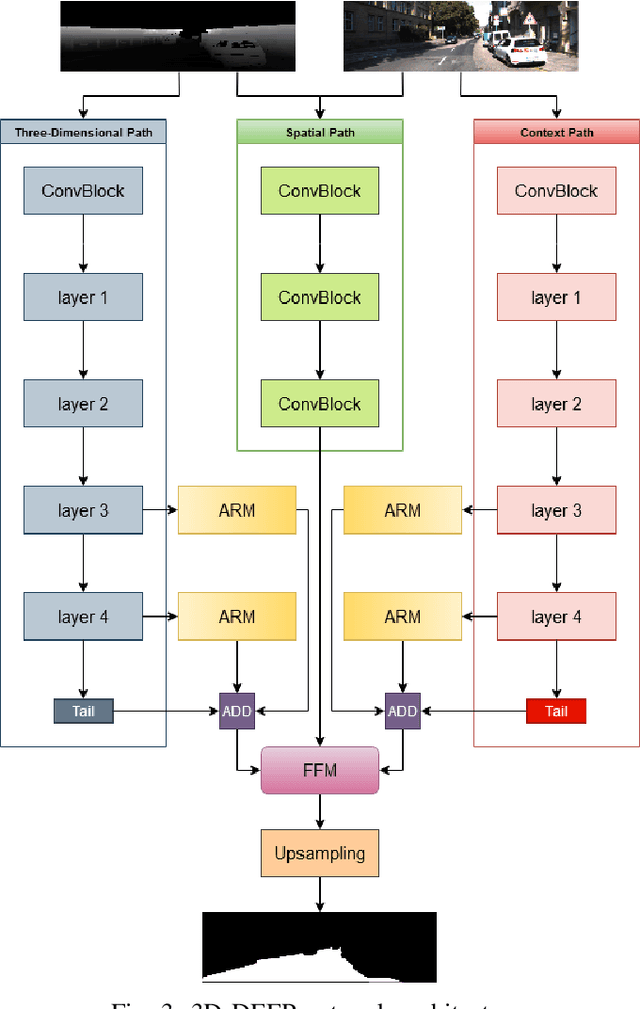
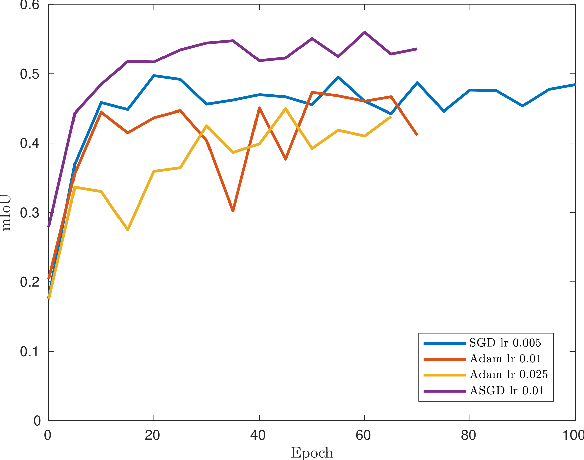
Road detection and segmentation is a crucial task in computer vision for safe autonomous driving. With this in mind, a new net architecture (3D-DEEP) and its end-to-end training methodology for CNN-based semantic segmentation are described along this paper for. The method relies on disparity filtered and LiDAR projected images for three-dimensional information and image feature extraction through fully convolutional networks architectures. The developed models were trained and validated over Cityscapes dataset using just fine annotation examples with 19 different training classes, and over KITTI road dataset. 72.32% mean intersection over union(mIoU) has been obtained for the 19 Cityscapes training classes using the validation images. On the other hand, over KITTIdataset the model has achieved an F1 error value of 97.85% invalidation and 96.02% using the test images.
Learning Arbitrary-Goal Fabric Folding with One Hour of Real Robot Experience
Oct 07, 2020

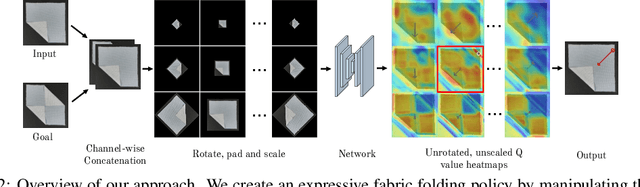
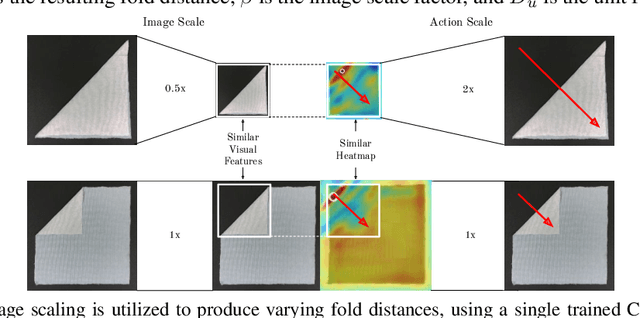
Manipulating deformable objects, such as fabric, is a long standing problem in robotics, with state estimation and control posing a significant challenge for traditional methods. In this paper, we show that it is possible to learn fabric folding skills in only an hour of self-supervised real robot experience, without human supervision or simulation. Our approach relies on fully convolutional networks and the manipulation of visual inputs to exploit learned features, allowing us to create an expressive goal-conditioned pick and place policy that can be trained efficiently with real world robot data only. Folding skills are learned with only a sparse reward function and thus do not require reward function engineering, merely an image of the goal configuration. We demonstrate our method on a set of towel-folding tasks, and show that our approach is able to discover sequential folding strategies, purely from trial-and-error. We achieve state-of-the-art results without the need for demonstrations or simulation, used in prior approaches. Videos available at: https://sites.google.com/view/learningtofold
Transformation on Computer-Generated Facial Image to Avoid Detection by Spoofing Detector
Apr 12, 2018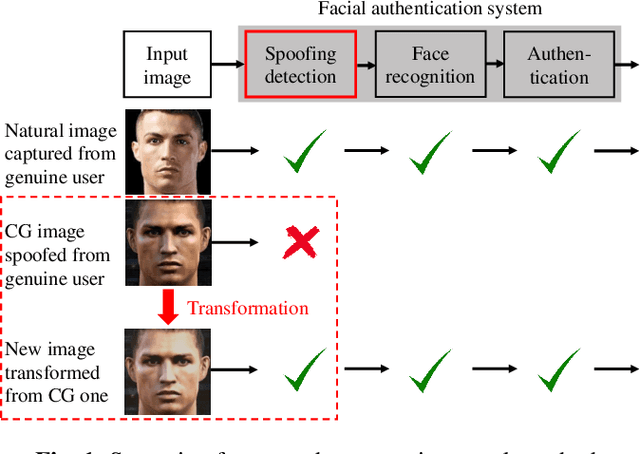
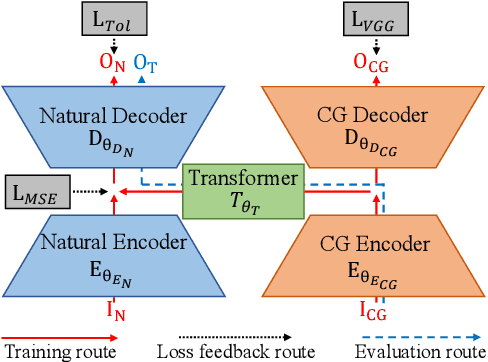

Making computer-generated (CG) images more difficult to detect is an interesting problem in computer graphics and security. While most approaches focus on the image rendering phase, this paper presents a method based on increasing the naturalness of CG facial images from the perspective of spoofing detectors. The proposed method is implemented using a convolutional neural network (CNN) comprising two autoencoders and a transformer and is trained using a black-box discriminator without gradient information. Over 50% of the transformed CG images were not detected by three state-of-the-art spoofing detectors. This capability raises an alarm regarding the reliability of facial authentication systems, which are becoming widely used in daily life.
Learning the Best Pooling Strategy for Visual Semantic Embedding
Nov 09, 2020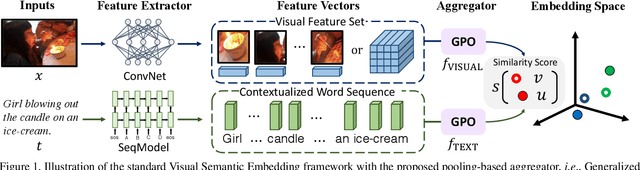
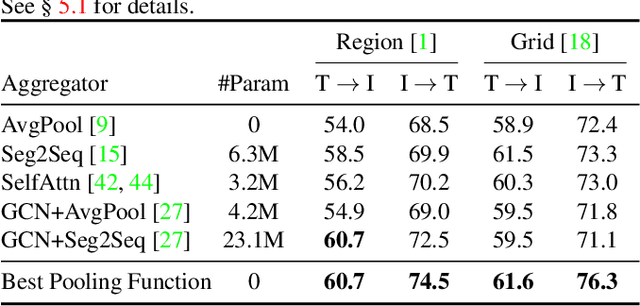
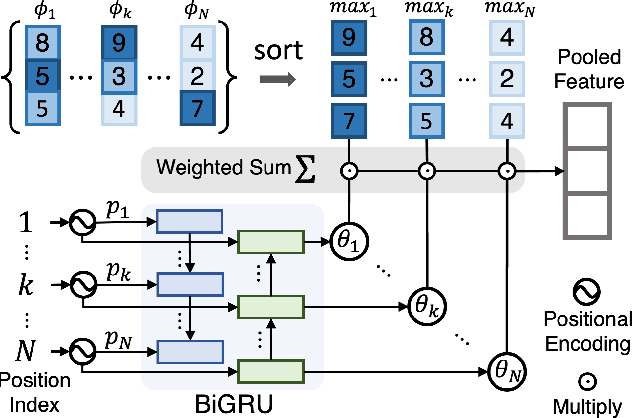
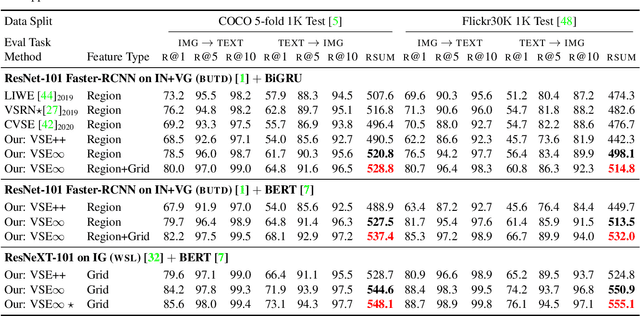
Visual Semantic Embedding (VSE) is a dominant approach for vision-language retrieval, which aims at learning a deep embedding space such that visual data are embedded close to their semantic text labels or descriptions. Recent VSE models use complex methods to better contextualize and aggregate multi-modal features into holistic embeddings. However, we discover that surprisingly simple (but carefully selected) global pooling functions (e.g., max pooling) outperform those complex models, across different feature extractors. Despite its simplicity and effectiveness, seeking the best pooling function for different data modality and feature extractor is costly and tedious, especially when the size of features varies (e.g., text, video). Therefore, we propose a Generalized Pooling Operator (GPO), which learns to automatically adapt itself to the best pooling strategy for different features, requiring no manual tuning while staying effective and efficient. We extend the VSE model using this proposed GPO and denote it as VSE$\infty$. Without bells and whistles, VSE$\infty$ outperforms previous VSE methods significantly on image-text retrieval benchmarks across popular feature extractors. With a simple adaptation, variants of VSE$\infty$ further demonstrate its strength by achieving the new state of the art on two video-text retrieval datasets. Comprehensive experiments and visualizations confirm that GPO always discovers the best pooling strategy and can be a plug-and-play feature aggregation module for standard VSE models.
CT-CAPS: Feature Extraction-based Automated Framework for COVID-19 Disease Identification from Chest CT Scans using Capsule Networks
Oct 30, 2020
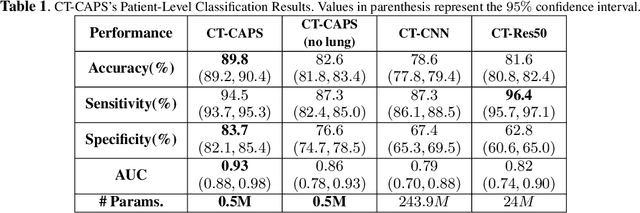

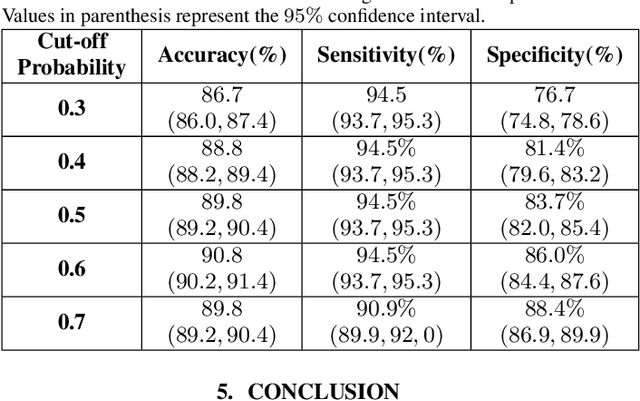
The global outbreak of the novel corona virus (COVID-19) disease has drastically impacted the world and led to one of the most challenging crisis across the globe since World War II. The early diagnosis and isolation of COVID-19 positive cases are considered as crucial steps towards preventing the spread of the disease and flattening the epidemic curve. Chest Computed Tomography (CT) scan is a highly sensitive, rapid, and accurate diagnostic technique that can complement Reverse Transcription Polymerase Chain Reaction (RT-PCR) test. Recently, deep learning-based models, mostly based on Convolutional Neural Networks (CNN), have shown promising diagnostic results. CNNs, however, are incapable of capturing spatial relations between image instances and require large datasets. Capsule Networks, on the other hand, can capture spatial relations, require smaller datasets, and have considerably fewer parameters. In this paper, a Capsule network framework, referred to as the "CT-CAPS", is presented to automatically extract distinctive features of chest CT scans. These features, which are extracted from the layer before the final capsule layer, are then leveraged to differentiate COVID-19 from Non-COVID cases. The experiments on our in-house dataset of 307 patients show the state-of-the-art performance with the accuracy of 90.8%, sensitivity of 94.5%, and specificity of 86.0%.
Evolving Normalization-Activation Layers
Apr 09, 2020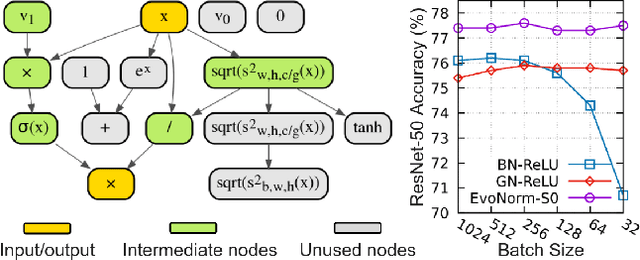

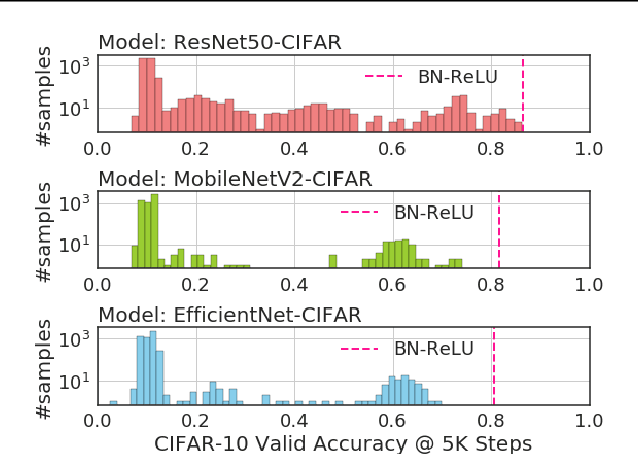
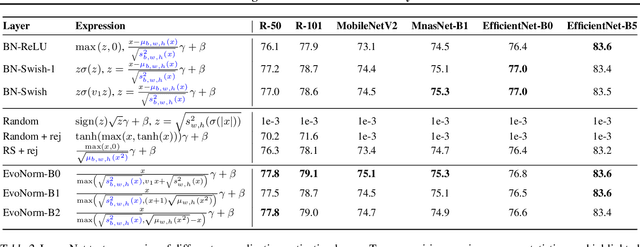
Normalization layers and activation functions are critical components in deep neural networks that frequently co-locate with each other. Instead of designing them separately, we unify them into a single computation graph, and evolve its structure starting from low-level primitives. Our layer search algorithm leads to the discovery of EvoNorms, a set of new normalization-activation layers that go beyond existing design patterns. Several of these layers enjoy the property of being independent from the batch statistics. Our experiments show that EvoNorms not only excel on a variety of image classification models including ResNets, MobileNets and EfficientNets, but also transfer well to Mask R-CNN for instance segmentation and BigGAN for image synthesis, outperforming BatchNorm and GroupNorm based layers by a significant margin in many cases.