 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Is Robustness the Cost of Accuracy? -- A Comprehensive Study on the Robustness of 18 Deep Image Classification Models
Aug 05, 2018
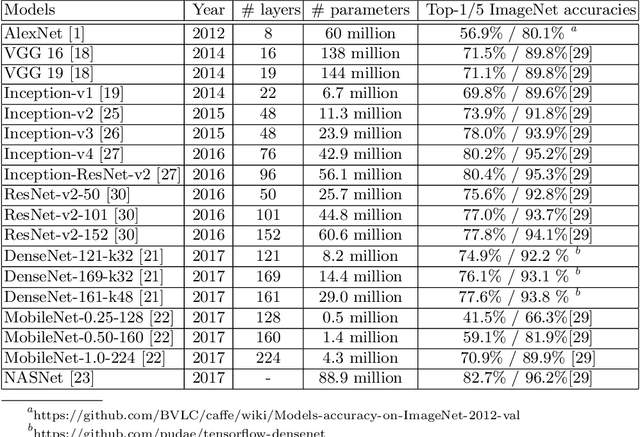
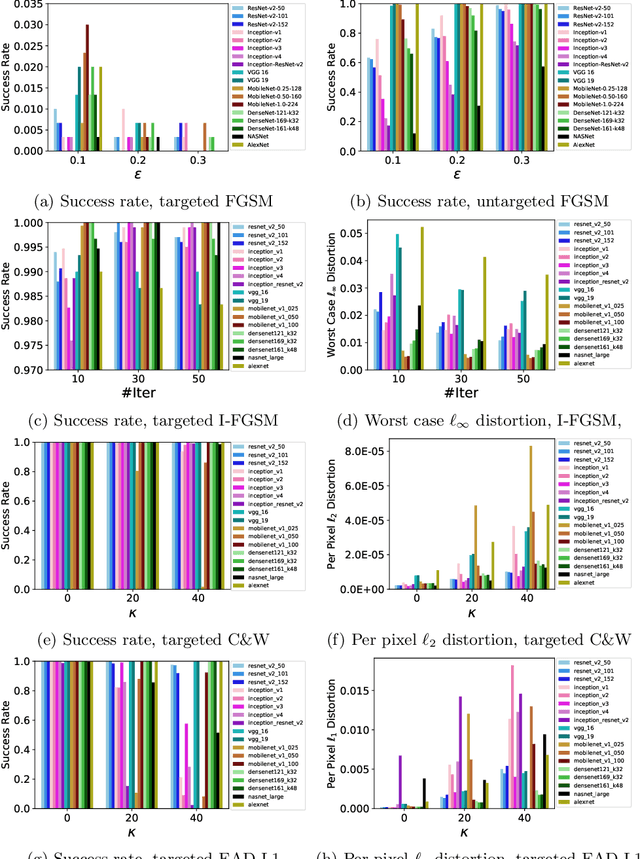
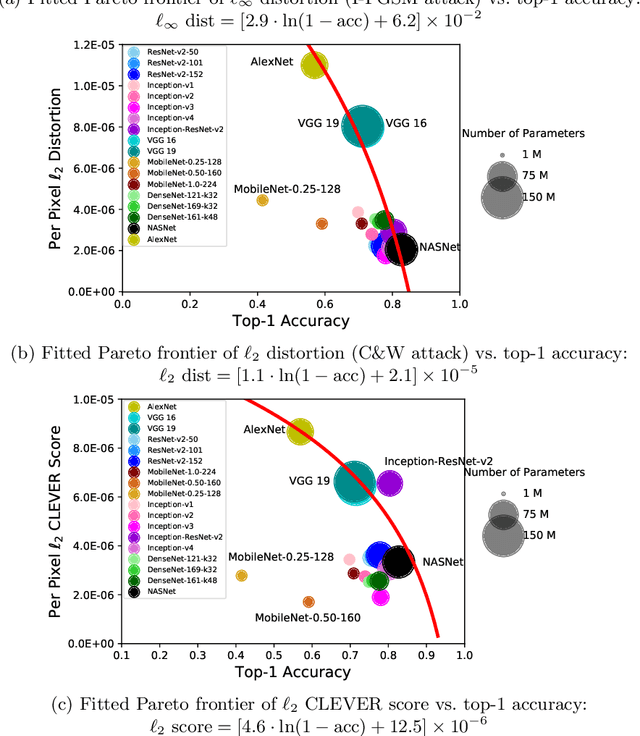
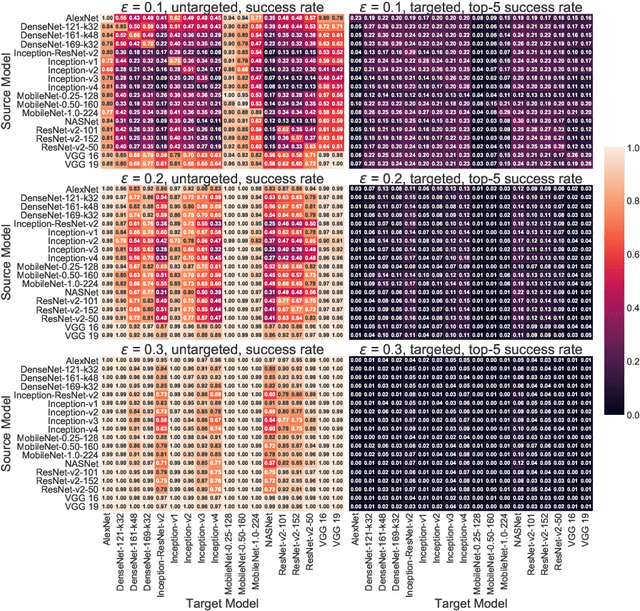
The prediction accuracy has been the long-lasting and sole standard for comparing the performance of different image classification models, including the ImageNet competition. However, recent studies have highlighted the lack of robustness in well-trained deep neural networks to adversarial examples. Visually imperceptible perturbations to natural images can easily be crafted and mislead the image classifiers towards misclassification. To demystify the trade-offs between robustness and accuracy, in this paper we thoroughly benchmark 18 ImageNet models using multiple robustness metrics, including the distortion, success rate and transferability of adversarial examples between 306 pairs of models. Our extensive experimental results reveal several new insights: (1) linear scaling law - the empirical $\ell_2$ and $\ell_\infty$ distortion metrics scale linearly with the logarithm of classification error; (2) model architecture is a more critical factor to robustness than model size, and the disclosed accuracy-robustness Pareto frontier can be used as an evaluation criterion for ImageNet model designers; (3) for a similar network architecture, increasing network depth slightly improves robustness in $\ell_\infty$ distortion; (4) there exist models (in VGG family) that exhibit high adversarial transferability, while most adversarial examples crafted from one model can only be transferred within the same family. Experiment code is publicly available at \url{https://github.com/huanzhang12/Adversarial_Survey}.
Over a Decade of Social Opinion Mining
Dec 05, 2020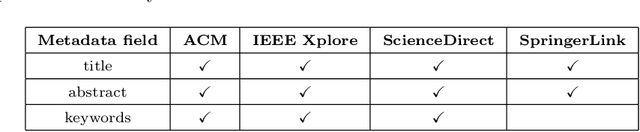
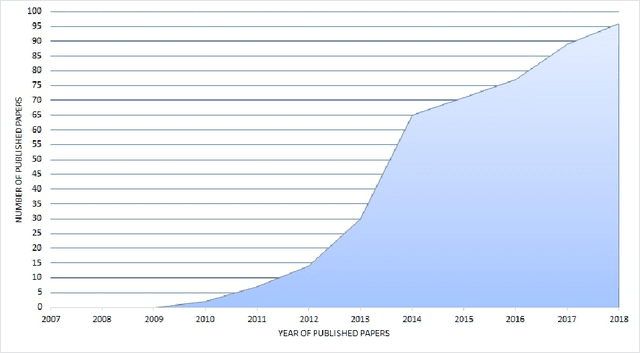
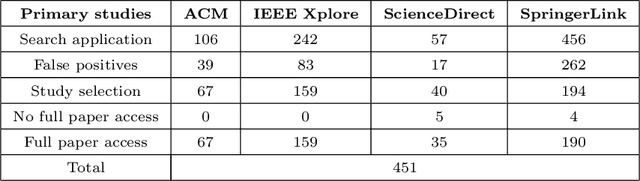
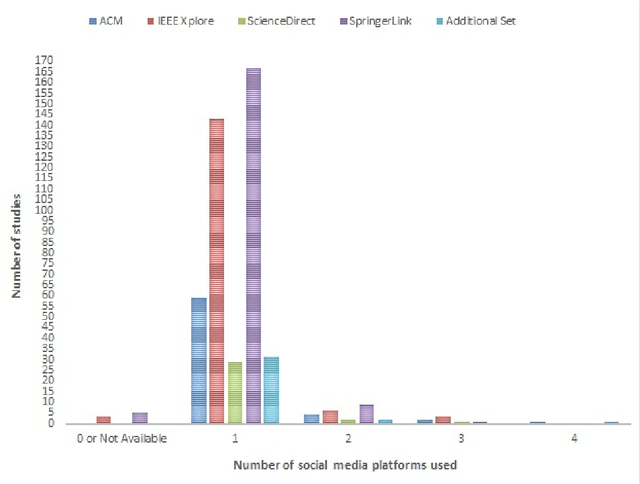
Social media popularity and importance is on the increase, due to people using it for various types of social interaction across multiple channels. This social interaction by online users includes submission of feedback, opinions and recommendations about various individuals, entities, topics, and events. This systematic review focuses on the evolving research area of Social Opinion Mining, tasked with the identification of multiple opinion dimensions, such as subjectivity, sentiment polarity, emotion, affect, sarcasm and irony, from user-generated content represented across multiple social media platforms and in various media formats, like text, image, video and audio. Therefore, through Social Opinion Mining, natural language can be understood in terms of the different opinion dimensions, as expressed by humans. This contributes towards the evolution of Artificial Intelligence, which in turn helps the advancement of several real-world use cases, such as customer service and decision making. A thorough systematic review was carried out on Social Opinion Mining research which totals 485 studies and spans a period of twelve years between 2007 and 2018. The in-depth analysis focuses on the social media platforms, techniques, social datasets, language, modality, tools and technologies, natural language processing tasks and other aspects derived from the published studies. Such multi-source information fusion plays a fundamental role in mining of people's social opinions from social media platforms. These can be utilised in many application areas, ranging from marketing, advertising and sales for product/service management, and in multiple domains and industries, such as politics, technology, finance, healthcare, sports and government. Future research directions are presented, whereas further research and development has the potential of leaving a wider academic and societal impact.
An Algorithm to Attack Neural Network Encoder-based Out-Of-Distribution Sample Detector
Sep 17, 2020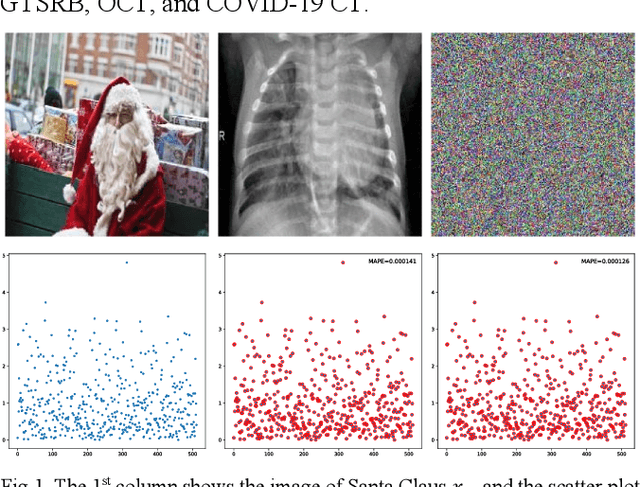
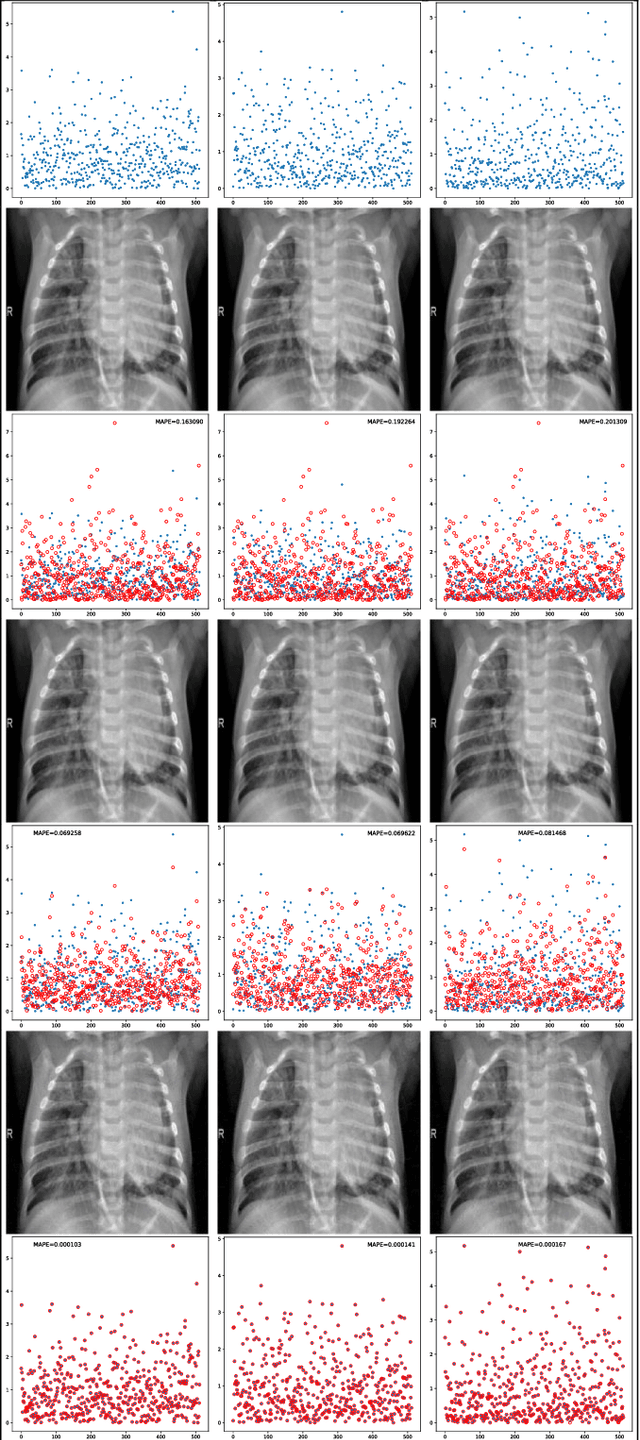
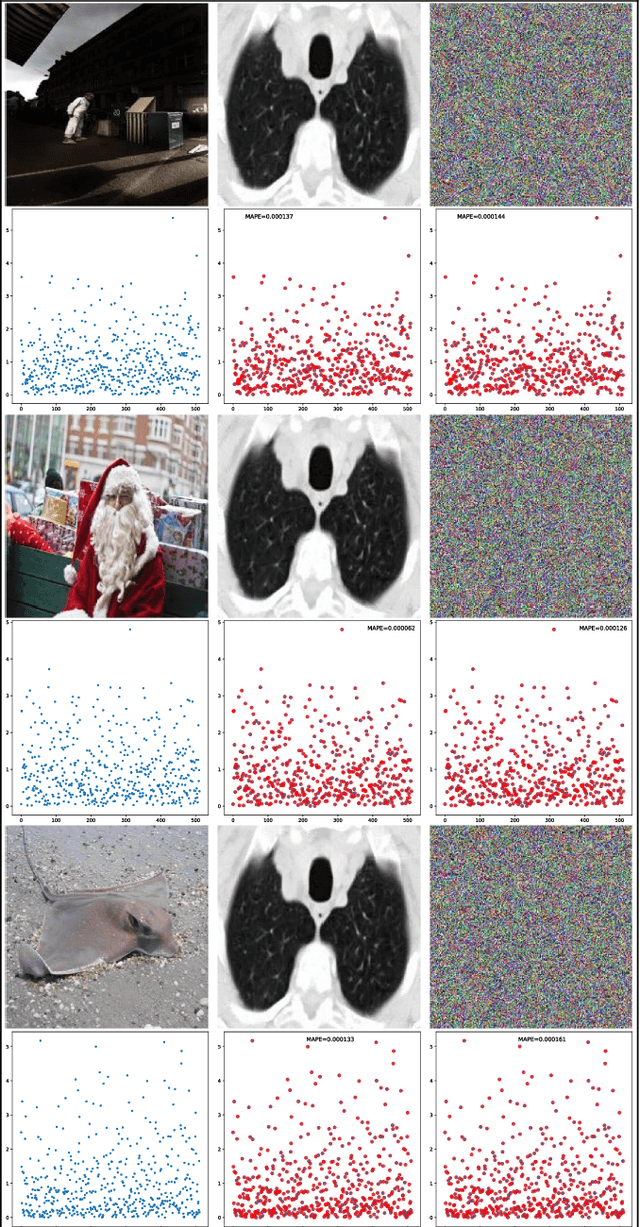
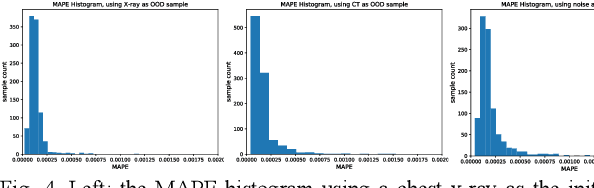
Deep neural network (DNN), especially convolutional neural network, has achieved superior performance on image classification tasks. However, such performance is only guaranteed if the input to a trained model is similar to the training samples, i.e., the input follows the probability distribution of the training set. Out-Of-Distribution (OOD) samples do not follow the distribution of training set, and therefore the predicted class labels on OOD samples become meaningless. Classification-based methods have been proposed for OOD detection; however, in this study we show that this type of method is theoretically ineffective and practically breakable because of dimensionality reduction in the model. We also show that Glow likelihood-based OOD detection is ineffective as well. Our analysis is demonstrated on five open datasets, including a COVID-19 CT dataset. At last, we present a simple theoretical solution with guaranteed performance for OOD detection.
GASNet: Weakly-supervised Framework for COVID-19 Lesion Segmentation
Oct 19, 2020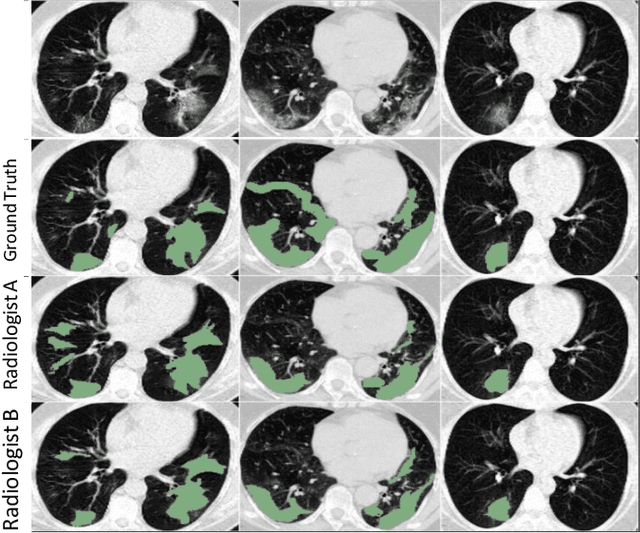
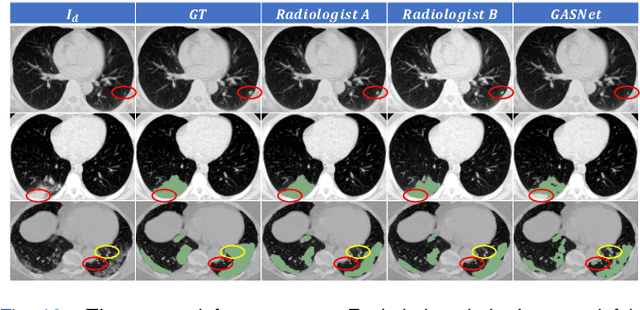
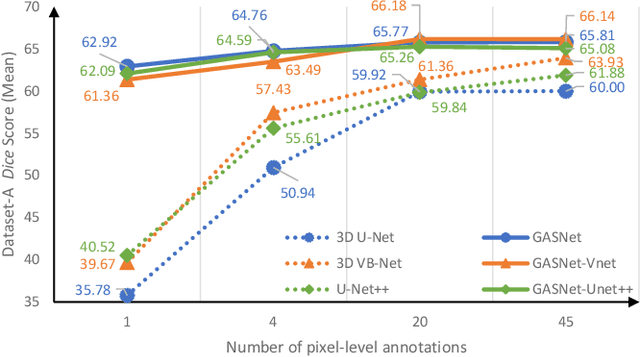
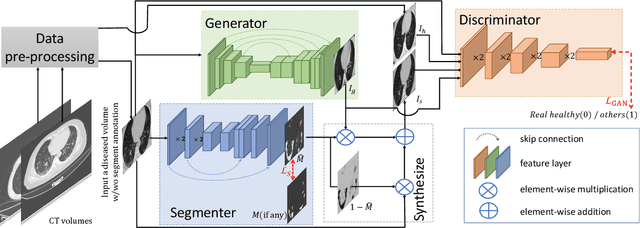
Segmentation of infected areas in chest CT volumes is of great significance for further diagnosis and treatment of COVID-19 patients. Due to the complex shapes and varied appearances of lesions, a large number of voxel-level labeled samples are generally required to train a lesion segmentation network, which is a main bottleneck for developing deep learning based medical image segmentation algorithms. In this paper, we propose a weakly-supervised lesion segmentation framework by embedding the Generative Adversarial training process into the Segmentation Network, which is called GASNet. GASNet is optimized to segment the lesion areas of a COVID-19 CT by the segmenter, and to replace the abnormal appearance with a generated normal appearance by the generator, so that the restored CT volumes are indistinguishable from healthy CT volumes by the discriminator. GASNet is supervised by chest CT volumes of many healthy and COVID-19 subjects without voxel-level annotations. Experiments on three public databases show that when using as few as one voxel-level labeled sample, the performance of GASNet is comparable to fully-supervised segmentation algorithms trained on dozens of voxel-level labeled samples.
Keeping Up Appearances: Computational Modeling of Face Acts in Persuasion Oriented Discussions
Sep 24, 2020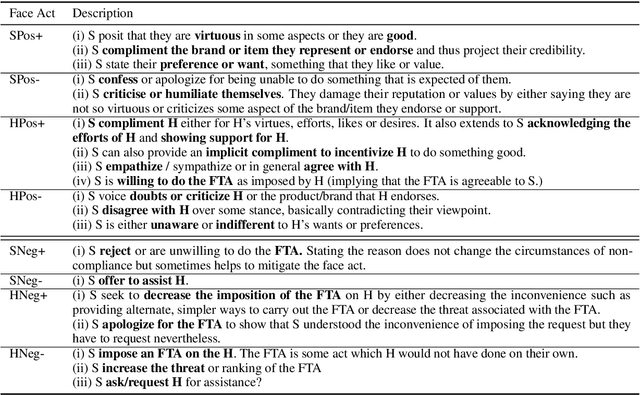
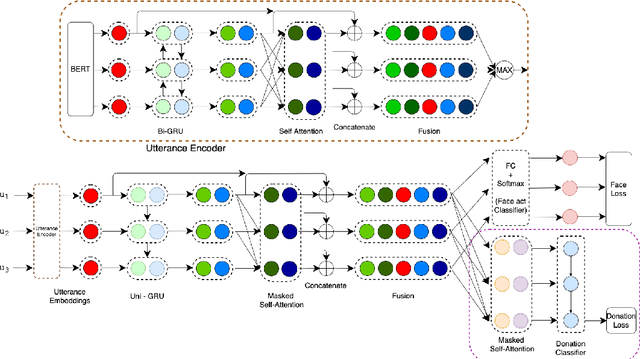
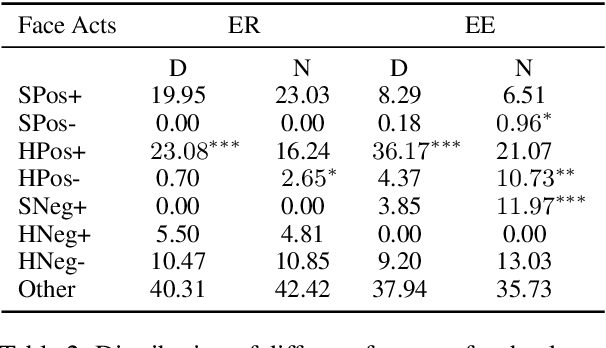
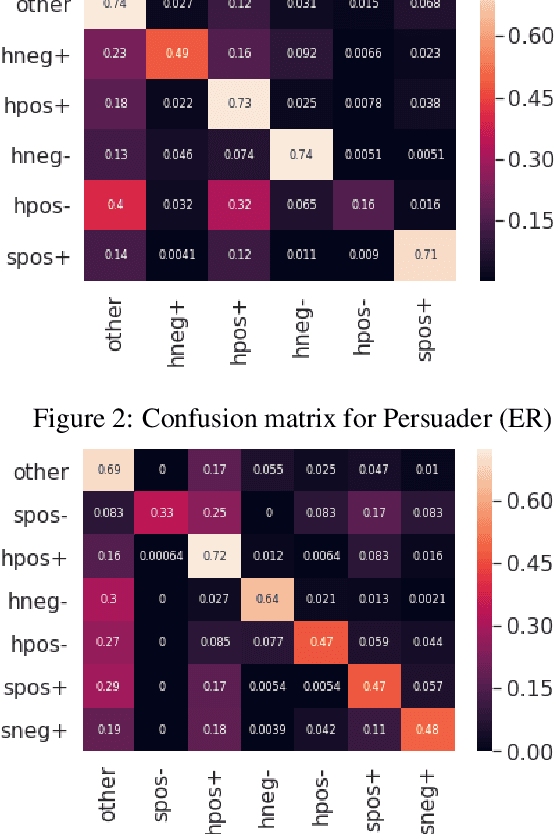
The notion of face refers to the public self-image of an individual that emerges both from the individual's own actions as well as from the interaction with others. Modeling face and understanding its state changes throughout a conversation is critical to the study of maintenance of basic human needs in and through interaction. Grounded in the politeness theory of Brown and Levinson (1978), we propose a generalized framework for modeling face acts in persuasion conversations, resulting in a reliable coding manual, an annotated corpus, and computational models. The framework reveals insights about differences in face act utilization between asymmetric roles in persuasion conversations. Using computational models, we are able to successfully identify face acts as well as predict a key conversational outcome (e.g. donation success). Finally, we model a latent representation of the conversational state to analyze the impact of predicted face acts on the probability of a positive conversational outcome and observe several correlations that corroborate previous findings.
Group Equivariant Generative Adversarial Networks
May 04, 2020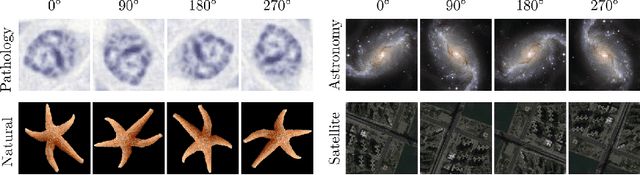
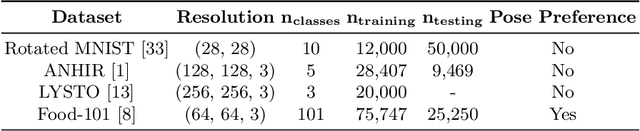
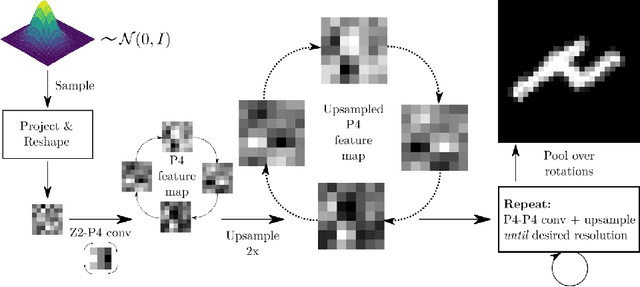
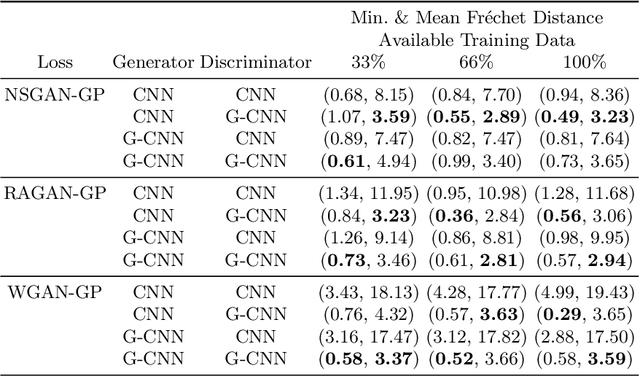
Generative adversarial networks are the state of the art for generative modeling in vision, yet are notoriously unstable in practice. This instability is further exacerbated with limited training data. However, in the synthesis of domains such as medical or satellite imaging, it is often overlooked that the image label is invariant to global image symmetries (e.g., rotations and reflections). In this work, we improve gradient feedback between generator and discriminator using an inductive symmetry prior via group-equivariant convolutional networks. We replace convolutional layers with equivalent group-convolutional layers in both generator and discriminator, allowing for better optimization steps and increased expressive power with limited samples. In the process, we extend recent GAN developments to the group-equivariant setting. We demonstrate the utility of our methods by improving both sample fidelity and diversity in the class-conditional synthesis of a diverse set of globally-symmetric imaging modalities.
Data-Driven Color Augmentation Techniques for Deep Skin Image Analysis
Mar 10, 2017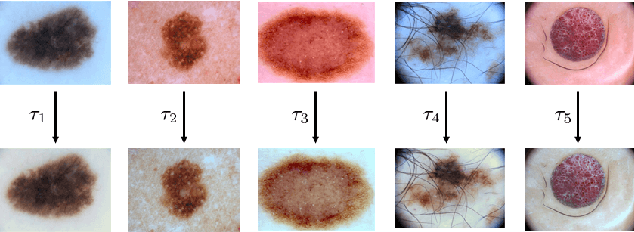
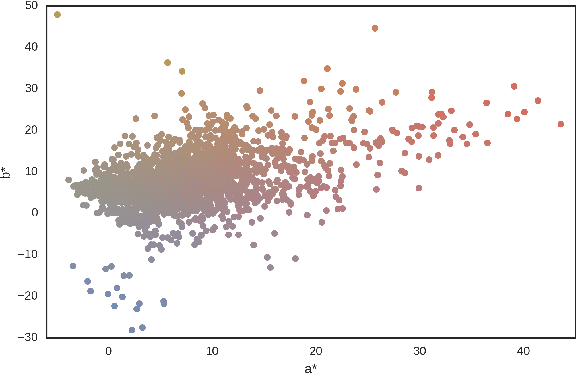

Dermoscopic skin images are often obtained with different imaging devices, under varying acquisition conditions. In this work, instead of attempting to perform intensity and color normalization, we propose to leverage computational color constancy techniques to build an artificial data augmentation technique suitable for this kind of images. Specifically, we apply the \emph{shades of gray} color constancy technique to color-normalize the entire training set of images, while retaining the estimated illuminants. We then draw one sample from the distribution of training set illuminants and apply it on the normalized image. We employ this technique for training two deep convolutional neural networks for the tasks of skin lesion segmentation and skin lesion classification, in the context of the ISIC 2017 challenge and without using any external dermatologic image set. Our results on the validation set are promising, and will be supplemented with extended results on the hidden test set when available.
Learning Arbitrary-Goal Fabric Folding with One Hour of Real Robot Experience
Oct 07, 2020

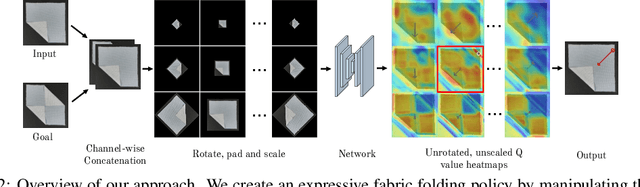
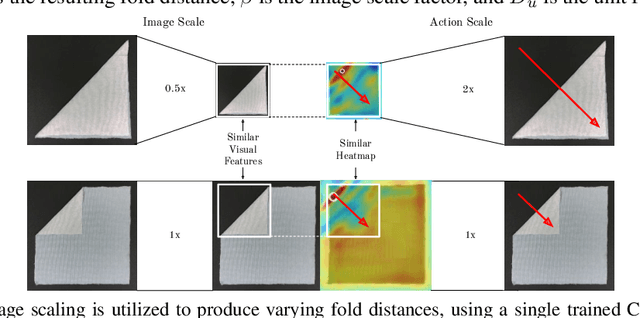
Manipulating deformable objects, such as fabric, is a long standing problem in robotics, with state estimation and control posing a significant challenge for traditional methods. In this paper, we show that it is possible to learn fabric folding skills in only an hour of self-supervised real robot experience, without human supervision or simulation. Our approach relies on fully convolutional networks and the manipulation of visual inputs to exploit learned features, allowing us to create an expressive goal-conditioned pick and place policy that can be trained efficiently with real world robot data only. Folding skills are learned with only a sparse reward function and thus do not require reward function engineering, merely an image of the goal configuration. We demonstrate our method on a set of towel-folding tasks, and show that our approach is able to discover sequential folding strategies, purely from trial-and-error. We achieve state-of-the-art results without the need for demonstrations or simulation, used in prior approaches. Videos available at: https://sites.google.com/view/learningtofold
3D-DEEP: 3-Dimensional Deep-learning based on elevation patterns forroad scene interpretation
Sep 01, 2020

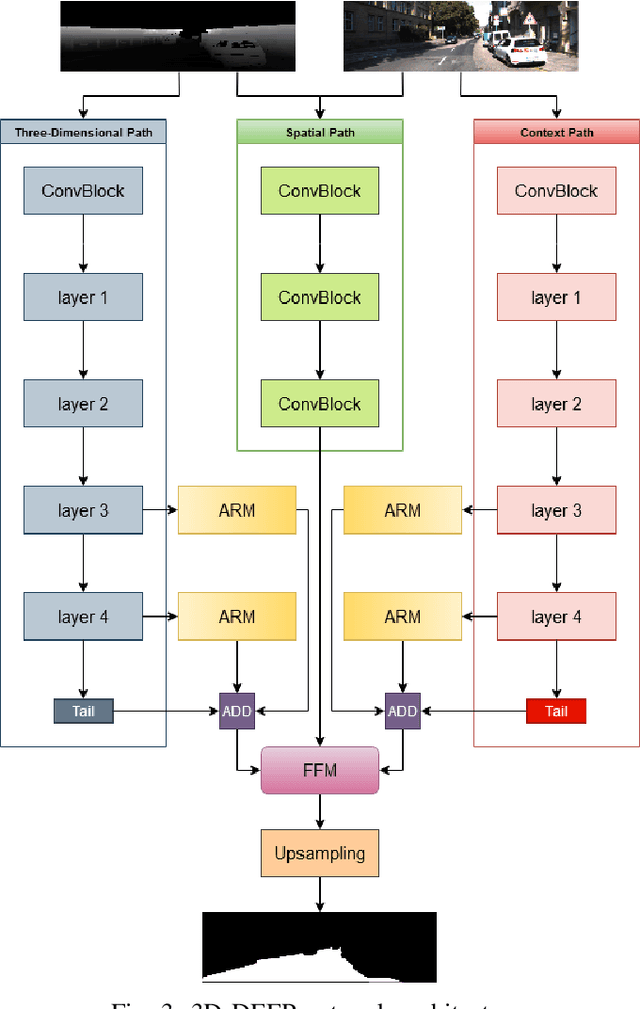
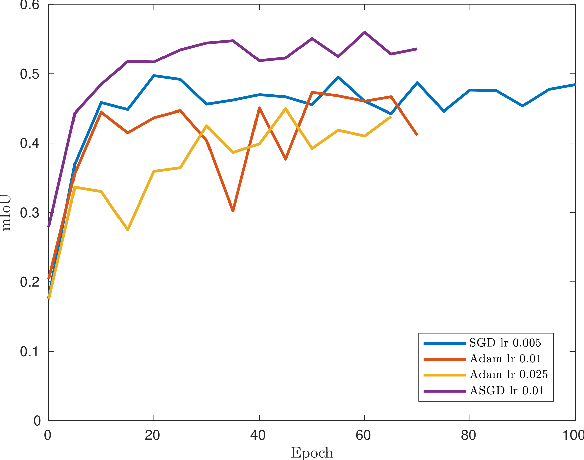
Road detection and segmentation is a crucial task in computer vision for safe autonomous driving. With this in mind, a new net architecture (3D-DEEP) and its end-to-end training methodology for CNN-based semantic segmentation are described along this paper for. The method relies on disparity filtered and LiDAR projected images for three-dimensional information and image feature extraction through fully convolutional networks architectures. The developed models were trained and validated over Cityscapes dataset using just fine annotation examples with 19 different training classes, and over KITTI road dataset. 72.32% mean intersection over union(mIoU) has been obtained for the 19 Cityscapes training classes using the validation images. On the other hand, over KITTIdataset the model has achieved an F1 error value of 97.85% invalidation and 96.02% using the test images.
Combining multiple resolutions into hierarchical representations for kernel-based image classification
Jul 12, 2016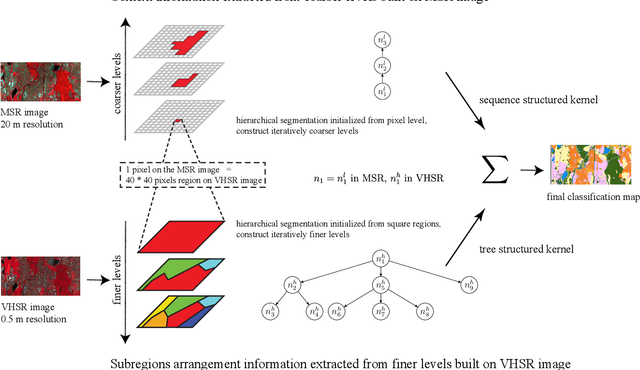
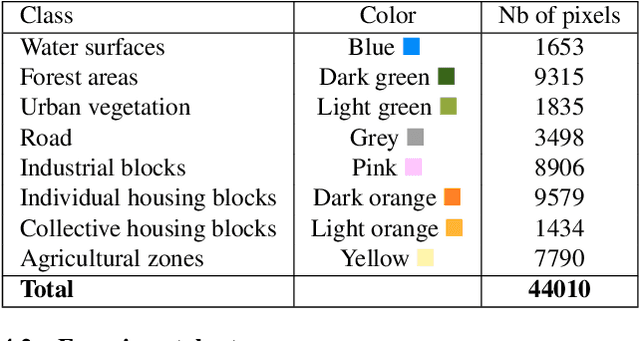
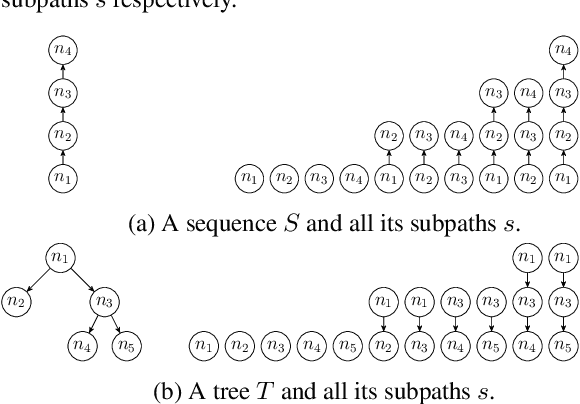
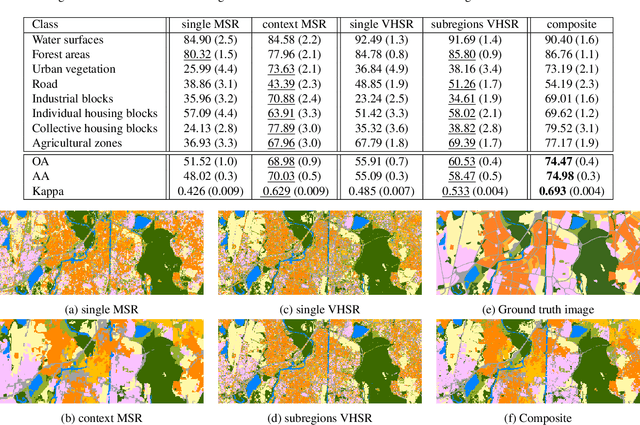
Geographic object-based image analysis (GEOBIA) framework has gained increasing interest recently. Following this popular paradigm, we propose a novel multiscale classification approach operating on a hierarchical image representation built from two images at different resolutions. They capture the same scene with different sensors and are naturally fused together through the hierarchical representation, where coarser levels are built from a Low Spatial Resolution (LSR) or Medium Spatial Resolution (MSR) image while finer levels are generated from a High Spatial Resolution (HSR) or Very High Spatial Resolution (VHSR) image. Such a representation allows one to benefit from the context information thanks to the coarser levels, and subregions spatial arrangement information thanks to the finer levels. Two dedicated structured kernels are then used to perform machine learning directly on the constructed hierarchical representation. This strategy overcomes the limits of conventional GEOBIA classification procedures that can handle only one or very few pre-selected scales. Experiments run on an urban classification task show that the proposed approach can highly improve the classification accuracy w.r.t. conventional approaches working on a single scale.