 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Learning-from-noise Dilated Wide Activation Network for denoising Arterial Spin Labeling (ASL) Perfusion Images
May 15, 2020
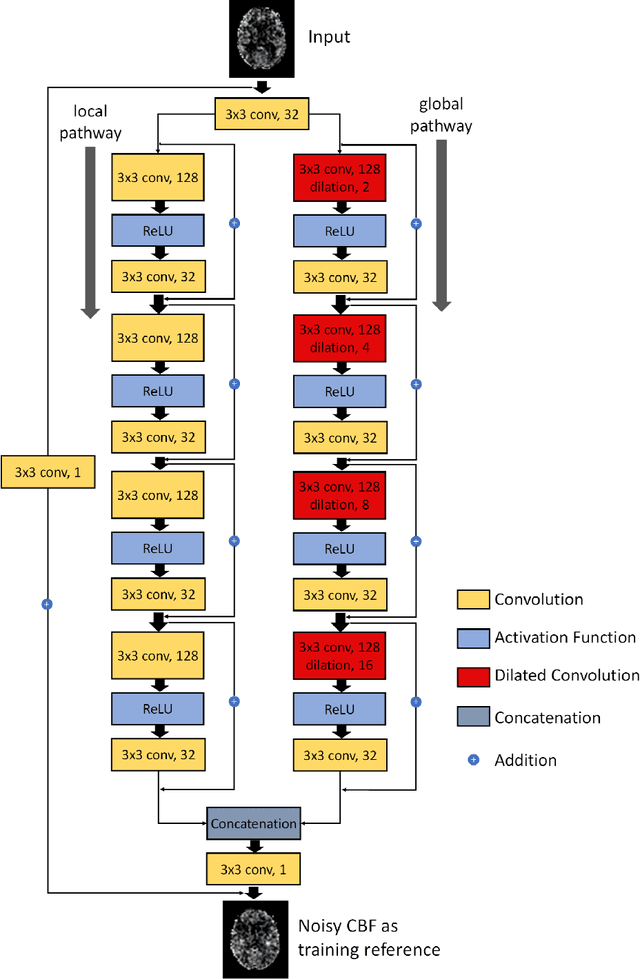
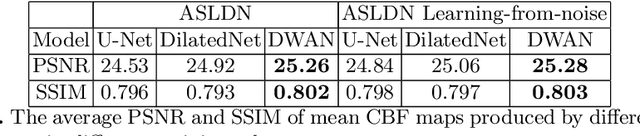
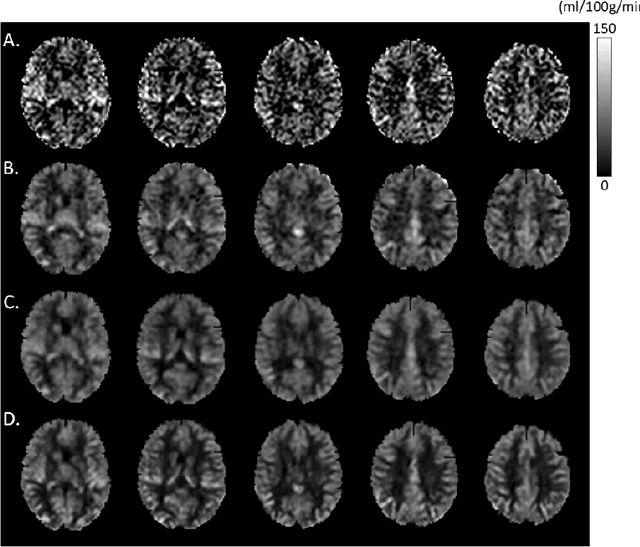
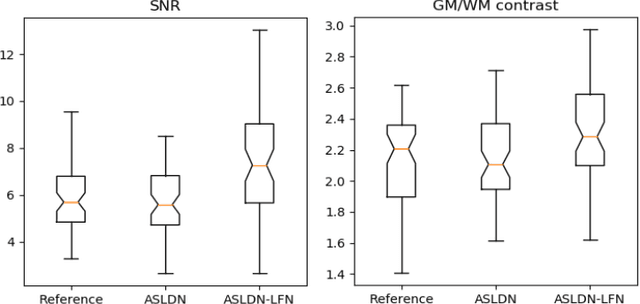
Arterial spin labeling (ASL) perfusion MRI provides a non-invasive way to quantify cerebral blood flow (CBF) but it still suffers from a low signal-to-noise-ratio (SNR). Using deep machine learning (DL), several groups have shown encouraging denoising results. Interestingly, the improvement was obtained when the deep neural network was trained using noise-contaminated surrogate reference because of the lack of golden standard high quality ASL CBF images. More strikingly, the output of these DL ASL networks (ASLDN) showed even higher SNR than the surrogate reference. This phenomenon indicates a learning-from-noise capability of deep networks for ASL CBF image denoising, which can be further enhanced by network optimization. In this study, we proposed a new ASLDN to test whether similar or even better ASL CBF image quality can be achieved in the case of highly noisy training reference. Different experiments were performed to validate the learning-from-noise hypothesis. The results showed that the learning-from-noise strategy produced better output quality than ASLDN trained with relatively high SNR reference.
An Automated Deep Learning Approach for Bacterial Image Classification
Dec 04, 2019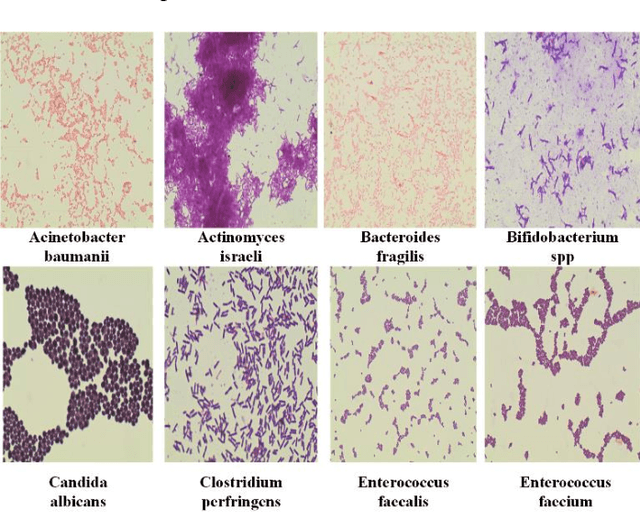
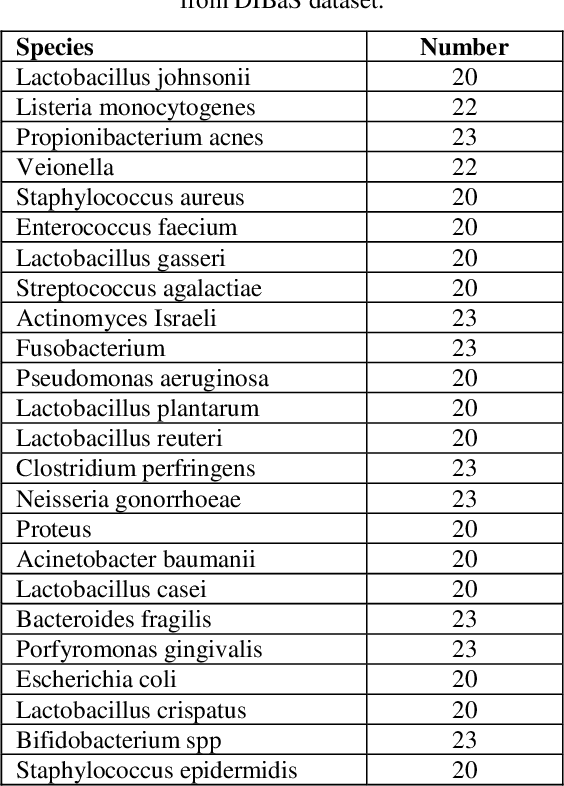
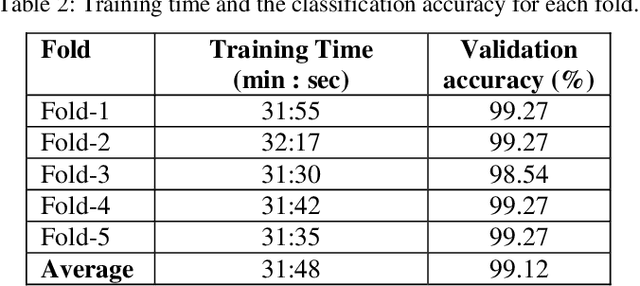
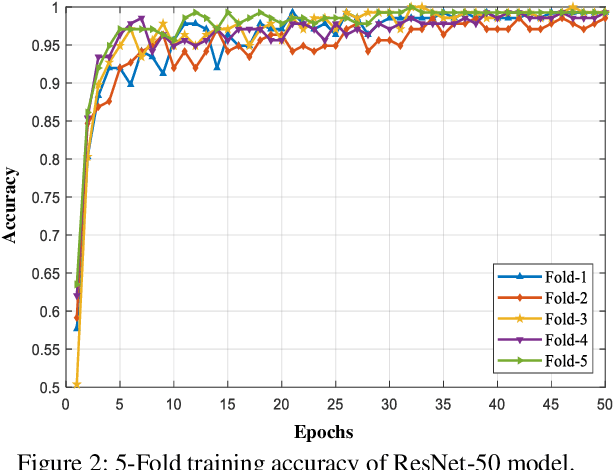
Automated recognition and classification of bacteria species from microscopic images have significant importance in clinical microbiology. Bacteria classification is usually carried out manually by biologists using different shapes and morphologic characteristics of bacteria species. The manual taxonomy of bacteria types from microscopy images is time-consuming and a challenging task for even experienced biologists. In this study, an automated deep learning based classification approach has been proposed to classify bacterial images into different categories. The ResNet-50 pre-trained CNN architecture has been used to classify digital bacteria images into 33 categories. The transfer learning technique was employed to accelerate the training process of the network and improve the classification performance of the network. The proposed method achieved an average classification accuracy of 99.2%. The experimental results demonstrate that the proposed technique surpasses state-of-the-art methods in the literature and can be used for any type of bacteria classification tasks.
DualVD: An Adaptive Dual Encoding Model for Deep Visual Understanding in Visual Dialogue
Nov 17, 2019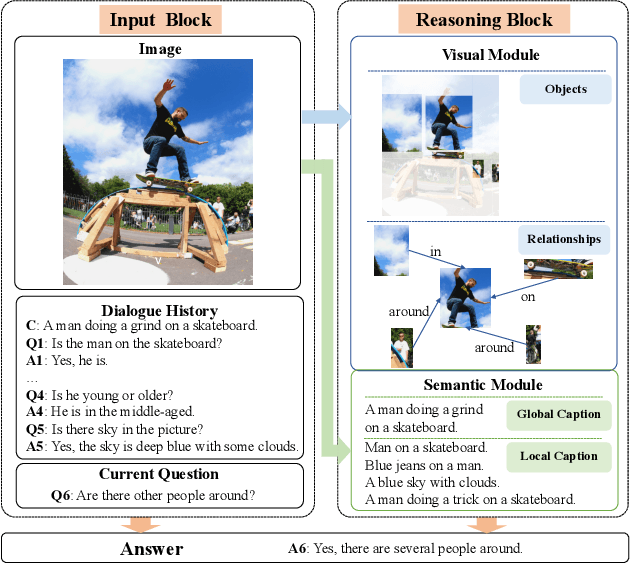
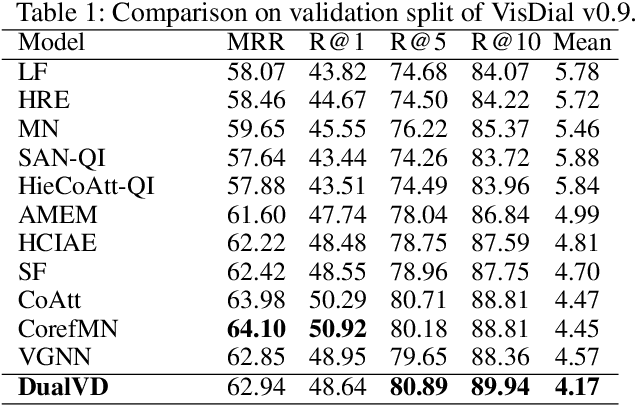
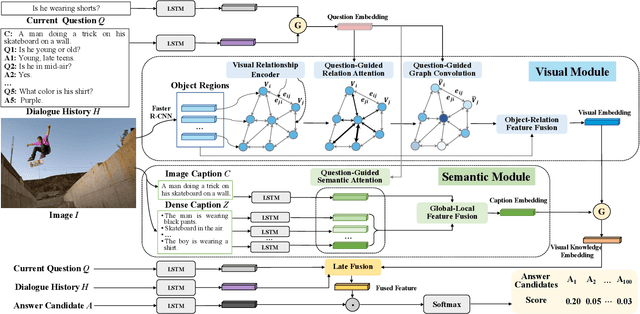
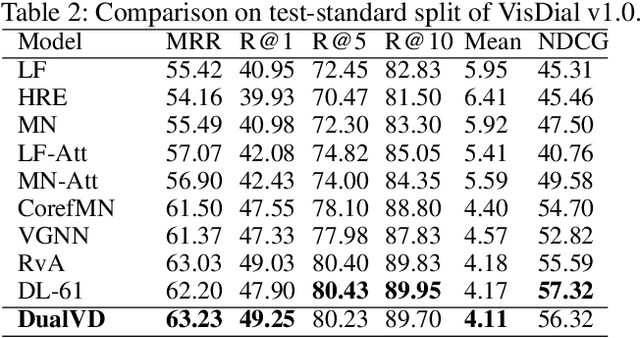
Different from Visual Question Answering task that requires to answer only one question about an image, Visual Dialogue involves multiple questions which cover a broad range of visual content that could be related to any objects, relationships or semantics. The key challenge in Visual Dialogue task is thus to learn a more comprehensive and semantic-rich image representation which may have adaptive attentions on the image for variant questions. In this research, we propose a novel model to depict an image from both visual and semantic perspectives. Specifically, the visual view helps capture the appearance-level information, including objects and their relationships, while the semantic view enables the agent to understand high-level visual semantics from the whole image to the local regions. Futhermore, on top of such multi-view image features, we propose a feature selection framework which is able to adaptively capture question-relevant information hierarchically in fine-grained level. The proposed method achieved state-of-the-art results on benchmark Visual Dialogue datasets. More importantly, we can tell which modality (visual or semantic) has more contribution in answering the current question by visualizing the gate values. It gives us insights in understanding of human cognition in Visual Dialogue.
Player Identification in Hockey Broadcast Videos
Sep 14, 2020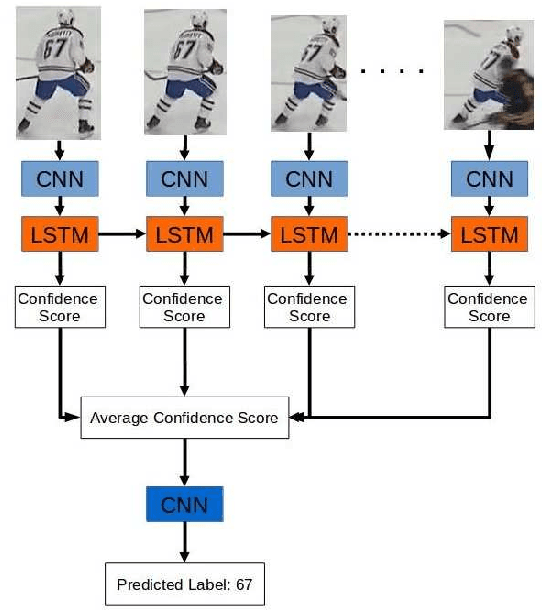
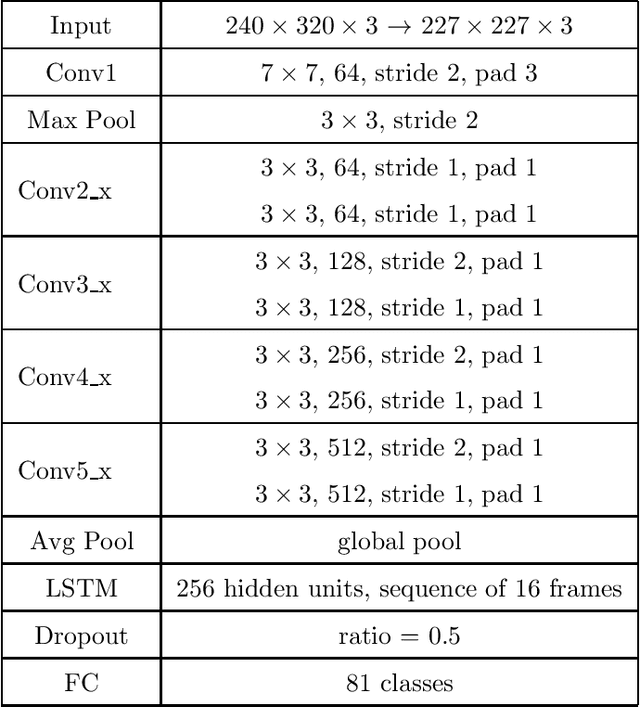
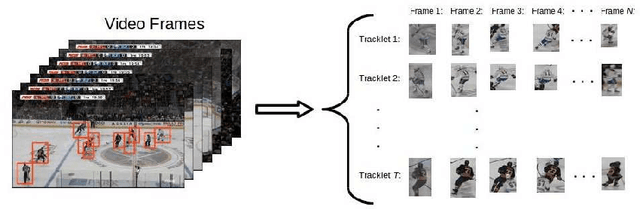
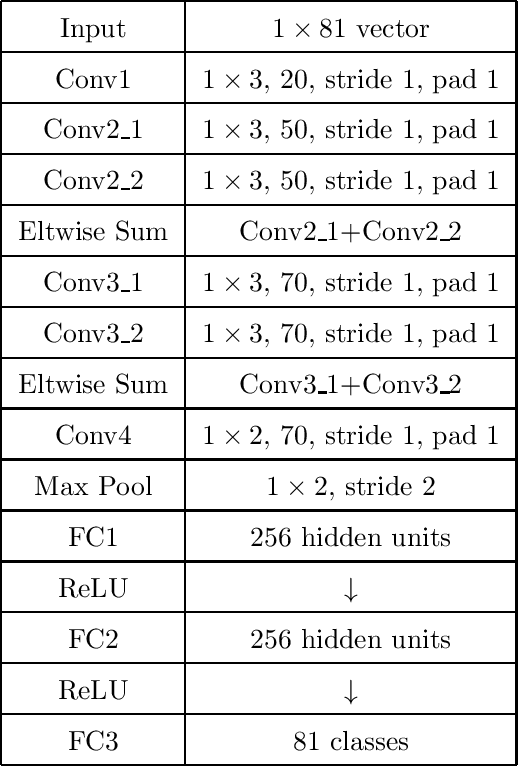
We present a deep recurrent convolutional neural network (CNN) approach to solve the problem of hockey player identification in NHL broadcast videos. Player identification is a difficult computer vision problem mainly because of the players' similar appearance, occlusion, and blurry facial and physical features. However, we can observe players' jersey numbers over time by processing variable length image sequences of players (aka 'tracklets'). We propose an end-to-end trainable ResNet+LSTM network, with a residual network (ResNet) base and a long short-term memory (LSTM) layer, to discover spatio-temporal features of jersey numbers over time and learn long-term dependencies. For this work, we created a new hockey player tracklet dataset that contains sequences of hockey player bounding boxes. Additionally, we employ a secondary 1-dimensional convolutional neural network classifier as a late score-level fusion method to classify the output of the ResNet+LSTM network. This achieves an overall player identification accuracy score over 87% on the test split of our new dataset.
Mutual Information Regularized Identity-aware Facial ExpressionRecognition in Compressed Video
Oct 20, 2020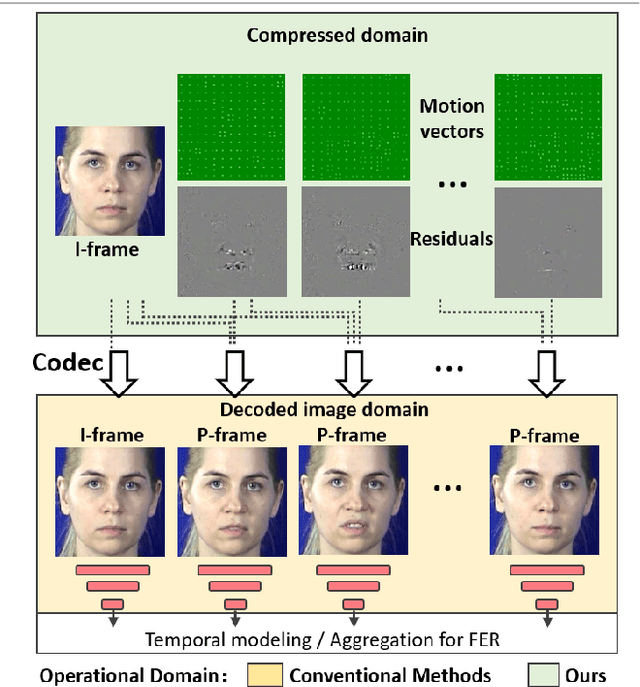
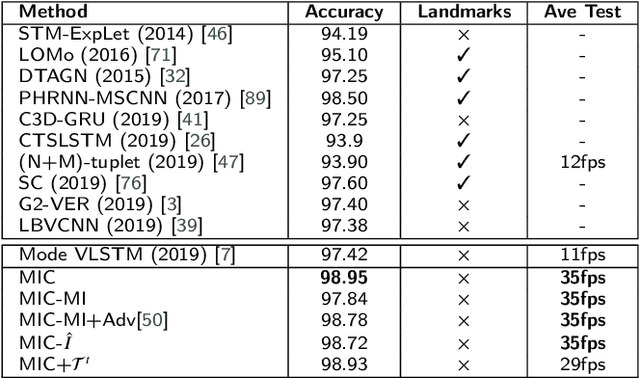
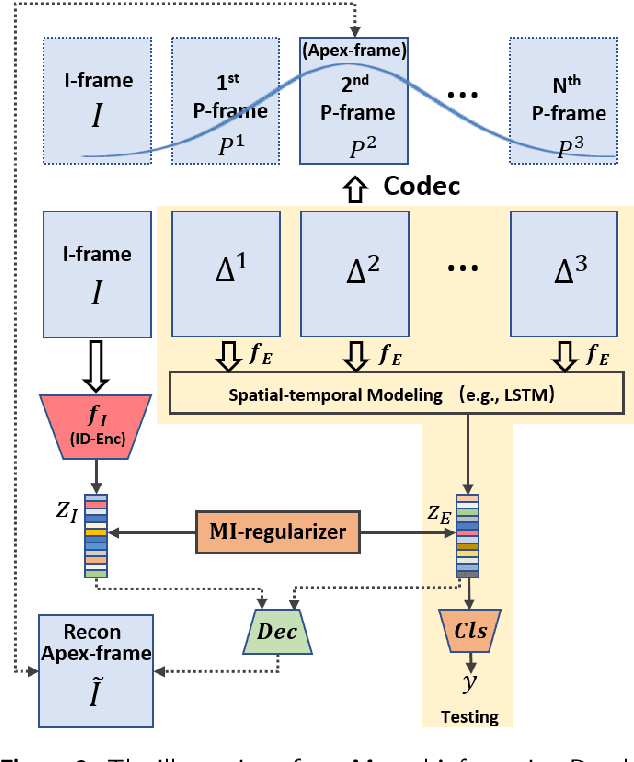
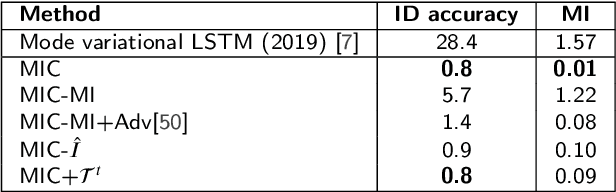
This paper targets to explore the inter-subject variations eliminated facial expression representation in the compressed video domain. Most of the previous methods process the RGB images of a sequence, while the off-the-shelf and valuable expression-related muscle movement already embedded in the compression format. In the up to two orders of magnitude compressed domain, we can explicitly infer the expression from the residual frames and possible to extract identity factors from the I frame with a pre-trained face recognition network. By enforcing the marginal independent of them, the expression feature is expected to be purer for the expression and be robust to identity shifts. Specifically, we propose a novel collaborative min-min game for mutual information (MI) minimization in latent space. We do not need the identity label or multiple expression samples from the same person for identity elimination. Moreover, when the apex frame is annotated in the dataset, the complementary constraint can be further added to regularize the feature-level game. In testing, only the compressed residual frames are required to achieve expression prediction. Our solution can achieve comparable or better performance than the recent decoded image-based methods on the typical FER benchmarks with about 3 times faster inference.
Interpreting convolutional networks trained on textual data
Oct 20, 2020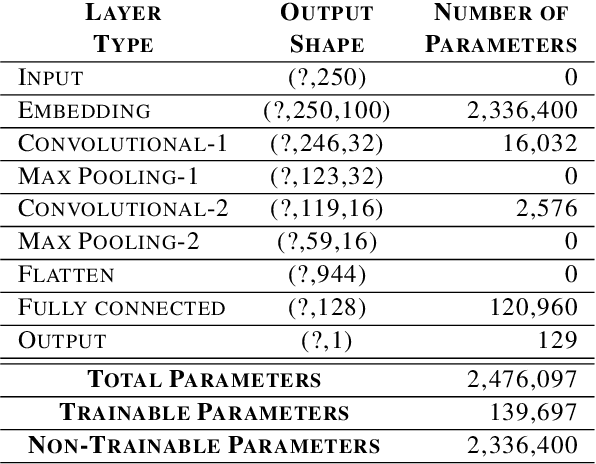
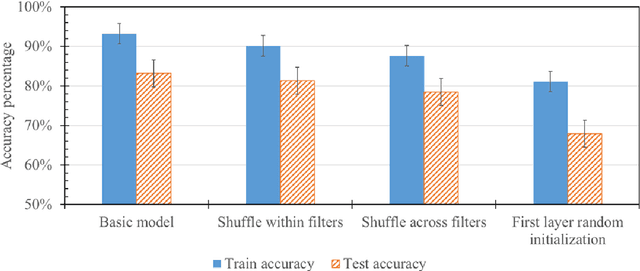

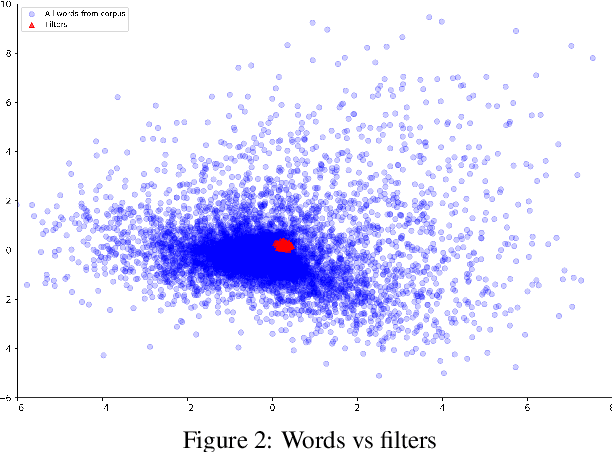
There have been many advances in the artificial intelligence field due to the emergence of deep learning. In almost all sub-fields, artificial neural networks have reached or exceeded human-level performance. However, most of the models are not interpretable. As a result, it is hard to trust their decisions, especially in life and death scenarios. In recent years, there has been a movement toward creating explainable artificial intelligence, but most work to date has concentrated on image processing models, as it is easier for humans to perceive visual patterns. There has been little work in other fields like natural language processing. In this paper, we train a convolutional model on textual data and analyze the global logic of the model by studying its filter values. In the end, we find the most important words in our corpus to our models logic and remove the rest (95%). New models trained on just the 5% most important words can achieve the same performance as the original model while reducing training time by more than half. Approaches such as this will help us to understand NLP models, explain their decisions according to their word choices, and improve them by finding blind spots and biases.
Exploring the Efficacy of Transfer Learning in Mining Image-Based Software Artifacts
Mar 03, 2020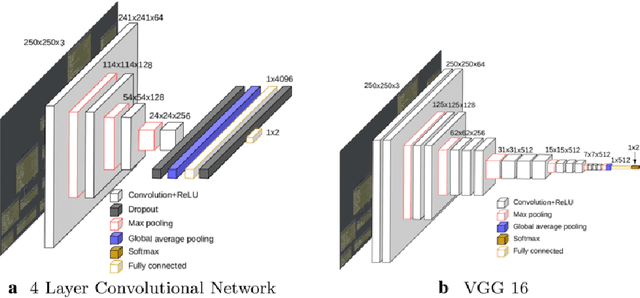
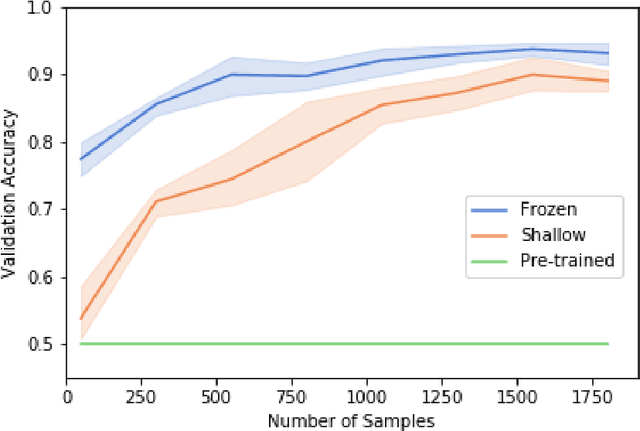
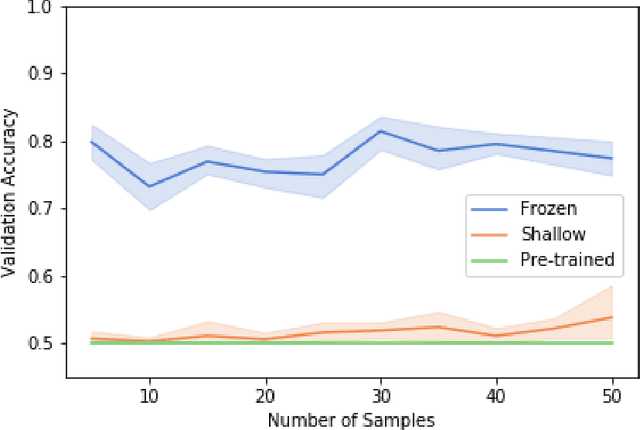
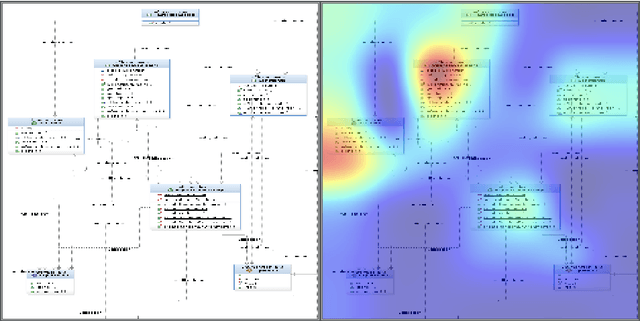
Transfer learning allows us to train deep architectures requiring a large number of learned parameters, even if the amount of available data is limited, by leveraging existing models previously trained for another task. Here we explore the applicability of transfer learning utilizing models pre-trained on non-software engineering data applied to the problem of classifying software UML diagrams. Our experimental results show training reacts positively to transfer learning as related to sample size, even though the pre-trained model was not exposed to training instances from the software domain. We contrast the transferred network with other networks to show its advantage on different sized training sets, which indicates that transfer learning is equally effective to custom deep architectures when large amounts of training data is not available.
Interpretable and Globally Optimal Prediction for Textual Grounding using Image Concepts
Mar 29, 2018
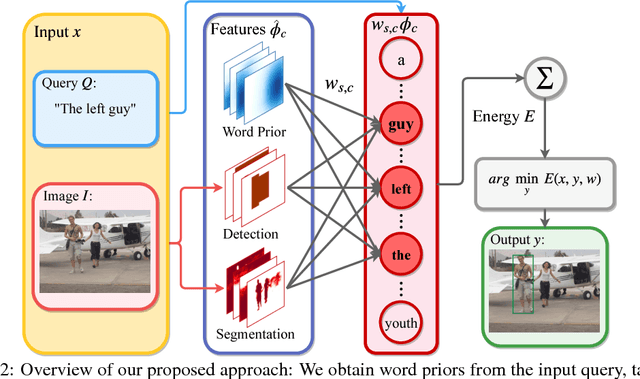
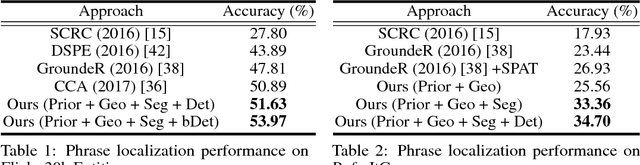

Textual grounding is an important but challenging task for human-computer interaction, robotics and knowledge mining. Existing algorithms generally formulate the task as selection from a set of bounding box proposals obtained from deep net based systems. In this work, we demonstrate that we can cast the problem of textual grounding into a unified framework that permits efficient search over all possible bounding boxes. Hence, the method is able to consider significantly more proposals and doesn't rely on a successful first stage hypothesizing bounding box proposals. Beyond, we demonstrate that the trained parameters of our model can be used as word-embeddings which capture spatial-image relationships and provide interpretability. Lastly, at the time of submission, our approach outperformed the current state-of-the-art methods on the Flickr 30k Entities and the ReferItGame dataset by 3.08% and 7.77% respectively.
"The cracks that wanted to be a graph": application of image processing and Graph Neural Networks to the description of craquelure patterns
May 13, 2019
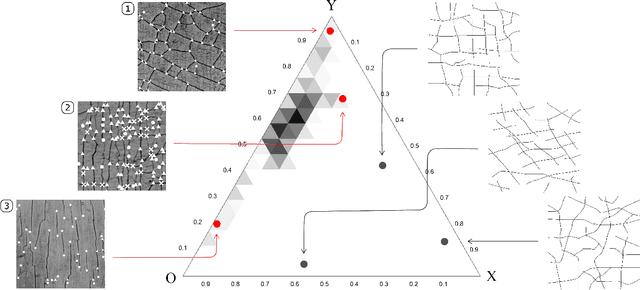

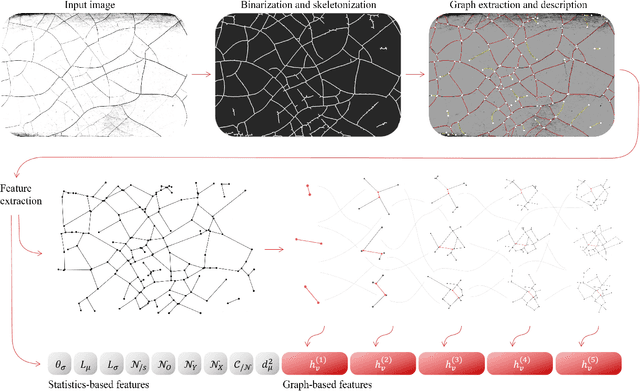
Cracks on a painting is not a defect but an inimitable signature of an artwork which can be used for origin examination, aging monitoring, damage identification, and even forgery detection. This work presents the development of a new methodology and corresponding toolbox for the extraction and characterization of information from an image of a craquelure pattern. The proposed approach processes craquelure network as a graph. The graph representation captures the network structure via mutual organization of junctions and fractures. Furthermore, it is invariant to any geometrical distortions. At the same time, our tool extracts the properties of each node and edge individually, which allows to characterize the pattern statistically. We illustrate benefits from the graph representation and statistical features individually using novel Graph Neural Network and hand-crafted descriptors correspondingly. However, we also show that the best performance is achieved when both techniques are merged into one framework. We perform experiments on the dataset for paintings' origin classification and demonstrate that our approach outperforms existing techniques by a large margin.
ZoomCount: A Zooming Mechanism for Crowd Counting in Static Images
Feb 27, 2020


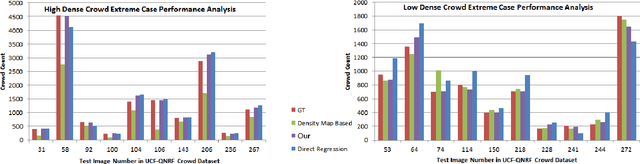
This paper proposes a novel approach for crowd counting in low to high density scenarios in static images. Current approaches cannot handle huge crowd diversity well and thus perform poorly in extreme cases, where the crowd density in different regions of an image is either too low or too high, leading to crowd underestimation or overestimation. The proposed solution is based on the observation that detecting and handling such extreme cases in a specialized way leads to better crowd estimation. Additionally, existing methods find it hard to differentiate between the actual crowd and the cluttered background regions, resulting in further count overestimation. To address these issues, we propose a simple yet effective modular approach, where an input image is first subdivided into fixed-size patches and then fed to a four-way classification module labeling each image patch as low, medium, high-dense or no-crowd. This module also provides a count for each label, which is then analyzed via a specifically devised novel decision module to decide whether the image belongs to any of the two extreme cases (very low or very high density) or a normal case. Images, specified as high- or low-density extreme or a normal case, pass through dedicated zooming or normal patch-making blocks respectively before routing to the regressor in the form of fixed-size patches for crowd estimate. Extensive experimental evaluations demonstrate that the proposed approach outperforms the state-of-the-art methods on four benchmarks under most of the evaluation criteria.