 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Interpreting convolutional networks trained on textual data
Oct 20, 2020
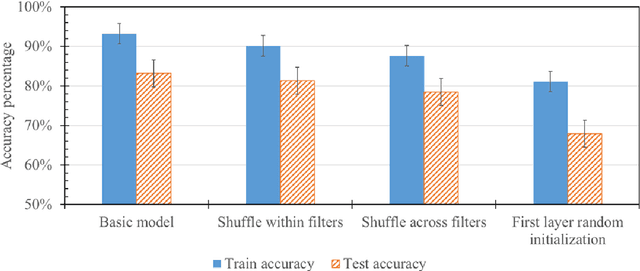

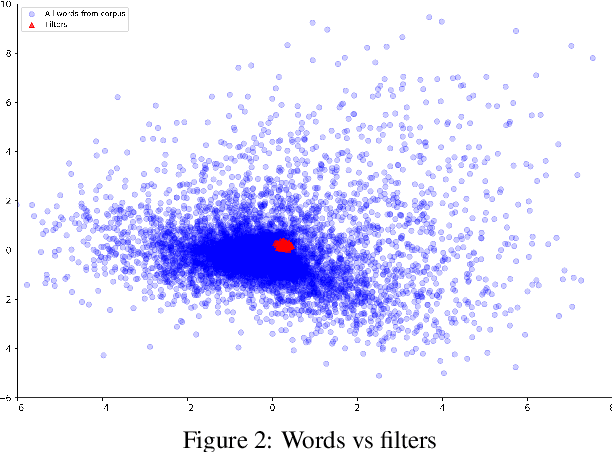
There have been many advances in the artificial intelligence field due to the emergence of deep learning. In almost all sub-fields, artificial neural networks have reached or exceeded human-level performance. However, most of the models are not interpretable. As a result, it is hard to trust their decisions, especially in life and death scenarios. In recent years, there has been a movement toward creating explainable artificial intelligence, but most work to date has concentrated on image processing models, as it is easier for humans to perceive visual patterns. There has been little work in other fields like natural language processing. In this paper, we train a convolutional model on textual data and analyze the global logic of the model by studying its filter values. In the end, we find the most important words in our corpus to our models logic and remove the rest (95%). New models trained on just the 5% most important words can achieve the same performance as the original model while reducing training time by more than half. Approaches such as this will help us to understand NLP models, explain their decisions according to their word choices, and improve them by finding blind spots and biases.
Player Identification in Hockey Broadcast Videos
Sep 14, 2020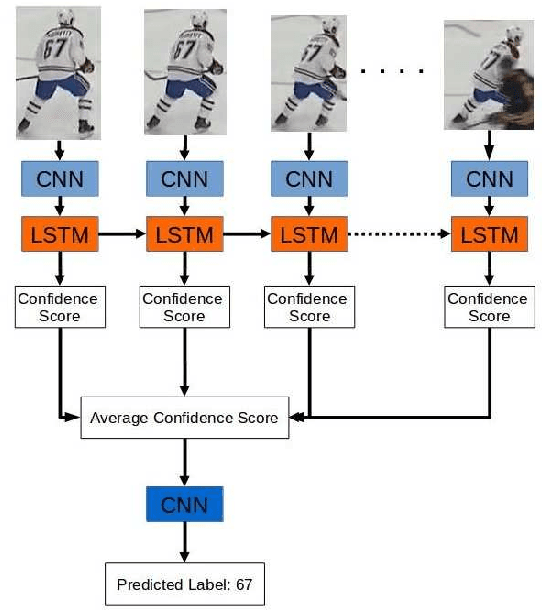
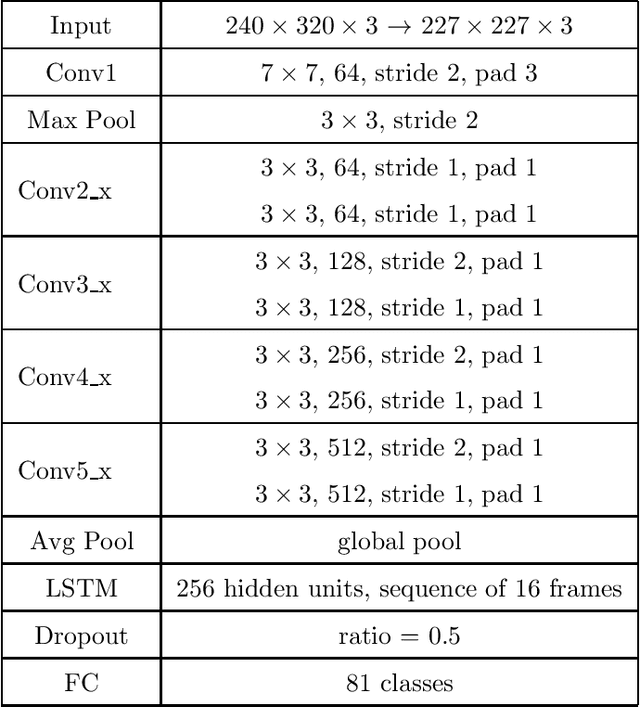
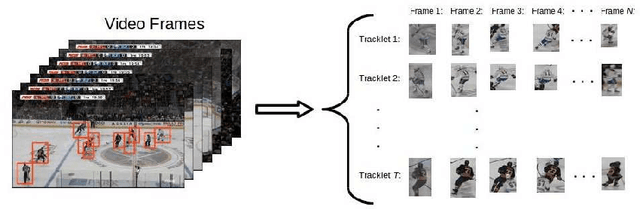
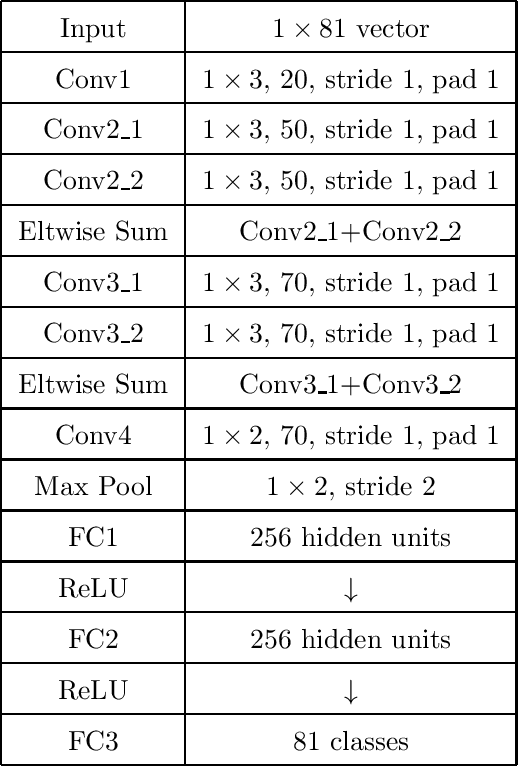
We present a deep recurrent convolutional neural network (CNN) approach to solve the problem of hockey player identification in NHL broadcast videos. Player identification is a difficult computer vision problem mainly because of the players' similar appearance, occlusion, and blurry facial and physical features. However, we can observe players' jersey numbers over time by processing variable length image sequences of players (aka 'tracklets'). We propose an end-to-end trainable ResNet+LSTM network, with a residual network (ResNet) base and a long short-term memory (LSTM) layer, to discover spatio-temporal features of jersey numbers over time and learn long-term dependencies. For this work, we created a new hockey player tracklet dataset that contains sequences of hockey player bounding boxes. Additionally, we employ a secondary 1-dimensional convolutional neural network classifier as a late score-level fusion method to classify the output of the ResNet+LSTM network. This achieves an overall player identification accuracy score over 87% on the test split of our new dataset.
Does Normalization Methods Play a Role for Hyperspectral Image Classification?
Oct 09, 2017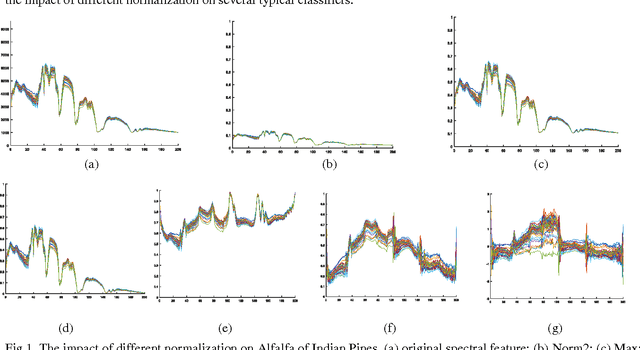
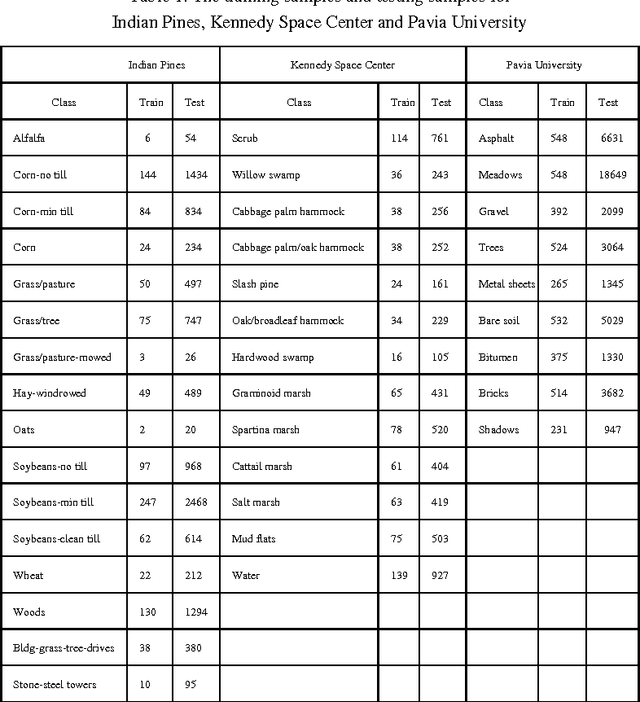
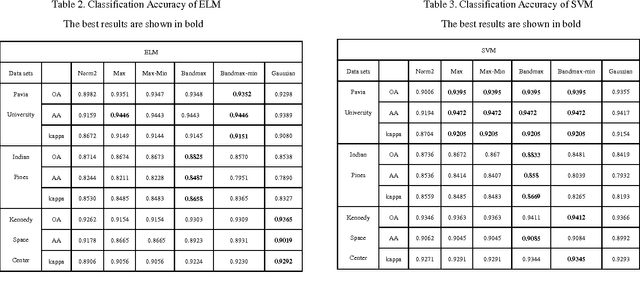
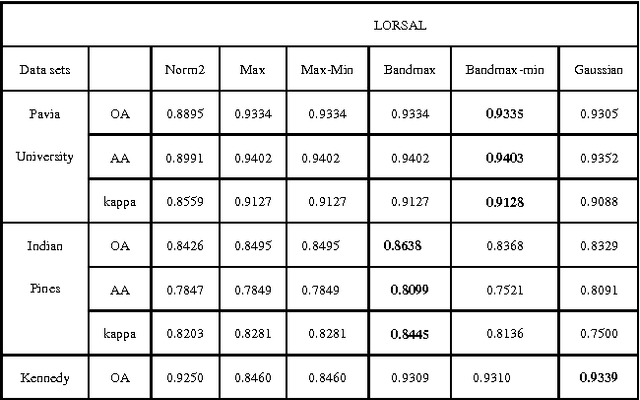
For Hyperspectral image (HSI) datasets, each class have their salient feature and classifiers classify HSI datasets according to the class's saliency features, however, there will be different salient features when use different normalization method. In this letter, we report the effect on classifiers by different normalization methods and recommend the best normalization methods for classifier after analyzing the impact of different normalization methods on classifiers. Pavia University datasets, Indian Pines datasets and Kennedy Space Center datasets will apply to several typical classifiers in order to evaluate and analysis the impact of different normalization methods on typical classifiers.
SegET: Deep Neural Network with Rich Contextual Features for Cellular Structures Segmentation in Electron Tomography Image
Nov 28, 2018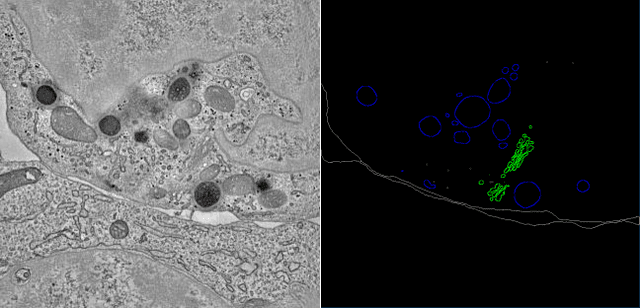
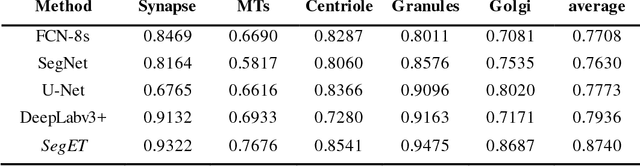
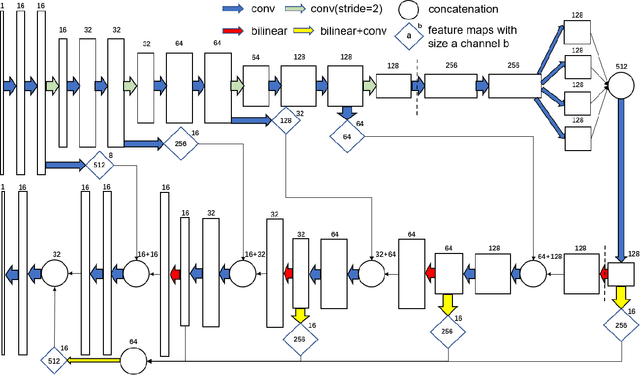
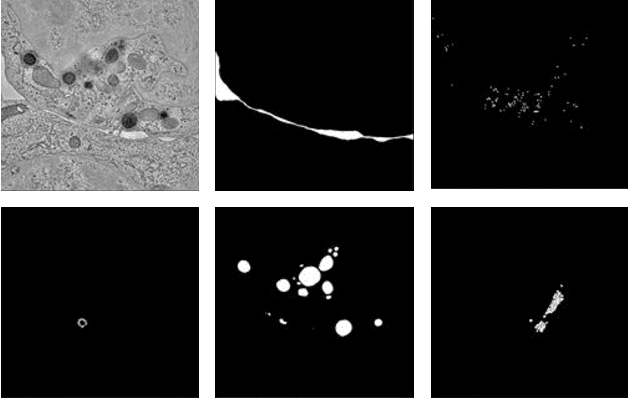
Electron tomography (ET) allows high-resolution reconstructions of macromolecular complexes at nearnative state. Cellular structures segmentation in the reconstruction data from electron tomographic images is often required for analyzing and visualizing biological structures, making it a powerful tool for quantitative descriptions of whole cell structures and understanding biological functions. However, these cellular structures are rather difficult to automatically separate or quantify from view owing to complex molecular environment and the limitations of reconstruction data of ET. In this paper, we propose a single end-to-end deep fully-convolutional semantic segmentation network dubbed SegET with rich contextual features which fully exploitsthe multi-scale and multi-level contextual information and reduces the loss of details of cellular structures in ET images. We trained and evaluated our network on the electron tomogram of the CTL Immunological Synapse from Cell Image library. Our results demonstrate that SegET can automatically segment accurately and outperform all other baseline methods on each individual structure in our ET dataset.
A Learning-from-noise Dilated Wide Activation Network for denoising Arterial Spin Labeling (ASL) Perfusion Images
May 15, 2020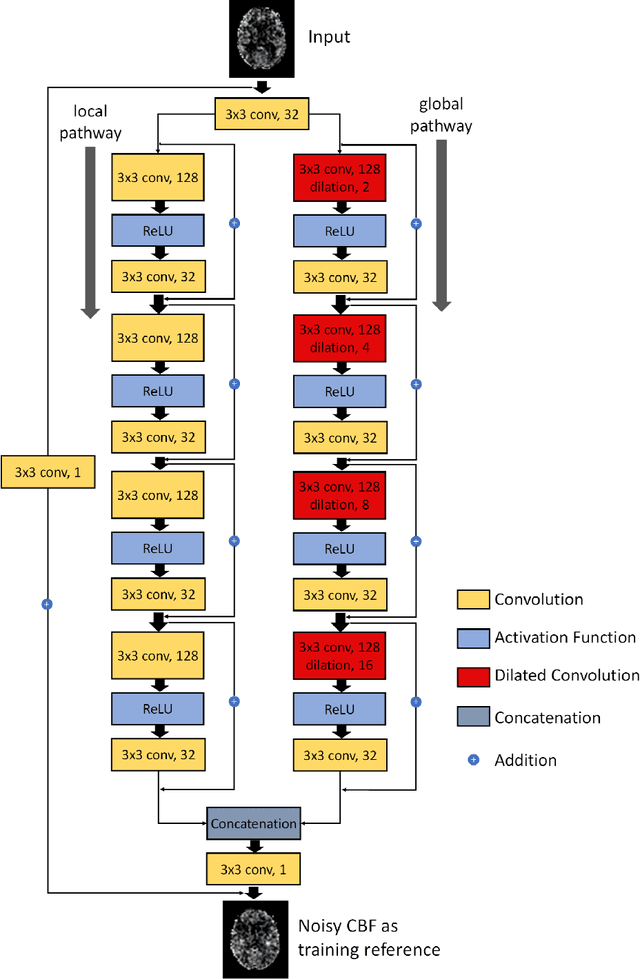
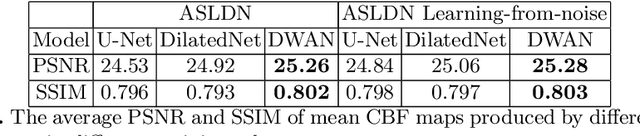
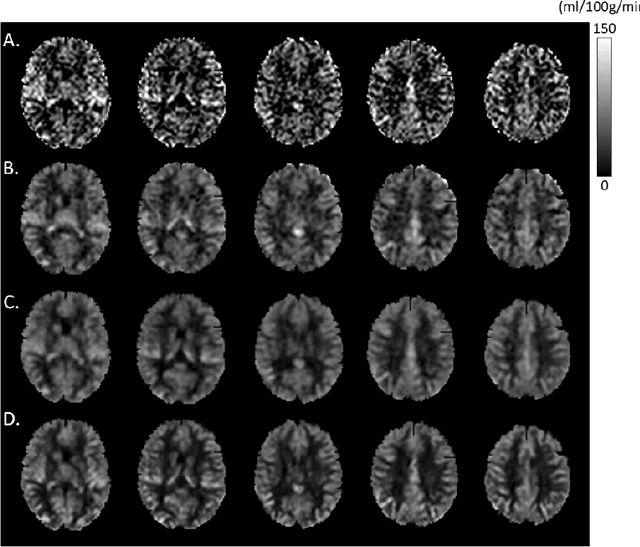
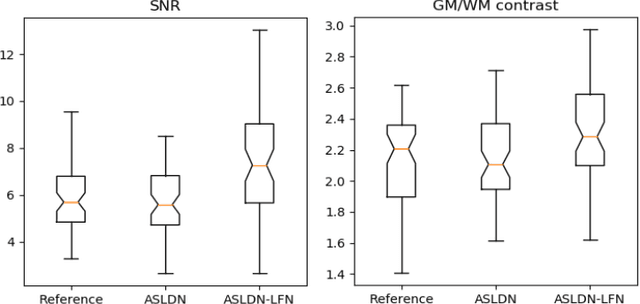
Arterial spin labeling (ASL) perfusion MRI provides a non-invasive way to quantify cerebral blood flow (CBF) but it still suffers from a low signal-to-noise-ratio (SNR). Using deep machine learning (DL), several groups have shown encouraging denoising results. Interestingly, the improvement was obtained when the deep neural network was trained using noise-contaminated surrogate reference because of the lack of golden standard high quality ASL CBF images. More strikingly, the output of these DL ASL networks (ASLDN) showed even higher SNR than the surrogate reference. This phenomenon indicates a learning-from-noise capability of deep networks for ASL CBF image denoising, which can be further enhanced by network optimization. In this study, we proposed a new ASLDN to test whether similar or even better ASL CBF image quality can be achieved in the case of highly noisy training reference. Different experiments were performed to validate the learning-from-noise hypothesis. The results showed that the learning-from-noise strategy produced better output quality than ASLDN trained with relatively high SNR reference.
Multi-Scale Superpatch Matching using Dual Superpixel Descriptors
Mar 09, 2020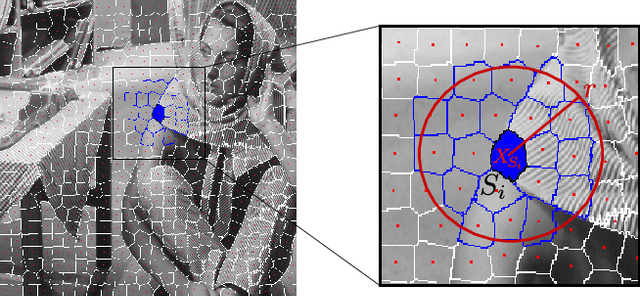
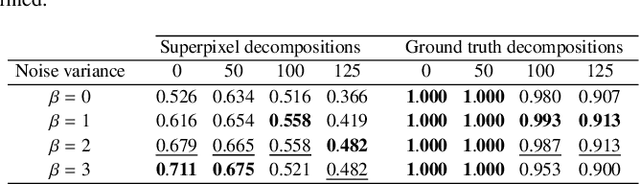
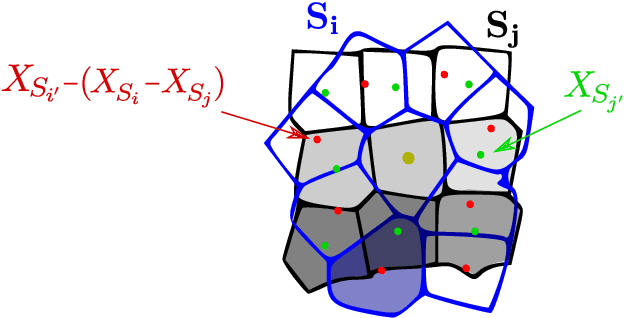
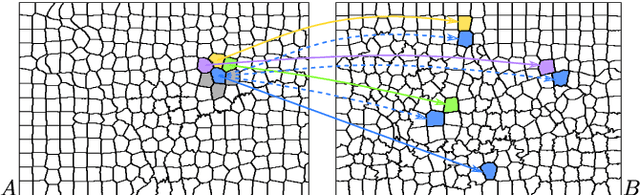
Over-segmentation into superpixels is a very effective dimensionality reduction strategy, enabling fast dense image processing. The main issue of this approach is the inherent irregularity of the image decomposition compared to standard hierarchical multi-resolution schemes, especially when searching for similar neighboring patterns. Several works have attempted to overcome this issue by taking into account the region irregularity into their comparison model. Nevertheless, they remain sub-optimal to provide robust and accurate superpixel neighborhood descriptors, since they only compute features within each region, poorly capturing contour information at superpixel borders. In this work, we address these limitations by introducing the dual superpatch, a novel superpixel neighborhood descriptor. This structure contains features computed in reduced superpixel regions, as well as at the interfaces of multiple superpixels to explicitly capture contour structure information. A fast multi-scale non-local matching framework is also introduced for the search of similar descriptors at different resolution levels in an image dataset. The proposed dual superpatch enables to more accurately capture similar structured patterns at different scales, and we demonstrate the robustness and performance of this new strategy on matching and supervised labeling applications.
AI on the Bog: Monitoring and Evaluating Cranberry Crop Risk
Nov 08, 2020

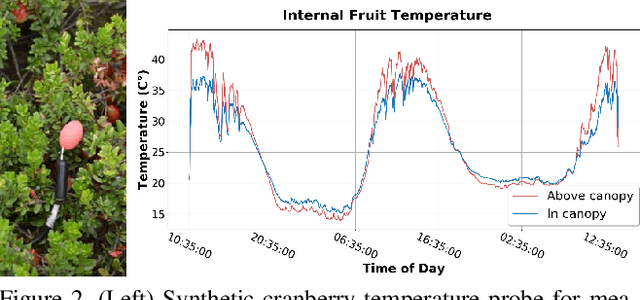

Machine vision for precision agriculture has attracted considerable research interest in recent years. The goal of this paper is to develop an end-to-end cranberry health monitoring system to enable and support real time cranberry over-heating assessment to facilitate informed decisions that may sustain the economic viability of the farm. Toward this goal, we propose two main deep learning-based modules for: 1) cranberry fruit segmentation to delineate the exact fruit regions in the cranberry field image that are exposed to sun, 2) prediction of cloud coverage conditions and sun irradiance to estimate the inner temperature of exposed cranberries. We develop drone-based field data and ground-based sky data collection systems to collect video imagery at multiple time points for use in crop health analysis. Extensive evaluation on the data set shows that it is possible to predict exposed fruit's inner temperature with high accuracy (0.02% MAPE). The sun irradiance prediction error was found to be 8.41-20.36% MAPE in the 5-20 minutes time horizon. With 62.54% mIoU for segmentation and 13.46 MAE for counting accuracies in exposed fruit identification, this system is capable of giving informed feedback to growers to take precautionary action (e.g. irrigation) in identified crop field regions with higher risk of sunburn in the near future. Though this novel system is applied for cranberry health monitoring, it represents a pioneering step forward for efficient farming and is useful in precision agriculture beyond the problem of cranberry overheating.
Cost-Effective Active Learning for Deep Image Classification
Jan 13, 2017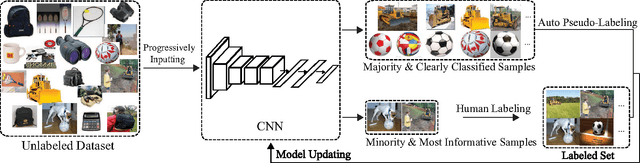

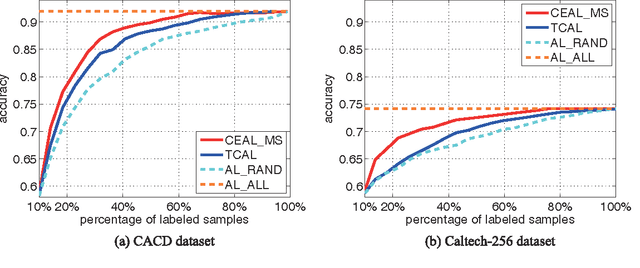
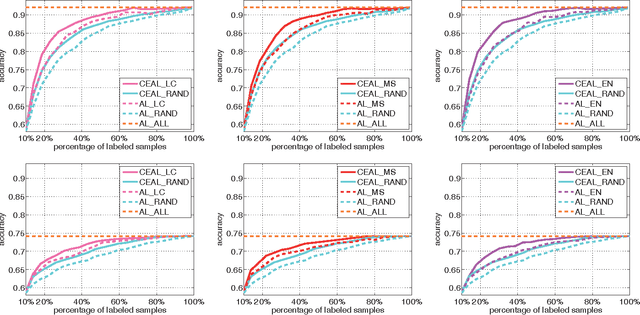
Recent successes in learning-based image classification, however, heavily rely on the large number of annotated training samples, which may require considerable human efforts. In this paper, we propose a novel active learning framework, which is capable of building a competitive classifier with optimal feature representation via a limited amount of labeled training instances in an incremental learning manner. Our approach advances the existing active learning methods in two aspects. First, we incorporate deep convolutional neural networks into active learning. Through the properly designed framework, the feature representation and the classifier can be simultaneously updated with progressively annotated informative samples. Second, we present a cost-effective sample selection strategy to improve the classification performance with less manual annotations. Unlike traditional methods focusing on only the uncertain samples of low prediction confidence, we especially discover the large amount of high confidence samples from the unlabeled set for feature learning. Specifically, these high confidence samples are automatically selected and iteratively assigned pseudo-labels. We thus call our framework "Cost-Effective Active Learning" (CEAL) standing for the two advantages.Extensive experiments demonstrate that the proposed CEAL framework can achieve promising results on two challenging image classification datasets, i.e., face recognition on CACD database [1] and object categorization on Caltech-256 [2].
Network Architecture Search for Domain Adaptation
Aug 13, 2020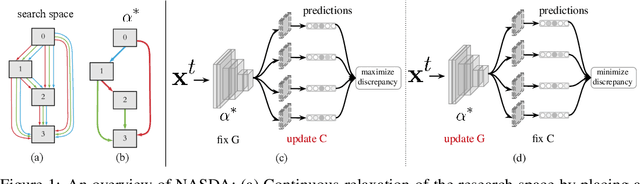
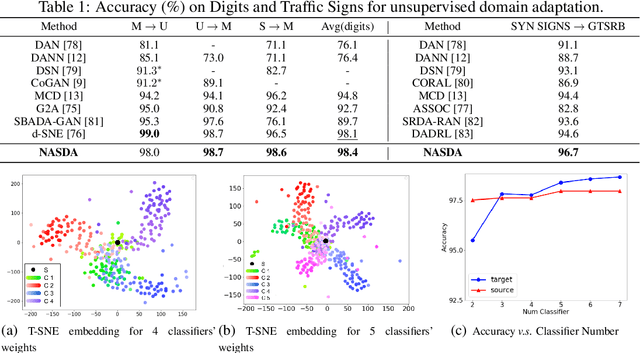
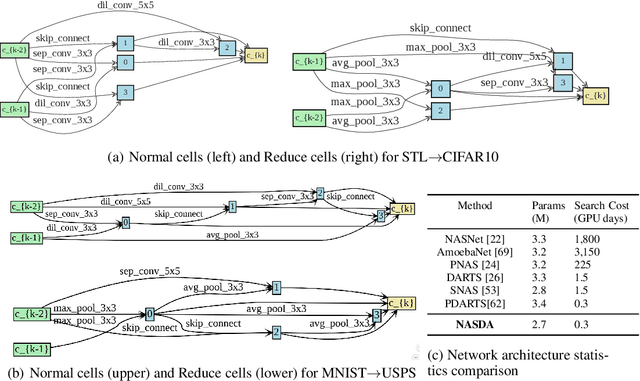
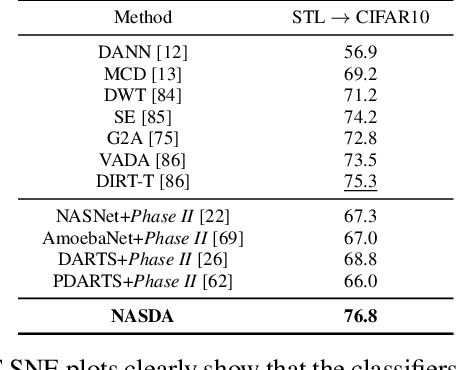
Deep networks have been used to learn transferable representations for domain adaptation. Existing deep domain adaptation methods systematically employ popular hand-crafted networks designed specifically for image-classification tasks, leading to sub-optimal domain adaptation performance. In this paper, we present Neural Architecture Search for Domain Adaptation (NASDA), a principle framework that leverages differentiable neural architecture search to derive the optimal network architecture for domain adaptation task. NASDA is designed with two novel training strategies: neural architecture search with multi-kernel Maximum Mean Discrepancy to derive the optimal architecture, and adversarial training between a feature generator and a batch of classifiers to consolidate the feature generator. We demonstrate experimentally that NASDA leads to state-of-the-art performance on several domain adaptation benchmarks.
DisCont: Self-Supervised Visual Attribute Disentanglement using Context Vectors
Jun 29, 2020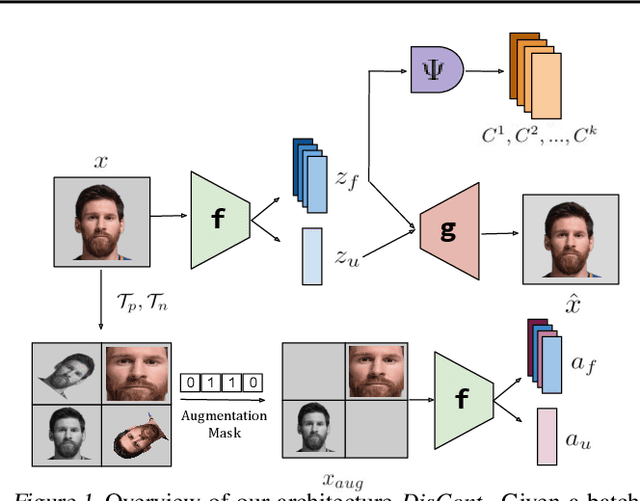
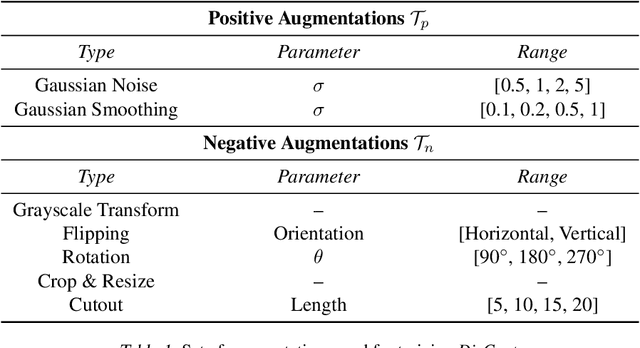
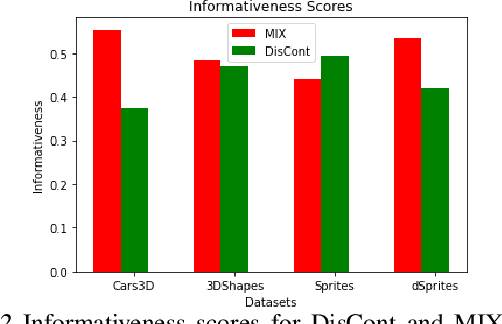

Disentangling the underlying feature attributes within an image with no prior supervision is a challenging task. Models that can disentangle attributes well provide greater interpretability and control. In this paper, we propose a self-supervised framework DisCont to disentangle multiple attributes by exploiting the structural inductive biases within images. Motivated by the recent surge in contrastive learning paradigms, our model bridges the gap between self-supervised contrastive learning algorithms and unsupervised disentanglement. We evaluate the efficacy of our approach, both qualitatively and quantitatively, on four benchmark datasets.