 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Quantifying Explainability of Saliency Methods in Deep Neural Networks
Sep 07, 2020

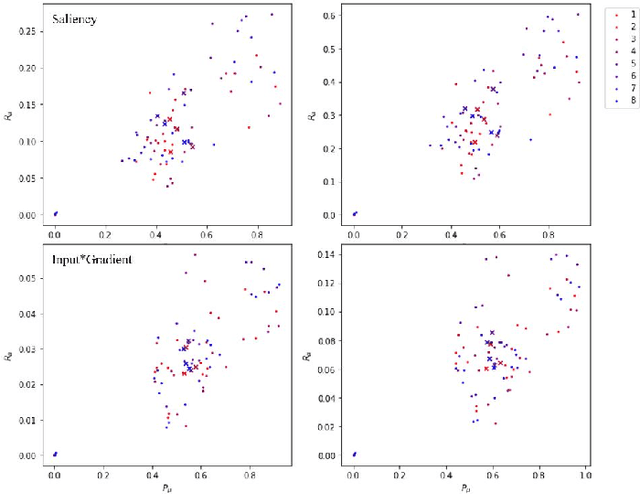

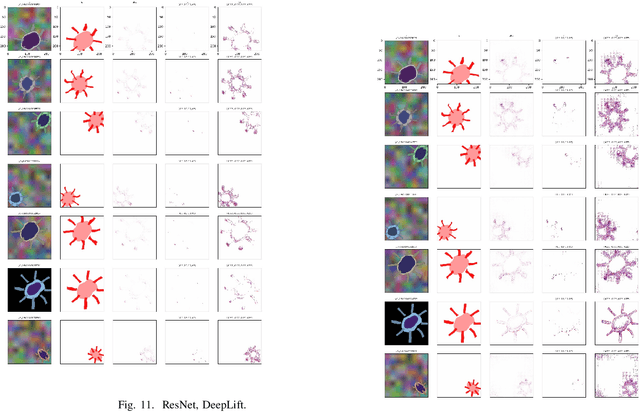
One way to achieve eXplainable artificial intelligence (XAI) is through the use of post-hoc analysis methods. In particular, methods that generate heatmaps have been used to explain black-box models, such as deep neural network. In some cases, heatmaps are appealing due to the intuitive and visual ways to understand them. However, quantitative analysis that demonstrates the actual potential of heatmaps have been lacking, and comparison between different methods are not standardized as well. In this paper, we introduce a synthetic data that can be generated adhoc along with the ground-truth heatmaps for better quantitative assessment. Each sample data is an image of a cell with easily distinguishable features, facilitating a more transparent assessment of different XAI methods. Comparison and recommendations are made, shortcomings are clarified along with suggestions for future research directions to handle the finer details of select post-hoc analysis methods.
Polyhedron Volume-Ratio-based Classification for Image Recognition
Jan 26, 2016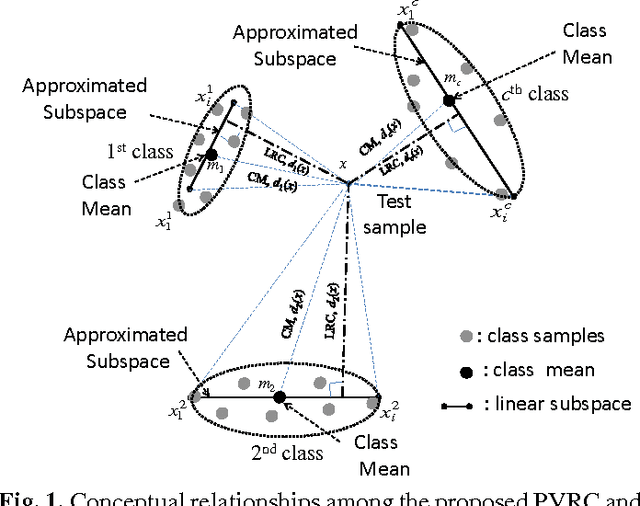

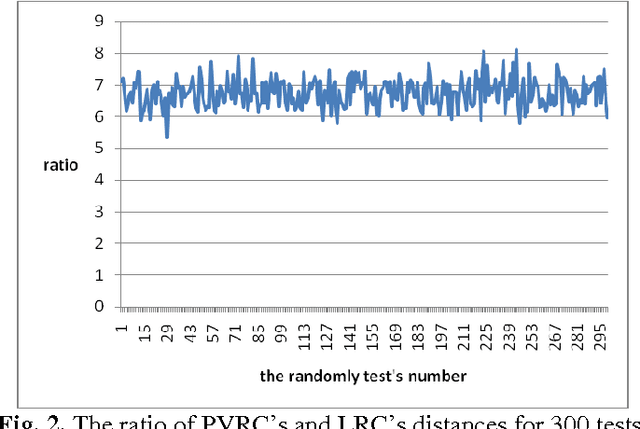

In this paper, a novel method, called polyhedron volume ratio classification (PVRC) is proposed for image recognition
Deep Lighting Environment Map Estimation from Spherical Panoramas
May 16, 2020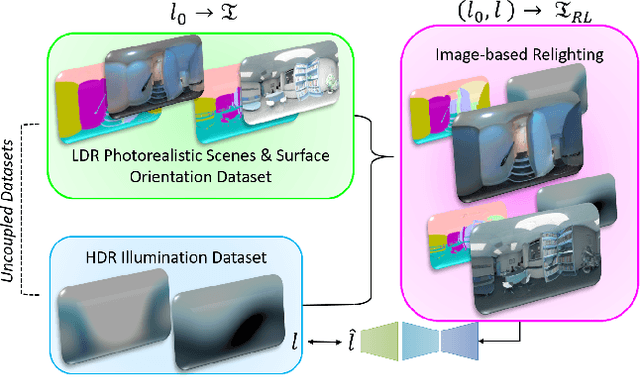


Estimating a scene's lighting is a very important task when compositing synthetic content within real environments, with applications in mixed reality and post-production. In this work we present a data-driven model that estimates an HDR lighting environment map from a single LDR monocular spherical panorama. In addition to being a challenging and ill-posed problem, the lighting estimation task also suffers from a lack of facile illumination ground truth data, a fact that hinders the applicability of data-driven methods. We approach this problem differently, exploiting the availability of surface geometry to employ image-based relighting as a data generator and supervision mechanism. This relies on a global Lambertian assumption that helps us overcome issues related to pre-baked lighting. We relight our training data and complement the model's supervision with a photometric loss, enabled by a differentiable image-based relighting technique. Finally, since we predict spherical spectral coefficients, we show that by imposing a distribution prior on the predicted coefficients, we can greatly boost performance. Code and models available at https://vcl3d.github.io/DeepPanoramaLighting.
Reinforcing Short-Length Hashing
Apr 24, 2020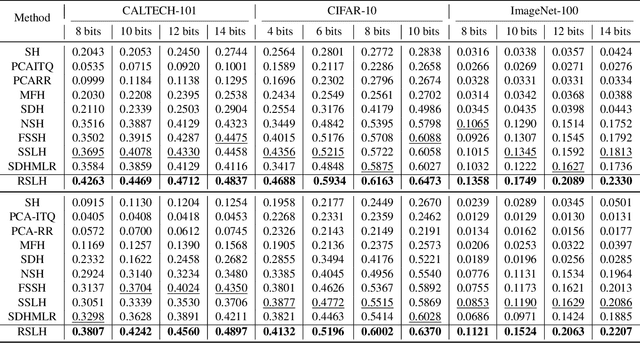
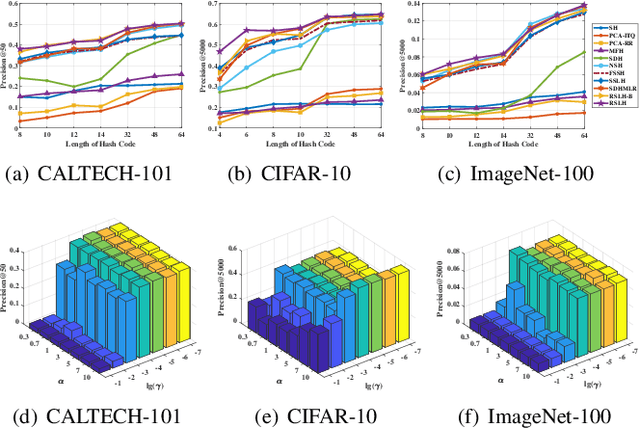
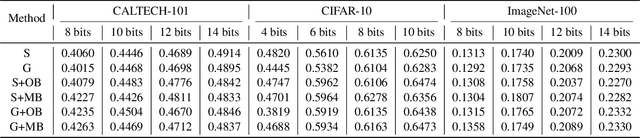
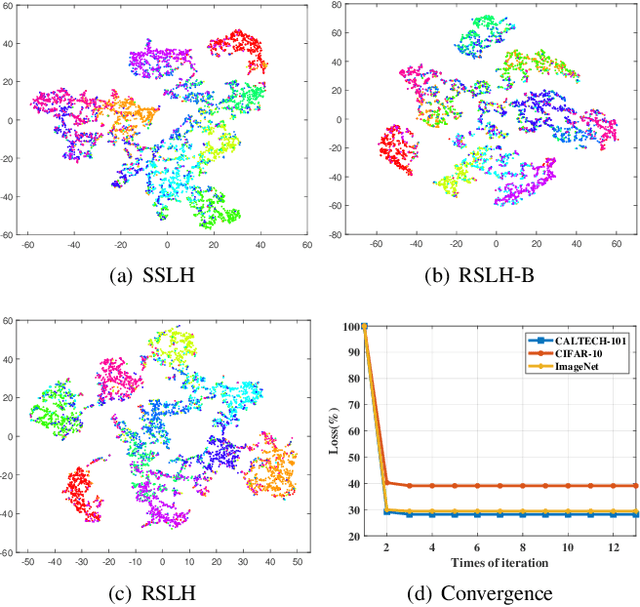
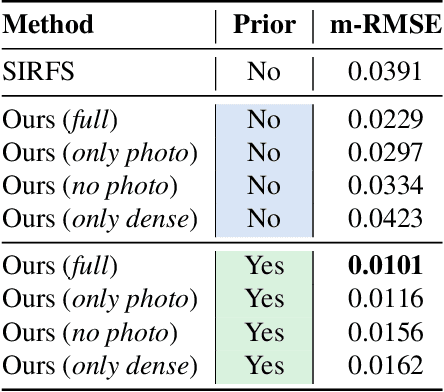
Due to the compelling efficiency in retrieval and storage, similarity-preserving hashing has been widely applied to approximate nearest neighbor search in large-scale image retrieval. However, existing methods have poor performance in retrieval using an extremely short-length hash code due to weak ability of classification and poor distribution of hash bit. To address this issue, in this study, we propose a novel reinforcing short-length hashing (RSLH). In this proposed RSLH, mutual reconstruction between the hash representation and semantic labels is performed to preserve the semantic information. Furthermore, to enhance the accuracy of hash representation, a pairwise similarity matrix is designed to make a balance between accuracy and training expenditure on memory. In addition, a parameter boosting strategy is integrated to reinforce the precision with hash bits fusion. Extensive experiments on three large-scale image benchmarks demonstrate the superior performance of RSLH under various short-length hashing scenarios.
Image Quality Assessment Techniques Show Improved Training and Evaluation of Autoencoder Generative Adversarial Networks
Aug 06, 2017
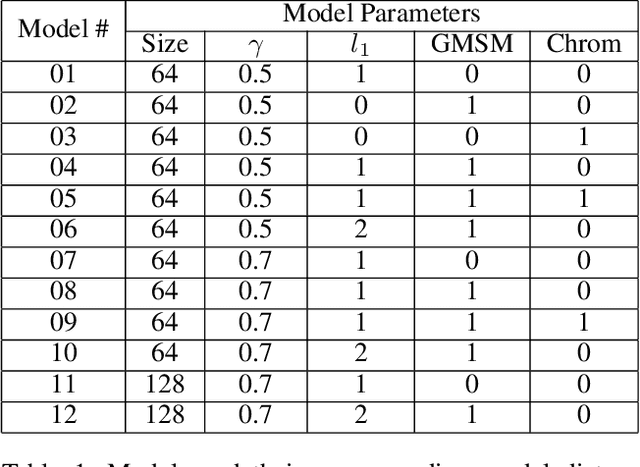

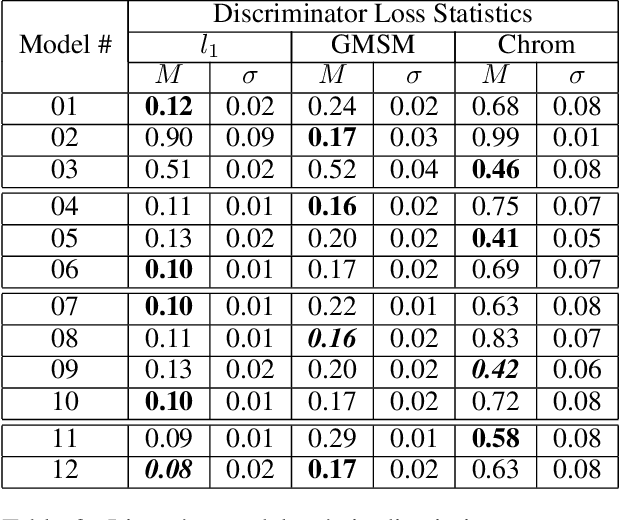
We propose a training and evaluation approach for autoencoder Generative Adversarial Networks (GANs), specifically the Boundary Equilibrium Generative Adversarial Network (BEGAN), based on methods from the image quality assessment literature. Our approach explores a multidimensional evaluation criterion that utilizes three distance functions: an $l_1$ score, the Gradient Magnitude Similarity Mean (GMSM) score, and a chrominance score. We show that each of the different distance functions captures a slightly different set of properties in image space and, consequently, requires its own evaluation criterion to properly assess whether the relevant property has been adequately learned. We show that models using the new distance functions are able to produce better images than the original BEGAN model in predicted ways.
Estimating and abstracting the 3D structure of bones using neural networks on X-ray (2D) images
Jan 16, 2020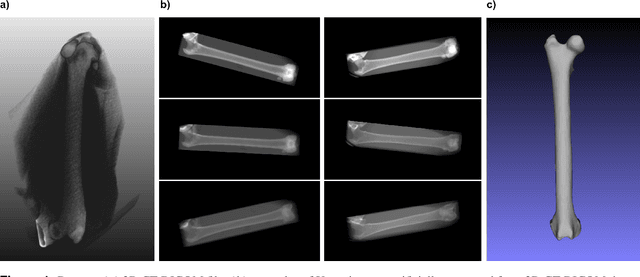


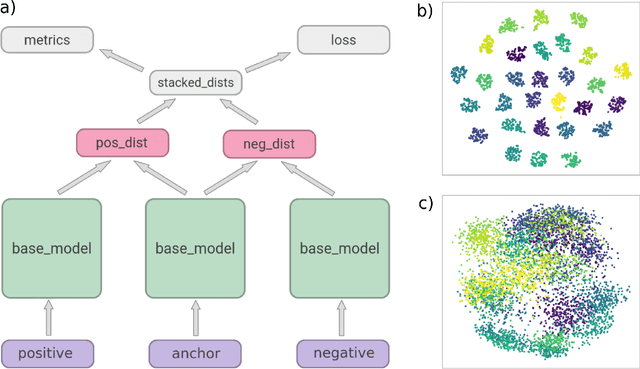
In this paper, we present a deep-learning based method for estimating the 3D structure of a bone from a pair of 2D X-ray images. Our triplet loss-trained neural network selects the most closely matching 3D bone shape from a predefined set of shapes. Our predictions have an average root mean square (RMS) distance of 1.08 mm between the predicted and true shapes, making it more accurate than the average error achieved by eight other examined 3D bone reconstruction approaches. The prediction process that we use is fully automated and unlike many competing approaches, it does not rely on any previous knowledge about bone geometry. Additionally, our neural network can determine the identity of a bone based only on its X-ray image. It computes a low-dimensional representation ("embedding") of each 2D X-ray image and henceforth compares different X-ray images based only on their embeddings. An embedding holds enough information to uniquely identify the bone CT belonging to the input X-ray image with a 100% accuracy and can therefore serve as a kind of fingerprint for that bone. Possible applications include faster, image content-based bone database searches for forensic purposes.
Mutual Information Regularized Identity-aware Facial ExpressionRecognition in Compressed Video
Oct 20, 2020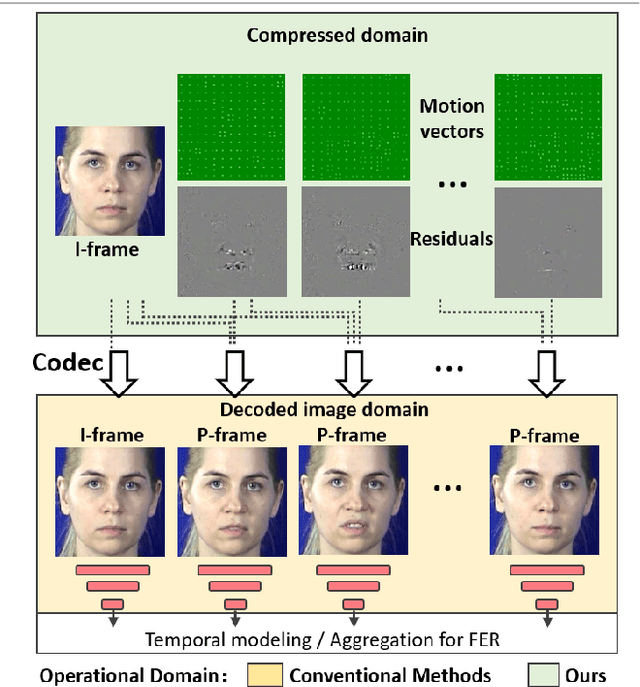
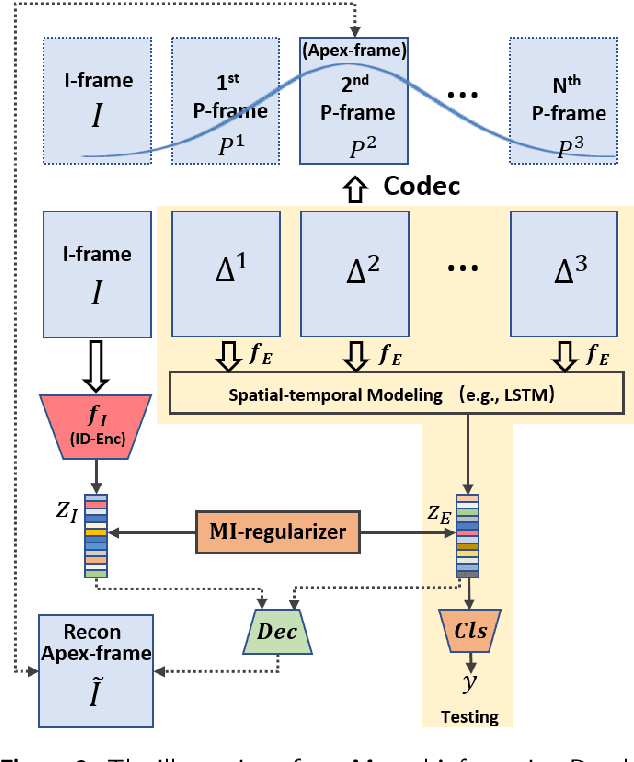
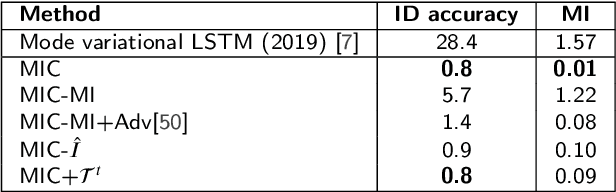
This paper targets to explore the inter-subject variations eliminated facial expression representation in the compressed video domain. Most of the previous methods process the RGB images of a sequence, while the off-the-shelf and valuable expression-related muscle movement already embedded in the compression format. In the up to two orders of magnitude compressed domain, we can explicitly infer the expression from the residual frames and possible to extract identity factors from the I frame with a pre-trained face recognition network. By enforcing the marginal independent of them, the expression feature is expected to be purer for the expression and be robust to identity shifts. Specifically, we propose a novel collaborative min-min game for mutual information (MI) minimization in latent space. We do not need the identity label or multiple expression samples from the same person for identity elimination. Moreover, when the apex frame is annotated in the dataset, the complementary constraint can be further added to regularize the feature-level game. In testing, only the compressed residual frames are required to achieve expression prediction. Our solution can achieve comparable or better performance than the recent decoded image-based methods on the typical FER benchmarks with about 3 times faster inference.
Automatic Image Annotation via Label Transfer in the Semantic Space
Jun 01, 2017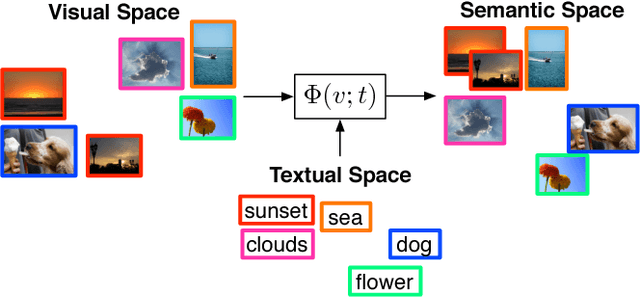
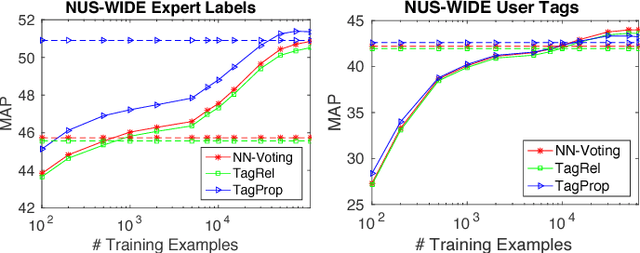
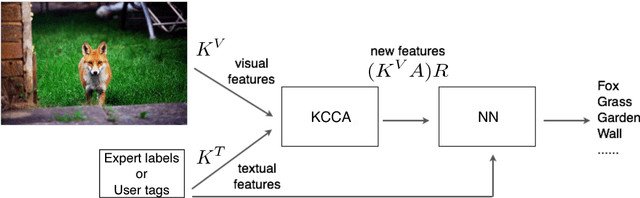
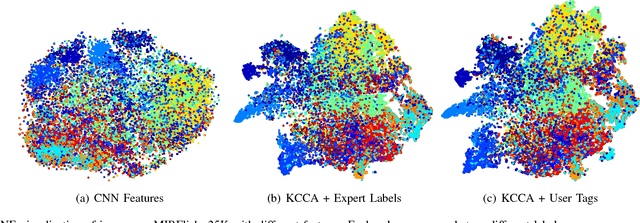
Automatic image annotation is among the fundamental problems in computer vision and pattern recognition, and it is becoming increasingly important in order to develop algorithms that are able to search and browse large-scale image collections. In this paper, we propose a label propagation framework based on Kernel Canonical Correlation Analysis (KCCA), which builds a latent semantic space where correlation of visual and textual features are well preserved into a semantic embedding. The proposed approach is robust and can work either when the training set is well annotated by experts, as well as when it is noisy such as in the case of user-generated tags in social media. We report extensive results on four popular datasets. Our results show that our KCCA-based framework can be applied to several state-of-the-art label transfer methods to obtain significant improvements. Our approach works even with the noisy tags of social users, provided that appropriate denoising is performed. Experiments on a large scale setting show that our method can provide some benefits even when the semantic space is estimated on a subset of training images.
Interpreting convolutional networks trained on textual data
Oct 20, 2020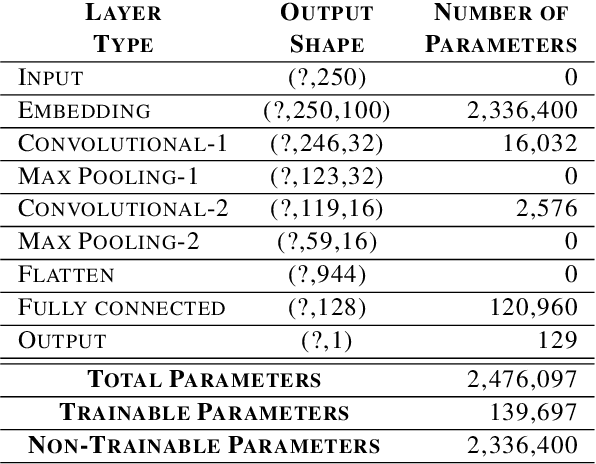
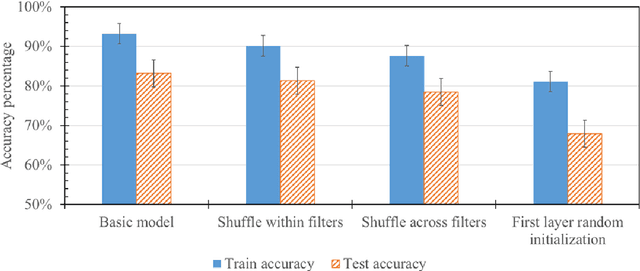

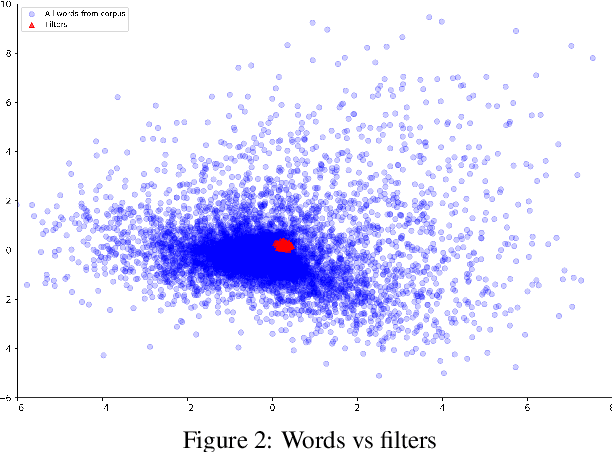
There have been many advances in the artificial intelligence field due to the emergence of deep learning. In almost all sub-fields, artificial neural networks have reached or exceeded human-level performance. However, most of the models are not interpretable. As a result, it is hard to trust their decisions, especially in life and death scenarios. In recent years, there has been a movement toward creating explainable artificial intelligence, but most work to date has concentrated on image processing models, as it is easier for humans to perceive visual patterns. There has been little work in other fields like natural language processing. In this paper, we train a convolutional model on textual data and analyze the global logic of the model by studying its filter values. In the end, we find the most important words in our corpus to our models logic and remove the rest (95%). New models trained on just the 5% most important words can achieve the same performance as the original model while reducing training time by more than half. Approaches such as this will help us to understand NLP models, explain their decisions according to their word choices, and improve them by finding blind spots and biases.
Player Identification in Hockey Broadcast Videos
Sep 14, 2020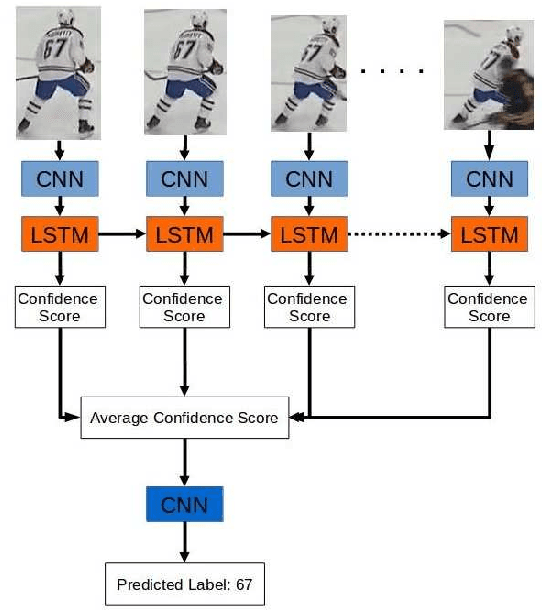
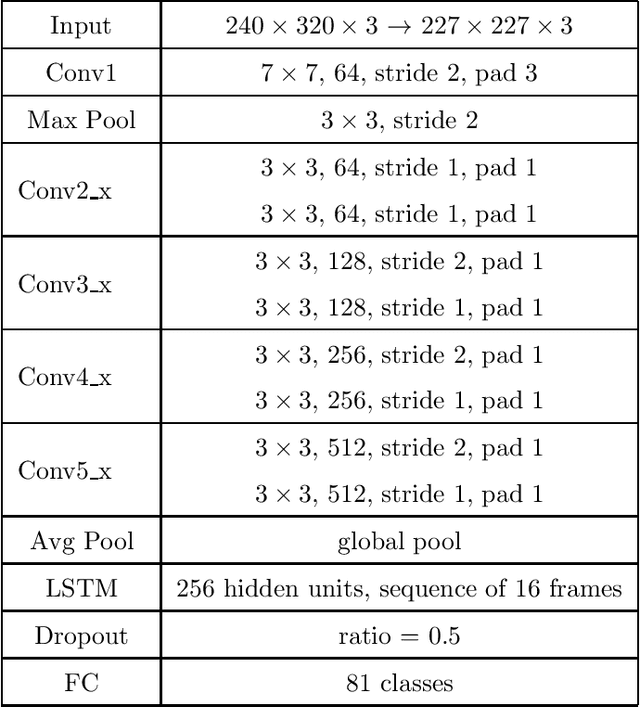
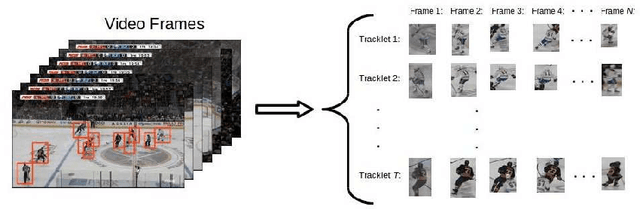
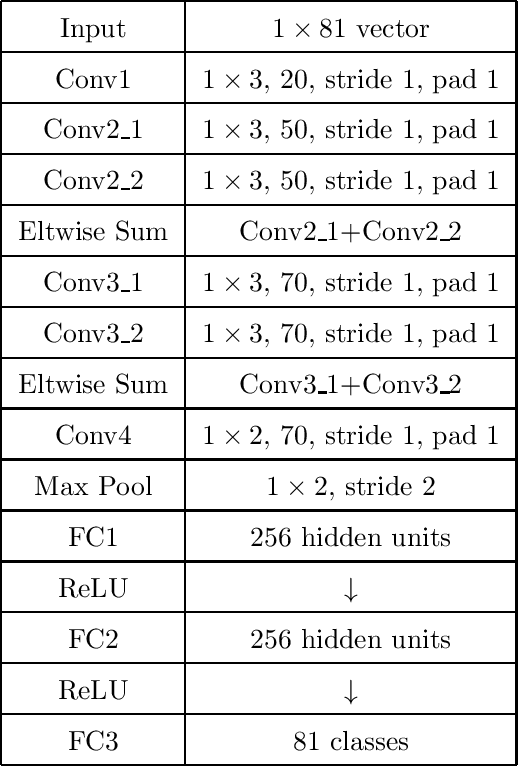
We present a deep recurrent convolutional neural network (CNN) approach to solve the problem of hockey player identification in NHL broadcast videos. Player identification is a difficult computer vision problem mainly because of the players' similar appearance, occlusion, and blurry facial and physical features. However, we can observe players' jersey numbers over time by processing variable length image sequences of players (aka 'tracklets'). We propose an end-to-end trainable ResNet+LSTM network, with a residual network (ResNet) base and a long short-term memory (LSTM) layer, to discover spatio-temporal features of jersey numbers over time and learn long-term dependencies. For this work, we created a new hockey player tracklet dataset that contains sequences of hockey player bounding boxes. Additionally, we employ a secondary 1-dimensional convolutional neural network classifier as a late score-level fusion method to classify the output of the ResNet+LSTM network. This achieves an overall player identification accuracy score over 87% on the test split of our new dataset.