 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
3DGEN: A GAN-based approach for generating novel 3D models from image data
Dec 13, 2023
The recent advances in text and image synthesis show a great promise for the future of generative models in creative fields. However, a less explored area is the one of 3D model generation, with a lot of potential applications to game design, video production, and physical product design. In our paper, we present 3DGEN, a model that leverages the recent work on both Neural Radiance Fields for object reconstruction and GAN-based image generation. We show that the proposed architecture can generate plausible meshes for objects of the same category as the training images and compare the resulting meshes with the state-of-the-art baselines, leading to visible uplifts in generation quality.
C-BEV: Contrastive Bird's Eye View Training for Cross-View Image Retrieval and 3-DoF Pose Estimation
Dec 13, 2023To find the geolocation of a street-view image, cross-view geolocalization (CVGL) methods typically perform image retrieval on a database of georeferenced aerial images and determine the location from the visually most similar match. Recent approaches focus mainly on settings where street-view and aerial images are preselected to align w.r.t. translation or orientation, but struggle in challenging real-world scenarios where varying camera poses have to be matched to the same aerial image. We propose a novel trainable retrieval architecture that uses bird's eye view (BEV) maps rather than vectors as embedding representation, and explicitly addresses the many-to-one ambiguity that arises in real-world scenarios. The BEV-based retrieval is trained using the same contrastive setting and loss as classical retrieval. Our method C-BEV surpasses the state-of-the-art on the retrieval task on multiple datasets by a large margin. It is particularly effective in challenging many-to-one scenarios, e.g. increasing the top-1 recall on VIGOR's cross-area split with unknown orientation from 31.1% to 65.0%. Although the model is supervised only through a contrastive objective applied on image pairings, it additionally learns to infer the 3-DoF camera pose on the matching aerial image, and even yields a lower mean pose error than recent methods that are explicitly trained with metric groundtruth.
A Multi-scale Information Integration Framework for Infrared and Visible Image Fusion
Dec 07, 2023Infrared and visible image fusion aims at generating a fused image containing the intensity and detail information of source images, and the key issue is effectively measuring and integrating the complementary information of multi-modality images from the same scene. Existing methods mostly adopt a simple weight in the loss function to decide the information retention of each modality rather than adaptively measuring complementary information for different image pairs. In this study, we propose a multi-scale dual attention (MDA) framework for infrared and visible image fusion, which is designed to measure and integrate complementary information in both structure and loss function at the image and patch level. In our method, the residual downsample block decomposes source images into three scales first. Then, dual attention fusion block integrates complementary information and generates a spatial and channel attention map at each scale for feature fusion. Finally, the output image is reconstructed by the residual reconstruction block. Loss function consists of image-level, feature-level and patch-level three parts, of which the calculation of the image-level and patch-level two parts are based on the weights generated by the complementary information measurement. Indeed, to constrain the pixel intensity distribution between the output and infrared image, a style loss is added. Our fusion results perform robust and informative across different scenarios. Qualitative and quantitative results on two datasets illustrate that our method is able to preserve both thermal radiation and detailed information from two modalities and achieve comparable results compared with the other state-of-the-art methods. Ablation experiments show the effectiveness of our information integration architecture and adaptively measure complementary information retention in the loss function.
PSCR: Patches Sampling-based Contrastive Regression for AIGC Image Quality Assessment
Dec 10, 2023In recent years, Artificial Intelligence Generated Content (AIGC) has gained widespread attention beyond the computer science community. Due to various issues arising from continuous creation of AI-generated images (AIGI), AIGC image quality assessment (AIGCIQA), which aims to evaluate the quality of AIGIs from human perception perspectives, has emerged as a novel topic in the field of computer vision. However, most existing AIGCIQA methods directly regress predicted scores from a single generated image, overlooking the inherent differences among AIGIs and scores. Additionally, operations like resizing and cropping may cause global geometric distortions and information loss, thus limiting the performance of models. To address these issues, we propose a patches sampling-based contrastive regression (PSCR) framework. We suggest introducing a contrastive regression framework to leverage differences among various generated images for learning a better representation space. In this space, differences and score rankings among images can be measured by their relative scores. By selecting exemplar AIGIs as references, we also overcome the limitations of previous models that could not utilize reference images on the no-reference image databases. To avoid geometric distortions and information loss in image inputs, we further propose a patches sampling strategy. To demonstrate the effectiveness of our proposed PSCR framework, we conduct extensive experiments on three mainstream AIGCIQA databases including AGIQA-1K, AGIQA-3K and AIGCIQA2023. The results show significant improvements in model performance with the introduction of our proposed PSCR framework. Code will be available at \url{https://github.com/jiquan123/PSCR}.
Multi-task Image Restoration Guided By Robust DINO Features
Dec 05, 2023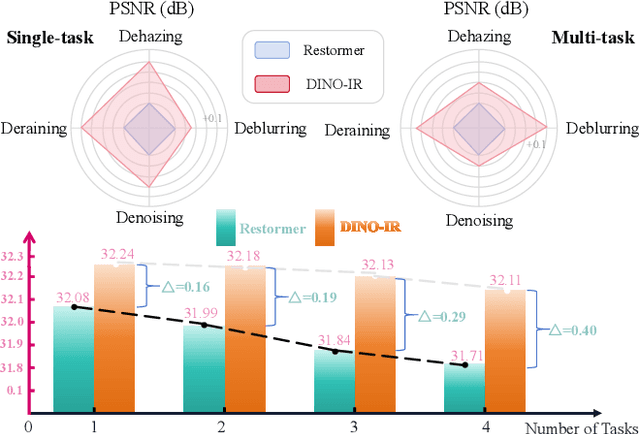
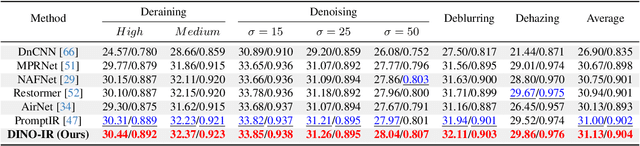
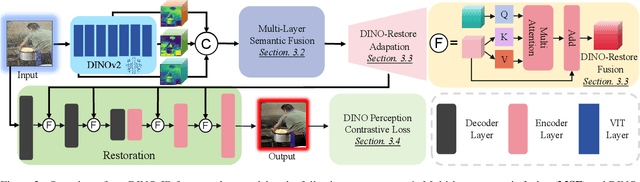
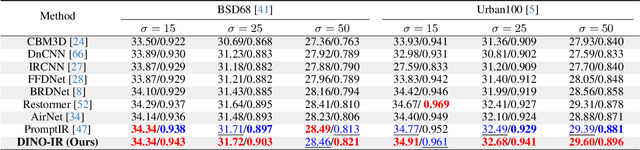
Multi-task image restoration has gained significant interest due to its inherent versatility and efficiency compared to its single-task counterpart. Despite its potential, performance degradation is observed with an increase in the number of tasks, primarily attributed to the distinct nature of each restoration task. Addressing this challenge, we introduce \mbox{\textbf{DINO-IR}}, a novel multi-task image restoration approach leveraging robust features extracted from DINOv2. Our empirical analysis shows that while shallow features of DINOv2 capture rich low-level image characteristics, the deep features ensure a robust semantic representation insensitive to degradations while preserving high-frequency contour details. Building on these features, we devise specialized components, including multi-layer semantic fusion module, DINO-Restore adaption and fusion module, and DINO perception contrastive loss, to integrate DINOv2 features into the restoration paradigm. Equipped with the aforementioned components, our DINO-IR performs favorably against existing multi-task image restoration approaches in various tasks by a large margin, indicating the superiority and necessity of reinforcing the robust features for multi-task image restoration.
Derm-T2IM: Harnessing Synthetic Skin Lesion Data via Stable Diffusion Models for Enhanced Skin Disease Classification using ViT and CNN
Jan 10, 2024This study explores the utilization of Dermatoscopic synthetic data generated through stable diffusion models as a strategy for enhancing the robustness of machine learning model training. Synthetic data generation plays a pivotal role in mitigating challenges associated with limited labeled datasets, thereby facilitating more effective model training. In this context, we aim to incorporate enhanced data transformation techniques by extending the recent success of few-shot learning and a small amount of data representation in text-to-image latent diffusion models. The optimally tuned model is further used for rendering high-quality skin lesion synthetic data with diverse and realistic characteristics, providing a valuable supplement and diversity to the existing training data. We investigate the impact of incorporating newly generated synthetic data into the training pipeline of state-of-art machine learning models, assessing its effectiveness in enhancing model performance and generalization to unseen real-world data. Our experimental results demonstrate the efficacy of the synthetic data generated through stable diffusion models helps in improving the robustness and adaptability of end-to-end CNN and vision transformer models on two different real-world skin lesion datasets.
Enhancing Image Captioning with Neural Models
Dec 01, 2023This research explores the realm of neural image captioning using deep learning models. The study investigates the performance of different neural architecture configurations, focusing on the inject architecture, and proposes a novel quality metric for evaluating caption generation. Through extensive experimentation and analysis, this work sheds light on the challenges and opportunities in image captioning, providing insights into model behavior and overfitting. The results reveal that while the merge models exhibit a larger vocabulary and higher ROUGE scores, the inject architecture generates relevant and concise image captions. The study also highlights the importance of refining training data and optimizing hyperparameters for improved model performance. This research contributes to the growing body of knowledge in neural image captioning and encourages further exploration in the field, emphasizing the democratization of artificial intelligence.
Content-Conditioned Generation of Stylized Free hand Sketches
Jan 09, 2024In recent years, the recognition of free-hand sketches has remained a popular task. However, in some special fields such as the military field, free-hand sketches are difficult to sample on a large scale. Common data augmentation and image generation techniques are difficult to produce images with various free-hand sketching styles. Therefore, the recognition and segmentation tasks in related fields are limited. In this paper, we propose a novel adversarial generative network that can accurately generate realistic free-hand sketches with various styles. We explore the performance of the model, including using styles randomly sampled from a prior normal distribution to generate images with various free-hand sketching styles, disentangling the painters' styles from known free-hand sketches to generate images with specific styles, and generating images of unknown classes that are not in the training set. We further demonstrate with qualitative and quantitative evaluations our advantages in visual quality, content accuracy, and style imitation on SketchIME.
Social Media Ready Caption Generation for Brands
Jan 03, 2024Social media advertisements are key for brand marketing, aiming to attract consumers with captivating captions and pictures or logos. While previous research has focused on generating captions for general images, incorporating brand personalities into social media captioning remains unexplored. Brand personalities are shown to be affecting consumers' behaviours and social interactions and thus are proven to be a key aspect of marketing strategies. Current open-source multimodal LLMs are not directly suited for this task. Hence, we propose a pipeline solution to assist brands in creating engaging social media captions that align with the image and the brand personalities. Our architecture is based on two parts: a the first part contains an image captioning model that takes in an image that the brand wants to post online and gives a plain English caption; b the second part takes in the generated caption along with the target brand personality and outputs a catchy personality-aligned social media caption. Along with brand personality, our system also gives users the flexibility to provide hashtags, Instagram handles, URLs, and named entities they want the caption to contain, making the captions more semantically related to the social media handles. Comparative evaluations against various baselines demonstrate the effectiveness of our approach, both qualitatively and quantitatively.
DGNet: Dynamic Gradient-guided Network with Noise Suppression for Underwater Image Enhancement
Dec 12, 2023Underwater image enhancement (UIE) is a challenging task due to the complex degradation caused by underwater environments. To solve this issue, previous methods often idealize the degradation process, and neglect the impact of medium noise and object motion on the distribution of image features, limiting the generalization and adaptability of the model. Previous methods use the reference gradient that is constructed from original images and synthetic ground-truth images. This may cause the network performance to be influenced by some low-quality training data. Our approach utilizes predicted images to dynamically update pseudo-labels, adding a dynamic gradient to optimize the network's gradient space. This process improves image quality and avoids local optima. Moreover, we propose a Feature Restoration and Reconstruction module (FRR) based on a Channel Combination Inference (CCI) strategy and a Frequency Domain Smoothing module (FRS). These modules decouple other degradation features while reducing the impact of various types of noise on network performance. Experiments on multiple public datasets demonstrate the superiority of our method over existing state-of-the-art approaches, especially in achieving performance milestones: PSNR of 25.6dB and SSIM of 0.93 on the UIEB dataset. Its efficiency in terms of parameter size and inference time further attests to its broad practicality. The code will be made publicly available.