 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Document Image Binarization with Fully Convolutional Neural Networks
Aug 10, 2017
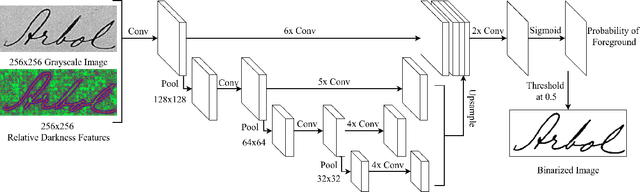

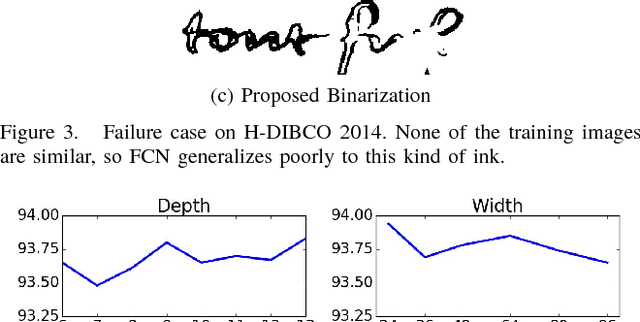
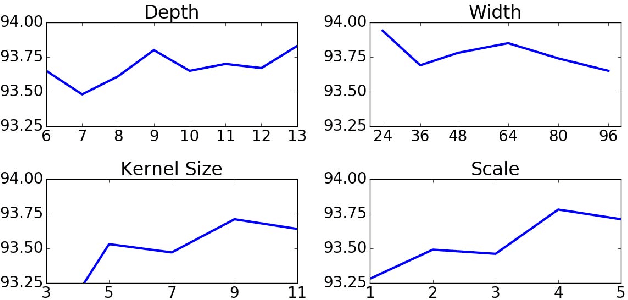
Binarization of degraded historical manuscript images is an important pre-processing step for many document processing tasks. We formulate binarization as a pixel classification learning task and apply a novel Fully Convolutional Network (FCN) architecture that operates at multiple image scales, including full resolution. The FCN is trained to optimize a continuous version of the Pseudo F-measure metric and an ensemble of FCNs outperform the competition winners on 4 of 7 DIBCO competitions. This same binarization technique can also be applied to different domains such as Palm Leaf Manuscripts with good performance. We analyze the performance of the proposed model w.r.t. the architectural hyperparameters, size and diversity of training data, and the input features chosen.
Deep Evolution for Facial Emotion Recognition
Sep 29, 2020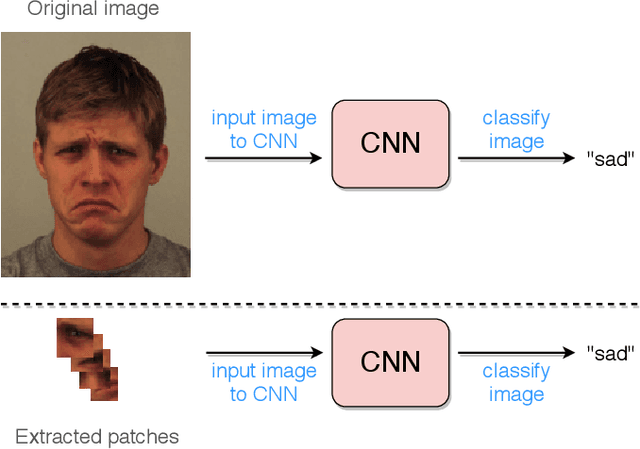
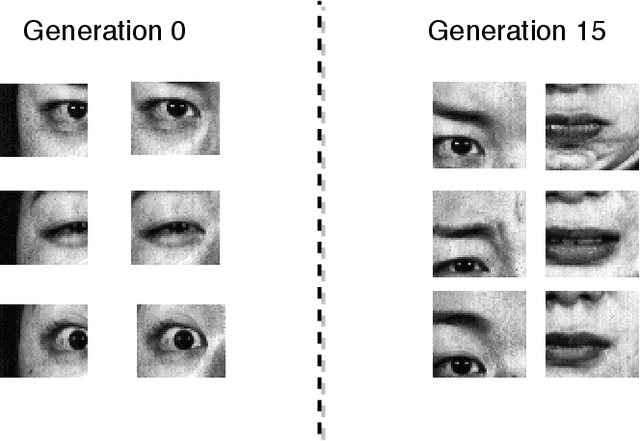
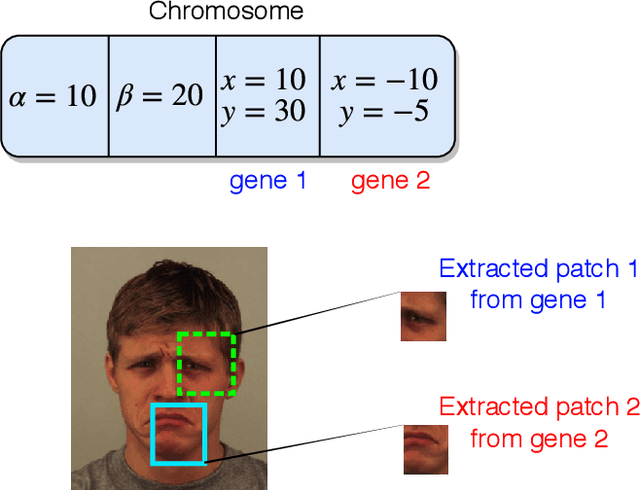

Deep facial expression recognition faces two challenges that both stem from the large number of trainable parameters: long training times and a lack of interpretability. We propose a novel method based on evolutionary algorithms, that deals with both challenges by massively reducing the number of trainable parameters, whilst simultaneously retaining classification performance, and in some cases achieving superior performance. We are robustly able to reduce the number of parameters on average by 95% (e.g. from 2M to 100k parameters) with no loss in classification accuracy. The algorithm learns to choose small patches from the image, relative to the nose, which carry the most important information about emotion, and which coincide with typical human choices of important features. Our work implements a novel form attention and shows that evolutionary algorithms are a valuable addition to machine learning in the deep learning era, both for reducing the number of parameters for facial expression recognition and for providing interpretable features that can help reduce bias.
Modality-bridge Transfer Learning for Medical Image Classification
Aug 10, 2017
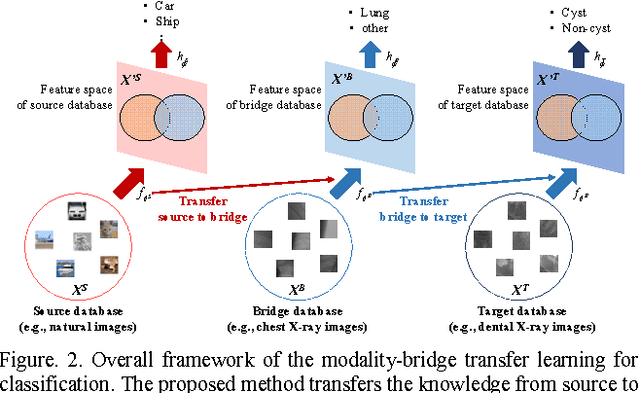
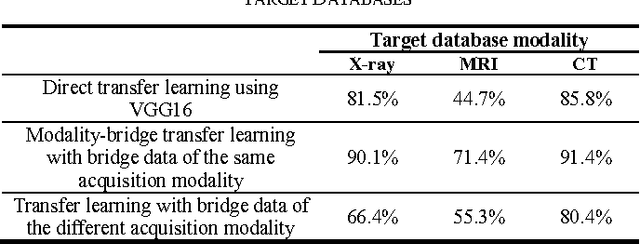
This paper presents a new approach of transfer learning-based medical image classification to mitigate insufficient labeled data problem in medical domain. Instead of direct transfer learning from source to small number of labeled target data, we propose a modality-bridge transfer learning which employs the bridge database in the same medical imaging acquisition modality as target database. By learning the projection function from source to bridge and from bridge to target, the domain difference between source (e.g., natural images) and target (e.g., X-ray images) can be mitigated. Experimental results show that the proposed method can achieve a high classification performance even for a small number of labeled target medical images, compared to various transfer learning approaches.
Spatiotemporal Imaging with Diffeomorphic Optimal Transportation
Nov 24, 2020
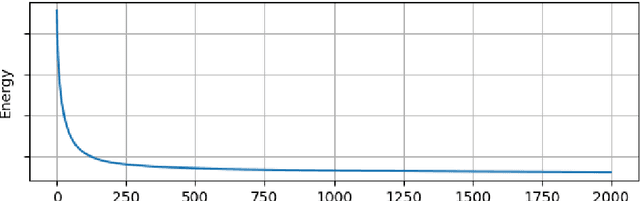

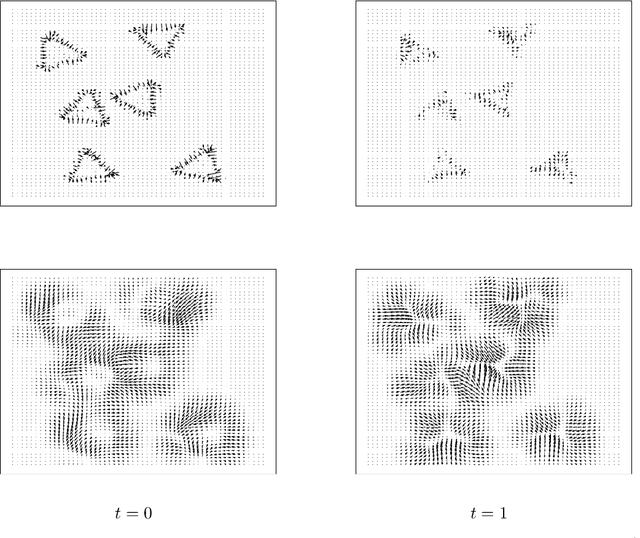
We propose a variational model with diffeomorphic optimal transportation for joint image reconstruction and motion estimation. The proposed model is a production of assembling the Wasserstein distance with the Benamou--Brenier formula in optimal transportation and the flow of diffeomorphisms involved in large deformation diffeomorphic metric mapping, which is suitable for the scenario of spatiotemporal imaging with large diffeomorphic and mass-preserving deformations. Specifically, we first use the Benamou--Brenier formula to characterize the optimal transport cost among the flow of mass-preserving images, and restrict the velocity field into the admissible Hilbert space to guarantee the generated deformation flow being diffeomorphic. We then gain the ODE-constrained equivalent formulation for Benamou--Brenier formula. We finally obtain the proposed model with ODE constraint following the framework that presented in our previous work. We further get the equivalent PDE-constrained optimal control formulation. The proposed model is compared against several existing alternatives theoretically. The alternating minimization algorithm is presented for solving the time-discretized version of the proposed model with ODE constraint. Several important issues on the proposed model and associated algorithms are also discussed. Particularly, we present several potential models based on the proposed diffeomorphic optimal transportation. Under appropriate conditions, the proposed algorithm also provides a new scheme to solve the models using quadratic Wasserstein distance. The performance is finally evaluated by several numerical experiments in space-time tomography, where the data is measured from the concerned sequential images with sparse views and/or various noise levels.
Variational Transfer Learning for Fine-grained Few-shot Visual Recognition
Oct 12, 2020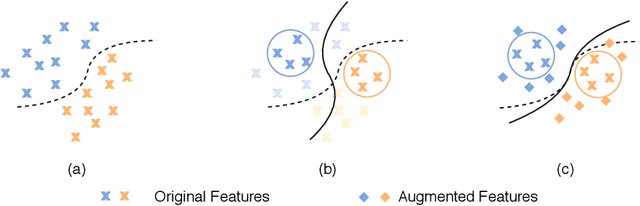
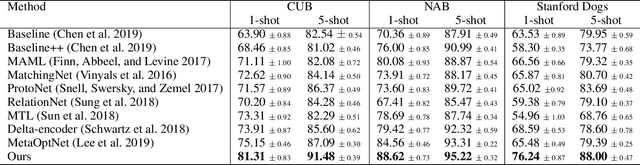
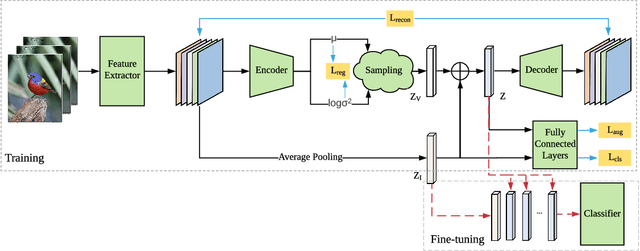
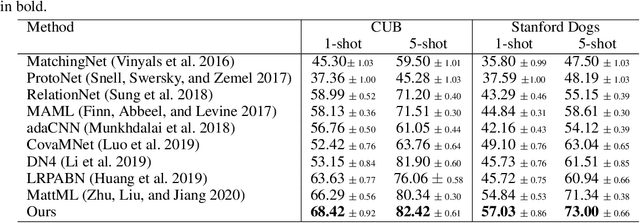
Fine-grained few-shot recognition often suffers from the problem of training data scarcity for novel categories.The network tends to overfit and does not generalize well to unseen classes due to insufficient training data. Many methods have been proposed to synthesize additional data to support the training. In this paper, we focus one enlarging the intra-class variance of the unseen class to improve few-shot classification performance. We assume that the distribution of intra-class variance generalizes across the base class and the novel class. Thus, the intra-class variance of the base set can be transferred to the novel set for feature augmentation. Specifically, we first model the distribution of intra-class variance on the base set via variational inference. Then the learned distribution is transferred to the novel set to generate additional features, which are used together with the original ones to train a classifier. Experimental results show a significant boost over the state-of-the-art methods on the challenging fine-grained few-shot image classification benchmarks.
Image Inpainting by Kriging Interpolation Technique
Jun 01, 2013


Image inpainting is the art of predicting damaged regions of an image. The manual way of image inpainting is a time consuming. Therefore, there must be an automatic digital method for image inpainting that recovers the image from the damaged regions. In this paper, a novel statistical image inpainting algorithm based on Kriging interpolation technique was proposed. Kriging technique automatically fills the damaged region in an image using the information available from its surrounding regions in such away that it uses the spatial correlation structure of points inside the k-by-k block. Kriging has the ability to face the challenge of keeping the structure and texture information as the size of damaged region heighten. Experimental results showed that, Kriging has a high PSNR value when recovering a variety of test images from scratches and text as damaged regions.
* 6 pages, 9 figures, 1 table
Self-supervised Keypoint Correspondences for Multi-Person Pose Estimation and Tracking in Videos
Jun 02, 2020

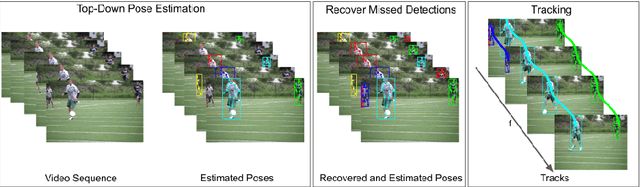

Video annotation is expensive and time consuming. Consequently, datasets for multi-person pose estimation and tracking are less diverse and have more sparse annotations compared to large scale image datasets for human pose estimation. This makes it challenging to learn deep learning based models for associating keypoints across frames that are robust to nuisance factors such as motion blur and occlusions for the task of multi-person pose tracking. To address this issue, we propose an approach that relies on keypoint correspondences for associating persons in videos. Instead of training the network for estimating keypoint correspondences on video data, it is trained on a large scale image datasets for human pose estimation using self-supervision. Combined with a top-down framework for human pose estimation, we use keypoints correspondences to (i) recover missed pose detections (ii) associate pose detections across video frames. Our approach achieves state-of-the-art results for multi-frame pose estimation and multi-person pose tracking on the PosTrack $2017$ and PoseTrack $2018$ data sets.
An embedded system for the automated generation of labeled plant images to enable machine learning applications in agriculture
Jun 01, 2020
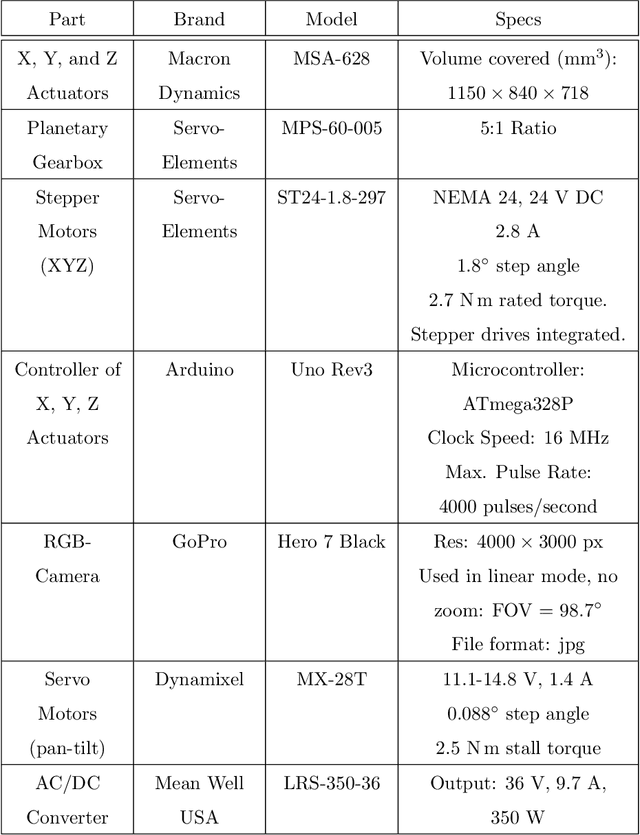

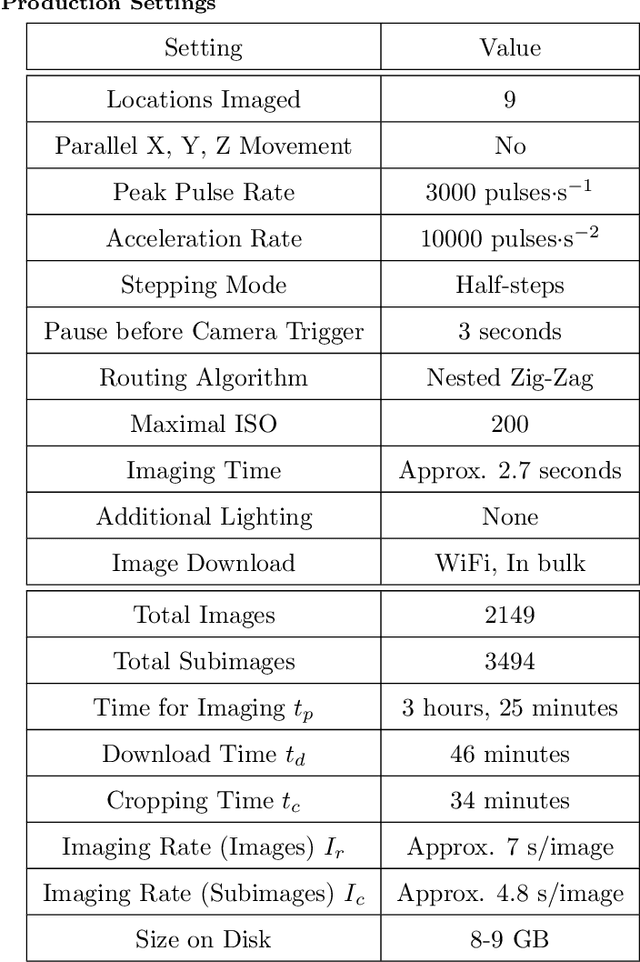
A lack of sufficient training data, both in terms of variety and quantity, is often the bottleneck in the development of machine learning (ML) applications in any domain. For agricultural applications, ML-based models designed to perform tasks such as autonomous plant classification will typically be coupled to just one or perhaps a few plant species. As a consequence, each crop-specific task is very likely to require its own specialized training data, and the question of how to serve this need for data now often overshadows the more routine exercise of actually training such models. To tackle this problem, we have developed an embedded robotic system to automatically generate and label large datasets of plant images for ML applications in agriculture. The system can image plants from virtually any angle, thereby ensuring a wide variety of data; and with an imaging rate of up to one image per second, it can produce lableled datasets on the scale of thousands to tens of thousands of images per day. As such, this system offers an important alternative to time- and cost-intensive methods of manual generation and labeling. Furthermore, the use of a uniform background made of blue keying fabric enables additional image processing techniques such as background replacement and plant segmentation. It also helps in the training process, essentially forcing the model to focus on the plant features and eliminating random correlations. To demonstrate the capabilities of our system, we generated a dataset of over 34,000 labeled images, with which we trained an ML-model to distinguish grasses from non-grasses in test data from a variety of sources. We now plan to generate much larger datasets of Canadian crop plants and weeds that will be made publicly available in the hope of further enabling ML applications in the agriculture sector.
Neural Enhancement in Content Delivery Systems: The State-of-the-Art and Future Directions
Oct 12, 2020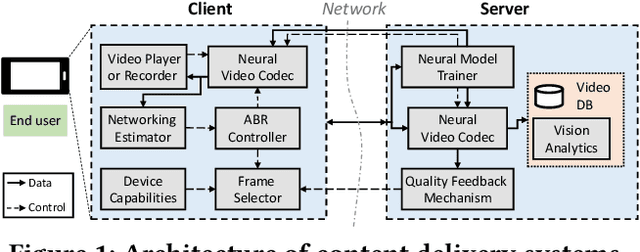


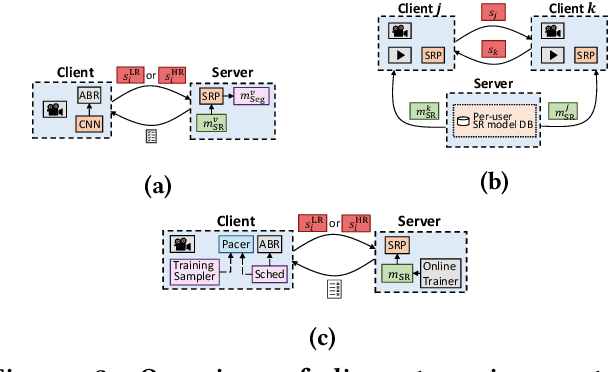
Internet-enabled smartphones and ultra-wide displays are transforming a variety of visual apps spanning from on-demand movies and 360-degree videos to video-conferencing and live streaming. However, robustly delivering visual content under fluctuating networking conditions on devices of diverse capabilities remains an open problem. In recent years, advances in the field of deep learning on tasks such as super-resolution and image enhancement have led to unprecedented performance in generating high-quality images from low-quality ones, a process we refer to as neural enhancement. In this paper, we survey state-of-the-art content delivery systems that employ neural enhancement as a key component in achieving both fast response time and high visual quality. We first present the deployment challenges of neural enhancement models. We then cover systems targeting diverse use-cases and analyze their design decisions in overcoming technical challenges. Moreover, we present promising directions based on the latest insights from deep learning research to further boost the quality of experience of these systems.
Deep Object Co-segmentation via Spatial-Semantic Network Modulation
Nov 29, 2019
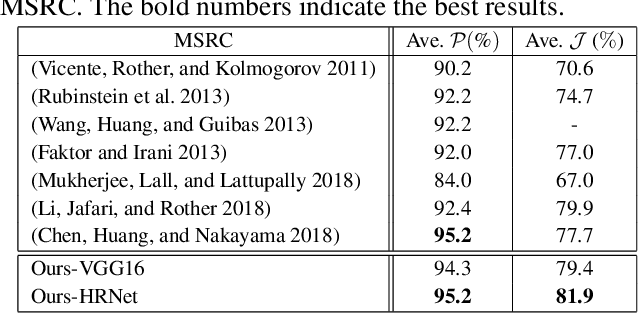
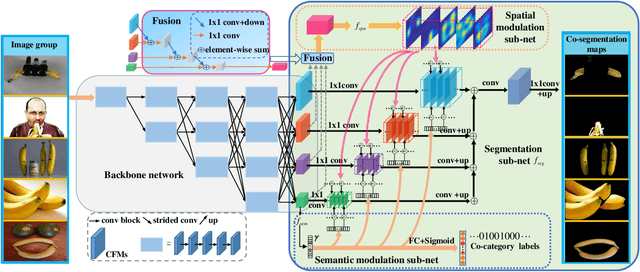
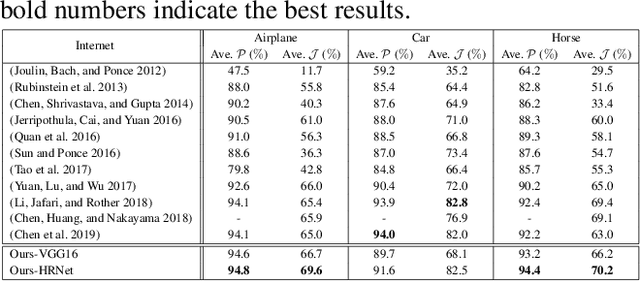
Object co-segmentation is to segment the shared objects in multiple relevant images, which has numerous applications in computer vision. This paper presents a spatial and semantic modulated deep network framework for object co-segmentation. A backbone network is adopted to extract multi-resolution image features. With the multi-resolution features of the relevant images as input, we design a spatial modulator to learn a mask for each image. The spatial modulator captures the correlations of image feature descriptors via unsupervised learning. The learned mask can roughly localize the shared foreground object while suppressing the background. For the semantic modulator, we model it as a supervised image classification task. We propose a hierarchical second-order pooling module to transform the image features for classification use. The outputs of the two modulators manipulate the multi-resolution features by a shift-and-scale operation so that the features focus on segmenting co-object regions. The proposed model is trained end-to-end without any intricate post-processing. Extensive experiments on four image co-segmentation benchmark datasets demonstrate the superior accuracy of the proposed method compared to state-of-the-art methods.