 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Self-training Algorithm Based on Deep Learning for Optical Aerial Images Change Detection
Oct 15, 2020
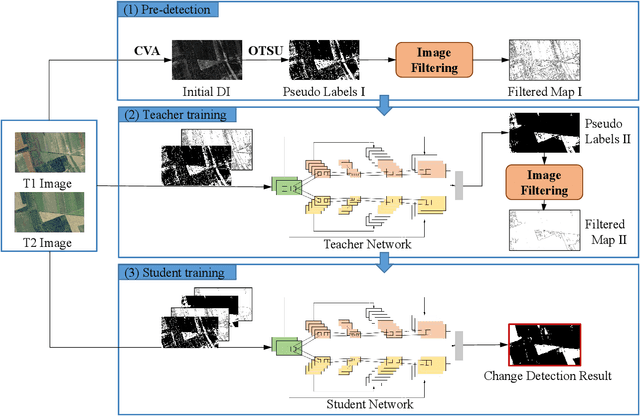
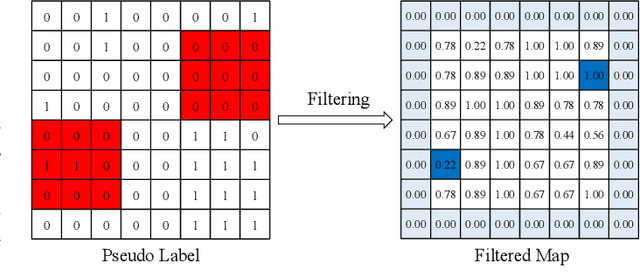
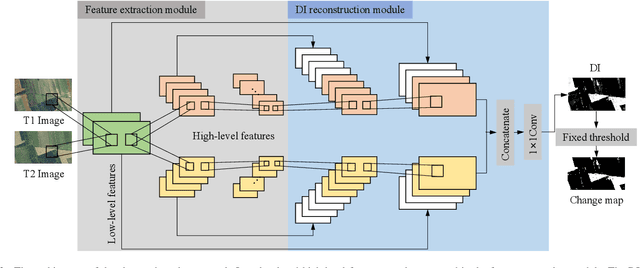

Optical aerial images change detection is an important task in earth observation and has been extensively investigated in the past few decades. Generally, the supervised change detection methods with superior performance require a large amount of labeled training data which is obtained by manual annotation with high cost. In this paper, we present a novel unsupervised self-training algorithm (USTA) for optical aerial images change detection. The traditional method such as change vector analysis is used to generate the pseudo labels. We use these pseudo labels to train a well designed convolutional neural network. The network is used as a teacher to classify the original multitemporal images to generate another set of pseudo labels. Then two set of pseudo labels are used to jointly train a student network with the same structure as the teacher. The final change detection result can be obtained by the trained student network. Besides, we design an image filter to control the usage of change information in the pseudo labels in the training process of the network. The whole process of the algorithm is an unsupervised process without manually marked labels. Experimental results on the real datasets demonstrate competitive performance of our proposed method.
Weakly Supervised Deep Nuclei Segmentation Using Partial Points Annotation in Histopathology Images
Jul 10, 2020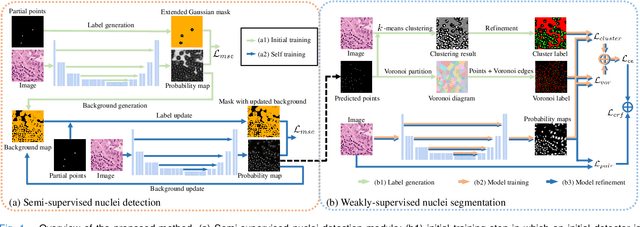
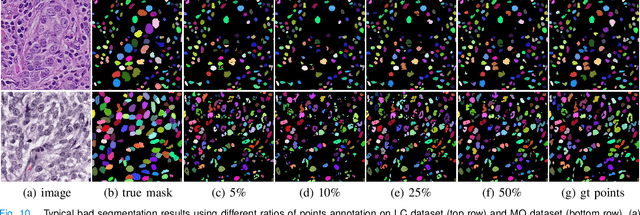
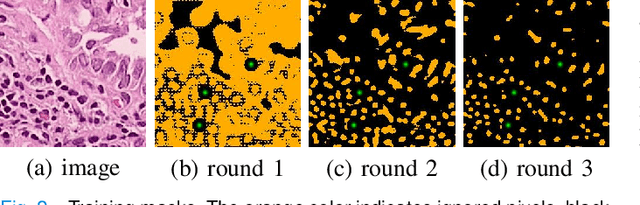

Nuclei segmentation is a fundamental task in histopathology image analysis. Typically, such segmentation tasks require significant effort to manually generate accurate pixel-wise annotations for fully supervised training. To alleviate such tedious and manual effort, in this paper we propose a novel weakly supervised segmentation framework based on partial points annotation, i.e., only a small portion of nuclei locations in each image are labeled. The framework consists of two learning stages. In the first stage, we design a semi-supervised strategy to learn a detection model from partially labeled nuclei locations. Specifically, an extended Gaussian mask is designed to train an initial model with partially labeled data. Then, selftraining with background propagation is proposed to make use of the unlabeled regions to boost nuclei detection and suppress false positives. In the second stage, a segmentation model is trained from the detected nuclei locations in a weakly-supervised fashion. Two types of coarse labels with complementary information are derived from the detected points and are then utilized to train a deep neural network. The fully-connected conditional random field loss is utilized in training to further refine the model without introducing extra computational complexity during inference. The proposed method is extensively evaluated on two nuclei segmentation datasets. The experimental results demonstrate that our method can achieve competitive performance compared to the fully supervised counterpart and the state-of-the-art methods while requiring significantly less annotation effort.
CIMON: Towards High-quality Hash Codes
Nov 05, 2020
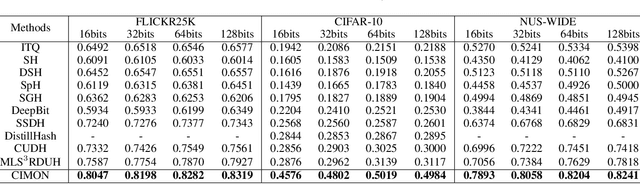
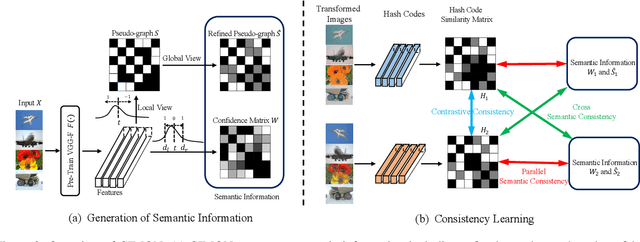
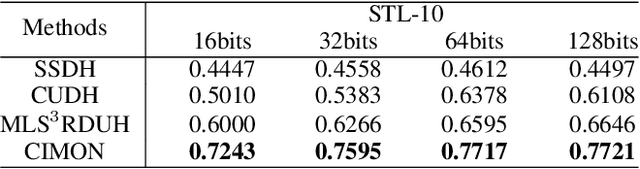
Recently, hashing is widely-used in approximate nearest neighbor search for its storage and computational efficiency. Due to the lack of labeled data in practice, many studies focus on unsupervised hashing. Most of the unsupervised hashing methods learn to map images into semantic similarity-preserving hash codes by constructing local semantic similarity structure from the pre-trained model as guiding information, i.e., treating each point pair similar if their distance is small in feature space. However, due to the inefficient representation ability of the pre-trained model, many false positives and negatives in local semantic similarity will be introduced and lead to error propagation during hash code learning. Moreover, most of hashing methods ignore the basic characteristics of hash codes such as collisions, which will cause instability of hash codes to disturbance. In this paper, we propose a new method named Comprehensive sImilarity Mining and cOnsistency learNing (CIMON). First, we use global constraint learning and similarity statistical distribution to obtain reliable and smooth guidance. Second, image augmentation and consistency learning will be introduced to explore both semantic and contrastive consistency to derive robust hash codes with fewer collisions. Extensive experiments on several benchmark datasets show that the proposed method consistently outperforms a wide range of state-of-the-art methods in both retrieval performance and robustness.
Restoring Negative Information in Few-Shot Object Detection
Oct 26, 2020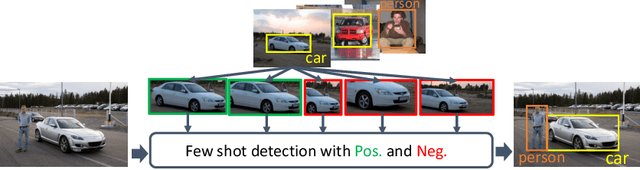
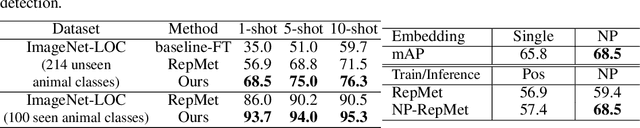
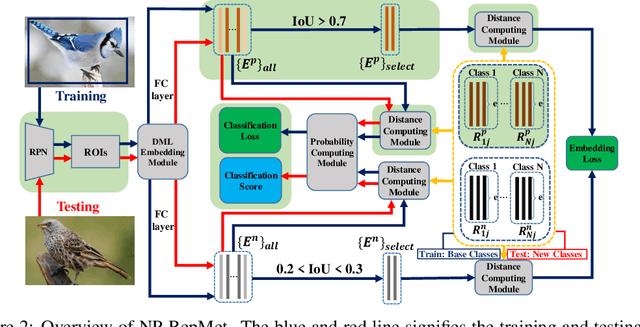

Few-shot learning has recently emerged as a new challenge in the deep learning field: unlike conventional methods that train the deep neural networks (DNNs) with a large number of labeled data, it asks for the generalization of DNNs on new classes with few annotated samples. Recent advances in few-shot learning mainly focus on image classification while in this paper we focus on object detection. The initial explorations in few-shot object detection tend to simulate a classification scenario by using the positive proposals in images with respect to certain object class while discarding the negative proposals of that class. Negatives, especially hard negatives, however, are essential to the embedding space learning in few-shot object detection. In this paper, we restore the negative information in few-shot object detection by introducing a new negative- and positive-representative based metric learning framework and a new inference scheme with negative and positive representatives. We build our work on a recent few-shot pipeline RepMet with several new modules to encode negative information for both training and testing. Extensive experiments on ImageNet-LOC and PASCAL VOC show our method substantially improves the state-of-the-art few-shot object detection solutions. Our code is available at https://github.com/yang-yk/NP-RepMet.
Structured Binary Neural Networks for Image Recognition
Sep 22, 2019
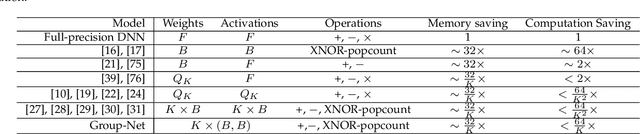
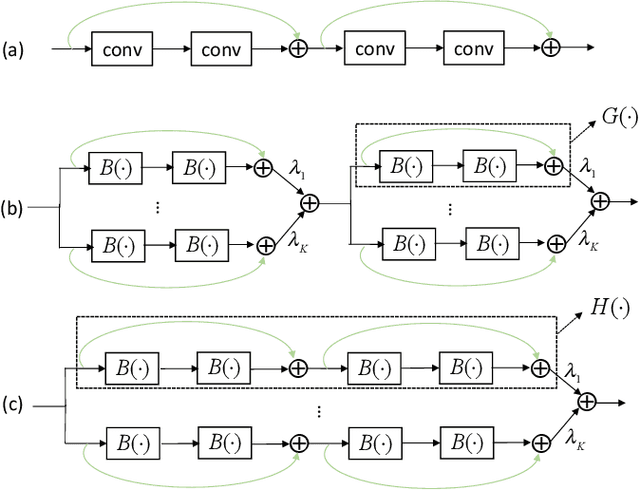

We propose methods to train convolutional neural networks (CNNs) with both binarized weights and activations, leading to quantized models that are specifically friendly to mobile devices with limited power capacity and computation resources. Previous works on quantizing CNNs often seek to approximate the floating-point information using a set of discrete values, which we call value approximation, typically assuming the same architecture as the full-precision networks. Here we take a novel "structure approximation" view of quantization---it is very likely that different architectures designed for low-bit networks may be better for achieving good performance. In particular, we propose a "network decomposition" strategy, termed Group-Net, in which we divide the network into groups. Thus, each full-precision group can be effectively reconstructed by aggregating a set of homogeneous binary branches. In addition, we learn effective connections among groups to improve the representation capability. Moreover, the proposed Group-Net shows strong generalization to other tasks. For instance, we extend Group-Net for accurate semantic segmentation by embedding rich context into the binary structure. Furthermore, for the first time, we apply binary neural networks to object detection. Experiments on both classification, semantic segmentation and object detection tasks demonstrate the superior performance of the proposed methods over various quantized networks in the literature. Our methods outperform the previous best binary neural networks in terms of accuracy and computation efficiency.
A Comparison of Deep Learning Convolution Neural Networks for Liver Segmentation in Radial Turbo Spin Echo Images
Apr 13, 2020



Motion-robust 2D Radial Turbo Spin Echo (RADTSE) pulse sequence can provide a high-resolution composite image, T2-weighted images at multiple echo times (TEs), and a quantitative T2 map, all from a single k-space acquisition. In this work, we use a deep-learning convolutional neural network (CNN) for the segmentation of liver in abdominal RADTSE images. A modified UNET architecture with generalized dice loss objective function was implemented. Three 2D CNNs were trained, one for each image type obtained from the RADTSE sequence. On evaluating the performance of the CNNs on the validation set, we found that CNNs trained on TE images or the T2 maps had higher average dice scores than the composite images. This, in turn, implies that the information regarding T2 variation in tissues aids in improving the segmentation performance.
Ontology-guided Semantic Composition for Zero-Shot Learning
Jun 30, 2020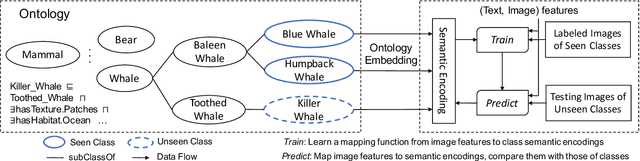
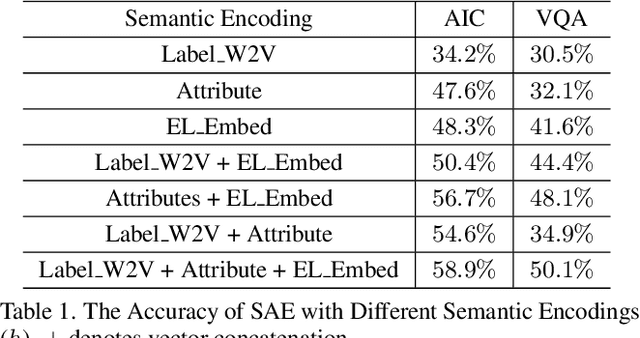

Zero-shot learning (ZSL) is a popular research problem that aims at predicting for those classes that have never appeared in the training stage by utilizing the inter-class relationship with some side information. In this study, we propose to model the compositional and expressive semantics of class labels by an OWL (Web Ontology Language) ontology, and further develop a new ZSL framework with ontology embedding. The effectiveness has been verified by some primary experiments on animal image classification and visual question answering.
Deep Active Learning with Augmentation-based Consistency Estimation
Nov 05, 2020
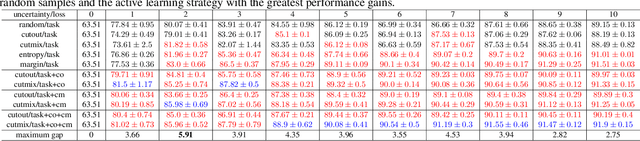
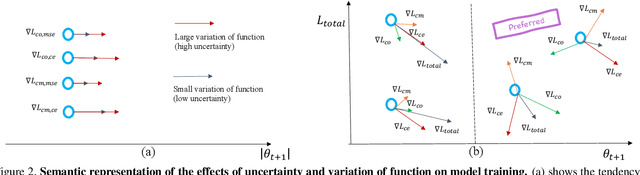

In active learning, the focus is mainly on the selection strategy of unlabeled data for enhancing the generalization capability of the next learning cycle. For this, various uncertainty measurement methods have been proposed. On the other hand, with the advent of data augmentation metrics as the regularizer on general deep learning, we notice that there can be a mutual influence between the method of unlabeled data selection and the data augmentation-based regularization techniques in active learning scenarios. Through various experiments, we confirmed that consistency-based regularization from analytical learning theory could affect the generalization capability of the classifier in combination with the existing uncertainty measurement method. By this fact, we propose a methodology to improve generalization ability, by applying data augmentation-based techniques to an active learning scenario. For the data augmentation-based regularization loss, we redefined cutout (co) and cutmix (cm) strategies as quantitative metrics and applied at both model training and unlabeled data selection steps. We have shown that the augmentation-based regularizer can lead to improved performance on the training step of active learning, while that same approach can be effectively combined with the uncertainty measurement metrics proposed so far. We used datasets such as FashionMNIST, CIFAR10, CIFAR100, and STL10 to verify the performance of the proposed active learning technique for multiple image classification tasks. Our experiments show consistent performance gains for each dataset and budget scenario.
Longevity Associated Geometry Identified in Satellite Images: Sidewalks, Driveways and Hiking Trails
Mar 05, 2020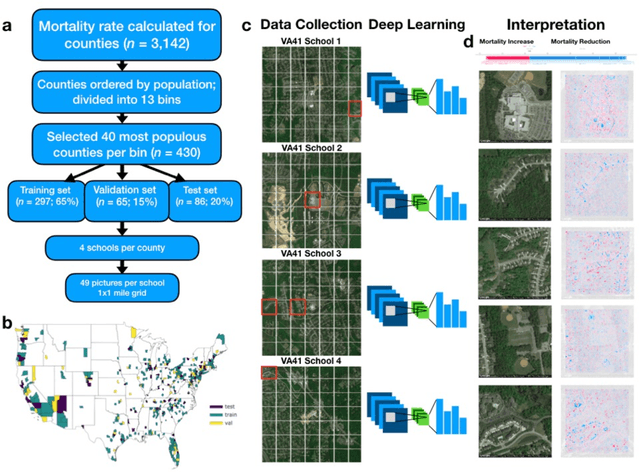
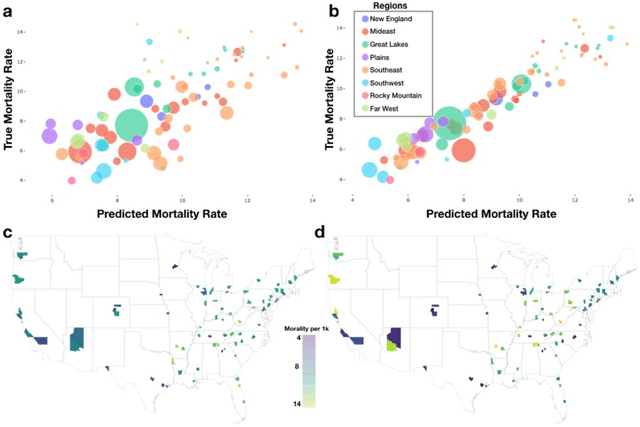
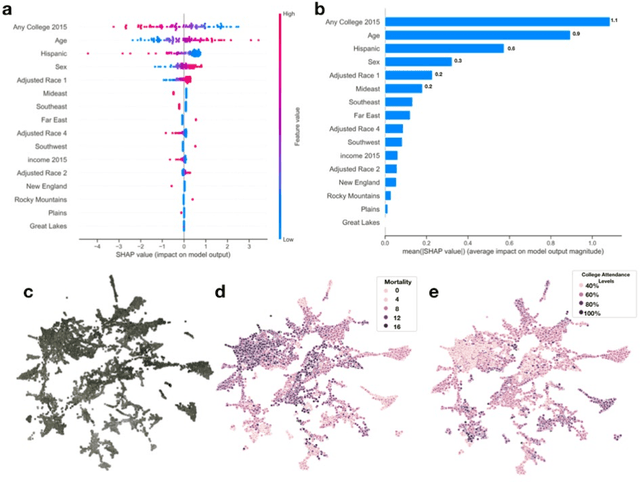
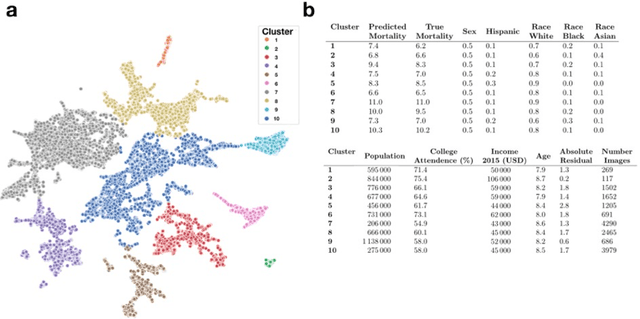
Importance: Following a century of increase, life expectancy in the United States has stagnated and begun to decline in recent decades. Using satellite images and street view images prior work has demonstrated associations of the built environment with income, education, access to care and health factors such as obesity. However, assessment of learned image feature relationships with variation in crude mortality rate across the United States has been lacking. Objective: Investigate prediction of county-level mortality rates in the U.S. using satellite images. Design: Satellite images were extracted with the Google Static Maps application programming interface for 430 counties representing approximately 68.9% of the US population. A convolutional neural network was trained using crude mortality rates for each county in 2015 to predict mortality. Learned image features were interpreted using Shapley Additive Feature Explanations, clustered, and compared to mortality and its associated covariate predictors. Main Outcomes and Measures: County mortality was predicted using satellite images. Results: Predicted mortality from satellite images in a held-out test set of counties was strongly correlated to the true crude mortality rate (Pearson r=0.72). Learned image features were clustered, and we identified 10 clusters that were associated with education, income, geographical region, race and age. Conclusion and Relevance: The application of deep learning techniques to remotely-sensed features of the built environment can serve as a useful predictor of mortality in the United States. Tools that are able to identify image features associated with health-related outcomes can inform targeted public health interventions.
Fast Class-wise Updating for Online Hashing
Dec 01, 2020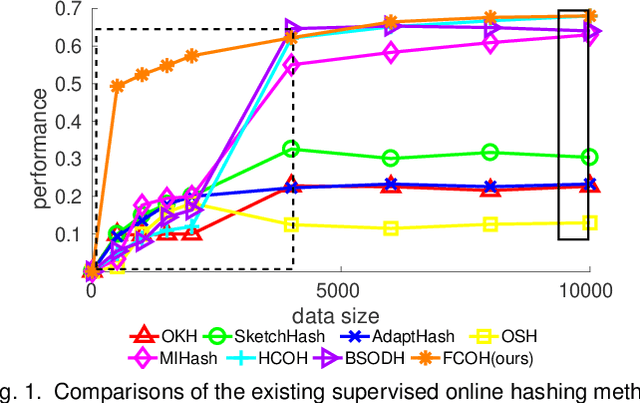
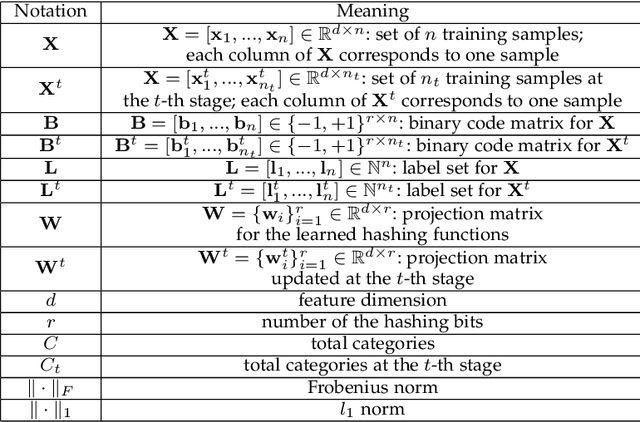
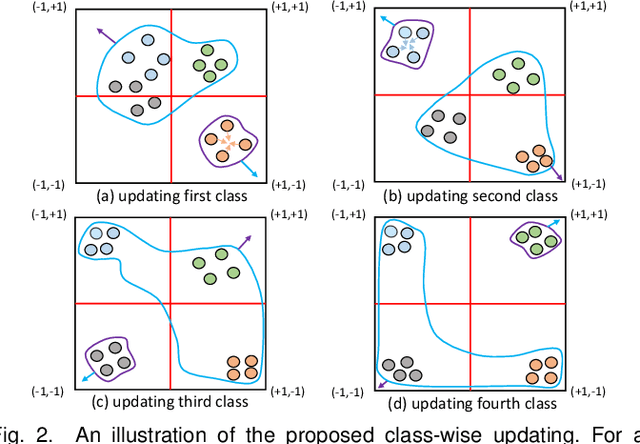
Online image hashing has received increasing research attention recently, which processes large-scale data in a streaming fashion to update the hash functions on-the-fly. To this end, most existing works exploit this problem under a supervised setting, i.e., using class labels to boost the hashing performance, which suffers from the defects in both adaptivity and efficiency: First, large amounts of training batches are required to learn up-to-date hash functions, which leads to poor online adaptivity. Second, the training is time-consuming, which contradicts with the core need of online learning. In this paper, a novel supervised online hashing scheme, termed Fast Class-wise Updating for Online Hashing (FCOH), is proposed to address the above two challenges by introducing a novel and efficient inner product operation. To achieve fast online adaptivity, a class-wise updating method is developed to decompose the binary code learning and alternatively renew the hash functions in a class-wise fashion, which well addresses the burden on large amounts of training batches. Quantitatively, such a decomposition further leads to at least 75% storage saving. To further achieve online efficiency, we propose a semi-relaxation optimization, which accelerates the online training by treating different binary constraints independently. Without additional constraints and variables, the time complexity is significantly reduced. Such a scheme is also quantitatively shown to well preserve past information during updating hashing functions. We have quantitatively demonstrated that the collective effort of class-wise updating and semi-relaxation optimization provides a superior performance comparing to various state-of-the-art methods, which is verified through extensive experiments on three widely-used datasets.