 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Viewmaker Networks: Learning Views for Unsupervised Representation Learning
Oct 14, 2020

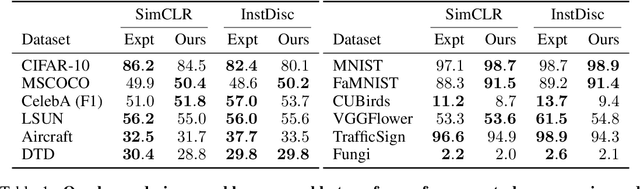
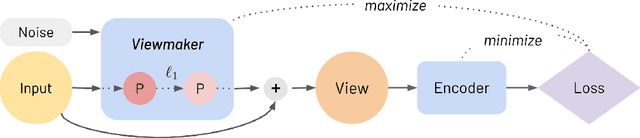
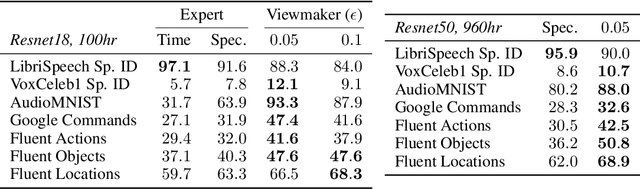
Many recent methods for unsupervised representation learning involve training models to be invariant to different "views," or transformed versions of an input. However, designing these views requires considerable human expertise and experimentation, hindering widespread adoption of unsupervised representation learning methods across domains and modalities. To address this, we propose viewmaker networks: generative models that learn to produce input-dependent views for contrastive learning. We train this network jointly with an encoder network to produce adversarial $\ell_p$ perturbations for an input, which yields challenging yet useful views without extensive human tuning. Our learned views, when applied to CIFAR-10, enable comparable transfer accuracy to the the well-studied augmentations used for the SimCLR model. Our views significantly outperforming baseline augmentations in speech (+9% absolute) and wearable sensor (+17% absolute) domains. We also show how viewmaker views can be combined with handcrafted views to improve robustness to common image corruptions. Our method demonstrates that learned views are a promising way to reduce the amount of expertise and effort needed for unsupervised learning, potentially extending its benefits to a much wider set of domains.
Enhanced Object Detection via Fusion With Prior Beliefs from Image Classification
Oct 21, 2016
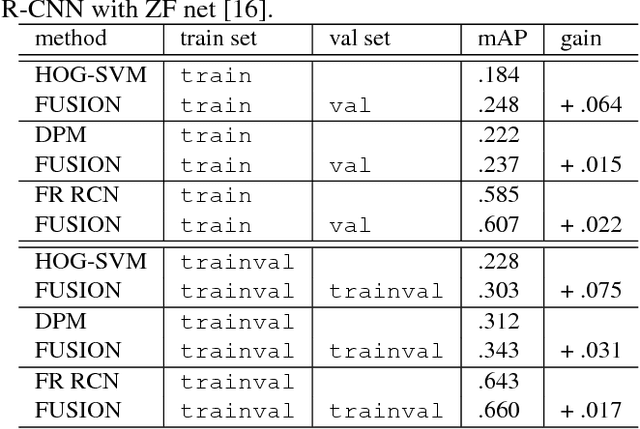
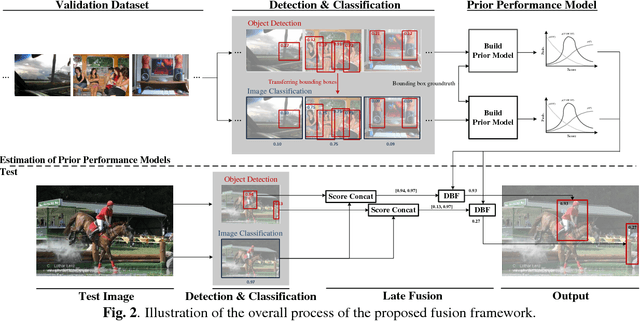
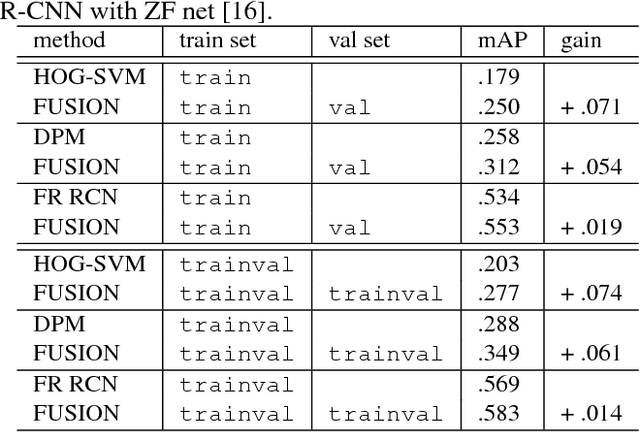
In this paper, we introduce a novel fusion method that can enhance object detection performance by fusing decisions from two different types of computer vision tasks: object detection and image classification. In the proposed work, the class label of an image obtained from image classification is viewed as prior knowledge about existence or non-existence of certain objects. The prior knowledge is then fused with the decisions of object detection to improve detection accuracy by mitigating false positives of an object detector that are strongly contradicted with the prior knowledge. A recently introduced novel fusion approach called dynamic belief fusion (DBF) is used to fuse the detector output with the classification prior. Experimental results show that the detection performance of all the detection algorithms used in the proposed work is improved on benchmark datasets via the proposed fusion framework.
On Interpretability of Deep Learning based Skin Lesion Classifiers using Concept Activation Vectors
May 05, 2020
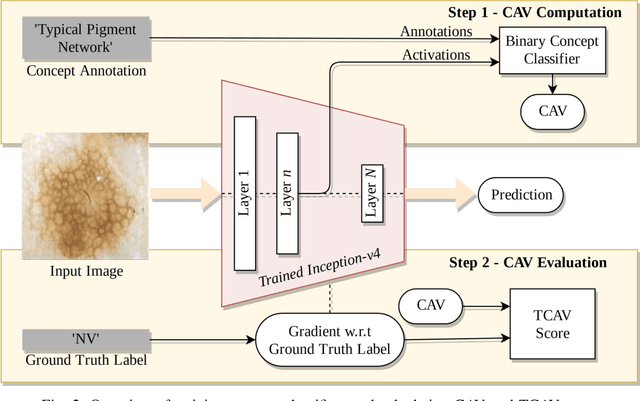
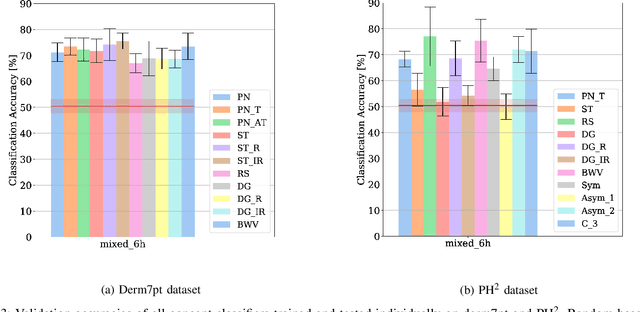
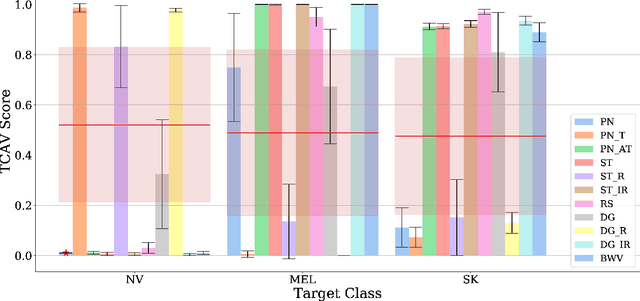
Deep learning based medical image classifiers have shown remarkable prowess in various application areas like ophthalmology, dermatology, pathology, and radiology. However, the acceptance of these Computer-Aided Diagnosis (CAD) systems in real clinical setups is severely limited primarily because their decision-making process remains largely obscure. This work aims at elucidating a deep learning based medical image classifier by verifying that the model learns and utilizes similar disease-related concepts as described and employed by dermatologists. We used a well-trained and high performing neural network developed by REasoning for COmplex Data (RECOD) Lab for classification of three skin tumours, i.e. Melanocytic Naevi, Melanoma and Seborrheic Keratosis and performed a detailed analysis on its latent space. Two well established and publicly available skin disease datasets, PH2 and derm7pt, are used for experimentation. Human understandable concepts are mapped to RECOD image classification model with the help of Concept Activation Vectors (CAVs), introducing a novel training and significance testing paradigm for CAVs. Our results on an independent evaluation set clearly shows that the classifier learns and encodes human understandable concepts in its latent representation. Additionally, TCAV scores (Testing with CAVs) suggest that the neural network indeed makes use of disease-related concepts in the correct way when making predictions. We anticipate that this work can not only increase confidence of medical practitioners on CAD but also serve as a stepping stone for further development of CAV-based neural network interpretation methods.
Learning to Caption Images with Two-Stream Attention and Sentence Auto-Encoder
Nov 22, 2019


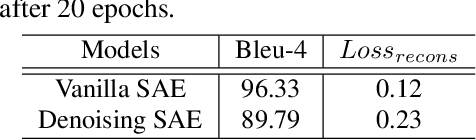
Automatically generating natural language descriptions from an image is a challenging problem in artificial intelligence that requires a good understanding of the correlations between visual and textual cues. To bridge these two modalities, state-of-the-art methods commonly use a dynamic interface between image and text, called attention, that learns to identify related image parts to estimate the next word conditioned on the previous steps. While this mechanism is effective, it fails to find the right associations between visual and textual cues when they are noisy. In this paper we propose two novel approaches to address this issue - (i) a two-stream attention mechanism that can automatically discover latent categories and relate them to image regions based on the previously generated words, (ii) a regularization technique that encapsulates the syntactic and semantic structure of captions and improves the optimization of the image captioning model. Our qualitative and quantitative results demonstrate remarkable improvements on the MSCOCO dataset setting and lead to new state-of-the-art performances for image captioning.
Large-Scale Evolution of Image Classifiers
Jun 11, 2017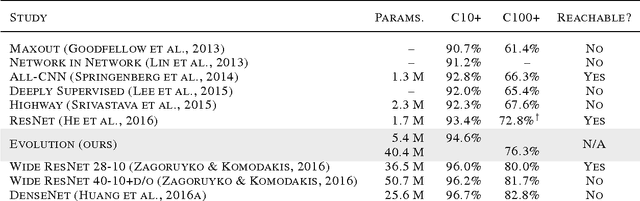
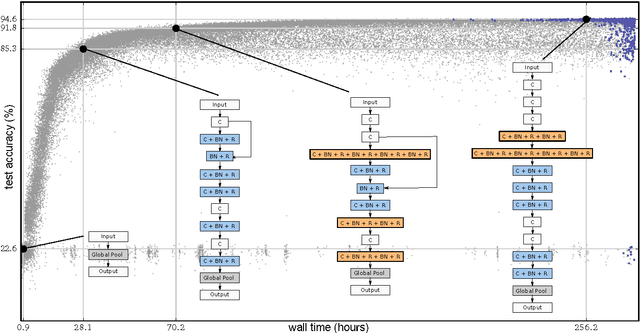
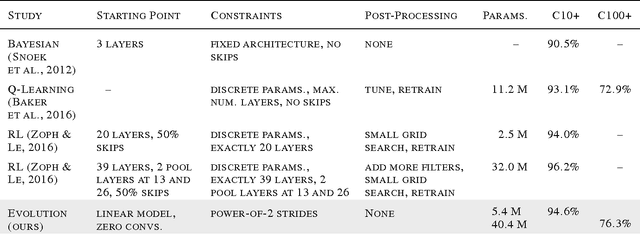
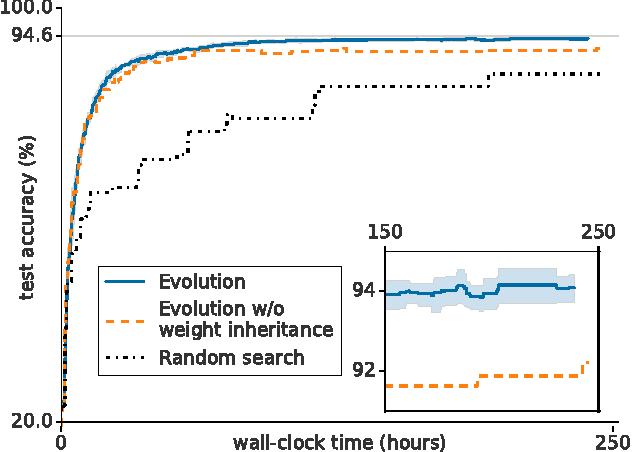
Neural networks have proven effective at solving difficult problems but designing their architectures can be challenging, even for image classification problems alone. Our goal is to minimize human participation, so we employ evolutionary algorithms to discover such networks automatically. Despite significant computational requirements, we show that it is now possible to evolve models with accuracies within the range of those published in the last year. Specifically, we employ simple evolutionary techniques at unprecedented scales to discover models for the CIFAR-10 and CIFAR-100 datasets, starting from trivial initial conditions and reaching accuracies of 94.6% (95.6% for ensemble) and 77.0%, respectively. To do this, we use novel and intuitive mutation operators that navigate large search spaces; we stress that no human participation is required once evolution starts and that the output is a fully-trained model. Throughout this work, we place special emphasis on the repeatability of results, the variability in the outcomes and the computational requirements.
Multi-Modal Graph Neural Network for Joint Reasoning on Vision and Scene Text
Mar 31, 2020
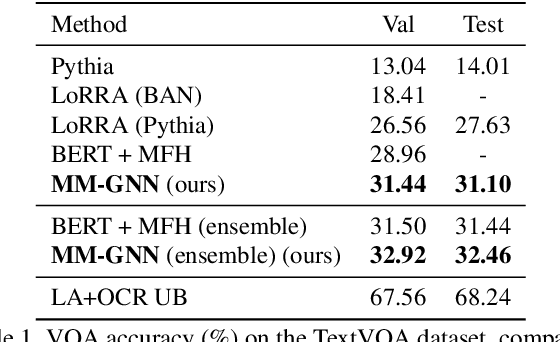

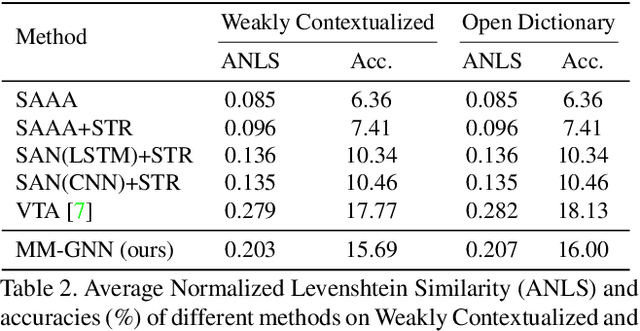
Answering questions that require reading texts in an image is challenging for current models. One key difficulty of this task is that rare, polysemous, and ambiguous words frequently appear in images, e.g., names of places, products, and sports teams. To overcome this difficulty, only resorting to pre-trained word embedding models is far from enough. A desired model should utilize the rich information in multiple modalities of the image to help understand the meaning of scene texts, e.g., the prominent text on a bottle is most likely to be the brand. Following this idea, we propose a novel VQA approach, Multi-Modal Graph Neural Network (MM-GNN). It first represents an image as a graph consisting of three sub-graphs, depicting visual, semantic, and numeric modalities respectively. Then, we introduce three aggregators which guide the message passing from one graph to another to utilize the contexts in various modalities, so as to refine the features of nodes. The updated nodes have better features for the downstream question answering module. Experimental evaluations show that our MM-GNN represents the scene texts better and obviously facilitates the performances on two VQA tasks that require reading scene texts.
Multiple Attentional Pyramid Networks for Chinese Herbal Recognition
May 13, 2020
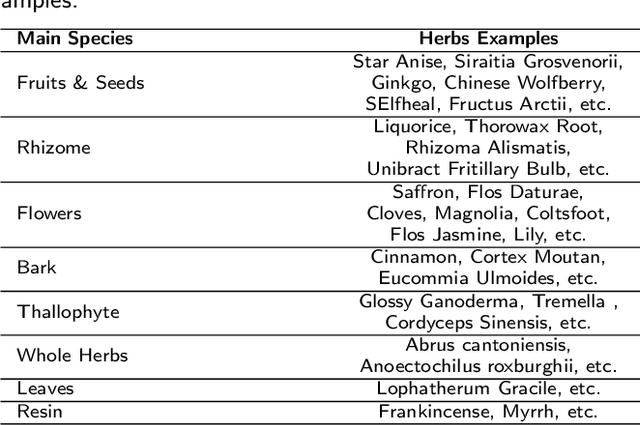
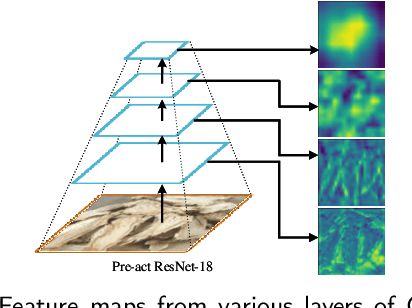
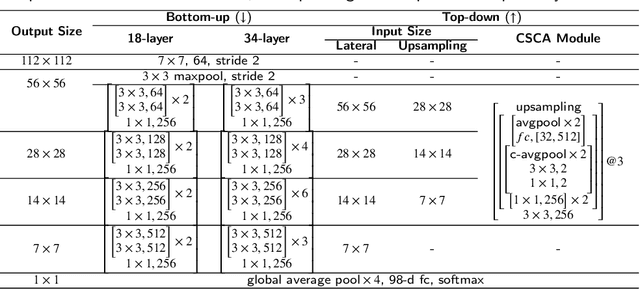
Chinese herbs play a critical role in Traditional Chinese Medicine. Due to different recognition granularity, they can be recognized accurately only by professionals with much experience. It is expected that they can be recognized automatically using new techniques like machine learning. However, there is no Chinese herbal image dataset available. Simultaneously, there is no machine learning method which can deal with Chinese herbal image recognition well. Therefore, this paper begins with building a new standard Chinese-Herbs dataset. Subsequently, a new Attentional Pyramid Networks (APN) for Chinese herbal recognition is proposed, where both novel competitive attention and spatial collaborative attention are proposed and then applied. APN can adaptively model Chinese herbal images with different feature scales. Finally, a new framework for Chinese herbal recognition is proposed as a new application of APN. Experiments are conducted on our constructed dataset and validate the effectiveness of our methods.
Exploiting Local Features from Deep Networks for Image Retrieval
Apr 30, 2015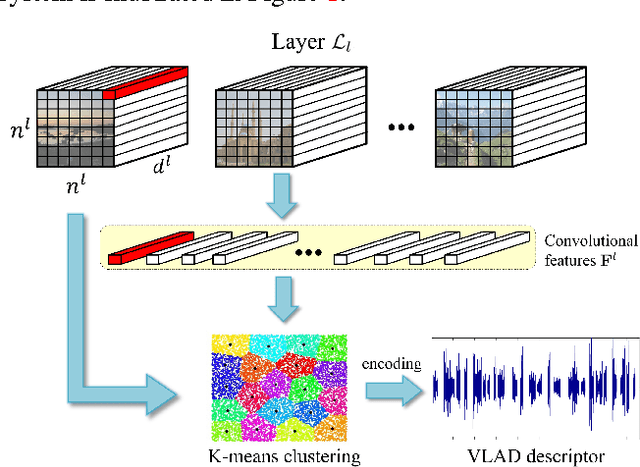
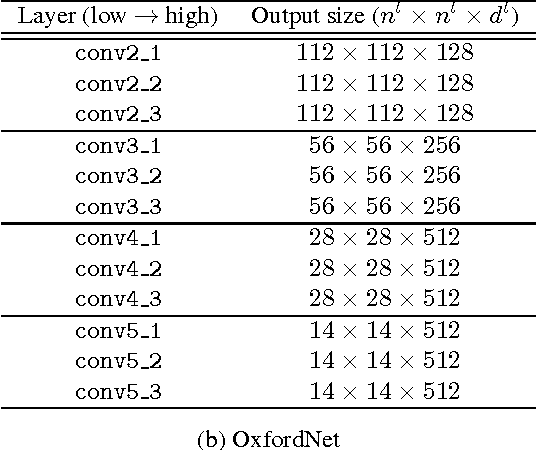
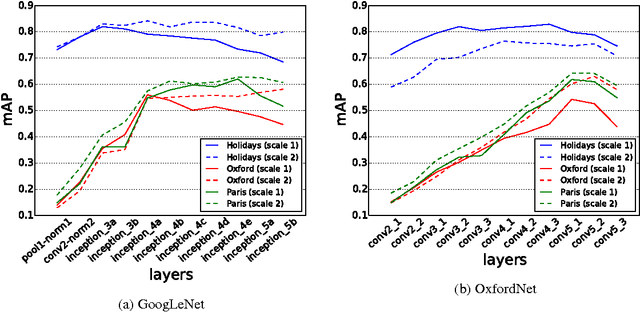
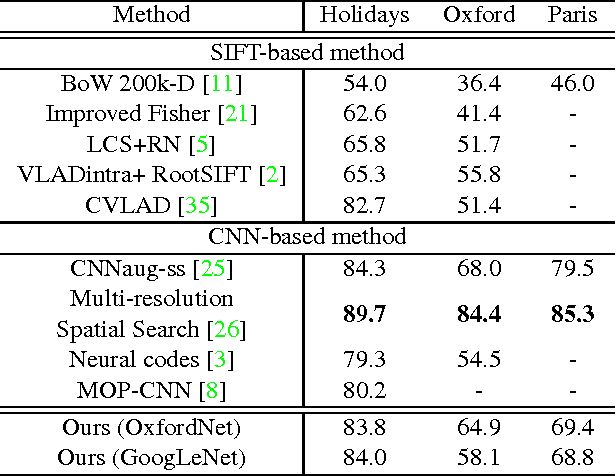
Deep convolutional neural networks have been successfully applied to image classification tasks. When these same networks have been applied to image retrieval, the assumption has been made that the last layers would give the best performance, as they do in classification. We show that for instance-level image retrieval, lower layers often perform better than the last layers in convolutional neural networks. We present an approach for extracting convolutional features from different layers of the networks, and adopt VLAD encoding to encode features into a single vector for each image. We investigate the effect of different layers and scales of input images on the performance of convolutional features using the recent deep networks OxfordNet and GoogLeNet. Experiments demonstrate that intermediate layers or higher layers with finer scales produce better results for image retrieval, compared to the last layer. When using compressed 128-D VLAD descriptors, our method obtains state-of-the-art results and outperforms other VLAD and CNN based approaches on two out of three test datasets. Our work provides guidance for transferring deep networks trained on image classification to image retrieval tasks.
Pragmatic factors in image description: the case of negations
Jun 27, 2016
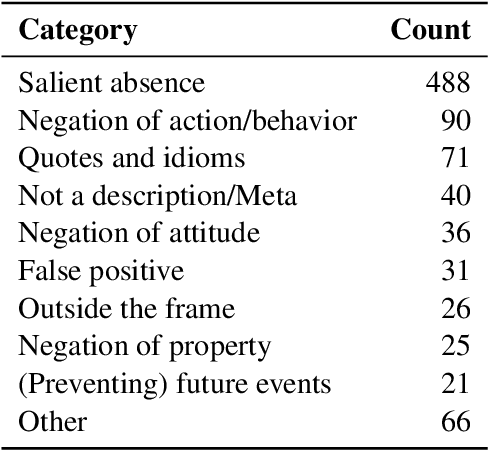
We provide a qualitative analysis of the descriptions containing negations (no, not, n't, nobody, etc) in the Flickr30K corpus, and a categorization of negation uses. Based on this analysis, we provide a set of requirements that an image description system should have in order to generate negation sentences. As a pilot experiment, we used our categorization to manually annotate sentences containing negations in the Flickr30K corpus, with an agreement score of K=0.67. With this paper, we hope to open up a broader discussion of subjective language in image descriptions.
HDR image reconstruction from a single exposure using deep CNNs
Oct 20, 2017
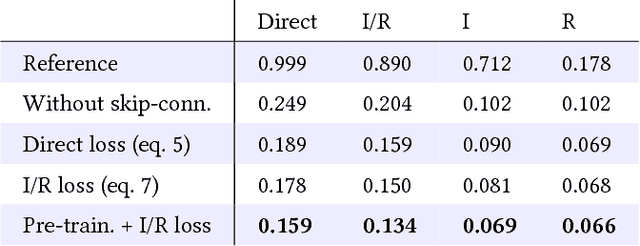
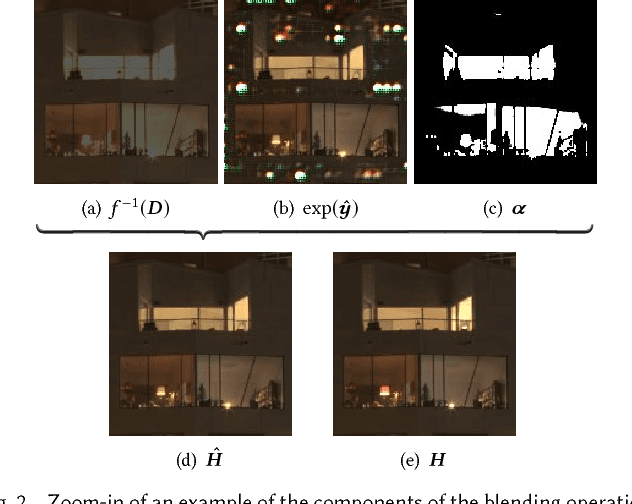
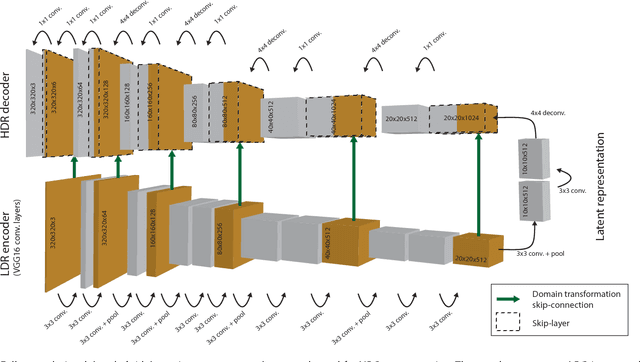
Camera sensors can only capture a limited range of luminance simultaneously, and in order to create high dynamic range (HDR) images a set of different exposures are typically combined. In this paper we address the problem of predicting information that have been lost in saturated image areas, in order to enable HDR reconstruction from a single exposure. We show that this problem is well-suited for deep learning algorithms, and propose a deep convolutional neural network (CNN) that is specifically designed taking into account the challenges in predicting HDR values. To train the CNN we gather a large dataset of HDR images, which we augment by simulating sensor saturation for a range of cameras. To further boost robustness, we pre-train the CNN on a simulated HDR dataset created from a subset of the MIT Places database. We demonstrate that our approach can reconstruct high-resolution visually convincing HDR results in a wide range of situations, and that it generalizes well to reconstruction of images captured with arbitrary and low-end cameras that use unknown camera response functions and post-processing. Furthermore, we compare to existing methods for HDR expansion, and show high quality results also for image based lighting. Finally, we evaluate the results in a subjective experiment performed on an HDR display. This shows that the reconstructed HDR images are visually convincing, with large improvements as compared to existing methods.
* 15 pages, 19 figures, Siggraph Asia 2017. Project webpage located at http://hdrv.org/hdrcnn/ where paper with high quality images is available, as well as supplementary material (document, images, video and source code)