 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ExpertNet: Adversarial Learning and Recovery Against Noisy Labels
Jul 13, 2020
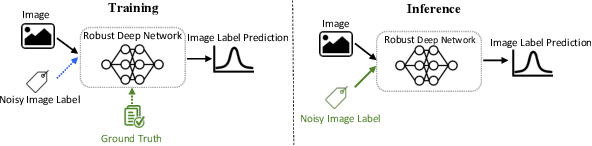
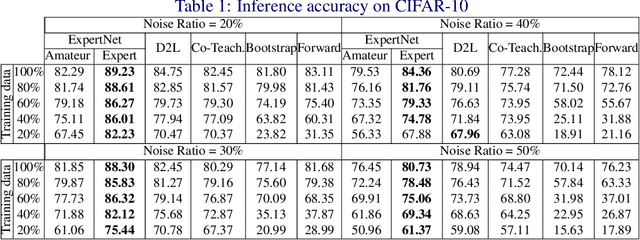
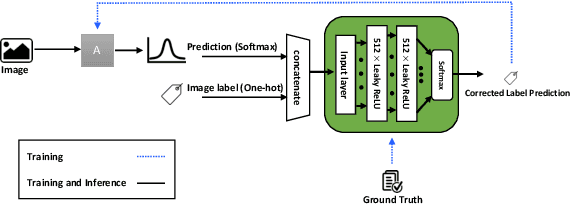
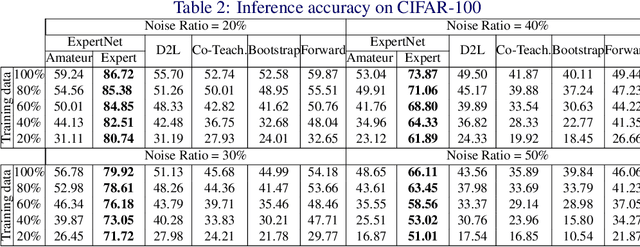
Today's available datasets in the wild, e.g., from social media and open platforms, present tremendous opportunities and challenges for deep learning, as there is a significant portion of tagged images, but often with noisy, i.e. erroneous, labels. Recent studies improve the robustness of deep models against noisy labels without the knowledge of true labels. In this paper, we advocate to derive a stronger classifier which proactively makes use of the noisy labels in addition to the original images - turning noisy labels into learning features. To such an end, we propose a novel framework, ExpertNet, composed of Amateur and Expert, which iteratively learn from each other. Amateur is a regular image classifier trained by the feedback of Expert, which imitates how human experts would correct the predicted labels from Amateur using the noise pattern learnt from the knowledge of both the noisy and ground truth labels. The trained Amateur and Expert proactively leverage the images and their noisy labels to infer image classes. Our empirical evaluations on noisy versions of CIFAR-10, CIFAR-100 and real-world data of Clothing1M show that the proposed model can achieve robust classification against a wide range of noise ratios and with as little as 20-50% training data, compared to state-of-the-art deep models that solely focus on distilling the impact of noisy labels.
Multi-Band Image Fusion Based on Spectral Unmixing
Mar 29, 2016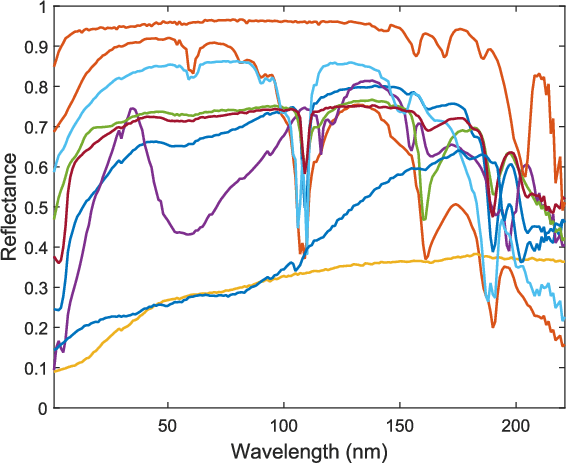

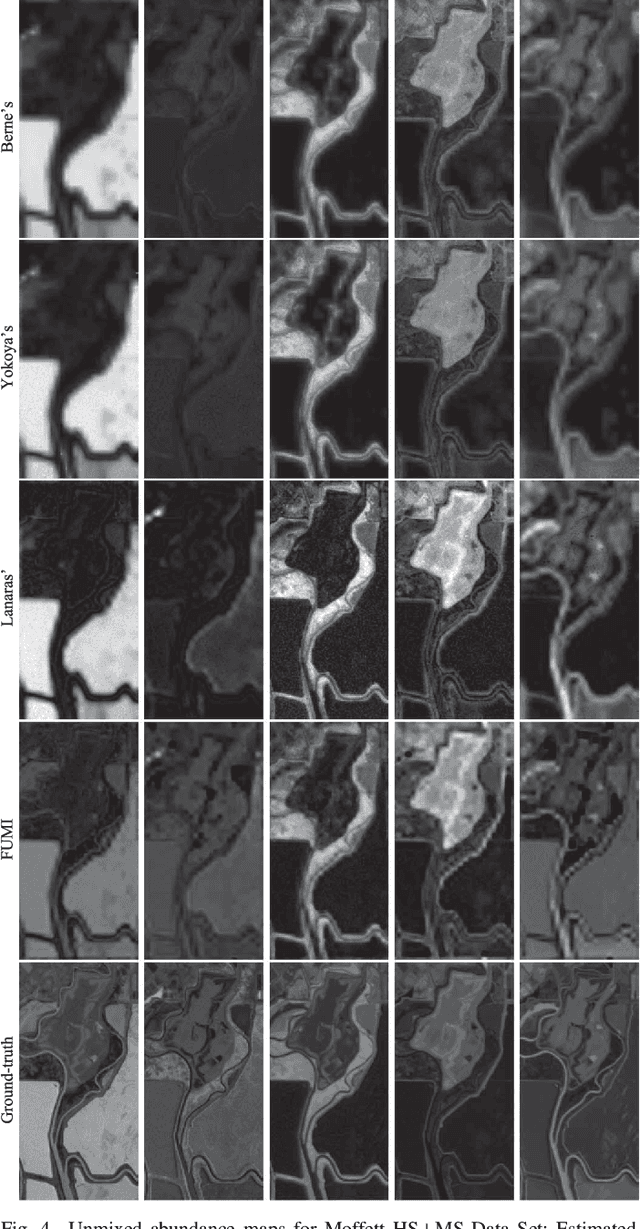

This paper presents a multi-band image fusion algorithm based on unsupervised spectral unmixing for combining a high-spatial low-spectral resolution image and a low-spatial high-spectral resolution image. The widely used linear observation model (with additive Gaussian noise) is combined with the linear spectral mixture model to form the likelihoods of the observations. The non-negativity and sum-to-one constraints resulting from the intrinsic physical properties of the abundances are introduced as prior information to regularize this ill-posed problem. The joint fusion and unmixing problem is then formulated as maximizing the joint posterior distribution with respect to the endmember signatures and abundance maps, This optimization problem is attacked with an alternating optimization strategy. The two resulting sub-problems are convex and are solved efficiently using the alternating direction method of multipliers. Experiments are conducted for both synthetic and semi-real data. Simulation results show that the proposed unmixing based fusion scheme improves both the abundance and endmember estimation comparing with the state-of-the-art joint fusion and unmixing algorithms.
Pose Proposal Critic: Robust Pose Refinement by Learning Reprojection Errors
May 14, 2020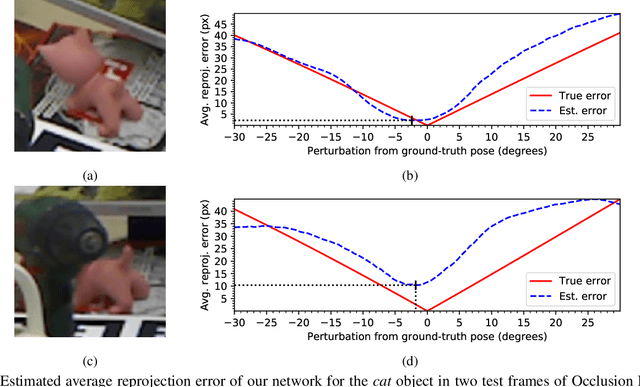
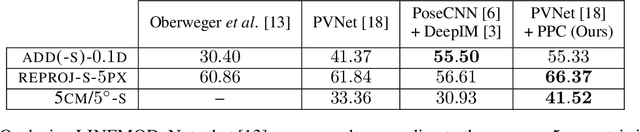
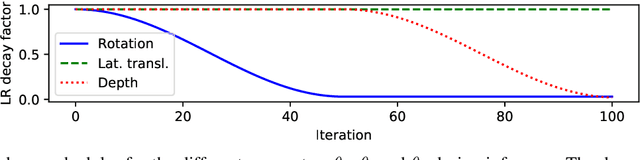

In recent years, considerable progress has been made for the task of rigid object pose estimation from a single RGB-image, but achieving robustness to partial occlusions remains a challenging problem. Pose refinement via rendering has shown promise in order to achieve improved results, in particular, when data is scarce. In this paper we focus our attention on pose refinement, and show how to push the state-of-the-art further in the case of partial occlusions. The proposed pose refinement method leverages on a simplified learning task, where a CNN is trained to estimate the reprojection error between an observed and a rendered image. We experiment by training on purely synthetic data as well as a mixture of synthetic and real data. Current state-of-the-art results are outperformed for two out of three metrics on the Occlusion LINEMOD benchmark, while performing on-par for the final metric.
Spatio-Temporal Inception Graph Convolutional Networks for Skeleton-Based Action Recognition
Nov 26, 2020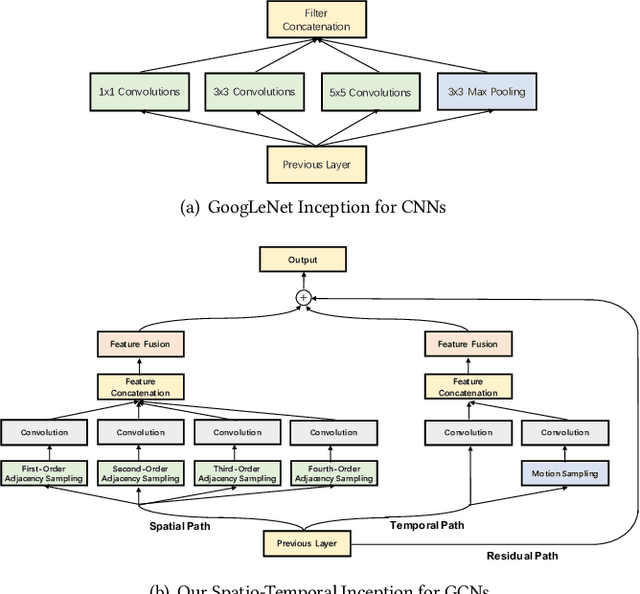
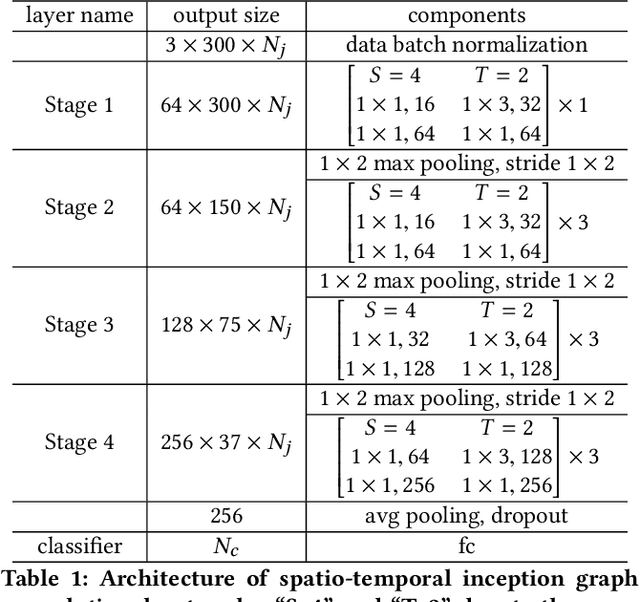

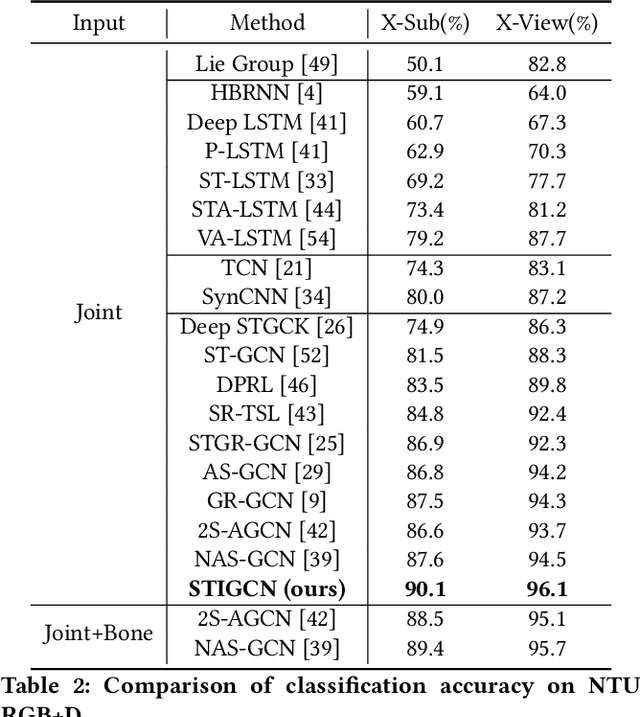
Skeleton-based human action recognition has attracted much attention with the prevalence of accessible depth sensors. Recently, graph convolutional networks (GCNs) have been widely used for this task due to their powerful capability to model graph data. The topology of the adjacency graph is a key factor for modeling the correlations of the input skeletons. Thus, previous methods mainly focus on the design/learning of the graph topology. But once the topology is learned, only a single-scale feature and one transformation exist in each layer of the networks. Many insights, such as multi-scale information and multiple sets of transformations, that have been proven to be very effective in convolutional neural networks (CNNs), have not been investigated in GCNs. The reason is that, due to the gap between graph-structured skeleton data and conventional image/video data, it is very challenging to embed these insights into GCNs. To overcome this gap, we reinvent the split-transform-merge strategy in GCNs for skeleton sequence processing. Specifically, we design a simple and highly modularized graph convolutional network architecture for skeleton-based action recognition. Our network is constructed by repeating a building block that aggregates multi-granularity information from both the spatial and temporal paths. Extensive experiments demonstrate that our network outperforms state-of-the-art methods by a significant margin with only 1/5 of the parameters and 1/10 of the FLOPs.
Learning Disentangled Representations via Mutual Information Estimation
Dec 09, 2019
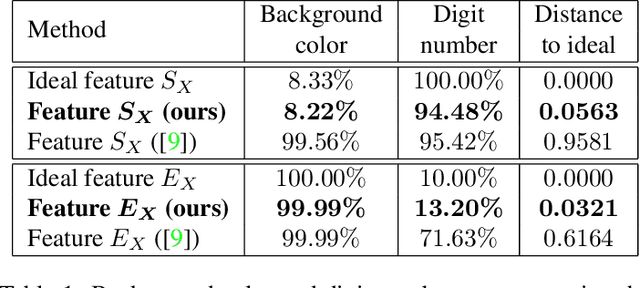
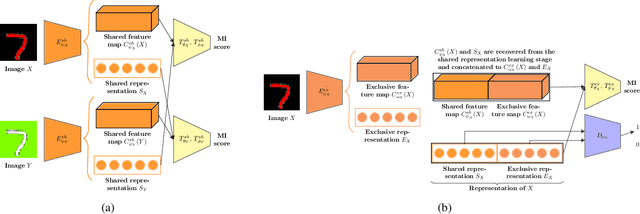
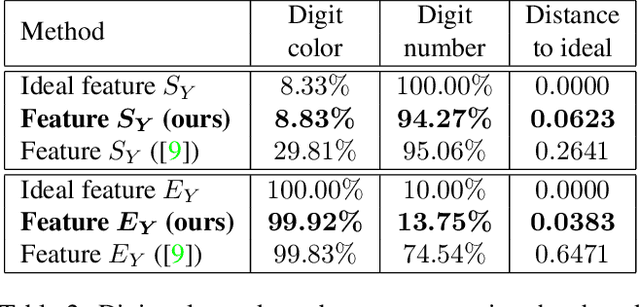
In this paper, we investigate the problem of learning disentangled representations. Given a pair of images sharing some attributes, we aim to create a low-dimensional representation which is split into two parts: a shared representation that captures the common information between the images and an exclusive representation that contains the specific information of each image. To address this issue, we propose a model based on mutual information estimation without relying on image reconstruction or image generation. Mutual information maximization is performed to capture the attributes of data in the shared and exclusive representations while we minimize the mutual information between the shared and exclusive representation to enforce representation disentanglement. We show that these representations are useful to perform downstream tasks such as image classification and image retrieval based on the shared or exclusive component. Moreover, classification results show that our model outperforms the state-of-the-art model based on VAE/GAN approaches in representation disentanglement.
Unsupervised Disentanglement of Pose, Appearance and Background from Images and Videos
Jan 26, 2020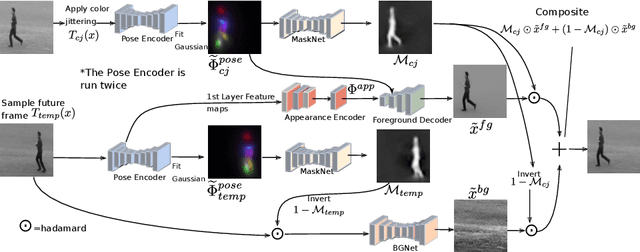

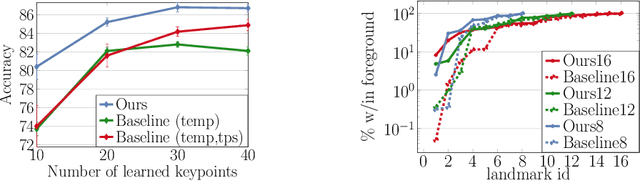
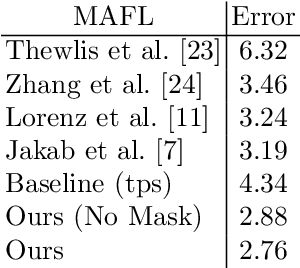
Unsupervised landmark learning is the task of learning semantic keypoint-like representations without the use of expensive input keypoint-level annotations. A popular approach is to factorize an image into a pose and appearance data stream, then to reconstruct the image from the factorized components. The pose representation should capture a set of consistent and tightly localized landmarks in order to facilitate reconstruction of the input image. Ultimately, we wish for our learned landmarks to focus on the foreground object of interest. However, the reconstruction task of the entire image forces the model to allocate landmarks to model the background. This work explores the effects of factorizing the reconstruction task into separate foreground and background reconstructions, conditioning only the foreground reconstruction on the unsupervised landmarks. Our experiments demonstrate that the proposed factorization results in landmarks that are focused on the foreground object of interest. Furthermore, the rendered background quality is also improved, as the background rendering pipeline no longer requires the ill-suited landmarks to model its pose and appearance. We demonstrate this improvement in the context of the video-prediction task.
Enhanced Object Detection via Fusion With Prior Beliefs from Image Classification
Oct 21, 2016
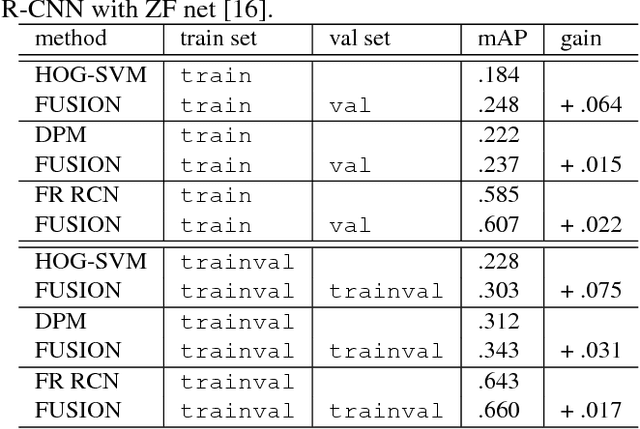
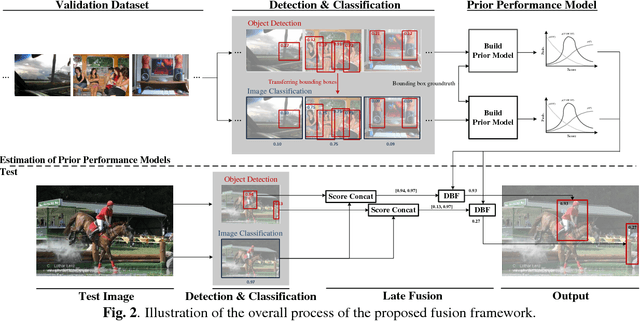
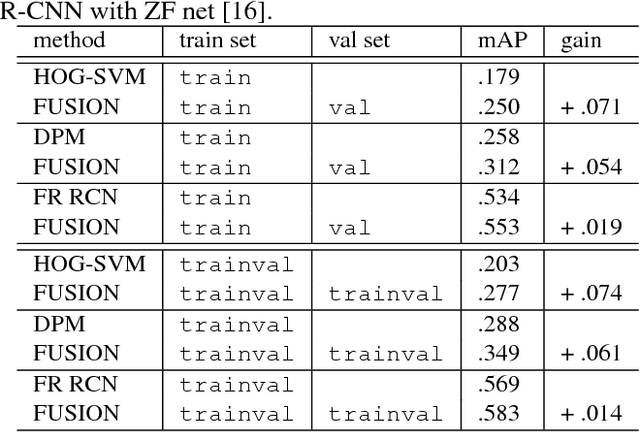
In this paper, we introduce a novel fusion method that can enhance object detection performance by fusing decisions from two different types of computer vision tasks: object detection and image classification. In the proposed work, the class label of an image obtained from image classification is viewed as prior knowledge about existence or non-existence of certain objects. The prior knowledge is then fused with the decisions of object detection to improve detection accuracy by mitigating false positives of an object detector that are strongly contradicted with the prior knowledge. A recently introduced novel fusion approach called dynamic belief fusion (DBF) is used to fuse the detector output with the classification prior. Experimental results show that the detection performance of all the detection algorithms used in the proposed work is improved on benchmark datasets via the proposed fusion framework.
Exploiting Local Features from Deep Networks for Image Retrieval
Apr 30, 2015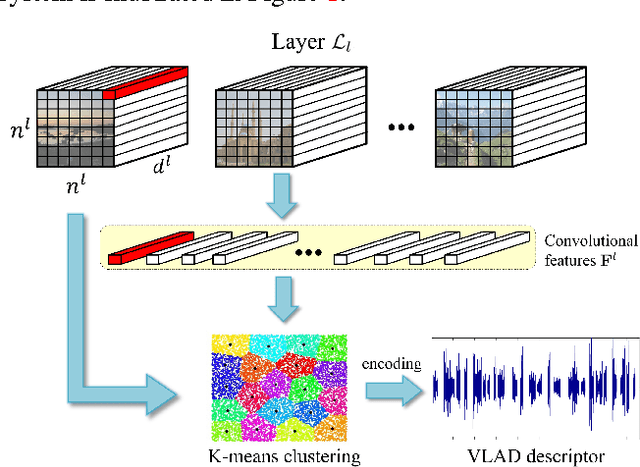
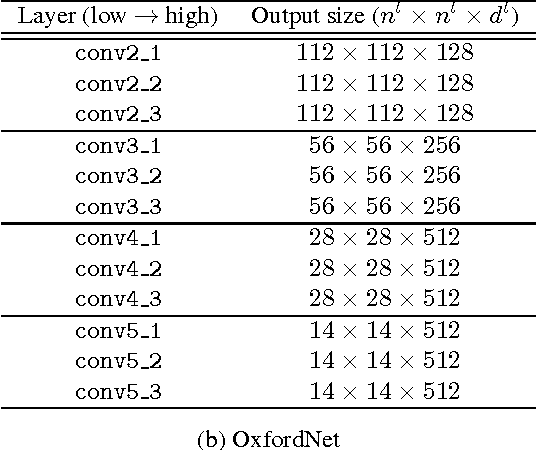
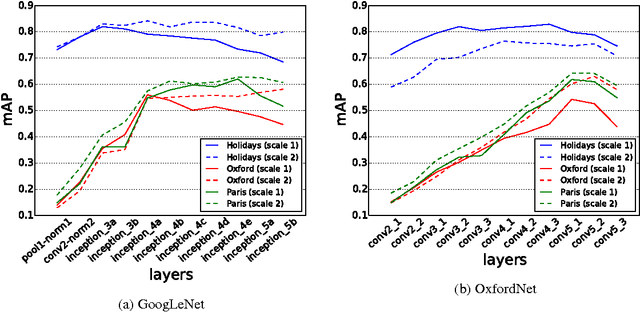
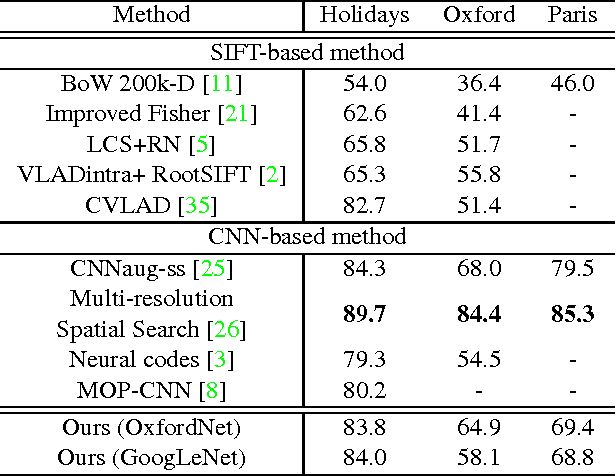
Deep convolutional neural networks have been successfully applied to image classification tasks. When these same networks have been applied to image retrieval, the assumption has been made that the last layers would give the best performance, as they do in classification. We show that for instance-level image retrieval, lower layers often perform better than the last layers in convolutional neural networks. We present an approach for extracting convolutional features from different layers of the networks, and adopt VLAD encoding to encode features into a single vector for each image. We investigate the effect of different layers and scales of input images on the performance of convolutional features using the recent deep networks OxfordNet and GoogLeNet. Experiments demonstrate that intermediate layers or higher layers with finer scales produce better results for image retrieval, compared to the last layer. When using compressed 128-D VLAD descriptors, our method obtains state-of-the-art results and outperforms other VLAD and CNN based approaches on two out of three test datasets. Our work provides guidance for transferring deep networks trained on image classification to image retrieval tasks.
Shapeshifter Networks: Cross-layer Parameter Sharing for Scalable and Effective Deep Learning
Jun 18, 2020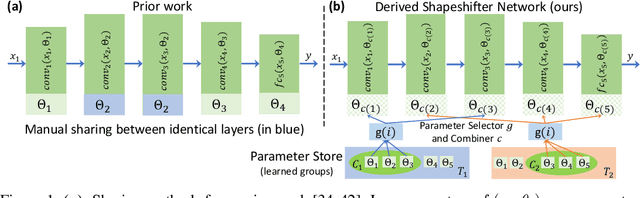
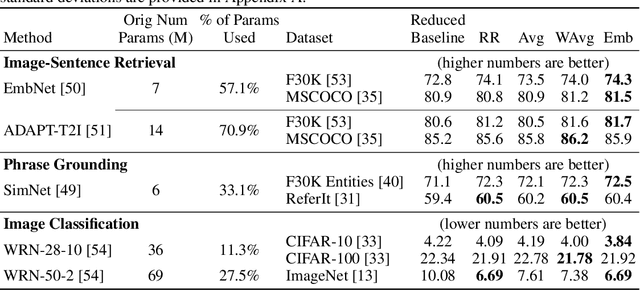
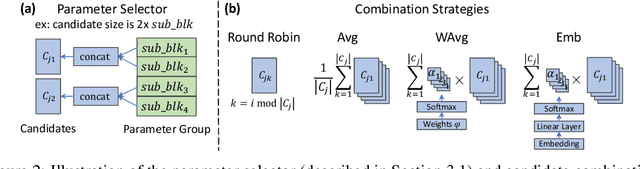
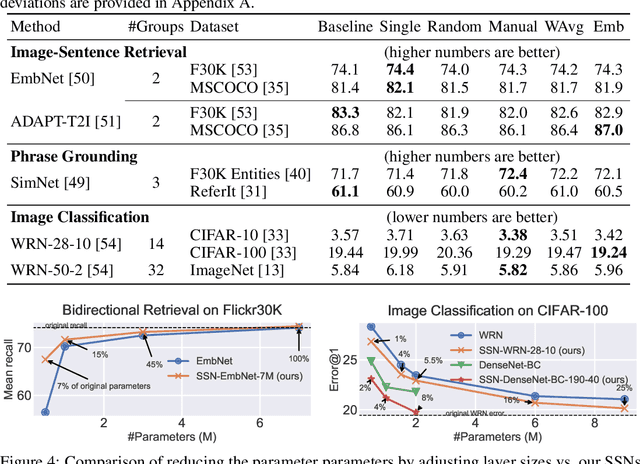
We present Shapeshifter Networks (SSNs), a flexible neural network framework that improves performance and reduces memory requirements on a diverse set of scenarios over standard neural networks. Our approach is based on the observation that many neural networks are severely overparameterized, resulting in significant waste in computational resources as well as being susceptible to overfitting. SSNs address this by learning where and how to share parameters between layers in a neural network while avoiding degenerate solutions that result in underfitting. Specifically, we automatically construct parameter groups that identify where parameter sharing is most beneficial. Then, we map each group's weights to construct layers with learned combinations of candidates from a shared parameter pool. SSNs can share parameters across layers even when they have different sizes, perform different operations, and/or operate on features from different modalities. We evaluate our approach on a diverse set of tasks, including image classification, bidirectional image-sentence retrieval, and phrase grounding, creating high performing models even when using as little as 1% of the parameters. We also apply SSNs to knowledge distillation, where we obtain state-of-the-art results when combined with traditional distillation methods.
Dense Semantic 3D Map Based Long-Term Visual Localization with Hybrid Features
May 21, 2020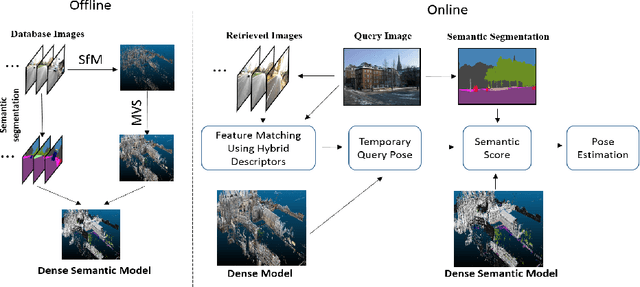
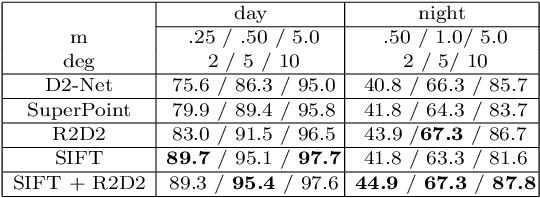

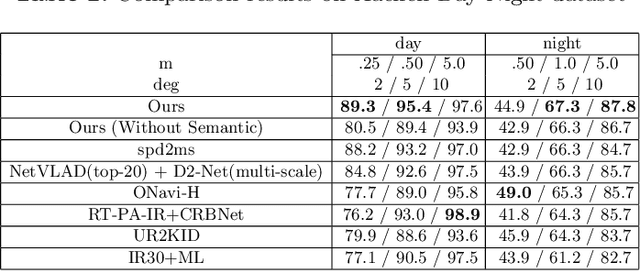
Visual localization plays an important role in many applications. However, due to the large appearance variations such as season and illumination changes, as well as weather and day-night variations, it's still a big challenge for robust long-term visual localization algorithms. In this paper, we present a novel visual localization method using hybrid handcrafted and learned features with dense semantic 3D map. Hybrid features help us to make full use of their strengths in different imaging conditions, and the dense semantic map provide us reliable and complete geometric and semantic information for constructing sufficient 2D-3D matching pairs with semantic consistency scores. In our pipeline, we retrieve and score each candidate database image through the semantic consistency between the dense model and the query image. Then the semantic consistency score is used as a soft constraint in the weighted RANSAC-based PnP pose solver. Experimental results on long-term visual localization benchmarks demonstrate the effectiveness of our method compared with state-of-the-arts.