 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-domain CT metal artifacts reduction using partial convolution based inpainting
Nov 13, 2019
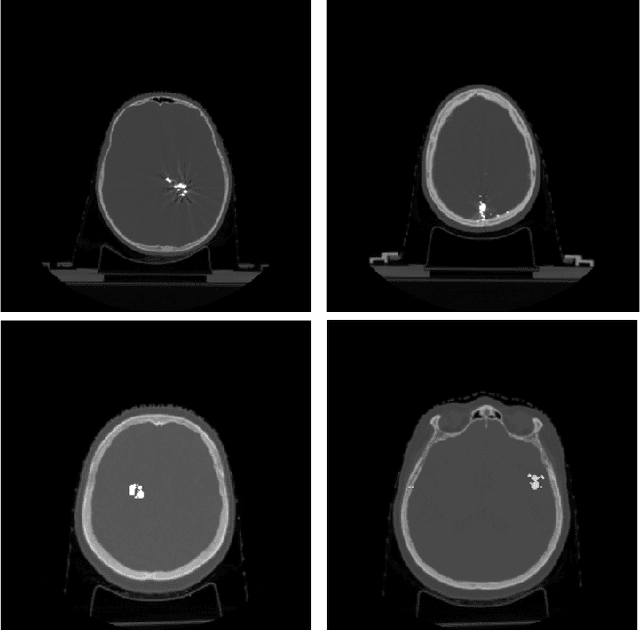
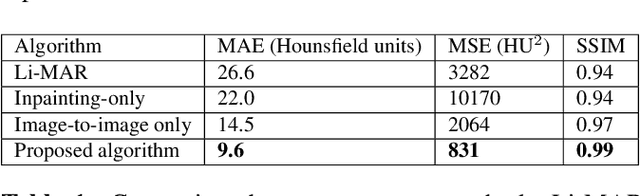
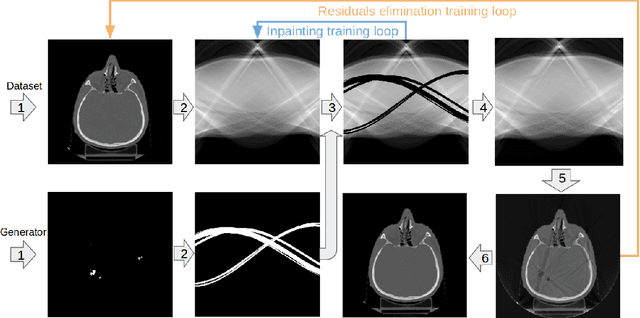
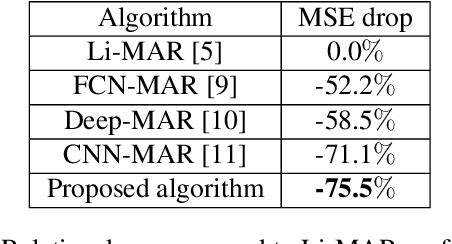
Recent CT Metal Artifacts Reduction (MAR) methods are often based on image-to-image convolutional neural networks for adjustment of corrupted sinograms or images themselves. In this paper, we are exploring the capabilities of a multi-domain method which consists of both sinogram correction (projection domain step) and restored image correction (image-domain step). Moreover, we propose a formulation of the first step problem as sinogram inpainting which allows us to use methods of this specific field such as partial convolutions. The proposed method allows to achieve state-of-the-art (-75% MSE) improvement in comparison with a classic benchmark - Li-MAR.
Bayesian Neural Networks for Uncertainty Estimation of Imaging Biomarkers
Aug 28, 2020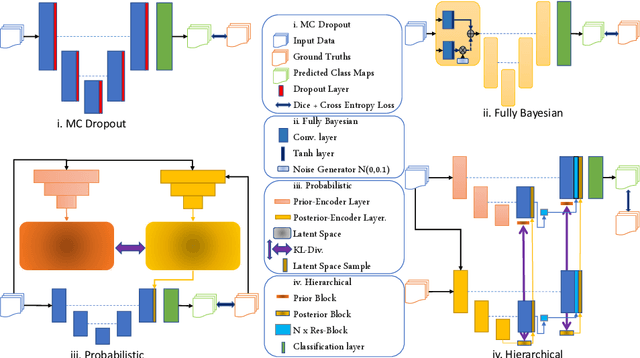
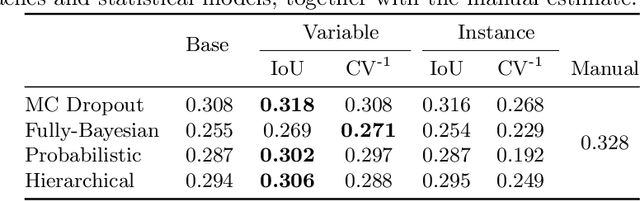
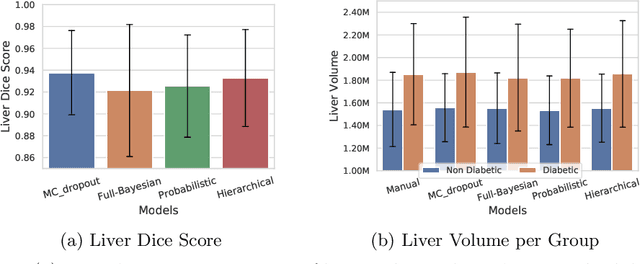
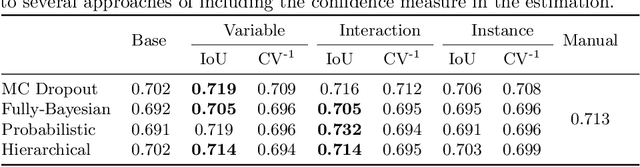
Image segmentation enables to extract quantitative measures from scans that can serve as imaging biomarkers for diseases. However, segmentation quality can vary substantially across scans, and therefore yield unfaithful estimates in the follow-up statistical analysis of biomarkers. The core problem is that segmentation and biomarker analysis are performed independently. We propose to propagate segmentation uncertainty to the statistical analysis to account for variations in segmentation confidence. To this end, we evaluate four Bayesian neural networks to sample from the posterior distribution and estimate the uncertainty. We then assign confidence measures to the biomarker and propose statistical models for its integration in group analysis and disease classification. Our results for segmenting the liver in patients with diabetes mellitus clearly demonstrate the improvement of integrating biomarker uncertainty in the statistical inference.
Unsupervised Self-training Algorithm Based on Deep Learning for Optical Aerial Images Change Detection
Oct 15, 2020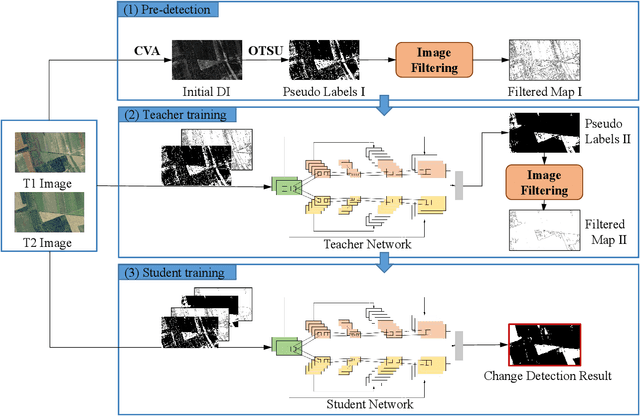
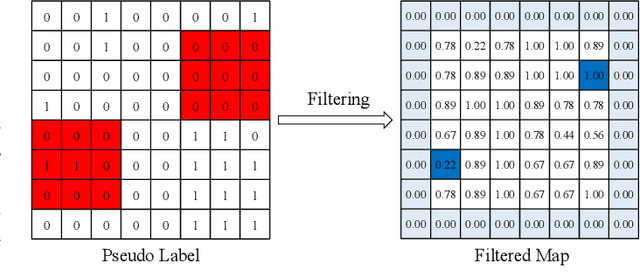
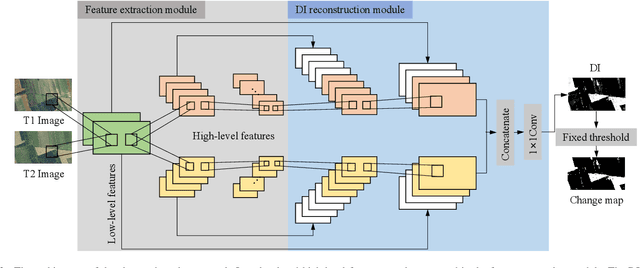

Optical aerial images change detection is an important task in earth observation and has been extensively investigated in the past few decades. Generally, the supervised change detection methods with superior performance require a large amount of labeled training data which is obtained by manual annotation with high cost. In this paper, we present a novel unsupervised self-training algorithm (USTA) for optical aerial images change detection. The traditional method such as change vector analysis is used to generate the pseudo labels. We use these pseudo labels to train a well designed convolutional neural network. The network is used as a teacher to classify the original multitemporal images to generate another set of pseudo labels. Then two set of pseudo labels are used to jointly train a student network with the same structure as the teacher. The final change detection result can be obtained by the trained student network. Besides, we design an image filter to control the usage of change information in the pseudo labels in the training process of the network. The whole process of the algorithm is an unsupervised process without manually marked labels. Experimental results on the real datasets demonstrate competitive performance of our proposed method.
Data-Driven Color Augmentation Techniques for Deep Skin Image Analysis
Mar 10, 2017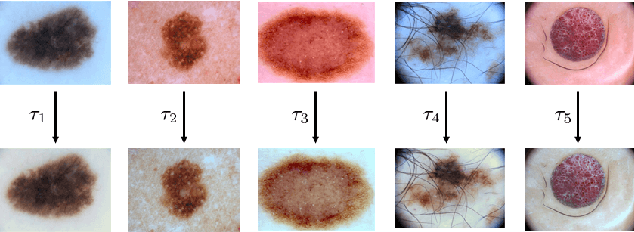
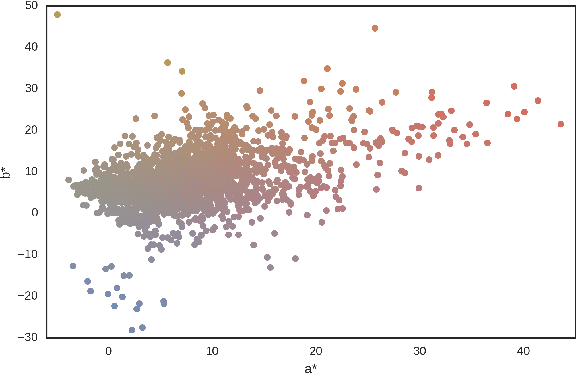

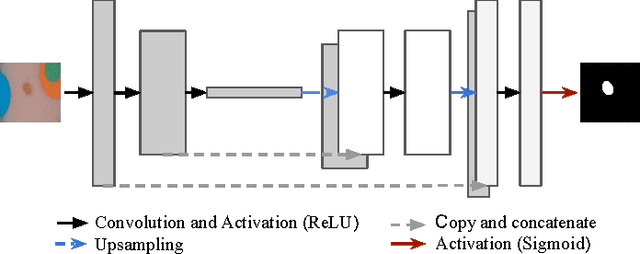
Dermoscopic skin images are often obtained with different imaging devices, under varying acquisition conditions. In this work, instead of attempting to perform intensity and color normalization, we propose to leverage computational color constancy techniques to build an artificial data augmentation technique suitable for this kind of images. Specifically, we apply the \emph{shades of gray} color constancy technique to color-normalize the entire training set of images, while retaining the estimated illuminants. We then draw one sample from the distribution of training set illuminants and apply it on the normalized image. We employ this technique for training two deep convolutional neural networks for the tasks of skin lesion segmentation and skin lesion classification, in the context of the ISIC 2017 challenge and without using any external dermatologic image set. Our results on the validation set are promising, and will be supplemented with extended results on the hidden test set when available.
Domain Stylization: A Strong, Simple Baseline for Synthetic to Real Image Domain Adaptation
Jul 24, 2018
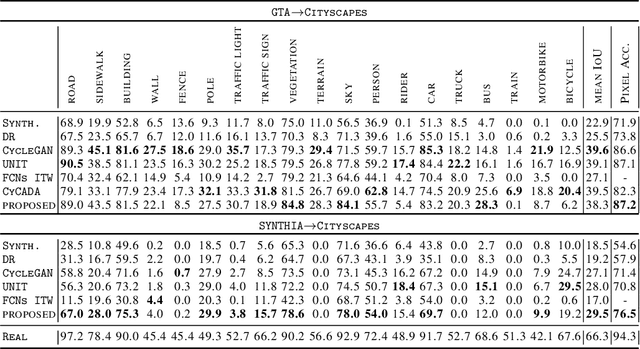

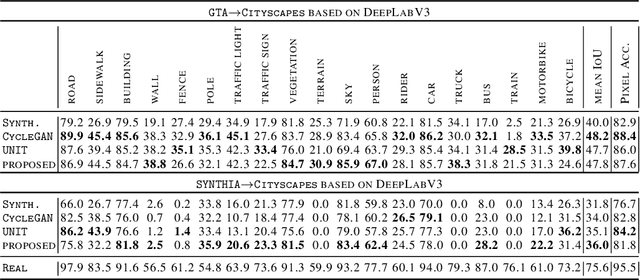
Deep neural networks have largely failed to effectively utilize synthetic data when applied to real images due to the covariate shift problem. In this paper, we show that by applying a straightforward modification to an existing photorealistic style transfer algorithm, we achieve state-of-the-art synthetic-to-real domain adaptation results. We conduct extensive experimental validations on four synthetic-to-real tasks for semantic segmentation and object detection, and show that our approach exceeds the performance of any current state-of-the-art GAN-based image translation approach as measured by segmentation and object detection metrics. Furthermore we offer a distance based analysis of our method which shows a dramatic reduction in Frechet Inception distance between the source and target domains, offering a quantitative metric that demonstrates the effectiveness of our algorithm in bridging the synthetic-to-real gap.
Improving the Reconstruction of Disentangled Representation Learners via Multi-Stage Modelling
Oct 25, 2020

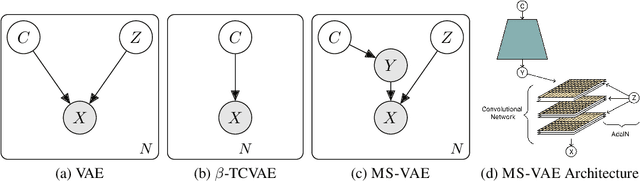

Current autoencoder-based disentangled representation learning methods achieve disentanglement by penalizing the (aggregate) posterior to encourage statistical independence of the latent factors. This approach introduces a trade-off between disentangled representation learning and reconstruction quality since the model does not have enough capacity to learn correlated latent variables that capture detail information present in most image data. To overcome this trade-off, we present a novel multi-stage modelling approach where the disentangled factors are first learned using a preexisting disentangled representation learning method (such as $\beta$-TCVAE); then, the low-quality reconstruction is improved with another deep generative model that is trained to model the missing correlated latent variables, adding detail information while maintaining conditioning on the previously learned disentangled factors. Taken together, our multi-stage modelling approach results in a single, coherent probabilistic model that is theoretically justified by the principal of D-separation and can be realized with a variety of model classes including likelihood-based models such as variational autoencoders, implicit models such as generative adversarial networks, and tractable models like normalizing flows or mixtures of Gaussians. We demonstrate that our multi-stage model has much higher reconstruction quality than current state-of-the-art methods with equivalent disentanglement performance across multiple standard benchmarks.
AvatarMe: Realistically Renderable 3D Facial Reconstruction "in-the-wild"
Mar 30, 2020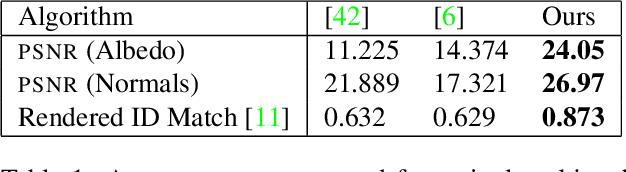


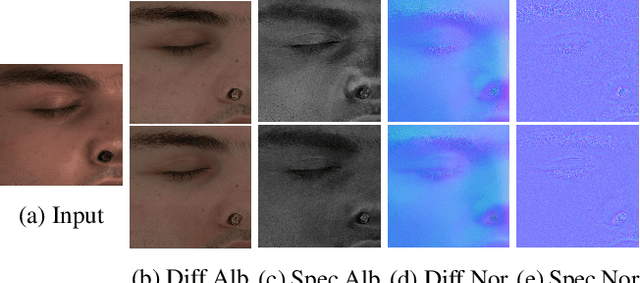
Over the last years, with the advent of Generative Adversarial Networks (GANs), many face analysis tasks have accomplished astounding performance, with applications including, but not limited to, face generation and 3D face reconstruction from a single "in-the-wild" image. Nevertheless, to the best of our knowledge, there is no method which can produce high-resolution photorealistic 3D faces from "in-the-wild" images and this can be attributed to the: (a) scarcity of available data for training, and (b) lack of robust methodologies that can successfully be applied on very high-resolution data. In this paper, we introduce AvatarMe, the first method that is able to reconstruct photorealistic 3D faces from a single "in-the-wild" image with an increasing level of detail. To achieve this, we capture a large dataset of facial shape and reflectance and build on a state-of-the-art 3D texture and shape reconstruction method and successively refine its results, while generating the per-pixel diffuse and specular components that are required for realistic rendering. As we demonstrate in a series of qualitative and quantitative experiments, AvatarMe outperforms the existing arts by a significant margin and reconstructs authentic, 4K by 6K-resolution 3D faces from a single low-resolution image that, for the first time, bridges the uncanny valley.
Are all negatives created equal in contrastive instance discrimination?
Oct 25, 2020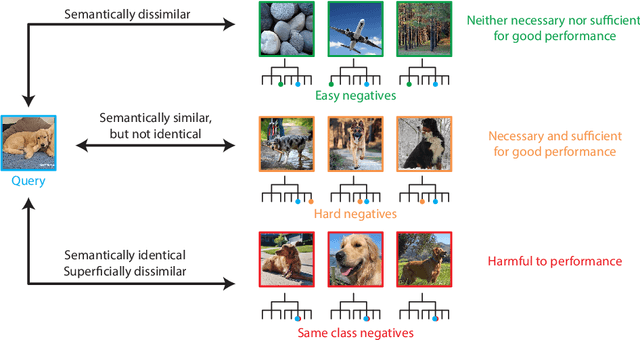
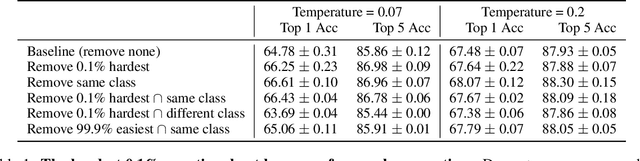
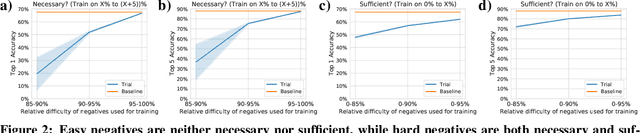
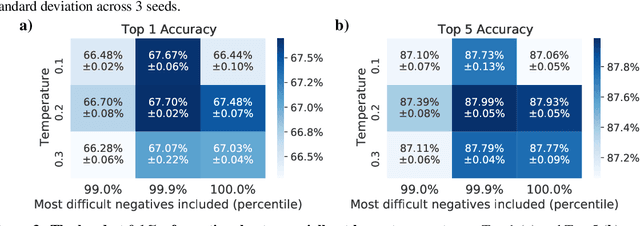
Self-supervised learning has recently begun to rival supervised learning on computer vision tasks. Many of the recent approaches have been based on contrastive instance discrimination (CID), in which the network is trained to recognize two augmented versions of the same instance (a query and positive) while discriminating against a pool of other instances (negatives). The learned representation is then used on downstream tasks such as image classification. Using methodology from MoCo v2 (Chen et al., 2020), we divided negatives by their difficulty for a given query and studied which difficulty ranges were most important for learning useful representations. We found a minority of negatives -- the hardest 5% -- were both necessary and sufficient for the downstream task to reach nearly full accuracy. Conversely, the easiest 95% of negatives were unnecessary and insufficient. Moreover, the very hardest 0.1% of negatives were unnecessary and sometimes detrimental. Finally, we studied the properties of negatives that affect their hardness, and found that hard negatives were more semantically similar to the query, and that some negatives were more consistently easy or hard than we would expect by chance. Together, our results indicate that negatives vary in importance and that CID may benefit from more intelligent negative treatment.
Multi-Modal Open-Domain Dialogue
Oct 02, 2020
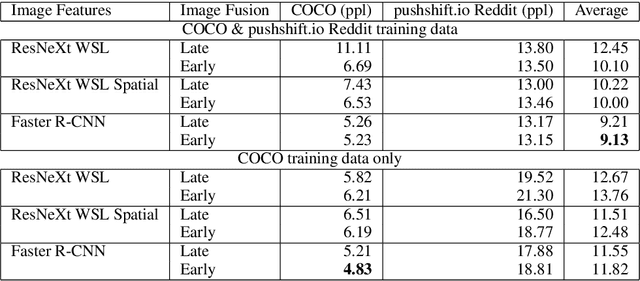
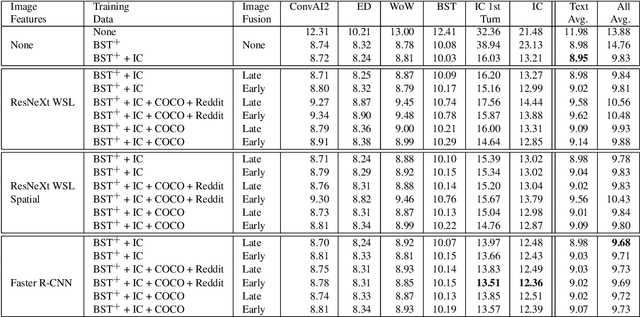

Recent work in open-domain conversational agents has demonstrated that significant improvements in model engagingness and humanness metrics can be achieved via massive scaling in both pre-training data and model size (Adiwardana et al., 2020; Roller et al., 2020). However, if we want to build agents with human-like abilities, we must expand beyond handling just text. A particularly important topic is the ability to see images and communicate about what is perceived. With the goal of engaging humans in multi-modal dialogue, we investigate combining components from state-of-the-art open-domain dialogue agents with those from state-of-the-art vision models. We study incorporating different image fusion schemes and domain-adaptive pre-training and fine-tuning strategies, and show that our best resulting model outperforms strong existing models in multi-modal dialogue while simultaneously performing as well as its predecessor (text-only) BlenderBot (Roller et al., 2020) in text-based conversation. We additionally investigate and incorporate safety components in our final model, and show that such efforts do not diminish model performance with respect to engagingness metrics.
Learning Propagation Rules for Attribution Map Generation
Oct 14, 2020
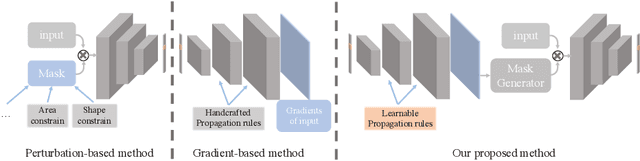
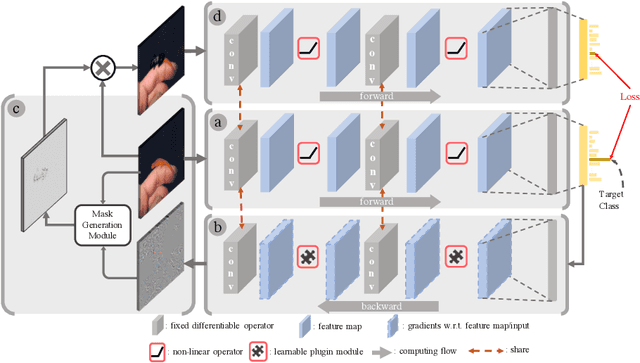
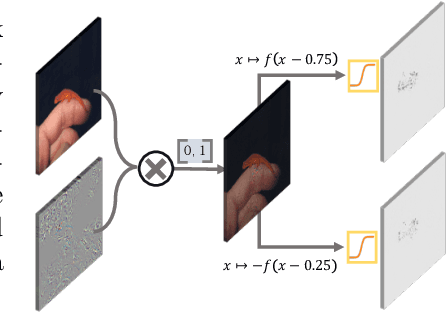
Prior gradient-based attribution-map methods rely on handcrafted propagation rules for the non-linear/activation layers during the backward pass, so as to produce gradients of the input and then the attribution map. Despite the promising results achieved, such methods are sensitive to the non-informative high-frequency components and lack adaptability for various models and samples. In this paper, we propose a dedicated method to generate attribution maps that allow us to learn the propagation rules automatically, overcoming the flaws of the handcrafted ones. Specifically, we introduce a learnable plugin module, which enables adaptive propagation rules for each pixel, to the non-linear layers during the backward pass for mask generating. The masked input image is then fed into the model again to obtain new output that can be used as a guidance when combined with the original one. The introduced learnable module can be trained under any auto-grad framework with higher-order differential support. As demonstrated on five datasets and six network architectures, the proposed method yields state-of-the-art results and gives cleaner and more visually plausible attribution maps.