 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Enhanced Color Palette Modeling for Lossless Screen Content Compression
Jan 09, 2024
Soft context formation is a lossless image coding method for screen content. It encodes images pixel by pixel via arithmetic coding by collecting statistics for probability distribution estimation. Its main pipeline includes three stages, namely a context model based stage, a color palette stage and a residual coding stage. Each subsequent stage is only employed if the previous stage can not be applied since necessary statistics, e.g. colors or contexts, have not been learned yet. We propose the following enhancements: First, information from previous stages is used to remove redundant color palette entries and prediction errors in subsequent stages. Additionally, implicitly known stage decision signals are no longer explicitly transmitted. These enhancements lead to an average bit rate decrease of 1.07% on the evaluated data. Compared to VVC and HEVC, the proposed method needs roughly 0.44 and 0.17 bits per pixel less on average for 24-bit screen content images, respectively.
PI3D: Efficient Text-to-3D Generation with Pseudo-Image Diffusion
Dec 14, 2023In this paper, we introduce PI3D, a novel and efficient framework that utilizes the pre-trained text-to-image diffusion models to generate high-quality 3D shapes in minutes. On the one hand, it fine-tunes a pre-trained 2D diffusion model into a 3D diffusion model, enabling both 3D generative capabilities and generalization derived from the 2D model. On the other, it utilizes score distillation sampling of 2D diffusion models to quickly improve the quality of the sampled 3D shapes. PI3D enables the migration of knowledge from image to triplane generation by treating it as a set of pseudo-images. We adapt the modules in the pre-training model to enable hybrid training using pseudo and real images, which has proved to be a well-established strategy for improving generalizability. The efficiency of PI3D is highlighted by its ability to sample diverse 3D models in seconds and refine them in minutes. The experimental results confirm the advantages of PI3D over existing methods based on either 3D diffusion models or lifting 2D diffusion models in terms of fast generation of 3D consistent and high-quality models. The proposed PI3D stands as a promising advancement in the field of text-to-3D generation, and we hope it will inspire more research into 3D generation leveraging the knowledge in both 2D and 3D data.
Improved Zero-Shot Classification by Adapting VLMs with Text Descriptions
Jan 04, 2024The zero-shot performance of existing vision-language models (VLMs) such as CLIP is limited by the availability of large-scale, aligned image and text datasets in specific domains. In this work, we leverage two complementary sources of information -- descriptions of categories generated by large language models (LLMs) and abundant, fine-grained image classification datasets -- to improve the zero-shot classification performance of VLMs across fine-grained domains. On the technical side, we develop methods to train VLMs with this "bag-level" image-text supervision. We find that simply using these attributes at test-time does not improve performance, but our training strategy, for example, on the iNaturalist dataset, leads to an average improvement of 4-5% in zero-shot classification accuracy for novel categories of birds and flowers. Similar improvements are observed in domains where a subset of the categories was used to fine-tune the model. By prompting LLMs in various ways, we generate descriptions that capture visual appearance, habitat, and geographic regions and pair them with existing attributes such as the taxonomic structure of the categories. We systematically evaluate their ability to improve zero-shot categorization in natural domains. Our findings suggest that geographic priors can be just as effective and are complementary to visual appearance. Our method also outperforms prior work on prompt-based tuning of VLMs. We plan to release the benchmark, consisting of 7 datasets, which will contribute to future research in zero-shot recognition.
Fus-MAE: A cross-attention-based data fusion approach for Masked Autoencoders in remote sensing
Jan 05, 2024Self-supervised frameworks for representation learning have recently stirred up interest among the remote sensing community, given their potential to mitigate the high labeling costs associated with curating large satellite image datasets. In the realm of multimodal data fusion, while the often used contrastive learning methods can help bridging the domain gap between different sensor types, they rely on data augmentations techniques that require expertise and careful design, especially for multispectral remote sensing data. A possible but rather scarcely studied way to circumvent these limitations is to use a masked image modelling based pretraining strategy. In this paper, we introduce Fus-MAE, a self-supervised learning framework based on masked autoencoders that uses cross-attention to perform early and feature-level data fusion between synthetic aperture radar and multispectral optical data - two modalities with a significant domain gap. Our empirical findings demonstrate that Fus-MAE can effectively compete with contrastive learning strategies tailored for SAR-optical data fusion and outperforms other masked-autoencoders frameworks trained on a larger corpus.
Progressive Knowledge Distillation Of Stable Diffusion XL Using Layer Level Loss
Jan 05, 2024Stable Diffusion XL (SDXL) has become the best open source text-to-image model (T2I) for its versatility and top-notch image quality. Efficiently addressing the computational demands of SDXL models is crucial for wider reach and applicability. In this work, we introduce two scaled-down variants, Segmind Stable Diffusion (SSD-1B) and Segmind-Vega, with 1.3B and 0.74B parameter UNets, respectively, achieved through progressive removal using layer-level losses focusing on reducing the model size while preserving generative quality. We release these models weights at https://hf.co/Segmind. Our methodology involves the elimination of residual networks and transformer blocks from the U-Net structure of SDXL, resulting in significant reductions in parameters, and latency. Our compact models effectively emulate the original SDXL by capitalizing on transferred knowledge, achieving competitive results against larger multi-billion parameter SDXL. Our work underscores the efficacy of knowledge distillation coupled with layer-level losses in reducing model size while preserving the high-quality generative capabilities of SDXL, thus facilitating more accessible deployment in resource-constrained environments.
Fine-Tuning InstructPix2Pix for Advanced Image Colorization
Dec 08, 2023
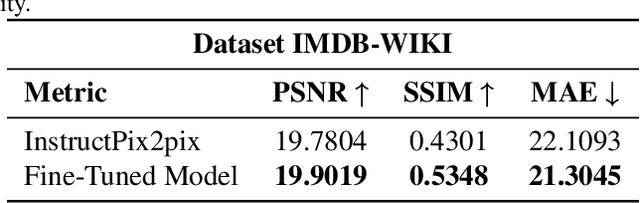
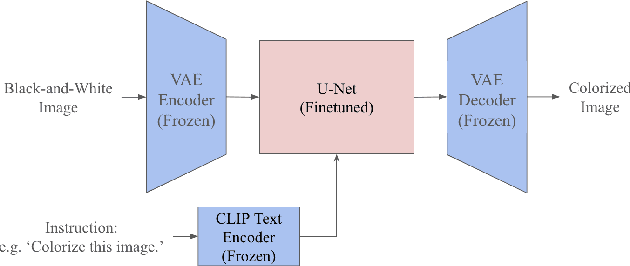

This paper presents a novel approach to human image colorization by fine-tuning the InstructPix2Pix model, which integrates a language model (GPT-3) with a text-to-image model (Stable Diffusion). Despite the original InstructPix2Pix model's proficiency in editing images based on textual instructions, it exhibits limitations in the focused domain of colorization. To address this, we fine-tuned the model using the IMDB-WIKI dataset, pairing black-and-white images with a diverse set of colorization prompts generated by ChatGPT. This paper contributes by (1) applying fine-tuning techniques to stable diffusion models specifically for colorization tasks, and (2) employing generative models to create varied conditioning prompts. After finetuning, our model outperforms the original InstructPix2Pix model on multiple metrics quantitatively, and we produce more realistically colored images qualitatively. The code for this project is provided on the GitHub Repository https://github.com/AllenAnZifeng/DeepLearning282.
AnimateZero: Video Diffusion Models are Zero-Shot Image Animators
Dec 06, 2023Large-scale text-to-video (T2V) diffusion models have great progress in recent years in terms of visual quality, motion and temporal consistency. However, the generation process is still a black box, where all attributes (e.g., appearance, motion) are learned and generated jointly without precise control ability other than rough text descriptions. Inspired by image animation which decouples the video as one specific appearance with the corresponding motion, we propose AnimateZero to unveil the pre-trained text-to-video diffusion model, i.e., AnimateDiff, and provide more precise appearance and motion control abilities for it. For appearance control, we borrow intermediate latents and their features from the text-to-image (T2I) generation for ensuring the generated first frame is equal to the given generated image. For temporal control, we replace the global temporal attention of the original T2V model with our proposed positional-corrected window attention to ensure other frames align with the first frame well. Empowered by the proposed methods, AnimateZero can successfully control the generating progress without further training. As a zero-shot image animator for given images, AnimateZero also enables multiple new applications, including interactive video generation and real image animation. The detailed experiments demonstrate the effectiveness of the proposed method in both T2V and related applications.
A Study on Self-Supervised Pretraining for Vision Problems in Gastrointestinal Endoscopy
Jan 11, 2024Solutions to vision tasks in gastrointestinal endoscopy (GIE) conventionally use image encoders pretrained in a supervised manner with ImageNet-1k as backbones. However, the use of modern self-supervised pretraining algorithms and a recent dataset of 100k unlabelled GIE images (Hyperkvasir-unlabelled) may allow for improvements. In this work, we study the fine-tuned performance of models with ResNet50 and ViT-B backbones pretrained in self-supervised and supervised manners with ImageNet-1k and Hyperkvasir-unlabelled (self-supervised only) in a range of GIE vision tasks. In addition to identifying the most suitable pretraining pipeline and backbone architecture for each task, out of those considered, our results suggest: that self-supervised pretraining generally produces more suitable backbones for GIE vision tasks than supervised pretraining; that self-supervised pretraining with ImageNet-1k is typically more suitable than pretraining with Hyperkvasir-unlabelled, with the notable exception of monocular depth estimation in colonoscopy; and that ViT-Bs are more suitable in polyp segmentation and monocular depth estimation in colonoscopy, ResNet50s are more suitable in polyp detection, and both architectures perform similarly in anatomical landmark recognition and pathological finding characterisation. We hope this work draws attention to the complexity of pretraining for GIE vision tasks, informs this development of more suitable approaches than the convention, and inspires further research on this topic to help advance this development. Code available: \underline{github.com/ESandML/SSL4GIE}
Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
Jan 11, 2024Is vision good enough for language? Recent advancements in multimodal models primarily stem from the powerful reasoning abilities of large language models (LLMs). However, the visual component typically depends only on the instance-level contrastive language-image pre-training (CLIP). Our research reveals that the visual capabilities in recent multimodal LLMs (MLLMs) still exhibit systematic shortcomings. To understand the roots of these errors, we explore the gap between the visual embedding space of CLIP and vision-only self-supervised learning. We identify ''CLIP-blind pairs'' - images that CLIP perceives as similar despite their clear visual differences. With these pairs, we construct the Multimodal Visual Patterns (MMVP) benchmark. MMVP exposes areas where state-of-the-art systems, including GPT-4V, struggle with straightforward questions across nine basic visual patterns, often providing incorrect answers and hallucinated explanations. We further evaluate various CLIP-based vision-and-language models and found a notable correlation between visual patterns that challenge CLIP models and those problematic for multimodal LLMs. As an initial effort to address these issues, we propose a Mixture of Features (MoF) approach, demonstrating that integrating vision self-supervised learning features with MLLMs can significantly enhance their visual grounding capabilities. Together, our research suggests visual representation learning remains an open challenge, and accurate visual grounding is crucial for future successful multimodal systems.
Surgical-DINO: Adapter Learning of Foundation Models for Depth Estimation in Endoscopic Surgery
Jan 12, 2024Purpose: Depth estimation in robotic surgery is vital in 3D reconstruction, surgical navigation and augmented reality visualization. Although the foundation model exhibits outstanding performance in many vision tasks, including depth estimation (e.g., DINOv2), recent works observed its limitations in medical and surgical domain-specific applications. This work presents a low-ranked adaptation (LoRA) of the foundation model for surgical depth estimation. Methods: We design a foundation model-based depth estimation method, referred to as Surgical-DINO, a low-rank adaptation of the DINOv2 for depth estimation in endoscopic surgery. We build LoRA layers and integrate them into DINO to adapt with surgery-specific domain knowledge instead of conventional fine-tuning. During training, we freeze the DINO image encoder, which shows excellent visual representation capacity, and only optimize the LoRA layers and depth decoder to integrate features from the surgical scene. Results: Our model is extensively validated on a MICCAI challenge dataset of SCARED, which is collected from da Vinci Xi endoscope surgery. We empirically show that Surgical-DINO significantly outperforms all the state-of-the-art models in endoscopic depth estimation tasks. The analysis with ablation studies has shown evidence of the remarkable effect of our LoRA layers and adaptation. Conclusion: Surgical-DINO shed some light on the successful adaptation of the foundation models into the surgical domain for depth estimation. There is clear evidence in the results that zero-shot prediction on pre-trained weights in computer vision datasets or naive fine-tuning is not sufficient to use the foundation model in the surgical domain directly. Code is available at https://github.com/BeileiCui/SurgicalDINO.