 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Ranky : An Approach to Solve Distributed SVD on Large Sparse Matrices
Sep 21, 2020
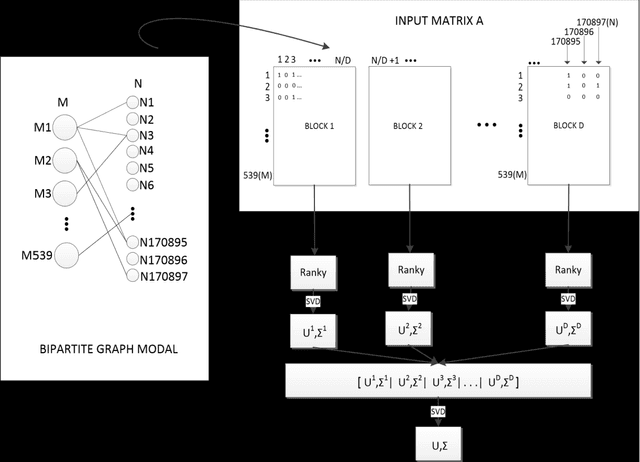
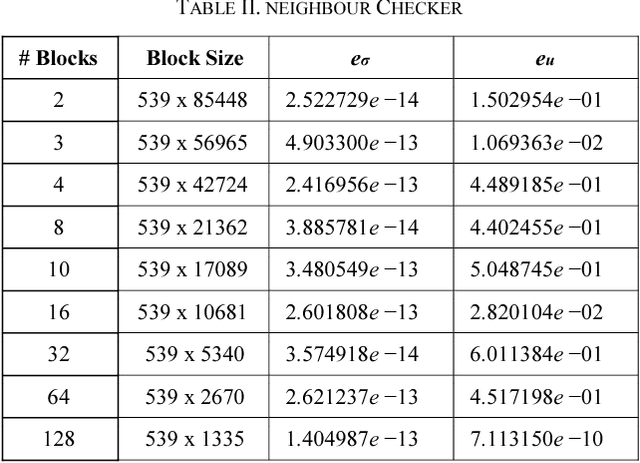
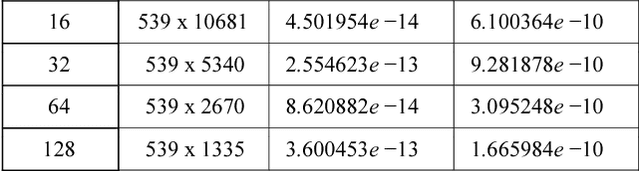
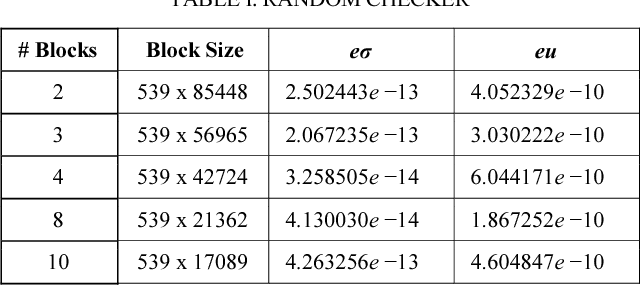
Singular Value Decomposition (SVD) is a well studied research topic in many fields and applications from data mining to image processing. Data arising from these applications can be represented as a matrix where it is large and sparse. Most existing algorithms are used to calculate singular values, left and right singular vectors of a large-dense matrix but not large and sparse matrix. Even if they can find SVD of a large matrix, calculation of large-dense matrix has high time complexity due to sequential algorithms. Distributed approaches are proposed for computing SVD of large matrices. However, rank of the matrix is still being a problem when solving SVD with these distributed algorithms. In this paper we propose Ranky, set of methods to solve rank problem on large and sparse matrices in a distributed manner. Experimental results show that the Ranky approach recovers singular values, singular left and right vectors of a given large and sparse matrix with negligible error.
Overcoming Statistical Shortcuts for Open-ended Visual Counting
Jul 01, 2020



Machine learning models tend to over-rely on statistical shortcuts. These spurious correlations between parts of the input and the output labels does not hold in real-world settings. We target this issue on the recent open-ended visual counting task which is well suited to study statistical shortcuts. We aim to develop models that learn a proper mechanism of counting regardless of the output label. First, we propose the Modifying Count Distribution (MCD) protocol, which penalizes models that over-rely on statistical shortcuts. It is based on pairs of training and testing sets that do not follow the same count label distribution such as the odd-even sets. Intuitively, models that have learned a proper mechanism of counting on odd numbers should perform well on even numbers. Secondly, we introduce the Spatial Counting Network (SCN), which is dedicated to visual analysis and counting based on natural language questions. Our model selects relevant image regions, scores them with fusion and self-attention mechanisms, and provides a final counting score. We apply our protocol on the recent dataset, TallyQA, and show superior performances compared to state-of-the-art models. We also demonstrate the ability of our model to select the correct instances to count in the image. Code and datasets are available: https://github.com/cdancette/spatial-counting-network
Coronavirus: Comparing COVID-19, SARS and MERS in the eyes of AI
May 23, 2020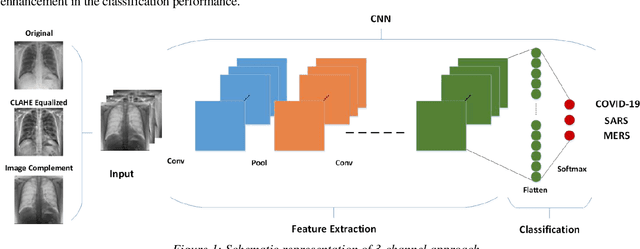

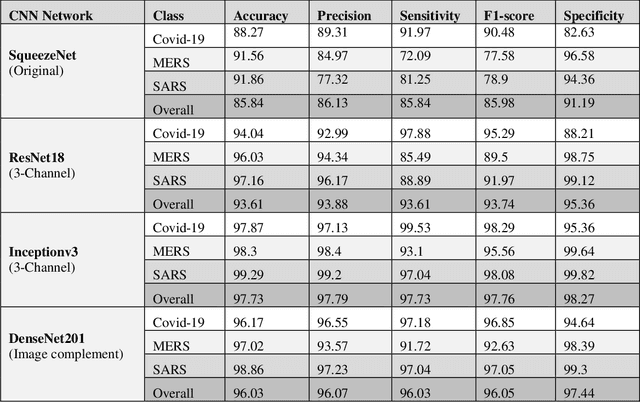
Novel Coronavirus disease (COVID-19) is an extremely contagious and quickly spreading Coronavirus disease. Severe Acute Respiratory Syndrome (SARS)-CoV, Middle East Respiratory Syndrome (MERS)-CoV outbreak in 2002 and 2011 and current COVID-19 pandemic all from the same family of Coronavirus. The fatality rate due to SARS and MERS were higher than COVID-19 however, the spread of those were limited to few countries while COVID-19 affected more than two-hundred countries of the world. In this work, authors used deep machine learning algorithms along with innovative image pre-processing techniques to distinguish COVID-19 images from SARS and MERS images. Several deep learning algorithms were trained, and tested and four outperforming algorithms were reported: SqueezeNet, ResNet18, Inceptionv3 and DenseNet201. Original, Contrast limited adaptive histogram equalized and complemented image were used individually and in concatenation as the inputs to the networks. It was observed that inceptionv3 outperforms all networks for 3-channel concatenation technique and provide an excellent sensitivity of 99.5%, 93.1% and 97% for classifying COVID-19, MERS and SARS images respectively. Investigating deep layer activation mapping of the correctly classified images and miss-classified images, it was observed that some overlapping features between COVID-19 and MERS images were identified by the deep layer network. Interestingly these features were present in MERS images and 10 out of 144 images were miss-classified as COVID while only one out of 423 COVID-19 images was miss-classified as MERS. None of the MERS images was miss-classified to SARS and only one COVID-19 image was miss-classified as SARS. Therefore, it can be summarized that SARS images are significantly different from MERS and COVID-19 in the eyes of AI while there are some overlapping feature available between MERS and COVID-19.
DeepDyve: Dynamic Verification for Deep Neural Networks
Sep 21, 2020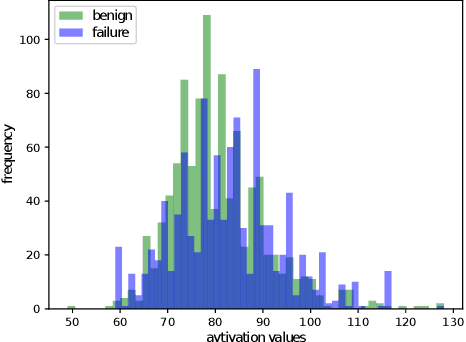

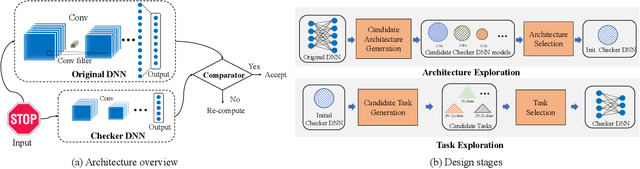
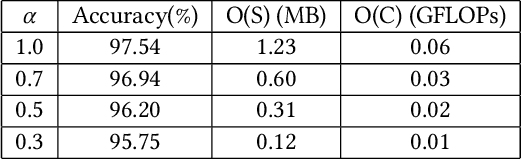
Deep neural networks (DNNs) have become one of the enabling technologies in many safety-critical applications, e.g., autonomous driving and medical image analysis. DNN systems, however, suffer from various kinds of threats, such as adversarial example attacks and fault injection attacks. While there are many defense methods proposed against maliciously crafted inputs, solutions against faults presented in the DNN system itself (e.g., parameters and calculations) are far less explored. In this paper, we develop a novel lightweight fault-tolerant solution for DNN-based systems, namely DeepDyve, which employs pre-trained neural networks that are far simpler and smaller than the original DNN for dynamic verification. The key to enabling such lightweight checking is that the smaller neural network only needs to produce approximate results for the initial task without sacrificing fault coverage much. We develop efficient and effective architecture and task exploration techniques to achieve optimized risk/overhead trade-off in DeepDyve. Experimental results show that DeepDyve can reduce 90% of the risks at around 10% overhead.
Indoor Positioning System based on Visible Light Communication for Mobile Robot in Nuclear Power Plant
Nov 16, 2020
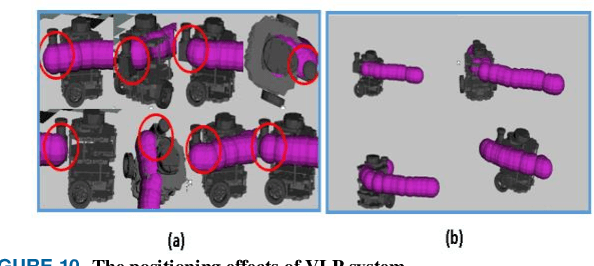
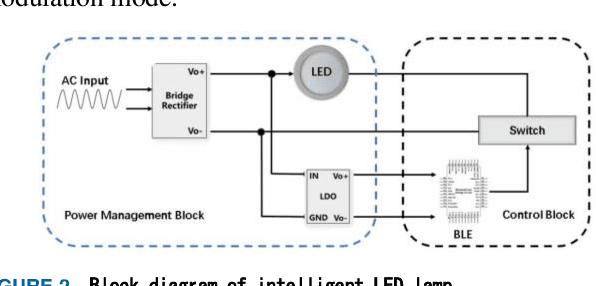
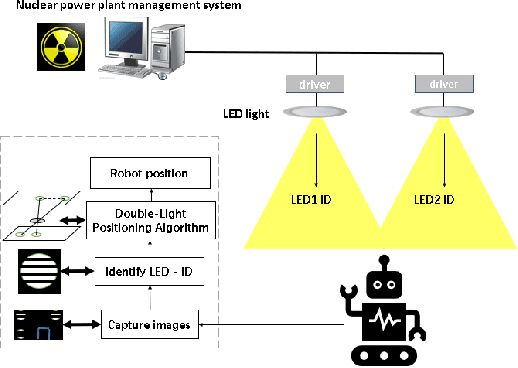
Visible light positioning (VLP) is widely believed to be a cost-effective answer to the growing demanded for robot indoor positioning. Considering that some extreme environments require robot to be equipped with a precise and radiation-resistance indoor positioning system for doing difficult work, a novel VLP system with high accuracy is proposed to realize the long-playing inspection and intervention under radiation environment. The proposed system with sufficient radiation-tolerance is critical for operational inspection, maintenance and intervention tasks in nuclear facilities. Firstly, we designed intelligent LED lamp with visible light communication (VLC) function to dynamically create the indoor GPS tracking system. By installing the proposed lamps that replace standard lighting in key locations in the nuclear power plant, the proposed system can strengthen the safety of mobile robot and help for efficient inspection in the large-scale field. Secondly, in order to enhance the radiation-tolerance and multi-scenario of the proposed system, we proposed a shielding protection method for the camera vertically installed on the robot, which ensures that the image elements of the camera namely the captured VLP information is not affected by radiation. Besides, with the optimized visible light positioning algorithm based on dispersion calibration method, the proposed VLP system can achieve an average positioning accuracy of 0.82cm and ensure that 90% positioning errors are less than 1.417cm. Therefore, the proposed system not only has sufficient radiation-tolerance but achieve state-of-the-art positioning accuracy in the visible light positioning field.
Why Are Convolutional Nets More Sample-Efficient than Fully-Connected Nets?
Oct 16, 2020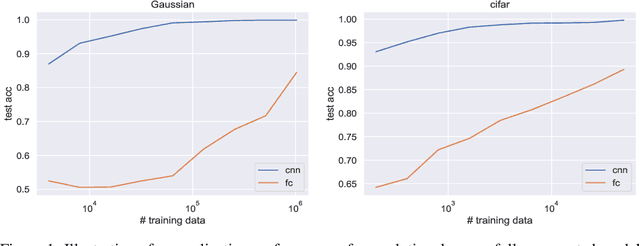

Convolutional neural networks often dominate fully-connected counterparts in generalization performance, especially on image classification tasks. This is often explained in terms of 'better inductive bias'. However, this has not been made mathematically rigorous, and the hurdle is that the fully connected net can always simulate the convolutional net (for a fixed task). Thus the training algorithm plays a role. The current work describes a natural task on which a provable sample complexity gap can be shown, for standard training algorithms. We construct a single natural distribution on $\mathbb{R}^d\times\{\pm 1\}$ on which any orthogonal-invariant algorithm (i.e. fully-connected networks trained with most gradient-based methods from gaussian initialization) requires $\Omega(d^2)$ samples to generalize while $O(1)$ samples suffice for convolutional architectures. Furthermore, we demonstrate a single target function, learning which on all possible distributions leads to an $O(1)$ vs $\Omega(d^2/\varepsilon)$ gap. The proof relies on the fact that SGD on fully-connected network is orthogonal equivariant. Similar results are achieved for $\ell_2$ regression and adaptive training algorithms, e.g. Adam and AdaGrad, which are only permutation equivariant.
SSGP: Sparse Spatial Guided Propagation for Robust and Generic Interpolation
Aug 21, 2020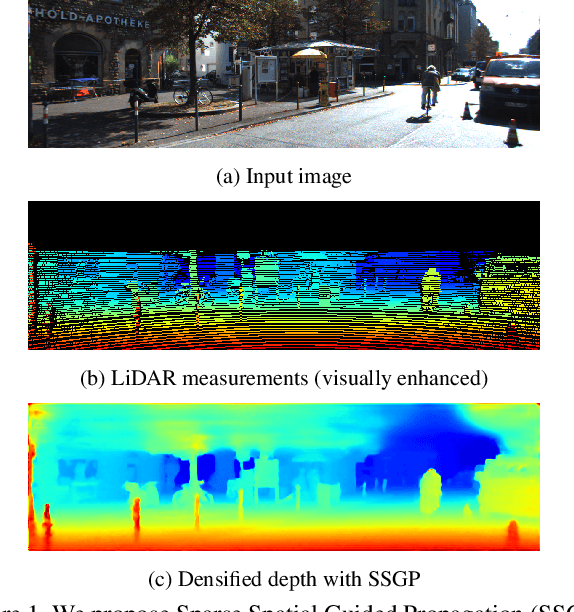
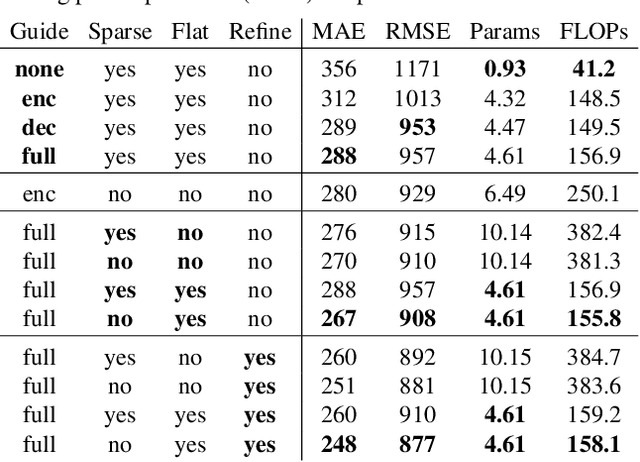
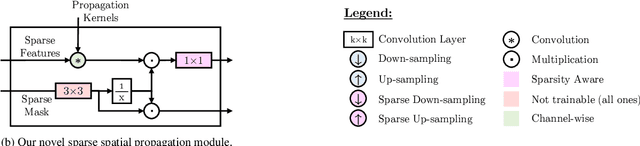
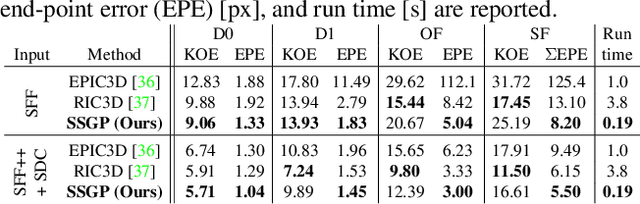
Interpolation of sparse pixel information towards a dense target resolution finds its application across multiple disciplines in computer vision. State-of-the-art interpolation of motion fields applies model-based interpolation that makes use of edge information extracted from the target image. For depth completion, data-driven learning approaches are widespread. Our work is inspired by latest trends in depth completion that tackle the problem of dense guidance for sparse information. We extend these ideas and create a generic cross-domain architecture that can be applied for a multitude of interpolation problems like optical flow, scene flow, or depth completion. In our experiments, we show that our proposed concept of Sparse Spatial Guided Propagation (SSGP) achieves improvements to robustness, accuracy, or speed compared to specialized algorithms.
Robust Semantic Segmentation in Adverse Weather Conditions by means of Fast Video-Sequence Segmentation
Jul 01, 2020
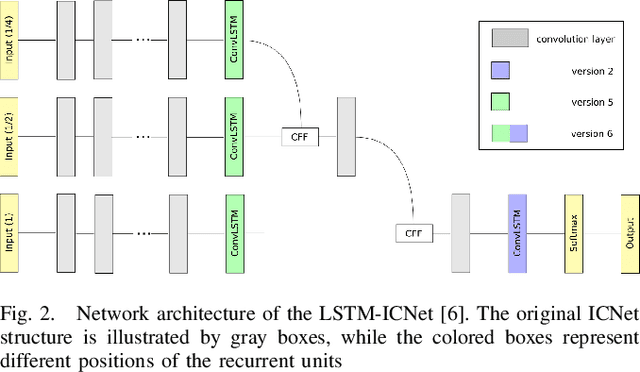
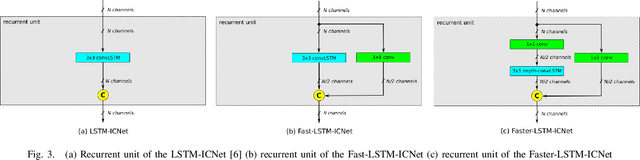
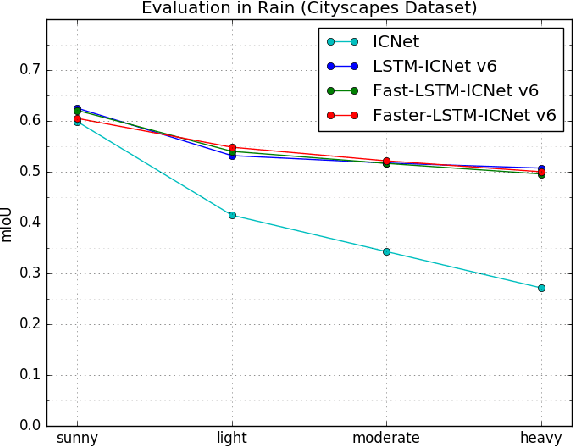
Computer vision tasks such as semantic segmentation perform very well in good weather conditions, but if the weather turns bad, they have problems to achieve this performance in these conditions. One possibility to obtain more robust and reliable results in adverse weather conditions is to use video-segmentation approaches instead of commonly used single-image segmentation methods. Video-segmentation approaches capture temporal information of the previous video-frames in addition to current image information, and hence, they are more robust against disturbances, especially if they occur in only a few frames of the video-sequence. However, video-segmentation approaches, which are often based on recurrent neural networks, cannot be applied in real-time applications anymore, since their recurrent structures in the network are computational expensive. For instance, the inference time of the LSTM-ICNet, in which recurrent units are placed at proper positions in the single-segmentation approach ICNet, increases up to 61 percent compared to the basic ICNet. Hence, in this work, the LSTM-ICNet is sped up by modifying the recurrent units of the network so that it becomes real-time capable again. Experiments on different datasets and various weather conditions show that the inference time can be decreased by about 23 percent by these modifications, while they achieve similar performance than the LSTM-ICNet and outperform the single-segmentation approach enormously in adverse weather conditions.
AvatarMe: Realistically Renderable 3D Facial Reconstruction "in-the-wild"
Mar 30, 2020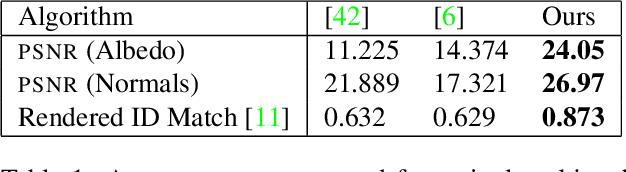


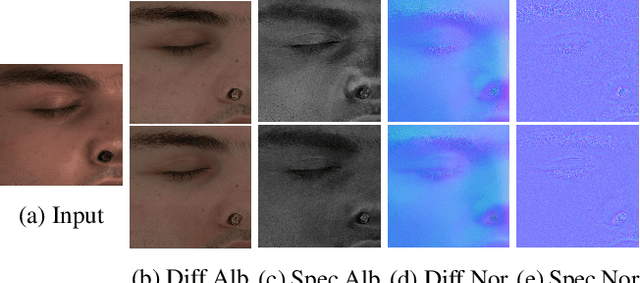
Over the last years, with the advent of Generative Adversarial Networks (GANs), many face analysis tasks have accomplished astounding performance, with applications including, but not limited to, face generation and 3D face reconstruction from a single "in-the-wild" image. Nevertheless, to the best of our knowledge, there is no method which can produce high-resolution photorealistic 3D faces from "in-the-wild" images and this can be attributed to the: (a) scarcity of available data for training, and (b) lack of robust methodologies that can successfully be applied on very high-resolution data. In this paper, we introduce AvatarMe, the first method that is able to reconstruct photorealistic 3D faces from a single "in-the-wild" image with an increasing level of detail. To achieve this, we capture a large dataset of facial shape and reflectance and build on a state-of-the-art 3D texture and shape reconstruction method and successively refine its results, while generating the per-pixel diffuse and specular components that are required for realistic rendering. As we demonstrate in a series of qualitative and quantitative experiments, AvatarMe outperforms the existing arts by a significant margin and reconstructs authentic, 4K by 6K-resolution 3D faces from a single low-resolution image that, for the first time, bridges the uncanny valley.
A Non-linear Function-on-Function Model for Regression with Time Series Data
Nov 24, 2020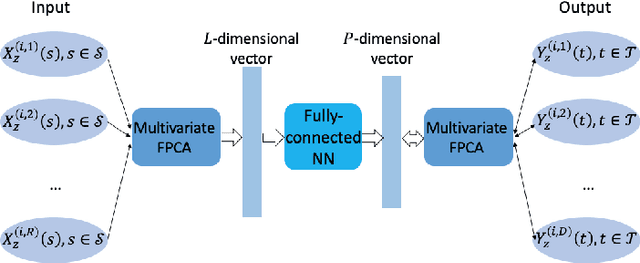
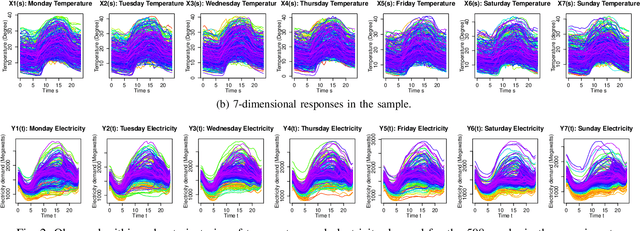
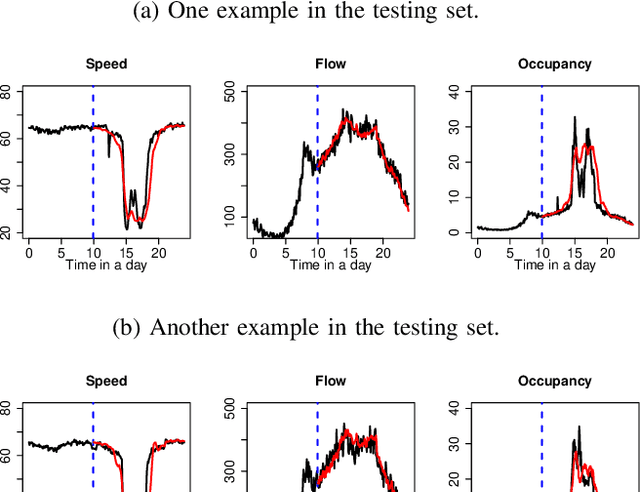

In the last few decades, building regression models for non-scalar variables, including time series, text, image, and video, has attracted increasing interests of researchers from the data analytic community. In this paper, we focus on a multivariate time series regression problem. Specifically, we aim to learn mathematical mappings from multiple chronologically measured numerical variables within a certain time interval S to multiple numerical variables of interest over time interval T. Prior arts, including the multivariate regression model, the Seq2Seq model, and the functional linear models, suffer from several limitations. The first two types of models can only handle regularly observed time series. Besides, the conventional multivariate regression models tend to be biased and inefficient, as they are incapable of encoding the temporal dependencies among observations from the same time series. The sequential learning models explicitly use the same set of parameters along time, which has negative impacts on accuracy. The function-on-function linear model in functional data analysis (a branch of statistics) is insufficient to capture complex correlations among the considered time series and suffer from underfitting easily. In this paper, we propose a general functional mapping that embraces the function-on-function linear model as a special case. We then propose a non-linear function-on-function model using the fully connected neural network to learn the mapping from data, which addresses the aforementioned concerns in the existing approaches. For the proposed model, we describe in detail the corresponding numerical implementation procedures. The effectiveness of the proposed model is demonstrated through the application to two real-world problems.