 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Monocular Depth Estimation via Listwise Ranking using the Plackett-Luce Model
Oct 28, 2020



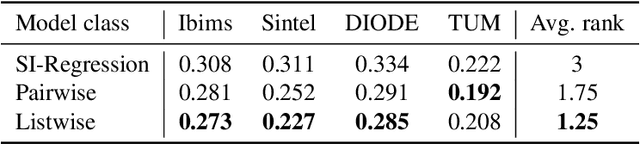
In many real-world applications, the relative depth of objects in an image is crucial for scene understanding, e.g., to calculate occlusions in augmented reality scenes. Predicting depth in monocular images has recently been tackled using machine learning methods, mainly by treating the problem as a regression task. Yet, being interested in an order relation in the first place, ranking methods suggest themselves as a natural alternative to regression, and indeed, ranking approaches leveraging pairwise comparisons as training information ("object A is closer to the camera than B") have shown promising performance on this problem. In this paper, we elaborate on the use of so-called listwise ranking as a generalization of the pairwise approach. Listwise ranking goes beyond pairwise comparisons between objects and considers rankings of arbitrary length as training information. Our approach is based on the Plackett-Luce model, a probability distribution on rankings, which we combine with a state-of-the-art neural network architecture and a sampling strategy to reduce training complexity. An empirical evaluation on benchmark data in a "zero-shot" setting demonstrates the effectiveness of our proposal compared to existing ranking and regression methods.
BigGAN-based Bayesian reconstruction of natural images from human brain activity
Mar 13, 2020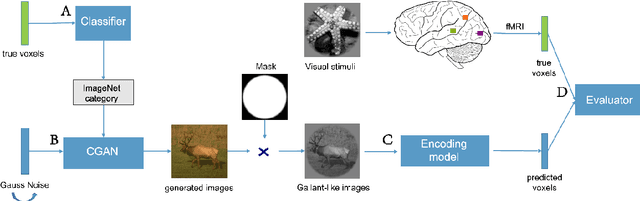
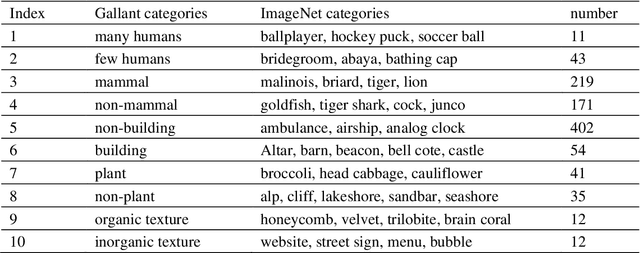


In the visual decoding domain, visually reconstructing presented images given the corresponding human brain activity monitored by functional magnetic resonance imaging (fMRI) is difficult, especially when reconstructing viewed natural images. Visual reconstruction is a conditional image generation on fMRI data and thus generative adversarial network (GAN) for natural image generation is recently introduced for this task. Although GAN-based methods have greatly improved, the fidelity and naturalness of reconstruction are still unsatisfactory due to the small number of fMRI data samples and the instability of GAN training. In this study, we proposed a new GAN-based Bayesian visual reconstruction method (GAN-BVRM) that includes a classifier to decode categories from fMRI data, a pre-trained conditional generator to generate natural images of specified categories, and a set of encoding models and evaluator to evaluate generated images. GAN-BVRM employs the pre-trained generator of the prevailing BigGAN to generate masses of natural images, and selects the images that best matches with the corresponding brain activity through the encoding models as the reconstruction of the image stimuli. In this process, the semantic and detailed contents of reconstruction are controlled by decoded categories and encoding models, respectively. GAN-BVRM used the Bayesian manner to avoid contradiction between naturalness and fidelity from current GAN-based methods and thus can improve the advantages of GAN. Experimental results revealed that GAN-BVRM improves the fidelity and naturalness, that is, the reconstruction is natural and similar to the presented image stimuli.
Teaching Cameras to Feel: Estimating Tactile Physical Properties of Surfaces From Images
May 07, 2020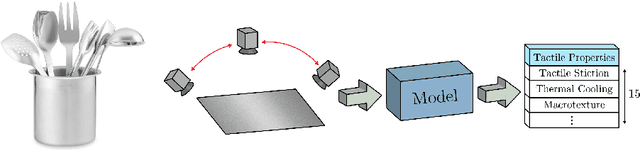


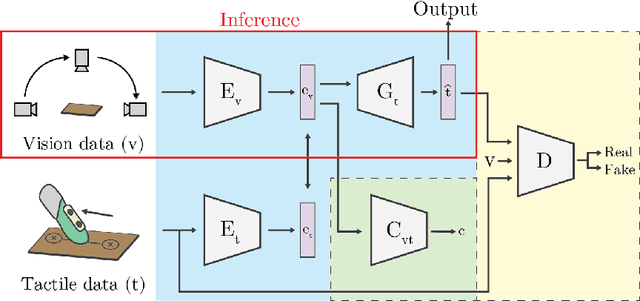
The connection between visual input and tactile sensing is critical for object manipulation tasks such as grasping and pushing. In this work, we introduce the challenging task of estimating a set of tactile physical properties from visual information. We aim to build a model that learns the complex mapping between visual information and tactile physical properties. We construct a first of its kind image-tactile dataset with over 400 multiview image sequences and the corresponding tactile properties. A total of fifteen tactile physical properties across categories including friction, compliance, adhesion, texture, and thermal conductance are measured and then estimated by our models. We develop a cross-modal framework comprised of an adversarial objective and a novel visuo-tactile joint classification loss. Additionally, we develop a neural architecture search framework capable of selecting optimal combinations of viewing angles for estimating a given physical property.
TCLNet: Learning to Locate Typhoon Center Using Deep Neural Network
Oct 03, 2020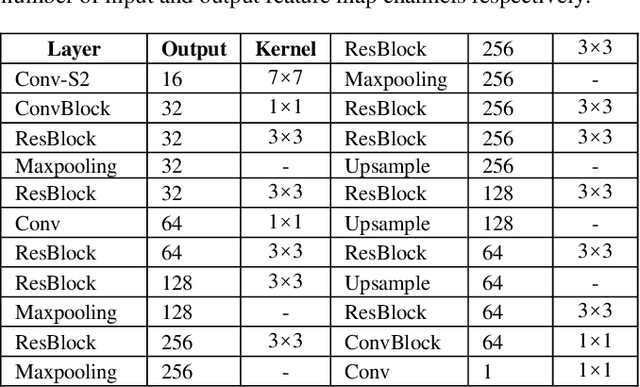
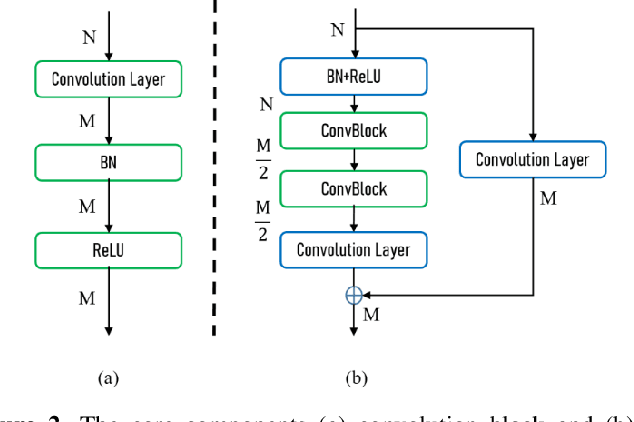
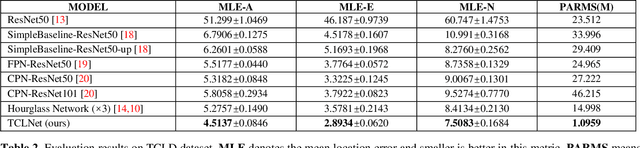
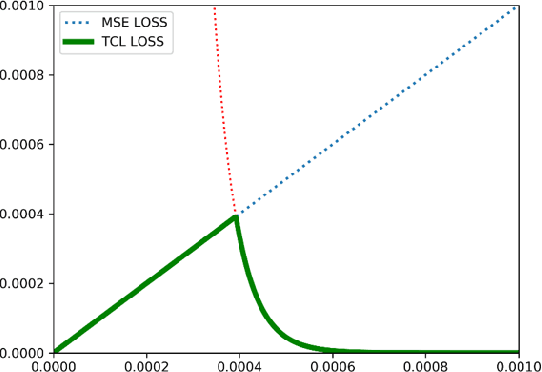
The task of typhoon center location plays an important role in typhoon intensity analysis and typhoon path prediction. Conventional typhoon center location algorithms mostly rely on digital image processing and mathematical morphology operation, which achieve limited performance. In this paper, we proposed an efficient fully convolutional end-to-end deep neural network named TCLNet to automatically locate the typhoon center position. We design the network structure carefully so that our TCLNet can achieve remarkable performance base on its lightweight architecture. In addition, we also present a brand new large-scale typhoon center location dataset (TCLD) so that the TCLNet can be trained in a supervised manner. Furthermore, we propose to use a novel TCL+ piecewise loss function to further improve the performance of TCLNet. Extensive experimental results and comparison demonstrate the performance of our model, and our TCLNet achieve a 14.4% increase in accuracy on the basis of a 92.7% reduction in parameters compared with SOTA deep learning based typhoon center location methods.
Human Perception-based Evaluation Criterion for Ultra-high Resolution Cell Membrane Segmentation
Oct 16, 2020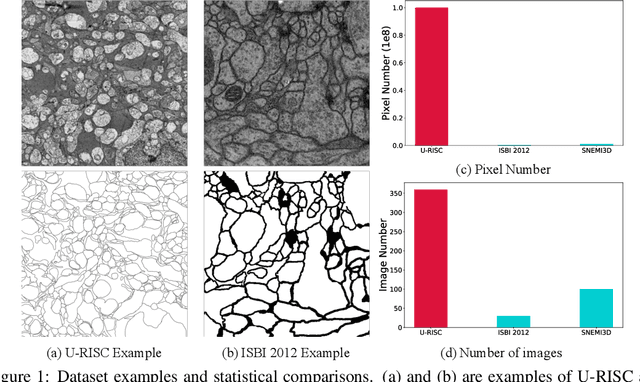
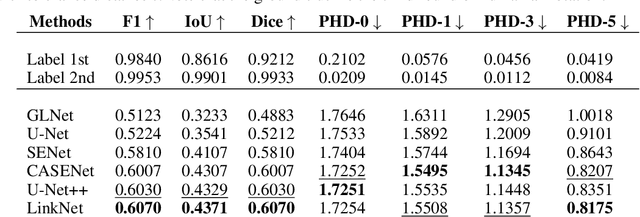
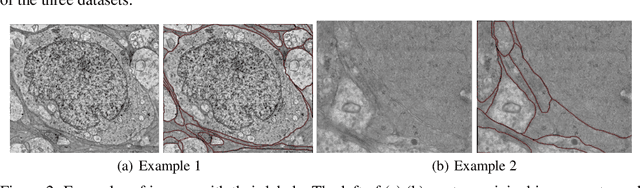

Computer vision technology is widely used in biological and medical data analysis and understanding. However, there are still two major bottlenecks in the field of cell membrane segmentation, which seriously hinder further research: lack of sufficient high-quality data and lack of suitable evaluation criteria. In order to solve these two problems, this paper first proposes an Ultra-high Resolution Image Segmentation dataset for the Cell membrane, called U-RISC, the largest annotated Electron Microscopy (EM) dataset for the Cell membrane with multiple iterative annotations and uncompressed high-resolution raw data. During the analysis process of the U-RISC, we found that the current popular segmentation evaluation criteria are inconsistent with human perception. This interesting phenomenon is confirmed by a subjective experiment involving twenty people. Furthermore, to resolve this inconsistency, we propose a new evaluation criterion called Perceptual Hausdorff Distance (PHD) to measure the quality of cell membrane segmentation results. Detailed performance comparison and discussion of classic segmentation methods along with two iterative manual annotation results under existing evaluation criteria and PHD is given.
Relevance Prediction from Eye-movements Using Semi-interpretable Convolutional Neural Networks
Jan 15, 2020
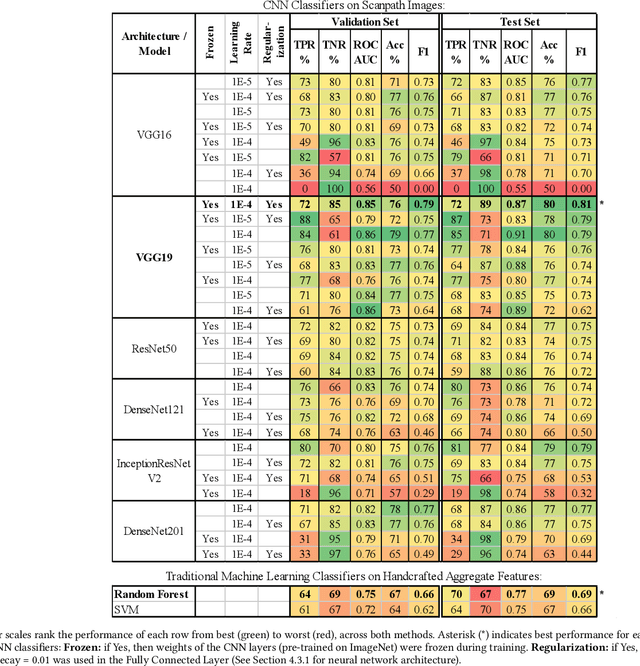
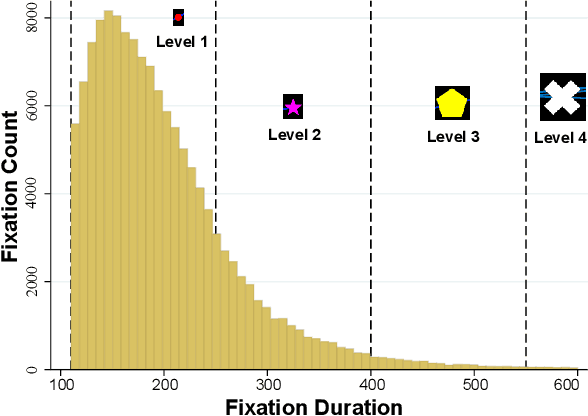
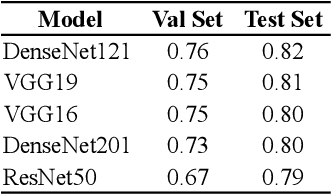
We propose an image-classification method to predict the perceived-relevance of text documents from eye-movements. An eye-tracking study was conducted where participants read short news articles, and rated them as relevant or irrelevant for answering a trigger question. We encode participants' eye-movement scanpaths as images, and then train a convolutional neural network classifier using these scanpath images. The trained classifier is used to predict participants' perceived-relevance of news articles from the corresponding scanpath images. This method is content-independent, as the classifier does not require knowledge of the screen-content, or the user's information-task. Even with little data, the image classifier can predict perceived-relevance with up to 80% accuracy. When compared to similar eye-tracking studies from the literature, this scanpath image classification method outperforms previously reported metrics by appreciable margins. We also attempt to interpret how the image classifier differentiates between scanpaths on relevant and irrelevant documents.
Human Segmentation with Dynamic LiDAR Data
Oct 16, 2020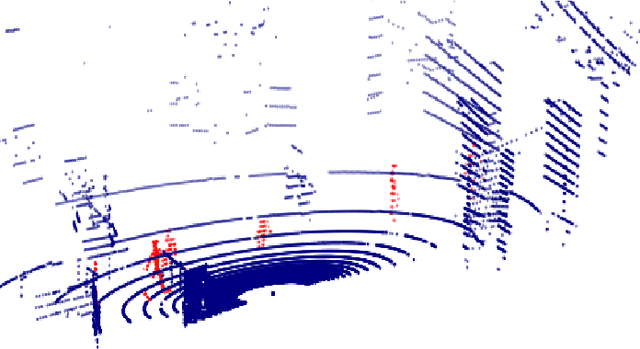
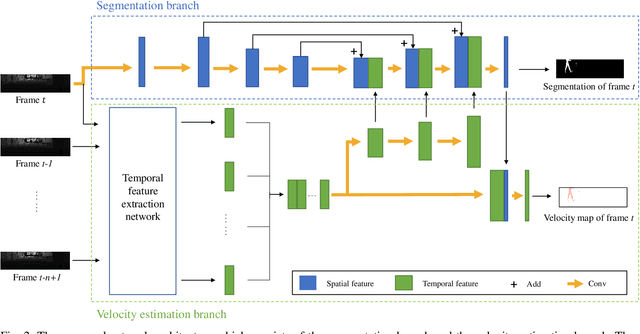
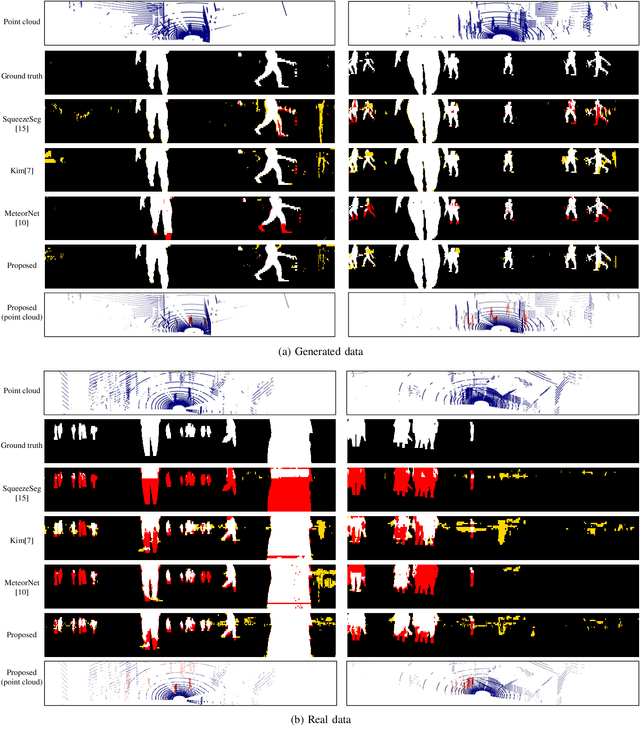
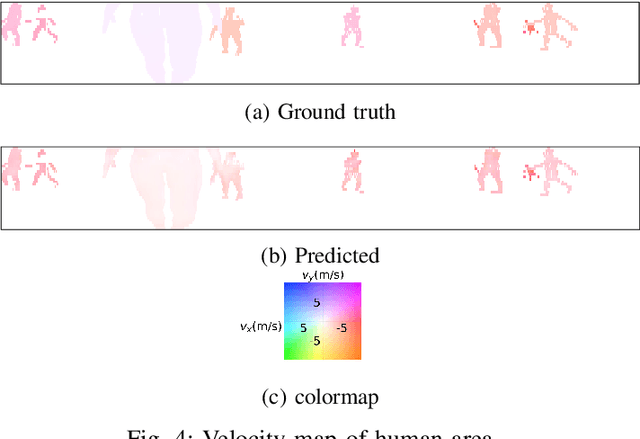
Consecutive LiDAR scans compose dynamic 3D sequences, which contain more abundant information than a single frame. Similar to the development history of image and video perception, dynamic 3D sequence perception starts to come into sight after inspiring research on static 3D data perception. This work proposes a spatio-temporal neural network for human segmentation with the dynamic LiDAR point clouds. It takes a sequence of depth images as input. It has a two-branch structure, i.e., the spatial segmentation branch and the temporal velocity estimation branch. The velocity estimation branch is designed to capture motion cues from the input sequence and then propagates them to the other branch. So that the segmentation branch segments humans according to both spatial and temporal features. These two branches are jointly learned on a generated dynamic point cloud dataset for human recognition. Our works fill in the blank of dynamic point cloud perception with the spherical representation of point cloud and achieves high accuracy. The experiments indicate that the introduction of temporal feature benefits the segmentation of dynamic point cloud.
Water level prediction from social media images with a multi-task ranking approach
Jul 14, 2020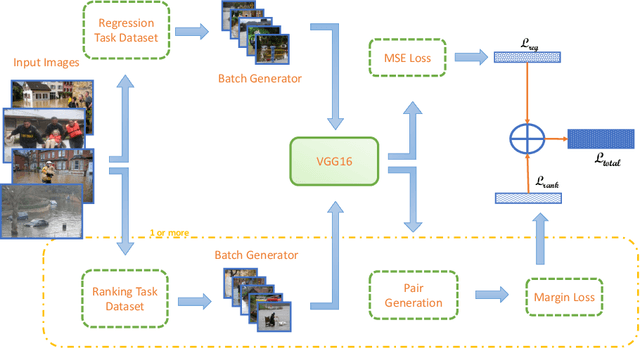
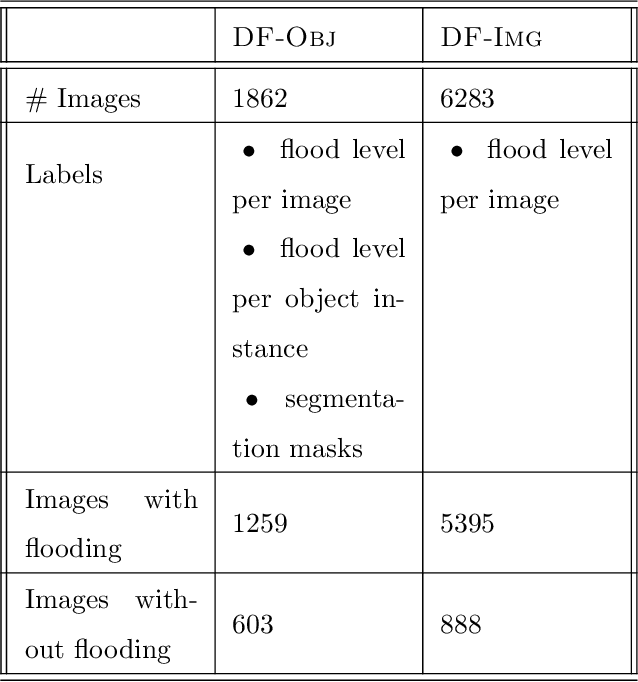
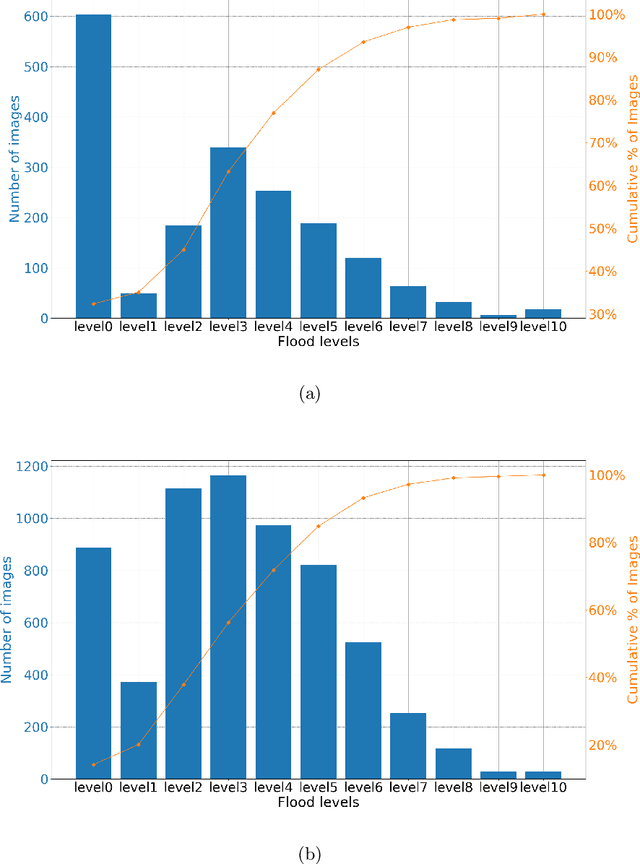
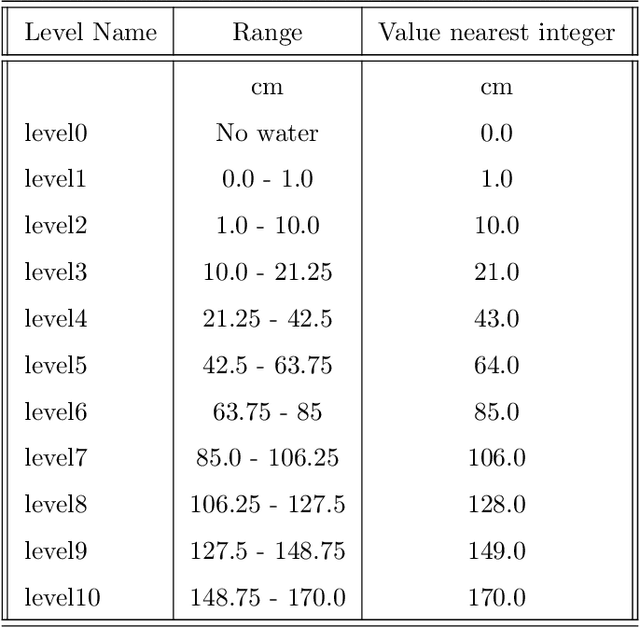
Floods are among the most frequent and catastrophic natural disasters and affect millions of people worldwide. It is important to create accurate flood maps to plan (offline) and conduct (real-time) flood mitigation and flood rescue operations. Arguably, images collected from social media can provide useful information for that task, which would otherwise be unavailable. We introduce a computer vision system that estimates water depth from social media images taken during flooding events, in order to build flood maps in (near) real-time. We propose a multi-task (deep) learning approach, where a model is trained using both a regression and a pairwise ranking loss. Our approach is motivated by the observation that a main bottleneck for image-based flood level estimation is training data: it is diffcult and requires a lot of effort to annotate uncontrolled images with the correct water depth. We demonstrate how to effciently learn a predictor from a small set of annotated water levels and a larger set of weaker annotations that only indicate in which of two images the water level is higher, and are much easier to obtain. Moreover, we provide a new dataset, named DeepFlood, with 8145 annotated ground-level images, and show that the proposed multi-task approach can predict the water level from a single, crowd-sourced image with ~11 cm root mean square error.
Autonomous Driving in Reality with Reinforcement Learning and Image Translation
Jan 13, 2018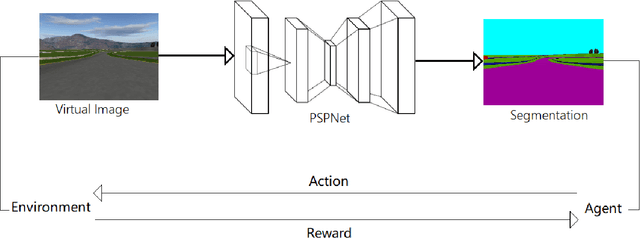



Supervised learning is widely used in training autonomous driving vehicle. However, it is trained with large amount of supervised labeled data. Reinforcement learning can be trained without abundant labeled data, but we cannot train it in reality because it would involve many unpredictable accidents. Nevertheless, training an agent with good performance in virtual environment is relatively much easier. Because of the huge difference between virtual and real, how to fill the gap between virtual and real is challenging. In this paper, we proposed a novel framework of reinforcement learning with image semantic segmentation network to make the whole model adaptable to reality. The agent is trained in TORCS, a car racing simulator.
A Time Series Graph Cut Image Segmentation Scheme for Liver Tumors
Sep 13, 2018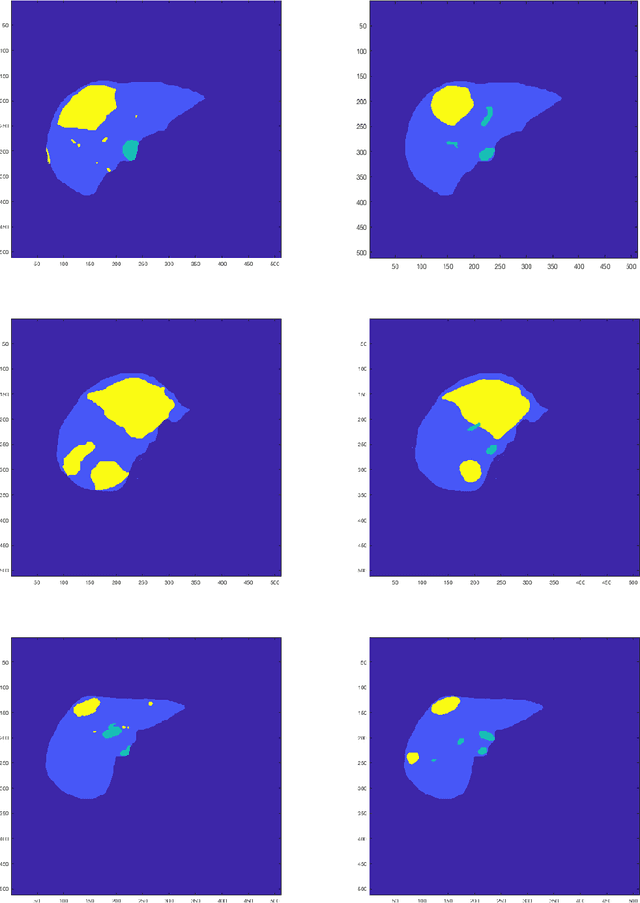
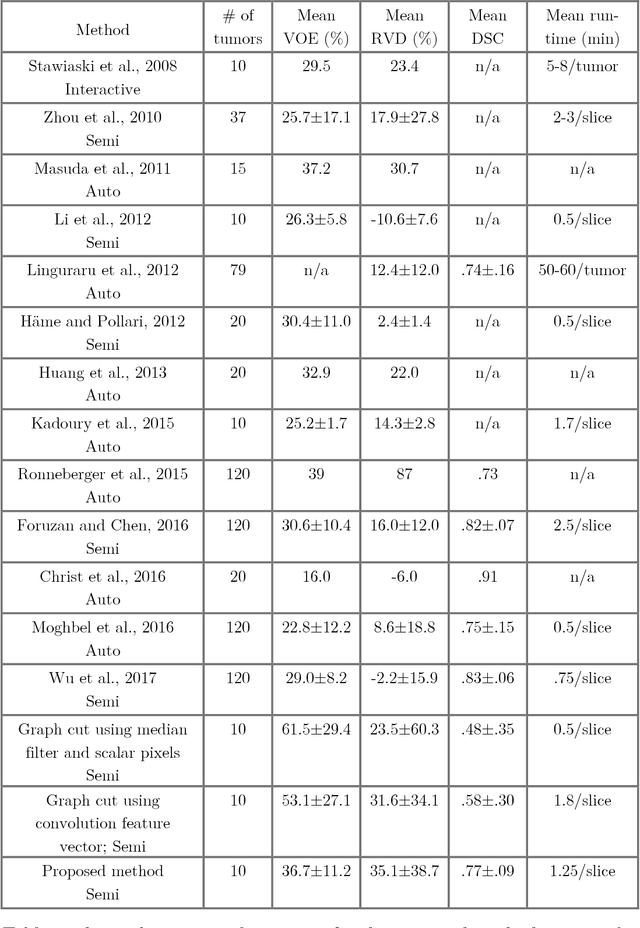
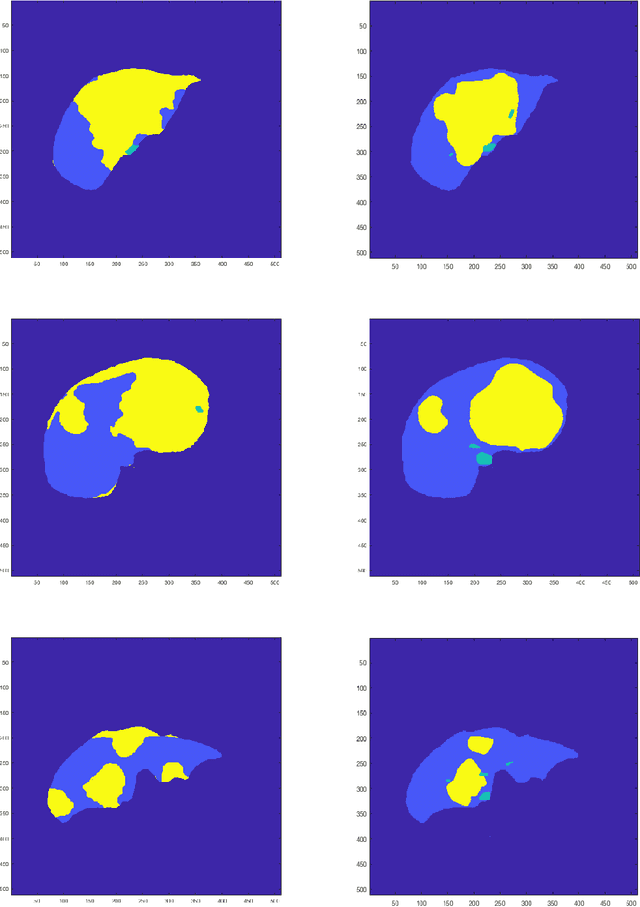
Tumor detection in biomedical imaging is a time-consuming process for medical professionals and is not without errors. Thus in recent decades, researchers have developed algorithmic techniques for image processing using a wide variety of mathematical methods, such as statistical modeling, variational techniques, and machine learning. In this paper, we propose a semi-automatic method for liver segmentation of 2D CT scans into three labels denoting healthy, vessel, or tumor tissue based on graph cuts. First, we create a feature vector for each pixel in a novel way that consists of the 59 intensity values in the time series data and propose a simplified perimeter cost term in the energy functional. We normalize the data and perimeter terms in the functional to expedite the graph cut without having to optimize the scaling parameter $\lambda$. In place of a training process, predetermined tissue means are computed based on sample regions identified by expert radiologists. The proposed method also has the advantage of being relatively simple to implement computationally. It was evaluated against the ground truth on a clinical CT dataset of 10 tumors and yielded segmentations with a mean Dice similarity coefficient (DSC) of .77 and mean volume overlap error (VOE) of 36.7%. The average processing time was 1.25 minutes per slice.