 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning-based Defect Recognition for Quasi-Periodic Microscope Images
Jul 02, 2020


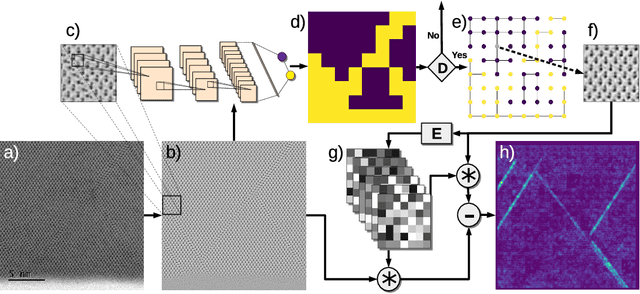

The detailed control of crystalline material defects is a crucial process, as they affect properties of the material that may be detrimental or beneficial for the final performance of a device. Defect analysis on the sub-nanometer scale is enabled by high-resolution transmission electron microscopy (HRTEM), where the identification of defects is currently carried out based on human expertise. However, the process is tedious, highly time consuming and, in some cases, can yield to ambiguous results. Here we propose a semi-supervised machine learning method that assists in the detection of lattice defects from atomic resolution microscope images. It involves a convolutional neural network that classifies image patches as defective or non-defective, a graph-based heuristic that chooses one non-defective patch as a model, and finally an automatically generated convolutional filter bank, which highlights symmetry breaking such as stacking faults, twin defects and grain boundaries. Additionally, a variance filter is suggested to segment amorphous regions and beam defects. The algorithm is tested on III-V/Si crystalline materials and successfully evaluated against different metrics, showing promising results even for extremely small data sets. By combining the data-driven classification generality, robustness and speed of deep learning with the effectiveness of image filters in segmenting faulty symmetry arrangements, we provide a valuable open-source tool to the microscopist community that can streamline future HRTEM analyses of crystalline materials.
Explaining Deep Neural Networks using Unsupervised Clustering
Jul 15, 2020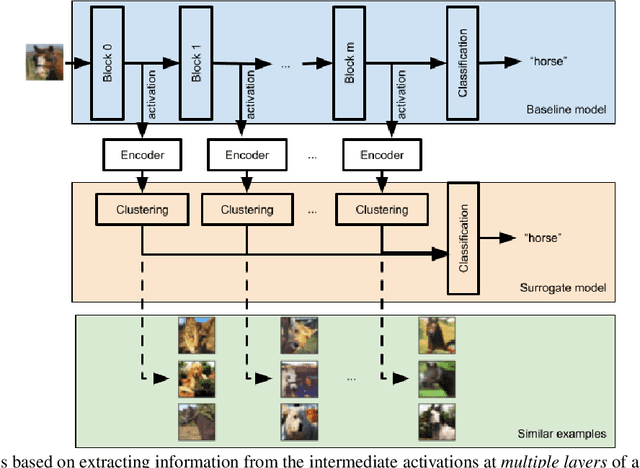


We propose a novel method to explain trained deep neural networks (DNNs), by distilling them into surrogate models using unsupervised clustering. Our method can be applied flexibly to any subset of layers of a DNN architecture and can incorporate low-level and high-level information. On image datasets given pre-trained DNNs, we demonstrate the strength of our method in finding similar training samples, and shedding light on the concepts the DNNs base their decisions on. Via user studies, we show that our model can improve the user trust in model's prediction.
DS-UI: Dual-Supervised Mixture of Gaussian Mixture Models for Uncertainty Inference
Nov 17, 2020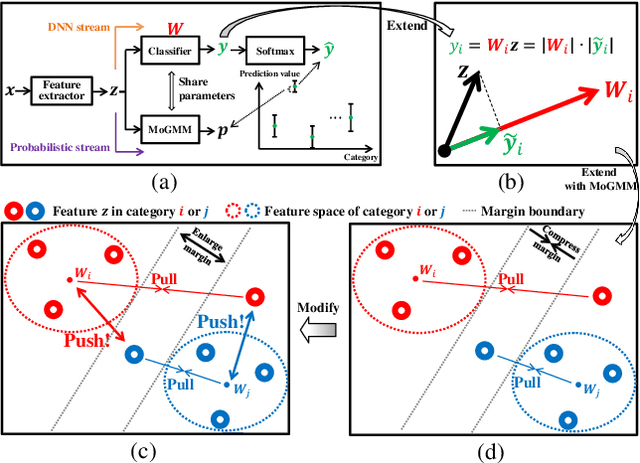
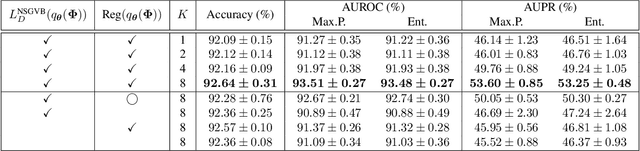
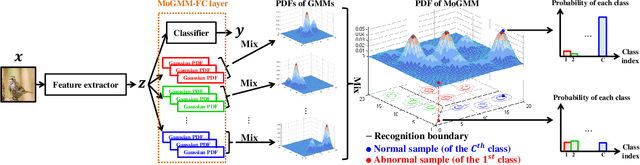
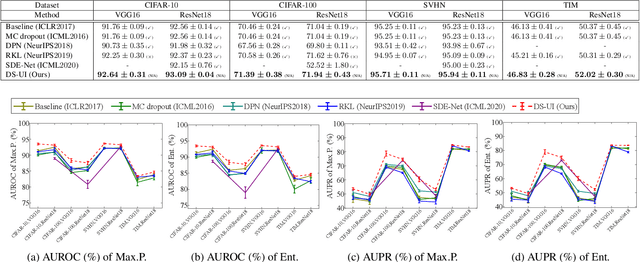
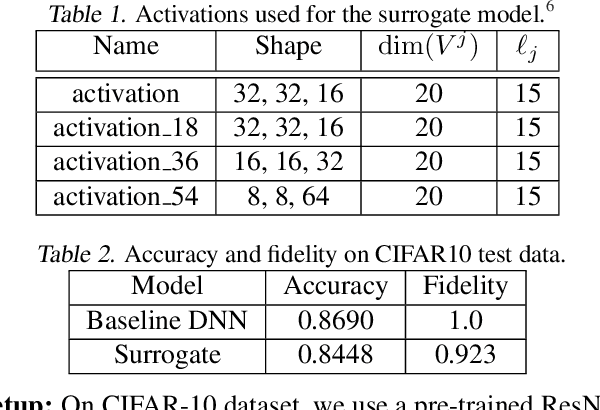
This paper proposes a dual-supervised uncertainty inference (DS-UI) framework for improving Bayesian estimation-based uncertainty inference (UI) in deep neural network (DNN)-based image recognition. In the DS-UI, we combine the classifier of a DNN, i.e., the last fully-connected (FC) layer, with a mixture of Gaussian mixture models (MoGMM) to obtain an MoGMM-FC layer. Unlike existing UI methods for DNNs, which only calculate the means or modes of the DNN outputs' distributions, the proposed MoGMM-FC layer acts as a probabilistic interpreter for the features that are inputs of the classifier to directly calculate the probability density of them for the DS-UI. In addition, we propose a dual-supervised stochastic gradient-based variational Bayes (DS-SGVB) algorithm for the MoGMM-FC layer optimization. Unlike conventional SGVB and optimization algorithms in other UI methods, the DS-SGVB not only models the samples in the specific class for each Gaussian mixture model (GMM) in the MoGMM, but also considers the negative samples from other classes for the GMM to reduce the intra-class distances and enlarge the inter-class margins simultaneously for enhancing the learning ability of the MoGMM-FC layer in the DS-UI. Experimental results show the DS-UI outperforms the state-of-the-art UI methods in misclassification detection. We further evaluate the DS-UI in open-set out-of-domain/-distribution detection and find statistically significant improvements. Visualizations of the feature spaces demonstrate the superiority of the DS-UI.
A review of deep learning in medical imaging: Image traits, technology trends, case studies with progress highlights, and future promises
Aug 02, 2020



Since its renaissance, deep learning has been widely used in various medical imaging tasks and has achieved remarkable success in many medical imaging applications, thereby propelling us into the so-called artificial intelligence (AI) era. It is known that the success of AI is mostly attributed to the availability of big data with annotations for a single task and the advances in high performance computing. However, medical imaging presents unique challenges that confront deep learning approaches. In this survey paper, we first highlight both clinical needs and technical challenges in medical imaging and describe how emerging trends in deep learning are addressing these issues. We cover the topics of network architecture, sparse and noisy labels, federating learning, interpretability, uncertainty quantification, etc. Then, we present several case studies that are commonly found in clinical practice, including digital pathology and chest, brain, cardiovascular, and abdominal imaging. Rather than presenting an exhaustive literature survey, we instead describe some prominent research highlights related to these case study applications. We conclude with a discussion and presentation of promising future directions.
Cascades of Regression Tree Fields for Image Restoration
Nov 21, 2014
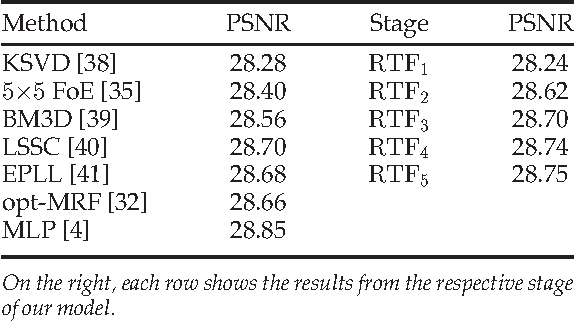
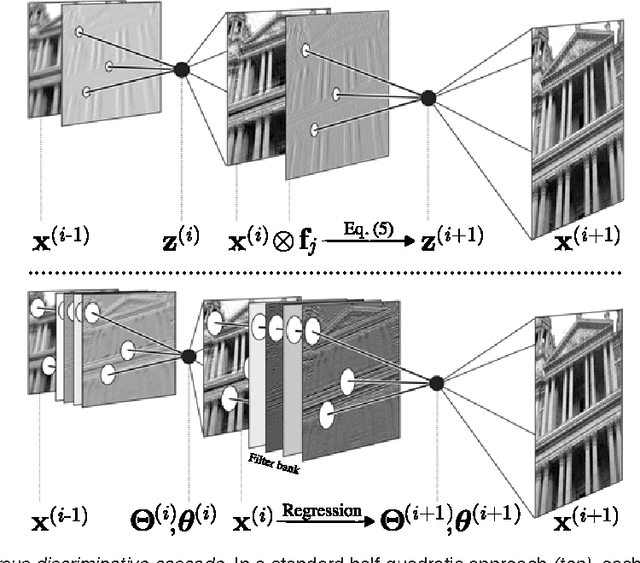
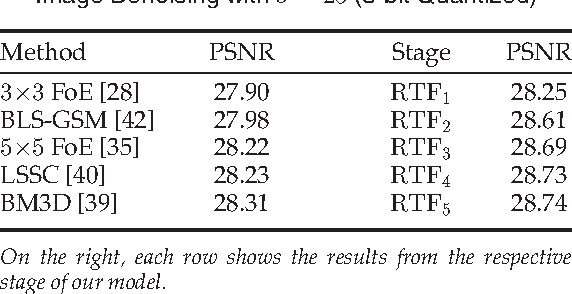
Conditional random fields (CRFs) are popular discriminative models for computer vision and have been successfully applied in the domain of image restoration, especially to image denoising. For image deblurring, however, discriminative approaches have been mostly lacking. We posit two reasons for this: First, the blur kernel is often only known at test time, requiring any discriminative approach to cope with considerable variability. Second, given this variability it is quite difficult to construct suitable features for discriminative prediction. To address these challenges we first show a connection between common half-quadratic inference for generative image priors and Gaussian CRFs. Based on this analysis, we then propose a cascade model for image restoration that consists of a Gaussian CRF at each stage. Each stage of our cascade is semi-parametric, i.e. it depends on the instance-specific parameters of the restoration problem, such as the blur kernel. We train our model by loss minimization with synthetically generated training data. Our experiments show that when applied to non-blind image deblurring, the proposed approach is efficient and yields state-of-the-art restoration quality on images corrupted with synthetic and real blur. Moreover, we demonstrate its suitability for image denoising, where we achieve competitive results for grayscale and color images.
On the use of Benford's law to detect GAN-generated images
Apr 16, 2020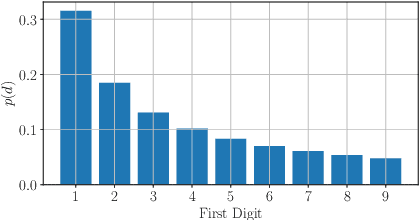
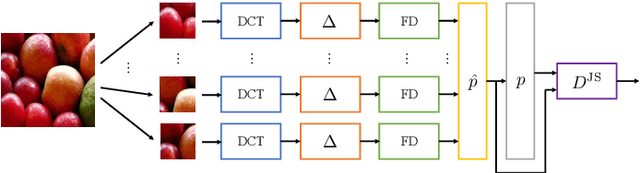
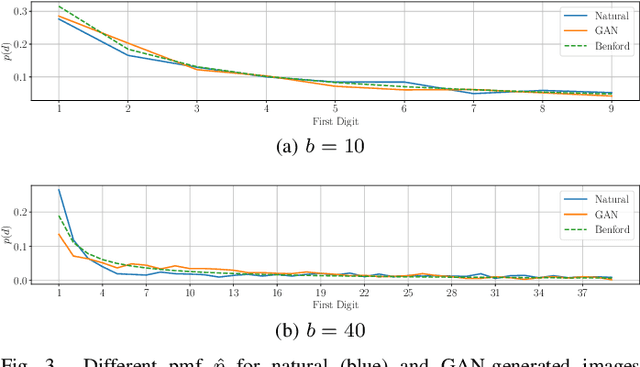

The advent of Generative Adversarial Network (GAN) architectures has given anyone the ability of generating incredibly realistic synthetic imagery. The malicious diffusion of GAN-generated images may lead to serious social and political consequences (e.g., fake news spreading, opinion formation, etc.). It is therefore important to regulate the widespread distribution of synthetic imagery by developing solutions able to detect them. In this paper, we study the possibility of using Benford's law to discriminate GAN-generated images from natural photographs. Benford's law describes the distribution of the most significant digit for quantized Discrete Cosine Transform (DCT) coefficients. Extending and generalizing this property, we show that it is possible to extract a compact feature vector from an image. This feature vector can be fed to an extremely simple classifier for GAN-generated image detection purpose.
Latent neural source recovery via transcoding of simultaneous EEG-fMRI
Oct 05, 2020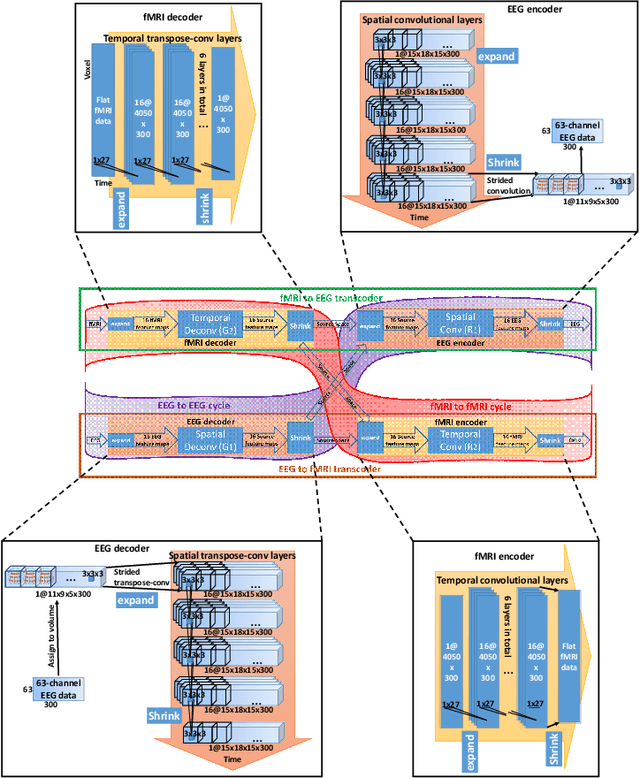
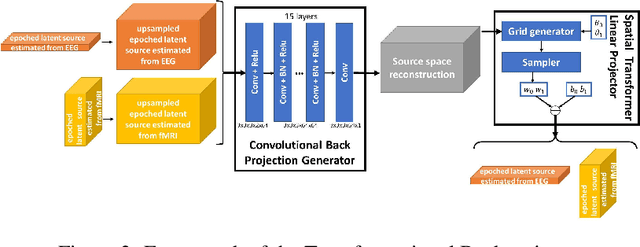
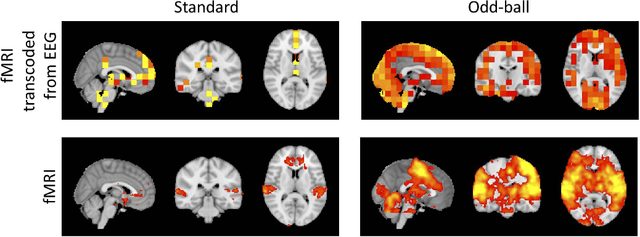
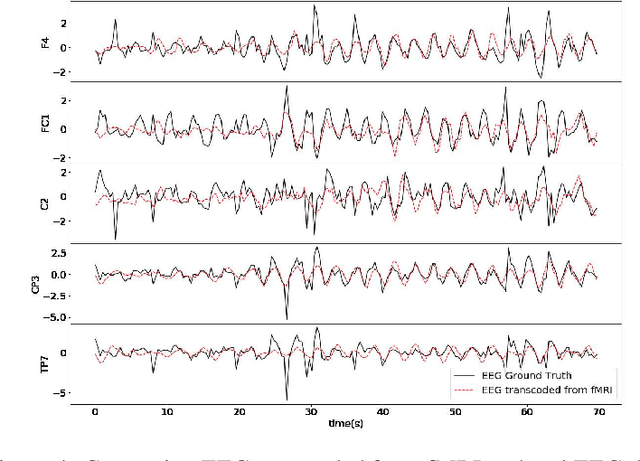
Simultaneous EEG-fMRI is a multi-modal neuroimaging technique that provides complementary spatial and temporal resolution for inferring a latent source space of neural activity. In this paper we address this inference problem within the framework of transcoding -- mapping from a specific encoding (modality) to a decoding (the latent source space) and then encoding the latent source space to the other modality. Specifically, we develop a symmetric method consisting of a cyclic convolutional transcoder that transcodes EEG to fMRI and vice versa. Without any prior knowledge of either the hemodynamic response function or lead field matrix, the method exploits the temporal and spatial relationships between the modalities and latent source spaces to learn these mappings. We show, for real EEG-fMRI data, how well the modalities can be transcoded from one to another as well as the source spaces that are recovered, all on unseen data. In addition to enabling a new way to symmetrically infer a latent source space, the method can also be seen as low-cost computational neuroimaging -- i.e. generating an 'expensive' fMRI BOLD image from 'low cost' EEG data.
Sampled Image Tagging and Retrieval Methods on User Generated Content
Dec 02, 2016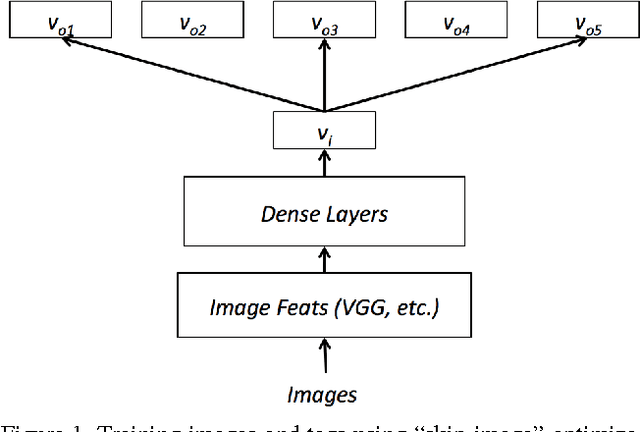
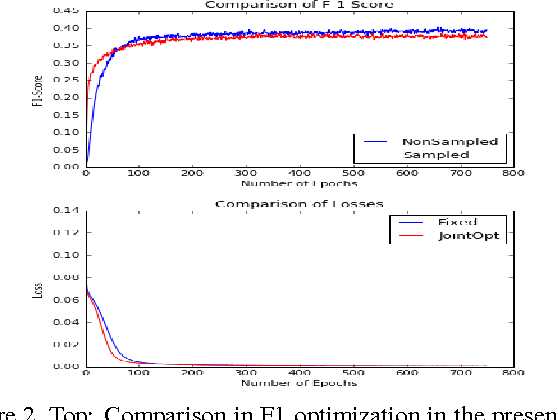
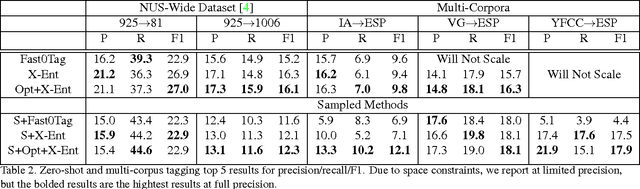
Traditional image tagging and retrieval algorithms have limited value as a result of being trained with heavily curated datasets. These limitations are most evident when arbitrary search words are used that do not intersect with training set labels. Weak labels from user generated content (UGC) found in the wild (e.g., Google Photos, FlickR, etc.) have an almost unlimited number of unique words in the metadata tags. Prior work on word embeddings successfully leveraged unstructured text with large vocabularies, and our proposed method seeks to apply similar cost functions to open source imagery. Specifically, we train a deep learning image tagging and retrieval system on large scale, user generated content (UGC) using sampling methods and joint optimization of word embeddings. By using the Yahoo! FlickR Creative Commons (YFCC100M) dataset, such an approach builds robustness to common unstructured data issues that include but are not limited to irrelevant tags, misspellings, multiple languages, polysemy, and tag imbalance. As a result, the final proposed algorithm will not only yield comparable results to state of the art in conventional image tagging, but will enable new capability to train algorithms on large, scale unstructured text in the YFCC100M dataset and outperform cited work in zero-shot capability.
Image Classification and Retrieval from User-Supplied Tags
Nov 25, 2014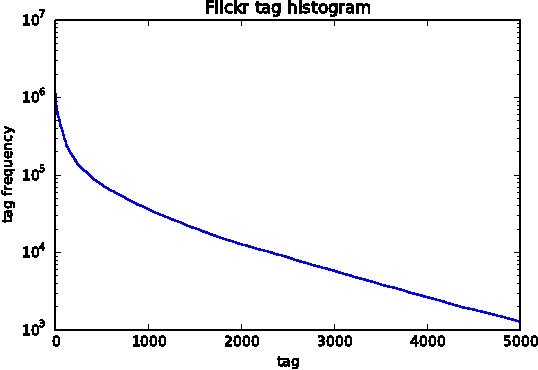
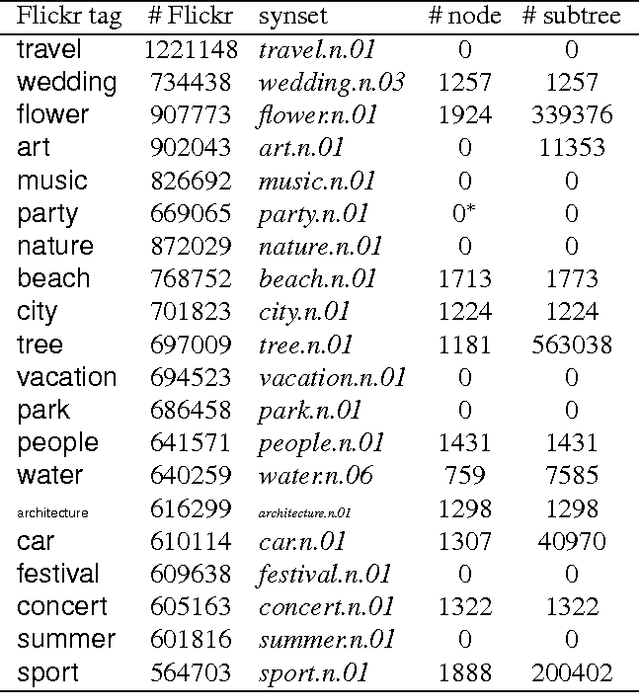
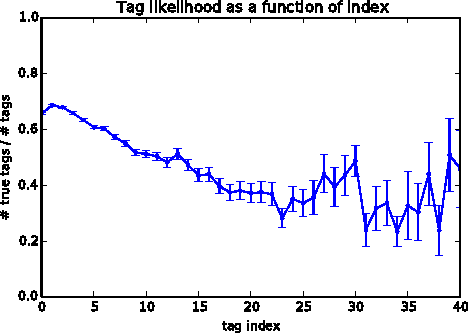
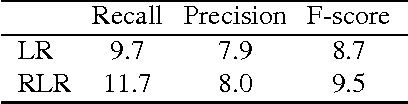
This paper proposes direct learning of image classification from user-supplied tags, without filtering. Each tag is supplied by the user who shared the image online. Enormous numbers of these tags are freely available online, and they give insight about the image categories important to users and to image classification. Our approach is complementary to the conventional approach of manual annotation, which is extremely costly. We analyze of the Flickr 100 Million Image dataset, making several useful observations about the statistics of these tags. We introduce a large-scale robust classification algorithm, in order to handle the inherent noise in these tags, and a calibration procedure to better predict objective annotations. We show that freely available, user-supplied tags can obtain similar or superior results to large databases of costly manual annotations.
Domain Stylization: A Strong, Simple Baseline for Synthetic to Real Image Domain Adaptation
Jul 24, 2018
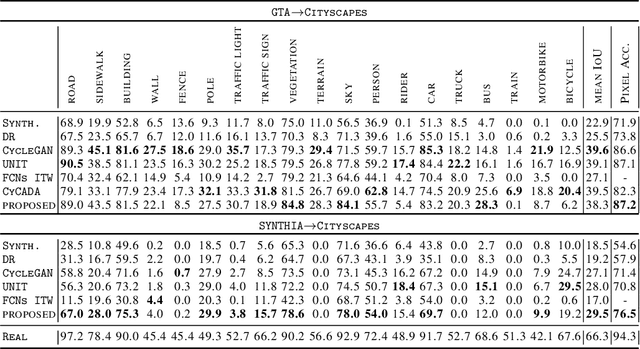

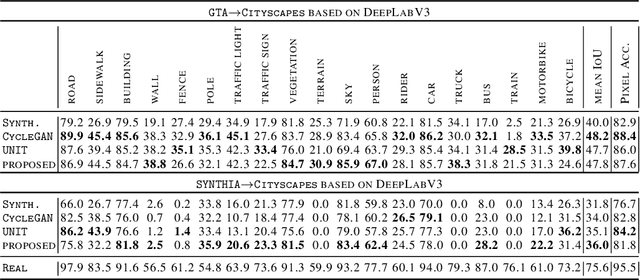
Deep neural networks have largely failed to effectively utilize synthetic data when applied to real images due to the covariate shift problem. In this paper, we show that by applying a straightforward modification to an existing photorealistic style transfer algorithm, we achieve state-of-the-art synthetic-to-real domain adaptation results. We conduct extensive experimental validations on four synthetic-to-real tasks for semantic segmentation and object detection, and show that our approach exceeds the performance of any current state-of-the-art GAN-based image translation approach as measured by segmentation and object detection metrics. Furthermore we offer a distance based analysis of our method which shows a dramatic reduction in Frechet Inception distance between the source and target domains, offering a quantitative metric that demonstrates the effectiveness of our algorithm in bridging the synthetic-to-real gap.